第三届中文倾向性分析评测(COAE2011)语料的构建与分析
2013-04-23廖祥文许洪波姚天昉
廖祥文,许洪波,孙 乐,姚天昉
(1. 福州大学 数学与计算机科学学院, 福建 福州 350108; 2. 中国科学院 计算技术研究所,北京 100190;3. 中国科学院 软件研究所,北京 100190; 4. 上海交通大学,上海 200240)
1 引言
随着Web 2.0的迅猛增长,网民能够在诸如博客、微博、购物网站等媒介上自由发表观点评论。文本倾向性分析的目标是挖掘民众对生活中各种对象和事件所表达出的态度、意见和情绪的倾向性[1-3],有着广泛的商业应用前景,已成为自然语言处理领域研究的热点问题之一。TREC评测[4]、NTCIR评测[5]以及前两届中文倾向性分析评测[6-7]推动和加速了倾向性分析研究的发展。随着研究的深入展开,也出现了一些新的研究关注点,例如,Aspect-Based Opinion Mining[8],Context-Sensitive Opinion Mining[9], Domain-Oriented Opinion Mining[10]等。如何结合中文特点,提供统一的中文倾向性语料促进中文倾向性分析在相关问题上的研究是目前亟待解决的问题。
为了进一步推动中文倾向性分析研究,中国中文信息学会信息检索专业委员会在成功组织前两届中文倾向性分析评测的基础上,以在山东大学举行的第七届全国信息检索学术会议(CCIR2011)为依托,继续组织第三届中文倾向性分析评测(The Third Chinese Opinion Analysis Evaluation-COAE2011)[11]。如表1所示,该评测主要关注领域和上下文语境(Context)对中文倾向性分析的影响,设置了领域观点词识别、观点句抽取、评价搭配抽取和观点检索四个评测任务,考察词—句子—篇章等不同粒度的倾向性分析。基于上述评测目标,本次评测从门户网站、博客、微博、购物网站和论坛等网络媒介上,选取电子产品、影视娱乐和金融证券三个领域构建语料。
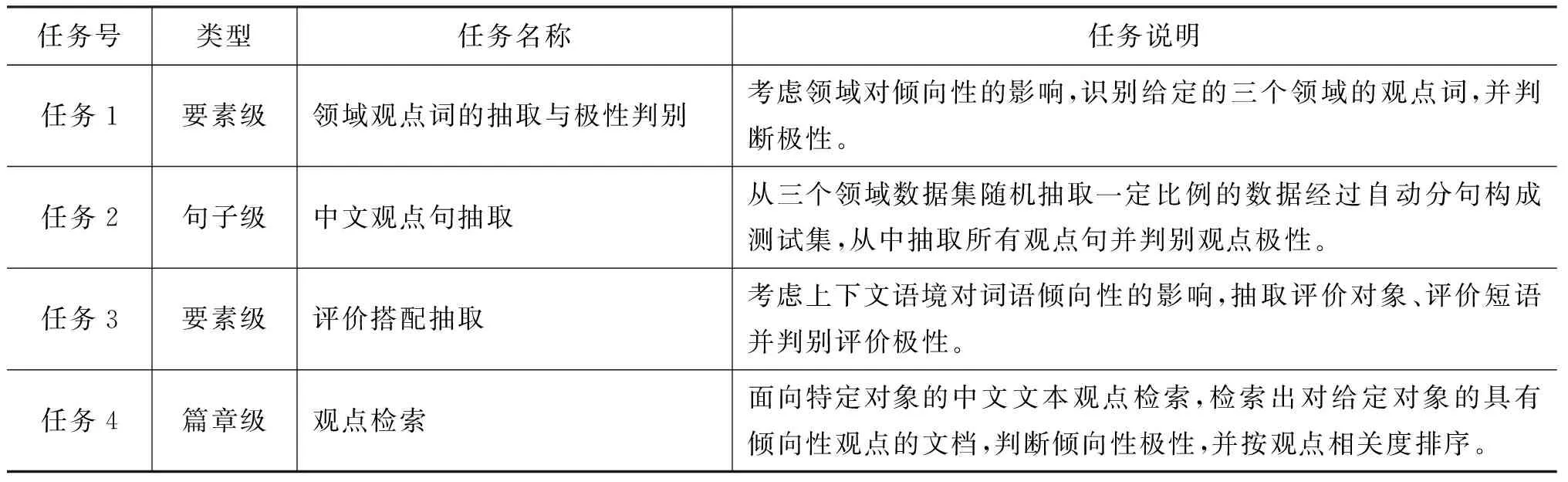
表1 COAE2011评测任务设置
借鉴前两届的语料和已有的倾向性语料构建[12],本文主要介绍COAE2011语料获取、标注,评测结果的评判,以及语料对倾向性分析的影响等详细情况。具体安排如下: 第1节介绍COAE2011语料领域选取、媒介分布等构建过程;第2节介绍标注原则与方法,并列出典型的例子;第3节依据评测结果阐述语料如何支撑对文本倾向性评测,并分析领域和上下文语境因素对倾向性的影响。
2 COAE2011语料构建
本次评测主要关注影响中文倾向性分析的两个重要因素: 领域和上下文语境(Context)。因此,本文选取了电子产品、影视娱乐和金融证券三个领域的文档建立语料集,用以分析领域对中文倾向性分析的影响。理想状态下,所采集的语料应该是来自整个网络所有文档的一个样本,并且与整个网络文档集同分布。因而,在构建语料集时,本文充分考虑媒介的多样性,依据领域的分布特点,从门户网站、专业网站、购物网、知名博客、微博、论坛等媒介上采集。
