基于中心语块扩展的汉藏基本名词短语对的识别
2013-10-15诺明花刘汇丹马龙龙丁治明
诺明花,刘汇丹,马龙龙,吴 健,丁治明
(中国科学院 软件研究所,北京100190)
1 引言
浅层句法分析也称作部分句法分析或语块分析(chunking)。它主要是识别句子中某些结构相对简单的独立成分。例如,非递归的名词短语、动词短语等。这些被识别出的结构通常被称作语块(chunk),语块和短语这两个概念可以换用[1]。目前最具代表性的语块分析任务是基本名词短语识别。
名词短语翻译是机器翻译的一个子任务。双语语料库是从事统计机器翻译/辅助翻译等自然语言处理研究必不可少的基础资源。构建双语语料库的关键技术之一是对齐,即在双语文本中找到互为翻译的源文和译文片段,对齐的单位包括篇章、段落、句子、短语、词语等,不同的自然语言应用要求做到不同单位的对齐。汉藏辅助翻译工作已经具备了大规模的汉藏句子对齐语料[2]和藏文分词工具[3-4]。短语级别的对齐工作刚刚开始,目前还未看到汉藏基本名词对齐相关研究报道。较大规模的汉藏短语词典的构建,仅靠手工对齐是不现实的,因此研究汉藏短语自动对齐方法是有意义且必要的。鉴于现代藏语句法结构,本文先从名词为中心词的基本名词短语(BaseNP)入手,识别汉藏基本名词短语互译对。
2 相关研究
目前英语基本名词短语的研究已相对比较深入并且渗透到语法分析、信息检索等应用领域。早在1991年,Abney[5]提出了语块分析的策略,并引进句法块概念后,浅层句法分析,特别是BaseNP的识别得到了普遍的关注,国内外出现了很多BaseNP识别的方法,许多有效的统计和机器学习方法被应用到英语语块识别中,并且取得了较好的识别效果。
Ramshaw和 Marcus[6]在他们的开创性工作中,把NP语块分析问题作为机器学习问题,并提出标准数据集和评价指标。2000年举行的自然语言学习国际会议(CONLL-2000)推出了组块共享任务[7],旨在统一组块类别,开发出一个大规模的英语组块库,为基于统计的不同分析方法的探索提供统一的训练和测试语料库。此项共享任务采用了Abney的组块描述框架,扩展其他基本组块,其中名词短语组块是从Ramshaw和Marcus的工作发展而来的。在研讨会中的很多系统利用了机器学习方法,其中,最有代表性的是Kudo和 Matsumoto[8]应用的支持向量机(Support Vector Machine,SVM)的方法[8]。此后,许多新的统计学习的方法被应用到了BaseNP识别中,例如,条件随机场(Conditional Random Fields,CRF)[9]、Winnow 算法[10]、结构学习方法(Structural Learning Methods)[11]等。Ando和Zhang提出了一种半监督学习(Semi-supervised Learning)的英文BaseNP识别方法并取得了目前最好的识别结果[11]。
