统计机器翻译中一致性解码方法比较分析
2013-04-23段楠,李沐,周明,
段 楠,李 沐,周 明,
(1.天津大学 计算机科学与技术学院,天津 300072;2.微软亚洲研究院,北京 100080)
1 引言
近十年来,随着计算机软、硬件技术的不断进步和对互联网大规模双语数据的有效获取,机器翻译研究迅猛发展。其中,基于统计的机器翻译(statistical machine translation,SMT)方法显示出巨大优势,并在翻译性能上牢牢占据主导地位。
给定源语言输入,单个SMT系统在翻译过程中,往往能够生成多条不同的目标语言翻译候选。但受到翻译模型本身的制约,按照模型打分排名最高的翻译候选通常并不是全部翻译候选中的最优结果。此外,基于不同翻译模型SMT系统的大量涌现,又进一步扩展了相同源语言输入能够对应的目标语言翻译候选集合。因此,如何有效地利用不同翻译候选中所包含的信息来获取更优的翻译结果,已经成为近年来机器翻译研究者们关注的一个热点课题。
本文使用“一致性解码”(consensus decoding)概念来概括上述课题所对应的若干种解决方法,这些方法的共性在于: 能够利用不同翻译候选中所包含的“一致性”信息,通过重排序或重组合已有翻译候选的方式来获取更佳的翻译结果。根据对SMT系统翻译结果使用方式的不同,我们将一致性解码方法大体分为如下两大类。
1)基于翻译假设重排序的一致性解码方法。在此类方法中,一致性解码模型并不会改变SMT系统所给出的输出结果,而是利用特定的重打分技术,对不同的翻译假设(translation hypothesis)进行重排序(reranking),并选取排序后排名最高的翻译假设作为最终翻译结果。代表性工作主要包括最小贝叶斯风险解码、模型融合和协作解码等。
2)基于翻译假设重组合的一致性解码方法。在此类方法中,一致性解码模型通过重新组合来自不同SMT系统的翻译假设片段构建新的翻译候选空间,并从中选取最终翻译结果。与第一类方法相比较,此类方法能够生成已有翻译假设集合之外的新的翻译候选,对翻译结果的生成能力更强,因此能够得到的翻译性能提升上限也更大。代表性工作主要包括词汇级系统融合和翻译假设混合解码等。
上述两大类方法的根本区别在于是否改变了已有的翻译候选集合。例如,句子级系统融合和词汇级系统融合虽然同属于系统融合方法,但前者仅仅对翻译候选集合进行重新排序,而后者却能够通过构建混淆网络生成已有翻译候选集合之外的翻译结果,因此两种方法分属一致性解码方法的不同两类。
在本文余下部分,第2节和第3节分别介绍两类一致性解码方法,包括代表性工作和数学模型等;第4节给出本文所列举的典型方法在大规模中—英机器翻译评测数据上的评测结果,并比较不同方法间的性能差异;第5节总结全文,并对未来研究方向进行展望。
2 基于翻译假设重排序的一致性解码
该类方法的运作流程可以概括为下述三步。
1) 给定源语言输入,(单个或多个)SMT系统首先给出多条目标语言翻译候选;
2) 基于特定的重打分函数(如贝叶斯风险、翻译结果相似度等),对全部翻译候选进行打分并重新排序;
3) 选取重排序后得分最高的翻译候选作为最终翻译结果。
在接下来的小节中,我们将对该类方法中的典型研究工作分别予以介绍。
2.1 最小贝叶斯风险解码

由式(1)可以看出,MBR模型主要由三部分组成。
(1) 假设空间(hypothesis space)εh和证据空间(evidence space)εe: 一般来讲,εh和εe可以是不同集合,但在机器翻译的应用场景中,εh和εe往往等同于SMT系统所输出的翻译假设空间(F)。(F)的数据存储形式可以为n-best列表、翻译网格(translation lattice)和翻译超图(translation hypergraph)。Kumar和Byrne[1]最早在n-best列表上应用MBR解码,但由于n-best列表中所包含的翻译候选数目极为有限,且相似度较高,因此翻译质量提升相对有限;Tromble等人[2]将MBR解码的应用范围从n-best列表扩展到包含翻译候选更多的翻译网格,并取得更多的性能增长,但解码效率偏低;Kumar等人[3]进一步将MBR解码的应用范围扩展到翻译超图,并提出更为有效的解码算法。
