水书键盘输入系统研究与实现
2013-04-23陈笑蓉杨撼岳郑高山
陈笑蓉,杨撼岳,郑高山,黄 千
(贵州大学 计算机科学与信息学院,贵州 贵阳 550025)
1 引言
水族是中华民族大家庭中的一员,其90%以上的人口聚居在贵州省,少量散居于广西壮族自治区、云南省等地[1]。水族有着自己的语言和文字,水族文字被称为水书。目前研究发现并能识读的有500多个单字(不含异体字,包括异体字有2 000多个字),其形状类似于甲骨文和金文,主要用来记载水族的天文、地理、宗教、民俗、伦理、哲学等文化信息。
为抢救保护珍贵的水书文化遗产,2006年,国务院正式批准“水书习俗”为国家级首批非物质文化遗产名录。2002年,经“中国文献遗产工程国家咨询委员会”评定,水书入选《中国档案文献遗产名录》,成为国家档案馆重点收藏的民族古籍。水书作为珍贵的民族文化遗产受到中央政府和有关单位的高度关注。
为了更有效地抢救保护与利用水书,水族文字的信息化处理成为当前亟待解决的问题。
2 水书的特征信息及其输入模型
水字所负载的特征信息可分为三类: 字形类特征信息;字音类特征信息;字义类特征信息[2]。本文仅讨论水书字形类特征信息。此外,还有字熵等作为宏观统计特征。
2.1 水书字形类特征信息
由于水族文字没有形成统一、标准、规范的字体,本文以《水书常用字典》收录的水字为蓝本,对水书字形进行分析和讨论。
2.1.1 水书笔画特征信息
下笔后按一定方向连续画成的每一笔,就叫作“笔画”[3]。本文分析了《水书常用字典》收录的水字,去粗取精,得到水字7种基本笔画(表1): 横;竖;撇;捺;点(实心圆点);折(两笔相接成角);曲(一笔连续写成的、复杂的曲线)。按其方向区分,横、竖、撇、捺、点为单向笔画,折、曲为复向笔画。

表1 水字的7种基本笔画
水字笔画之间的组合关系大致可分离散、连接、交叉、包围结构(表2)。
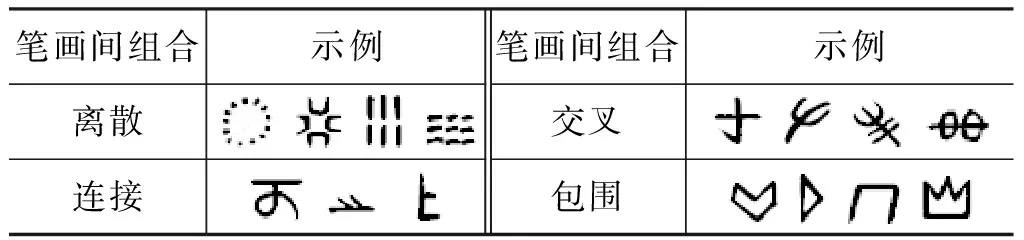
表2 水字笔画间的组合关系
2.1.2 水书字根特征信息
字根(部件)是组配水字的构字单元,通过笔画相互间 “单、散、连、交”式的关系组成。它可分为两类: 成字字根和非成字字根。例如,“”;“”为成字字根;排除成字字根外, 7种基本笔画及它们之间的组合关系都可为非成字字根。
