甘丽新,涂 伟,王明文,石 松
(1. 江西科技师范大学 光电子与通信重点实验室,江西 南昌 330038;2. 江西师范大学 计算机信息工程学院,江西 南昌 330022;3. 上海财经大学 公共经济与管理学院,上海 200093 )
1 引言
随着互联网的飞速发展,信息检索技术的进步使人们在信息海洋中捞到所需“珍宝”的愿望得以实现。然而网络信息的膨胀使用户很难快速、准确的从浩瀚的信息资源中找到所需的信息,即所谓的“信息爆炸,资源匾乏”。其原因在于用户提供的查询信息过少、查询表达模糊不清等,使得在查询时出现难以克服的问题,即信息迷向、信息过载和词不匹配而造成信息检索的查全率和查准率都较低。查询扩展是解决上述问题的关键技术之一,它指的是利用计算语言学、信息学等多种技术,在原始查询的基础上加入与用户用词相关联的词,组成新的更长、更准确的查询,然后再次检索文档,以改善检索系统的查全率和查准率,弥补用户查询信息不足的缺陷[1-4]。因此,研究信息检索中的查询扩展技术,通过对用户的初始查询进行扩展和重构,具有重要的理论价值和实践意义[5-7]。
查询扩展一般包含两个基本的步骤: 利用新的词对原始查询进行扩展;在扩展查询中给词重新加权[8]。因此,查询扩展技术的核心问题是如何选择高质量的扩展词和如何对词进行重新加权。在已有很多研究中均认为: 若一个词与查询中某个原始查询词的直接相关性越高,则该词与查询主题越相关,因而被扩展的机会越大[9]。虽然直接相关性扩展对检索效果有所提高,但却忽略了词间间接相关性的作用。钟茂生提出了利用二分图模型来求解和量化词汇间间接相关关系的方法来解决在统计语料库中没有出现的词汇对的相关关系量化求解问题[10]。文献[11]则是通过对训练文档集的学习,利用Markov网络中的无向边,通过多层推理激活与查询词密切相关的词作为查询附加证据源加入到查询扩展中。文献[12]则提出了一种全新的全局分析查询扩展方法,利用Markov转移矩阵计算词间深层次关系的多步转移间接关系对查询进行处理。上述方法的检索效果均优于基于直接相关词扩展的检索效果。因此,本文的工作依然是建立在Markov网络的基础上,通过提取Markov网络中的词团信息来量化词间的混合相关性,即把直接相关和间接相关的量化值进行加权处理,将强化后的词间混合相关性应用于信息检索扩展模型中。实验表明: 基于混合相关的Markov网络信息检索扩展模型的检索效果优于基于直接相关的查询扩展模型的检索效果。同时,与基于团的Markov网络信息检索扩展模型相比,该模型最大的优势在于大大减少了词团提取的计算开销。
2 基于混合相关的Markov网络信息检索扩展模型
2.1 模型描述
Markov是一种较好的表示知识关联的图形表示方法,很容易从实例数据中训练获得,它的无向性更好地解释信息检索中知识之间的关系,具有强大的学习功能和推导能力,通过对文档集的学习,利用词项之间的关系构造Markov网络,通过词项之间的关系对查询进行扩展[9]。一个Markov网络可以表示为一个二元组(V,E),V为所有节点的集合,E为一组无向边的集合,E={(xi,xj)|xi≠xj∧xi,xj∈V},E中的边表示变量之间的依赖关系。在Markov网络中,每个节点v条件独立于其邻居节点给定的v的非邻居节点的任意节点子集,节点只和其直接相邻节点存在依赖性,即满足p(vi|vj)=p(vi|vj(vi,vj)∈E)[9]。在图1所示的Markov网络中,图中节点表示词,边表示词间关系。
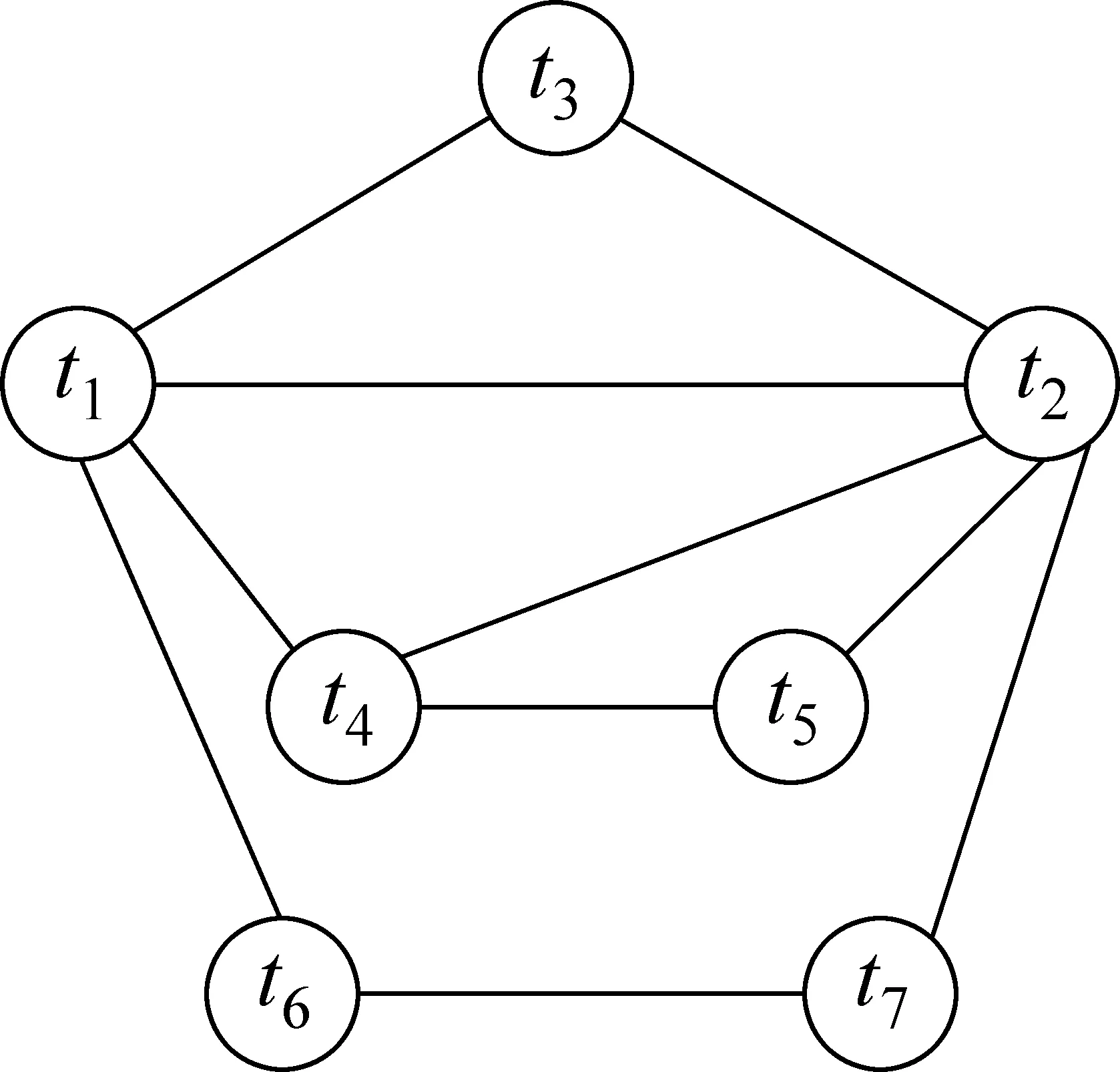
图1 Markov网络结构
2.2 词间相关性计算
对于给定的词t1和t2,在Markov网络图中主要存在三类词间相关性: (1)直接相关性: 即可从数据集中直接统计出现的词间关系,见图2(a)所示,t1和t2直接有边相连;(2)间接相关性: 从数据集中无法统计出现或者词间通过第三方词变量隐含导出的关系,即t1和t2没有直接边相连,而是通过词t3导出,如图2(b);(3)混合相关性: 词间既有直接相关性,又有间接相关性,如图2(c)所示。
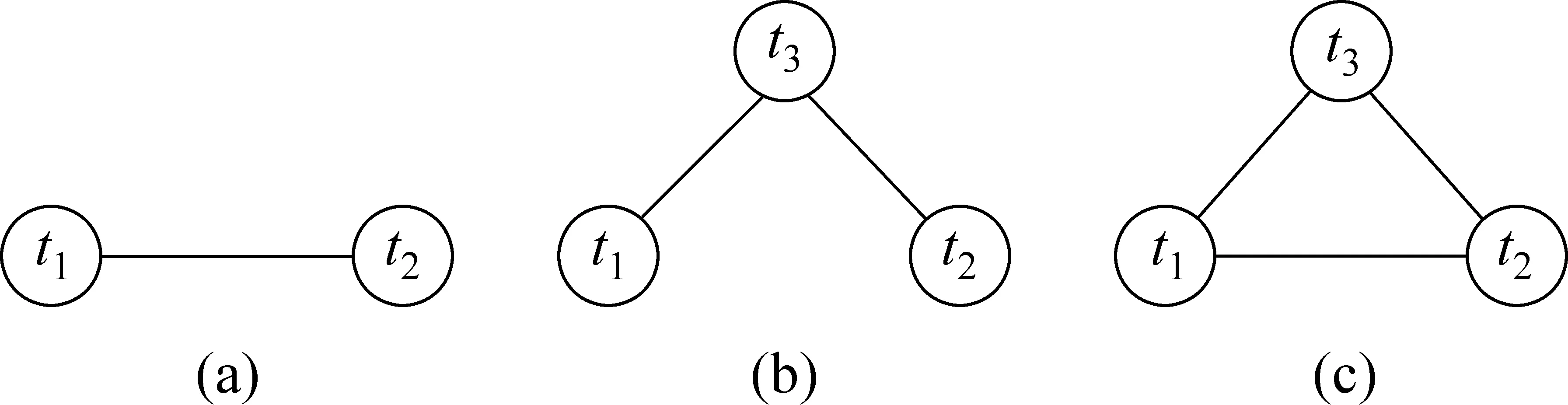
图2 词间的三类相关性
