一种基于社会化标签的信息检索方法
2013-04-23李鹏,王斌,晋薇
李 鹏,王 斌,晋 薇
(1. 中国科学院 计算技术研究所,北京 100190; 2. 中国科学院大学,北京 100049;3. Department of Computer Science, North Dakota State University, Fargo, USA)
1 引言
作为Web 2.0时代的基础应用,社会化标注(Social Annotation)允许用户使用任意的词—标签(Tag)-来标记浏览过的网络对象,并将这些标记进行共享。研究表明用户使用的标签词在很大程度上可以反映网页的主题[1],直观上会对检索产生积极效果。
在学术界,目前大量研究集中在标注数据的分析上,如类别、数量以及统计特征,而利用标注信息提高检索效果只有少量探索[2-4]。其中,一些方法尝试利用标签来扩充文档的向量表示,然后进行检索。这种方式虽然简单,但存在如下问题: (1)适用范围有限。该方法要求文档有足够的标注数据,而实际上大部分网页的标注是稀疏的。(2)表意失真。很多标签词来自多个词的组合,例如,“computer_storage”,这些组合词可以准确表达文档主题,但若将其看作普通词,则会降低其对主题的表达能力。(3)跨语言的问题。网络上的标签词往往来自多种语言,词形不同导致同义词会被看作多个词,从而降低标签关键词对文档的权重。
针对以上问题,我们提出将标签建模为高层类别加以利用的方法。一个基本想法是通过结合标签代表的用户分类知识与文档本身的统计信息来估计文档话题,然后用来平滑检索模型。这种利用标签数据分类属性进行检索的方法目前还没有被系统的研究过。具体地,该问题涉及到下列三方面子问题: (1)模型构建。(2)类别表示。是使用<标签、用户>二元组作为类别还是仅使用标签作为类别?(3)标签类别的权重。一篇文档可能包含多条标注信息,它们对文档的重要性是否需要区分及如何区分。
在本文中,我们首先提出TR-LDA模型,该模型认为相同标签类别下的文档在话题上存在一致性,基于该假设来对话题模型进行约束。在标签类别的表示上,我们考虑了两种方法,即是否融入用户因素。此外,我们还探索了不同标签权重的计算方法以及他们的效果。在实验部分,我们提出一种基于现有TREC评测的数据集构建方法。其中,文档集、查询和相关性判断来自Web Track任务,需要的用户标注数据来自Delicious[5]。实验结果表明,我们的方法可以显著提高检索效果,超过了目前已知最好的基于LDA的检索平滑方法[6],并且也要好于现有的利用标签关键词属性进行检索的方法。
本文的组织结构如下: 第2节介绍相关工作,第3节给出TR-LDA模型,第4节讨论基于TR-LDA的检索方法,第5节介绍评价过程与实验结果,第6节为结论。
2 相关工作
目前已经有不少的研究围绕标签数据展开。这些工作大致可以分为两类: 对标签数据的分析以及利用标签数据来做检索。
对于第一方面,文献[1]从数量和质量上对标签数据进行描述,总结了标签数据对检索可能有用的一些特征。文献[7]统计了标签与查询的分布,指出两者在词汇方面差异较大,这表明直接利用查询与文档标签词进行匹配的检索方法存在局限,至少召回率会受到影响。文献[8]根据用途定义了标签词的类别,并且发现对于网页数据,“话题型”及“资源型”的标签占大多数。文献[9]发现对于“流行”网页,即标注信息较多的网页,其上的高频标签词能最好体现文档主题,这说明从群体标注信息来挖掘共性知识的可行性。
