基于主动学习的本体概念关系判断
2013-10-15张桂平李文博王裴岩
张桂平,李文博,王裴岩
(沈阳航空航天大学 知识工程中心,辽宁 沈阳,110136)
1 引言
本体可以促进各种领域之间的交流,这种交流实现了给定领域中不同知识的重用和共享。在人工智能界,Gr uber[1]给出了本体的一个最为流行的定义,即“本体是概念模型的明确的规范说明”。目前本体的构建方法主要分为三种:自动构建、半自动构建和手工构建。自动构建会产生大量的噪声数据而且所得本体的可信度得不到保障[2];手工构建需要领域专家的参与,费时、费力。因此如何利用知识获取技术半自动地构建本体是一个重要研究方向[3],半自动构建也称辅助构建。
近年来,本体辅助构建的研究有很多。David等人[4]采用基于模板的方法无监督地构建领域术语树来构建领域本体。Tao Jiang等人[5]首先对文本语料进行语法分析得到本体概念以及它们之间的关系,然后利用关联规则算法确定概念关系是否正确。文献[6 先构建核心领域本体,然后利用通用本体Wor d Net来扩展领域本体。虽然半自动构建本体取得了很好的效果,但是人工标注的问题仍然是本体构建中不小的瓶颈。
本文提出基于主动学习的本体关系辅助构建方法,对边缘采样、熵采样、最不确信采样等主动学习查询生成策略进行了比较研究,并讨论了在三种不同样本初始情况下主动学习技术的应用,从而实现了在概念关系判定过程中对用户反馈信息的有效利用,使得在较少的训练样例的情况下可获得较高的本体关系推荐结果。
2 相关研究
对于本体概念关系的判断,常用的方法有:基于模板、词典和关联规则挖掘的方法等。基于模板的方法往往准确率低,且模式的获取是否完备对结果影响较大。Kavalec[7]等人利用关联概念动词出现的频率来挖掘概念间的非分类关系,但该方法未考虑句子的结构信息,效果并不理想。Faure等人[8]用聚类方法获取概念间关系,但该方法只能划分出概念所属关系的集合,不能明确给出概念间的确切关系。文献[9]采用改进的BM25相似度计算方法为用户提供参考文本,并提出基于概念最短距离的分类样本提取方法,进而为用户提供概念关系的推荐。该方法能有效地辅助用户判断概念间关系,但用户对系统每次给出的推荐结果都要做出决策,当需要判断大量概念关系时,人为工作量仍很大。
