基于多FPGA的片上网络模拟平台设计和实现*
2013-07-13梁利平
赵 淳,梁利平
(中国科学院 微电子研究所,北京 100029)
随着应用的发展和芯片制造水平的提高,片上系统单位面积上计算核心的数量呈现出近似指数的增长趋势[1].进入65nm工艺后,片上连线延时的比重迅速上升,甚至超过逻辑延时,这导致基于总线的传统互连结构无法满足复杂系统芯片的设计需求[2].高性能的系统级芯片强调良好的逻辑和物理局部性,以降低芯片的全局连线延时.片上网络(Networks-on-Chip)相对于总线具有良好的伸缩性和能量效率,能够有效地缓解全局连线在深亚微米工艺条件下所引入的延时和功耗等问题,因而被认为是一种适合未来多核系统芯片大规模扩展的片上互连和通信结构[3].
片上网络拥有庞大的设计空间,其研发周期覆盖拓扑结构、路由算法、交换策略、流控制机制、服务质量、通信协议和网络接口等多个方面的设计和实现问题[4].因此如何快速地验证片上网络硬件结构的功能,并准确地评估其性能和实现开销成为设计者面临的严峻挑战.基于FPGA的硬件模拟技术[5-7]相对于典型的软件仿真技术[8-9]具有明显的速度优势,尤其适合大规模片上网络设计空间的深度搜索.
现有的片上网络FPGA模拟平台大多采用片上微处理器,配合专用的硬件功能单元,为目标网络产生模拟环境中所需要的各种流量模型[5].这种方法实现复杂,硬件资源开销较大,且模拟平台的性能往往受到流量模型的制约[6],缺乏设计和移植的灵活性.针对这一点,本文提出并实现了一种基于多FPGA的高性能片上网络模拟平台结构,采用了层次化设计和软件可重构的分布式流量管理器等技术,降低了系统硬件设计的复杂度,减小了流量管理系统与片上网络内核的耦合度,大大提高了片上网络功能验证和性能评估的灵活性.
1 片上网络模拟平台
片上网络模拟平台的系统结构框架如图1所示,包括上位机和基于多FPGA的原型验证引擎两大部分,两者之间可以通过PCIe,Ethernet等接口实现高速的数据交换.模拟平台自顶向下可以划分为系统软件层、软/硬件接口层和硬件结构层3个抽象层次,为结构设计者提供一套完整的多目标、自动化片上网络功能验证和性能评估环境.

图1 片上网络模拟平台结构框架Fig.1 NoC emulation platform framework
硬件结构层主要包括多片多种形式互连(普通单端、LVDS和千兆级高速串行总线等)的大容量FPGA芯片,为系统中的硬件功能单元提供充足的实现空间.完整的片上网络硬件原型包括网络内核、片间网络接口、分布式片上流量管理器和中央控制器等模块.用户可以通过每颗FPGA芯片上实现的中央控制器,利用系统应用层的软件服务,直接对流量管理器进行读/写操作,完成对其功能的软重构.软/硬件接口层由设备(PCIe、Ethernet)驱动程序构成,为上层软件提供了一组可扩展的专用API,将上层的软件服务映射为对底层硬件的访问操作,保证系统软件层和硬件结构层之间的正确交互.系统应用层包括在上位机运行的基于高级语言(SystemC)的仿真引擎[10]和基于脚本语言的控制引擎.其中仿真引擎用于产生下载到流量管理器的模型信息,以及分析处理由流量管理器读回的统计信息;控制引擎则用于控制整个模拟流程,协调和管理各部分系统应用软件功能,以及发起和终止用户对底层硬件的访问操作等.
2 流量管理器软/硬件实现
在片上网络的功能验证和性能评估过程中,流量的产生、收集和分析处理一直都是设计者所面临的最棘手的问题.如何设计结构简单,灵活度高的片上流量管理器,以实现对片上网络全面的功能覆盖和大范围的设计空间搜索,成为整个模拟平台的设计重点和难点.为了提高平台的效率和灵活性,避免网表文件的反复生成和下载,本文设计了软件可重构的分布式片上流量管理器,通过软件配置和控制指令解析的方式为片上网络提供丰富的流量模型.