对于第二方面,现有检索方法主要利用标签数据来估计网页重要度[3]或者估计文档模型[2]。网页重要度的估计一般利用用户、标签、网页构成的网络,而文档模型估计大部分是将标签建模为额外的词,只是建模方式存在细微差别。如文献[2]对标签词和文档词共用同一个话题生成词的分布,文献[10]则使用不同的分布,但上述方法都需要文档有大量的标注数据才能确保话题估计的准确性。
我们的建模方法部分受到文献[11]的启发。具体的,Mei等人提出基于网络结构对话题模型进行正则化的方法,该方法认为对于连接紧密的文档,其话题分布应该相近。通过定义两两文档之间的正则化项,同时最大化正则化项与似然函数,从而对话题模型进行约束。这里,我们提出的方法基于贝叶斯统计来表达标签类别的约束作用,相比于Mei的方法,TR-LDA可以更精细地刻画类别与文档的权重,并且需要的计算项更少。
3 基于标注类别的话题模型
在这一部分内容中,我们首先给出基于标签数据分类属性的话题模型,然后给出推导公式,最后讨论模型的实现细节,包括参数设置、更新以及计算上的简化。
3.1 TR-LDA生成模型
将标签建模为类别,那么被标注的文档在话题上应该与标签代表的话题存在一致性。此外,除使用标签作为类别,还可以使用<用户、标签>作为类别,这两种表示方式对模型估计的效果会在后边进行讨论,这里先简单使用名称“标注类别”来指代他们。
假设D为文档集合,对每篇文档d∈D,Cd为文档d的标注类别,那么Cd的集合构成了文档集上的类别集合C。注意到C中的一部分类别会包含多篇文档,我们使用Dc来表示和特定类别c相关联的文档集合。
为了反映类别的作用,我们认为文档词有一部分,假设比例为1-λ(λ≤1),是从类别生成,另一部分λ从文档本身生成。具体的,假设文档有Nd个词,那么(1-λ)Nd个词从标注类别生成,而剩下的λNd个词由文档产生。这个过程中,每个文档词对应的变量实际上被替换为两个独立的变量,并且它们的出现次数为λ和(1-λ)。类似的,我们可以进一步把标注类别生成的变量切分为Cd个具体类别对应的变量,类别c对应的变量的出现次数为μdc。通过上面的切分,每个观测词单元被替换成1+Cd个变量,并且假设它们之间是相互独立可交换的。生成过程如图1和表1所示。

图1 TR-LDA的图模型

1:对每个标注目录c∈Cd:生成θc~Dirichlet(•|αc)2:对每篇文档d∈D:3: 生成θd~Dirichlet(•|αd)4: 对每一个词n∈1,…,Nd5: 从文档抽样λ次:zdn~Multinomial(•|θd)wdn~Multinomial(•|β,zd)6: 对每个标注类别c∈Cd:7: 从类别c抽样(1-λ)μdc次:8: zdn~Multinomial(•|θc)wdn~Mul-tinomial(•|β,zdn)
在TR-LDA模型中,λ和μ作为参数需要提前指定。这两个参数控制我们对标注类别的相信程度,详细设置会在3.3节进行讨论。其他参数可以通过文档集合进行推导。实际上,LDA可以看作是TR-LDA的一个特例,即λ=1的情况。
3.2 TR-LDA模型的推导框架
给定参数Θ={αc,αd,μd,λ,β},词w的似然函数为
整个文档集上的似然函数为
P(D|Θ)=
dθd,θc
