基于多粒度的英汉人名音译
2013-10-15凃兆鹏
于 恒,凃兆鹏,刘 群,刘 洋
(1.中国科学院 计算技术研究所 智能信息重点实验室,北京100190;2.清华大学 计算机科学与技术系,北京100084)
1 引言
音译作为一种按照文字读音进行近似翻译的方法,在人名翻译中有着广泛的应用[1]。人名音译接受一个源语言的人名作为输入,在保证发音基本不变的原则下,输出与该人名以目标语言表示的翻译。例如,“Julianne”→“朱丽安”。由于音译从读音角度处理翻译问题,在处理未登录词翻译问题上有着良好的效果,因此在很多跨语言任务如机器翻译、跨语言检索以及跨语言问答系统中有着广泛的应用。
由于语言习惯的不同,人名音译过程中,应当适当调整源语言的序列结构(即切分),以使之符合目标语言的语言习惯。因此翻译粒度一直是音译研究的重点之一。Knight和Graehl[2]在日英人名音译中,以英文音素和日文音素为单位,通过发音相似性寻求转换。Al-Onaizan和 Knight[3],Sherif[4]提出以字母为单位,跳过发音过程,直接进行翻译。Wei-Hao Lin和 Hsin-His Chen[5]使用音节相似度模型进行人名音译。邹波、赵军[6]将音节切分问题转换为序列标注问题,采用机器学习的方法进行人名音译。以上方法从不同角度处理音译粒度问题,取得了良好的效果,但每种方法均存在不足之处,主要有以下几个方面。
(1)以字母为粒度的方法能够生成较为广泛的音译规则,但规则错误率较高,无法充分利用发音信息辅助切分。
(2)以音节为粒度的方法利用发音信息进行音节切分,生成准确度较高的音译规则,但模型鲁棒性较差,对一些特例或歧义性音译无法得到正确切分。
(3)采用机器学习方法的音译策略能够从语料中自主学习音译知识。但对标注语料的依赖性较强,对语料外的切分问题处理能力不佳。
因此,本文提出基于多粒度的英汉人名音译方法。通过词图融合各种粒度的切分,从而缓解了因切分错误而导致的音译错误,在充分利用语言学知识的同时又提高了模型的鲁棒性和音译规则的多样性。实验结果表明,在英汉人名音译中基于多粒度音译方法效果好于单一粒度的音译方法,在准确率上提高3.1%,在翻译BLEU值上提高2.2个百分点。
2 统计音译模型
音译问题可以应用P Br own[7]提出的噪声信道模型进行建模。当观察到噪声信道的信号为O时,我们可以得到一个可能的输入序列集合F(O),其中的每组输入序列f都能得到对应的输出序列e。我们的目标是找到概率最高的作为输出。
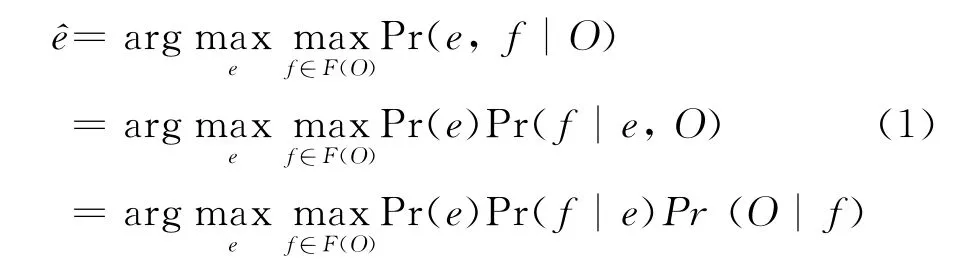
在人名音译问题中,O即为输入英文人名,f为可能的音节切分序列,e为人名翻译。模型的目标是从O中获取最佳的切分序列f,然后利用音译规则进行解码,得到正确的音译结果e。理论上,我们可以简单地通过穷举F(O)集合中的所有可能序列f来得到最佳翻译,但这样做会带来巨大的计算开销。实际上,许多可能的序列都具有相同的子片段,因此通过词图对这些可能的序列进行表示并在此基础上进行解码会大大提升系统的性能。