因为汉语名词短语结构的复杂性,汉语语言学界对名词短语结构的看法尚未形成成熟而统一的意见。在汉语BaseNP研究方面,赵军[12]依据张卫国对名词短语中三类定语的论述,首先提出了汉语基本名词短语的严格形式化定义,阐明了它的语言学内涵,提出了基于转换的中文基本名词短语识别方法和模型[13]。还有许多其他的方法用于汉语基本名词短语的识别,例如,利用隐马尔科夫模型(Hidden Markov Model,HMM)[14]、利用最大熵(Maximum Entropy,ME)方法[15]、利用基于记忆的学习方法(Memory-based Learnig)[16]和利用组合分类器的方法[17]等。徐昉采用一种新的错误驱动的组合分类器方法,与单独使用基于转化的方法、条件随机场方法以及支持向量机方法相比较,显著提高了中文BaseNP识别效果[18]。目前,汉语还没有像CoNLL-2000那样的标准数据集和评估系统,因此无法评价不同的中文BaseNP识别系统。
藏语BaseNP研究还处于起步阶段。2003年,江荻初步阐述了藏语组块分析的基本观念[19],同时对藏语组块构成的类型和标记形式做了广泛的描述。其后,详细分析了藏语的组块计算处理问题,并落实到计算处理方法上[20]。从形式标记着手提出解决非谓动词自动识别的方法。而在藏语名词组块分析中,黄行[21]针对现代藏语名词组块的构成与结构,对名词组块做了初步定义,并根据名词组块的句法功能开展了名词组块的分类研究。尝试解决词格标记的同形问题和词根黏着问题。对于采用零标记的名词组块,利用其他上下文隐性标记加以处理,其中主宾语名词组块的识别率均达到了可接受的程度[22]。
双语名词短语自动抽取相关成果发表较少。刘冬明提出了一种在汉英双语语料库句子对齐的基础上,自动进行汉英名词短语划分和对应的方法[23]。他将短语分高频和低频短语分别处理,对于高频短语,利用英语短语和汉语词在双语语料库中的关联信息,采用一种迭代重估算法进行双语短语的对应;对于低频短语,根据双语词典中源词和译词之间的对应信息,结合一套人工编写的句法规则进行双语低频短语的对应,从而提高了覆盖率。屈刚用基于“有效句型”概念和“翻译中相对不变准则”的短语对齐模型对源语言和目标语言句法树间对应关系排除歧义[24]。这个模型的输入是源语言(英语)、目标语言(汉语)候选句法分析树集。汉藏双语BaseNP的研究还未见相关报道。
