基于统计的记叙文语句焦点的分布特点研究
2013-04-23赵建军杨玉芳吕士楠
赵建军, 杨玉芳, 吕士楠
(1. 南京师范大学 语言科技研究所,江苏 南京 210097;2. 中国科学院 心理研究所 脑与认知科学国家重点实验室,北京 100101;3. 中国科学院 声学研究所,北京 100080)
1 引言
焦点(focus)是音系学、句法学、语义学、话语分析等语言学各个学科共同感兴趣的问题,也是形式语言学、功能语言学等语言学各个学派共同感兴趣的问题。近40年来,语言学家对焦点的概念、焦点的分类、焦点的表现方式、焦点的结构和功能等方面进行了广泛和深入的研究。在语言学研究成果的基础上,人工智能和语音工程等学科也对焦点问题进行了探讨。在关于焦点的众多研究中,焦点的确定及分布是语言学和心理学中的一个重要的理论问题,同时也是语音工程中一个具有很高应用价值的问题。本文主要探讨在文本语篇中焦点如何分布的问题。
焦点位于句法、韵律、语义和语用相互作用的交界面上,不同的研究者从各自不同的研究立场出发,给焦点赋予了不同的含义。Halliday[1]提出焦点就是新信息,是说话者认为听话者从文本和情境中都无法推出的信息。Jackendoff[2]提出焦点就是说话者所设想的听话者不与之共享的信息。这两种焦点定义都是从写作者或说话者的角度来界定的。但对于阅读者来说,如何判断文本语篇中什么是焦点?要回答这个问题,就需要从阅读者的角度来界定焦点。徐烈炯[3]提出,焦点就是句子中的重要部分、突出部分、强调部分。本文在徐烈炯的焦点定义的基础上,为了探讨文本语篇中阅读者是如何确定焦点的,以及焦点的分布受哪些因素的影响,对焦点概念作如下操作性界定: 焦点就是阅读者在语篇理解的基础上,认为语义上最重要的、作者着重强调的句子成分。
对于阅读者如何确定焦点的问题,高路[4]用7个文本语篇进行了探讨。他发现不同阅读者在语篇理解的基础上,对焦点的判断是趋于一致的,并且是相对稳定的。但他没有对文本语篇中焦点如何分布的问题进行探讨。Donzel[5]通过文本分析的方法对信息结构如何影响语篇中焦点分布进行了探讨,发现有52%的新信息被判断为焦点,有13%的旧信息被判断为焦点。但他们没有分析其他因素如何影响焦点的分布。
除了信息结构以外,词类、句法、语义以及语篇结构都会影响到焦点的分布。本研究通过对30个文本语篇进行文本标注和统计分析,在阅读者确定的焦点的基础上,探讨焦点在词类和语义角色中的分布规律。
2 研究方法
本研究所使用的语料为30篇自然叙事语篇,每个语篇平均约50个小句,600个汉字。这些语篇包括文化教育、科普和历史三类题材,每类题材各10篇。首先对每个语篇进行词语切分和词性标注(利用北京大学计算语言学研究所开发的《汉语词语切分与词性标注软件》),再由6名经过培训的研究生对文本语料进行论元结构等多层面的标注。在此基础上,进行焦点标定。参加焦点标定的是14名在校大学生和6名研究生,均具有较好的语文基础。文本语篇以打印材料呈现给被试。请被试认真阅读每个语篇至少两遍,确保对语篇准确理解。在理解的基础上,请被试逐句找出自己认为每个小句中在语义上最重要的、作者着重强调的词项,并在词的下方划一横线。告诉被试,每个小句中所划出的词项可以是一个,也可以是两个或更多个;如果认为整个小句的语义在语境中不重要,可以不做任何标记。对理解和标定的时间均没有限制。