(2) 损失函数(loss function)L(E′,E): Kumar和Byrne[1]提出词汇级(lexical)、目标语言句法树级(target parse-tree)和双语句法树级(bilingual parse-tree) 3种不同的损失函数;Ehling等人[4]提出直接使用翻译译文质量自动评测指标BLEU得分[5]定义损失函数为L(E′,E)=1-BLEU(E′,E);Tromble等人[2]将标准BLEU得分经过泰勒级数展开后得到的对数—线性形式作为标准BLEU得分的一个近似, 并将其作为增益函数G代替损失函数L。这样就将最小化贝叶斯风险转化为最大化增益函数的形式,如式(2)所示:
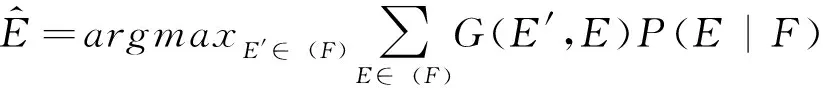
(2)
(3) 概率分布P(E|F): 用来表示在当前的翻译假设空间(F)中,将源语言句子F翻译为目标语言句子E的概率大小,其计算方式如式(3)所示:
(3)
其中,S(E,F)为翻译系统对翻译候选E给出的模型得分。当翻译模型得分已知时,该分布可由模型得分归一化获得;当翻译模型得分未知时,则可假设该分布服从均匀分布。
MBR解码适用于任意SMT系统,但由于同一翻译模型给出的翻译假设之间的相似度较高,导致不同翻译假设对应的贝叶斯风险得分区别度不大,因此,该方法在翻译性能上所能获得的提升相对不大。此外,由于不同翻译模型对翻译候选的评分标准并不一致,MBR解码并不能直接应用于多个SMT系统的翻译结果之上。
针对传统MBR解码仅能应用于单个SMT系统的不足,Duan等人[6]提出基于混合模型(mixture model-based)的MBR解码方法,将MBR方法的应用框架从单个SMT系统扩展到多个SMT系统。该方法的数学模型表达如式(4)所示:


(4)
与基于单个SMT系统的MBR解码相比,该方法的特点在于:
(1) 条件翻译概率P(E|F)不再由任何单个SMT系统的输出结果决定,而是由多个SMT系统所生成的翻译假设空间共同决定,其计算公式为式(5)所示:
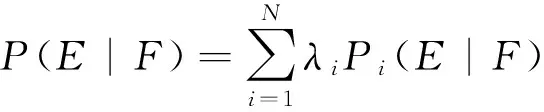
(5)
其中,Pi(E|F)为E在第i个系统输出的翻译假设空间i(F)上计算得到的条件翻译概率,λi为第i个系统对应的系统权重,它满足如下两个条件: 0≤λi≤1和
(2) 将多个SMT系统给出的全部翻译候选集合作为系统输入,搜索空间如式(6)所示:
基于混合模型的MBR解码方法泛化能力更强,能够使用到的目标语言翻译候选数目更多。不同SMT系统的性能差异通过系统权重参数λ来刻画,这样使得条件翻译概率分布P(E|F)的计算更为准确,按照最小化贝叶斯风险准则选取出来的最终译文质量也就更高。传统MBR解码可以看成是该方法在N=1情况下的一个特例。
2.2 模型融合
DeNero等人[7]提出模型融合(model combination,MC)方法: 给定源语言句子F,多个SMT系统首先独立地进行解码并输出各自的翻译假设空间;然后,将多个翻译假设空间的根节点直接连接到一个统一节点,从而构成一个更大的、合并的翻译假设空间;最后,对于该合并后的空间中所包含的每一条翻译候选,使用一个对数—线性模型对其进行打分,并选取得分最高的翻译候选作为最终翻译结果。该对数—线性模型由4类特征按式(7)形式组成:

与基于混合模型的MBR解码方法相比,模型融合的最大区别在于: 它没有显式地设定系统权重参数去区分不同SMT系统的性能差异,而是通过MERT算法自动调节不同翻译模型对最终翻译结果的贡献度。
2.3 协作解码
Li等人[8]提出协作解码(collaborative decoding,CD)方法,该方法能够利用多个SMT系统提供的一致性统计量,在解码过程中直接作用于任意源语言序列所对应的中间翻译结果,并能够在一定程度上避免更优的局部翻译假设被较早剪枝的问题。
给定源语言句子F和K个SMT系统{dk},k(F)表示dk对F给出的翻译假设空间,第m个解码器在协作解码过程中,使用如下准则选取翻译结果,如式(8)所示:
在协作解码过程中,每个成员系统并不能直接利用其他成员系统生成的翻译结果,但评分函数Fm(E)却基于全部成员系统给出的翻译假设空间进行计算,其数学展开式为式(9):