在现有研究中,度量词间相关性的方法主要有潜在语义索引、协方差、词的共现性、互信息和条件概率等[9]。在度量词间的直接相关性时,本文选取了条件概率综合指标。两个词ti和tj之间的直接相关度记为RD(ti,tj),如式(1)所示。
其中:p(ti|tj)是在被统计的数据集中,在词tj出现的条件下词ti出现的概率,0≤RD(ti,tj) ≤1。在实际计算中,用词频来代替相应变量的概率。
钟茂生利用二分图模型来求解和量化词汇间间接相关关系,最后将直接相关关系和间接相关关系量化值进行加权处理, 并将加权结果看成是两词汇之间的量化相关关系[10]。文献[11-12]则是通过多层推理激活与查询词密切相关的词来寻找查询附加证据源或是利用Markov转移矩阵计算词间多步转移的间接关系。本文则通过提取Markov网络中的词团信息来量化词间的混合相关性,即把直接相关和间接相关的量化值进行加权处理,将强化后的词间混合相关性应用于信息检索扩展模型中。考虑到影响词间相关性的因素[13]: (1)词间的直接或间接连接边数越多,其间的相关度越大;(2)词间的相隔路径越长,其间的相关度越小。同时鉴于文献[11-12]的实验表明: 词间间接相关性的路径不超过2对于检索最好。因此,综合考虑上述因素,本文将仅仅考虑利用3阶词团来量化词间的间接相关性。因此,上述图2中的词ti和tj的间接相关性将由图3所示的3阶词团clique(t1,t3,t2)和clique(t1,t4,t2)来量化。
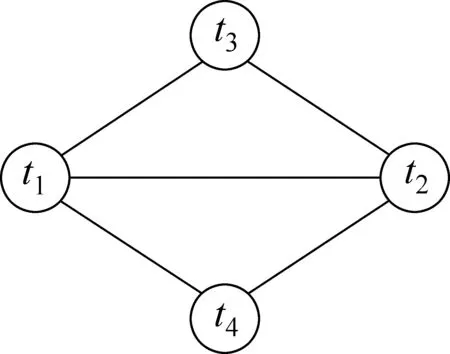
图3 3阶词团
我们可以用下面的式(2)来求解词ti和tj的间接相关性RI(ti,tj):
其中:RD(ti,tk)表示ti和tk之间的直接相关度;RD(tk,tj)表示tk和tj之间的直接相关度;clique(ti,tk,tj)表示包含词ti,tk和tj的3阶词团;m表示词团clique(ti,tk,tj)的总数;0≤RI(ti,tj) ≤1。
如图3所示,对于给定的词ti和tj,由它们构成的3阶词团即包含词间的直接相关性,也包含词间的间接相关性,即词ti和tj存在混合相关性。因此本文仍然采用类似文献[10]的加权方法量化词间混合相关性RM(ti,tj):
其中:θ为间接相关和直接相关的加权因子,0≤θ≤1。RD(ti,tj)和RI(ti,tj)分别可以由式(1)和(2)得到。
2.3 查询扩展
查询扩展的目的在于将有利于提高检索性能的信息加入到检索过程中,其一般包含两个基本的步骤:对原始查询进行扩展和利用重新加权的扩展词进行检索。在查询扩展过程中,本文依然采用此策略: 给定一个查询,对于一个查询词,若一个扩展候选词与原始查询词的混合相关性越大,则认为该词与查询主题越相关,越有利于检索。因此,给定查询Q和任一文档D,计算其相关概率。本文采用了Markov网络检索扩展模型来计算相关概率,见式(4)。
其中:RM(ti,tj)表示词间混合相关性。
将式(3)代入式(4),可得式(5)。
其中: λ为平滑参数(0≤λ≤1)。在实验中,本文通过同时调整平滑因子λ和θ,使得模型达到检索性能的最优效果。
3 实验设计与分析
为了验证本文提出的基于混合相关的Markov网络信息检索扩展模型对检索性能的影响,我们在5个常用的标准数据集进行了一些实验,下面介绍使用的数据集、预处理、实验步骤、结果及相关分析。
3.1 数据集与预处理
本文使用了5个标准数据集adi, med, cran, cisi及cacm。其中: adi是信息科学方面的文档集(82篇文档和35个查询);med是医学方面的文档集(1 033篇文档和30个查询);cran是航空方面的文档集(1 400篇文档(含2篇空文档)和225个查询);cisi是图书馆科学方面的文档集(1 460篇文档和76个查询);cacm是计算机科学方面的文档集(3 024篇文档和64个查询)[14]。在预处理阶段,主要提取文档中的