3 基于词图的解码
3.1 词图
词图G=<V,E>为一个由点和有向边构成的有向无环图,其中V为点集合,E为有向边集合。形式上是一种带权有限自动机。如图1所示。
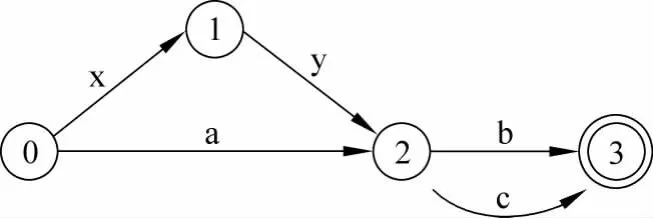
图1 词图示意图
词图可以表示各种输入序列,并且支持相同子序列的共享,从初始节点0到终止节点的每条路径都代表一组可能的序列,因此能够将不同输入融合在同一个图结构中。
在音译问题中,假设源端为n个字母的词,词图上的每个节点为源端的跨度(从0到n),连接节点的边为该跨度下可能的翻译。我们的目标即为找到一条概率最大的路径,路径上的边即为生成的目标翻译。
如图2所示,音译“Julianne”的最佳路径为红线标出的“0-2-4-7-8”,生成的结果为“朱丽安”。
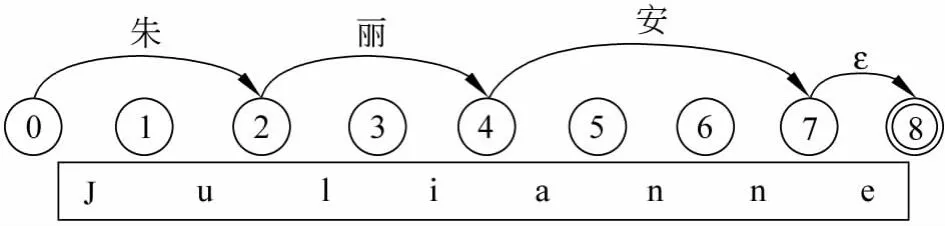
图2 实例Julianne的词图及最优翻译路径
3.2 解码
Chiang[8]提出了基于上下文无关文法(SCFG)的层次短语翻译模型。在解码过程中,不断使用翻译规则匹配源端输入串,生成翻译片段,同时在目标端生成基于SCFG的树结构。本文采用类似方法,从对齐语料中抽取符合上下文无关文法的音译规则进行解码。
在我们的解码算法中包含两种元素。
1.[X→α·β,i,j]表示在跨度(i,j)上未匹配完成规则,“·”为位点,指示当前需要匹配的符号位置。
2.[X,i,j]表示在跨度(i,j)上为非终结符X。解码的目标为找到一组覆盖整个词图跨度[S,0,|V|-1]的规则推导。
在解码中,我们定义如下两种规则推导。
1.匹配一个终结符β,位点前进一位,同时覆盖相应词图上的一条边。规则跨度变为[i,j+1],生成新的翻译片段 wj,j+1
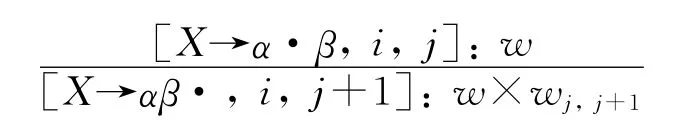
2.匹配一个非终结符X,位点移位,并找到其对应后继,将两者的翻译片段合并为w1×w2。

基于以上两种推导规则,我们使用CKY算法,按照自底向上的顺序,对词图进行解码。
4 多粒度切分方法
为了进行多粒度的融合,需要获得各种粒度的英文切分。本节主要介绍三种切分方法。
4.1 基于字母的切分
基于字母的切分方法[3-4]以英文字母为单位,采用统计的方法学习源端和目标端的对应关系。
4.2 基于音节的切分
Wei-Hao Lin和 Hsin-His Chen[5]提出以英文音节为单位的切分方法。从发音的角度来寻找符合目标端语言习惯的最佳切分。如图3所示。
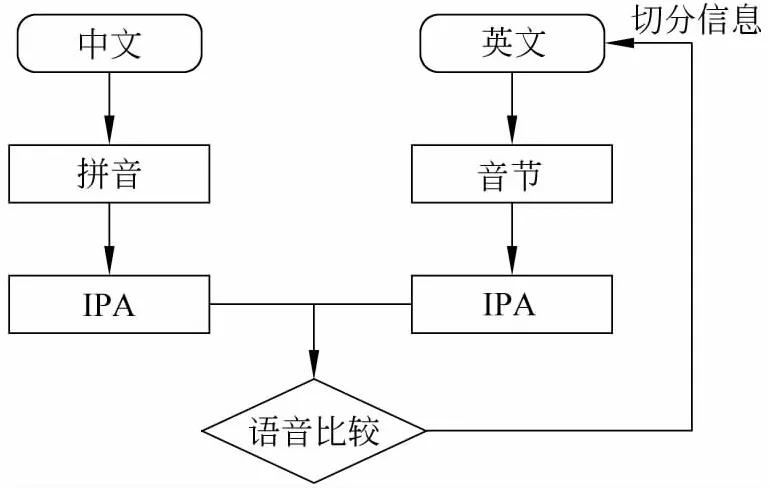
图3 音译的切分获取方法
首先英文部分利用CMU pronouncing dict①http://www.speech.cs.c mu.edu/cgi-bin/c mudict将英文序列拆分成相应的音节,再通过音节词典转换为国际通用发音序列Inter national Phonetic Alphabet(IPA)。同时中文端将汉字转化为拼音,再转化为IPA序列。这样源端和目标端通过IPA序列进行语音比较,从而找到源端正确的切分。