2.1 流量管理器和中央控制器
流量管理器作为片上网络的终端功能单元,模拟实际系统中的计算资源节点,按照一定的时间和空间分布规律产生并向网络注入数据,同时接收并校验由其他终端发往本地的数据.流量管理器包括两组单向的总线接口.其中用户接口用于连接片上网络中央控制器,为用户提供“控制指令”的下载和“状态数据”回传服务,接口满足简单的存储器读写规范.系统接口用于连接路由节点,接口满足片上网络物理链路的通信规范.每个路由节点可以根据其空闲物理链路的数量连接一个或多个流量管理器.流量管理器内部用于存储控制指令和状态数据的存储空间被线性地映射到64位地址所覆盖的空间范围内,允许系统软件层以直接映射的方式对其进行访问.整个硬件系统结构如图2所示.
流量管理器发送和接收通道的结构如图3所示,其结构划分为发送通道和接收通道,分别处理网络通信事务的发送和接收.其中发送通道由一块用户只写、网络只读的指令存储器和一个发送控制状态机构成.指令存储器的每一项存储一条流量控制指令,对应一项网络发送事务,其内容由目标地址、事务类型、负载长度、事务编号、发送时间等字段构成.发送控制状态机每次从指令存储器中读出一条流量控制指令,对其进行解析并完成一个完整网络数据包的重建,同时在其结尾添加校验信息,在流控机制的约束下,将数据包有序地注入到片上网络中.接收通道由一块用户只读、网络只写的数据存储器和一个接收控制状态机构成.当流量管理器接收到一个来自其他终端的网络数据包时,接收控制状态机首先对整个数据包的内容进行解析和校验,从中还原出其基本控制信息如源地址、事务类型、负载长度和事务编号等,并记录下其到达时间,然后将这些信息合并为一项状态数据存储到接收通道内的数据存储器中,供系统软件层读取.

图2 硬件系统结构框图Fig.2 Block diagram of hardware system architecture
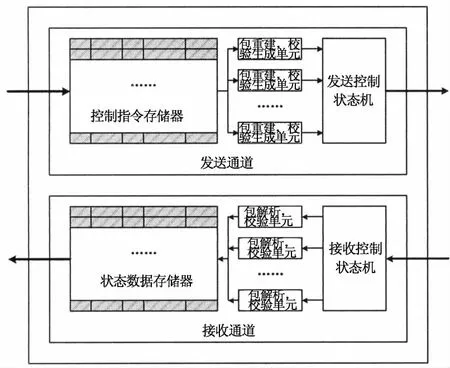
图3 流量管理器结构框图Fig.3 Block diagram of traffic manager architecture
中央控制器为流量管理器提供通用的总线访问接口,用于对其内部存储资源的读/写访问,从而实现系统软件层对底层硬件的控制和观测.中央控制器本质上是一个总线译码单元,通过对输入地址总线的三级译码选择其所要访问的片上存储空间.相对于其他平台实现中的微处理器[5-6],中央控制器的资源开销只有不足其1/10,不仅功能简单易于实现,同时减小了硬件的开销.
2.2 系统软件服务
模拟平台的系统软件层为用户提供了大量抽象的参数配置和控制接口,大大提高了系统的效率和灵活性,避免了硬件代码的反复修改,使平台可以一次性地完成对目标平台的验证和评估.系统软件层中的仿真引擎可以自动地为系统中每个流量管理器产生一定约束条件下的流量控制指令序列,并通过控制引擎将其下载到相应的指令存储器中;同时,控制引擎也可以将保存在流量管理器内部的状态数据读回给仿真引擎,供其快速地考察片上网络在不同流量模式下的性能指标.
仿真引擎采用SystemC事务级建模(TLM)的方法实现,其核心是一套参数化的片上网络软件仿真程序,同时具备周期精确的仿真粒度和较快的仿真速度等特点.模拟平台利用仿真引擎构造一个和硬件平台结构相同的软件仿真框架,但这个框架只为每个流量管理器产生单独的网络通信事务队列,并不进行实际的软件仿真.通信事务队列的数据结构与流量管理器中指令存储器的存储结构一致,以二进制文件的形式保存在上位机的文件系统中,由控制引擎将其下载到相应的流量管理器中.用户可以调整流量模型参数,不断地产生新的二进制文件,从而改变片上网络流量的通信特点,以获得全面的性能统计信息.仿真引擎内嵌了性能分析模块,可以处理从流量管理器中读回的状态数据文件.性能分析模块根据状态数据文件和先前产生的控制指令序列文件,精确匹配每一组通信流量,计算其延时,从而得到整个网络的平均延时和吞吐性能.
