基于Apriori关联规则在信息无障碍网站的应用
2013-10-15张伟红
王 玉,张伟红,刘 雨
(吉林大学 应用技术学院,长春 130012)
0 引 言
信息无障碍是指无论健全人还是残疾人、无论年轻人还是老年人都能从信息技术中获益,任何人在任何情况下都能平等、方便、无障碍地获取和利用信息。
目前国内外的信息无障碍研究主要集中在相关的理论研究与技术研究。早在2002年就有学者对阿拉巴马州政府网站进行了无障碍水平评价,结果显示,无障碍水平虽有相当的进步,但水平仍然偏低,进而提出通过标准推动联邦一级公共部门实现信息无障碍。2006年Shadi[1]试图通过建立语义网络技术数据模型,对网页进行自动化易读性评价。Stuart[2]研究显示,交互式语音浏览器能为弱视的用户提供可访问世界各地网页的工具。Vicente[3]对网页内容易读性指导方针W3C的WCAG进行分析,以方便残疾人士使用浏览器获取信息,并对网页无障碍程度的评价工具进行了分析。我国在这方面的研究相对滞后。
通过实现信息无障碍,加大社会宣传,促进政府、企业相关部门加大建设信息无障碍力度,可使更多的人群在信息社会中受益。通过实现网页无障碍的相关新闻、最新政策的发布、信息无障碍行业标准技术发表等,提高政府、企业相关部门对信息无障碍的认识、呼吁全社会关心信息无障碍事业,加速网站无障碍事业的发展。笔者旨在通过在Web日志数据中挖掘关联规则以指导信息无障碍网站的设计与开发。根据3次点击原则及网站结构设计的特点,针对大量用户对网站页面URL的访问频率等信息通过Apriori算法实现数据挖掘,以寻找用户访问页面之间的关联规则,优化网站结构,实现网站信息无障碍化。
1 数据挖掘相关技术
数据挖掘是指从大量的、模糊的、不完全的、随机的数据中提取隐含的,人们无法用肉眼发现的一些潜在的信息和知识的过程,数据挖掘技术已在社会各方面得到广泛应用[4,5]。数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术。主要包含数据准备、规律寻找和规律表示3个步骤。数据准备是从相关的数据源中选取所需的数据并整合成用于数据挖掘的数据集; 规律寻找是用某种方法将数据集所含的规律找出来;规律表示是尽可能以用户可理解的方将找出的规律表示出来。数据挖掘的任务可分为关联规则发现、数据聚类、分类知识发现、序列模式发现和趋势预测等,典型数据挖掘系统结构如图1所示。
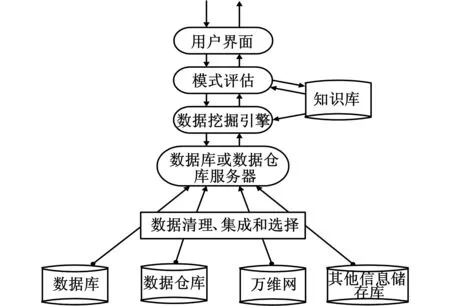
图1 典型数据挖掘系统结构
数据挖掘是在数据库领域中占比较重要地位的领域,国内外数据挖掘的发展趋势及其研究方向主要有知识发现方法的研究及应用。目前大部分有关数据挖掘的研究主要集中在数据挖掘的数据总结、分类、聚类和关联规则等方面。关联规则挖掘作为数据挖掘的核心内容之一,近年来得到了很快的发展,并成为当今数据挖掘的热点。
网站的数据挖掘主要是对Web日志的挖掘[6,7],Web日志如何产生这里不再进行详细介绍。Web日志挖掘主要分为数据的预处理、数据发现、模式识别和模式分析5个步骤。在模式识别中,主要用了路径分析和关联规则两种技术。
1.1 数据预处理
用户访问网站后,在Web日志中会产生一系列的数据,这些数据不能完全被人们用到,如网站的结构都会产生Web日志,还有一些图片等无用的数据。数据预处理是对那些人们用不到的数据,即被称为“脏”数据进行处理[8]。这些处理主要用一些数据库的操作语言实现的,把这些语言嵌套在实现数据挖掘的程序代码中,在其进行数据挖掘前,由程序自动清理。数据预处理是个重要的过程,如果在这个过程对数据不能进行有效处理,将会影响到后面的操作,出现结果不准确等问题。
1.2 数据发现
数据发现主要是通过一些程序处理,把Web日志中对人们有用的数据存储到事务数据库中,以便以后对这些数据的应用。这里把能用到的数据单独放到一个容器,就可以对容器进行操作,提高了程序执行的速度和效率。