字根可以根据设计需要,按照一定标准,决定选择个数。水字字根集确定后,在其中挑选有限个字根,可以拼成某一个水字(图1)。
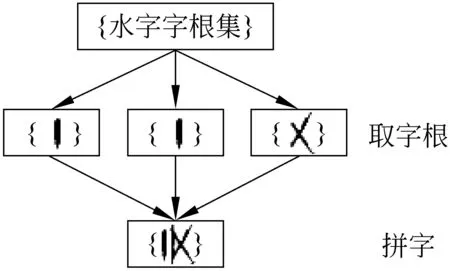
图1 字根拼字的过程
2.2 水书键盘输入模型
2.2.1 定义
1) 水字集S:S={si|i=1,2,…,n}。式中si为水字,n是该集中水字的总数。
2) 编码特征信息元集(码元集)T:T={ti|i=1,2,…,m}。式中ti为特征信息元(码元),m是特征信息元的总数。T集的构造应易于使用者从字形、字音中提取限定的持征信息,且其编码序列能覆盖水字集S。
3) 特征信息元编码集V:V={vi|i=1,2,…,p},vi=ta1ta2…tal,taj∈T(j=1,2,…,l)。l为组成编码的码元个数,vi为水字的特征信息编码。
4) 键元集K(用作输入的键盘上键元的集合):K={ki|i=1,2,…,q}。q用作输入特征信息元的键元的总数。
5) 键元编码集E(与特征信息元编码对应的键元编码的集合):E={ei|i=1,2,…,w},ei=ka1ka2…kal,kaj∈K(j=1,2,…,l)。w为该集的大小,l为组成编码的键元个数,ei为水字输入的键元编码。
6) 重码集R:R={ei|i=1,2,…,w1},R⊂E。w1为重码的总数。
7) 水字内部码集M:M={mi|i=1,2,…,n}。M集与S集元素为一一对应关系,因此集的大小均为n。
8) 映射(函数)
设X和Y是任意两个集合,而f是X到Y的一个关系,如果对于每一个x∈X,有唯一的y∈Y,使得〈x,y〉∈f,称关系f为X到Y的映射或函数。记作f: X→Y。
9) 复合映射
映射f:X→Y,g:Y→Z。
若g∘f={〈x,z〉|x∈X∧z∈Z∧(∃y)(y∈Y∧y=f(x)∧z=g(y))},则称g∘f为复合函数。
2.2.2 重码
重码是两个或两个以上表意字符相同的输入编码,存在两种类型的重码[2]。
1) 编码规则重码
编码规则是水字集S到特征信息元编码集V的一个映射,记为f:S→V。为了易学和减轻编码过程中的脑力负担,编码码长被限长,从而产生规则性重码,即存在若干关系〈va,si〉,i=1,2,…,l(水字不同而键元编码相同)。