和<Body>部分的内容,去掉了非法字符和数字,大写字母变小写字母,去除停用词,运用Porter算法进行词干化处理[14]。</p><h3>3.2 实验步骤</h3><p>为了验证本文提出的利用Markov网络中的词团信息来量化词间的混合相关性,将强化后的词间混合相关性应用于信息检索扩展模型中的效果,实验步骤如下:</p><p>(1) 构造Markov词项网络: 对于给定的数据集,根据式(1)计算词项的直接相关性RD(ti,tj),若RD(ti,tj)≥α(α为给定阈值),则ti和tj有边直接相连,即ti和tj存在直接相关性,按照RD(ti,tj)的大小降序排列。</p><p>(2) 提取3阶词团: 对于任意词ti和tj,采用文献[14]提出的团提取算法,在已经构造好的Markov词项网络中提取3阶词团clique(ti,tk,tj)集。</p><p>(3) 词团修剪: 给定词ti和tj,其3阶词团clique(ti,tk,tj)中若满足条件RD(ti,tk)≥β∧RD(tk,tj)≥β(β为给定阈值),则该词团clique(ti,tk,tj)保留,否则从词团集中删除。</p><p>(4) 计算词间的间接相关性: 根据式(2),计算词团中词间的间接相关性。</p><p>(5) 检索计算: 利用词团信息来量化词间的混合相关性,将强化后的词间混合相关性应用于查询扩展过程中。依据式(5),计算检索文档得分,从而计算出评价指标的值。本文通过同时调整查询扩展候选词的个数n、查询扩展权重平滑因子λ、间接相关和直接相关的加权因子θ,使得模型检索性能达到最优效果。</p><h3>3.3 实验结果与分析</h3><p>为了验证本文提出的基于混合相关的Markov网络信息检索扩展模型(MRM)的总体有效性,我们分别与以下模型进行实验对比: (1)经典的BM25模型[14];(2)基于直接相关的查询扩展检索模型(DRM)[9]。</p><p>本文采用信息检索系统的经典评价指标11-avg (在11个召回率点(0,0.1,…,1.0)上每一个查询对应精度的平均值)和3-avg(在3个召回率点(0.2,0.5,0.8)上每一个查询对应精度的平均值)。表1和表2分别给出了在5个文档集上3个检索模型的实验结果。实验以BM25模型实验结果为基准,其余两个模型的结果均是在此实验结果上增加的百分比。</p><p><img src="https://img.fx361.cc/images/2023/0128/cb6224a25838bcf895869aa9fcf47d8c61f6a9f6.webp"/></p><p>表1 在数据集上的11-avg实验结果</p><p><img src="https://img.fx361.cc/images/2023/0128/fc6fc8377d836b709f20c9d430db69b231eee4f2.webp"/></p><p>表2 在数据集上的3-avg实验结果</p><p>从表2和表3可以发现: 在所有数据集上,DRM和MRM整体表现都比BM25的检索效果明显要好,说明了扩展后的查询都优于未扩展的原始查询。通过与基于直接相关的查询扩展检索模型DRM相比较,本文提出的基于混合相关的Markov网络信息检索扩展模型MRM总体上表现最好,特别是在adi、cisi和cacm上检索性能均有较大的提高,说明基于混合相关的Markov网络信息检索扩展模型MRM更加强化了与原始查询词的关系,从而在扩展过程中加入更多有用的信息。在med和cran两个数据集上, MRM在检索性能上略弱于DRM,其原因在于与数据集的领域和词性有关。med是关于医学的数据集,cran是关于信息科学的数据集,这两个数据集的专业性较强,即对于原始查询词而言,查询词的语义都比较清晰, 查询词能比较有效地描述查询主题,与查询词的直接相关的词较多,且词间的直接相关性也较高,通过实验发现MRM利用间接相关性来增强与原始查询词的混合相关强度在查询过程中几乎不起作用。</p><p>本文通过同时调整查询扩展候选词的个数n,查询扩展权重平滑因子λ和混合相关权重平滑因子θ,使得模型的检索性能达到最优。在查询扩展过程中,对于每一查询词,其查询扩展词的个数n应该加以合理控制,若n太小,则在查询扩展中加入的有用扩展信息过少,不利于检索效率的提高;若n太大,则容易带来过多的噪音信息,产生主题漂移,而且增加了检索计算量。在实验中,当检索性能达到最优时,文档集上的每一个查询词的候选扩展词个数平均不超过10,较之DRM在每个文档集上大约要扩展到20多个候选词而言,本文提出的MRM模型利用3阶词团进行混合相关计算更有利于强化扩展词与原始查询词的关系,同时在扩展计算时间上有所缩短。