基于词元语义特征的汉语框架排歧研究
2013-10-15李国臣张立凡刘海静
李国臣,张立凡,李 茹,2,刘海静,石 佼
(1.山西大学 计算机与信息技术学院,山西 太原030006;2.计算智能与中文信息处理教育部重点实验室,山西 太原030006;3.太原工业学院,山西 太原030008)
1 引言
自然语言处理研究旨在使计算机像人一样理解并使用自然语言,最终实现最高层次的人与计算机的有效“交流”,是人工智能领域的一个重要研究方向。但是,自然语言与计算机语言最大的不同就是它具有歧义性。例如,“我叫夏明”和“你妈妈叫你回家”这两个句子中,词“叫”就有“命名”和“发声”两种框架语义。这样的多义现象虽然对人与人之间的交流并不会造成太大影响,可是对目前自然语言处理的研究热点——语义分析的影响却至关重要。而框架排歧作为语义分析中的一个中间环节,对一条给定句子中的动词(或事件名词等),计算机可以为其自动分配一个正确的框架,从而消解这种歧义现象。如果能有效地处理好语义分析中的框架分配的歧义问题,不仅可以为语义角色标注任务奠定基础,还可以为构建语料库提供技术支持和保障,更可以为信息检索、机器翻译等应用提供有用的语义信息。
框架排歧是指在一个给定的句子中,根据句中目标词激起的语义场景,判断当前语境与该目标词可能属于的哪个场景一致,则将该场景下的框架分配给当前的目标词。例如,句子“我叫夏明”中的目标词“叫”可以激起“命名”和“发声”框架,根据人类的认知经验,在该句中目标词“叫”激起的是命名场景,而命名场景与框架库中的“命名”框架相一致,因此,给该句中的目标词“叫”应分配“命名”框架而不是“发声”框架。其中,目标词[1]是指在一个具体的句子中能够激起框架的词。框架[2]指的是与一些激活性语境相一致的结构化范畴系统,它是储存在人类认知经验中的图式化情境,是理解词语的背景和动因。在框架语义学中,场景是一个图式化情境,是语言之外的真实世界,语言中的每一个词、短语、句子都是对场景的描述。例如,“觉得、认为、以为、主张”等动词在人类经验中激起的是观点的场景,该场景涉及提出观点的人、观点、所考虑的对象和对提出的观点所持有的坚定程度等要素。因此,描述“觉得、认为、以为、主张”等动词的语义性质,就可以将其归入观点框架,以提出观点的人、观点、所考虑的对象和对提出的观点所持有的坚定程度等来刻画观点框架。