其中,φm(F,E)表示dm对翻译假设E给出的模型得分,ψk(E,k(F))表示E基于翻译假设空间k(F)计算得到的一致性分数,该分数由一组一致性特征经线性加权计算获得,如式(10)所示:
每个hk,l(E,k(F))对应E基于k(F)计算的一个一致性特征,λk,l为该特征对应的特征权重。在协作解码中,hk,l(E,k(F))通过选取不同的一致性量度Gl,经式(11)计算获得:
P(E′|dk)表示翻译候选E′由系统dk给出的条件翻译概率,Gl(E,E′)为当前翻译E与翻译候选E′计算的一致性量度,该量度的计算分为两类:
• n-gram一致性量度(agreement measure):
(12)
• n-gram差异性量度(disagreement measure):
(13)
协作解码的特点在于: 它能够在解码过程中对局部搜索空间进行重排序,而不是作为后处理模块在解码全部完成后进行,这样能够在一定程度上避免更好的局部翻译结果被过早剪枝。协作解码可以看作是利用所有参与系统给出的翻译候选中所包含的一致性信息,来对每个参与系统进行翻译假设重排序。虽然这样做并不能改变参与系统对翻译结果的生成能力,但在一定程度上使得更好的局部翻译候选被最终保留。由于每个参与解码的SMT系统均可以输出一组翻译结果,因此,在协作解码完成之后,还可以通过系统融合获取更大的性能提升。
2.4 其他的一些方法
Li等人[9]提出变化解码(variational decoding),该方法使用基于n-gram的概率分布q(E)去近似条件翻译概率分布p(E|F),进而对整个翻译假设空间进行重排序。p(E|F)和q(E)的相关程度使用KL距离进行刻画。变化解码与MBR解码源于不同的初衷,但对统计机器翻译任务而言,最终推导出的决策准则极为相似,均为基于n-gram一致性特征的线性组合。因此,该方法在模型上的优缺点与MBR解码大体相同。
Duan等人[10]提出基于特征子空间(feature subspace)的系统融合,该方法将任意基于对数—线性模型的翻译系统看成基准系统,并将其包含的特征集合作为特征全集;每次通过选取特征全集的一个特征子集来构建一个新的翻译子系统;对于源语言输入,基准系统和多个翻译子系统分别对其进行解码,并给出各自的翻译候选;最后,一个独立的一致性解码模型用来对所有翻译假设进行重排序,并从中选取最终翻译结果。特征子集方法的优点在于: 较之重新实现一个新的翻译模型,利用特征子集构造翻译子系统更为快速、简便,而且多个翻译子系统的引入扩大了一致性解码的搜索空间,因此性能上也比传统MBR解码更为有效。
DeNero等人[11]提出针对翻译森林(translation forest)的一致性解码算法,该算法主要从效率角度对一致性特征的计算进行优化;在此基础上,Paul等人[12]提出改进的参数训练算法。
Rosti等人[13]提出句子级系统融合方法: 该方法对参与融合的每个翻译候选进行置信度估计,并将其与语言模型、翻译长度惩罚等特征进行线性加权来对翻译候选进行重打分。但由于翻译候选置信度估计所使用的函数定义主观性过强、参数过多,导致融合效果不如MBR解码,因此该方法并没有得到更进一步的发展。
3 基于翻译假设重组合的一致性解码
该类方法的运作流程可以概括为下述4步。
1) 给定源语言输入,多个SMT系统首先给出多条不同的目标语言翻译候选;
2) 利用已有翻译候选中包含的翻译片段,重新构造一个新的翻译假设空间;
3) 使用独立的解码模块对新建翻译假设空间中包含的翻译候选进行打分;
4) 选取得分最高的翻译候选作为最终翻译结果。
我们将着重介绍该类方法中的两个典型工作: 第一个是近年来使用最为广泛、效果也最为显著的系统融合;第二个是一致性解码方法最新的研究成果,翻译假设混合解码。
3.1 系统融合
目前国内外所采用的系统融合(system combination,SC)技术都是在Fiscus等人[14]提出的“投票策略减小识别器输出错误率(ROVER)”算法基础上发展起来的。最初ROVER是用于语音识别领域对多个识别器输出结果构造词转换网络(word transition network)的一种后处理技术,其核心思想在于通过将多个结果进行对齐,然后再投票重组识别结果,来产生一个得分最高的路径作为输出。ROVER开创了多系统融合技术的先河,极大地推动了多引擎识别器的研究和发展。随着统计机器翻译的发展,多种不同翻译模型的不断涌现,多系统融合技术也逐步被引入到统计机器翻译的研究领域,并取得了显著地成功。