在实验中,通过调整λ和θ的取值从而进一步提高检索精度。对于不同的n,λ的变化范围不大,而且对于检索效果的影响也比较缓慢。在最优结果下λ取值都比较小,5个文档集上的λ值均不超过0.2。λ的取值与文档集规模有一定的关系。在文档集cacm上λ的值最大,这与cacm的文档结构有关,因为cacm文档的平均长度比较短使得包含的信息量比较少,通过对词权重的修正使得在检索过程中得到很多有益的信息。当参数n和λ固定时,进一步调整混合相关权重平滑因子θ。我们采用从0到1, 步调为0.01来逐步调节θ。在查询扩展中,最重要的还是以词间的直接相关性为主,利用间接相关性来进一步加强词间的混合相关性。在实验中,当评价指标11-avg和3-avg达到最优时,我们发现θ的取值一般不超过0.3比较合适。</p><p>文献[14]提出了基于团的Markov网络信息检索模型CM,该模型是将团作为一个概念整体加入到查询扩展中。本文提出的MRM模型则是利用3阶词团来量化词间的间接相关性,然后将词间混合相关性直接应用于查询扩展中。实验将本文提出的MRM模型与CM检索效果进行对比和分析,实验结果见表3和表4。</p><p>从总体检索性能来看,本文提出的基于混合相关的Markov网络信息检索扩展模型MRM稍优于文献[14]提出的基于团的Markov网络信息检索模型CM,说明词团存在较强的语义相关,聚合了有利于查询扩展的信息。而在med和cran数据集上, MRM在检索性能上略弱于CM的检索效果,其原因在于查询扩展过程中扩展词的选择方式的不同。MRM依然采用传统的简单查询扩展方式,按照词间的混合相关性强弱进行依次选取扩展词。然而根据上述表1和表2的实验结果分析可知: MRM在med和cran数据集上利用间接相关性来增强与原始查询词的混合相关性在查询扩展中几乎不起作用。而CM则采用基于概念的查询扩展方式,以词团为一个概念整体加入到查询过程中,在med和cran数据集上,词团概念信息有利于选择出与查询主题更相关的词。但是本文提出的MRM模型其最大的优势在于: 较之CM模型在查询扩展中采用了9阶词团信息,而MRM模型则仅仅利用了3阶词团来量化词间混合相关性,从而大大减少了词团提取的计算复杂度和时间开销。特别是在大数据上,随着词汇规模的增大,词团提取的计算开销和复杂度将随之剧增。因此在大数据上,本文提出的MRM在计算开销上的优势将会更加明显。</p><p><img src="https://img.fx361.cc/images/2023/0128/f3853217f9d60f4e6b001bbc7c25a35879666c29.webp"/></p><p>表3 MRM 和CM的11-avg实验结果</p><p><img src="https://img.fx361.cc/images/2023/0128/a7942ccb32c3c497efaf1359817ae22bc5eed4b7.webp"/></p><p>表4 MRM 和CM的3-avg实验结果</p><p>在构造Markov词项网络和词团修剪的过程中,有2个重要参数需要控制: 直接相关性阈值α和间接相关性阈值β。为了使最终检索结果达到最优,词间相关性必须选定合适的阈值。若阈值α过大,则获取直接相关的词会太少,不利于词间混合相关性的提取;若α过小,则会增加构造Markov词项网络和提取词团的计算量。出于同样的考虑,对于间接相关性阈值β,若β过大,容易造成词团的削减过多,从而量化间接相关性信息太少,可能会影响本文提出的利用混合相关信息进行查询扩展的检索效果;若β过小,则在间接相关性时计算量过大,而且在查询扩展时容易带来太多的噪音。因此,实验中对本文提出的模型进行了两种参数设置策略: (1)出于简单起见,直接相关性和间接相关性取相同的阈值,即α=β,见模型MRM1;(2)本文模型在查询扩展中,最重要是考虑与原始查询直接相关的词,只是利用词团的间接相关性来进一步加强混合相关性,因此考虑设置直接相关的阈值大于间接相关的阈值进行实验,即β>α,进一步利用阈值β对词团进行修剪,见模型MRM2。