例: 以笔形特征信息的输入方法

f() =,,;f() =,,
2) 归并重码
由于将若干个特征信息元归并到一个键元输入所引起的重码称为归并重码。
例: 以笔形特征信息的输入方法

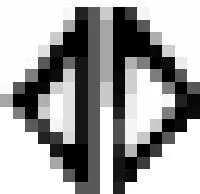
f1() =,,f2(,) = AA,即f2∘f1() = AA。
2.2.3 输入法数学模型
由于键盘的键位数量有限,又因编码规则的简明,重码是不可避免的。最简单的处理重码的方法是通过屏幕提示人工选择重码字,因此水字键盘输入方法的数学模型可为式(1)所示:
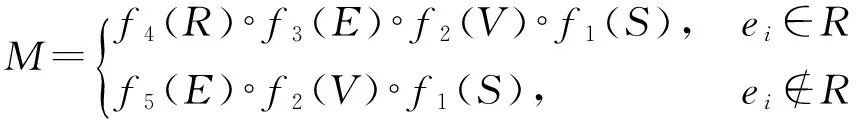
(1)
式中S为水字集,V为特征信息元编码集,E为键元编码集,R为重码集,M为水字内部码集。f1:S→V,f2:V→E,f3:E→R,f4:R→M,f5:E→M。
2.2.4 一一映射编码输入法(Unicode输入法)
Unicode输入法是微软公司提供的一款没有重码的输入法,即一一映射输入法。它将每个字符的十进制内码值映射到十六进制数值。在Unicode输入法状态下,键入十六进制数值,相对应的字符被录入计算机。其编码特征信息元集T和键元集K为T= {0,1,2,3,4,5,6,7,8,9};K= {0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f}。
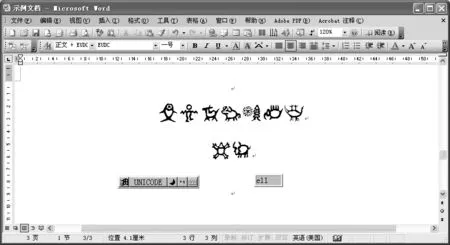
图2 Unicode输入法在Word 2003中输入水字
3 水书输入系统设计
3.1 水字字库建立
3.1.1 水字字符集编码设计
水族文字信息化的一个重要意义在于能让不同环境下的操作系统识别。而水字字符目前在Unicode中还没有被分配的码位。本文的编码方案必须采用Unicode方案,才能保证水字与其他语种文字的混排,保证在不同的操作系统中正常显示,不出现乱码。只有这样做出来的课题,才能得到全世界水书研究者和爱好者的认可。