1.3 关联规则
关联规则最早是Agrawal等[9,10]于1993年提出的,假设I是项的集合,给定一个交易数据库D,其中每个事务T是I的非空子集,即每个交易都与一个唯一的标识符TID(Transaction IDentity)对应。设一个X项集,T中包含A。关联规则是形如X⟹Y的蕴含式,在D中的支持度S是D中事务同时包含项集X、项集Y的百分比,即概率; 置信度c是包含X的事务中同时又包含Y的百分比,即条件概率。
同时满足最小支持度阈值和最小置信度阈值的规则成为强规则,这些阈值是根据挖掘需要人为设定的。关联规则的挖掘一般分为两个步骤:1)找出所有频繁项集,这些项集的支持度必须满足用户给定的最小支持度; 2)根据找出的频繁项集产生强关联规则,这些规则必须满足最小支持度和最小可信度。
支持度和置信度是描述关联规则的两个重要概念,前者用于衡量关联规则在整个数据库中的统计重要性,后者用于衡量关联规则的可信程度。一般来说,只有支持度和置信度均较高的关联规则才可能是用户感兴趣、有用的关联规则。关联规则的挖掘问题就是在事务数据库D中找出具有用户给定的最小支持度minsup和最小置信度minconf的关联规则。若support(X⟹Y)≥minsup且confidence(X⟹Y)≥minconf,称关联规则X⟹Y为强规则。
2 基于改进的Apriori算法的Web日志挖掘过程
Apriori 算法是最有影响的挖掘布尔关联规则频繁项集的算法之一,Apriori 算法使用频繁项集性质的先验知识,是最有影响的挖掘布尔型关联规则频繁项集的算法[11]。Apriori算法基于Apriori性质----频繁项集的所有非空子集都必须是频繁的,以压缩搜索空间。笔者主要利用Apriori算法找出数据的关联规则,通过关联规则挖掘的实现找出事务数据之间的关系。
2.1 Apriori算法
Apriori算法查找频繁项集的基本思想是:首先找出所有的频繁集,这些项集出现的频繁性至少和预定义的最小支持度一样; 然后由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小可信度; 再由找到的频繁项集产生期望的规则。一旦这些规则被生成,则只有大于用户给定的最小可信度的规则才被保留。
Apriori算法在第1次迭代时,由I直接构成候选I项目集的集合CI,若I={i1,i2,…,im},则CI={{i1},{i2},…,{im}}。Apriori算法在第k次迭代中,先根据上一次迭代过程中找到的频繁项目集的集合Fk-1产生本次迭代的候选项目集的集合Ck; 然后为Ck中的每个项目集分配一个初始为零的计数器,依次扫描数据集D中的事务,确定包含在每条事务中并且属于Ck的项目集,增加这些项目集的计数器值,在所有事务都扫描完后即可得到Ck中各项目集的支持数,根据数据集D的事务总数|D|和最小支持度计算各项目集的支持度就可确定Ck中频繁项目集。重复上述过程直到没有新的项目集产生为止。
为生成所有频集,使用了递归的方法。首先找到频繁1-项集的集合,记作L1,用L1找出频繁项集L2,以此类推直到最后找到的项集为空时为止。
算法结构化描述过程如下:
1)L1=find_frequent_1-itemsets(D);//挖掘频繁1-项集
2)for (k=2;Lk-1≠Φ;k++){
3)Ck=apriori_gen(Lk-1,min_sup);//调用apriori_gen方法生成候选频繁k-项集
4)for each transactiont∈D{//扫描事务数据库D
5)Ct=subset(Ck,t);
6)for each candidatec∈Ct
7)c.count++;//统计候选频繁k-项集的计数
8)}
9)Lk={c∈Ck|c.count≥min_sup} //满足最小支持度的k-项集即为频繁k-项集
10)}
11)returnL=∪kLk;//合并频繁k-项集(k>0)
2.2 针对无障碍Web访问的算法改进