主动学习,也称 “query lear ning”,是机器学习领域中的一个分支领域[10],它用于那些标注样例较难获取或者代价昂贵,而未标注样例较容易获取的情况。很多研究中都有主动学习的应用:Settles和Craven[11]分析了主动学习方法在序列标注任务中的应用;车万翔等人[12]在中文依存句法分析中加入主动学习来减少人工的标注量;陈荣等[13]在图像分类任务中加入了主动学习方法,使得系统提高了图像分类问题中训练样本选择的效率。文献[14]采用基于字的CRF模型获取候选术语集合,并利用主动学习方法从候选术语集合中选择概念推荐给用户来获取领域本体概念。
本文针对文献[9]的研究做了进一步扩展,利用航空百科词典作为数据源,把主动学习技术加入到本体概念关系判断任务中,使得在关系的辅助判断中进一步减少人为工作量。并且本文还对主动学习中不确定性采样的各个算法做了详细的对比分析,验证了不确定性采样在本体概念关系判断中的有效应用。
3 概念关系辅助判断方法
3.1 基于知识获取技术的本体概念关系判断
文献[9]针对非领域人员在没有领域背景知识的情况下,采用改进的BM25相似度算法为用户提供参考文本,还利用概念的最短距离信息提取分类样本,并利用KNN分类算法为用户提供概念关系的推荐。本文利用KNN的分类结果,在概念关系判断中加入主动学习技术,使系统选取那些有潜在价值的样例予以标注,期望能在较小训练集合的情况下获得较高的关系推荐准确率。
3.2 主动学习方法
不确定性采样(Uncertainty Sampling)是主动学习算法中应用最普遍的查询策略[10],它选取当前分类器最不确定的样例进行标注。本文选取不确定性中的最不确信采样、基于阈值的采样、边缘采样和基于熵的采样,并与随机采样对比,以下介绍这几种采样算法。