鉴于申请Unicode编码的长期性和复杂性,本文将467个水字字符临时放入Unicode的Private user(私用码位区)当中的E000-E1D3码位。
3.1.2 水字字库制作
本文所用字稿为《水书常用字典》,它录选常用字468个。本文剔除1个重复字,得到不重复字467个[3]。
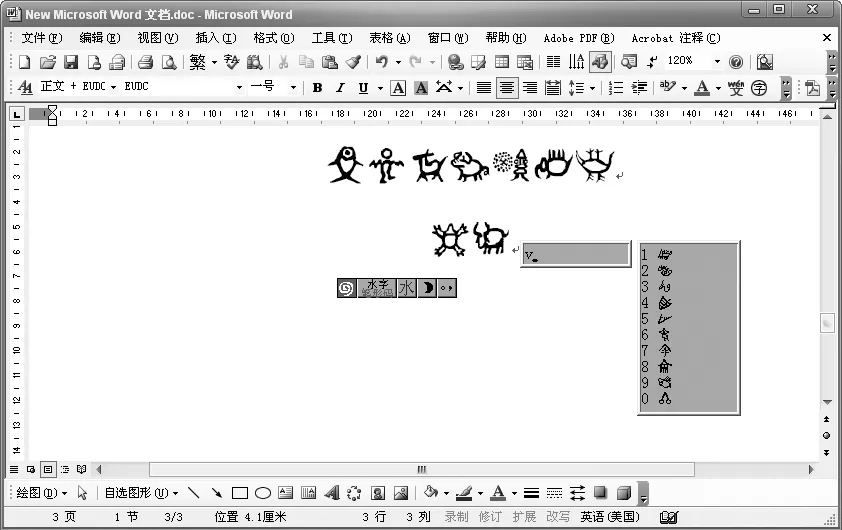
字库建立流程: 1. 利用扫描仪扫描字稿;2. 利用图像处理软件制作字模;3. 在字库制作软件中导入水字模图象;4. 在字库制作软件中,按照实际需求进行修字。制作完成的水字TrueType字库截图,如图3所示。
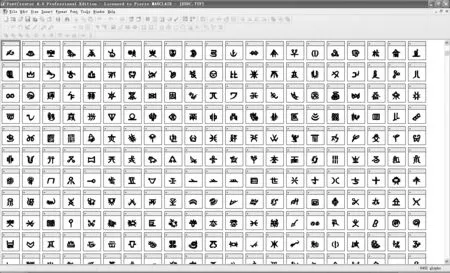
图3 水字TrueType字库的部分水字
3.2 输入编码设计
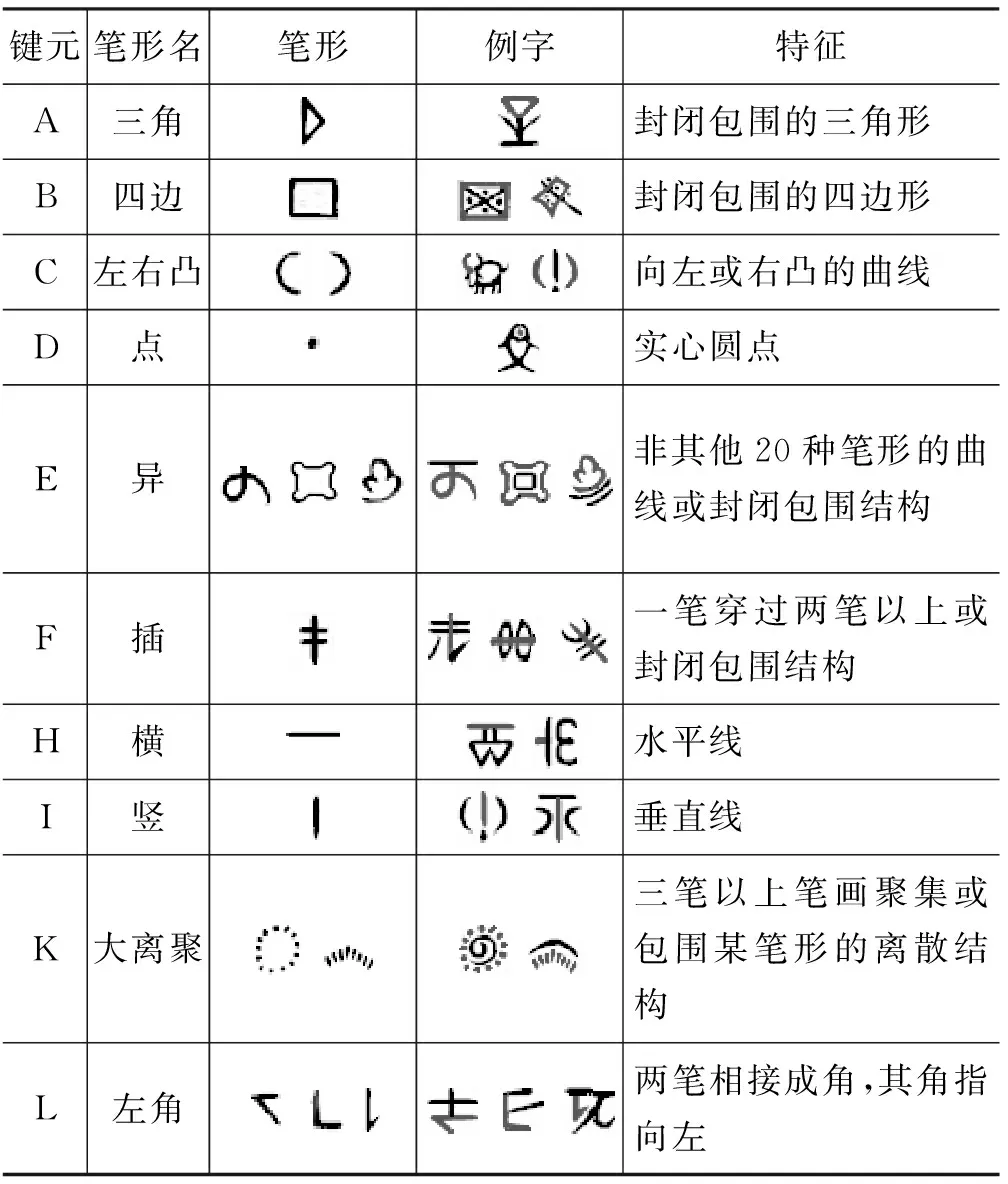
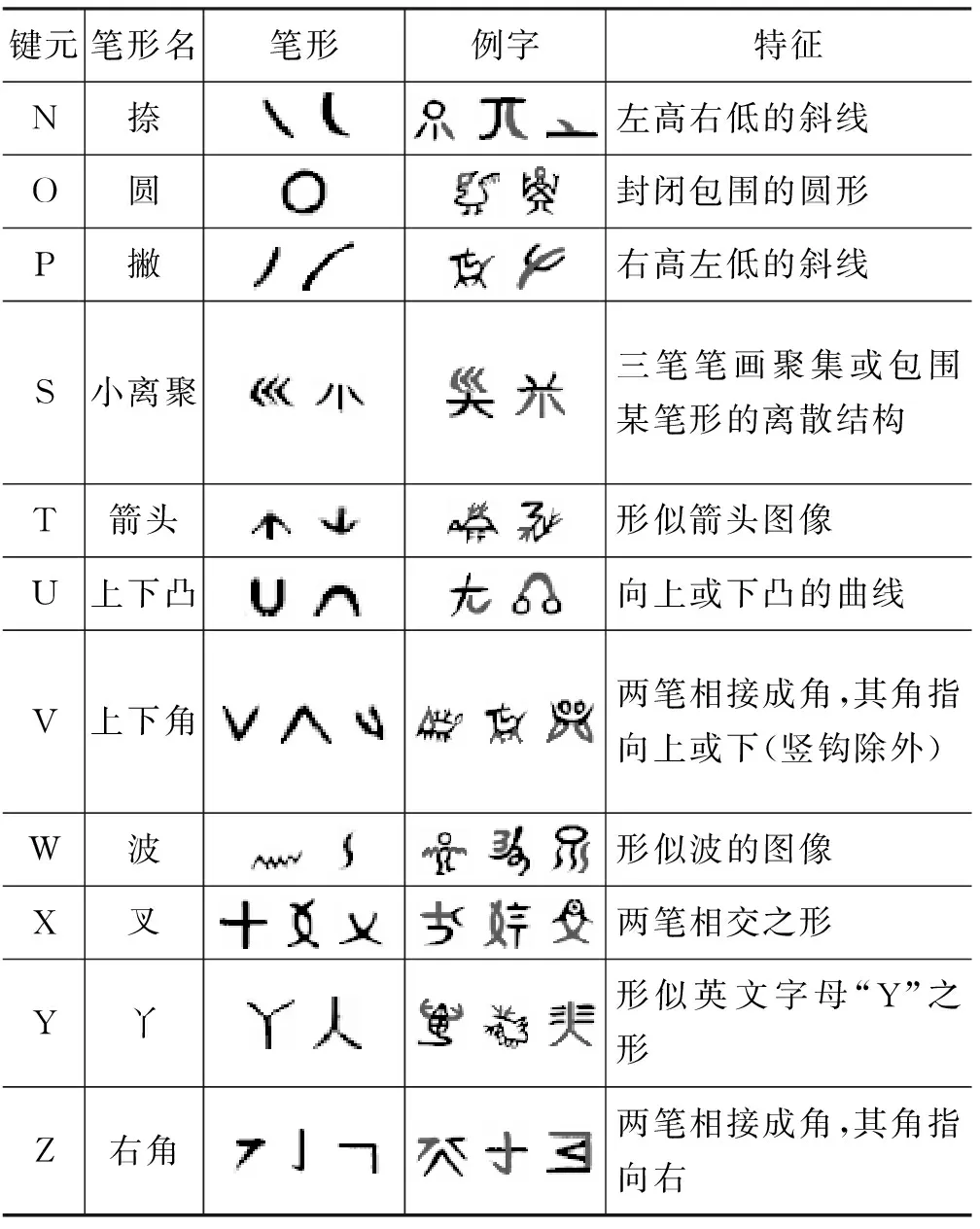
3.2.1 特征信息元集(码元集)的构造
本输入法的设计目标是向会写不会读的用户,提供一个易学、易用的水字输入系统。因此水字的特征信息元在字形中挖掘,采用拼形方法。
构成字形的最小结构单元是笔画,笔画不仅简单而且在理解上相对容易形成共识。水字笔形的种类(包括基本笔画及其组合关系)远比水字字根的数量少,故相对字根而言,记忆量小。此外,水字字集中含有20%左右的图画文字,如果采用传统的字根特征信息编码方法,对复杂的图画文字编码是相当困难的。故本方案采用笔形特征信息为每个水字编码。
大量实验和统计的基础上,将7种基本笔画按几何图形特征,细分或重组成21种笔画(表3)。“曲笔”被细分为圆形、上下凸形、左右凸形、波形等;“折”笔被细分为上下角、左和右角。在笔画归类时,倾斜的凸形容易引起歧义,于是规定倾角小于45度归于“上下凸”,大于45度归于“左右凸”。通过实验发现,如果把“左角”和“右角”归为一类,重码字数提高了19%,故将它们细分为两类笔形;而“上下凸”、“左右凸”和“上下角”按上下、左右方向细分后,重码字数减少了2%~4%,对重码的影响不大,因此不再对它们按方向细分。