Bangalore等人[15]将多个翻译假设进行短语级的编辑距离(WER)对齐来构造混淆网络(confusion network),但该方法仅允许单调(monotone)对齐操作而无法进行调序对齐操作;Jayaraman和Lavie[16]针对上述无法调序问题进行改进措施,他们使用启发式函数使得对齐能够非单调地进行,但由于所使用到的启发函数数目过多,导致融合后的错误率与具体采用的对齐准则相关性很大;Matusov等人[17]也提出一种非单调的混淆网络对齐方法,他们利用GIZA++工具对n-best列表训练词对齐,进而对假设翻译构造词转换网络并进行重排序;Sim等人[18]提出利用TER准则对n-best列表进行词对齐来生成混淆网络;Rosti等人[13]从句子级(word-level)、短语级(phrase-level)和词汇级(word-level)三个角度对多系统融合进行了深入研究,并提出三种不同的融合框架;He等人[19]提出基于隐马尔可夫(HMM)的对齐方法来构造混淆网络;Watababe和Sumita[20]提出基于混淆森林的系统融合方法等。
系统融合的优点在于: 它并不依赖于翻译系统的具体实现,任何类型的翻译系统输出结果都可以作为系统融合方法的输入;混淆网络的构造,允许生成已有翻译假设空间以外的新的翻译候选作为最终翻译结果,该类方法的生成能力更强。系统融合本身也存在一些缺点: 由于效率上的考虑,混淆网络的构建仅能使用包含翻译候选有限的n-best列表,而不能使用翻译网格和翻译超图等;需要额外的对齐模块来构建混淆网络,不同对齐模块往往会导致最终结果性能有所不同。作为一致性解码技术中最流行的方法,李茂西和宗成庆[21]已经对系统融合进行了详细的综述,这里就不再重复介绍。
3.2 翻译假设混合解码
Duan等人[22]提出翻译假设混合解码(hypothesis mixture decoding,HMD),将MBR解码和系统融合两类方法的优点有效地结合在一起。该解码方法分为以下两步完成。
1) 独立解码阶段: 多个翻译系统对源语言句子分别进行解码,并保留解码过程中生成的翻译假设空间;
2) 混合解码阶段: 首先,HMD通过使用相同源语言片段在不同翻译假设空间中对应的不同翻译结果重新组合翻译候选,并构建新的翻译假设空间;然后,使用对数—线性模型和一组与已有成员翻译模型无关的特征集合对新建翻译假设空间中所包含的翻译候选进行评分;最后,选取分数最高的翻译候选作为最终翻译结果:
在混合解码阶段,HMD可以使用两种不同的解码算法: 第1种算法基于括号转录文法(bracketing transducer grammar,BTG),任意相邻两个源语言片段对应的翻译结果通过顺序(straight)或逆序(inverted)的方式自底向上地合并。两个调序特征用来控制对顺序和逆序合并规则的使用;第2种算法基于同步上下文无关文法(synchronous context free grammar,SCFG),该算法采用自底向上的CKY解码方式,但与第1种算法不同,该算法通过使用一个独立的层次化翻译规则集合处理目标语言的调序现象,并合并来自不同翻译模型的目标语言翻译片段。该翻译规则集合采用Chiang等人[23]提出的层次化短语方法进行抽取。类似地,通过引入两个调序特征来控制对层次化规则和粘合规则(glue rule)的使用。
与之前工作相比,HMD一方面继承了MBR解码可以使用更多翻译候选的优点;另一方面,由于在混合解码过程中可以使用来自任意翻译假设空间中的翻译片段进行翻译假设重组合,因此该方法也同样具有系统融合方法的优点,即能够产生已有翻译假设集合之外的新的翻译结果。因此,HMD可以看作是对MBR解码和词汇级系统融合两类方法的统一。
4 实验与分析
本文通过在大规模中—英机器翻译评测数据上进行翻译质量评测,对本文中介绍的5种最具代表性的一致性解码方法进行性能比较和分析。
4.1 数据和基准系统
训练语料: NIST 2008中—英受限机器翻译评测中全部可以使用的双语语料被用来作为训练数据,包括510万中—英双语句对。双语词对齐由GIZA++工具提供,并使用intersect-diag-grow启发规则进行双向词对齐合并及优化。LDC Gigaword Version 3.0中所包含的新华语料英语部分被用来训练五元语言模型。