1)随机采样(rando m sa mpling):不考虑类别的后验概率,随机选取样例。
2)基于阈值的采样(t hreshold sampling):选取类别后验概率在0.4到0.6之间的样例。
3)最不确信采样(least confident sampling):仅标注结果中最不确信样例,如式(1)所示。
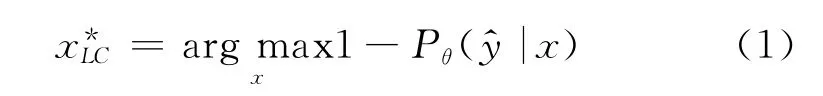
4)边缘采样(margin sampling):基于边缘采样的主动学习公式如式(2)所示。
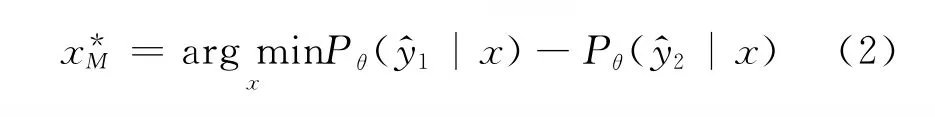
这里的Pθ(|x)和Pθ|x)表示类别分值最高的前两类的后验概率。
5)基于熵的采样(entr opy sa mpling):基于熵采样主动学习样本选择准则如式(3)所示。
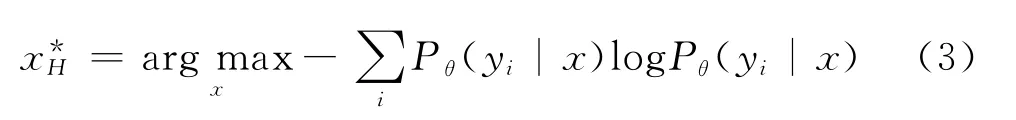
其中,yi代表KNN计算结果中的各个类别。
以上几种采样的实际应用中,基于阈值采样与最不确信采样在二分类问题上获得了很好的结果[15],并且研究者验证了边缘采样和基于熵的采样在多分类情况下的有效性[16-17]。
4 主动学习在本体关系辅助判断中的应用
本文在本体概念关系判断中加入了主动学习技术,使得系统能最大限度地减少人为工作量,提高本体的构建速度。根据航空本体概念间类别的划分体系,“部件关系”、“属性关系”等这样的类别称为正例,而在划分体系之外或者根本没有关系的类别称为反例。经分析得到,初始样例集合可分为表1中的几种情况。
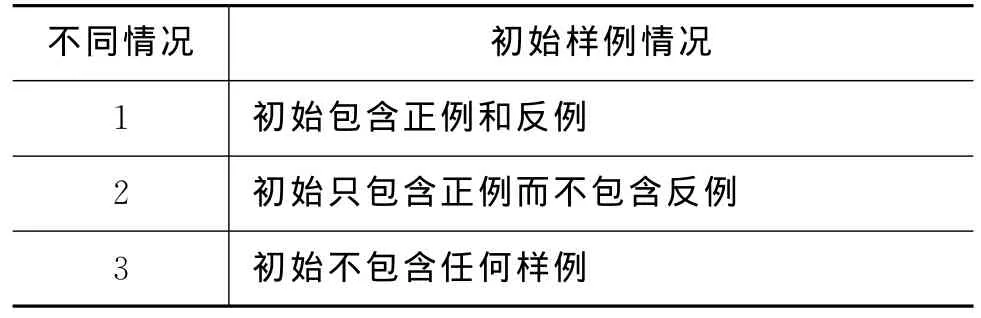
表1 不同的初始样例规划