被采集的原始网页在进行抽取、过滤、去重等消除噪声工作后,形成了本次评测的COAE2011_Corpus_All_Text数据集。根据前两届中文倾向性分析评测的经验发现: 如果把COAE2011_Corpus_All_Text数据集直接用于任务2和任务3的抽取倾向观点句和评价搭配,可能会导致召回率过低。这不仅会降低各个参评队伍评测结果的可比性,而且会给后期的标注带来巨大的困难。为了避免出现上述情况,本文对COAE2011_Corpus_All_Text数据集做进一步抽样,每个领域随机抽取2 000个文档,组成COAE2011_Corpus_Sample_Sentence数据子集。考虑到各参评单位采用不同的分句工具,分句的精度不同会产生不同的句子集,进而导致评判结果偏差。对COAE2011_Corpus_Sample_Sentence数据子集中的文本采用中国科学院计算技术研究所提供的自动分句工具统一进行了断句处理,每篇文本均组织成一句话占一行的格式,每行以 结束。构建的两个评测数据集如表2所示。
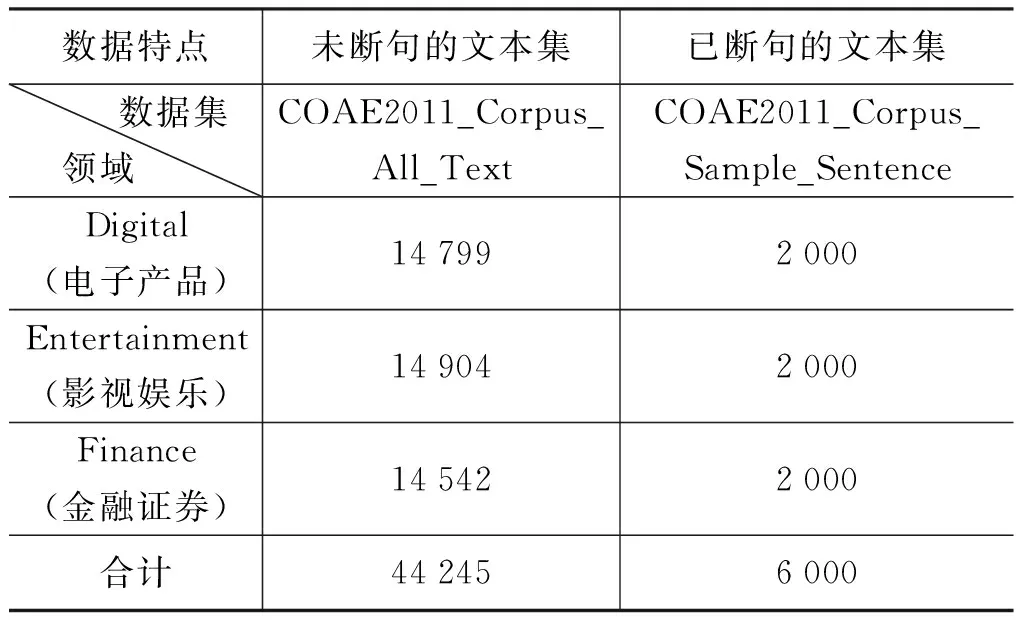
表2 COAE2011评测数据
3 COAE2011语料标注
领域观点词抽取与极性(任务1)和观点检索(任务4)使用COAE2011_Corpus_All_Text数据集,而中文观点句抽取(任务2)和评价搭配抽取(任务3)则使用COAE2011_Corpus_Sample_Sentence数据子集。为减轻标注工作量,对于使用COAE2011_Corpus_All_Text数据集的两个任务,使用国内外评测常用的Pooling方式,从各个参评队伍提交的结果中截取前K个结果合并形成候选集,用以裁判员人工评判构建标准答案。由于COAE2011_Corpus_Sample_Sentence数据子集的数据规模较小,对整个数据集进行标注。因而,本届评测的任务1和任务4只标注了部分答案,属于不完全评测,而任务2和3则属于完全评测。
本文构建了一个简易的评测标注系统,把待标注数据统一存入数据库,然后通过Apache服务器生成的标注界面呈现给标注人员。在标注时,评测四个任务的语料标注均采用如下方法: 从待标注数据库中选择一条数据,随机指派给两个标注人员,如果两个标注人员标注的结果一致,则直接写入已标注数据库;如果两个标注人员标注的结果不一致,再指派给第三个标注人员标注,把多数一致的标注结果写入已标注数据库。为了减少标注误差,在进行每个标注任务时,所有标注人员标注完前50条数据时,集中分析讨论标注结果,统一标注原则,然后再标注剩下的数据。
3.1 领域观点词抽取与极性标注
本次评测任务1共有14支队伍提交了15个run。由于时间和人力资源的限制,本文采用Pooling方法截取前K=500构成待标注语料集。标注任务为标注观点词和观点词的极性。在标注过程中,根据参评队伍提供的待标注词的前后20个字节上下文,只抽取存在较明显的评价对象的观点词,不考虑像程度副词、否定词之类的修饰成分,然后标注其极性(+1褒义、-1贬义)。与COAE2009评测不同的是,本次评测只关注对评价对象的褒贬义评价,而不考虑诸如喜、怒、哀、乐的个人情感。在标注时,一个句子如果包含多个观点词,那么全部抽取出来作为标注答案。例如:
