基于对偶分解的词语对齐搜索算法
2013-10-15沈世奇孙茂松
沈世奇,刘 洋,孙茂松
(清华大学 计算机科学与技术系 智能技术与系统国家重点实验室,北京100084)
1 引言
词语对齐旨在计算平行文本中词语之间的对应关系。例如,给定一个中文句子和一个英文句子①该例句及词语对齐源自(Liu et al,2010)
中国建筑业对外开放呈现新格局。
The opening of China's construction industry to the outside presents a new str ucture.
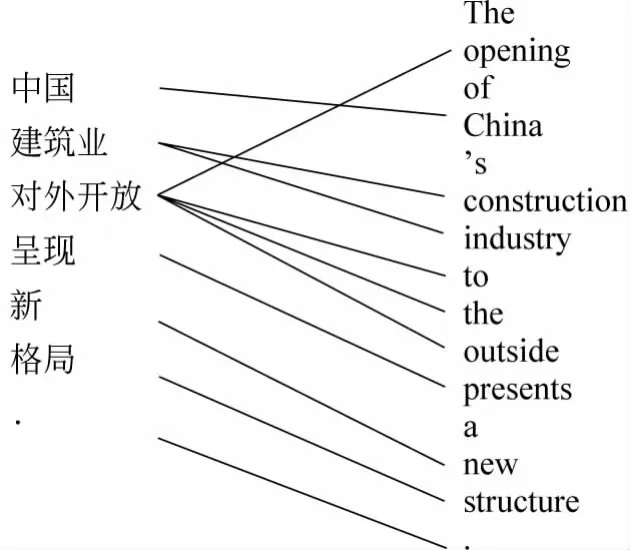
图1 词语对齐示例
图1 给出了这两个句子的词语对齐。由于中文词“中国”与英文词“China”互相翻译,两者之间存在一条连线显示对应关系。需要指出的是,中文词与英文词并不完全是一一对应,例如,中文词“建筑业”对应两个英文词“constr uction industr y”。更复杂的情况是一个中文词对应到若干个非连续的英文词,例如,“对外开放”对应英文词“opening...to the outside”。因此,由于自然语言的多样性和复杂性,发现不同语言之间的词语对应关系是一个非常具有挑战性的问题。
词语对齐最早是作为机器翻译的中间结果由Br own et al.提出[1]。由于词语对齐能够为不同自然语言在词语层建立关联,它在机器翻译、机器辅助翻译、词义消歧和双语词典构建等多项自然语言处理任务中起着关键的作用。例如,在统计机器翻译中,无论是基于短语的方法[2]、基于层次短语的方法[3]还是基于句法的方法[4],往往都依赖于词语对齐进行规则抽取,因而词语对齐的质量对机器翻译译文的质量具有重要的影响。
词语对齐模型大致可分为生成式模型和判别式模型两大类。生成式模型[1,5-6]为词语对齐设计生成故事(generative story 其优点在于不需要标注数据进行训练,很容易应用于各个领域,其缺点在于模型难以扩展。判别式模型[7-10]将各种知识源作为特征函数加入到模型中,易于扩展,其主要缺点在于依赖于标注数据。在训练算法方面,生成式模型主要使用EM算法[1]实现无监督学习,而判别式模型可以使用最小错误率训练算法[11]实现直接优化评价指标,大幅提高对齐质量。Dyer et al.[12]最近提出了判别式模型的无监督训练,实现了判别式模型与无监督学习的优势互补。
然而,尽管词语对齐在建模和训练算法方面取得了较大的进展,多数搜索算法仍然面临着搜索错误严重的问题。给定一个源语言句子fJ1和一个目标语言句子eI1,可能的词语对齐结果数量是2J×I。对于以IBM模型[1]为代表的生成模型而言,虽然简单的模型1和模型2可以精准计算Viterbi对齐,但是对于更复杂的模型3、4、5只能使用爬山法计算近似解[1,13]。对于以线性模型[10]为代表的判别式模型而言,往往也只能使用柱搜索算法来计算近似解。