在Apriori算法用于网页链接关系的发现中,Apriori算法中的事务对应于用户的一次访问活动,数据集对应于网页页面集,通过应用Apriori算法来找到网页页面的链接关系。但如果直接应用Apriori算法挖掘网页结构的频繁集,频繁集数量会非常庞大,特别是发现频繁集在最坏情况下可达到指数级,使其难以应用到现实的页面关系挖掘中。
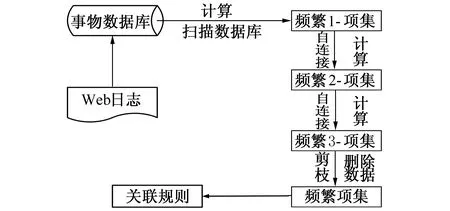
图2 基于Apriori算法的数据挖掘过程
根据交互设计领域的基本理论之一的“3次点击”原则,即对于Web设计来说,如果用户在3次点击中无法找到信息或完成网站功能,用户就会对该网站失去耐心,对信息无障碍网站的设计和开发更需要遵循这样的设计原则。因此,信息无障碍网站在网站的结构设计上最多只设置3层链接深度,即从网站首页开始到网站任意子页面不超过3层链接。
根据上述网站结构的特点,网页之间的超链接不超过3个网页,所以对于发现网页之间的频繁集而言,只需要发现频繁3-项集即可,而不必发现大于3-项集的频繁集,基于Web日志的Apriori改进算法,使频繁集的挖掘大大减少,不仅可满足网站的需要,而且降低了算法的时间复杂度。
基于改进的Apriori算法的数据挖掘过程如图2所示。
2.3 算法实现过程
算法实现及结果如下。
Step1 数据收集及数据净化处理。从服务端获得Web日志数据库信息,删除日志文件中不是由用户请求,而是由浏览器自动请求产生的访问记录。图3是经过处理后的数据库。

图3 数据预处理后的Web日志数据库
Step2 对Web日志进行预处理,得到事务数据库。事务数据库主要由用户IP及每次访问的URL信息组成。
Step3 扫描事务数据库,计算每个数据项出现的次数。根据给定的最小支持度(0.8),挖掘出挖掘频繁1-项集的集合,每项的支持度都必须大于或等于0.8。
Step4 挖掘频繁1-项集自身连接,重复Step3的操作,产生候选频繁2-项集; 再根据给出的最小支持度(0.8)挖掘出挖掘频繁2-项集。
Step5 挖掘频繁2-项集的自身连接,重复Step3的操作,产生候选频繁3-项集,因为其自身连接产生的子集为空; 再根据给出的最小支持度(0.8)挖掘出挖掘频繁3-项集。
Step6 执行上述过程后,程序会根据Apriori的频繁项集的所有子集都是频繁原理进行剪枝操作,把不符合要求的数据删除,从而产生频繁项集,最终通过程序的挖掘获得关联规则。
各步骤结果及数据挖掘发现的关联规则如图4所示。
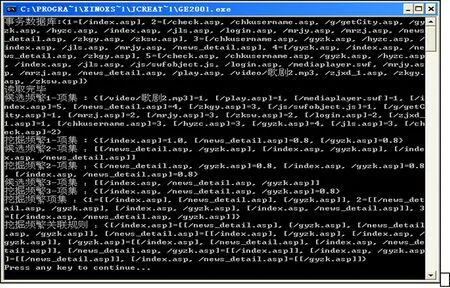
图4 数据挖掘结果
通过上面的步骤实现了数据的挖掘,找到了需要的关联规则,通过这些数据可找出访问网站的用户在浏览这个网页的同时还喜欢浏览的网页类型,以便为其做出推荐。
3 结 语
通过上述工作,达到了信息无障碍网站设计的基本目标,网站可通过用户在访问网站时Web日志数据库中的信息,利用数据挖掘方法分析得到用户访问网页之间的链接关系,通过分析网站结构,结合“3次点击”原则,在网站的结构设计上最多只设置3层链接深度,频繁项集只需发现网站频繁3-项集即可,针对此结构特征,减少了数据集的复杂性,有效降低了算法的时间复杂度。
上述过程是对访问过网站所有用户的数据进行分析,产生的关联规则适用于大多数用户。下一步工作则主要通过对每个IP地址进行分析,借助上述方法找到每个IP地址访问内容的关联规则,了解每个用户感兴趣的网页,以实现对每个用户进行内容推荐,进一步完善网站,让更多人受益。
参考文献:
[1] SHADI ABOU-ZAH RA.A Data Model to Facilitate the Automation of Web Accessibility Evaluations[J].Electronic Notes in Theoretical Computer Science,2006,157(2):3-9.