当评价指标11-avg和3-avg达到最优时,α和β的取值及实验结果如表5所示。</p><p><img src="https://img.fx361.cc/images/2023/0128/fe0650ef675d1e7b3c26b19c8356446448419bed.webp"/></p><p>表5 MRM1和MRM2的11-avg和3-avg实验结果</p><p>从表5中可知: (1)与基准模型BM25相比,模型MRM1和MRM2都提高了检索性能,说明对于直接相关性和间接相关性阈值设定的两种策略都加入了有利于查询扩展的混合相关信息。(2)模型MRM1和MRM2在整体检索性能上表现相当。从实验中发现其原因在于: 在查询扩展中,模型MRM1和MRM2平均扩展不到10个候选词,在MRM1中,α取值足以保证每个词均有超过10个直接相关词。因此相对于MRM2来说,MRM1在构造Markov词项网络和提取3阶词团时,大大减少了计算量和内存开销。(3)阈值β用于进一步修剪3阶词团信息。在模型MRM1中,β=α,说明实验中省去了词团修剪步骤;而在模型MRM2中,β>α,由于α值较小,用于间接相关性计算的词团信息过多,因此利用β进一步去除噪音词团。在评价指标达到最优时,对于每一个数据集,模型MRM1和MRM2中β的阈值几乎相同,大概保证每个词均有5个3阶词团用于提取混合相关信息。从实验中可见,参数β的值至少控制在β≥α将更有利于获取提高检索性能的有用信息和减少计算开销。</p><h2>4 总结与展望</h2><p>本文通过提取Markov网络中的3阶词团信息来量化词间的混合相关性,即把直接相关和间接相关量化值进行加权处理, 将强化后的词间混合相关性应用于信息检索扩展模型中。通过实验表明: 基于混合相关的Markov网络信息检索扩展模型的检索效果优于基于直接相关的查询扩展的检索效果。同时,在整体检索性能上,该模型略优于基于团的Markov网络信息检索模型,但本文模型在词团提取上却大大减少了计算开销,因此本文模型可能更有利于大数据上的检索计算。未来的研究工作主要包括: (1)在官方数据集TREC上测试其通用性;(2)为了弥补未登录词由于在单一数据集上无法获取直接相关性而造成在查询扩展中无法利用混合相关信息,今后打算考虑加入HowNet或Wikipedia来获取更多有益于提取词间混合相关性的资源。</p><p>[1] 陈燕红,黄名选. 基于APriori改进算法的局部反馈查询扩展[J].现代图书情报技术,2007,09:84-87.</p><p>[2] C Lioma, B Larsen, W Lu. Rhetorical relations for information retrieval[C]//Proceedings of the 35th annual international ACM SIGIR conference on research and development in information retrieval, 2012: 931-940.</p><p>[3] D Metzler, W B Croft. Latent Concept Expansion Using Markov Random Fields[C]//Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval, 2007: 311-318.</p><p>[4] Yuan Lin, Hongfei Lin,Song Jin. Social Annotation in Query Expansion: a Machine Learning Approach[C]//Proceedings of the 34th annual international ACM SIGIR conference on research and development in information retrieval, 2011: 405-414.</p><p>[5] Fonseca B M, Golgher P B, Moura E S de. Discovering Search Engine Related Query Using Association Rules [J]. Journal of Web Engineering, 2004, 2(4): 215-227.