图2给出了文献[10]所提出的柱搜索算法的搜索空间,该算法以空对齐为起点,不断添加连线直至模型分数无法增加为止。由于词语对齐中连线之间存在错综复杂的依赖关系,无论是爬山法还是柱搜索算法都面临着严重的搜索错误问题。最近,Riesa和 Marcu[14]将立方体剪枝[3]引入词语对齐,但本质上仍然只能计算近似解。因此,搜索算法已经成为制约词语对齐质量的瓶颈问题。
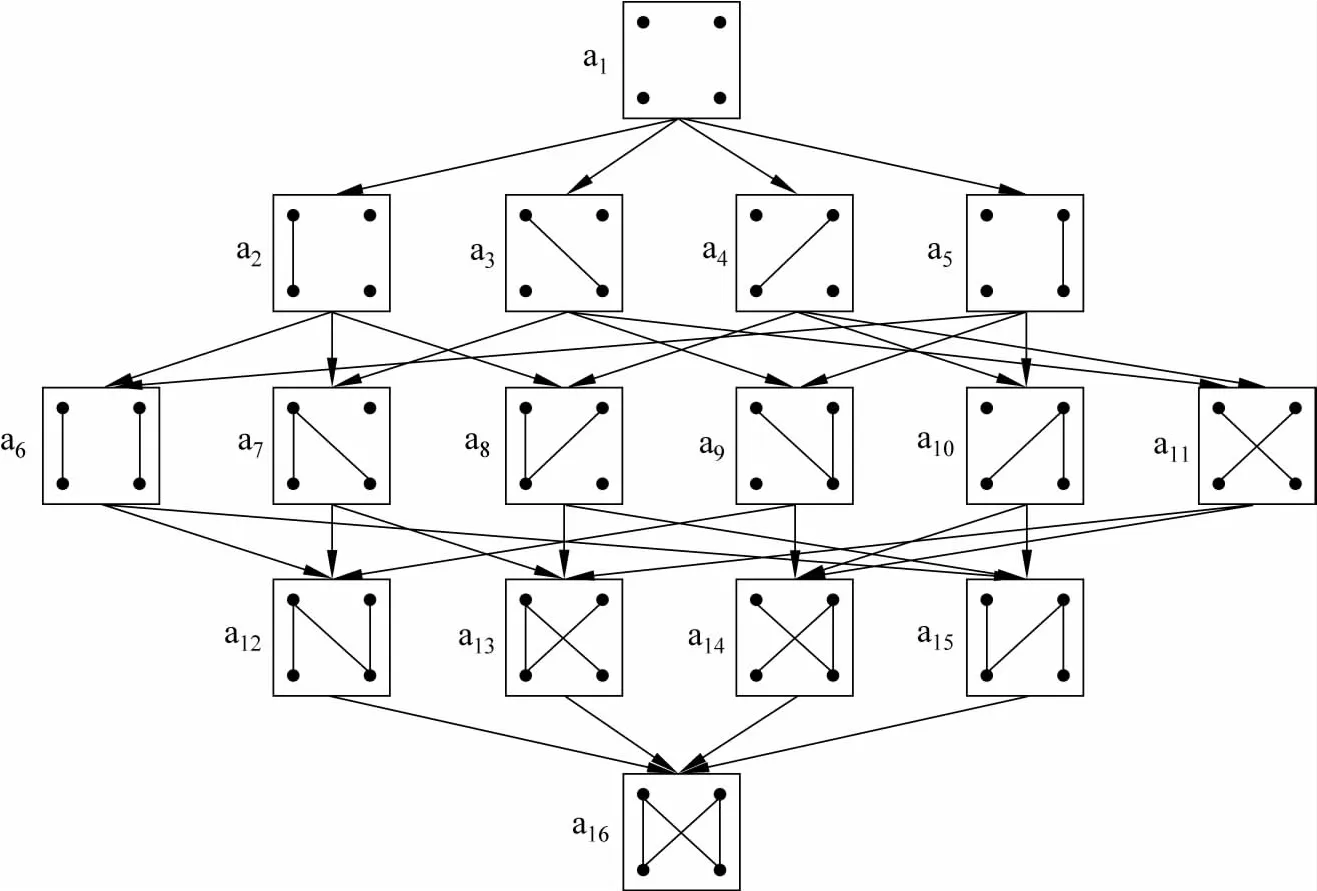
图2 词语对齐的搜索空间
近年来,对偶分解(dual decomposition被广泛应用于句法分析[15]和机器翻译[16]等自然语言处理任务来实现精准求解(exact decoding),均取得了良好的效果。为了缓解词语对齐所面临的搜索错误问题,本文提出一种基于对偶分解的词语对齐搜索算法,其基本思想是将复杂的问题分解为两个相对简单的子问题,迭代求解直至收敛。由于对偶分解能够确保求解的收敛性和最优性[17],我们的方法在2005年度863计划词语对齐评测数据集上显著超过IBM模型的爬山法[1]与判别式模型的柱搜索算法[10],对齐错误率分别降低4.4% 和1.1%。
2 基于对偶分解的词语对齐搜索算法
对偶分解的基本思想是将一个复杂的问题分解为两个相对简单的子问题,之后对两个子问题进行分别求解,通过一个数据结构记录两者的差异之处并利用该数据结构试图使两个子问题的解趋于一致。当算法经过多轮迭代收敛(即两个子问题得出相同的解)时,该解为最优解。
图3给出了基于对偶分解的词语对齐搜索算法的一个示例。给定中文句子“呈现 新 格局 。”和英文句子“present a new str ucture.”,假设我们将一个词语对齐模型拆成两个子模型进行分别求解,并定义函数u (j,i)来记录两个子模型的解的差异之处。初始状态对于任意的i和j,u (j,i)均设为0。图3(a)显示了两个子问题的解,上面是子问题一的解,下面是子问题二的解。可以发现,两个解存在差异:子问题一的连线 (2,2)与子问题二的连线 (2,1)不一致,即子问题一将“新”与“a”连线而子问题二将“呈现”与“a”相连。因此,算法更新u函数,将u (2 ,2)设为-1,将u(2,1)设为1,试图使两个子问题的解趋向一致(如图3(b)所示)。再次进行求解,两个子问题的解达成一致,获得最终解(如图3(c)所示)。这也说明了对偶分解的方法得到的解3(c)能够优于子问题的解3(a)的原因。

图3 基于对偶分解的词语对齐算法示例