4.3 基于机器学习的切分
我们将英文音节的切分看成一个序列标注的问题:以L(音节首),M(音节中),R(音节尾),S(独立音节)来标识英文字母在所在音节中的位置。这四个类别可以覆盖英文字母位置的所有情况。给定一个人工切分好音节的训练集,我们可以很容易得到英文字母的标注序列。
在估计字母位置标注的概率分布时,我们使用最大熵模型。假设h为该标注的上下文特征集合,t为可能的标注集,则最终标注的概率可以表示为H和T的联合概率分布,如式(2)所示。
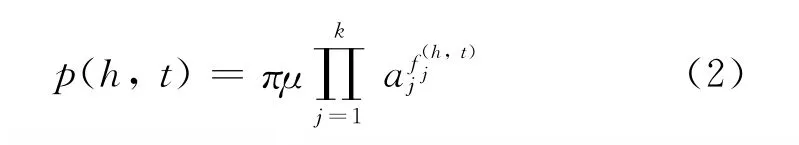
其中π为归一化常数,{μ,a1,…,ak}为模型参数,{f1,…,fk}为最大熵模型中定义的特征,fj(h,t)∈{0,1}。对于每一个特征fj,都有一个参数aj与之对应,作为该特征的权重。在训练过程中,给定一个英文字母序列{c1,…,cn}和它们的标注集{t1,…,tn},训练的目的是找到一组最佳的参数{μ,a1,…,ak},使训练数据的P的似然值L(P)最大。
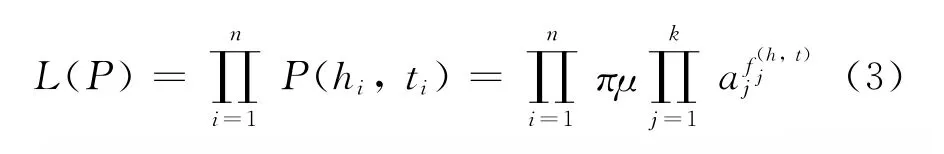
最大熵模型的效果在很大程度上取决于选择合适的特征。在(h,t)给定的条件下,所选特征必须包含对预测t有用的信息。我们在实验中使用特征见表1。
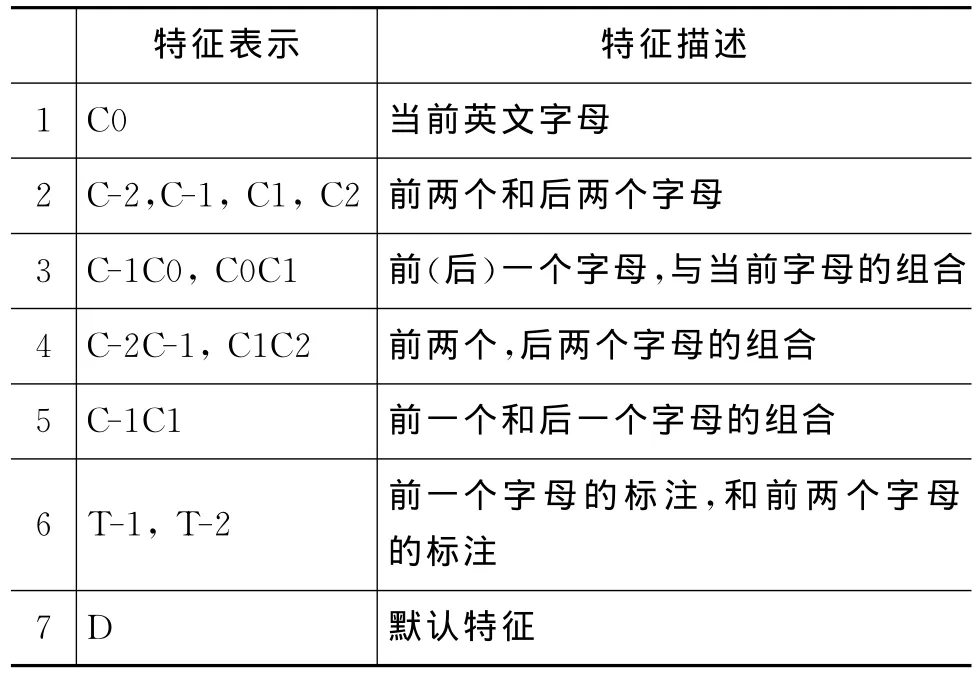
表1 切分特征模板
如上列表所示,我们定义了三类特征,第一类是基于当前和上下文字母的特征(12345 第二类是基于前一二个字母的标注特征(6),第三类是默认特征(7),用来捕捉前两类无法表示的情况。当训练完成时,特征和它们的对应权重将可以用作计算未知数据中各种标记的出现概率,如式(4)所示。
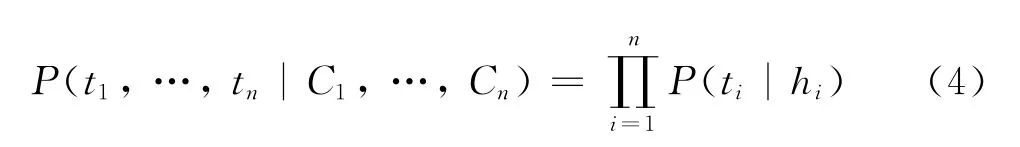
给定一个序列{c1,…,cn},通过viter bi算法可以得到概率最大的标注序列{t1,…,tn},进而得到切分序列。
5 实验
5.1 实验准备
实验的语料来源于Chinese-English Name Entity Lists v1.0(LDC2005 T34),该语料库包括565935音译对。我们从中过滤掉一些其他语种音译对,得到4万英汉人名对。从中随机挑选500对作为开发集,500对作为测试集,其余作为训练集。汉语语言模型以汉字为单位使用训练集进行训练。
我们分别使用第4节所述的三种切分方法获得不同粒度的英文切分,再使用GIZA++工具对中英文两端进行对齐。音译规则抽取及词汇化模型的训练在生成的对齐数据上进行。
我们使用最小错误率训练方法来优化线性模型的参数。所使用的解码器是层次短语解码的C++重实现版本。该解码器采用CKY方式进行解码,并使用cube-pr uning的方法进行剪枝,以减少搜索空间。实验所使用的栈大小为100。