构成输入编码的笔画序列方式主要有两种,笔顺方式和取角方式[2]。本编码方案采用取角方式,取一个水字3个角的笔形,组成一个有序序列表示该水字。水字“取角”最主要的优点是可以避开图画文字中间复杂的图形;不利是重码略微增加。
3.2.2 键盘上特征信息元的分布
特征信息元分布于键位的方式主要有三种,音托法、形托法和笔画结构分区法[2]。例如,在汉字字根输入中将汉字字根的声母发音依托于键元的字母读音,此法是音托法;以字根的形状为依托对应于形似的字母键位上,是形托法;五笔、郑码输入法采用以笔画结构的组合方式按键盘的位置分区,即笔画结构分区法。
本输入法采用“形托”为主“音托”为辅的方式,将13类笔形分布在其形似的字母键位,5类笔形对应于其发音相似的字母键位,3类笔形安排在键盘中排易于敲击的键位(表3)。
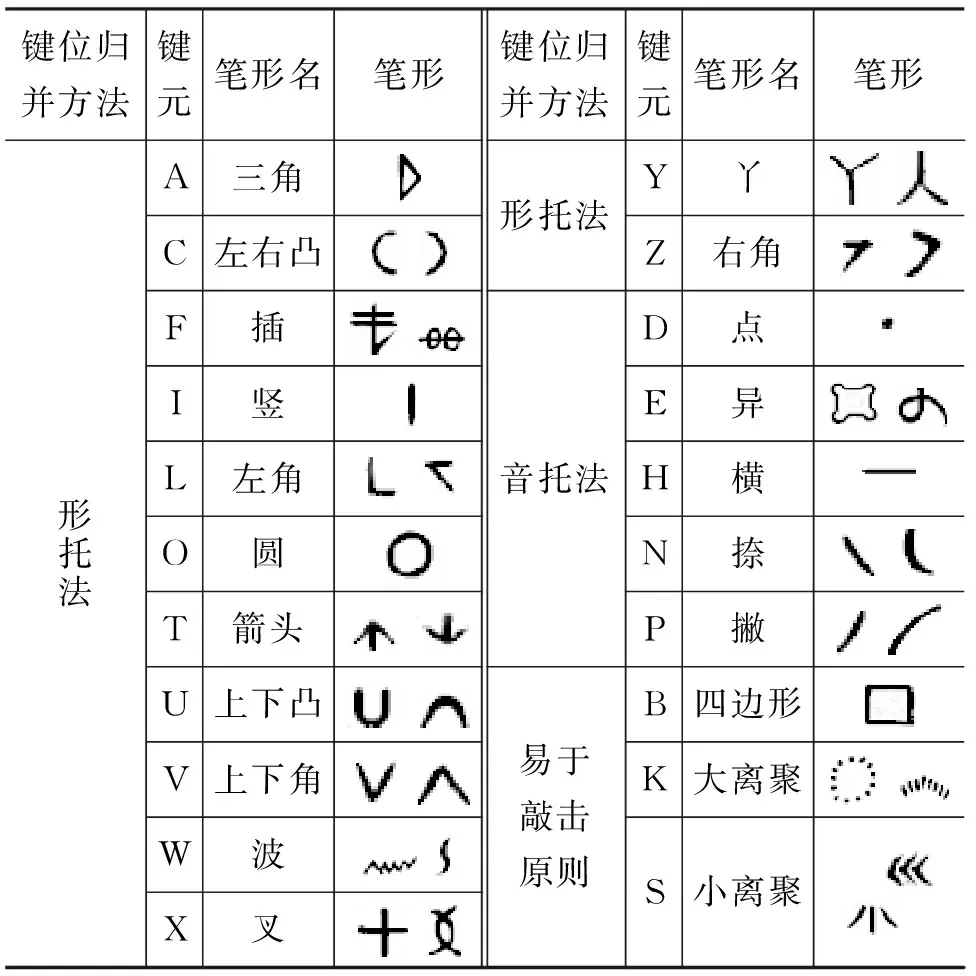
表3 键位分布表
3.2.3 码长设计
方块字的特征信息元所依托键位的集合是编码键元集,输入一个方块字所需的击键次数称之为码长。以键元数(a)为底,取码长(l)的乘方(al)称之为编码空间,它的值代表了在限定的键元集和码长下,可容纳输入编码的数量[2]。
如何设计码长呢?限定键元数为21,字符集的数量是467时,我们令码长为2、3和4,则它们的编码空间分别是441(212)、9 261(213)和194 481(214)。码长为2时的编码空间(441)小于字符集的数量(467),意味该空间不能容纳整个水字字符集。码长为3、4的编码空间均大于467,因此理论上最大码长取3或4都是可行的。
我们假设编码是随机的(没有编码规则)。在总数为n的编码空间中,为m个水字编码(m 对于非随机性有确定编码规则的输入系统,则字符集重码概率如式(3): 式中R由编码规则决定,称为人工干预因子[2]。 当码长等于3或4时,它们的字符集重码概率分别是 从“低重码”的角度来考虑,码长取4最理想。但是重码只是输入编码方案设计的一个侧面,输入效率也是要考虑的重要因素。码长取3时,字符集重码概率为0.02R,其重码的量级也是相当低的,故本方案设计最大编码码长为3。 3.3.1 键元集和码长 本输入法共用了21个字母键,采用不等长码,最长编码为3码。 3.3.2 笔形和键元的对应关系 表4是笔形和键元的对应关系。 