一种基于可用性的动态云数据副本管理机制
2018-03-27陶永才
陶永才,巴 阳,石 磊,卫 琳
1(郑州大学 信息工程学院,郑州 450001) 2(郑州大学 软件技术学院,郑州 450002)
1 引 言
近年来随着科学技术的快速发展,云计算、物联网、社会网络等新技术应运而生,数据的类型和数量呈现爆炸式增长,大数据时代已经到来.
云存储把互联网上大量地理上分散的存储设备整合到一个存储池中,应用虚拟化技术,基于低成本、不可靠的节点和网络资源,为用户提供大容量和高性能的云存储服务[1].云存储是云计算的基础,其规模正以惊人的速度扩大.目前比较流行的云存储系统有RAID 1,GFS[1],Ceph[2]和HDFS[3].
在云存储中,为提高性能,数据分块是一种广泛采用的技术[4].除了最后一个块,文件被分割成多个大小相同的块.这些块分布存储在各数据节点中,通过并行传输数据,提高数据带宽.然而,由于云存储系统的动态性、分布性和异构性,节点软硬件故障、电源故障和网络故障时常发生,导致数据块无法访问[16].因此,一个数据块访问故障可能会导致整个文件不可用.为了避免由节点故障引起的访问失败和数据丢失,数据副本被广泛采用,通过在不同节点上放置数据副本来保证云存储中数据的可靠性和可用性[5].数据副本保证如果一个数据节点失效,数据仍然可用,服务将不中断.除了提高数据可靠性和可用性之外,如果副本的分布和请求合理,副本机制将能改善系统负载平衡和总体性能.
现有的云存储系统(如Amazon S3[6]、GFS和HDFS)主要采用静态副本管理策略,副本因子一般为3,放置策略是将一个副本放置在本地机架上的节点,另一个副本放在同一机架上的其他节点,最后一个副本放在不同机架上的任意一个节点[7].这种机制存在一些缺点.首先,在可靠性高的云存储系统中,副本会占用大量的存储空间,提高云存储系统的可靠性成本,最终转嫁给用户.其次,该机制无法适应动态变化的数据访问量和节点性能变化,导致系统负载不均衡和性能低.
为解决上述问题,本文提出一种动态副本管理机制DRM(Dynamic Replica Management scheme),DRM主要贡献如下:
1)研究确定数据可用性和副本数之间的关系模型,并利用此模型来动态计算和维护给定可用性要求的最小副本数.
2)基于节点性能和用户访问特性确定副本放置位置.
本研究在HDFS上实现了DRM,实验结果表明DRM在成本、负载平衡和性能都优于现有HDFS副本管理机制.
2 相关工作
现有的GFS和HDFS的副本管理使用默认数量,通过数据迁移实现负载均衡,消耗较多的带宽资源[3].
副本放置对于存储系统的数据可用性和容错至关重要[12].一个好的副本放置策略可以提高数据可靠性、可用性和网络带宽利用率.因此,如果副本分布和请求合理,优化副本策略不仅可以提高可用性,还可以提高负载均衡和总体性能.文献[8]提出面向用户的副本放置策略,把副本放置在距离用户较近的节点上,使得访问数据时能够较快地获取数据.文献[9]提出面向请求的副本放置策略,对经常访问的数据创建较多的副本,并把副本放置到用户访问密集的区域.此方法能够明显减少查找路径长度,从而提高查询效率.文献[10]提出面向业务的副本放置策略在具有最多转发流量的节点上进行副本放置,与面向请求的方法相比,其副本可以为大多数请求者服务,使得利用率更高.文献[11]提出了一种改进的数据放置策略,该策略基于数据负载和结点网络距离计算各个结点的调度评价值,依据此调度评价值选择一个最佳的远程数据副本的放置结点.
上述研究都是采用类似HDFS中的静态副本管理策略.在很多情况下,仅仅使用三个副本放置策略会引起巨大的空间资源的浪费,它无法适应动态变化的数据访问和节点性能,并会导致糟糕的性能和负载不均衡,本文提出的动态副本管理机制,根据可用性来决定副本的数量,基于节点性能和用户访问特性确定副本放置位置.不仅节省了大量的存储空间,也提高了大规模云存储的性能.