根据表1中初始样例的不同情况,概念的关系判断就是一个多分类问题,对于初始正反样例充足的情况,可以直接多分类。Sophia Katrenko等人[18]认为,关系抽取可以看作是具有两个步骤的过程:识别存在关系的证据和检查是否存在关系。那么针对本文的问题,可以先进行二分类,判断概念间有没有关系,如果有关系,则可以再多分类,看看两个概念间是哪种关系。本文针对不同的初始样例,提出了A、B、C三种策略,将主动学习技术应用到本体概念关系半自动构建中,这三种策略具体描述如下。
策略A:针对初始样本正反例充足的情况,首先利用3.2节中的主动学习方法生成查询,进行多分类。然后对语料进行二分类,去除反例后对剩余的有关系概念对进行多分类,以此判断有关系的概念具体属于哪类关系。策略A的主动学习方法伪代码如图1所示。

图1 策略A 中主动学习伪代码
策略B:针对初始样本仅有正例的情况,首先采用相似度策略的主动采样方法,从未标注集合中选取反例,每次选取最不相似的5个样例作为反例集合加入到初始样本中,当反例集合达到与策略A中的反例相当的数目时停止采样,然后重复A中的实验。策略B的主动学习伪代码如图2所示。

图2 策略B 中主动学习伪代码
策略C 针对缺乏初始样例的情况,根据词对共现文档的信息以及词对在共现文档中的距离信息选取正反例,选取的规则如下:
1.共现文档多,并且在文档中距离近的词对作为正例集;
2.共现文档少,并且在文档中距离远的词对作为反例集;
当采用上述策略标注的正反例集合达到与策略A、B中的正反例集合数目相当时停止标注,然后重复A中的实验。
5 实验结果与分析
5.1 实验设置
实验采用《航空百科词典》作为数据源,共7892篇文档。预定义5类概念关系,它们为:部件关系、材料关系、用途关系、制造与工艺关系和属性关系。人工标注1300对概念。基于《航空百科词典》抽取的样例说明如表2所示。
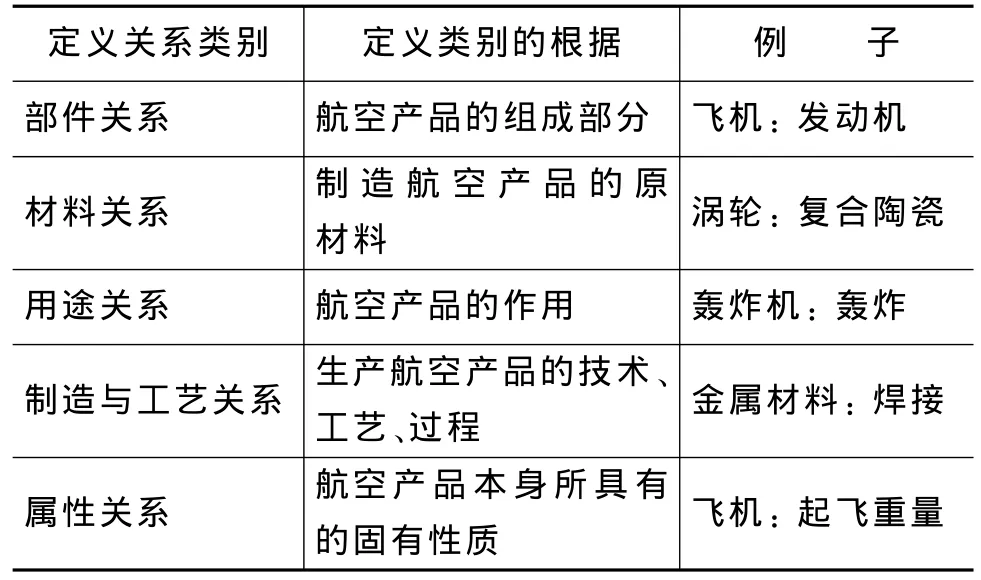
表2 抽取样例的说明