[01] “能会知道,其附件非常丰富,并且包装看起来就很”
标注结果: 丰富 +1
在标注过程中,发现一些需要处理的特殊情况,并对这些情况做了一些简要处理。当然,这样的处理只是为了标注方便,其合理性仍然值得商榷。具体介绍如下。
(1) 垃圾串与特殊串的处理
在任务1中,垃圾串指的是对于提供的上下文片段内容不完整或者语义错乱的字符串。这些垃圾串虽然出现了有明显褒贬义的观点词,但是根据上下文语境无法判断其评价对象和极性,因此不标注其观点词。典型的例子如下:
[02] “欧曼牵引车开着舒适我的欧曼牵引车已经”
标注结果: 垃圾串 NULL
虽然在很多语境下,“舒适”是褒义的,但是由于该上下文片段语义错乱,不予标注。
特殊串指的是内容为文学描述、祝福语、广告等的上下文片段。由于任务1关注的是对观点对象进行褒贬义评价的观点词,因此即使上下文片段中包含诸如“好”、“性价比最高”等有明显褒贬义的观点词,也不标注其观点词。例如:
[03] “轻轻的掠过,掀起点点涟漪。徜徉在你的小家轻轻”
标注结果: 文学描述 NULL
[04] “在此,中关村在线也衷心祝愿lg光存储事业部在”
标注结果: 祝福语 NULL
[05] “最精准的券商研究报告…请访问XX的博客”
标注结果: 广告 NULL
[06] “卓越的XXX培训助各位早日踏上财务自由之路。”
标注结果: 广告 NULL
(2) 否定词“不”的处理
按照任务要求,只抽取评价对象的观点词,而不考虑程度副词、否定词等修饰成分。例如,“不完美”、“不完善”中的“不”是否定词,只抽取出观点词,即“完美”、“完善”,并极性标为(+1 褒义);但并不是对所有含“不”的观点词都做上述处理,在标注过程中,发现对有些带否定词“不”的观点词,不能简单地把否定词去掉。例如,“不俗”,如果简单地把“不”去掉,只抽取“俗”,那么容易引起歧义。因为在“不俗”一词中,其词义是“平凡、普通”。但是对单个“俗”字,还有“不雅,缺乏修养的”等意思。因此,若含“不”的否定观点词是两个字的而且语义结合紧密,如“不好”、“不俗”、“不错”,则当作一个观点词抽取。典型的例子如下:
[07] “卡威盛高保真音频有点不地道。”
标注结果: 地道 +1
[08] “值得购买,售后服务不完善,更新不及时”
标注结果: 完善 +1,及时 +1
[09] “在取景器中的显示效果不俗,但拍照成像过程等待”
标注结果: 不俗 +1
[10] “输出略显不够,有点失真。价位应该很不错了”
标注结果: 不够-1,失真-1,不错+1
(3) 组合词的处理
本文把两个或两个以上语义联系紧密构成的短语称为组合词。这些组合词虽然不在词典中,但是如果用以对评价对象进行褒贬义评价,则标注成一个整体。例如:
[11] “活到美国去,一个热情奔放的国家!”