更形式化地,给定源语言句子fJ1和目标语言句子eI1,基于对偶分解的词语对齐的搜索算法的目标如式(1)所示。

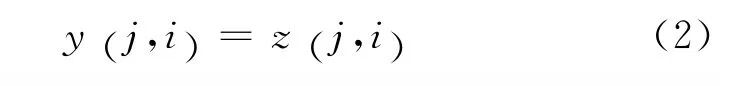
其中,Y和Z分别是两个词语对齐的解集合,y和z分别是其中的一个解,f (y)对应子问题一的模型,g(z)对应子问题二的模型,y j,(i)=1表示子问题一将fj与ei连在一起,0则表示没有相连。因此,对偶分解的目标是计算两个子问题达成一致的最优解。
对偶分解将按照子问题一和子问题二进行分别求解。子问题一的优化目标如式(3)所示。

子问题二的优化目标如式(4)所示。

图4给出了基于对偶分解的词语对齐搜索算法。算法的输入是源语言句子和目标语言句子(第1行)。首先初始化惩罚函数u (j,i),全部设为0(第2行)。之后进入迭代求解(第3行),分别对子问题一(第4行)和子问题二(第5行)进行求解。如果满足收敛条件,即两个子问题生成完全相同的对齐,则返回最优解(第6至7行),否则更新惩罚函数(第9行)进入下一轮迭代。如若超过最大迭代次数仍然没有收敛,则选取迭代过程中子问题的最优解作为最后的结果。其中,αk是第k轮迭代的更新比率,用来控制算法收敛的速度。Rush和Collins[18]证明当αk满足以下条件时

图4 基于对偶分解的词语对齐搜索算法

并且

对偶分解算法能确保评价函数收敛。
3 实验
本文的训练集是中英24万句对的政府新闻类双语语料库,开发集和测试集是2005年度863计划词语对齐评测数据集,开发集包含502句对,测试集包含505句对。我们所使用的评价指标是由Och和 Ney[13]的对齐错误率 (Align ment Err or Rate,AER),对齐错误率越低表示对齐质量越高。
我们与以下两个系统进行对比:
(1)GIZA++:IBM 模型[1],采用EM 算法进行参数训练,爬山法进行搜索,由Och和Ney[13]实现。
(2)Vigne:Liu et al.[10]提出的判别式词语对齐方法,采用最小错误率训练算法[11]进行参数训练,柱搜索算法进行搜索。
我们首先使用GIZA++的默认设置进行双向训练,得到中英和英中两个方向的IBM模型4的对齐结果以及模型参数。Vigne主要采用GIZA++输出的IBM模型参数作为主要特征,具体为文献[10]提出的9个特征,利用最小错误率训练[11]在开发集上优化特征权重,在测试集上采用柱搜索算法获得最优对齐结果。我们的词语对齐系统在建模和训练算法上与Vigne完全一致,只是在搜索算法上采用对偶分解法。
3.1 与传统搜索算法的对比
表1给出了我们的系统与GIZA++和Vigne的对比结果。GIZA++产生四种对齐结果:
(1)中英:以中文为源语言,英文为目标语言,使用IBM模型4;
