基于ListMLE排序学习方法的机器译文自动评价研究
2013-04-23李茂西江爱文王明文
李茂西,江爱文,王明文
(江西师范大学 计算机工程信息学院,江西 南昌 330022)
1 机器译文自动评价
对机器译文质量进行自动评价是机器翻译的一个重要研究内容。它极大地促进了机器翻译系统的研究和开发。译文的自动评价结果不仅方便最终用户选择更好的机器译文,而且它也可以指导翻译系统开发时特征参数的调整。在WMT’2011评测中,评测方专门增加了一个调整机器翻译系统特征权重的评测任务(Tunable Metrics Task),该任务要求参加单位使用不同的自动评价方法在Joshua[1]解码器上对相同的翻译模型和语言模型的特征权重进行调整,以调查使用与人工评价相关性高的译文自动评价尺度来调整系统特征权重,是否能真正的提高翻译质量[2]。相关的研究结果表明,利用一个与人工评价相关性高的译文质量自动评价方法指导统计翻译系统的特征权重调整,能够使研究者开发出一个性能更优的翻译系统[3]。因此,研究机器译文的自动评价方法对机器翻译有着重要的意义。
BLEU尺度由于其简洁性而被广泛使用,它计算机器译文的n元文法在参考译文中的准确率,并考虑译文的简短惩罚来进行译文自动评价[4]。但是BLEU尺度存在着一定的不足,最突出的是由于参考译文在覆盖多种语言现象上的稀疏性,导致它在句子级别(segment-level or sentence-level)译文评价结果上与人工评价结果的相关性偏低[5-6]。其他译文自动评价方法,包括NIST[7],METEOR[8],GTM[9],TER[10]等,也存在着这样问题。因此它们通常用在系统级别的机器译文自动评价中。
1.1 相关工作
为了提高译文自动评价结果与人工评价结果的相关性,近年来,研究者们提出了许多基于机器学习的译文自动评价方法。基于机器学习的译文自动评价方法以译文人工评价的结果为标准,使用有监督学习的方法对影响译文质量的特征进行建模,因此,它能够较好地融合多个特征来拟合译文的人工评价结果,提高译文质量的预测准确率。被使用的机器学习方法包括分类[11-12]、回归[13-15]和排序学习[16-18]。
Corston-Oliver等是最早尝试将二值分类器引入到译文自动评价中,待评价译文的语言学特征,主要是反映流利度的结构特征决策树结构,被用来训练分类器以区分人工译文和机器译文[11]。Alex Kulesza 等以n元文法的准确率(n=1,…,4)、词错误率和独立词错误率为特征,使用支持向量机来进行译文评价,训练出的分类器模型能较好地提高译文自动评价结果与人工评价结果的相关性[12]。
Joshua Albrecht 等使用回归模型来进行译文自动评价,他们的工作主要是抽取机器译文的字符串特征和句法特征,直接针对流利度/忠实度的人工评价结果进行特征权重优化[14];最近,Lucia Specia等尝试引入句子的置信估计值(confidence estimation)作为一个新的特征,与传统的机器译文与参考译文对比获取的特征进行融合,来进行译文自动评价[15]。Sebastian Padó等将文本蕴涵关系(textual entailment)作为特征引入回归模型中进行译文自动评价[13]。