标注结果: 热情奔放 +1
[12] “《聊斋志异》,剧中女性机智勇敢,聪明绝伦。她们”
标注结果: 机智勇敢 +1,聪明绝伦 +1
3.2 中文观点句与评价搭配抽取标注
任务2和任务3采用COAE2011_Corpus_Sample_Sentence数据子集。本文对该数据集所有句子进行标注。其标注原则是: 首先标注句子的倾向性: 褒义标1,贬义标-1,既有褒义又有贬义标0。对于倾向性句子,再标注三元组<评价对象,评价短语,评价极性>。在三元组中,评价对象是指评论针对的对象或对象的属性;评价短语是指修饰成分和评价词语组合而成的评价单元。修饰成分是指加强、减弱或置反观点的语言成分,可以是程度副词、否定词等。在标注过程中,为了减少标注偏差和便于后期的处理,对评价对象和评价短语均抽取“最大字串”作为标注结果。 而对于评价极性,只标注对评价对象的褒贬义评价(-1表示贬义, 1表示褒义),不考虑喜、怒、哀、乐等个人情感。此外,要注意的是如果一个倾向性句子有多个三元组,则抽取全部三元组。下面介绍在标注过程中出现的典型情况。在标注时,由于时间和经验局限性,只采取一些简单的处理方法,其合理性仍有待进一步研究。
(1) 垃圾句与特殊句的处理
与任务1一样,垃圾句指的是内容不完整或者语义错乱的句子。特殊句是指对内容为文学描述、祝福语、广告等的句子。对这两类句子,在标注时,直接标注为“NULL”。例如:
[13] 支持博主,我的最新博文,内容丰富多彩,细腻情感、出位艺术,欢迎光临!
标注结果: 广告 NULL。
(2) 转折句的处理
对于“虽然……但是……”,“但是”、“却”等转折词连接的转折句,只有当连接的两部分呈现出不同的褒贬义评价时,才标注为“有褒有贬”。例如:
[14] 这个设计虽然很新颖,但是毫无时尚感
标注结果: 首先该句的前半句是褒义,后半句则为贬义的,故把该句标注为“有褒有贬0”。在此基础上,抽取搭配三元组: <设计,很新颖,1>、<设计,毫无时尚感,-1>
[15] 口味还不错,不过周围环境很差
与[14]不同的是,句子前后两个半句的评价对象不同。显然,该句是整体评价“某餐馆”,但是句子本身却省略了整体评价对象。因此,句子的倾向性标注为“有褒有贬0”。在此基础上,抽取评价搭配三元组: <口味,还不错,1>、<周围环境,很差,-1>
(3) 对影视娱乐数据的处理
在标注影视娱乐数据时,只有对娱乐影视内容、演员表演技能等进行褒贬义评价才标注为有倾向性。但是,如果采用褒贬义词描述剧目中的人物、事件等内容,而不对剧目进行评价,则标注为无倾向性。例如:
[16] 该剧讲述了一个音乐制作人靠欺骗观众令一个歌手走红,舞台上的歌手只有靓丽的外表,他的演唱是由幕后一个其貌不扬但才华横溢的歌手完成的,最终两人主动揭穿了骗局。
标注结果: 该句是对剧目内容的描述,并不是对剧目本身好坏的评价。虽然用了很多诸如“靓丽”、“其貌不扬”、“才华横溢”等倾向词,但仍判为无倾向性,而不是有褒有贬。
(4) 对金融数据的处理
金融数据的倾向性表达较为复杂,因此关于金融数据的处理,只有对金融产品、现象等进行褒贬义评价时才标注为有倾向性。但是,对于采用“跌”、“涨”等描述一个事实或现象时,虽然这些词在其他领域具有很强的褒贬色彩,但是在金融领域中则标为无倾向性。例如:
[17] 至收盘,沪指报2 587.81点,跌0.27%,成交789.8亿元;深成指报9 991.40点,跌0.12%,成交629.4亿元 。
标注结果: 无倾向性
[18] 韩国3月消费者信心指数为2009年7月以来最低,韩国央行周四公布的数据显示,韩国3月消费者信心指数连续第二个月下跌,至八个月低位,令对经济复苏放缓的担忧加重。
标注结果: 贬义(-1)。抽取的评价搭配三元组为: <对经济复苏放缓的担忧 加重-1>。
此外,在标注过程中,参评队伍的一些老师提出“某股票领涨、某股票跌穿”带有一定倾向性,确实有一定的道理,由于时间比较仓促,没有考虑这种细节。
(5) 评价对象省略情况
语料存在一些句子,评价对象是省略的,但是可以推测出该句具有非常明显的褒贬义评价。对于这种情况,任务2标为有倾向性,但是在任务3的评价搭配三元组抽取标为空。例如:
[19] 就是稍贵了一点,但也算物有所值了显然,该句虽然省略了评价对象,但是具有非常明显的褒贬义评价。因此,任务2的标注结果是有褒义有贬义。然而,对于任务3的评价搭配抽取则标注为空。
3.3 观点检索标注
与前两届一样,观点检索的目标是检索出与给定查询不仅主题相关,而且对该主题有褒贬义评价的文档。其标注原则如下: 首先标注文档内容与给定查询是否主题相关;如果相关,则进一步判断文档内容对该主题的褒贬义评价(-1: 贬义、1: 褒义、0: 褒贬义混合、2: 无倾向性)。例如:
[20] 给定查询: Iphone
DOC01: N8的上市让很多消费者将其与iphone 4和三星i9000等产品作比较,注重时尚元素的N8毫不逊色任何机型。
标注结果: 不相关
DOC02: 外观上,苹果 iPhone 4代 16G采用了轻薄时尚的外观设计,机身以黑色为主色调,外壳选用不锈钢框架打造,表面经过烤漆工艺处理,质地十分光滑并有着细腻的光泽度,简练的线条勾勒出大气的轮廓,略显圆润的边角过度自然流畅,金属材质的音量调节按键设计在左上侧,方便日常操作。但是与三星等其它品牌相比,价格仍然偏高。
标注结果: 相关 0(褒贬义混合)
[20] 给定查询: 房产税
DOC03:房产税会不会出台,目前对房产业有什么影响近期房市稳定不会有大的动作!