3 问题分析
数据副本一定程度上满足了数据可靠性的要求,但是需要更多的存储空间.在云存储中,如果采用一些适当的策略,数据副本机制仍可以减少对存储空间的占用.数据副本机制必须面临两个挑战:副本数量和副本放置.
在实际应用中,数据访问是高度不规则的,呈现时间局部性和空间局部性,数据时间局部性是一些数据在一定时间段内被访问频率很高,数据空间局部性是用户对数据的访问主要集中一些热点区域[17].因此,热点区副本访问量通常偏高,节点负载过大,无法满足用户的访问质量.相反,一些数据副本很少被访问,而且有些热点区副本随着时间的推移会被冷却,所以,过多的副本将浪费存储资源,并导致不必要的维护开销.
Hadoop[7]采用3副本策略,存储1 GB数据需要3 GB的数据空间,这将导致200%的额外成本.对于一些数据密集型应用程序,额外的花费可能是巨大的.然而,在实际中,有些数据不需要可靠性保证,比如一些应用的中间结果数据.对于这类数据,可以不采用副本机制.此外,对于有高可靠性保证要求的关键数据,固定的3副本策略并不能保证.在爆炸性访问突发的情况下应该始终保持最大数量的副本,还是保持较少副本以牺牲性能为代价来节省资源?因此,系统应保留多少个副本以满足可用性要求是云存储需要解决的一个难题?
另一方面,与小规模同构系统相比,分布式大规模异构存储系统中的副本放置更复杂,其中每个数据节点可能具有不同的处理能力(包括CPU、存储、网络带宽等),并且只能提供有限数量的访问请求.在这种异构存储系统中平均的副本分配策略不能达到负载均衡和优化总体性能.相反,可能会发生访问倾斜,使得热数据节点的请求被拒绝,而其他数据节点处于空闲,从而导致系统负载不均衡和低性能[18].
为了降低存储成本,提高存储性能和负载均衡,上述问题必须予以考虑.
4 动态副本管理机制DRM
本文提出一种动态副本管理机制DRM,旨在优化如何基于可用性来确定副本数目和副本放置位置问题.
4.1 基于可用性的副本创建模型
DRM研究数据可用性和副本数之间的关系,设计基于可用性的副本创建模型,并利用此模型来动态计算和维护给定可用性要求的最小副本数[13].
符号定义如表1所示.
表1 符号的定义
Table 1 Definition of symbols

符号定义P(NAi)数据节点Ai的可用概率P(NAi)数据节点Ai的不可用概率P(BAi)数据块Bi的可用概率P(BAi)数据块Bi的不可用概率P(FA)文件F的可用概率P(FA)文件F的不可用概率Aexcept期望文件F的可用性
在云存储系统中,假设文件F由m个数据块组成,标记为{b1,b2,…,bm},并存放到不同的数据节点中.假设块bi有rj个副本,如果这个块的所有节点都是不可用的,说明这个块是不可用的,所以块bi不可用的概率如式(1)所示.
(1)
因为所有节点都是独立的,所以可以得到:
(2)
云存储数据可靠性服从指数分布.根据经典理论[14],假设一个云存储节点的可靠性在时间T内服从指数分布:
F(T)=e-λ T
(3)
其中λ是云存储节点的故障率,F(T)表示在某时间段内云存储节点故障的期望值.
假设多个副本存储在不同的存储节点中.根据云存储节点可靠性,数据的可靠性与多个副本的关系可以由式(4)计算.
(4)
Trj为rj个副本的存储生命期时间.
要保证文件的可用性就必须要求所有的块可用,一个不可用的块会导致整个文件不可用,如式(5)所示.
(5)
DRM假设数据块相互独立,即块bj的不可用不会影响块bk.可以获得:
(6)
由式(4)和(5)可计算得式(7).
(7)
则文件F的可用性如式(8)所示.
(8)
如果要满足文件F的可用性Aexcept,则式(9)应满足成立.
(9)
DRM使用式(9)计算最小副本数rmin以满足具有平均数据节点故障率的预期可用性.在数据节点失效或者数据块的当前副本数量小于rmin的情况下,额外的副本将被创建到云存储的数据节点中.
此外,对于不是关键的并且仅用于短期的数据类型,可以采用相对低的可靠性保证,并且不需要必要的数据回复,因此副本的数量可以设置为1.