(2)英中:以英文为源语言,中文为目标语言,使用IBM模型4;
(3)交集:两个方向对齐结果的交集;(4)并集:两个方向对齐结果的并集。
其中,GIZA++的交集取得了四种设置中最好的结果23.9。判别式词语对齐系统Vigne取得的对齐错误率是20.8,显著超过了GIZA++。而我们的对偶分解算法取得了最好的对齐错误率19.7,超过GIZA++4.4个百分点,Vigne1.1个百分点。我们采用了Koehn[19]提出的显著性检验方法验证上述差别在统计上是显著的(p=0.05),从而验证了对偶分解算法确实有效减少了搜索错误。
在搜索效率上,GIZA++作为一个无监督的方法,需要对较大的数据进行整体的处理,并不能对单句进行词对齐,与Vigne和我们的方法很难比较。
而我们使用的对偶分解采用的是迭代的方法,每一轮迭代都需要对两个子问题分别搜索,所以在时间上要慢于Vigne时间复杂度随着迭代次数的增长而增长。
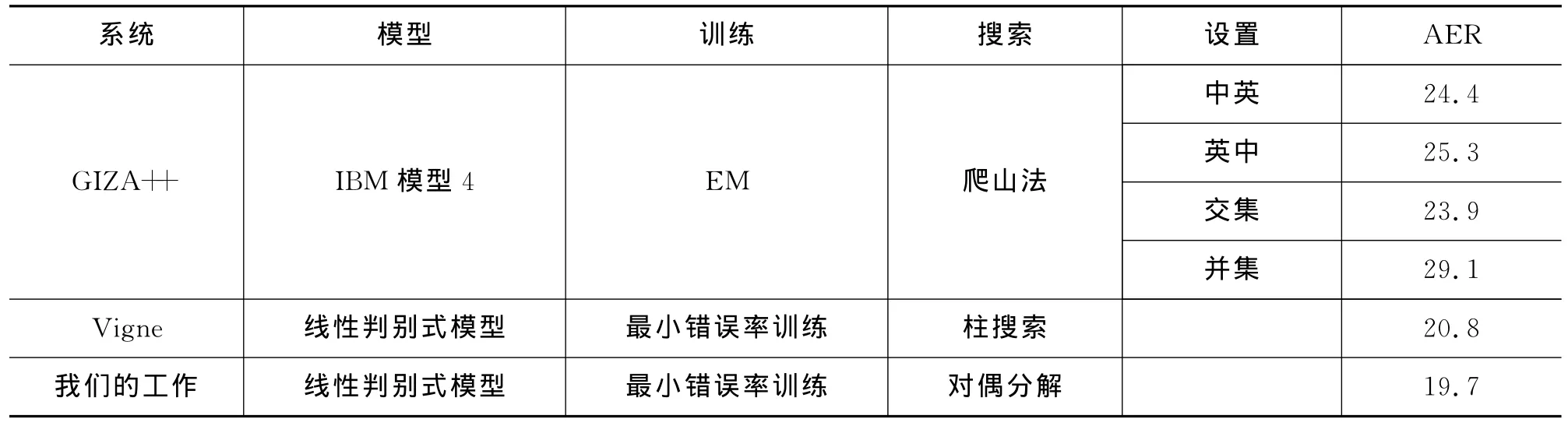
表1 GIZA++、Vigne与我们的方法的对比结果
3.2 迭代更新比率αk对收敛率和对齐错误率的影响
Rush和Collins[18]指出迭代更新比率αk将对对偶分解的迭代是否收敛产生重要影响。因此,我们通过实验研究迭代更新比率对收敛率的影响。所谓收敛率,是指待对齐文本中达到收敛的句子比例。例如,如果对偶分解算法在100个句子中的90个句子达到收敛,则收敛率为90%。我们设定最大迭代次数K为100,当迭代超过100次后我们认为该句子在本方法下不收敛。表2给出了不同的迭代更新比率及相应的收敛率和对齐错误率。其中,k为迭代次数,t是一个整数,其值为在迭代过程中对偶分解的评价函数增长的次数。由于1/t(+1)和1/k满足式(5)和(6),它们对应的收敛率均超过96% 并取得较低的AER。与之相反,常数型的更新比率(如0.1、0.01和0.001)则对应较低的收敛率和较高的AER。因此,更新比率对于收敛率和AER具有重要的影响①需要指出的是,在实际过程中,我们发现对于较长的句子无法实现$100\%$的收敛率,原因在于收敛性与最优性的约束条件并不完全一致。但即使对偶分解算法无法通过收敛获得最优解,也可以计算出较好的次优解。。

表2 迭代更新比率αk对结果的影响
3.3 句子长度对收敛率的影响
对于词语对齐问题来说,句子的长度直接影响了算法的复杂性。直观来看,句子越短,词语对齐所需要的搜索空间越小。反之,句子越长,搜索空间越大。我们设置不同的迭代收敛比率αk,观察对偶分解算法在不同长度的句子上的收敛率。图5给出了在αk=0.1、总收敛率为0.6040的条件下,句子的收敛比率随句子长度变化的关系图。可以看出,对偶分解算法的收敛率随着句子长度的增长大致是呈现下降趋势。也就是说,由于句子长度的增长而增大的搜索空间会使得算法收敛率下降。