标注结果: 相关 2(无倾向性)
DOC04: 韩令国: 房地产热是经济泡沫与民生的双重灾难最好的解决方法是对投机或投资性购房加征高额暴利税,依我看其税率为房产价格的40%足矣!
标注结果: 相关 1(褒义)
4 评测结果分析
本次评测得到了国内同行的热情支持,总共有20个单位报名参加,其中18支队伍成功提交结果: 任务1共有14支队伍提交了15个run;任务2共有17支队伍提交了20个run;任务3共有12支队伍提交了14个run;任务4共有5支队伍提交了9个run。基于上述过程标注的数据,根据不同任务要求选取P@N、Precision、Recall、F1、R-accuracy、Map等评价指标对参赛队伍进行评价,具体结果如表3~5所示。本次评测的目标侧重考虑领域和上下文语境对倾向性的影响。因此,首先根据评测结果考察领域和语境对倾向性的影响,然后总结语料、标注尚待改进之处。
4.1 领域对倾向性的影响分析
从表3~5可以看出,在观点词识别任务中,对于电子产品、影视娱乐和金融证券三个领域,观点词识别P@1000指标中值在0.57左右、最佳值约为0.62;召回率三个领域也相差不多,但是均取得较低值: 中值约为0.09、最佳值为0.12左右;而准确率虽然最佳值金融证券比影视娱乐和电子产品高,但区别不是很明显,中值也均集中在0.35左右。
在观点句识别任务中,对于不考虑句子极性的情况,三个领域的准确率、F1值、P@1000则显著不同: 电子产品最优,影视娱乐次之,金融证券最差。电子产品领域的准确率、F1的中值和最佳值几乎是金融证券领域的两倍。如果同时考虑句子极性,三个领域的准确率、F1值、P@1000虽然略有下降,但是三者之间的仍然保持较大差异。
在评价搭配抽取任务中,分别统计了下面三种情况: (1)“评价对象+评价短语+极性”,同时考虑评价对象、评价短语和极性,只有当三个元组同时抽取正确,才判为正确;(2)“评价对象”,只考虑评价对象,当评价对象抽取正确,就判为正确;(3)“评价短语”,只考虑评价短语,当评价短语抽取正确,就判为正确。从表3~5可知,这三种情况的各项指标均较低,评价搭配抽取仍然是一个很困难的任务。但是仍然可以看出,电子产品领域的各项指标均高于影视娱乐和金融证券领域。
需要特别指出的是,观点检索的评测任务设置并没有区别领域,但是查询主题的设置基本上是平均分配的。因此,在统计评价指标时可以看成针对三个领域设置分别数量相当的查询主题。在此基础上,可以计算不同领域的准确率、召回率、F1等评价指标。从表3~5计算结果可知: 电子产品领域的准确率、召回率、F1值高于影视娱乐和金融证券领域;影视娱乐领域的评价指标略高于金融证券领域;但是,三者的差距除了最佳值外,并不是非常显著。

表3 电子产品领域的评测结果

续表