4.2 智能副本放置机制
大型云存储系统的存储节点通常分布在集群的多个机架中,节点间通过交换机互连.不同机架节点间的通信必须经过交换机.通常情况下,同一机架节点间的网络带宽大于不同机架节点间的网络带宽.
目前的云存储系统(HDFS)采用静态副本管理机制,不考虑节点异构性,地理分布性.这将导致副本成本增加、负载不均衡和低性能.因此,在智能副本放置机制应考虑一些重要因素,例如:访问热点变化、网络带宽、阻塞概率、节点异构性、负载不均衡等.
为解决上述问题,DRM采用智能副本放置机制,采用三种不同的副本放置策略(面向用户,面向请求和面向业务)适应不同的应用场景.副本放置机制可以分为如下两个步骤:
1.副本创建阶段.在此阶段,DRM使用面向用户的副本放置策略.在初始阶段,副本创建的目的是保证数据可用性,而不是增加访问量.在开始阶段,系统不能确定用户访问密集的区域,访问量低难以判断转发业务量大的节点,并且难以预测未来的访问速率和访问来源.因此,面向请求和面向业务的副本放置策略不适合.此外,由于复制成本较低,因此复制失败的可能性也较低,所以使用面向用户的策略更优.DRM采用的面向用户策略的算法如下.
首先,系统将客户端作为起始点,其标记为0.最靠近客户端的机架标记为1,需要通过标记1机架的其他机架标记为2,以此类推.系统选择具有最小标记机架中的节点来放置副本.
第二,在同一机架中,根据四个性能指标选择节点:(1)自由空间存储,(2)CPU性能,(3)I/O性能,(4)网络带宽.
2.副本运行时调整.在系统运行期间,数据的访问率高度不规则.如果数据块访问量增加并成为热分区,则将创建新的副本以保证负载均衡,并且在指定的时间内对客户端做出响应.因此,系统采用面向业务的策略,在具有最多转发流量的节点(许多必要的路由路径的连接节点)上放置副本数据.与面向请求策略相比,面向业务策略下的副本可以为大多数请求者服务,保证更高的利用率.
在路由转发过程中,转发查询根据不同的路由算法产生的流量也不同.在此,只计算直接到目的地的有效流量,不包括向所有邻居转发信息.每个请求者j到副本Bi存在路由路径,该路径中的所有节点的集合被表示为Aij.
Aij={Nk|Nk表示此节点在节点Ni到节点Nj的路由路径上}
在单位时间t内,假设trijkt表示节点Nk从请求者j到副本Bi的业务负载,trikt表示节点Nk用于副本Bi的转发流量.节点Nk的处理能力和副本数分别为Cikl(0 (10) 在单位时间t内将来自请求者j到副本Bi的查询数量定义为qijt,假设节点Nkx是路由路径中节点Nk之前的任何一个节点,因此Nkx∈Aij.节点Nkx的处理能力和副本数分别为Cikxl(0 (11) (12) 对于转发节点,如果其流量大于系统平均查询的γ倍,则认为它是过载的并且被标记为流量中心节点,即: (13) DRM采用文献[15]提出的动态副本调整策略,利用灰色预测技术,根据最近数据的访问特征来预测未来数据块的访问热度,并且动态调整副本数目.当数据块访问增加成为热点时,动态增加副本数目,以提高数据访问效率.如果数据块为非热点访问数据,则动态删除最近访问频数最少的副本,以节省系统存储空间. 算法1为动态副本控制算法.首先是基于可用性的副本创建模型,使用式(9)根据用户给定的文件可用性算出最小副本数rmin(第2-6行).其次是智能副本放置机制,在副本创建阶段,采用面向用户的策略将副本放置在离用户最近的机架上,以保证数据的可用性(第11-12行);而在副本运行调整阶段,采用面向业务的策略,在具有最多转发流量的节点放置副本,保证为大多数请求者服务,有效的提高利用率(第14-15行).最后是动态副本调整策略,数据块的访问频率并不总是保持很高,根据文献[13]提出的算法,如果当前副本数大于rmin并且数据块平均访问频率下降到删除阈值thdel,则根据文献[15]提出的LFU算法计算出数据块各个副本i在当前时刻之前的N个单位时间段T内的总访问频数VNi,删除最近访问频数最少的副本,调整副本数目以节省存储空间(第18-22行). 算法1.动态副本控制算法 输入:Aexcept,文件的可用性; trk,路由路径上节点k用于副本的转发流量; q,副本的平均查询; thdel,删除阈值. 输出:data nodel k,副本放置的流量中心节点. 