图5 句子长度对收敛率的影响
3.4 收敛与不收敛数据集上对偶分解与柱搜索的比较
表3给出了收敛数据集和不收敛数据集上对偶分解算法与柱搜索算法的比较情况。我们发现无论是在收敛数据集上还是在非收敛数据集上,对偶分解算法都取得了比柱搜索算法更好的结果,进一步证明对偶分解算法能有效地提高对齐质量①值得注意的是,在收敛数据集和非收敛数据集上对齐错误率有较大的差异,收敛数据集上的对齐错误率明显较优,原因在于对偶分解能够在相对简单的句子上收敛,故根据收敛性就会将数据集划分为“较难”和“较易”的两部分。。
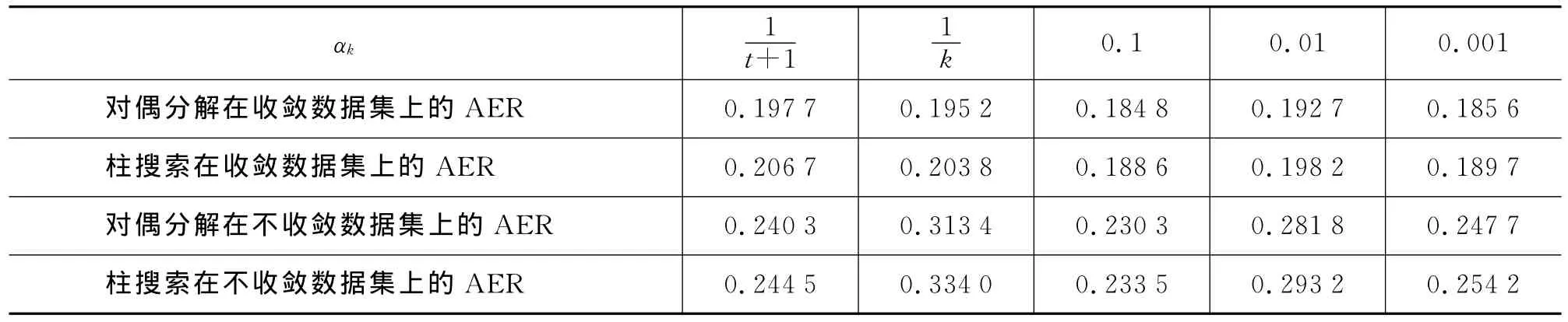
表3 收敛和不收敛数据集上对偶分解与柱搜索的比较
3.5 对偶分解与子模型的比较
在实验中,我们采用的子模型一是线性模型,采用Liu et al.[10]提出的9个特征,与Vigne的特征一致,子模型二也是线性模型,采用Liu et al.[10]提出的6个特征。表4给出了对偶分解算法与其使用的两个子模型各自的对齐错误率。我们观察到与两个子模型相比,对偶分解方法取得了更优的结果,这也进一步说明对偶分解算法的确能够在子模型的基础上减少搜索错误,降低对齐错误率。

表4 对偶分解与子模型的对齐错误率比较
4 相关工作
Koo et al.[19]首次将对偶分解应用于自然语言处理领域,他们在句法分析上验证了对偶分解算法的有效 性。Rush 和 Collins[17]与 Chang 和 Collins[16]则分别将对偶分解算法引入基于句法和基于短语的机器翻译中,有效减少了搜索错误。De Nero和Macherey[20]首次将对偶分解引入词语对齐,但他们的重点是模型融合,我们则侧重扩展判别式模型的搜索算法。Martins et al.[21]进一步将对偶分解扩展为可以处理若干个子问题。
除了对偶分解,整数线性规划(Integer Linear Pr ogra mming)是另一项被广泛应用的优化技术。Ravi和Knight[22]将整数线性规划首次应用于词语对齐,为GIZA++设计了精准搜索算法。
综合利用多个结果来改善结果的方法有模型融合和系统融合,但是对偶分解本质上是一种最优化搜索算法,它可以被用于系统融合:不是将原问题分成两个子问题,而是分成多个子问题。
5 结论
本文提出了一种基于对偶分解的词语对齐搜索算法,通过子问题迭代分别求解直至收敛于最优解。我们的方法在2005年度863计划词语对齐评测数据集上显著超过生成式模型的爬山法和判别式模型的柱搜索算法。未来我们将深入研究提高长句收敛率的方法,希望能进一步减少词语对齐的搜索错误。