*注: 观点词识别、句子识别、句子识别+极性采用的是P@1000的指标,观点检索采用的是P@10的指标。
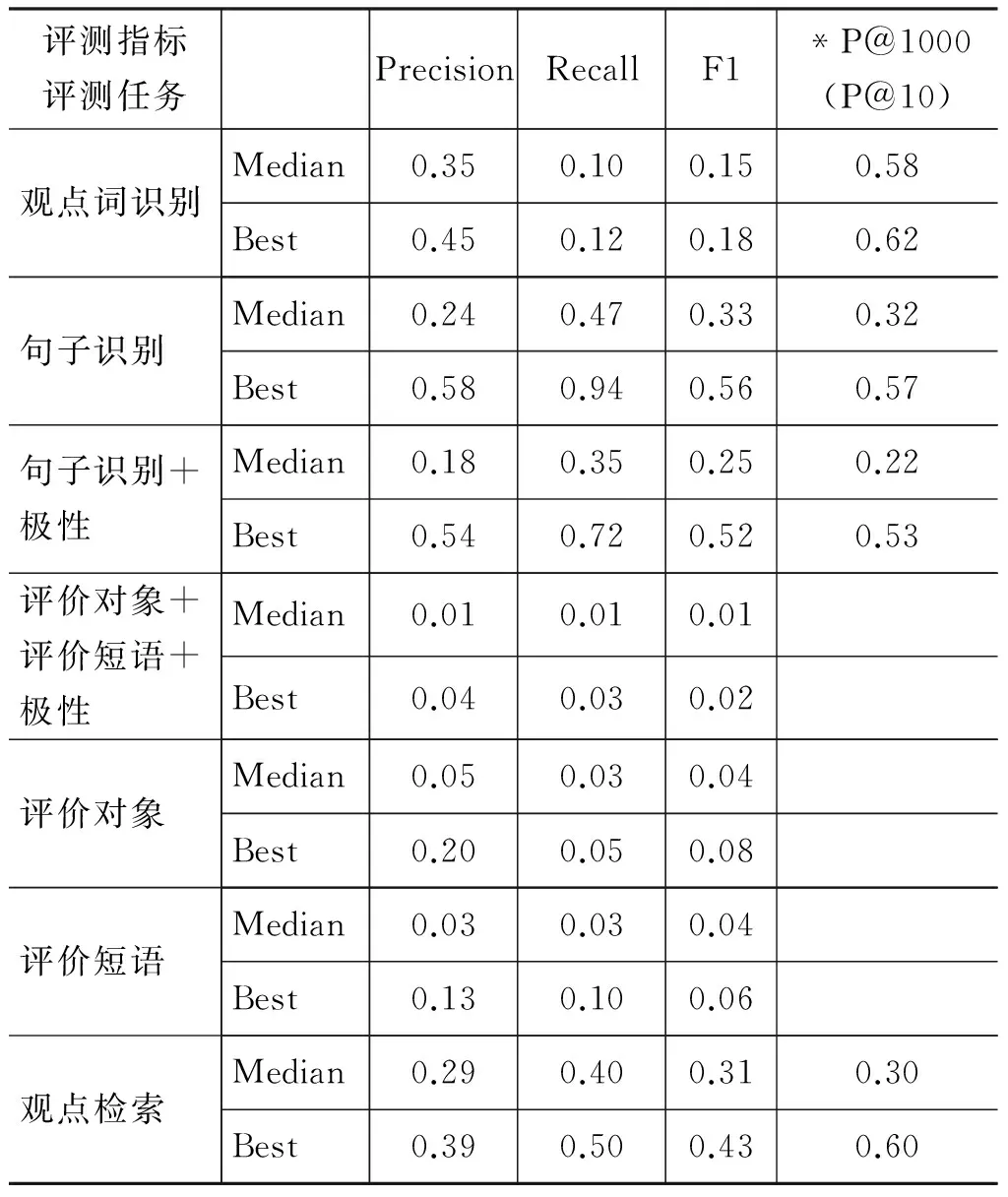
表4 影视娱乐领域的评测结果
*注: 观点词识别、句子识别、句子识别+极性采用的是P@1000的指标,观点检索采用的是P@10的指标。
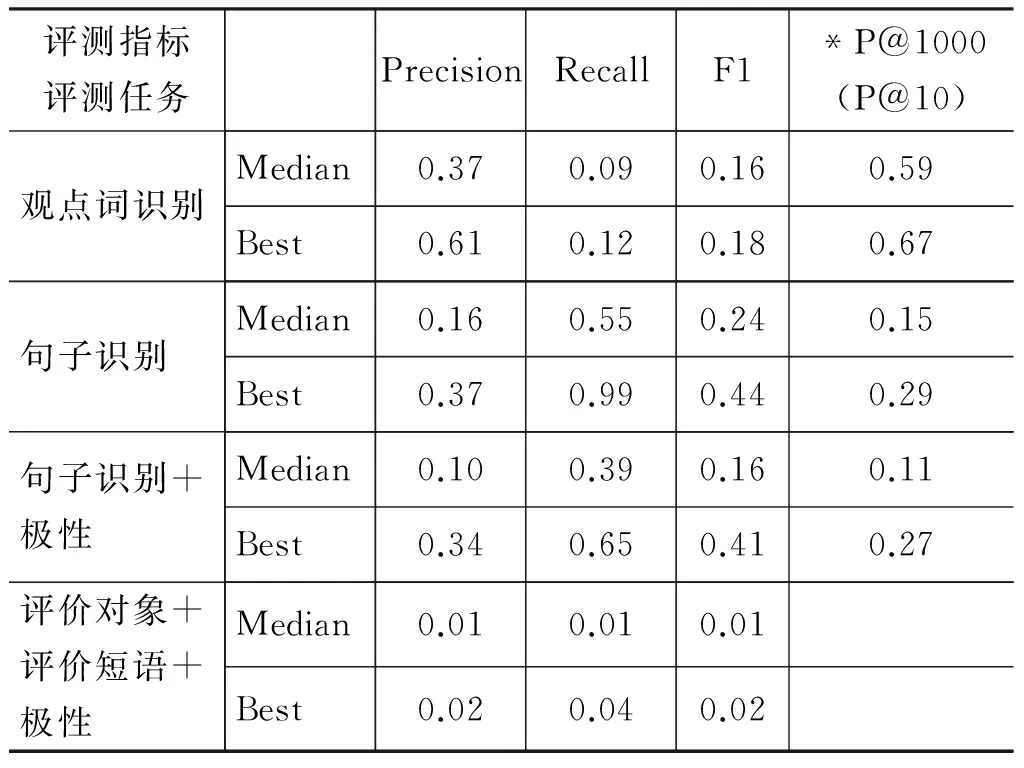
表5 金融证券领域的评测结果

续表
*观点词识别、句子识别、句子识别+极性采用的是P@1000的指标,观点检索采用的是P@10的指标。
综上所述,领域因素对观点词识别和观点检索影响不大,而对观点句识别、评价搭配抽取的影响较为显著: 电子产品领域所体现出的褒贬评价较为明确,抽取相对容易;影视娱乐和金融证券领域的褒贬评价较为模糊,比较难以判断。这与标注过程中标注人员所反映出的难易程度一致。
4.2 上下文语境对倾向性的影响分析
在观点词识别任务中,其识别任务是要素级的。从结果上看,虽然三个领域的各项评价指标相差不大,但准确率、召回率值偏低,特别是召回率仅达到0.10左右。准确率不高一方面是由于抽取算法的不太理想,另一方面可能是标注的影响: 标注时根据“以观点词为中心的前后各20字节组成的文本片段”来判断观点词的识别比较困难。召回率偏低则表明评测队伍的抽取算法抽取的结果吻合度较低,观点词识别任务仍然是一个比较有挑战性的任务。三个领域P@1000的最佳值则均达到0.60以上。这说明评测队伍更注重靠前命中率,其置信度排序算法较为有效。因此,虽然评测队伍可能根据多种信息源、充分利用上下文语境来进行判断,但是观点词识别任务仍然较为困难。需要强调的是,在标注过程中,根据“以观点词为中心的前后各20字节组成的文本片段”的上下文语境对本任务的标注影响较大。
对于观点句识别任务,句子是表达的一个完整单位。与“以观点词为中心的前后各20字节组成的文本片段”相比较,句子提供较为丰富的上下文语境信息。从表3~5可以看出,观点句子识别的各项指标仍然较低,这说明仅从句子信息出发对句子总体极性进行判断仍然有一定的不确定性: 特别是有些句子省略了观点持有者或评价对象,给倾向性判断带来较大的困难。
评价搭配抽取任务要求抽取包含“评价对象+评价短语+极性”信息的评价搭配。对于明确的评价搭配,应该能较为准确地判定观点。然而,该任务要求从判定为有观点的句子抽取搭配对,可利用的语境是句子的上下文信息。从表3~5可以看出,本次评测结果不够理想,评价搭配抽取的各项评价指标非常低,仍然有很大的提升空间。这一方面由于评测的尺度比较严格,另一方面确实反映出自然语言表达的灵活性、复杂性和不确定性,需要考虑除了句子的上下文语境以外的信息进行抽取。