控制引擎采用脚本语言实现,主要用于模拟流程中各软件模块的控制.模拟流程中的每一步操作都由控制引擎直接发起,通过调用相应的应用程序驱动整个流程向下进行.直接受控制引擎调度的程序包括FPGA综合和后端实现工具、仿真引擎和软/硬件接口API等.
2.3 基于流量管理的系统模拟流程
片上网络模拟流程分为结构定义和设计空间搜索2个阶段,共7个步骤,由系统软件层中的控制引擎进行集中控制和调度.控制引擎对已有的可执行程序进行高效地集成和封装,使整个模拟流程无须用户干预,自动地完成流程中的所有步骤.
片上网络的模拟流程如图4所示.其中第1步和第2步为结构定义阶段.在这个阶段里,控制引擎首先根据用户设定的结构参数,从结构单元库中实例化基本结构单元,快速构建目标片上网络平台,并调用FPGA开发工具,生成可直接下载的FPGA网表,通过软/硬件接口服务程序,将网表下载到验证板的FPGA芯片上.第3步到第7步为设计空间搜索阶段,这一阶段往往要进行多次循环迭代,以考察片上网络在各种流量模型下的通信状况和性能指标.在一次迭代过程里,控制引擎首先根据用户设定的流量模型参数,调用仿真引擎,为每个流量管理器产生流量控制指令文件,随后通过软/硬件接口服务程序,将其下载到对应流量管理器的指令存储器中.当全部文件下载结束后,控制引擎向底层硬件发送一个启动命令,片上网络进入正常工作状态.系统中全部的流量到达其目标后,控制引擎向底层硬件发送一个暂停命令,并调用软/硬件接口服务程序,将每个流量控制器数据存储器中的状态数据读回上位机,并保存在文件系统中.最后,控制引擎调用仿真引擎,对接收到的数据文件进行分析处理,得到本次迭代的平均通信延时和吞吐率等性能参数.
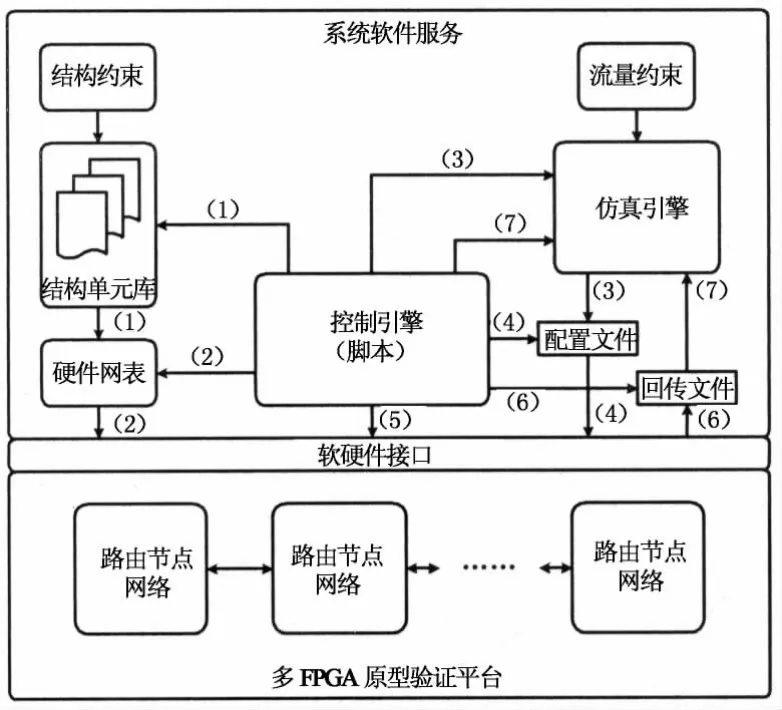
图4 片上网络模拟流程Fig.4 Emulation flow of NoC emulation
3 实验结果分析
本文提出的片上网络模拟平台采用通用PC和DINI公司的 DN-DualV6-PCIe-4原型验证引擎共同构建实现.其中,验证引擎既可以通过PCIe接口插放在PC机的主板上,也可以在作为Ethernet终端供局域网内的其他PC进行访问.模拟过程中的全部软硬件交互均通过PCIe或Ethernet实现.引擎上包括两个大容量的FPGA芯片(Xilinx XC6VSX475T)并通过千兆级高速串行总线互连,为片上网络提供基本的硬件实现空间.