</p><p>[6] 刘文飞,林鸿飞.基于网页查询结果的广告查询扩展研究[J].中文信息学报,2012,26(5):88-94.</p><p>[7] Dai Jiahong. Fuzzy cluster-based query expansion [D]. Master Thesis, Department of Information Management, National Sun Yat-sen University, Taiwan, 2004.</p><p>[8] 姚小同.查询扩展技术研究[D].北京:北京邮电大学,2009.</p><p>[9] 左家莉.基于Markov网络的信息检索模型[D].南昌:江西师范大学, 2005.</p><p>[10] 钟茂生,刘慧,刘磊.词汇间语义相关关系量化计算方法[J].中文信息学报,2009,23(2):115-122.</p><p>[11] 曹瑛,王明文,陶红亮.基于Markov 网络的检索模型[J].山东大学学报(理学版),2006,41(3):126-130.</p><p>[12] 石松.基于Markov团的信息检索扩展模型[D].南昌:江西师范大学, 2011.</p><p>[13] 刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012,39(2):8-13.</p><p>[14] 甘丽新.基于Markov概念的信息检索模型[D].南昌:江西师范大学, 2007.</p></div></div>
<!-- <div class="m_article_pdf"><a href="https://cimg.fx361.com/kkb.apk">查看pdf文档请下载app</a></div>--><div class="article_love_part">
<h3>猜你喜欢</h3>
<div class="article_love_keyword"><span><a href="/tags/b/0/3b5f9af517dfde91/1.html" target="_blank">信息检索</a></span><span><a href="/tags/3/5/c0eb5cb77d8024b6/1.html" target="_blank">文档</a></span><span><a href="/tags/8/e/54ba8f7ee7441dd1/1.html" target="_blank">检索</a></span></div>
<div class="article_love_news"><dd><a href="/news/2022/0531/10341748.html" target="_blank" title="浅谈Matlab与Word文档的应用接口">浅谈Matlab与Word文档的应用接口</a></dd><dd><a href="/news/2021/0727/8621423.html" target="_blank" title="有人一声不吭向你扔了个文档">有人一声不吭向你扔了个文档</a></dd><dd><a href="/news/2021/0103/14075006.html" target="_blank" title="高职院校图书馆开设信息检索课的必要性探讨">高职院校图书馆开设信息检索课的必要性探讨</a></dd><dd><a href="/news/2019/1025/8143714.html" target="_blank" title="瑞典专利数据库的检索技巧">瑞典专利数据库的检索技巧</a></dd><dd><a href="/news/2019/0820/13183596.html" target="_blank" title="一种基于Python的音乐检索方法的研究">一种基于Python的音乐检索方法的研究</a></dd><dd><a