以基于排名的人工评价结果作为译文自动评价方法特征权重调整的优化目标。译文评价问题可以转化为排序学习(learning to rank)[19]问题。但是目前在译文自动评价中使用的排序学习方法主要是成对比较的方法(pairwise approach),机器译文对参考译文的词语和句法覆盖率被用作开源工具包RankSVM[20]的特征,以进行译文质量的比较[16-18]。由于成对比较的排序学习方法将译文排名问题转化成译文两两比较,因此,它忽略了译文之间排名本身的排列结构。
本文使用排序学习中排列方法(listwise approach)来进行译文的自动评价,与成对比较的排序学习方法不同,基于排列的排序学习方法直接对多个机器译文的排名进行建模,因此,它能较好地学习排名的次序,提高排名的预测精度。基于排列的排序学习方法有多种,这里使用性能较好的一种,即ListMLE排序学习方法[21]。在此基础上,探讨引入计算译文的语言模型概率来度量译文的翻译流利度;计算译文和源语言句子的双向翻译概率来刻画翻译的忠实度。并通过实验验证本文提出的方法和引入的特征能显著的提高译文自动评价结果与人工评价结果之间的相关性。
2 基于ListMLE排序学习方法的机器译文评价
排序学习是信息检索中近年来研究的一个热点问题。在信息检索中,排序学习方法首先通过训练获取排序模型,当给定一个查询时,排序模型对文档集中与查询相关文档的排名次序进行预测,并返回相关性较高的几个文档[22-24]。ListMLE方法[21]直接对排名的次序结构进行建模,是排序学习中性能最好的方法之一,下面针对译文自动评价任务,对ListMLE方法进行重新阐述。
2.1 ListMLE方法

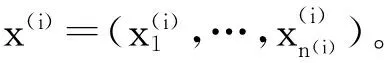
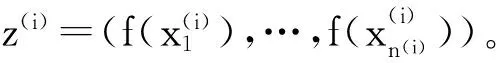

因此在训练集上人工排名概率的似然函数(likelihood function)为:
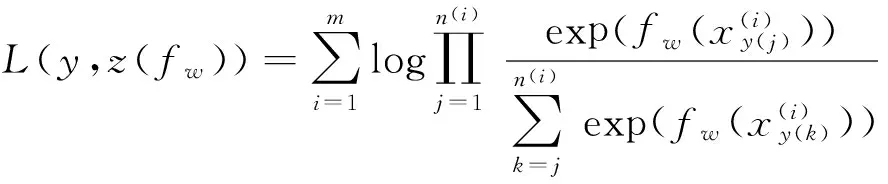
(2)
ListMLE方法就是求解使训练集上人工排名概率的似然函数值最大时的排序函数参数w,此时的预测排名和人工排名之间的损失最小。
对式(2)的似然函数求导如式(3)所示。
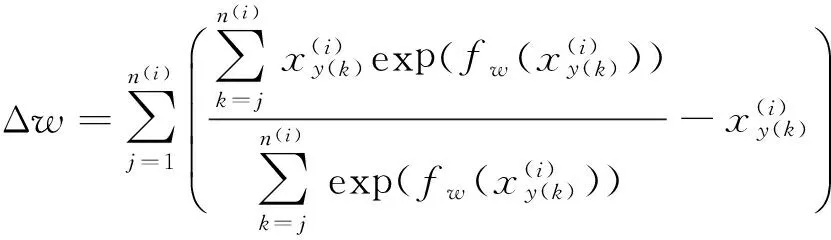
(3)
根据式(3)可以使用梯度下降算法求取排序函数的参数w。
通过训练获取排序函数的模型后,我们就可以利用它对源语言句子的多个机器译文质量进行预测,得到机器译文之间的一个相对排名。
2.2 机器译文的人工排名评价
对机器译文进行人工评价的方法主要包括传统的流利度/忠实度 (fluency/adequacy)的5分制方法和基于排名(rank)的方法。
由于流利度/忠实度的人工评价方法需要对所有的参与系统译文均进行独立的评分,不同的评价员给不同的系统翻译打分存在较大的主观性,不同评价员打分的不一致给多个翻译系统性能的相对比较带来困难。近年来,一种基于排名的人工评价方法在机器翻译评测中使用越来越频繁,并有取代流利度/忠实度的人工评价方法的趋势,例如,WMT2011年评测中,评测方不再像往年那样同时提供译文的流利度/忠实度的人工评价结果和基于排名的人工评价结果,而仅仅提供基于排名的结果[2]。表1给出了在IWSLT’08 BTEC CE ASR任务上不同评价员对相同译文的质量进行评价时,评价结果之间的kappa系数[27]。kappa系数越高,表明评价结果的一致性越强。表1结果表明当多个评价员对多个系统译文进行评价时,基于排名的人工评价结果之间的一致性大幅度高于流利度和忠实度的人工评价结果之间的一致性。