1.foreach time window Tdo 2.foreachfile 3.ifavailability reset by user 4. Calculate rmin 5.endif 6.endfor 7.foreach block do 8. rj=current replica number of block j 9. aj=Access frequency of block j 10.ifr < rmin 11.ifr=0 //副本创建阶段 12. add rminreplicas to the nearest data nodes 13.else 14.iftrk>= γq 15. add one replica to the data node k 16.endif 17.else 18.ifaj< thdelthen 19.fori=1 to rjdo 20. calculate VNi 21.endfor 22. delete the replicas of smallest VNito the data nodes 23.endif 24.endfor 25.endfor 该算法可以很好的解决静态副本策略无法适应云计算的动态性特征,算法中提出的动态副本控制策略可以根据资源环境的变化而动态调整副本的数目与位置,以适应资源环境不稳定的情况.该算法虽然会增加一些额外的开销,但是计算主要集中在系统CPU空闲时间,对整体性能影响很小. 除了默认的副本管理策略,HDFS还提供了灵活的API方便扩展和实施高效的副本管理.副本因子在HDFS中按文件进行配置.应用程序可以指定文件的副本数.副本因子可以在文件创建时被指定,以后可以更改.但是,HDFS不提供确定副本因子的策略.本文可用于确定给定可用性要求下的最小副本数.HDFS还为Datanode之间的数据迁移提供接口,以平衡工作负载.因此,HDFS是实现和评估DRM的良好平台. 为了在HDFS中实现本文提出的DRM,使用副本因子来表示Namenode的元数据中的最小副本数.图1显示了HDFS中DRM的框架.由于DRM需要块数来计算给定可用性需求的最小副本数,因此修改HDFS客户端以将整个文件数据缓存到本地文件而不是第一块.将整个中间文件缓存在本地文件中是合理的,其大小范围从几百兆字节到千兆字节.这简化了在HDFS中的原型实现,但可能不适用于大型(太字节)的文件.找到将DRM有效地集成到HDFS中的最佳方式是未来工作的一个重要方向. 图1 动态副本管理框架Fig.1 Dynamic replication management framework 将整个数据写入本地文件后,客户端通过可用性设置和块号联系NameNode.NameNode将文件名插入到文件系统层次结构中,基于式(9)计算副本因子,并利用面向用户的策略获得每个数据块的DataNode的列表.NameNode使用每个块的DataNode列表,目标数据块和副本因子来响应客户机请求.然后客户端以流水线方式将每个数据块从本地临时文件刷新到指定的DataNode及其副本到选定的DataNode. 系统运行期间,在数据节点不可达或者当前副本数小于最小副本数rmin的情况下,新副本将被动态地添加到数据节点以保证可用性要求. 测试平台建立在由一个NameNode节点和二十个DataNode节点的集群上.每个节点都有2.8GHz的Intel Pentium 4 CPU,1GB或2GB的内存,80GB或160GB的SATA磁盘.操作系统是带有内核2.6.20的Red Hat AS4.4.Hadoop版本为0.16.1,java版本为1.6.0. 为了评估式(9)的准确性,实验随时调整系统中存在的副本数目,并测量文件可用性. 在这个实验中,文件被分割成4块.图2比较对应于预期可用性的副本数目.例如,假设数据节点失效率为0.1和用户期望的文件可用性为0.8,基于式(9)的计算,最小副本数为2.当系统将每个块的副本数保持为2时,我们测量文件的平均可用性为0.93左右.虽然模型预测在图中的坐标可能都不是特别准确,但这验证了模型指向的总趋势. 为了评估DRM作为动态算法的优势,测量实验中运行的副本数目.结果如图3所示,将Aexcept设置为0.8,开始阶段每个块设置一个副本.从结果中可以看到,在实验开始时副本数目不断增加.达到一定程度后,实验中副本的数目维持在一个恒定的水平.这表明如果当前副本数目不满足可用性需求,DRM便会动态添加更多副本. 图2 可用性模型的准确性比较Fig.2 Accuracy comparison of availability model 图3 数据节点故障率为0.1和0.2,期望值为0.8的动态复制Fig.3 Dynamic replication with data node failure rate of 0.1 and 0.2,Aexcept=0.8 在不同的访问流行度和访问率下比较DRM和HDFS的平均访问延迟.HDFS静态维护配置系统中的副本数目,并采用机架感知副本放置策略.当副本因子为3时,HDFS将两个副本放置在同一机架中,将一个副本放置在不同的机架中.然而,在同一机架中的Datanode是随机选择的,而不考虑Datanode之间的性能和工作负载差异.