观点检索任务提供篇章级的信息和完整的上下文语境,使得参评队伍能够充分考虑领域、上下文语境等信息,计算对给定话题的评论强弱。从表3~5可以看出,三个领域的准确率、召回率、F1值差别不大,但是P@10最佳值达到0.60以上。这是由于各参评队伍对更侧重首页命中率,结果的全面性有所忽视,导致准确率较高、召回率很低。从本任务的评测结果可以看出,篇章级文本能够提供较为完整的上下文语境,因而能够较为准确计算出对给定查询的评论强弱。
综上所述,上下文语境对倾向性分析产生较大的影响: 观点词识别任务和观点检索任务能够充分利用篇章的上下文语境,能够取得较好的结果;而观点句识别任务和评价搭配抽取任务只能利用句子的上下文语境,各项评价指标仍然偏低。
4.3 语料、标注有待改进之处
首先,在标注金融证券数据时,标注人员的原则是在表达一个金融事实或现象时,标注为无倾向性。但是该尺度较难掌握,仍然存在着一定程度的争议。例如:
[21] 昨日股市涨了200点但今天跌了300点
[22] 某股票领涨、某股票跌穿
上述两个例子标注人员均标注为无倾向性。然而,一些同行则认为上述例子在一定程度表达一定的褒贬义色彩。
其次,对于评价搭配抽取任务,为了便于处理规定抽取的评价对象和评价短语均取最大字串。在评测时采用了严格尺度,只有跟标注答案完全一致的结果才被判为正确。这样虽然减轻了标注和评测的工作量,但由于过于严格也漏掉了一些近似的正确结果。例如,
[23] LED显示效果非常清晰
标注结果为:
在结果判别时,诸如“< LED 清晰 1>、< LED 非常清晰 1> 和
此外,由于工作量较大、时间有限,本次评测仍存在许多需要改进之处: (1)标注结果存在少量的重复句子,这是由于标注系统在分派任务的时候是随机指派的,每次展现一个句子给标注人员,并没有做近似的去重;(2)媒介覆盖率有待提高,需要更加科学采样以反映整个网络数据样本;(3)评测指标有待进一步考虑。例如,对于观点检索任务,可以考虑NDCG指标等。
5 结论
为了推动文本倾向性分析研究,在前两届文本倾向性分析评测的基础上中文信息学会信息检索专委会举办了第三届中文倾向性分析评测(COAE2011)。该评测主要关注领域和上下文语境(Context)对中文倾向性分析的影响。本文主要介绍评测语料的构建以及其对评测的支撑: 首先介绍第三届中文倾向性分析评测(COAE2011)的语料构建,然后基于标注实例阐述电子产品、金融证券和影视娱乐三个不同领域语料的标注原则与方法,最后结合评测结果分析领域和上下文语境两种因素对语料中不同领域倾向性的影响。此外,还分析了本次语料尚待改进之处,为进一步丰富和完善提供参考。COAE2011语料的建立将为中文倾向性分析提供强大的资源支持。
6 致谢
感谢中国中文信息学会信息检索专业委员会各位领导的指导与支持;感谢参评队伍的老师和同学的热情参与和积极反馈;感谢福州大学信息检索课题组的同学和福州大学数学与计算机科学学院志愿者的辛苦付出。