在形式上,框架排歧与词义消歧任务很相似,本质上,两者还是有很大的不同。首先,词义消歧的义项是给定的,而框架排歧任务存在框架缺失;其次,词义消歧针对的是句子中所有的词语,而框架排歧针对的是句子中可以激起框架的目标词元;再者,词义消歧更侧重于静态地计算多义词在词典中的哪个释义更适合于当前句子,而框架排歧是通过动态语义场景中的参与者和涉及的相关语义角色,来判断哪个候选框架所激起的语义场景与当前句子的语义场景是一致的。虽然框架排歧和词义消歧有很大的不同,但是框架排歧的研究刚刚起步,因而,目前框架排歧的方法[3-7]大都还是借鉴词义消歧[8-16]的 研究策略,将框架排歧看作是一个分类问题。在针对框架排歧的分类处理中,研究人员都是人工地设置特征模板,模板的特征项一般是由一定窗口内的词、词性、词与词性的组合以及词、词性的n-gram等构成。这种方法不仅需要研究者有丰富的语言学知识,还要对实验数据进行大量地观察,甚至通过多次实验才能确定特征模板的构成成分,这无疑是繁琐的。此外,对不同歧义的目标词而言,所能激起的语义场景是不同的,影响框架排歧的窗口大小和特征模板也是不一样的。如果完全通过人工对每个歧义的目标词分别构造合理的特征模板,工作量也将是巨大的。
为了克服传统的人工特征选择方法的繁琐,并充分利用每个歧义目标词的语义特征,本文研究了框架排歧中特征模板的自动选择方法,借助汉语框架语义资源(Chinese Frame Net,以下简称CFN)[17],进行5-f ol d交叉验证,分析和比较了该方法与传统的人工特征选择方法。实验结果表明,该方法要明显优于人工特征选择方法,且框架排歧的平均精确率可达到84.46%。
本文的组织结构如下:第2节描述了CFN及其汉语框架排歧任务;第3节描述了两种特征选择算法;第4节介绍了实验的设计与分析;第5节为结论与展望。
2 框架排歧任务描述
汉语框架网语义资源是由山西大学研发,以Fill more的框架语义学[18]为理论基础,以加州大学伯克利Frame Net[19]为参照,以汉语真实语料为依据构建的汉语词汇语义知识库。目前,CFN语料库[20]共标注了309个框架、3151个词元和2万多条句子,其宗旨[21]是构建大规模汉语框架语义网的样本,使CFN成为一部计算机可读、可理解的语义词典。