表4 输入法键位分布表 续表 3.3.3 编码输入方法 对水字进行编码时,根据表中的笔形,按照左上角、右上角、左下角、右下角的取角顺序取三码。 1) 若四个角均有笔形,则取前三个角的笔形。 2) 若四个角中有一个笔形占两个角,则这两个角的笔形只取其一。 5) 按实有笔形取码,最少一码,最多三码。 3.3.4 取码注意点 1) 含插、叉笔形的字,如该字不足三码,用插入的一笔笔形和和被插入的笔形补充(叉形中,自上而下的单向笔画是插入的一笔),不得超过最大码长三码。 2) 含“小离聚"或“大聚集”笔形的字,如该字不足三码,按取角顺序取构成离聚的笔画补充,不得超过最大码长三码。若构成离聚的笔画全部相同,则只须补其中一笔。 6) 有两复笔形可取时,上角较高笔形优先取,下角较低笔形优先取。例如,“”右上角应取复笔“叉”(X),而不取“右角”(Z)。 在远东Windows系统下,输入法的开发主要是根据Microsoft提供的IMM-IME结构,在它的框架内为系统各个部分编写代码,实现相应的功能。 为了方便技术人员开发Windows的驱动程序,微软公司为开发人员提供了一套用于开发Windows驱动程序的工具包DDK,利用它就可以开发输入法。此外,工具包DDK还提供了相关文档以及一个区位输入法的实例代码。DDK中的区位输入法的代码,为设计其他的输入法提供了基础,因此设计新的输入法主要就是在这个区位输入法的代码基础上进行修改,这样可以大大节省开发时间。 本文在Windows XP操作系统下,Microsoft Visual C++ 6.0中,使用Unicode字符编码标准作为输入法内部的编码标准,利用区位输入法源代码成功地开发出了水书笔形输入法软件。通过该输入系统可以把《水书常用字典》收录的467个水字中任一字输入计算机中。图4是水书笔形输入法在Word 2003中输入水字的示例。 图4 水书笔形输入法在Word 2003中输入水字 水书笔形输入法软件主要由IME转换接口和IME用户接口两个部分组成。IME转换接口是由用户实现的一组接口函数,这些函数将由输入法管理器在适当的时机调用,实现从用户的输入编码到水书字符的转换等功能。IME用户接口主要的作用是接收各种消息以及通过各种窗口的显示,让用户随时了解输入法的当前状态,为IME提供用户接口界面。