假设有20个数据节点,访问率为 δ(0<δ<1),设置Aexcept= 0.8,数据节点失效率为0.1,系统最初每块保持2个副本.测试结果绘制在图4中. 由图4可以看出,随着访问流行度的增加,DRM和HDFS的访问延迟都会降低.但是,当访问流行度很小时,DRM的性能比HDFS的性能好.这是因为DRM可以通过增加流行块的副本数目并根据面向业务的策略调整副本位置,在数据节点之间动态分配工作负载.从实验结果还可以发现,当将访问率从0.2增加到0.6时,DRM的性能优于HDFS.这表明DRM利用面向业务的策略在数据节点集群之间分配繁重的工作负载,并利用整个集群的资源来实现整体性能的提高. 实验结果表明,DRM可以适应环境的变化,保持一个合理数量的副本,这不仅满足可用性,而且还提高了访问延迟,负载均衡,并保持整个存储系统稳定. 目前的分布式系统都是采用数据副本的方法来提高数据的可用性,但是当前的数据副本方法大多都是静态地提供固定个数的数据副本,无法适应动态变化的数据访问和节点性能,并会导致糟糕的性能和负载不均衡,本文提出的DRM策略充分考虑到了这些问题,该策略能根据可用性计算得到合适的数据副本个数,不仅考虑到数据可靠性还避免了不必要的数据复制,基于节点性能和用户访问特性确定副本放置位置.实验结果表明DRM在成本、负载平衡和性能都优于现有HDFS副本管理机制. [1] Ghemawat S,Gobioff H,Leung S T.The google file system[J].Acm Sigops Operating Systems Review,2003,37(5):29-43. [2] Weil S A,Brandt S A,Miller E L,et al.Ceph:a scalable,high-performance distributed file system[C].Symposium on Operating Systems Design and Implementation,USENIX Association,2006:307-320. [3] Konstantin Shvachko K,Hairong Kuang,Radia S,et al. The hadoop distributed file system[C].In Proc.of the 26th Mass Storage System and Technologies,2010:1-10. [4] Rahman R M,Barker K,Alhajj R.Replica placement strategies in data grid[J].Journal of Grid Computing,2008,6(1):103-123. [5] Xu Jing,Yang Shou-bao,Wang Shu-ling,et al.CDRS:an adaptive cost-driven replication strategy in cloud storage[J].Journal of the Graduate School of the Chinese Academy of Sciences,2011,28(6):759-767. [6] Amazon simple storage service website[EB/OL].http://aws.amazon.com/s3/,Jan,2017. [7] Melorose J,Perroy R,Careas S.Hadoop definitive guide[M].Hadoop:The Definitive Guide.Yahoo! Press,2015:1-4. [8] Chandy J A.A generalized replica placement strategy to optimize latency in a wide area distributed storage system[M].Proceedings of the 2008 International Workshop on Data-aware Distributed Computing (DADC′08),Boston,USA,New York NY,USA,ACM,2008:49-54. [9] Ding Y,Lu Y.Automatic data placement and replication in grids[C].High Performance Computing (HiPC),2009 International Conference on.IEEE,2009:30-39. [10] Qu Y,Xiong N.RFH:a resilient,fault-tolerant and