3 结果
3.1 焦点标定的结果
由于介词、连词、助词和语气词等虚词只有语法意义,没有词汇意义,不是说话者的语义重心所在,一般不会成为焦点,所以最后统计分析的时候,我们只对六类主要实词(名词、动词、形容词、副词、代词、数量词)进行分析。对20个被试的焦点标定结果进行统计,把至少有14个被试标定该词为焦点的词(一致性≥70%)最终确定为焦点。以此为基础,对焦点分布规律进行统计分析。
我们用焦点比率来描述语篇中焦点词占实词总数的比例情况。焦点比率(F)= 语篇中标定为焦点的词数/语篇的实词总数。
30个语篇的焦点标定的结果如表1所示。

表1 30个语篇焦点标定的结果
从表1可以看出,记叙文语篇中平均每个小句大约有1.4个词成为了焦点,焦点词占实词总数的比例大约为五分之一。
高路[4]用类似的方法对汉语文本语篇进行焦点标定,得到记叙文的焦点比率为0.249,与本研究得到的结果基本一致。这说明文本语篇的焦点比率具有较高的一致性和稳定性。
3.2 焦点在词类上的分布
不同词类承载的信息量不同,成为焦点的概率也不同,词类对焦点的确定和分布有重要影响。我们首先来探讨焦点在词类上的分布规律。
焦点在词类上的分布结果如表2所示。

表2 焦点在词类上的分布
由表2可以看出,形容词的焦点比率最高,其次是数量词和名词,副词和动词较低,最低的是代词。二比率差异的显著性检验(后文均用此方法进行统计检验)表明,数量词和名词之间没有显著差异(P>0.05);副词和动词之间有显著差异(P<0.05);其他的词类相互之间都有显著差异(Ps<0.01)。
上述结果说明,形容词成为焦点的概率远高于其他词类;数量词和名词成为焦点的概率没有差异;副词成为焦点的概率略高于动词;代词成为焦点的概率非常低。
形容词主要作谓语或定语(本文把作定语的成分称为论元修饰成分)。对数据进一步分析发现,共有152个形容词作谓语,其中有115个成为了焦点,焦点比率为0.76。充当论元修饰成分的形容词,焦点比率为0.54。例如:
① 他奉旨之后非常高兴。
② 南阳城西牛家庄有个聪明、忠厚的小伙子。
例①中的“高兴”和例②中的“聪明”“忠厚”都是焦点(例句中加着重号的词是焦点,下文同)。
上述结果说明,当形容词作谓语时成为焦点的概率非常高;当它作论元的修饰成分时,也有大约一半的概率会成为焦点。由于形容词作谓语时不能带宾语,没有了宾语的竞争,形容词就成为这类小句的陈述部分的唯一重心所在,因此形容词谓语非常容易成为该类小句的焦点。形容词充当论元的修饰成分时,对主体论元或客体论元的属性进行描述。一般来说,只有重要的、必要的属性说话者才会明确说出,因此充当论元修饰成分的形容词也往往会成为焦点。
在口语中,疑问代词一般就是句子的焦点所在。但在我们的文本语篇中,共有47个疑问代词,其中有7个成为了焦点,焦点比率仅为0.15。这说明疑问代词在口语和在文本语篇中的用法非常不同。在文本语篇中,很多疑问代词的疑问性质并没有实现,而是“任指”和“虚指”的用法。例如:
③ 他在理念和现实之间究竟架设了一座怎样的桥梁。
④ 这地方在我看来跟别处没什么不同。
例句中的“怎样”和“什么”都没有表达疑问,都不是句子的焦点所在。