本文是在给定句子和歧义目标词的条件下,使用CFN语义资源,实现汉语框架排歧任务。在CFN语义资源中,目标词是在一个具体的句子中能够激起框架的词,由于一个框架可看作是刻画一个小的抽象的“场景”,因此可以通过计算歧义目标词可能激起的框架与歧义目标词所处的场景的匹配程度,从而为歧义目标词在给定的场景中选择合适的框架。
因而,框架排歧任务可形式化描述为:
对于歧义目标词T能够激起n个的框架,记为F={f1,f2,...,fn}。T 出现在某个确定的场景S中,汉语框架排歧的任务就是根据给定的场景S,在n个框架中选择一个最合适的框架,记为式(1)。
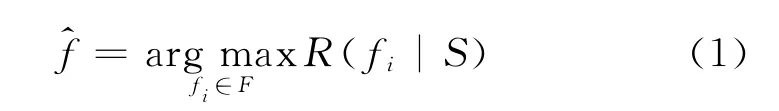
其中,R用来计算每个框架和场景的匹配程度。
3 特征选择
本文在参照文献[6]和文献[7]的特征基础上,利用哈尔滨工业大学LTP[22]平台对语料进行词法和句法分析,将可以激起多个框架的目标词元看作是支配其他成分的“控制项”,句中与“控制项”具有依存关系的成分(“依存项”)就是控制项激起的框架所对应的框架元素[23]。本文使用丰富的词法和依存句法特征作为特征空间,其中,词法特征包括在不同位置的词、词性和命名体识别特征。这些位置包括传统的BOW上下文和一些基于句法依存树结构的句法关系。句法特征包括目标词与其父节点和子节点之间的依存关系。目标词父节点的特征有词、词性与目标词的依存关系类型。子节点的特征选取与父节点一样的特征。依存关系类型,使用LTP分析器中定义的24种依存关系类型。
3.1 人工特征选择
为了考察传统的人工特征选择方法对汉语框架排歧性能的影响,本文选取文献[6]和文献[7]中对汉语框架排歧性能显著提升的一些特征,并首次选用对语义理解贡献最大的4种依存关系类型(主谓关系 SBV(subject-ver b)、动宾关系 VOB(ver bobject)、状中结构 ADV(adver bial)和定中关系ATT(attribute))的子节点作为特征,最终设计出10个特征模板,如表1所示。