[1]Peter F Brown,Vincent J Della Pietra,Stephen A Della Pietra,et al.The mathematics of statistical machine translation:parameter estimation[J].Computational Linguistics,1993,19(2):263-311.
[2]Philipp Koehn,Franz J Och,Daniel Marcu.Statistical phrase-based translation[C]//Pr oceedings of HLTNAACL,Ed monton,Canada,May.2003:127-133.
[3]David Chiang. Hierarchical phrase-based translation[J].Computational Linguistics,2007,33(2):201-228.
[4]Michel Galley,Jonathan Graehl,Kevin Knight.Scalable inference and training of contextrich syntactic translation models[C]//Proceedings of COLINGACL,Sydney,Australia,July.2006:961-968.
[5]Stephan Vogel,Her mann Ney,Christoph Till mann.Hmm-based word align ment in statistical translation[C]//Proceedings of t he 16th conference on Co mputational linguistics—Volu me 2,COLING'96,Stroudsburg,PA,USA.Association f or Computational Linguistics.1996:836-841.
[6]Percy Liang Ben Taskar Dan Klein.Align ment by agreement[C]//Proceedings of the main conference on Human Language Technology Conference of the North American Chapter of the Association of Co mputational Linguistics, HLT-NAACL'06, Str oudsbur g, PA,USA. Association for Co mputational Linguistics.2006:104-111.