(2)
其中
我们希望通过最大化似然(2)来得到后验分布P(θd,θc,z|C,D,θ)及β。前者用来估计文档话题,而后者用来估计话题特定的词分布。这里我们采用变分法来估计后验分布,具体的,算法使用的近似分布,如式(3)所示。
Λ={γc,γd,φdn|c∈C,d∈D,dn∈1,…,Nd}为变分参数,其中γc,γd为Dirichlet参数,φdn为Multinomial参数。基于EM算法可以得到如下的参数更新式。
E-step
M-step
3.3 TR-LDA模型的实现
3.3.1 λ及μd的设置
1-λ控制从标注类别抽样文档词的比例,如果λ较小,那么标注类别对应的词生成概率对似然函数的影响较大,从而导致学习到的话题模型更多反映类别含义。然而考虑到标注类别的质量,我们倾向于设置大的λ,认为话题模型主要还是依赖于文档集的统计信息。μdc控制文档词从类别c抽样的比例,显然μdc应该与类别c对文档d的重要性相一致。对于μdc计算,我们首先确定标注类别对文档的权重,然后使用L1 norm来进行归一化。考虑到之前标注类别的两种表示方法,我们会在后面实验中重点考察下面几种权重计算方法(表2)。

表2 TR-LDA中标注类别表示及权重计算
3.3.2 参数更新
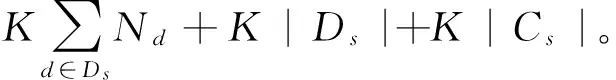
基本的想法是通过移除不必要的文档—标注连边,从而减小最大子图的规模。值得注意的是,被去掉的连边不参与推导,我们认为这样的近似对模型学习影响不大。具体的,为了确保切分后的子图小并且均衡,我们采用NCut的切分方法[12],切分之后再学习相关参数。
另外,对于不包含标注信息的文档,认为所有文档词完全从文档本身抽样,在更新(4)时设置λ=1。
4 基于TR-LDA的文档检索
经典的语言模型使用查询似然来对文档进行排序。具体的,对于查询Q,文档d的打分使用式(8),其中q为查询词,P(q|d)是估计的文档模型。
显然P(q|d)的估计是语言模型的关键,之前大量研究表明平滑对P(q|d)的估计至关重要。平滑方法包括最基本的Jelinek-Mercer和Dirichlet平滑,像后来的基于聚类与话题模型的平滑可以取得更好的效果[6,13],但最近的研究也发现更复杂的完全基于统计的话题模型如PAM等很难继续提高检索效果[14]。实际上这也是我们工作的出发点,即我们认为需要融入相关知识,以使得估计的话题模型粒度与人的理解更接近,从而提高检索效果。基于话题模型的平滑一般采用式(9)的线性组合方式。

(1-τ)Ptp(w|d)
(9)
Ptp(w|d)=EP(θd,z|D)[P(w|z)P(z|θd)·
P(θd|d)]
(10)
其中,Pml(w|d)、P(w|coll)是词w在文档d及文档集合coll中的最大似然估计,δ是Dirichlet先验,τ作为线性参数控制精确的词匹配与不精确的通过话题匹配的比例。Ptp(w|d)的计算依赖于选择的话题模型,这里我们使用TR-LDA来估计,计算公式如式(11)所示。
5 实验
5.1 数据集构建