href="/news/2018/0125/15726192.html" target="_blank" title="网络环境下数字图书馆信息检索发展">网络环境下数字图书馆信息检索发展</a></dd><dd><a href="/news/2017/0721/15373342.html" target="_blank" title="浅议专利检索质量的提升">浅议专利检索质量的提升</a></dd><dd><a href="/news/2017/0506/1721133.html" target="_blank" title="Word文档 高效分合有高招">Word文档 高效分合有高招</a></dd><dd><a href="/news/2016/0228/13848442.html" target="_blank" title="基于神经网络的个性化信息检索模型研究">基于神经网络的个性化信息检索模型研究</a></dd><dd><a href="/news/2015/1222/13022959.html" target="_blank" title="Persistence of the reproductive toxicity of chlorpiryphos-ethyl in male Wistar rat">Persistence of the reproductive toxicity of chlorpiryphos-ethyl in male Wistar rat</a></dd></div>
</div><div class="phbk_part"><h3>杂志排行</h3>
<ul><li><a href="/bk/hzjjykj/202413.html" class="title">《合作经济与科技》</a><a href="/bk/hzjjykj/202413.html" class="date">2024年13期</a></li><li><a href="/bk/hyyjk/202410.html" class="title">《婚育与健康》</a><a href="/bk/hyyjk/202410.html" class="date">2024年10期</a></li><li><a href="/bk/swyzhsby/20247.html" class="title">《思维与智慧·上半月》</a><a href="/bk/swyzhsby/20247.html" class="date">2024年7期</a></li><li><a href="/bk/tckjyjs/202311.html" class="title">《陶瓷科学与艺术》</a><a href="/bk/tckjyjs/202311.html" class="date">2023年11期</a></li><li><a href="/bk/zgsr/20247.html" class="title">《中国商人》</a><a href="/bk/zgsr/20247.html" class="date">2024年7期</a></li><li><a href="/bk/jsbl/20244.html" class="title">《教师博览》</a><a href="/bk/jsbl/20244.html" class="date">2024年4期</a></li><li><a href="/bk/sdjy/20246.html" class="title">《师道·教研》</a><a href="/bk/sdjy/20246.html" class="date">2024年6期</a></li><li><a href="/bk/zgdwmy/20246.html" class="title">《中国对外贸易》</a><a href="/bk/zgdwmy/20246.html" class="date">2024年6期</a></li><li><a href="/bk/bl/20246.html" class="title">《伴侣》</a><a href="/bk/bl/20246.html" class="date">2024年6期</a></li><li><a href="/bk/jjjsxzxx/20246.html" class="title">《经济技术协作信息》</a><a href="/bk/jjjsxzxx/20246.html" class="date">2024年6期</a></li></ul>