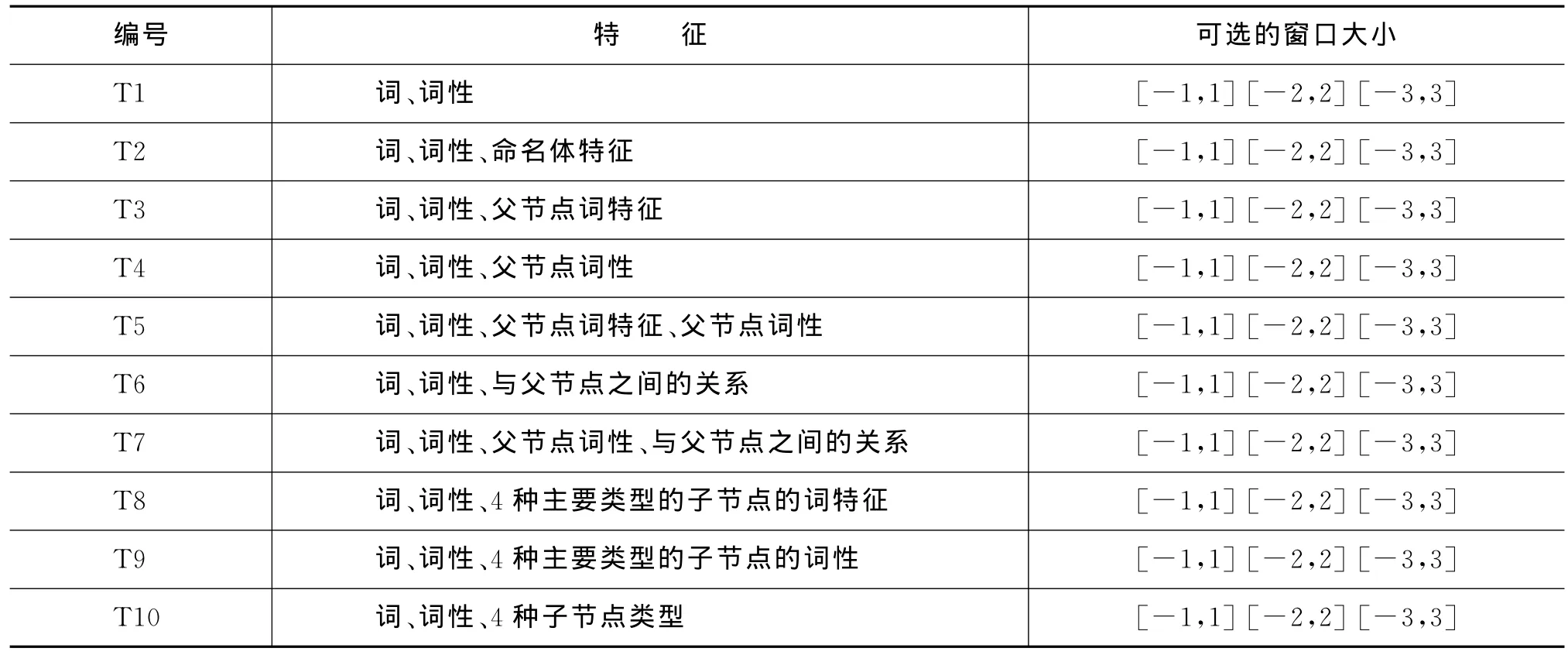
表1 人工特征模板
图1给出了对汉语句子“奥巴马表示,他想下次带夫人和孩子来长城。”利用LTP进行依存句法分析后,得到的结果。
在图1中,两个词汇之间有弧相连则说明两词之间存在某种依存关系,且弧是从父节点指向子节点。例如,“奥巴马”和“表示”之间存在主谓关系(SBV),且前者是后者的子节点。在上面的这个例句中,“表示”和“想”都是歧义的目标词,它们分别能够激起的框架有“代表”、“陈述”、“表达”和“观点”、“渴望”。表2列出了具体的特征值。
3.2 自动特征选择

图1 LTP自动分析的依存句法分析树

表2 例句的特征值取值

依存句法特征
本文采用贪心策略算法设计了一种自动特征选择方法,即为每个歧义词元选择独立的特征模板。这种方法的主要思想是:在给定的特征集中,每次从中选出一个特征模板项,并对其进行打分,每次评分后,只保留得分最高的特征项,直到相邻两次的得分不再增加。在实验中窗口特征值设置为[-1,1]和[-2,2],具体的特征项描述如表3所示。
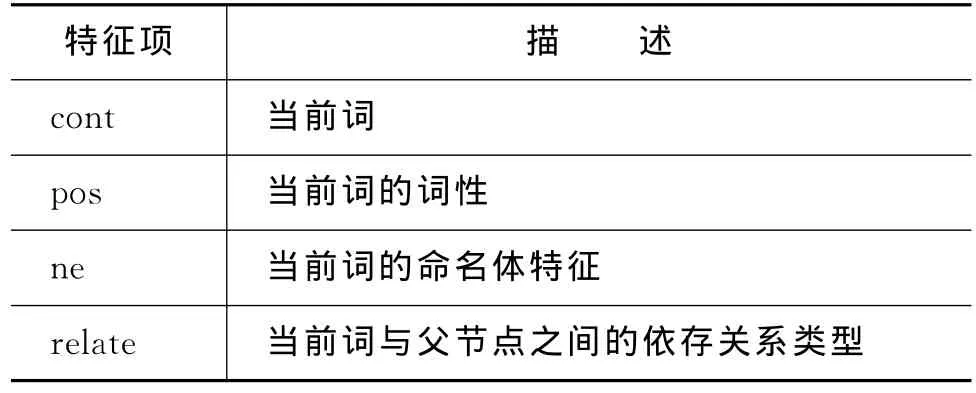
表3 特征项描述
由于为每个词元选择独立的特征模板时,语料规模相对较小,容易出现数据稀疏和过拟合的问题,导致特征模板项选择的偶尔性增加。为了避免这些问题,本文除了使用5-fold交叉验证方法外,还设置了特征模板项的优先级(relate>ne>pos>cont)。
自动特征模板选择算法如下:

算法分析:
算法中的主要操作就是比较查找和计算,计算是线性的,而比较操作接近n2。因此算法的时间复杂度为O(n2)。由于计算最大值和Score值需要独立进行,所以算法的空间复杂度为O(2n)。
而人工特征选择方法的时间复杂度为O(2n),空间复杂度为O(n2)。无论时间复杂度还是空间复杂度,自动特征选择算法都要优于人工特征选择方法。
4 实验
4.1 实验设置及预处理
本文实验中所用的语料均来自山西大学构建的CFN语料库。实验前期从281个词元中对16个词元进行语料的扩充,针对每个词元从北京大学CCL语料库中选取合适的句子进行扩充,语料规模从原有的7个词元扩充至23个词元,涉及的框架从14个增加到38个,句子数从原有的1600条扩充至2827条。表4是实验中所用到的词元,以及这些词元可能激起的框架的一个分配情况。