实验中的路由节点模块采用了六端口虫孔交换虚通道路由器,二维Mesh拓扑结构下可以连接2个流量管理器.每个输入端口包括4条虚通道,每条虚通道的深度为8个微片(flit),采用两级轮转优先的仲裁机制进行虚通道分配和交换分配.片间网络接口支持RapidIO高速串行通信,饱和通信带宽可达10Gbps.每个FPGA芯片上实现一个4×4的Mesh片上网络,网络内核的时钟频率可以达到100 MHz.
文献[6]提出的片上网络FPGA模拟平台AcENoCs在模拟速度上受到目标网络的规模和流量注入率的制约,使其在设计空间搜索的深度和广度上具有一定的局限性.本文所提出的模拟平台不受流量注入模型的约束,且受网络规模的影响很小,在6×6的Mesh网络下主频仍可达到80MHz,这使模拟平台的工作效率得到显著提高.图5为2种平台在模拟速度上的对比结果,均采用2×2的Mesh网络实现.由图5可知,本文实现的平台结构工作在较低主频条件下,在性能上仍然具有较大优势.在目标网络规模增大和流量注入率升高时,这种优势体现得更加明显.
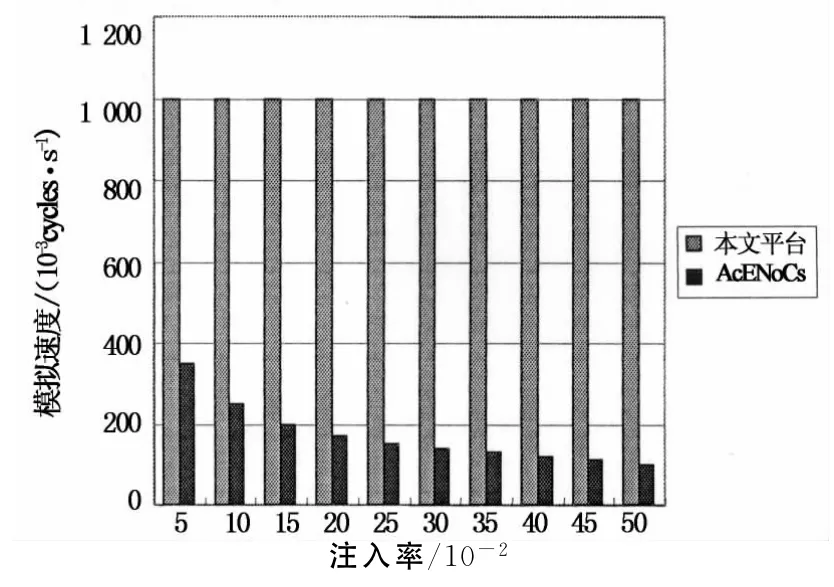
图5 模拟平台性能对比Fig.5 Performance comparison between the platform and AcENoCs[6]
表1反映了目标片上网络在相同配置条件下,分别使用模拟平台,高级语言仿真器和RTL仿真进行设计空间搜索的时间开销.从表中可以看出,模拟平台与基于SystemC语言的仿真器相比,速度提高了近500倍,与基于Verilog的RTL仿真相比,速度提高了10 000倍以上.

表1 片上网络模拟-仿真性能对比表Tab.1 Performance comparison between NoC emulation and simulation
图6为片上网络各部分硬件资源所占的比例.从图中可以看出,片上网络内核占据了硬件系统的绝大部分资源开销,流量管理器,中央控制器等辅助功能模块的硬件开销则相对较小,这符合模拟平台的设计原则,以较小的实现代价换取了系统的灵活性,同时最大限度地提高了硬件系统的可控制性和可观测性.

图6 4×4片上网络各部分资源分布Fig.6 Resource utilization of a 4×4NoC emulation
图7为uniform流量下,不同负载长度的流量对片上网络平均延时性能的影响.当流量的有效负载长度增大时,网络的饱和注入率略有降低,网络负载的平均延时显著增大.这是由于随着负载注入率的升高,较长负载的数据包对网络的阻塞更加敏感,从而导致其排队延时的急剧增大,此外,长负载本身的串行延时也是导致平均延时增大的因素之一.