测试语料: NIST 2004测试集作为开发集用来训练基准翻译系统的模型参数和不同一致性解码方法的模型参数,NIST 2005、NIST2006和2008中的新闻语料部分作为测试集评测不同解码方法的翻译性能。翻译质量由不区分大小写的BLEU得分衡量。统计显著性使用Koehn[24]提出的重采样(re-sampling)方法进行计算。表1给出开发集和测试集的一些统计量。
基准系统: 本文使用两种SMT系统来实现不同的一致性解码方法,它们包括:
(1)PB: 基于短语(phrase-based)的SMT系统,该系统是对Xiong等人[25]方法的重现,使用基于最大熵的词汇级调序模型完成短语调序任务;

表1 开发集与测试集的一些统计量
(2)DHPB: 基于从串到句法依存树(string-to-dependency tree)的SMT系统,该系统是对Shen等人[26]方法的重现,将源语言字符串转化为目标语言句法依存树,并使用一个基于句法依存树的三元语言模型处理长距离依存现象。
两个基准系统使用的短语翻译表通过在全部双语语料上抽取获得,PB中使用的调序模型和DHPB中使用的层次化短语翻译表通过在特定的数据子集上抽取获得,该子集包括LDC2003E07、LDC2003E14、LDC2005T06、LDC2005T10、LDC2005E83、LDC2006E26、LDC2006E34、LDC2006E85和LDC2006E92。DHPB中使用的三元依存树语言模型通过在经Berkeley句法分析器分析后的语言模型训练数据上训练获得。
4.2 一致性解码方法
本文共实现5种不同的一致性解码方法用于进行对比实验:
1) 最小贝叶斯风险解码(MBR): 重现Kumar等人[3]提出的方法,使用单个SMT系统输出的翻译超图作为MBR解码的系统输入。我们使用MBRPB和MBRDHPB分别表示MBR解码在基准系统PB和DHPB上对应的评测结果;
2) 词汇级系统融合(SC): 重现He等人[19]提出的方法,使用两个基准系统输出的20-best列表作为系统输入,并采用隐马尔科夫对齐模型构造混淆网络;
3) 协作解码(CD): 重现Li等人[8]提出的方法,每个基准系统均输出协作解码后的(n-best列表)翻译结果(表示为CDPB和CDDHPB),并在此基础上,继续使用词汇级系统融合方法获取进一步的翻译性能提升(表示为CD-Comb);
4) 模型融合(MC): 重现DeNero等人[11]提出的方法,与协作解码不同,模型融合仅能够输出唯一一组翻译结果*由于基于混合模型的MBR解码与模型融合在理论框架及性能上均非常相近,因此在本文的实验中不再重复列举其评测结果。;
5) 翻译假设混合解码(HMD): 重现Duan等人[22]提出的方法,该方法允许使用两种基于不同文法的解码算法(表示为HMDBTG和 HMDSCFG),因此同样能够输出两组翻译结果,并在该基础上再次进行词汇级系统融合(表示为HMD-Comb)。
4.3 对比结果
本文将上述5种一致性解码方法在4组测试集上的BLEU得分对比列于表2。对于每组测试集,“^”表示该分数对应的一致性解码方法在统计上显著地好于基准系统PB,“*”表示该分数对应的一致性解码方法在统计上显著地好于基准系统DHPB。

表2 5种一致性解码方法实际翻译性能比较
通过分析表2中的测试结果,能够得到如下若干结论:
• 与基准系统(PB和DHPB)相比,全部5种一致性解码方法均能得到显著的翻译性能提升;
• 受限于单个SMT系统给出翻译候选间的较高相似度,传统MBR解码方法(MBRPB和MBRDHPB)所获得的性能提升较之其他4种方法而言相对较低;
• 基于多个SMT系统的3种一致性解码方法中: 词汇级系统融合(SC)和模型融合(MC)两种方法的翻译质量非常接近;而对与协作解码而言,虽然单个SMT系统(CDPB和CDDHPB)对应的输出结果并没有系统融合和模型融合效果好,但由于在这两组输出结果的基础上还可以再次使用系统融合(CD-Comb),因此协作解码能够获得的翻译性能提升在这3种方法中最大;