3.3 焦点在语义角色中的分布
焦点是句子中语义上最重要的成分,各句子成分在语义重要性上的差异对焦点的分布有重要影响。下面我们将探讨焦点在语义角色中是如何分布的。
刘探宙[6]的研究表明,焦点标记词、疑问代词、唯量词和焦点敏感算子等强式句法标记对焦点有很强的标记性。这些强式句法标记的出现会影响焦点在语义角色中的自然分布,所以我们在进行统计分析的时候把有强式句法标记的小句删除了,只分析没有强式句法标记的小句中焦点在语义角色中的分布情况。在我们的30个语篇中,共有272个小句出现强式焦点标记,占总小句数的18.7%。
对语义角色的划分,本文参照了袁毓林[7]的相关研究,并在此基础上对语义角色进行了细分,把语义角色分为: 主体论元(包括主体论元修饰成分和主体论元中心语)、外围论元(包括环境论元和凭借论元)、谓词部分(包括不含论元的谓词修饰成分和谓词)和客体论元(包括客体论元修饰成分和客体论元中心语)。本文对30个语篇的实词的语义角色按照上述分类进行了标注。
由于焦点的分布与语句类型有密切联系,因此在考察焦点在语义角色中的分布之前首先要把小句按照句型进行分类。我们把小句按照句型分为四类: 句型1: 主体论元—谓词—客体论元;句型2: 主体论元—谓词;句型3: 谓词—客体论元;句型4: 既没有主体论元也没有客体论元的特殊小句。
各种类型小句的总词数和焦点词数及焦点比率如表3所示。

表3 各种类型小句的总词数和焦点词数及焦点比率
显著性检验表明,句型3的焦点比率与其他三种句型之间有显著差异(Ps<0.01);而另外三种句型之间差异不显著(Ps>0.05)。这说明谓词—客体论元类型小句中的句子成分更容易成为焦点。
参照王韫佳[8]关于重音分布倾向的计算方法,本文用焦点分布倾向系数T作为反映某语义角色成为焦点的难易程度的指标。T的计算公式为式(1):
其中,R为某语义角色成为焦点的比率,R= 某语义角色成为焦点的词的总数/该语义角色所包含的词的总数;F为整个语料的焦点比率。T值的大小反映出某语义角色成为焦点的倾向性。T值越大,该语义角色成为焦点的倾向性也越大。
为了考察焦点在语义角色中的总体分布趋势,我们在统计分析的时候把语义角色进行了粗略分类,分为: 主体论元、外围论元、谓词部分和客体论元。不同句型中焦点在语义角色中的总体分布倾向如图1所示。

图1 不同句型中焦点在语义角色中的总体分布倾向
从图1可以看出,不同语义角色成为焦点的概率在不同句型间存在差异。显著性检验表明,句型1中的客体论元要显著高于主体论元(P<0.01)和谓词部分(P<0.01),后两者又显著高于外围论元(P<0.01),主体论元和谓词部分之间没有显著差异(P>0.05);句型3中的客体论元要显著高于外围论元(P<0.01),外围论元显著高于谓词部分(P<0.01);句型2和句型4中,各语义角色之间没有显著差异(Ps>0.05)。
上述结果说明,当有客体论元出现时,客体论元的焦点化倾向要显著高于其他语义角色; 当没有客体论元出现时, 谓词部分与论元部分的焦点化倾向没有显著差异。客体论元包括受事、与事、结果、对象和系事,通常作句子的宾语,是句子陈述部分的语义重心所在。从信息结构的角度来看,句子的话题—陈述结构中,陈述部分一般负载新信息,是说话者着重想表达的部分。因此,从语义语用的角度来看,客体论元最容易成为焦点,统计分析结果证实了这一点。