我们使用层次短语的经典特征进行解码:
1.英文序列e音译为汉语序列c的概率P(c|e)
2.汉语序列c音译为英文序列e的概率P(e|c)
3.英文序列e音译为汉语序列c的词汇化概率lex(c|e)
4.汉语序列c音译为英文序列e的词汇化概率lex(e|c)
5.语言模型特征l m(c)
6.汉语译文长度L(c)
7.音译规则使用数量n
8.黏着规则使用数量m
5.2 实验结果
在实验中,我们比较了基于各种粒度的音译效果,评价的标准如下。
部分管理者甚至认为有了先进的设备就可以忽略人的作用,将人与设备对立了起来,导致设备的无人看管和缺少维护。完全依靠先进设备进行电网调度的做法使得很多具体情况不能够得到充分认识和考虑,使工作中出现顾此失彼的现象。
1.准确率:音译结果完全匹配的结果百分比。
2.BLEU:机器翻译中常用评价指标,表征音译结果片段的准确率。
由于准确率只考虑完全匹配的情况,从而忽视了某些音译片段的效果提升。因此我们加入BLEU作为评价标准,从更细的粒度来考察音译的准确率。
如表2所示,以字母为粒度的音译方法准确率为49.2%,BLEU值为0.5325,在所有方法中效果较差。主要原因是因为以字母为粒度导致对齐边的增多,从而引入了很多对齐错误,导致许多错误的切分。在没有其他发音信息的辅助下,生成过多无用的音译规则,使规则表达到29 MB。而以音节为粒度的方法充分利用发音信息,系统性能有所提升准确率为54.2%,BLEU值为0.5513。但此方法生成的音译规则过少,导致覆盖率不足,并且不具备处理音译歧义现象的能力。通过机器学习方法得到切分的音译模型在性能上有了进一步的提升,准确率为61.2%,BLEU值为0.5721。该方法通过标注语料自动学习切分,但由于人工标注语料较为稀少,所以覆盖率有限。
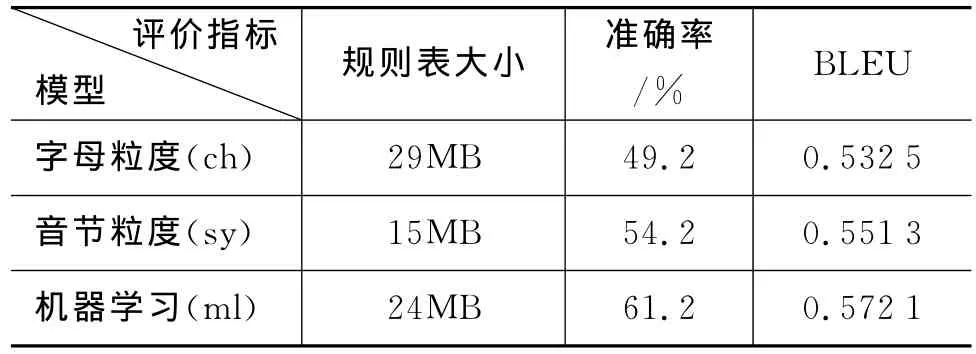
表2 不同粒度实验效果比较
本文采用词图的方法混合以上三种粒度进行音译规则抽取。实验结果如表3所示。
ch+sy:融合字母和音节粒度
ch+ml:融合字母和机器学习粒度
sy+ml:融合音节和机器学习粒度
ch+sy+ml:同时融合三种粒度

表3 不同粒度融合实验效果比较
从表3中可以发现,基于词图的多粒度融合方法取得了明显的性能提升。值得注意的是字母粒度虽然自身的性能较差,但是和其他两种粒度融合都取得了明显的效果。而音节粒度和机器学习粒度的融合却没有取得明显的效果提升。造成这种现象的原因是音节粒度和机器学习粒度生成规则的相似性较高,且粒度都较大,因此规则数量较少。所以两者融合后规则表数量并无明显提升,性能上也没有显著增长。而字母为粒度的方法生成规则和其他两种方法差异较大,从某种意义上提升了规则的多样性,从而在融合中取得了良好的效果。最终,我们将三种粒度进行混合,得到最佳的性能,准确率为64.3%,BLEU值为0.594,比单粒度的最好性能准确率提升3.1%,BLEU 提升2.2%。