其组成部分包括缺省的IME窗口、用户界面窗口、用户界面组件窗口,编码窗口、状态窗口、候选窗口等。输入法的整体架构如图5所示。 图5 水书笔形输入法的组成 1) 缺省的IME窗口[4] 当一个应用程序线程初始化时,Windows会基于IME窗口类为其创建一个缺省的IME窗口。它管理输入法编辑器的用户界面,处理从IME、IMM和应用程序之间传递的所有消息。应用程序的所有输入法将共享这个缺省的IME窗口。 2) 用户界面窗口[4] UI窗口是IME窗口的一个子窗口,是水书笔形输入法的总控窗口。当IME窗口被创建的同时,IME自身的UI窗口也被创建,并被IME窗口所控制。用户界面窗口对用户也是不可见的,它负责接收由IMM和应用程序传来的消息,并根据消息的内容做出响应。 3) 用户界面窗口组件包括状态窗口、编码输入窗口和字符选择窗口等[4],它们对用户是可见的。所有的组件窗口由用户界面窗口创建并拥有。 (1) 水书笔形输入法的状态窗口。该窗口的出现意味该输入法系统已经启动,可以使用此输入方法输入水书字符。通过状态窗口,可以调整输入的状态,例如,水书、英文状态、半角或全角、中文或英文标点符号等,如图6所示。 图6 水书笔形输入法的状态窗口 (2) 水书笔形输入法的输入窗口。用于显示输入英文字符串,如图7所示。 图7 水书笔形输入法的输入窗口 (3) 水书笔形输入法的候选窗口。用于显示输入编码英文字符串映射的水字的候选列表,用户可以按相应的数字键来选择需要的水字。所有重码不可能一次全部显示,部分需要翻页才能够显示,可以按“-”“,”键或“=”“.”键实现向前、向后翻页。如图8所示。 图8 水书笔形输入法的候选窗口 从输入法菜单中选择水书笔形输入法后(图9),输入系统从码表文件中读入编码和其对应的水字。并分别用一个表结构来保存编码和水字。当从键盘输入英文字符串时,输入法程序可以根据该表结构迅速地进行查找和处理,实现水字的输入。系统工作流程图如图10所示。 图9 从输入法菜单中选择水书笔形输入法 图10 水字笔形输入系统流程图 本文制作的TrueType水字轮廓字体美观、可任意缩放、与设备无关。字库编码采用Unicode方案,从而保证水字与其他语种文字的混排和在不同的操作系统中正常显示。