[2]STUART GOOSE.Enhancing Web Accessibility via the Vox Portal and a Web-Hosted Dynamic HTML ↔ VoxML Converter[J].Computer Networks,2000,33(6):583-592.
[3]VICENTE LUQUE CENTENO.Web Accessibility Evaluation Tools:A Survey and Some Improvements[J].Electronic Notes in Theoretical Computer Science,2006,157(2):87-100.
[4]孙兵,刘雯,田地,等.基于时间序列的数据挖掘在证券中的应用[J].吉林大学学报:信息科学版,2010,28(3):270-274.
SUN Bing,LIU Wen,TIAN Di,et al.Application of Time Series Data Mining on Security Analysis[J].Journal of Jilin University:Information Science Edition,2010,28(3):270-274.
[5]于曼,胡明,金刚,等.关联规则算法的电信网络告警应用[J].吉林大学学报:信息科学版,2010,28(3):264-269.
YU Man,HU Ming,JIN Gang,et al.Association Rules Algorithm Applied to Telecommunications Network Alarms[J].Journal of Jilin University:Information Science Edition,2010,28(3):264-269.
[6]汤恒耀,占晓燕.基于Web日志挖掘的信息无障碍网站设计研究[J].电脑知识与技术,2011,7(4):3261-3262.
TANG Heng-yao,ZHAN Xiao-yan.The Research of the Accessibility Website Design Baed on Web Log Mining[J].Computer Knowledge and Technology,2011,7(4):3261-3262.
[7]宋淑彩,祁爱华,王剑雄.面向Web的数据挖掘技术在网站优化中的个性化推荐方法的研究与应用[J].科技通报,2012,28(2):117-119.
SONG Shu-cai,QI Ai-hua,WANG Jian-xiong.Facing the Web Site of the Data Mining Technology in the Opti-Mization of Personalized Recommendation Methods of Research and Application[J].Bulletin of Science and Technology,2012,28(2):117-119.
[8]姚洪波,杨炳儒.Web日志挖掘数据预处理过程技术研究[J].微计算机信息,2006,22(18):234-236.
YAO Hong-bo,YANG Bing-ru.Research of Data Preparatin Based on Design Based on Web Log[J].Micro Computer Information,2006,22(18):234-236.
[9]AGRAWAL R,IMILIENSKI T,SWAMI A.Mining Association Rules between Sets of Items in Large Database[C]∥SIGMOD.Washington DC:[s.n.],1993:207-216.
[10]AGRAWAL R,SRIKANT R.Fast Algorithms for Mining Association Rules[C]Proceedings of the 20thInternational Conference on Very Large Databases.Santiago,Chile:[s.n.],1994:487-499.
[11]毕永成.Web日志处理中Apriori算法及其改进[J].电脑知识与技术,2010,14(6):3573-3574.
BI Yong-cheng.Apriori Arithmetic and Amelioration in Weblog Disposal[J].Computer Knowledge and Technology,2010,14(6):3573-3574.