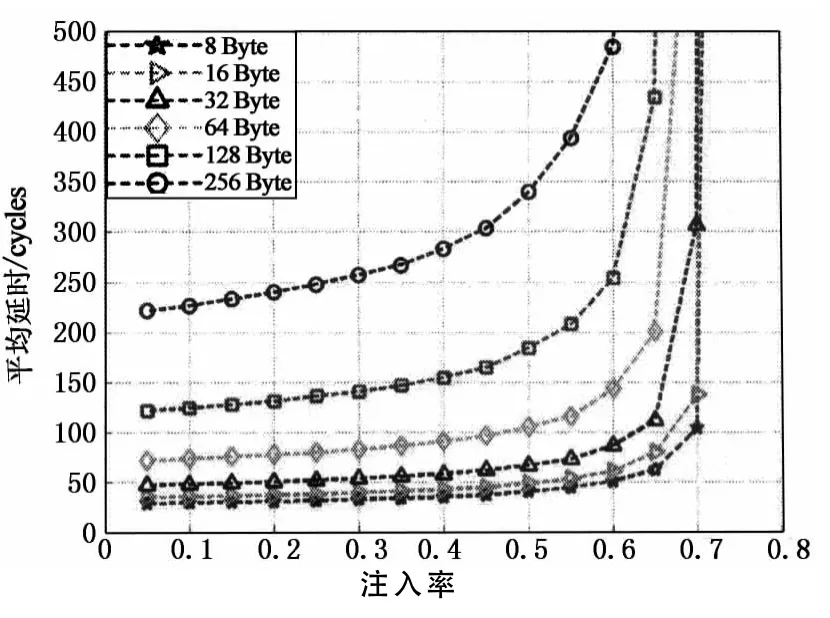
图7 平均延时随负载长度变化特性Fig.7 Average packet delay divided by packet length versus normalized accepted traffic for uniform traffic
4 结 论
本文提出了一种基于多FPGA的高性能片上网络模拟平台,用于解决大规模片上网络设计空间搜索的效率问题.模拟平台通过对分布式片上流量管理器的软件重构为目标网络提供丰富的流量模型,避免硬件代码的反复修改和下载,大大缩短了验证和调试周期.该平台不依赖于网络的规模和具体实现,可以完成对多种结构参数下片上网络的功能验证和性能评估.实验结果表明,该平台硬件开销小,灵活性高,可以快速、准确地给出网络的性能指标.与同类型的FPGA模拟平台相比,该平台不受流量模型的制约,大大提高了整个系统的模拟性能.与基于软件的仿真相比,该平台具有500~10 000倍的加速,能够高效率地实现片上网络设计空间的深度搜索.
[1]GEER D.Chip makers turn to multicore processors[J].IEEE Computer,2005,38(5):11-13.
[2]PULLINI A,ANGIOLINI F,MURALI S,etal.Bringing NoCs to 65nm[J].IEEE Micro,2007,27(5):75-85.
[3]DALLY W J,TOWLES B.Route packets,not wires:on-chip interconnection networks[C]//Design Automation Conference.Las Vegas:IEEE Press,2001:684-689.
[4]MARCULESCU R,OGRAS U Y,PEH L S,etal.Outstanding research problems in NoC design:system,microarchitecture,and circuit perspectives[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2009,28(1):3-21.
[5]GENKO N,ATIENZA D,DE-MICHELI G,etal.NoC emulation:a tool and design flow for MPSoC[J].IEEE Circuits and Systems Magazine,2007,7(4):42-51.
[6]LOTLIKAR S,PAI V,GRATZ P V.AcENoCs:a configurable HW/SW platform for FPGA accelerated NoC emulation[C]//24th International Conference on VLSI Design.Madras:IEEE Press,2011:147-152.
[7]WANG Dan-yao,JERGER N E,STEFFAN J G.DART:a programmable architecture for NoC simulation on FPGAs[C]//Fifth IEEE/ACM International Symposium on Networks on Chip.Pittsburgh:IEEE Press,2011:145-152.
[8]REN Peng-ju,LIS M,MYONG H C,etal.HORNET:a cycle-level multicore simulator[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2012,31(6):890-903.
[9]BEN-ITZHAK Y,ZAHAVI E,CIDON I,etal.NoCs simulation framework for OMNeT++[C]//Fifth IEEE/ACM International Symposium on Networks on Chip.Pittsburgh:IEEE Press,2011:265-266.
[10]李烨挺,梁利平.一种基于SystemC的片上网络建模与仿真方法[J].微电子学与计算机,2010,27(3):78-82.LI Ye-ting,LIANG Li-ping.An NoC modeling and simulating method with systemC[J].Microelectronics & Computer,2010,27(3):78-82.(In Chinese)