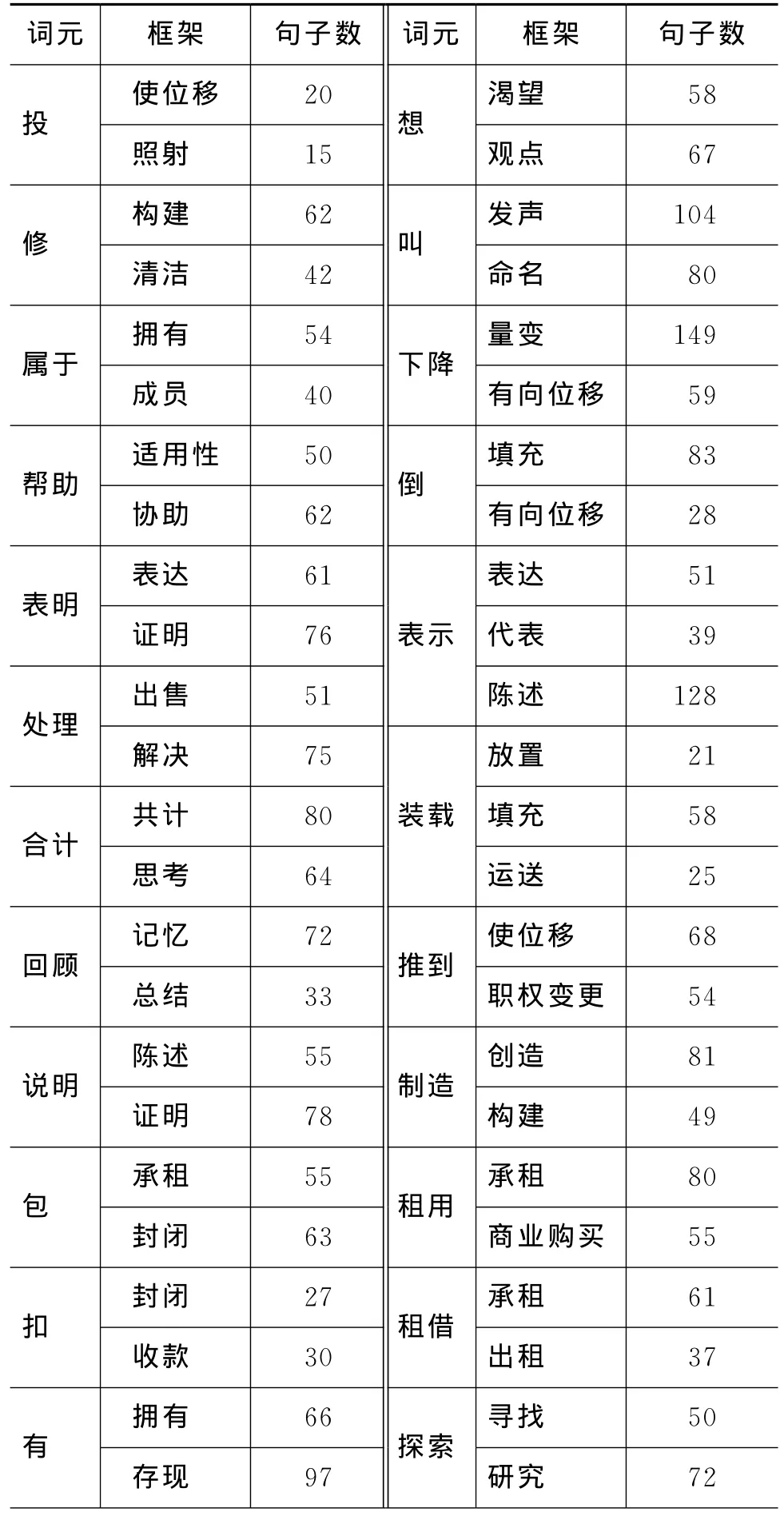
表4 词元和框架的分配情况
4.2 评价指标
给定一个目标词ti(i=1,2,...,N),N 为所选词元的总数(在本文,N=23),在5-f ol d交叉验证下,全部目标词的分类精确率计算如式(2)、式(3)所示。
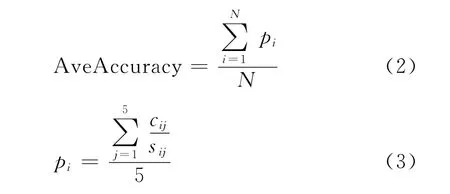
其中,sij是目标词ti的第j份交叉验证试验中测试例句的个数,cij是目标词ti的第j份交叉验证中框架分类正确的测试例句个数,pi称为第i个目标词的精确率。
4.3 实验结果及分析
本节实验主要用来验证本文提出的自动特征模板选择算法的有效性,并与文献[6]和文献[7]中的方法以及本文设计的人工特征模板的选择方法进行对比分析。
4.3.1 人工特征选择方法的实验结果与分析
表5列出了使用表1中设计的10个特征模板,选用最大熵模型训练,并进行5-f ol d交叉验证得到的实验结果。实验中最大熵分类器使用的是张乐博士[24]开发的最大熵工具包,采用LBFGS参数估计方法,实验中最大熵模型的参数采用最大熵分类器默认的参数设置。
从使用人工选择特征方法得到的实验结果,可以得出以下4个结论。
(1)使用基本特征和父节点词性、与父节点之间的依存关系组成的特征模板(T7特征模板),取得了最好的结果77.06%。这是因为,控制项与依存项之间的依存关系类型要比依存边更能有效地反映出两者之间的关系,在LTP平台中共定义了24种依存关系类型,而控制项与依存项之间的边组合却有成千上万种。所以,这种特征在一定程度上缓解了数据稀疏问题。同时也表明,依存句法特征对于汉语框架排歧任务是有帮助的,在树结构上的依存关系能够捕获更多的句子信息。
(2)在基本特征基础上添加子节点的词特征(T8特征模板)后性能下降。这是由于词特征的稀疏问题导致性能的下降。

表5 基于人工特征选择方法的汉语框架排歧的实验结果/%