3 汉藏基本名词短语对齐框架
对于不同的语言,名词短语的结构有着较大的差异,定义的方式也往往不同。英语基本名词短语定义为简单的非嵌套的名词短语,即一个基本名词短语内部不能再包含有更小的名词短语。通过对汉藏双语语料的分析,鉴于双语短语对的源语言是汉语,我们参考文献[12]提出的从限定性定语的角度出发的汉语基本名词短语的概念,定义本文所抽取的藏语基本名词短语的概念。
定义1:藏语基本名词短语 (BaseNP)
BaseNP→BaseNP+BaseNP
BaseNP→BaseNP+名词
BaseNP→限定性定语+BaseNP
BaseNP→限定性定语+名词
限定性定语→形容词|区别词|动词|名词|处所词|(数词+量词)
其中,为了抽取结合比较紧密的一般名词短语,“的”字短语作定语及并列的名词性成分都在藏语基本名词短语范围内。本文工作目标是建立汉藏双语基本名词短语词典。因此,只抽取两个或以上单词构成的短语。
定义2:汉藏名词短语准等价对
汉藏准等价对是短语级的对齐,设符号 “↔”表示对齐关系,短语用词序列表示,汉藏准等价对的定义表示如下。
<Cr1,Cr2,…,Crq>↔<Tt1,Tt2,…,Ttp>
关于此定义的说明为:由于汉语和藏语语义上的差别,很难在语法层面上找到一个定义使得汉语名词短语和藏语名词短语完全等价,因此本文称为汉藏准等价名词短语,以下简称汉藏名词短语对。
下面介绍本文提出的汉藏基本名词短语对自动抽取框架。分两步完成。首先,抽取汉语基本名词短语。这一步以汉藏句子对齐的语料为基础,用Stanford parser对双语语料中的所有汉语句子做句法分析,从句法树中抽取所有NP。自动抽取的NP存在一定的误差,我们进行适当的人工筛选后作为汉语基本名词短语。第二步是从已得到的汉语基本名词短语出发,用不同的基于中心语块扩展的方法找到藏语短语译文。处理流程如图1所示。
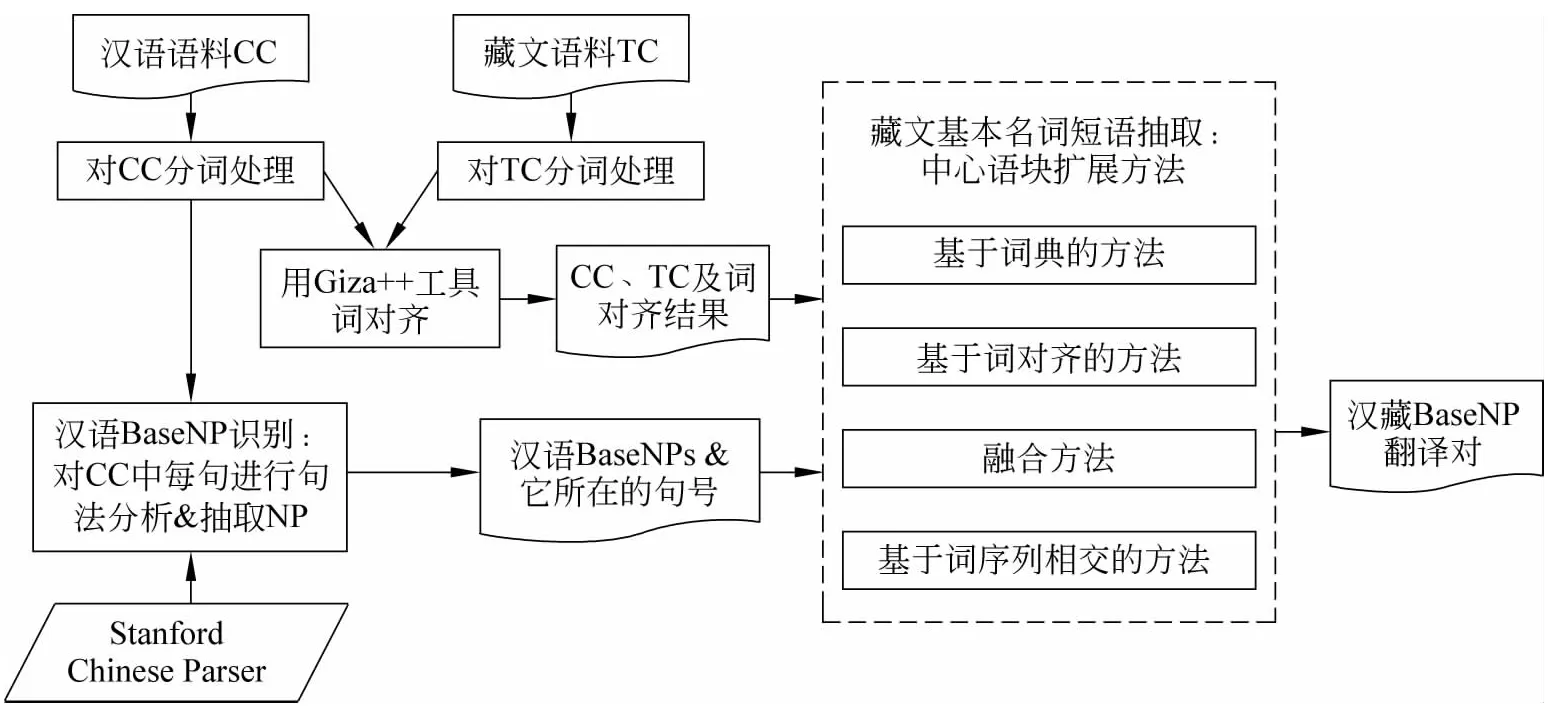
图1 汉藏基本名词短语对齐流程图
识别过程主要分三步来完成。
1.预处理。句子对齐的汉语语料和藏语语料以一行一句的形式分开存储。汉语和藏语语料均分别做分词处理后用GIZA++①http://code.google.com/p/giza-pp/downloads/list自动词对齐。
2.识别汉语基本名词短语。用Stanford Chinese parser②http://www-nlp.stanford.edu/software/lex-parser.shtml对汉语语料做句法分析,自动抽取句法树中的NP得到分词的汉语基本名词短语,并存储短语及它所在的句号。