目前没有公开的、用于评价基于标签的检索方法的数据集,为此我们需要自行构建。这样的数据集需要包含两个部分: 文档集合及文档集上的标注信息;查询集合及相关性判断。实际上TREC评测唯一不能提供的是标注信息,而其他如文档、查询、相关性判断都可以复用。为此我们选择TREC评测的Web Track 2009及Web Track 2010任务来构造我们数据集,主要因为这两个任务使用的文档集是ClueWeb09[16],而ClueWeb09是2009年1~2月对网络的爬取结果,这可以确保其中的部分网页能够在目前的Delicious中找到标注信息。具体的,我们使用ClueWeb09的“CategoryB”文档集,但该数据集包含的网页数目大约为5 000万,我们不可能对每篇文档都查找其标注信息,参考相关工作中的实验规模,我们采用下面一种“反向”的方法来构造检索用的数据集。
1) 出现在相关性判断中的文档(相关文档和不相关文档)对应的URL被输入到Delicious,来查找关联的标注信息。假设相关文档集合D(rel)对应的标注信息为A(rel),不相关文档集合D(nonrel)对应的标注信息为A(nonrel),这里标注信息是指<用户、标签>二元组。实际上只有部分文档可以找到标注信息,我们定义Dna∈D(rel)+D(nonrel)为不包含任何标注信息的文档集合。
2)A(rel)、A(nonrel)中的标注信息被再次输入到Delicious来获得相关的网页集合DE(rel)、DE(nonrel),这些网页集合对应的新的标注信息被用来更新A(rel)+A(nonrel)。
3)DE(rel)、DE(nonrel)与“CategoryB”的文档集进行求交操作,获得的交集为DC(rel)、DC(nonrel),显然DC(rel)与DC(nonrel)为“CategoryB”的子集。不在DC(rel)+DC(nonrel)中的文档对应的标注信息被从A(rel)+A(nonrel)中删掉。
现在我们定义两类数据集:
R1={DC(rel)+D(rel)+DC(nonrel)+D(nonrel)-Dna,A(rel)+A(nonrel)};
R2={D(rel)+DC(nonrel)+D(nonrel),A(rel)+A(nonrel)}。
我们计划使用R1来评价TR-LDA话题模型,使用R2来评价基于TR-LDA检索方法。R1和R2的区别在于R1中每篇文档都有标注信息,而R2中的部分文档没有标注。此外,R1包含与相关文档有相同标注信息的文档,即DC(rel),但R2不包含。这是因为DC(rel)可能包含相关文档(与D(rel)在标注上存在关联),而我们不希望进行额外的相关性判断,所以将DC(rel)从R2中移除。尽管DC(nonrel)也可能包含相关文档,但这种情况的可能性较低,我们认为所有出现在DC(nonrel)中的文档都不相关。
具体地,我们构建了三个数据集: (1)基于Web Track2009构建了09R1及09R2; (2)基于Web Track2010构建了10R2; (3)Web Track及构造的数据集的统计信息见表3、表4。
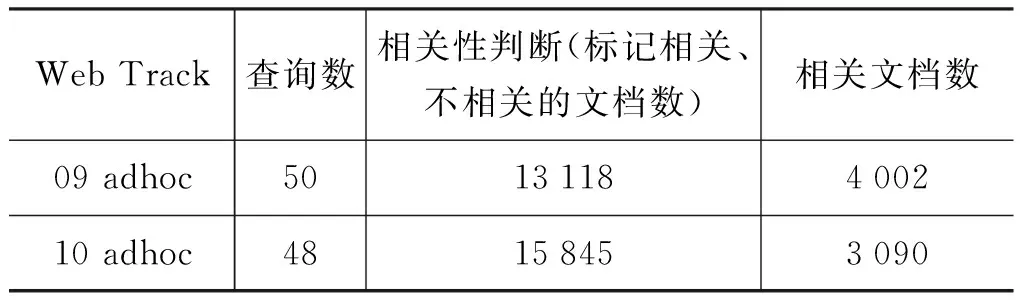
表3 Web Track adhoc任务的统计信息
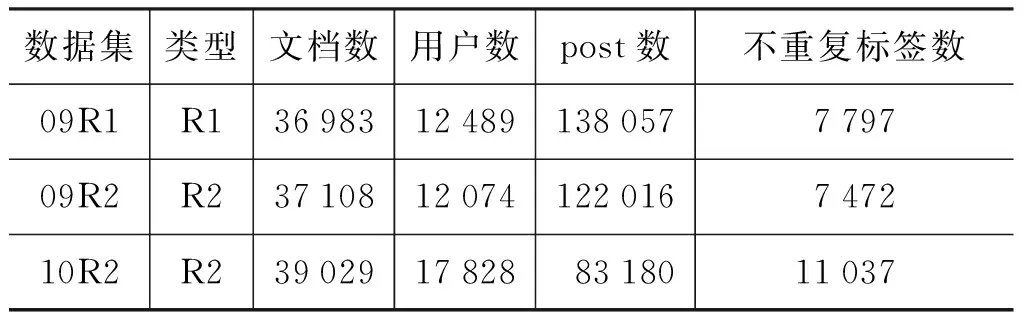
表4 构造的数据集的统计信息
5.2 评价TR-LDA的预测性能
评价话题模型最常用的方法是在训练集上学习相关参数,在测试集上计算困惑度(perplexity),一般困惑度越小,话题模型的泛化能力越好。对于一个测试集DT,困惑度的计算使用式(12),其中,P(wd)是估计的话题模型在测试文档d上的似然。