[1] 黄萱菁,赵军. 中文文本情感倾向性分析[J].中国计算机学会通讯[J],2008,4(2): 41-46.
[2] B Pang, L Lee. Opinion Mining and Sentiment Analysis [J]. Foundations and Trends in Information Retrieval, 2008,2(1-2): 1-135.
[3] 赵妍妍, 秦兵, 刘挺. 文本情感分析综述.软件学报[J],2010,21(8):1834-1848.
[4] TREC2008. The 17 Text Retrieval Conference Proceedings [EB/OL], 2008[2011.3.10]. http:trec.nist.gov/pubs/trec17/t17_proceedings.html.
[5] NTCIR (NII Test Collection for IR Systems) Project [EB/OL], 2009[2011.3.10]. http:research.nii.ac.jp/ntcir/ntcir-ws8/ws-en.html.
[6] 赵军,许洪波,黄萱菁,等.中文倾向性分析评测技术报告[R]. 北京,2008.
[7] 许洪波,姚天昉,黄萱菁,等.第二届中文倾向性分析评测技术报告[R].第二届中文倾向性分析评测会议,上海,2009.
[8] B Li, L Zhou, S Feng, et al. A Unified Graph Model for Sentence-Based Opinion Retrieval[C]//Proceedings of ACL’10, Uppsala, Sweden, 2010:1367-1375.
[9] J Zhu, H Wang, M Zhu, et al. Aspect-Based Opinion Polling from Customer Reviews[J]. IEEE Transactions on Affective Computing, 2011.
[10] W Du, S Tan, X Cheng, et al. Adapting information bottleneck method for automatic construction of domain-oriented sentiment lexicon[C]//Proceedings of WSDM 2010: 111-120.
[11] 许洪波,孙乐,姚天昉,等. 第三届中文倾向性分析评测(COAE2011)总结报告[R]. 第三届中文倾向性分析评测会议,山东,2011.
[12] 徐琳宏,林鸿飞,赵晶.情感语料库的构建和分析[R].中文信息学报,2008, 22(1):116-122.