3.找对齐的藏语基本名词短语。用中心语块扩展策略和统计信息为第二步抽取的汉语基本名词短语确定正确的译文。
下一节重点介绍中心语块扩展策略和不同的藏语基本名词短语自动抽取的方法。
4 藏语基本名词短语生成模型
在汉英短语对齐方面,张春祥[25]提出中心语块扩展的源语言短语候选译文生成方法。其中,译文生成过程大致分两步,先确定中心语块的边界,再通过扩展中心语块找出正确的译文。
本文提出的藏语基本名词短语生成模型用中心语块扩展的策略,在两个处理阶段中用与文献[25]不同的方法。在藏语短语中心语块边界确定阶段,可以以基于词典的对齐结果为锚点,在藏语句子中抽取汉语短语的译文。显然,基于词典的对齐方法具有很高的正确率,但召回率低。因此,本文用GIZA++生成的词对齐结果弥补召回率。另外,参考王辰[26]提出的基于序列相交的短语译文获取方法的基本思想,对已知的汉语基本名词短语,对它所存在的所有藏语句子进行序列相交操作得到候选译文,再应用统计信息进一步确认正确译文。在中心语块扩展阶段,定义中心语块扩展可信度,当扩展中的候选译文与汉语基本名词短语之间的可信度明显降低时认为已经扩展到了译文边界。
4.1 基于词对齐的中心语块确定方法
为已知的汉语基本名词短语,依据它所在的汉藏句对的词对齐结果获得短语译文对齐区间[i,j]。其中,i和j分别是当前汉语基本名词短语中各个词对齐的藏语单词位置中最小和最大值。
具体实现中,词对齐可以用汉藏双语词典或采用intersect启发式规则的GIZA++词对齐,还尝试这两种词对齐的融合来确定藏语中心语块。融合策略描述如下。
汉语基本名词短语的每个单词在汉藏双语词典中查找,如果有对应词条即可以得到藏语词列表(TWL)。
· 如果TWL不为空,在当前汉语基本名词短语所存在的句号找到藏语句子。判断TWL中是否有单词出现在该藏语句子中。并把所有出现的位置记录下来。
· 如果TWL为空,直接用GIZA++生成的词对齐结果找到对齐单词在藏语句子中的位置,并记录位置信息。
在位置集合中最小和最大两个值之间的词串作为藏语中心语块。
4.2 基于序列相交的中心语块确定方法
汉藏句子对齐语料中任何一个句对用SP表示,对齐关系可以表示为SP=CS↔TS,其中CS和TS分别表示汉语和藏语句子。本文的汉藏语料是分词处理过的,因此句子可以表示为词序列;汉语句子、藏语句子和汉藏对齐词序列表示形式如式(1)、(2)、(3)所示。
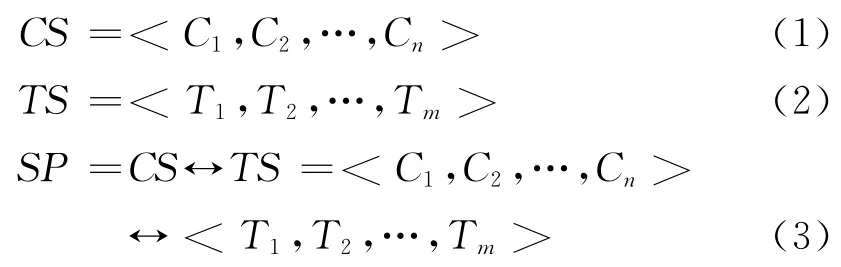
定义3:藏语句子序列相交
设SPr,SPt∈CTBC是汉藏句子对齐语料中任意两个句对,可以表示为SPr=CSr↔TSr和SPt=CSt↔TSt,两个句对中藏语句子的相交可以用式(4)表示。