(12)
这里我们要比较TR-LDA与LDA的预测性能,另外衡量不同标注类别的表示及加权方法对TR-LDA的影响。
具体地,我们使用09R1数据集,为了精确度量预测性能,没有采用图切分方法,而是将09R1中最大子图去掉。上面的操作产生一个新的数据集,该数据集包含9 149篇文档。我们抽取其中994篇 (大约10%)作为测试集,剩下的作为训练集。对于TR-LDA,μd按照前面3.3.1节中的三种方法来计算;λ的取值从0.1到1,我们发现当λ为0.8时,TR-LDA在训练集上的性能最好。
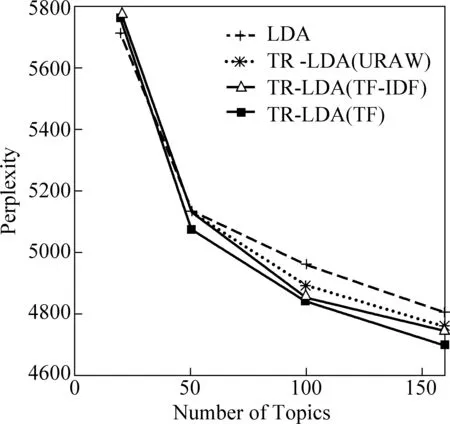
图2 LDA与TR-LDA在测试集上的困惑度(λ=0.8)
图2给出了各个方法在指定不同话题数时,模型在测试集上的困惑度值。从该图中,我们可以看到:
(1)TR-LDA要优于LDA,对于不同的μd计算方法,结论是一致的。
(2)使用标签作为标注类别,并且使用TF方法来计算μd,TR-LDA(TF)获得的性能最好。该方法实际上利用群体的标注统计信息来对标签进行加权,可以有效地降低如“toread”等与主题无关的标签的权重,因为不同用户在噪音标签上刚好一致的可能性较低。TR-LDA(TF-IDF)性能相对较低可能是因为文档特有的标签词被赋予高的权重,而这样的标签词并没有足够的文档来精确估计其话题分布,从而导致偏差。使用<用户、标签>作为标注类别,使用均匀分布的μd计算效果要差一些(TR-LDA(URAW)),说明对标注类别进行区分的重要性。
综上,由于TR-LDA(TF)在性能预测上的优势,我们使用该实现来完成后面基于TR-LDA的文档检索实验。
5.3 检索实验
在本节中,我们重点考察基于TR-LDA的检索方法(TBDM),目标回答下面两个问题: (1)标注信息能否提高检索效果;(2)TBDM方法是否要好于现有的其他基于标签数据的检索方法。
为了回答第一个问题,我们将TBDM与下面几种方法进行比较: (1)使用Dirichlet平滑的语言模型(LM);(2)使用LDA平滑的语言模型(LBDM)[6]。实际上LBDM是目前已知的最好的平滑方法,性能与伪相关反馈非常接近。为了回答第二个问题,我们对比了TBDM和下列三种方法: (1)将标签词作为额外的文档词来表示文档,使用LDA来估计话题模型,然后再平滑语言模型;(2)WT-LDA;(3)WT-QDAU+。其中(2)(3)来自文献[2],也是和我们最相关的工作。具体地,在WT-LDA与WT-QDAU+中,文档(查询)表示为词与话题的拼接,如式(13)、(14)所示。其中,U(d)为文档d的标注用户集合,δx正比于用户x给出的标注数,P(topic|d),P(topic|x)通过文中所提的UCA话题模型推导得到,而UCA实际等价于LDA,区别在于用户的所有标签集合被作为额外的伪文档来参与学习。最后文档得分通过计算查询与文档的KL散度得到。
09R2作为训练集来获得最优参数,10R2用来测试最优参数的效果。运行对应的Web Track任务的查询,每次运行结果的前100篇文档用来做评价,没有出现在相关性判断中的文档都认为是不相关的。性能评价指标采用MAP(Mean Average Precision),整个实验过程是参照文献[6]中的实验进行的,包括参数选择等。