水字笔形输入法的笔画的种类远比水字字根的数量少,故记忆量小,而且避开了如何去定义“字根”的困难,因此该输入法易学、易用。本文的研究为推广和普及规范水族文字奠定了技术基础,对推动水族文字信息化的发展起到了积极的作用。 致谢: 作者衷心感谢贵州省三都水族自治县水族文化研究所的潘兴文、潘政波和韦世方提供了水字字形资料。 [1] 潘朝霖,韦宗林.中国水族文化研究[M].贵阳:贵州人民出版社.2004. [2] 陈一凡,胡宣华.汉字键盘输入技术与理论基础[M].北京:清华大学出版社,南宁: 广西科学技术出版社.1994. [3] 韦世方.水书常用字典[M].贵阳:贵州民族出版社.2007. [4] 胡宇晓.基于IMM-IME输入法接口的实现方法[J].计算机工程与应用,2002.38(1): 117-124. [5] 郭平欣,张淞芝.汉字信息处理技术 [M].北京:国防工业出版社.1985. [6] Yang Hanyue, Chen Xiaorong. Shui Nationality Characters Stroke Shape Input Method[C]//Proceedings of the 6th IEEE International Conference on Natural Language Processing and Knowledge Engineering. 2009: 127-132. [7] Hai Guo. NaXi Pictographs Input Method and WEFT[J].Journal of Computers,2010,5(1):117-124. [8] 顾绍通,马小虎,杨亦鸣.基于字形拓扑结构的甲骨文输入编码研究[J].中文信息学报.2008, 22(4):123-128.3.3 水书笔形输入法编码规则



4 水书笔形输入法软件的实现
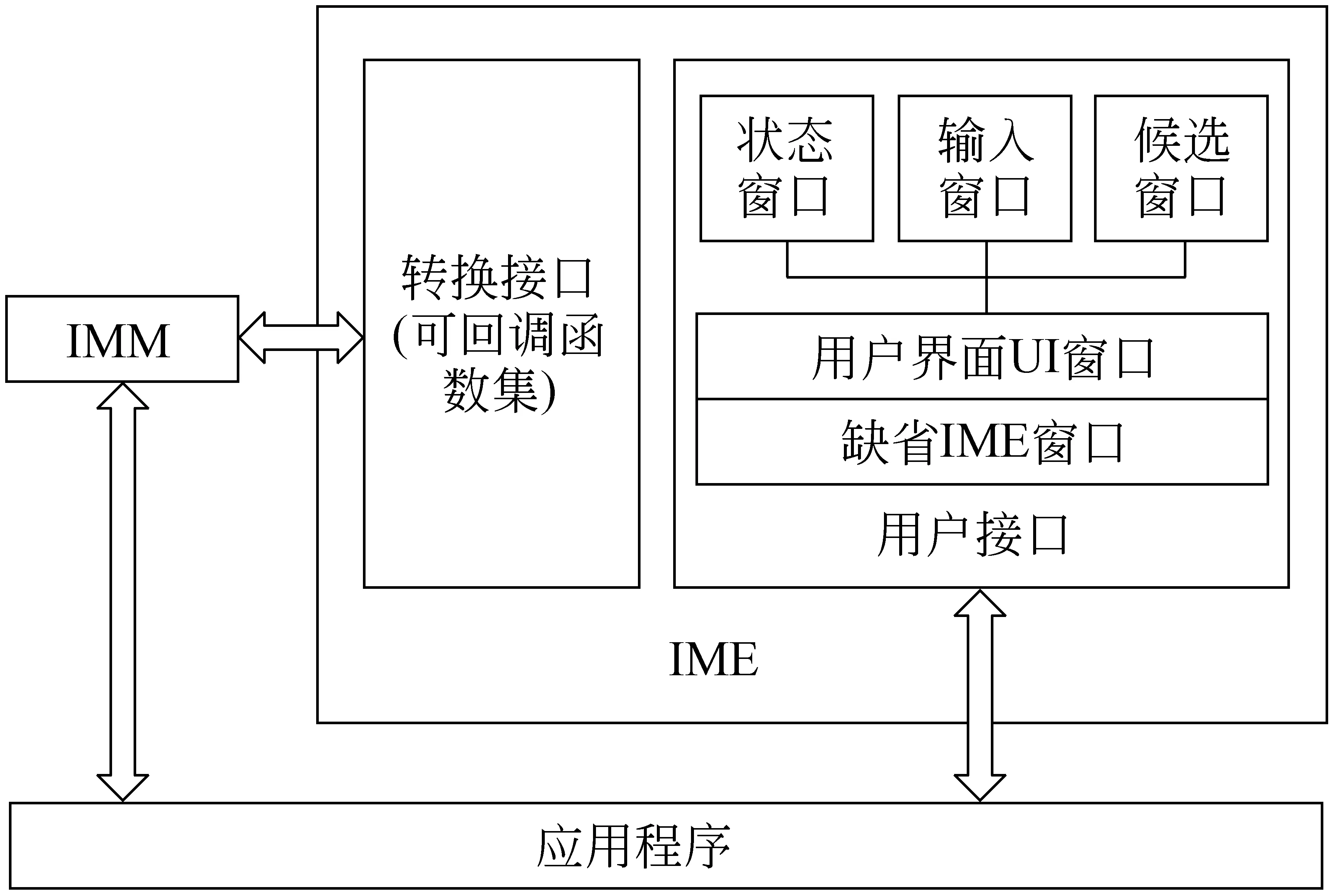
4.1 笔形输入法软件的开发
4.2 笔形输入法软件的组成


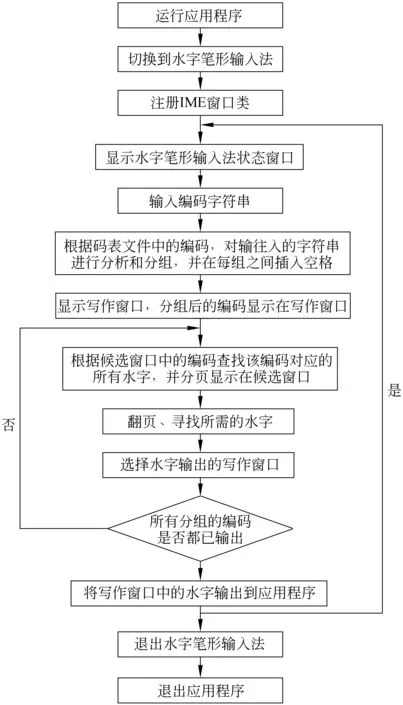
4.3 系统工作流程图

5 结论