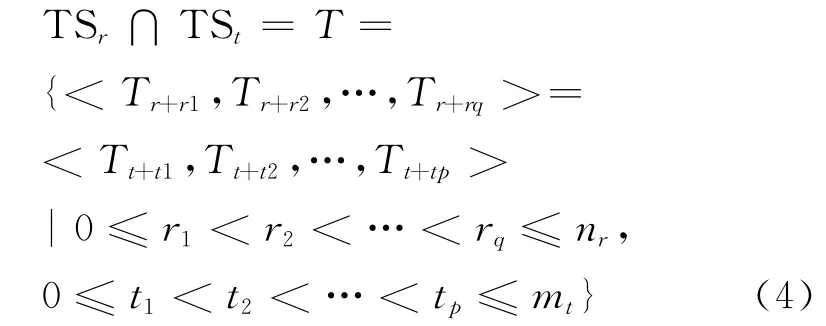
其中,TSr∩TSt是藏语句子TSr和TSt的交集。下标r1,r2…rq和t1,t2…tp是递增的。
语料中,如果一个汉语基本名词短语Qi出现在多个汉语句子中,通常在这些汉语句子所对应的藏语句子中Qi的译文是完全相同或核心词相同。藏文是语法特征和形式标记比较丰富的语言,名物化标记、格助词等使得序列相交的结果为核心词相同的可能性更大。因此,集合T中的某一个元素肯定是Qi译文的中心语块。从而,找藏语基本名词短语的任务可以转化为计算藏语句子之间的公共子串的问题。
经过以上分析,可以用式(5)表示藏语句子的序列相交。
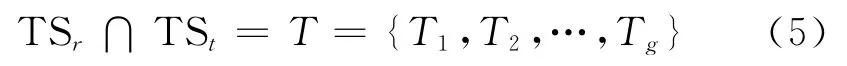
集合T一定包含Qi的翻译译文的一部分,用Tj表示。假设与已识别的汉语BaseNP共现的,连续的藏语字串T用下面的符号表示:

汉语BaseNP与T之间的平均互信息(Average Mutual Information,AMI)和平均t值(Average T-score,AT)的计算公式分别如下:
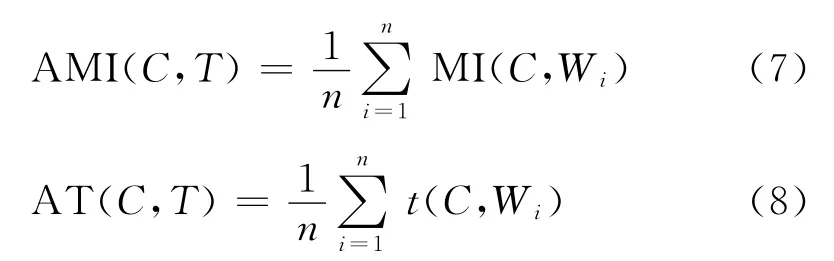
我们设定一个选择函数来确定候选译文。为每个Tj(1≤j≤g)用 MI和t-value来定义选择函数Ψj,如式(9)所示。
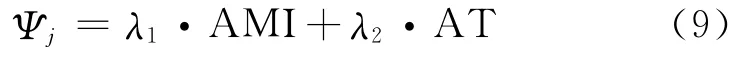
其中,Ψj值最大的Tj(1≤j≤g)是藏语基本名词短语的中心语块。藏语中心语块确定后,下一步工作是从中心语块出发确定藏语基本名词短语的左右边界。
4.3 藏语中心语块扩展策略
藏语基本名词短语生成模型第二步是定义扩展策略来确定藏语短语的统计边界。一般统计方法中最常用的是互信息和关联度t-value值。所用公式如下:
4.3 藏语中心语块扩展策略
藏语基本名词短语生成模型第二步是定义扩展策略来确定藏语短语的统计边界。一般统计方法中最常用的是互信息和关联度t-value值。所用公式如下:
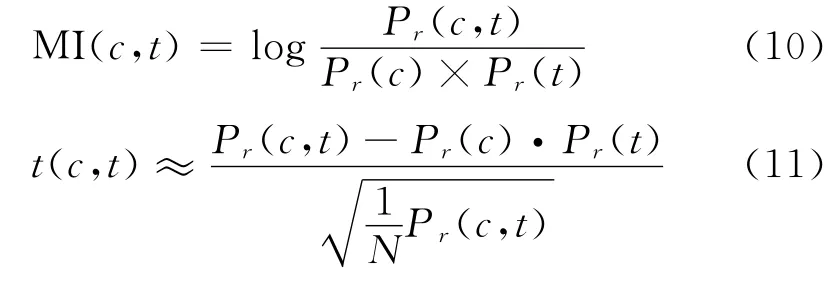
其中N是句子总数,c表示汉语短语,t表示藏语词汇,Pr(c,t)表示c和t的共现概率,Pr(c)和Pr(t)分别表示c和t出现的概率。为每个汉语基本名词短语,计算它和所在的句对中的藏语句子中每个单词之间的MI和t-value。互信息在此用于表征汉语名词短语和藏语词语之间对应的确定性程度,t-value值用于说明统计信息值得信任的程度。
定义4:中心语块扩展可信度