5.3.1 话题模型估计
上面提到的检索方法除LM外都需要估计一个话题模型。具体地,LBDM、LBDM-T、WT-LDA以及WT-QDAU+依赖于LDA的估计,TBDM依赖于TR-LDA的估计。这里我们选择LBDM及TBDM为代表来研究其中话题模型估计对检索的影响,其他方法与之类似。
根据之前5.2节的结论,使用标签作为类别,使用TF来计算μd,TR-LDA可以取得最好性能。这样做去掉了用户因素,话题模型的估计基于新的文档—标签二分图进行。出于计算上的考虑,我们需要将这样的二分图切分成小的、均衡的子图。为了选择一个合理的切分数,我们观察随着切分数的变化,最大子图的文档数、标签数的变化,如图3所示。最终09R2的切分数设为20,10R2的切分数设为50。切分之后,09R2、10R2有标签的文档比例分别为68%及 63%;在推导话题模型参数时,最多大约有7 000篇文档需要驻留在内存中。
下面四个环节会对检索产生影响:
1) 推导算法的迭代次数。一般来讲,迭代次数越多,学习到的话题模型越接近于收敛。然而更好的话题粒度可能在迭代中产生,而非出现在收敛后的结果里。为此,我们观察随着迭代数的变化,检索性能的变化,如图4所示。可以看到迭代数设为5,一般检索性能最好。
2) 局部最优化问题。尽管基于EM的推导算法很快,但是学习到的话题模型是局部最优值。为此,对于给定的话题数,我们使用不同的初始值,重复10次话题学习及对应的检索,10次的MAP平均值作为最后的评价指标。图4给出10次随机的LBDM、TBDM运行结果。可以看到,TBDM、LBDM的MAP取值区间分别为(0.235,0.25)及(0.22,0.24)。

图3 最大子图中的文档数、标签数 VS 切分数
3) 话题数的设置。话题数决定学习到的话题粒度。在实验中,为了选择最优话题数K,我们设置K的变化范围为10~80,步长为10,来观察对应的MAP值。当K=20时,LBMD、TBDM的效果最好。
4)λ参数。λ控制文档词被从文档源抽样的比例,之前的分析提到λ应该接近于1。这里我们设置λ的变化范围为0.6~1.0,步长为0.05。当λ=0.85时,TBDM效果最好(图5)。
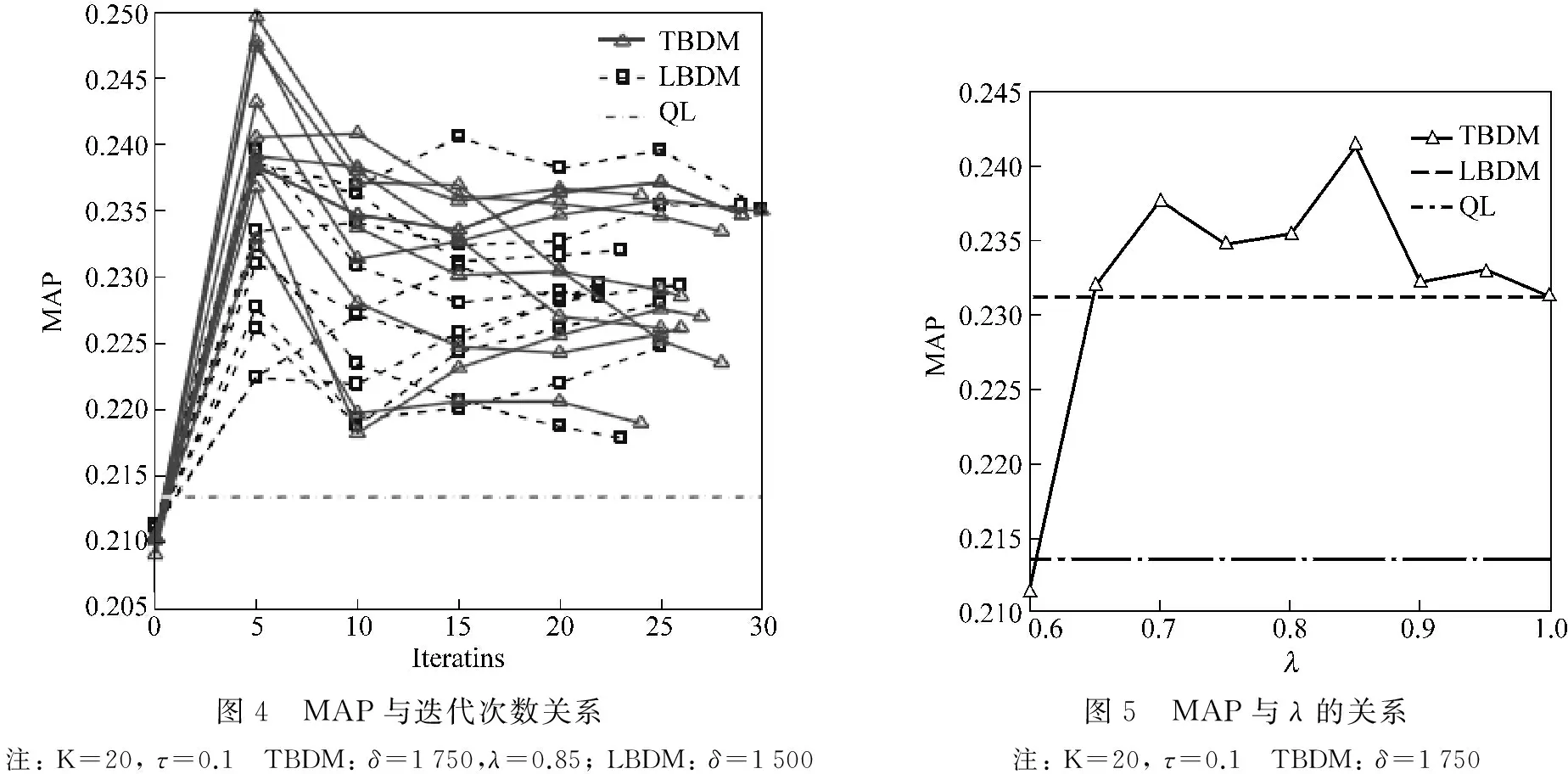
图4 MAP与迭代次数关系注:K=20,τ=0.1 TBDM:δ=1750,λ=0.85;LBDM:δ=1500图5 MAP与λ的关系注:K=20,τ=0.1 TBDM:δ=1750
5.3.2 检索性能比较
基于话题模型的检索(式9)有两个参数δ和τ需要提前设置,为了选择最优参数,设置δ的变化范围为250~2 000,使用250作为步长;τ的变化范围为0.1~0.9,使用0.1作为步长。通过在09R2上比较不同的δ、τ组合产生的检索结果,我们发现τ最优取值为0.9,而δ稍微有点区别,对于LBDM,δ最优值为1 500,对于TBDM,δ最优值为1 750。
QL、LBDM、TBDM在09R2上的检索性能在表5中给出,可以看到,我们所提的TBDM方法在不同的召回率(recall)级别上准确率(precision)要显著好于LBDM及QL。利用在09R2训练得到的参数,在10R2上进行同样的实验,检索性能如表6所示。同样, TBDM要优于LBDM及QL。值得注意的是,在10R2上,LBDM性能并没有显著优于QL,说明在某些情况下,完全基于统计的话题模型对检索效果有限。以上的结果证明了合理利用社会化标注信息可以提高检索效果。