主体论元和谓词部分一般较少成为焦点,但在一些特殊情况下它们也能成为焦点。通过对语料的深入分析发现,当主体论元是新引入的话题或者是对比性话题的时候通常会成为焦点。例如:
⑤ 话音刚落,徐庶已经笑着进来了。
⑥ 北京人孝心最强,上海人则最弱。
例⑤中“徐庶”是文中新引入的话题,例⑥中“北京人”与“上海人”进行对比,成为对比焦点。
谓词一般只有在下列情况下才会成为焦点: a. 小句中无客体论元;b. 客体论元是旧信息;c. 谓词是用来陈述话题的重要动作、行为或属性。例如:
⑦ 齐国自从齐桓公死后,国内一直很不安定。
⑧ 如姬为了这件事非常感激公子。
⑨ 秦昭襄王就把楚怀王押到咸阳软禁起来。
例⑦小句没有客体论元,例⑧小句中“公子”是上文多次出现的旧信息,例⑨重点说明秦昭襄王对楚怀王的“软禁”行为。
为了进一步考察各语义角色内部的焦点分布规律,我们把语义角色精细分类后再进行统计分析。不同句型中焦点在语义角色精细分类中的分布倾向如图2所示。
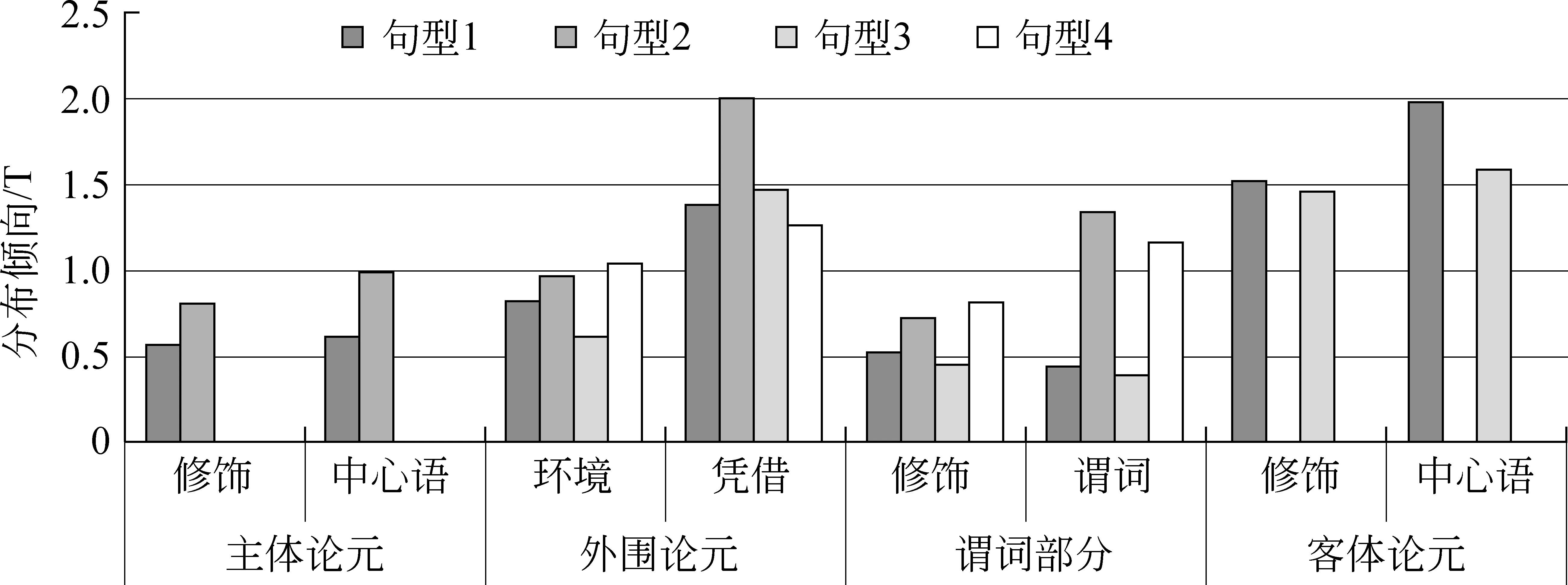
图2 不同句型中焦点在语义角色精细分类中的分布倾向
显著性检验表明:在句型1和句型2中,主体论元的中心语与修饰成分之间差异不显著(P>0.05);前三种句型中,外围论元中的凭借论元都要比环境论元成为焦点的倾向性高(P<0.05),但在句型4中二者没有显著差异(P>0.05);只有句型2中谓词要显著高于不含论元的谓词修饰成分(P<0.05),在其他三种句型中谓词部分的两种语义角色之间没有显著差异(Ps>0.05);在客体论元内部的中心语和修饰成分之间,句型1中前者要显著高于后者(P<0.05),句型3中二者差异不显著(P>0.05)。
在句型1和句型2中,主体论元的修饰成分与中心语的焦点化倾向都没有显著差异。这说明主体论元的修饰成分与中心语的语义重要性总体是相当的。在句型1中,客体论元的中心语的焦点化倾向要显著高于其修饰成分,在句型3中,客体论元的中心语与修饰成分的焦点化倾向没有显著差异。这说明客体论元的修饰成分与中心语的语义重要性跟句子类型有一定关系。
在句型2中,谓词的焦点化倾向要显著高于不含论元的谓词修饰成分,但在其他各种句型中,两者之间均没有显著差异。对语料进行深入分析后发现,句型2中的谓词有很多是由形容词来担当的。这种谓词的焦点比率非常高,导致了这种句型中谓词的焦点化倾向要显著高于不含论元的谓词修饰成分。
外围论元中的凭借论元通常要比环境论元成为焦点的倾向性高。这主要是因为,凭借论元主要是动作、行为所凭借的工具、所用的材料、所采取的方法或者是动作、行为的原因、目的,这些成分在语义上相对比较重要,往往会成为说话者强调的对象。环境论元主要是动作、行为、事件等发生的时间、处所、频率、幅度等,主要用来构建行为、事件发生的时空构架,在语义上的重要性相对较低。例如:
⑩ 它用嘴巴作挖掘的工具。
4 结论