汉语短语PhC在藏语句子中的中心语块为PhT(n),其中n为长度,扩展相邻藏语单词后获得的译文为PhT(n+1),则中心语块扩展可信度Cn可以定义为:

其中,AMI和AT分别表示PhC和正在扩充的候选藏语基本名词短语中所有单词之间 MI和tvalue的均值。
依据Cn,藏语基本名词短语统计边界确定过程描述如下。从译文中心语块出发,在藏语句子中不断向一侧扩充单词,每扩充一个藏语单词就计算Cn;如果Cn大于等于阈值,则继续扩展,直到Cn小于阈值时停。获得汉语短语PhC的译文统计边界具体过程如图2所示。
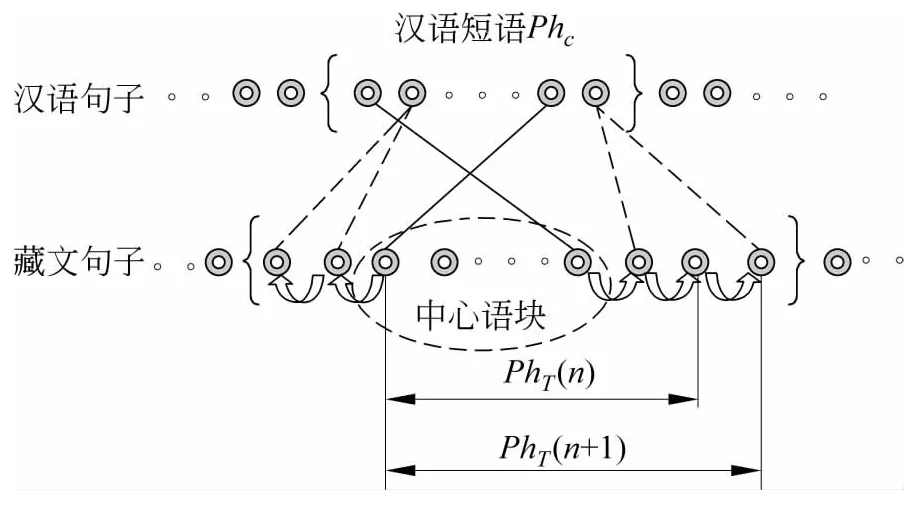
图2 中心语块扩展过程图
图2中,汉语句子中方括弧内是汉语基本名词短语PhC,藏语译文的左右边界已用大括弧括起来,获得了扩展后的藏语基本名词短语,表示为PhT(n+ω),0≤ω≤L-n,它们构成准等价基本名词短语对(PhC,PhT)。
5 实验
5.1 实验语料
本文实验在汉藏法律法规和公文报告领域句子对齐语料上进行。收集到的原始语料通过篇章对齐和句子对齐后,分单语语料存储。句子级对齐的汉语和藏语语料经过分词、GIZA++工具词对齐以及对汉语句子做句法分析等预处理工作后,最终形成汉藏基本名词短语对抽取框架可以处理的初始数据。表1给出了语料基本信息。
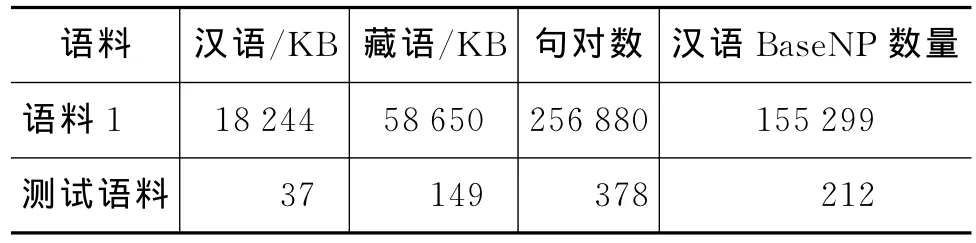
表1 语料信息
已有的句对齐的汉藏语料规模达到25万余,称为语料1,包括长句和短句。本文工作目标为从较大规模语料中自动抽取汉藏基本名词短语对,从而构建汉藏基本名词短语词典。但现阶段还没有汉藏对齐短语对正确率的自动评价工具,需要人工完成正确率计算;考虑到工作量较大,在测试阶段从语料1随机抽取了378句对,作为测试语料。对测试语料通过句法分析能够抽取384条汉语基本名词短语,其中包括只有一个名词构成的基本名词短语、不符合本文定义的基本名词短语和句法分析识别错误的基本名词短语等。人工筛选后,获得符合本文的基本名词短语212条。随后我们邀请藏族学者为212条汉语基本名词短语提供正确译文,再以此为参考自动判断不同算法的实验结果。
5.2 实验结果及分析
本文参考文献[23],使用的评价指标为覆盖率和正确率,定义如下。
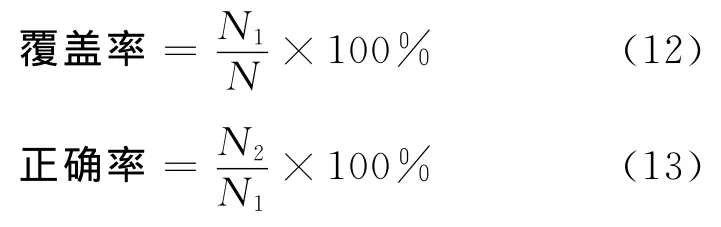
其中,N为实验语料中汉语基本名词短语总的出现次数,N1为语料中获得对应的汉语基本名词短语的总出现次数,N2为语料中获得正确对应的汉语基本名词短语总出现次数。以参考答案为基础,自动计算N1和N2。