本文在文献[9]的基础上加入主动学习技术,选取标注语料的30%作为测试概念关系集,把剩余70%语料分为两部分:1.为基础(f oundation)语料;2.为查询(query)语料。其中f oundation与quer y语料的比例为1∶3。策略A、B、C利用不同的主动学习策略分别进行六分类、二分类和五分类。其中六分类与二分类迭代次数为60,因为过滤了没有关系的类别,所以剩余的五分类的迭代次数为50。实验中每种主动学习策略每次采样10对概念,并且三种策略均进行5次交叉验证。
其中,三种策略在二分类时均采用基于阈值和最不确信的采样算法,得到二分类的最好结果,去除其中被分为反例的部分,剩余语料利用边缘采样和基于熵采样再进行五分类。衡量结果的准确率定义如式(4所示。

5.2 实验结果与分析
5.2.1 实验结果
策略A正反例充足的情况下,得到的六分类与二分类如图3、4所示。
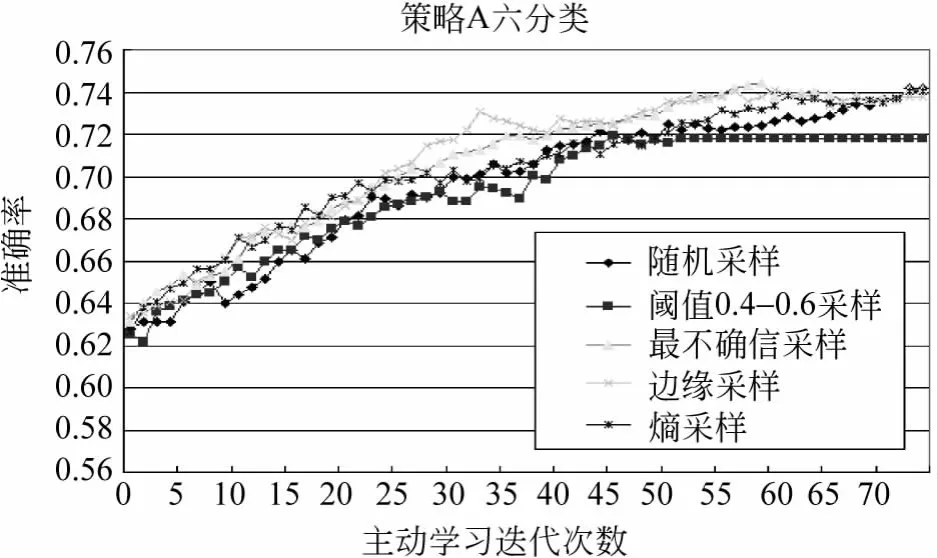
图3 策略A的六分类结果
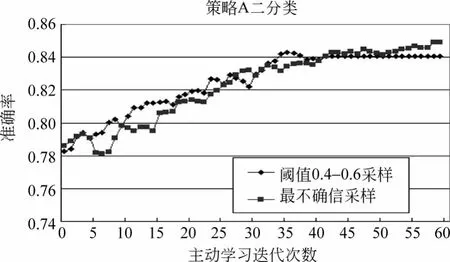
图4 策略A的二分类结果
从图3中看到,六分类中边缘采样得到了最高结果,最高准确率为74.5%。从图4看到,策略A的二分类中基于阈值的采样要比最不确信的结果好,最高准确率达到了84.9%,选取此时关系推荐结果中的正例进行五分类,结果如图5所示。
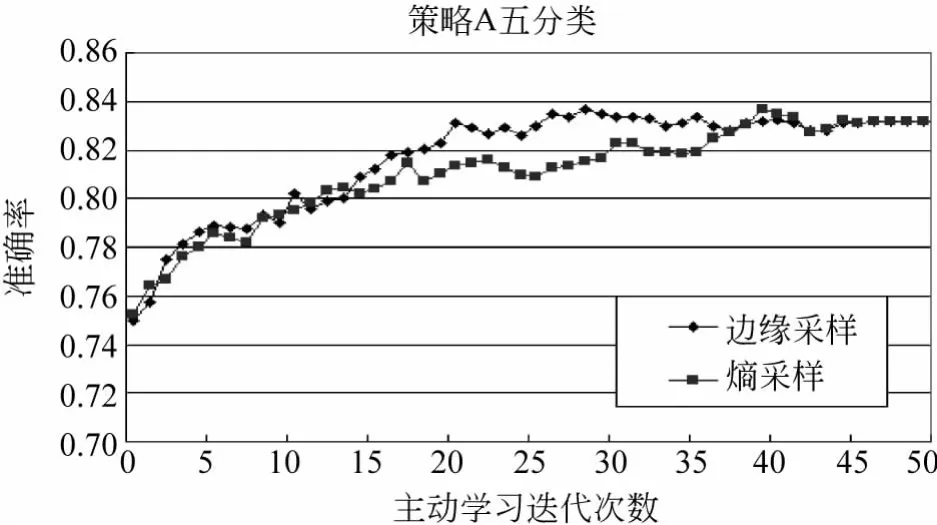
图5 策略A的五分类结果
通过图5看到,边缘采样在迭代30次时,分类准确率达到了83.6%,并且边缘采样的效果要优于基于熵的采样。策略B在缺少反例的情况下,得到的六分类与二分类的结果如图6、7所示。
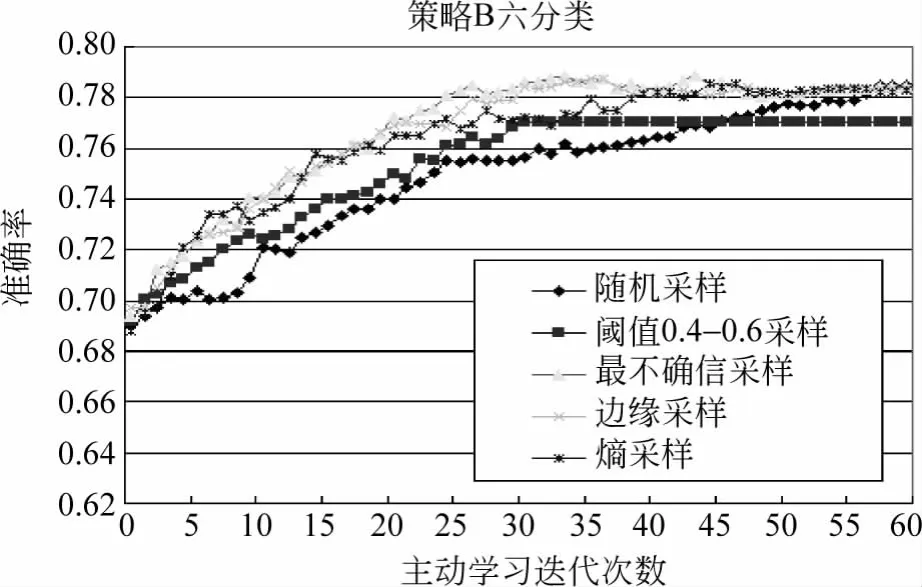
图6 策略B的六分类结果
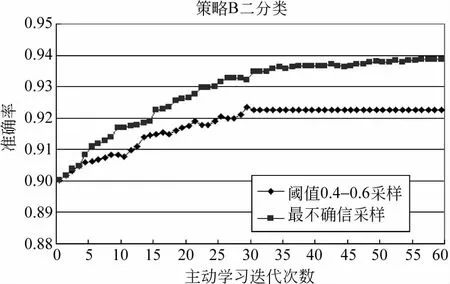
图7 策略B的二分类结果

图8 策略B的五分类结果