• 翻译假设混合解码方法(HMDBTG和HMDSCFG)能够组合来自不同SMT系统的翻译片段构建新的翻译候选,该方法在全部5种方法中对翻译结果的生成能力最强,获得的性能提升也最为显著。由于采用两种基于不同文法的混合解码算法,该方法同样可以通过系统融合获取更进一步的翻译性能提升(HMD -Comb)。
本文也给出不同一致性解码方法所对应的Oracle翻译结果在4组测试集上的翻译质量对比(表3),并以此来进一步比较和说明不同一致性解码方法的性能差异:
• 首先,根据不同一致性解码算法输出的翻译假设空间,我们从中抽取1000-best的翻译候选,用于进行Oracle翻译结果抽取;
• 然后,根据句子级BLEU得分,从每组测试集对应的1000-best翻译候选中抽取得分最高的翻译假设作为Oracle翻译结果;
• 最后,对不同解码方法在4组测试集上对应的Oracle翻译结果进行BLEU得分计算。

表3 5种一致性解码方法Oracle翻译性能比较
由表3可见,不同一致性解码方法所对应的Oracle翻译性能差异与表2中所对应的实际翻译性能差异大体一致。特别指出的是,由于HMD同时继承了MBR解码和系统融合两类方法的优点,其所对应的Oracle翻译质量也最好。
综上所述,MBR解码、协作解码和模型融合虽然能够使用包含翻译候选较多的翻译假设空间,但仅能对其中包含的翻译候选进行重排序而不能生成新的翻译结果;词汇级系统融合能够通过构造混淆网络来生成新的翻译结果,但受限于效率因素,该方法仅能使用包含翻译候选数目极为有限的n-best列表作为系统输入,这极大地限制了该方法在性能上的提升空间;翻译假设混合解码既允许使用翻译网格或翻译超图作为系统输入,又能够在混合解码过程中通过组合来自不同SMT系统的目标语言翻译片段生成新的翻译结果,因此该方法所能获得的翻译性能提升在本文所列举的所有一致性解码方法中最大。
5 总结及展望
本文对统计机器翻译中的一致性解码方法进行了系统分类,并对每类方法中的典型研究工作进行了回顾。通过大规模中—英机器翻译评测数据集上的对比实验,给出5种典型一致性解码方法的性能比较,并分析了不同方法的优缺点。随着基于不同翻译模型SMT方法的进一步深入发展,一致性解码作为利用不同翻译系统输出结果以获取更优译文质量的方法,必定受到持续的关注。
我们注意到,尽管一致性解码方法的有效性已被众多研究成果和评测比赛所证明,其仍具有较大的发展空间: 目前绝大多数方法均建立在连续的n-gram统计量基础之上,并未涉及任何结构化信息。随着基于句法的统计机器翻译模型研究热度的不断提升,如何将句法信息融入到一致性解码方法中去,将成为未来研究中的一个潜在课题;另一方面,如何提高已有方法的执行效率,也是一致性解码方法在实际应用中一个极具意义的研究课题。此外,我们也将尝试在其他语言对上,如日—英、中—日等,验证不同一致性解码方法的有效性。
[1] S Kumar, W Byrne. Minimum Bayes-Risk Decoding for Statistical Machine Translation[C]//Proceedings of the North American Association for Computational Linguistics. 2004: 169-176.
[2] R Tromble, S Kumar, F Och, et al. Lattice Minimum Bayes-Risk Decoding for Statistical Machine Translation[C]//Proceedings of the Conference on Empirical Methods on Natural Language Processing. 2008: 620-629.
[3] S Kumar, W Macherey, C Dyer, et al. Efficient Minimum Error Rate Training and Minimum Bayes-Risk Decoding for Translation Hypergraphs and Lattices[C]//Proceedings of the Association for Computational Linguistics. 2009: 163-171.