基于中心语块扩展的藏语基本名词短语识别方法由两部分组成,分别是中心语块的抽取和中心语块的扩展。本文在中心语块抽取过程中使用不同方法做实验,最终确定一个适合藏语中心语块抽取的方法。基于词对齐结果的中心语块确定方法可以独立应用汉藏双语词典或GIZA++词对齐结果。也可以将两者结合起来用。应用GIZA++中,评估多种启发式合并规则提供的词对齐结果,结论是intersect最适合用于中心语块抽取。因为,intersect提供的词对齐是孤立单词的正确对应,从而避免了藏语名物化标记、格助词和停用词等边界高频干扰信息。
在中心语块的抽取过程中,基于汉藏双语词典的方法(DicB)、基于GIZA++词对齐的方法(WA)、词典和GIZA++词对齐相结合的方法(Dic&WA)以及基于序列相交的方法(SI)的实验结果如表2所示。
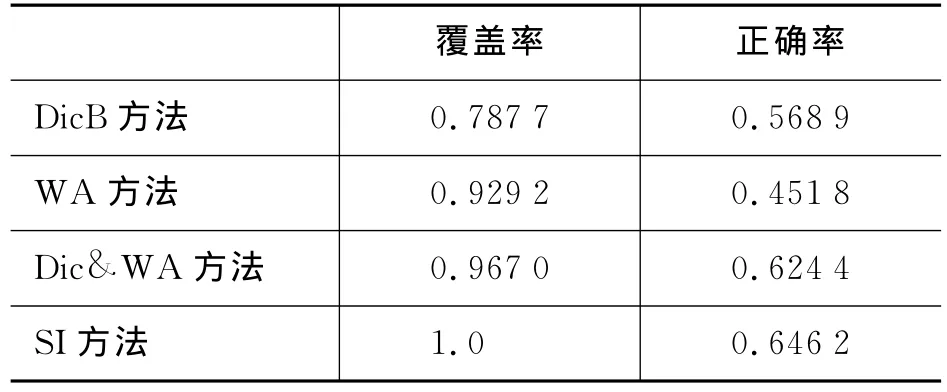
表2 不同方法BaseNP对齐结果
从实验结果可以看出,汉藏词典的召回率较低,但具有很高的正确率,导致DicB方法正确率高,而覆盖率太低。如果单独用GIZA++词对齐结果,能够提高覆盖率。因为GIZA++工具本身的误差导致WA方法正确率明显降低。Dic&WA方法通过两种词对齐结果的互补来提高了整体性能。因此,与词典和GIZA++相结合的方法相比,基于序列相交的方法适合低频短语的抽取,从而能够提高覆盖率;同时,它在句子序列相交的过程中能够把附加的形式化标记和高频干扰项过滤,所以能够获得较高的正确率。在自动抽取汉藏基本名词短语对任务中,基于序列相交的方法效果最好。
6 结论
本文参考英汉短语对齐的方法,针对藏语语言的特殊性,提出基于中心语块扩展的汉藏基本名词短语对自动抽取方法。对汉藏句子对齐语料进行一些预处理后,用Stanford parser抽取汉语基本名词短语。进一步应用中心语块扩展策略为这些汉语基本名词找到语料中的正确译文。中心语块确定过程中,用DicB方法、WA方法、Dic&WA方法以及基于序列相交的方法;在扩展中心语块过程中,定义了扩展可信度来确定左右统计边界。自动抽取的汉藏基本名词短语对能够节省人工校正的工作量,可以很好地辅助汉藏基本名词短语词典建设。
总体来说,藏语基本名词短语之间的边界比较模糊,长名词短语较丰富,就目前而言语言学界对藏语基本名词短语的描述不够深入。因此,藏语基本名词短语识别的正确率比英语和汉语BaseNP识别结果偏低,在识别精度方面还有待于提高。本文提出的汉藏基本名词短语对自动抽取框架也可以用于汉藏一般名词短语或动词短语对识别任务中。
[1]孙宏林,俞士汶.浅层句法分析方法综述[J].当代语言学,2000,2(2):74-83.