(3)4种主要类型的子节点特征(T8、T9、T10特征模板)的加入使系统的性能下降。从语言学角度上看,在一个依存句法树上,控制项与其依存项共同组成了一个“语义团”,该结构在一定程度上能够表达句子的部分语义,而控制项的语义代表了整个“语义团”的语义。
(4)不同的特征取得标注最高精确率时对应的窗口大小是不同的,有些特征在窗口较小时结果比较好,有些随着窗口增大不断提高。如表6中的T3模板在窗口大小为1时,取得最高的精确率,T9模板随着窗口的增大而不断提高。
4.3.2 自动特征选择方法的实验结果
表6中列出了每个词元使用自动特征选择算法得到的特征模板及特征模板的模板项数。其中,每个特征模板的模板项由词的位置特征以及词法和句法特征构成,例如,“w1_relate”表示的是在目标词左边第一个词与其父节点的依存关系类型。

表6 使用自动特征模板的结果
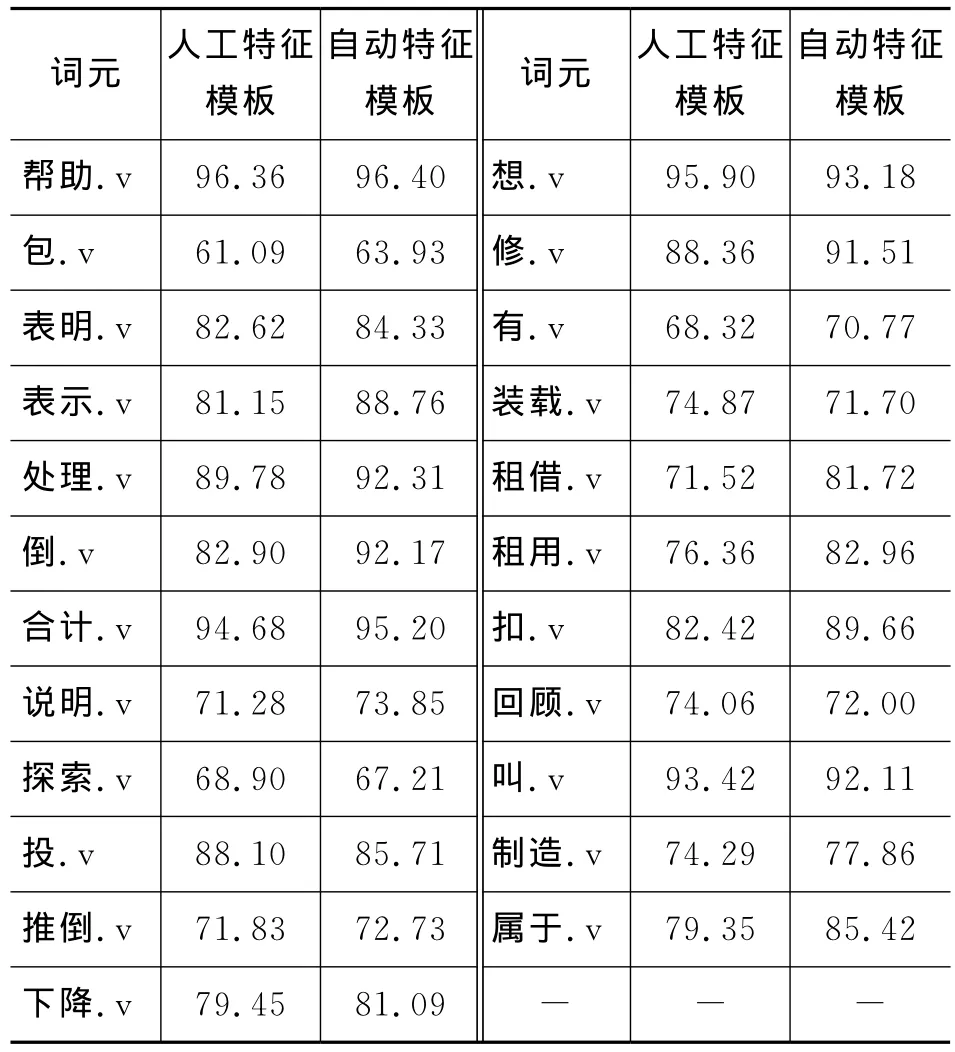
表7 每个人工特征模板和自动特征模板的结果对比/%
通过分析和比较表6和表7中的结果,从中可以发现,使用自动特征选择方法相比于使用人工特征选择方法具有以下优点。
(1)直观地,自动特征选择方法没有人工特征选择方法在人力和时间的花费大,并且特征项数明显减少。
(2)自动特征选择方法可以有效地减少大数据的特征集合中的噪音特征和冗余特征,而这些噪音特征和冗余特征可能导致训练的有效性降低和不合理的参数产生。这些不合理的参数不能有效地评估训练集,而自动特征模板的选择恰恰可以很好地的解决这一问题。
(3)为每个词元自动选择的特征模板,能够有效地利用每个词元的语义特性,整体上,使用自动特征模板要优于使用人工特征选择方法。
值得注意的是,并不是所有的歧义目标词使用本文提出的自动特征选择方法后,结果都有所提升,其原因是,一方面,本文的自动特征选择方法使用的贪心策略,得到的结果是局部最优的;另一方面,为了实验的方面,本文只选用了4种类型的特征作为特征项,不像人工特征选择方法使用了丰富的依存特征。
4.3.3 对比实验结果
本文用 most-frequent-fra me[4]作为baseline。
为了使自动特征选择方法有效地解决框架排歧任务,本文做了基于最大熵模型和SV M模型的自动特征选择方法的对比实验,具体的实验结果如表8所示。