</div><div class="bk_part">
<div class="bk_im_b"><a href="/bk/zwxxxb/20134.html"><img src="https://img.fx361.cc/images/2023/0128/b3e34919e2c7a1771df6e8d1d77a881ed35d17fe_mini.webp" alt=""></a></div>
<div class="dbk_title"><a href="/bk/zwxxxb/" target="_blank">中文信息学报</a></div>
<div class="dbk_date"><a href="/bk/zwxxxb/20134.html" target="_blank">2013年4期</a></div>
</div><div class="others">
<h3><a href="/bk/zwxxxb/" target="_blank">中文信息学报</a>的其它文章</h3>
<ul><li><a href="/news/2013/0423/16011346.html" title="中国机器翻译研究的机遇与挑战<br/>——第八届全国机器翻译研讨会总结与展望">中国机器翻译研究的机遇与挑战<br/>——第八届全国机器翻译研讨会总结与展望</a></li><li><a href="/news/2013/0423/16013390.html" title="维吾尔语评论文本主题抽取研究">维吾尔语评论文本主题抽取研究</a></li><li><a href="/news/2013/0423/16011689.html" title="基于ListMLE排序学习方法的机器译文自动评价研究">基于ListMLE排序学习方法的机器译文自动评价研究</a></li><li><a href="/news/2013/0423/16011772.html" title="基于序列标注的中文分词、词性标注模型比较分析">基于序列标注的中文分词、词性标注模型比较分析</a></li><li><a href="/news/2013/0423/16012822.html" title="基于用户生成内容的产品搜索模型">基于用户生成内容的产品搜索模型</a></li><li><a href="/news/2013/0423/16012859.html" title="基于排序学习的微博用户推荐">基于排序学习的微博用户推荐</a></li></ul></div></div>
<div class="m_footer"></div>
<script>
if ('serviceWorker' in navigator) {
window.onload = function () {
navigator.serviceWorker.register('/sw.js');
};
}
</script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery/3.4.0/jquery.min.js"></script>
<script type="text/javascript" src="https://s2.pstatp.com/cdn/expire-1-M/Swiper/4.5.0/js/swiper.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery.lazyload/1.9.1/jquery.lazyload.js"></script>
<script type="text/javascript">
document.write('<script src="https://img.fx361.cc/js/m.index_cc.js"><\/script>');
</script>
</section>
</body>
</html>