[2]于新,吴健,洪锦玲.基于词典的汉藏句子对齐研究与实现[J].中文信息学报,2011,25(4):57-62.
[3]Huidan Liu,Weina Zhao,Minghua Nuo,et al.Tibetan number identification based on classification of number components in Tibetan word segmentation[C]//Proceedings of the 23rd International Conference on Computational Linguistics (COLING'10):Posters,2010:719-724.
[4]刘汇丹,诺明花,赵维纳,等.SegT:一个实用的藏文分词系统[J].中文信息学报,2012,26(2):97-103.
[5]Steven P Abney.Principle-Based Parsing[M],Kluwer Academic Publishers.1991.
[6]Ramshaw L A,Marcus M P.Text Chunking using Transformation-Based Learning[C]//Proceedings of Schiffrin A.Proceedings of ACL Workshop on Very Large Corpora.Boston,1995:82-94.
[7]Erik F Tjong Kim Sang,S Buchholz.Introduction to the CoNLL-2000shared task:Chunking.[C]//Proceedings of CoNLL-2000,2000:127-132.
[8]Taku Kudo,Yuji Matsumoto.Chunking with support vector machine [DB/OL].acl.ldc.upenn.edu/N/N01/N01-1025.pdf.2000.
[9]Fei Sha,Fernando Pereira.Shallow Parsing with Conditional Random Fields.Eduard Hovy[C]//Proceedings of HLT-NAACL,Edmonton,Alberta,2003:134-141.
[10]Zhang Tong,Fred Damerau,David Johnson.Text chunking using regularized Winnow[C]//Proceedings of ACL'01,2001:539-546.
[11]Ando R K,Zhang Tong.A High-Performance Semi-Supervised Learning Method for Text Chunking[C]//Kevin Knight.Proceedings of the 43rd Annual Meeting of ACL.Ann Arbor,Michigan,2005:1-9.
[12]赵军.汉语基本名词短语识别及结构分析研究[D].清华大学博士研究生学位论文.1998.
[13]赵军,黄昌宁.基于转换的汉语基本名词短语识别模型[J].中文信息学报,1999,13(2):1-7.
[14]Heng Li,Jonathan J.Webster,Chunyu Kit,et al.Transductive HMM based Chinese text chunking[C]//Proceedings of IEEE NLP-KE 2003,2003:257-262,Beijing.
[15]李素建,刘群,杨志峰.基于最大熵模型的组块分析[J].计算机学报,2003,26(12):1722-1727.
[16]Yuqi Zhang, Qiang Zhou. Chinese base-phrases chunking[C]//Proceedings of the First SIGHAN Workshop on Chinese Language Processing,vol(18):1-5,Taipei,Taiwan,2002.
[17]Wenliang Chen,Yujie Zhang,Hitoshi Isahara.An Empirical Study of Chinese Chunking[C]//Proceedings of the 43rd Annual Meeting of ACL.Sydney,Australia,2006:97-104.
[18]徐昉,宗成庆,王霞.中文Base NP识别:错误驱动的组合分类器方法[J].中文信息学报,2007,21(1):115-119.
[19]江荻.现代藏语组块分词的方法和过程概述[J].民族语文,2003,(4).
[20]江荻.现代藏语的句法组块与形式标记,语言计算与基于内容的文本处理[C]//全国第七届计算语言学联合学术会议论文集.2003:160-166.
[21]黄行,孙宏开,江荻,等.现代藏语名词组块的类型及形式标记特征[C]//全国第八届计算语言学联合学术会议.2005:615-617.
[22]黄行,江荻.现代藏语判定动词句主宾语的自动识别方法[M].语言计算与基于内容的文本处理.清华大学出版社.2003:167-172.
[23]刘冬明,赵军,杨尔弘.汉英双语语料库中名词短语的自动对应[J].中文信息学报,2003,17(5):6-12.
[24]屈刚,陈笑蓉,陆汝占.基于有效句型的英汉双语短语对齐[J].计算机研究与发展,2003,40(2):143-149.
[25]张春祥,李 生,赵铁军.基于中心语块扩展的短语对齐[J].计算机研究与发展,2006,43(9):1658-1665.
[26]王辰,宋国龙,吴宏林,等.基于序列相交的短语译文获取[J].中文信息学报,2009,23(1):38-43.