从图6看到,策略B的六分类中,最不确信采样与边缘采样取得了优于其他采样的效果,最高准确率达到了78.8%。从图7看到,二分类中最不确信采样的效果要明显优于阈值采样,算法在迭代到30次后收敛,准确率最高接近94%。从图8看到,在策略B的五分类中,基于边缘采样与熵采样的效果相当,准确率在迭代35次后就达到90%以上,曲线在迭代45次后收敛。策略C在缺少标注样例情况下,根据词对共现文档的信息及词对在共现文档中的距离信息选取正反例,再重复策略A的实验,得到的六分类与二分类的结果如图9、10所示。
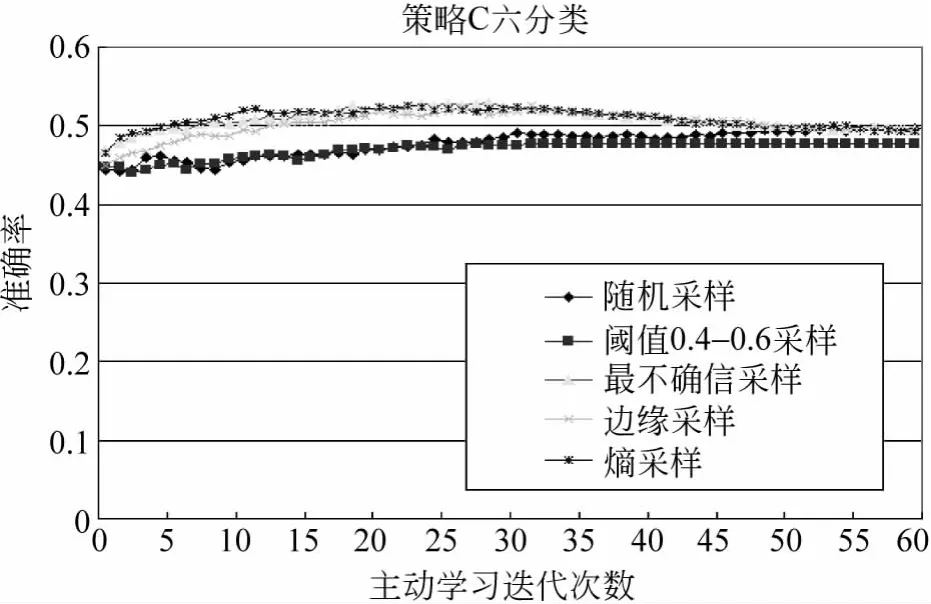
图9 策略C的六分类结果
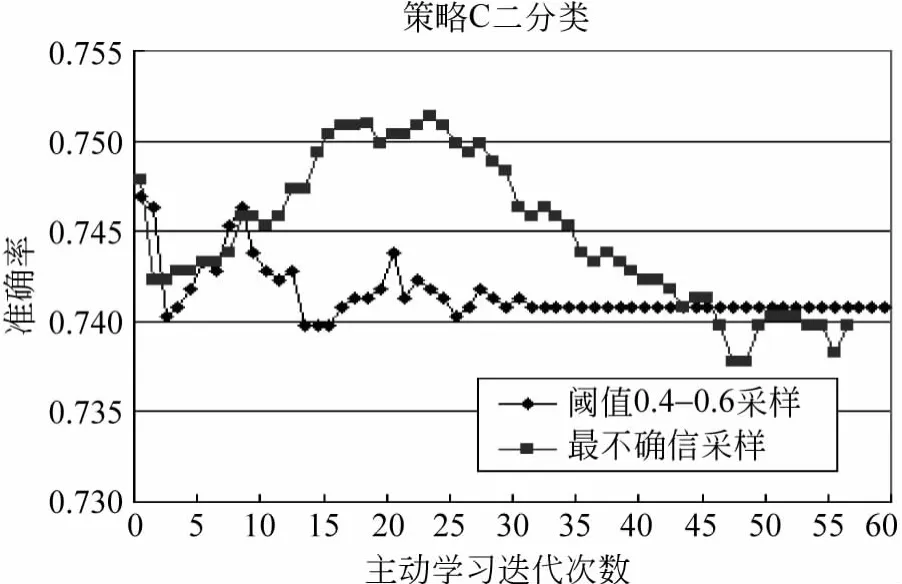
图10 策略C的二分类结果
策略C的六分类结果曲线相对平缓,最高关系推荐准确率在52.7%。二分的准确率结果在迭代25次后下降,其中最不确信采样的结果好于阈值采样的结果,最高准确率达到了75.1%。策略C的五分类结果如图11所示。将本文三种策略实验语料用文献[9中的方法求出准确率,并与这三种策略去除反例后的准确率对比,其中文献[9]的方法用“Z”表示,结果如图12所示。
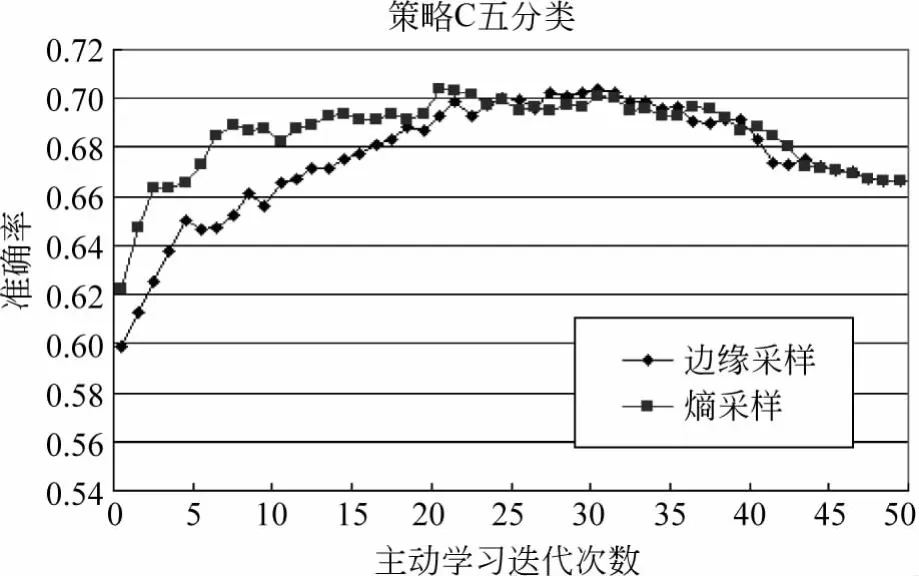
图11 策略C的五分类结果
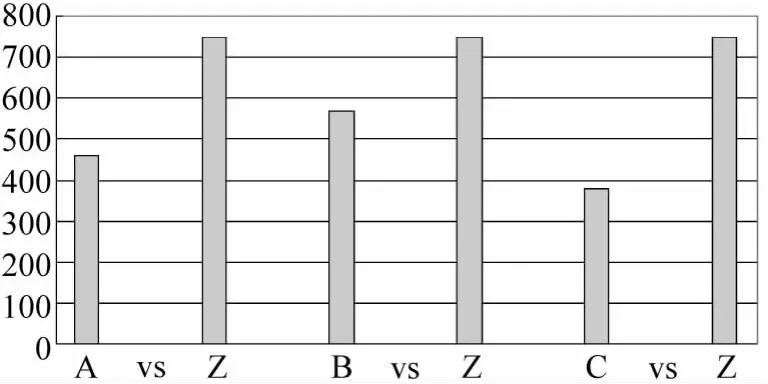
图12 三种策略与Z方法对比
策略C的五分类中基于熵采样的结果好些,最高准确率达到了70.4%。说明策略C的方法对于没有任何初始样例的情况起到了一定的作用。图12中,纵坐标表示标注样例的数目,横坐标表示三种方法与Z的方法比较,其中策略A的语料用Z方法实验得出的准确率为83.2%,策略B为94.1%,策略C为66.7%。通过图12的对比看到,三种策略在取得相同准确率的同时,人标注的样例明显减少,从而验证了主动学习技术在本体概念关系判断中的有效性。
5.2.2 实验分析
对于策略A与策略B,两者不同的是反例的选取方法,分别计算策略A、B中正、反例的相似度,相似度计算采用余弦相似度计算方法,结果如表3所示。