表4列出了不同音译粒度下英文人名,“Julianne”的音译结果。我们可以发现单粒度的结果都存在着不同程度上的问题。而多粒度融合的方法能够得到正确的结果。

表4 不同粒度方法音译“Julianne”的结果
6 相关工作
近些年来,研究者们在人名音译领域进行了广泛的研究,Knight和Graehl[2]在日英人名音译中,提出以英文音素为粒度,通过发音相似性寻求转换的方法。Al-Onaizan 和 Knight[3],Sherif[4]提出以字母为单位,跳过发音过程,直接进行翻译。Wei-Hao Lin和 Hsin-His Chen[5]使用音节相似度模型进行人名音译。Long Jiang[10]通过人工定义规则的方法进行了有益的尝试,将英文字母划分为元音和辅音,在切分时遵循元音和辅音配对的原则。邹波,赵军[6]将音节切分问题转换为序列标注问题,将机器学习和统计机器翻译模型用于音译。本文的模型融合以上方法的优势,通过词图融合生成多粒度的音译规则,缓解了因切分错误带来的翻译错误,提高了系统的鲁棒性。
在使用机器学习方法进行切分时,本文使用了最大熵模型[11]。该方法在NLP其他领域都有广泛的应用,如Ratnaparkni[12]将其用于处理词性标注问题,Nianwen Xue 在处理中文分词问题时也用到类似方法,取得良好的效果。
在词图解码算法上,Christopher Dyer[14]将其使用在机器翻译上,融合源端的多种分词结果,提升机器翻译的性能。
7 结论
本文提出了一种基于多粒度的英汉人名音译方法,融合多种粒度的切分信息,生成更鲁棒的音译规则。实验结果在准确率上比单粒度效果提升3.1%,BLEU提升2.2%。在后续的研究中,我们将探索更多的切分方法的融合,并改进解码算法,争取进一步提升音译系统的性能。
[1]Li Haizhou,Zhang Min,Su Jian.A Joint Source-Channel Model f or Machine Transliteration[C]//Proceedings of ACL,2004:159-166.
[2]Kevin Knight,J.Graehl.Machine Transliteration[J],Co mputational Linguistics,1998,24(4):599-612.
[3]Yaser Al-Onaizan,Kevin Knight.Translating named entities using monolingual and bilingual resources[C]//Proceedings of ACL,2002:400-408.
[4]Tarek Sherif,Grzegorz Kondrak.Bootstrapping a stochastic transducer f or Arabic-English transliteration extraction[C]//Proceedings of ACL,2007:864-871.