本研究让20名被试对30篇汉语记叙文进行焦点标定,在焦点标定的基础上,结合文本标注和统计分析,对焦点在词类和语义角色中的分布规律进行了探讨。结果主要发现,记叙文语篇中焦点词大约占实词总数的五分之一。形容词成为焦点的概率远高于其他词类;数量词和名词成为焦点的概率没有差异;副词成为焦点的概率略高于动词;代词成为焦点的概率非常低。焦点在语义角色中分布的总体趋势是: 客体论元的焦点化倾向最高,其次是外围论元,最低的是主体论元和谓词部分。主体论元中心语和主体论元修饰成分之间的焦点化倾向没有显著差异。凭借论元的焦点化倾向通常要高于环境论元。
高路[4]也用类似方法对汉语文本语篇进行焦点标定,得到记叙文的焦点比率为0.249。这说明文本语篇的焦点比率具有较高的一致性和稳定性。
Donzel[5]通过文本分析的方法发现信息结构对焦点的分布有显著的影响。把词类、语义角色与信息结构、语篇结构等文本信息对焦点分布的影响结合起来,才能更准确地判断出文本语篇中哪些成分会成为焦点。后续研究中,我们将对语篇结构对焦点分布的影响进行探讨。
语篇的焦点分布规律可以应用于自然语言处理的多个领域。焦点信息对提高自动文摘系统的精度和文本信息抽取的有效性有实际应用价值[9-10]。此外,焦点与重音之间有密切的关系,所以焦点分布规律对改进文语转换系统(TTS)的韵律控制[11]也有一定的应用价值。
[1] Halliday, M.A.K. Notes on transitivity and theme in English[J]. Journal of Linguistics, 1967, (3): 199-244.
[2] Jackendoff, Ray. Semantic interpretation in generative grammar[M]. Cambridge: MIT Press, 1972: 230.
[3] 徐烈炯,潘海华. 焦点结构和意义的研究[M]. 北京: 外语教学与研究出版社, 2005.
[4] 高路. 汉语文本语篇语句焦点确定及焦点与重音关系研究[D]. 北京:中国科学院心理研究所, 2007.
[5] Monique E. van Donzel, Florien J. Koopmans-Van Beinum[C]//Prominence judgements and textual structure in discourse. Proceedings of the Institute of Phonetic Sciences, University of Amsterdam, 1995: 11-23.
[6] 刘探宙. 多重强式焦点共现句式[J]. 中国语文, 2008, (3): 259-269.
[7] 袁毓林. 语义角色的精细等级及其在信息处理中的应用[J]. 中文信息学报, 2007, 21(4): 10-20.
[8] 王韫佳,初敏,贺琳. 汉语焦点重音和语义重音分布的初步实验研究[J]. 世界汉语教学, 2006, (2): 86-98.
[9] 傅间莲,陈秀群. 基于规则和统计的中文自动文摘系统[J]. 中文信息学报,2006,20(5): 10-16.
[10] 袁毓林. 信息抽取的语义知识资源研究[J]. 中文信息学报,2002,16(5):8-14.
[11] 朱维彬. 支持重音合成的汉语语音合成系统[J]. 中文信息学报,2007,21(3):122-128.