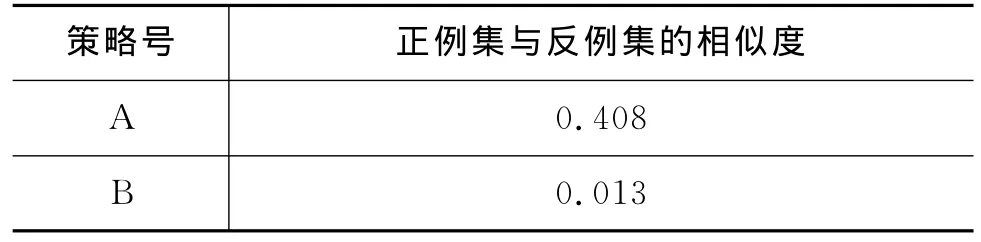
表3 策略A、B中正反例集相似度
通过结果可以看出,策略B的反例集与正例集的相似度结果只有1.3%,而策略A却达到了40%以上,这样在二分类过程中,策略A对于测试集合的正例和反例的区分能力明显不如策略B好,所以策略B的二分类优于策略A。也正是由于策略B中二分类有效地过滤了反例,所以策略B的五分类结果的准确率要高于策略A。综合上述,策略A中的反例是人工给出的,具有一定的不确定性和随机性,而策略B中通过最小相似度的主动学习策略选取的反例具有一定指导性,所以策略B的效果很理想。
策略C中,虽然取得了一定效果,但是当主动学习算法迭代到一定次数后,曲线出现了下降。分析得到策略C的反例中,例如,[机轮:歼击轰炸机]、[减震器:歼击机]、[机轮:强击机、[机轮:轰炸机]等几组概念,它们共现在同一文档中,并且概念间的距离远,根据策略C中的规则他们被认为没有任何关系,但是它们共现的句子是举例说明这几种飞机及其组成的部件,显然它们之间应该是“部件关系”,在选取的反例集合中这样的例子还有很多。
6 结语
本文依据关系判断任务特点,并从实际应用角度出发,讨论了在三种不同样本初始情况下主动学习技术的应用,对比分析了三种策略实验结果。实验验证了主动学习在本体关系辅助判断任务中的有效性,并且实现了在概念关系判定过程中对用户反馈信息的有效利用,在本体关系构建任务中,利用较少的训练样例获得了较高的关系推荐准确率。
在未来的研究中,可以针对策略C的方法做进一步改进,不仅是通过统计信息,还可以加入一些启发式知识来指导选取样例,这样可以在大大减少人为工作量的同时提高本体的构建效率。
[1]Thomas R Gruber.A translation approach to portable ontologies[J].Knowledge Acquisition,1993,5(2):199-220.