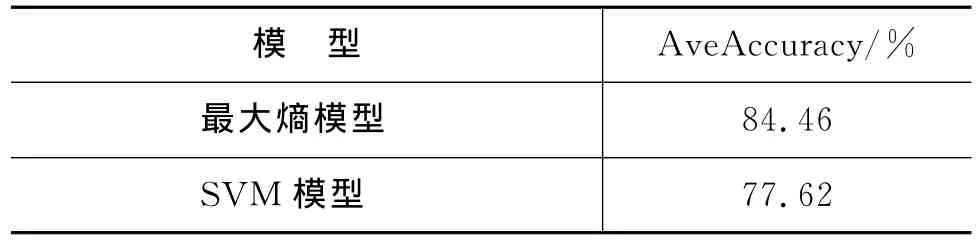
表8 基于不同模型的自动特征选择方法的结果对比
从表8中可以看出,最大熵模型优于SV M模型。因此,本文采用最大熵模型和4.1节中的语料,使用文献[6]和文献[7]中最好的特征模板和5-fold交叉验证方法进行实验,并对所得的结果做了比较,具体的详见表9。
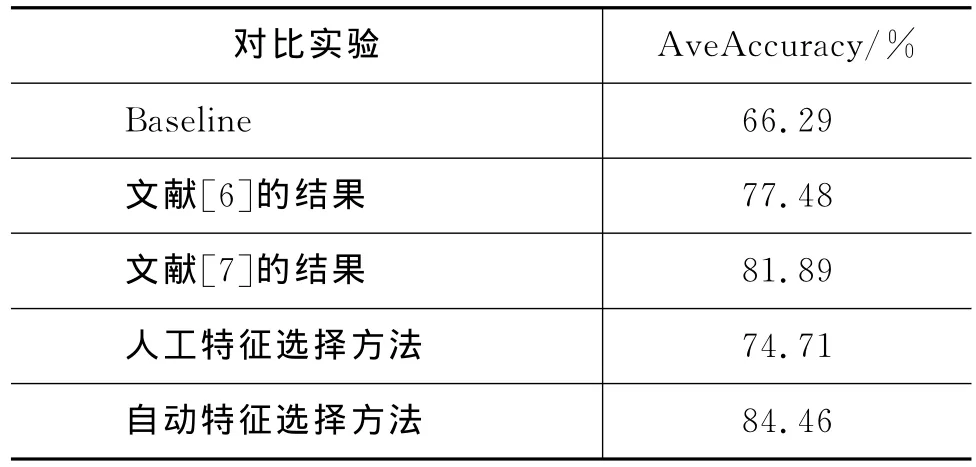
表9 对比实验的结果
从表9中可以看出,使用自动特征选择方法要明显优于其他实验结果。文献[6-7]的结果,比本文采用的人工特征选择方法得到的结果高,一方面,是因为文献[6]中没有加入子节点的词特征和词性特征;另一方面,文献[7]中没有使用4种依存关系类型的子节点作为特征。

表10 基于词法层面(词+词性特征)的实验结果对比
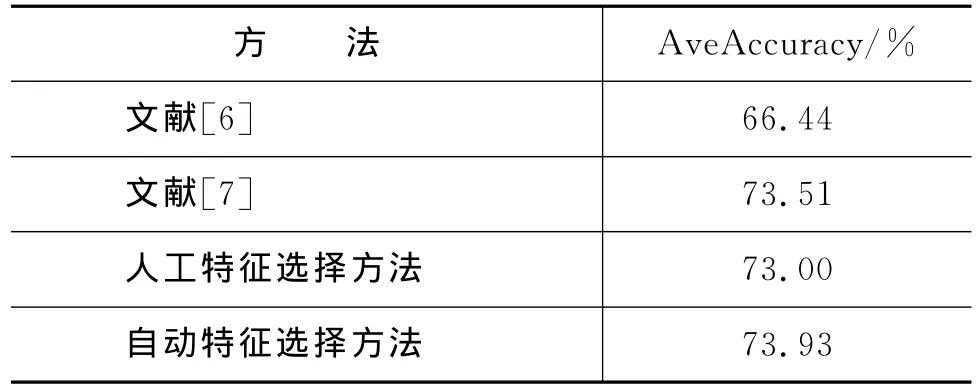
表11 基于句法层面(词法特征+句法特征)的实验结果对比
表10-11列出了本文提出的自动特征选择方法与文献[6和文献[7的方法从词法层面和句法层面的对比结果。可以看出,本文提出的自动特征选择方法无论是从哪个层面,都要优于文献[6]和文献[7]的方法,特别是,在词法层面要优于人工特征选择方法。
5 结论与展望
本文提出了一种使用自动特征选择算法进行汉语框架排歧的方法,该方法克服了人工选择特征的繁琐,使特征模板大大简化,排歧结果有明显的提升。此外,依存特征对汉语框架排歧的性能有很大的作用,特别是,父节点特征的加入,使汉语框架排歧的性能有显著性地提升。
下一步的工作主要集中在以下三个方面。首先,在现有的语料库基础上,通过自动的方法扩建一个更大规模的语料库;其次,在自动特征选择方法的候选特征项中,加入丰富的父节点特征及更多的语义特征,如框架元素和框架间的语义关系;再次,将本文提出的用自动特征选择方法在英文上进行实验,并与中文的结果作对比分析;最后,尝试使用其他机器学习的方法,结合自动特征模板的选择算法进行汉语框架排歧。
[1]李茹.汉语句子框架语义结构分析技术研究[D].山西大学博士学位论文.2012.