[4] N Ehling, R Zens, H Ney. Minimum Bayes Risk Decoding for BLEU[C]//Proceedings of the Association for Computational Linguistics Demo and Poster session. 2007: 101-104.
[5] K Papineni, S Roukos, T Ward, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the Association for Computational Linguistics. 2002: 311-318.
[6] N Duan, M Li, D Zhang, et al. Mixture Model-based Minimum Bayes Risk Decoding using Multiple Machine Translation Systems[C]//Proceedings of the International Conference on Computational Linguistics. 2010: 313-321.
[7] J DeNero, S Kumar, C Chelba, et al. Model Combination for Machine Translation[C]//Proceedings of the North American Association for Computational Linguistics. 2010: 975-983.
[8] M Li, N Duan, D Zhang, et al. Collaborative Decoding: Partial Hypothesis Re-Ranking Using Translation Consensus between Decoders[C]//Proceedings of the Association for Computational Linguistics. 2009: 585-592.
[9] Z Li, J Eisner, S Khudanpur. Variational Decoding for Statistical Machine Translation[C]//Proceedings of the Association for Computational Linguistics. 2009: 567-575.
[10] N Duan, M Li, T Xiao, et al. The Feature Subspace Method for SMT System Combination[C]//Proceedings of the Conference on Empirical Methods on Natural Language Processing. 2009: 1096-1104.
[11] J DeNero, D Chiang, K Knight. Fast Consensus Decoding over Translation Forests[C]//Proceedings of the Association for Computational Linguistics. 2009: 567-575.
[12] A Pauls, J DeNero, D Klein. Consensus Training for Consensus Decoding in Machine Translation[C]//Proceedings of the Conference on Empirical Methods on Natural Language Processing. 2009: 567-575.
[13] A Rosti, N Ayan, B Xiang, et al. Combining Outputs from Multiple Machine Translation Systems[C]//
Proceedings of the North American Association for Computational Linguistics. 2007: 228-235.
[14] J Fiscus. A post-processing system to yield reduced word error rates: recognizer output voting error reduction (ROVER)[C]//IEEE Workshop on Automatic Speech Recognition and Understanding. 1997: 347-354.
[15] S Bangalore, F Bordel, G Riccardi. Computing consensus translation from multiple machine translation systems[C]//IEEE Workshop on Automatic Speech Recognition and Understanding. 2001: 351-354.
[16] S Jayaraman, A Lavie. Multi-Engine Machine Translation Guided by Explicit Word Matching[C]//10th EAMT conference. 2005: 143-152.
[17] E Matusov, N Ueffing, H Ney. Computing consensus translation from multiple machine translation systems using enhanced hypotheses alignment[C]//Proceedings of the European Association for Computational Linguistics: 2006:33-40.
[18] K Sim, W Byrne, M Gales, et al. Consensus network decoding for statistical machine translation system combination[C]. //ICASSP. 2007: 105-108.
[19] X He, M Yang, J Gao, et al. Indirect-hmm-based hypothesis for combining outputs from machine translation systems[C]//Proceedings of the Conference on Empirical Methods on Natural Language Processing. 2008: 98-107.
[20] T Watanabe, E Sumita. Machine Translation System Combination by Confusion Forest[C]//Proceedings of the Association for Computational Linguistics. 2011: 1249-1257.
[21] 李茂西, 宗成庆. 机器翻译系统融合技术综述[J]. 中文信息学报,2010,25(4): 74-84.
[22] N Duan, M Li, M Zhou. Hypothesis Mixture Decoding for Statistical Machine Translation[C]//Proceedings of the Association for Computational Linguistics. 2011: 1258-1267.
[23] D Chiang. A Hierarchical Phrase-based Model for Statistical Machine Translation[C]//Proceedings of the Association for Computational Linguistics. 2005: 263-270.
[24] P Koehn. Statistical Significance Tests for Machine Translation Evaluation[C]//Proceedings of the Conference on Empirical Methods on Natural Language Processing. 2004: 388-395.
[25] D Xiong, Q Liu, S Lin. Maximum Entropy based Phrase Reordering Model for Statistical Machine Translation[C]//Proceedings of the Association for Computational Linguistics. 2006: 521-528.
[26] L Shen, J Xu, R Weischedel. A new String-to-Dependency Machine Translation Algorithm with a Target Dependency Language Model[C]//Proceedings of the Association for Computational Linguistics. 2008: 577-585.