[2]何琳,侯汉清.基于统计自然语言处理技术的领域本体半自动构建研究[J].情报学报,2009,28(2):201-207.
[3]杜小勇,李曼,王珊.本体学习研究综述[J].软件学报,2006,17(9):1837-1847.
[4]David Sanchez,Antonio Moreno.Patter n-based Automatic Taxono my Lear ning fr om the Web[J].AI Co mmunications.2008,21(1):27-48.
[5]Tao Jiang,Ah-Hwee Tan,Ke Wang.Mining Generalized Associations of Semantic Relations fr o m Textual Web Content[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(2):164-179.
[6]徐力斌,刘宗田,周文,等.基于 Wor d Net和自然语言处理技术的半自动领域本体构建[J].计算机科学,2007,34(6):219-222.
[7]Kavalec M,Svate K V.A study on auto mated relation labeling in ontology learning[J].Buitelaar P,Cimiano P,Magnini B,eds.Ontology Lear ning fro m Text:Methods,Evaluation and Applications.Amster dam:IOS Press,2005.
[8]Faure D Nedellec C.A cor pus-based conceptual clustering method f or verb frames and ontology acquisition[C]//Velardi P,ed.Proc.of the LREC Workshop on Adapting Lexical and Cor pus Resources to Sublanguages and Applications Granada:LREC,1998:5-12.
[9]张晓莹,张桂平,王裴岩.领域本体构建中关系辅助判
断技术研究[C]//中国计算语言学研究前沿进展(2009-2011).中国:中文信息学会,2011:276-282.
[10]Burr Settles.Active Lear ning Literature Survey[R].Co mputer Sciences Technical Report,University of Wisconsin-Madison,2009.
[11]B Settles,M Craven.An analysis of active learning strategies for sequence labeling tasks[C]//Proceedings of the Conference on Empirical Met hods in Natural Language Processing (EMNLP),USA:ACL Press,2008:1070-1079.
[12]车万翔,张梅山,刘挺.基于主动学习的中文依存句法分析[J].中文信息学报,2012,26(2):18-22.
[13]陈荣,曹永锋,孙洪.基于主动学习和半监督学习的多类图像分类[J].自动化学报,2011,37(8):954-962.
[14]Guiping ZHANG Xiaoying ZHANG Peiyan WANG,et al.Study on Assistant Concept Acquisition in Domain Ontology Construction for Chinese Texts[C]//Proceedings of 7t h Inter national Conference on Natural Language Processing and Knowledge Engineering.Japan:2011:177-182.
[15]A Culotta,A Mc Callum.Reducing labeling effort f or stuctured prediction tasks [C]//Proceedings of the National Conference on Artificial Intelligence(AAAI),USA:AAAI Press,2005:746-751.
[16]T Scheffer,C Deco main,S Wrobel.Active hidden Markov models f or inf or mation extraction[C]//Proceedings of the International Conference on Advances in Intelligent Data Analysis(CAIDA).Springer-Verlag,2001:309-318.
[17]R Hwa.Sample selection for statistical parsing[J].Computational Linguistics,2004,30(3):253-276.
[18]Katrenko S,Adriaans P.Learning Relations from Bio medical Cor pora Using Dependency Tree Levels[C]//Proceedings of the BENELEARN conference.Springer-Verlag,2007:61-80.