[2]郝晓燕,刘伟,李茹,等.汉语框架语义知识库及软件描述体系[J].中文信息学报,2007,21(5):96-100.
[3]Ken Litkowski.CLR:Integration of Frame Net in a Text Representation System[C]//Pr oceedings of the 4th International Workshop on Semantic Evaluations,2007:113-116.
[4]Cos min Adrian Bejan,Hathaway Chris.UTD-SRL:A Pipeline Architecture f or Extracting Frame Semantic Str uctures[C]//Proceedings of the 4t h Inter national Workshop on Semantic Evaluations,2007:460-463.
[5]Richard Johansson,Nugues Pierre.LTH:Semantic Str ucture Extraction using Nonprojective Dependency Trees[C]//Proceedings of the 4th Inter national Wor kshop on Semantic Evaluations 2007227-230.
[6]李济洪,高亚慧,王瑞波,等.汉语框架排歧中的歧义消解[J].中文信息学报,2011,25(3):38-44.
[7]Ru Li,Haijing Liu,Shuanghong Li.Chinese Frame I-dentification using T-CRF Model[C]//Pr oceedings of Inter national Conference on Co mputational Linguistics,2010:674-682.
[8]李涓子,黄昌宁,杨尔弘.一种自组织的汉语词义排歧方法[J].中文信息学报,1998,13(3):1-8.
[9]郑杰,茅于杭,董清富.基于语境的语义排歧方法[J],中文信息学报,2000,14(5):1-7.
[10]刘凤成,黄德根,姜鹏.基于AdaBoost,MH算法的汉语多义词消歧[J].中文信息学报,2006,20(3):6-13.
[11]吴云芳,金澎,郭涛.基于词典属性特征的粗粒度词义消歧[J].中文信息学报,2007,21(2):3-8.
[12]郭宇航,车万翔,刘挺.基于语言模型验证的词义消歧语料获取[J].中文信息学报,2008,22(6):38-42.
[13]陈浩,何婷婷,姬东鸿,等.基于k-means聚类的无导词义消歧[J].中文信息学报,2005,19(4):10-16.
[14]刘冬明,杨尔弘,方莹.汉英双语平行语料库的词义标注[J].中文信息学报,2005,19(6):50-56.
[15]郭宇航,车万翔,刘挺.基于语言模型验证的词义消歧语料获取[J].中文信息学报,2008,22(6):38-42.
[16]何径舟,王厚峰.基于特征选择和最大熵模型的汉语语义消歧[J].软件学报,2010,21(6):1287-1295.
[17]You Liping,Kaiying Liu.Building Chinese Frame Net Database[C]//Proceedings of IEEE NLP-KE'05,2005.
[18]Charles J Fill more.Frame Semantics[C]//Proceedings of Linguistic in t he Mor ning Cal m Hanshin Publishing Company,1982:111-137.
[19]Collin F Baker,Charles J Fill more,John B Lowe.The Ber keley Frame Net Project[C]//Proceedings of the COLING-ACL,1998:86-90.
[20]刘开瑛.汉语框架语义网构建及其应用技术研究[J].中文信息学报,2011,25(6):46-53.
[21]刘开瑛.汉语框架语义网(CFN)构建现状[R].计算语言学2008年青年学生会议大会邀请报告.
[22]刘挺,车万翔,李正华.语言技术平台[J].中文信息学报,2011,25(6):53-61.
[23]由丽萍,范开泰,刘开瑛.汉语语义分析模型研究综述[J].中文信息学报,2005,19(6):57-63.
[24]http://ho mepages.inf.ed.ac.uk/s0450736/maxent toolkit.ht ml.