high-efficient replication algorithm for distributed cloud storage[C].International Conference on Parallel Processing,IEEE,2012:520-529. [11] Lin Wei-wei.An improved data placement strategy for hadoop[J].Journal of South China University of Technology,2012,40(1):152-158. [12] Ibrahim I A,Wei D,Bassiouni M.Intelligent data placement mechanism for replicas distribution in cloud storage systems[C].IEEE International Conference on Smart Cloud,IEEE Computer Society,2016:134-139. [13] Wei Q,Veeravalli B,Gong B,et al.CDRM:a cost-effective dynamic replication management scheme for cloud storage cluster[C].IEEE International Conference on CLUSTER Computing.IEEE,2010:188-196. [14] Deng J L.Control problems of grey systems[J].Systems & Control Letters,1982,1(5):288-294. [15] Tao Yong-cai,Zhang Ning-ning,Shi Lei,et al.Researching on dynamic management of data replicas of cloud computing in heterogeneous environments[J].Journal of Chinese Computer Systems,2013,34(7):1487-1492. [16] Lin Chang-hang,Guo Wen-zhong,Chen Huang-ning.Node-capability-aimed data distribution strategy in heterogeneous hadoop cluster[J].Journal of Chinese Computer Systems,2015,36(1):83-88. [17] Xun Ya-ling,Zhang Ji-fu,Qin Xiao.Data placement strategy for MapReduce cluster environment[J].Journal of Software,2015,26(8):2056-2073. [18] Qu K,Meng L,Yang Y.A dynamic replica strategy based on Markov model for hadoop distributed file system (HDFS)[C].Cloud Computing and Intelligence Systems (CCIS),2016 4th International Conference on.IEEE,2016:337-342. 附中文参考文献: [5] 徐 婧,杨寿保,王淑玲,等.CDRS:云存储中一种代价驱动的自适应副本策略[J].中国科学院大学学报,2011,28(6):759-767. [11] 林伟伟.一种改进的Hadoop数据放置策略[J].华南理工大学学报:自然科学版,2012,40(1):152-158. [15] 陶永才,张宁宁,石 磊,等.异构环境下云计算数据副本动态管理研究[J].小型微型计算机系统,2013,34(7):1487-1492. [16] 林常航,郭文忠,陈煌宁.针对Hadoop异构集群节点性能的数据分配策略[J].小型微型计算机系统,2015,36(1):83-88. [17] 荀亚玲,张继福,秦 啸.MapReduce集群环境下的数据放置策略[J].软件学报,2015,26(8):2056-2073.
4.3 DRM控制策略
5 DRM实现

6 性能评估
6.1 可用性
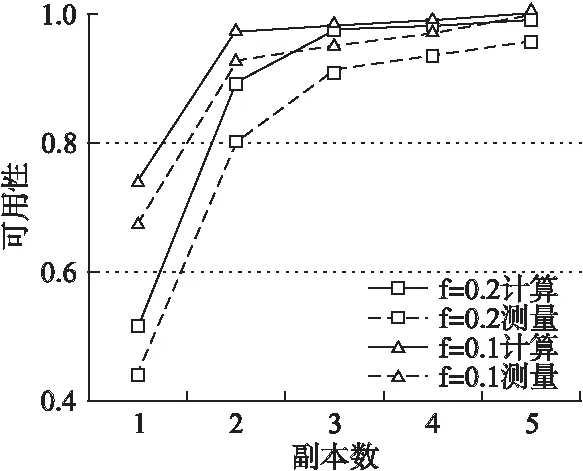
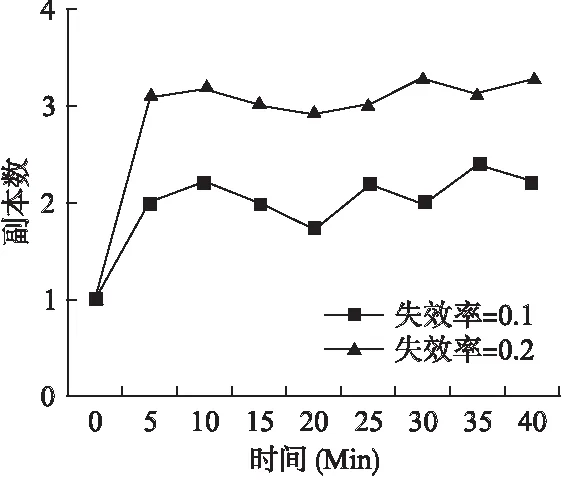
6.2 访问延迟
7 结 论