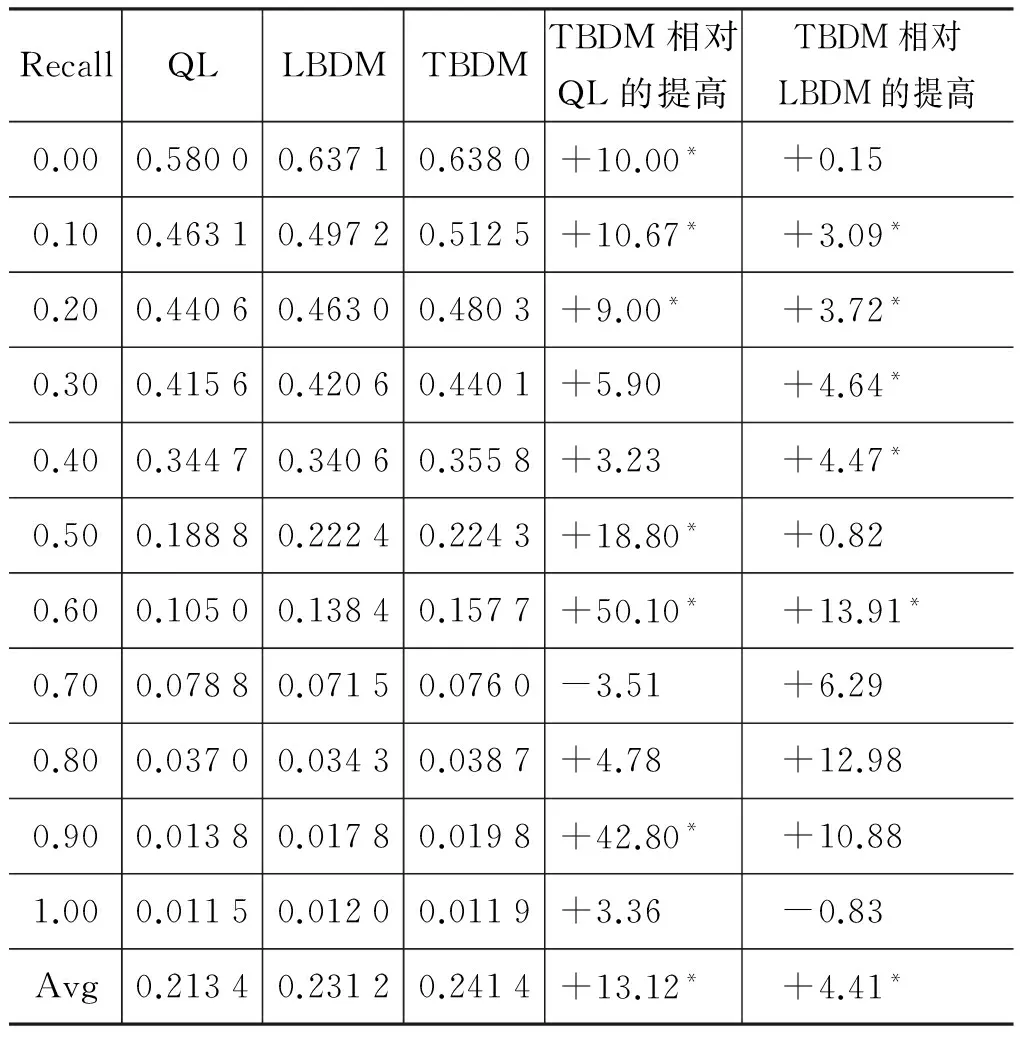
表5 QL、LBDM、TBDM在09R2上的检索结果
*表示显著提高,使用one-tailed Wilcoxon signed-rank test(pvalue<0.05)
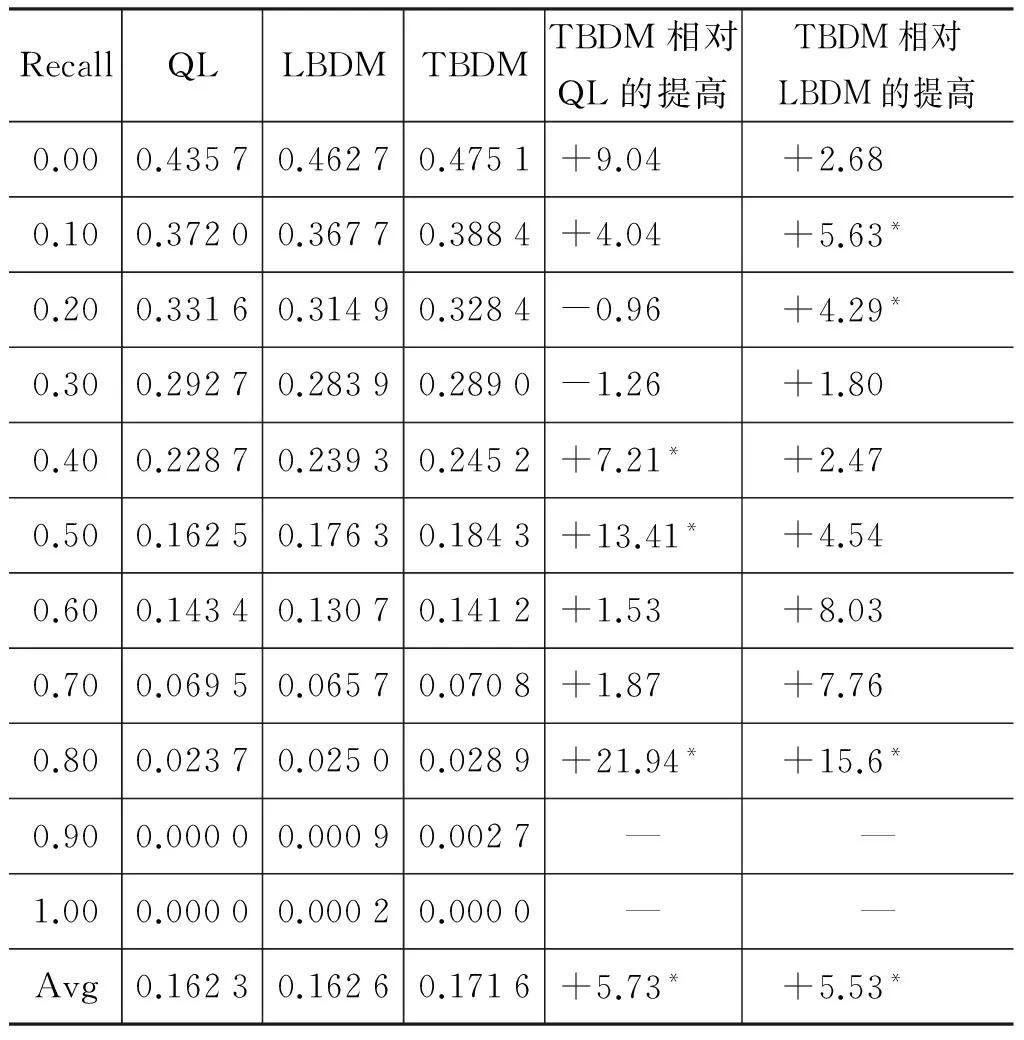
表6 QL、LBDM、TBDM在10R2上的检索结果
*表示显著提高,使用one-tailed Wilcoxon signed-rank test(pvalue<0.05)

表7 LBDM、LBDM-T、WT-LDA、WT-QDAU+及TBDM的比较
对于LBDM-T、WT-LDA、WT-QDAU+涉及到的话题模型估计,我们采用与LBDM类似的方法在09R2上进行调参,发现最优的话题数、迭代次数与LBDM相同。此外,LBDM-T中的参数δ、τ的最优取值与LBDM中的δ、τ取值相同。WT-LDA,WT-QDAU+最优性能在λ1=λ2=0.9中取到。这些方法的MAP值在表7中给出。可以看到,LBDM-T与LBDM结果相当,说明将标签作为额外的文档词很难发挥标注信息的作用。TBDM性能显著好于WT-LDA以及WT-QDAU+,说明我们将标签建模为类别的方法在检索上的优势。
6 结论
本文提出了一种利用社会化标注的分类属性来做检索的方法。首先给出话题模型TR-LDA,该模型可以有效融入用户知识,降低标注稀疏性的影响。在检索阶段,使用TR-LDA来平滑语言模型。实验表明,基于TR-LDA的检索方法要显著优于基于LDA的检索方法,也要优于将标签建模为关键词的检索方法。
[1] P Heymann, G Koutrika, H Garcia-Molina. Can social bookmarking improve web search.[C]//Proceedings of WSDM’08. New York: ACM, 2008: 195-206.
[2] D Zhou, J Bian, S Zheng, et al. Exploring social annotations for information retrieval[C]//Proceedings of WWW’08. New York: ACM, 2008: 715-724.
[3] S Bao, G Xue, X Wu, et al. Optimizing web search using social annotations[C]//Proceedings of WWW’07. New York: ACM, 2007: 501-510.
[4] S Xu, S Bao, B Fei, Z Su, et al. Exploring folksonomy for personalized search[C]//Proceedings of SIGIR’08. WWW’07. New York: ACM, 2008: 155-162.
[5] AVOS Systems, Inc. Delicious.com - Discover Yourself![OL]. [2010-12-10]. http://www.delicious.com/