[5]Wei-Hao Lin,Hsin-His Chen.Back ward Machine Transliteration by Lear ning Phonetic Si milarity[C]//Pr oceedings of the 6th Co NLL,2002:139-145.
[6]邹波,赵军.英汉人名音译方法研究[C]//第四届全国学生计算语言学研讨会论集,2008:24-30.
[7]Brown P F,Pietra S A D,Pietra V J D.The mathematics of statistical machine translation:parameter esti mation[J].Co mputational Linguistics,1993:19(2):263-311.
[8]David Chiang. Hierarchical phrase-based translation[J].Co mputational Linguistics,2007,33(2):201-288.
[9]Franz Josef Och,Her mann Ney.A Systematic Comparison of Various Statistical Align ment Models[J].Co mputational Linguistics,2003,29(1):19-51.
[10]Long Jiang,Ming Zhou,Lee-Feng Chien,et al.Na med entity translation with web mining and transliteration[C]//Proceedings of IJCAI,2007:1629-1634.
[11]Adam L Berger,Stephen A.Della Pietra,Vincent J.Della Pietra.A Maxi mu m Entropy appr oach to Natural Language Processing[J].Computational Linguistics,1996,22:156-242.
[12]Ratnapar khi,Ad wait,A maxi mu m entropy part of speech tagger[C]//Proceedings of EMNLP,1996:133-124.
13 Nian wen Xue.Chinese Wor d Seg mentation as Character Tagging[J].Computational Linguistics and Clinese Language Processing,2003,8(1):29-48.
[14]Christopher Dyer,Muresan,Philip Resnik.Generalizing Wor d Lattice Transltion[C]//Proceedings of ACL,2008:1012-1020.