[7]Yang Liu,Qun Liu,Shouxun Lin.Loglinear models for wor d align ment[C]//Proceedings of the 43r d Annual Meeting on Association f or Computational Linguistics,ACL'05,Stroudsburg,PA,USA.Association for Computational Linguistics.2005:459-466.
[8]Robert C Moore.A discriminative framework f or bilingual wor d align ment[C]//Proceedings of the Conference on Hu man Language Technology and Empirical Methods in Natural Language Processing,HLT'05,Stroudsburg,PA,USA.Association f or Computational Linguistics.2005:81-88.
[9]Phil Blunso m,Trevor Cohn.Discri minative wor d align ment with conditional random fields[C]//Proceedings of the 21st Inter national Conference on Co mputational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics,ACL-44,Stroudsburg,PA,USA.Association f or Co mputational Linguistics.2006:65-72.
[10]Yang Liu,Qun Liu,Shouxun Lin.Discri minative word align ment by linear modeling[J].Computational Linguistics,2010:36(3):303-339.
[11]Franz Josef Och.Mini mu m error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association f or Co mputational Linguistics—Volume 1,ACL'03,Stroudsburg,PA,USA.Association f or Computational Linguistics.2003:160-167.
[12]Chris Dyer,Jonat han H Clar k,Alon Lavie,et al.Unsupervised word align ment with ar bitrary feat ures[C]//Proceedings of the 49th Annual Meeting of the Association f or Computational Linguistics:Human Language Technologies,Portland,Oregon,USA,June.Association f or Co mputational Linguistics.2011:409-419.
[13]Franz Josef Och,Her mann Ney.A systematic comparison of various statistical alignment models[J].Co mput.Linguist.,2003,29(1):19-51,March.
[14]Jason Riesa,Daniel Marcu.Hierarchical search f or wor d align ment[C]//Pr oceedings of t he 48th Annual Meeting of the Association f or Computational Lin-guistics ACL'10 Stroudsburg PA USA.Association f or Computational Linguistics.2010:157-166.
[15]Terry Koo,Alexander M Rush,Michael Collins,et al.Dual deco mposition f or parsing wit h non-projective head auto mata[C]//Proceedings of t he 2010 Conference on Empirical Methods in Natural Language Processing,EMNLP'10,Stroudsburg,PA,USA.Association for Computational Linguistics.2010:1288-1298.
[16]Yin-Wen Chang,Michael Collins.Exact decoding of phrase-based translation models through lagrangian relaxation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,EMNLP'11,Stroudsburg,PA,USA.Association f or Co mputational Linguistics.2011:26-37.
[17]Alexander M Rush,Michael Collins.Exact decoding of syntactic translation models through lagrangian relaxation[C]//Proceedings of the 49th Annual Meeting of the Association f or Co mputational Linguistics:Hu man Language Technologies—Volu me 1,HLT'11,Stroudsburg,PA,USA.Association f or Co mputational Linguistics.2011:72-82.
[18]Alexander Rush,Michael Collins.A tutorial on lagrangian relaxation and dual deco mposition f or nlp[J].Jour nal of Artificial Intellegience Research.2012.
[19]Philipp Koehn.Statistical significance tests for machine translation evaluation[C]//Dekang Lin and Dekai Wu,editors,Proceedings of EMNLP,Barcelona,Spain,July.Association for Co mputational Linguistics.2004:388-395.
[20]John De Nero,Klaus Macherey.Model-based aligner combination using dual decomposition[C]//Proceedings of the 49th Annual Meeting of the Association f or Co mputational Linguistics:Hu man Language Technologies,Portland,Oregon,USA,June.Association f or Computational Linguistics.2011:420-429.
[21]Andre Martins,Noah Smith,Mario Figueiredo,et al.Dual deco mposition with many overlapping co mponents[C]//Pr oceedings of the 2011 Conference on Empirical Methods in Natural Language Processing,Edinburgh,Scotland,UK,July.Association f or Co mputational Linguistics.2011:238-249.
[22]Sujith Ravi,Kevin Knight.Does giza++make search errors?[J].Computational Linguistics,2010,36(3).