[6] X. Wei, W. B. Croft. LDA-based document models for ad-hoc retrieval[C]//Proceedings of SIGIR’06. New York: ACM, 2006: 178-185.
[7] M. J. Carman, M. Baillie, R. Gwadera, et al. A statistical comparison of tag and query logs[C]//Proceedings of SIGIR’09. New York: ACM, 2009: 123-130.
[8] K. Bischoff, C. S. Firan, W. Nejdl, et al. Can all tags be used for search?[C]//Proceedings of CIKM’08. New York: ACM, 2008: 193-202.
[9] H. Halpin, V. Robu, H. Shepherd. The complex dynamics of collaborative tagging[C]//Proceedings of WWW’07. New York: ACM, 2007:211-220.
[10] D. Ramage, P. Heymann, C. D. Manning, et al. Clustering the tagged web[C]//Proceedings of WSDM’09. New York: ACM, 2009: 54-63.
[11] Q. Mei, D. Cai, D. Zhang, et al. Topic modeling with network regularization[C]//Proceedings of WWW’08. New York: ACM, 2008: 101-110.
[12] J. Shi, J. Malik. Normalized cuts and image segmentation[J].IEEE Trans. Pattern Anal. Mach. Intell., 2000, 22:888-905.
[13] X. Liu, W. B. Croft. Cluster-based retrieval using language models[C]//Proceedings of SIGIR’04. New York: ACM, 2004: 186-193.
[14] X. Yi, J. Allan. Evaluating topic models for information retrieval[C]//Proceedings of CIKM’08. New York: ACM, 2008: 1431-1432.
[15] NIST. TREC 2010 Web Track Guidelines[OL]. [2010-07-07]. http://plg.uwaterloo.ca/~trecweb/2010.html.
[16] The ClueWeb09 Dataset[OL]. [2012-0-12]. http://boston.lti.cs.cmu.edu/Data/clueweb09/.