表1不同评价员对译文人工评价结果之间的一致性(Inter-GraderConsistency)
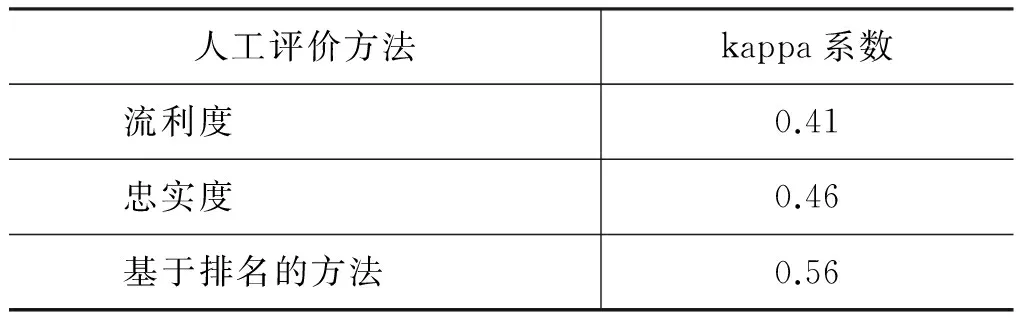
人工评价方法kappa系数流利度0.41忠实度0.46基于排名的方法0.56
得到译文质量排名次序的操作方法是,将源语言句子和相应的多个系统输出译文(一般为5个)同时呈现给评价员,评价员根据机器译文的质量对它们按照优劣顺序进行排序(在排序时允许相同的排名)。由于参加评测的系统个数一般大于5个,例如,WMT2011评测德英任务的参加单位有20个,在排序时不是要求一次对所有的参与系统进行完全排序,而是通过大量的随机组合和多次比较来保证排名公平。图1给出了一个基于排名的人工评价结果以及相应字段的含义,其中(3 4 5 2 1)是这5个系统翻译质量的依次对应排名,1表示译文质量最优;5表示译文质量最劣。图1的人工评价结果表明,在对德英任务“de-en.test”测试集第1 926个句子的5个译文进行人工评价时,“A10P4CWMDQU4W”评价员给出的排名是:limsi > cu-zeman > cst > cmu-dyer > jhu。

图1 一个WMT2011基于排名的人工评价结果示例
人工排名评价由于需要高昂的人力费用和较长的评价周期,因此,只有少量的机器译文通过人工进行评价,这些人工评价的结果可以指导自动评价方法参数的调整和性能的对比。
2.3 特征
在基于ListMLE方法的机器译文评价方法中,我们使用三类特征来刻画机器译文的质量,包括机器译文和参考译文之间n元文法匹配的准确率、机器译文语言模型概率特征和双向翻译概率特征。
(1) n元文法匹配的准确率
机器译文和多个参考译文之间的n元文法准确率是自动评价尺度BLEU和NIST采用的特征,它能在一定程度上刻画机器译文的质量。这里,我们使用开源工具“mteval-v13a.pl*ftp://jaguar.ncsl.nist.gov/mt/resources/mteval-v13a.pl”来计算机器译文n元文法的准确率。为了防止句子级别n元文法准确率为0导致对数计算产生溢出,n元文法准确率计算时采用了折半平滑。另外,为了避免机器译文简短导致准确率虚高的情况,我们引入了机器译文简短惩罚系数。
(2) 语言模型特征
机器译文的统计语言模型概率定量地描述了译文在训练语料中被生成的概率,它能够较好地刻画译文的流利程度。我们将机器翻译目标语言端的训练语料与参考译文按照1∶1的比例进行混合,利用它训练语言模型,然后计算机器译文由这个语言模型生成的概率。使用语言模型概率来度量机器译文的流利度。另外,为了避免译文过长,导致语言模型概率值偏小,我们同时引入了长度惩罚因子来规范语言模型概率。
(3) 双向翻译概率特征
为了刻画机器译文表达源语言句子信息量的多少,即机器译文的忠实度。在缺乏机器译文和源语言句子中词语之间词对齐关系的情况下,我们使用式(4)来近似地计算由含有m个词的源语言句子f生成含有n个词的机器译文e的概率。
其中,p(ei|fj)是词语间翻译概率,可通过在双语平行语料上词对齐训练获取。为了进一步衡量译文的忠实度,我们采用了类似的方法计算机器译文生成源语言句子的近似概率。
表2对在基于ListMLE方法的机器译文自动评价中使用的三类特征进行了总结。

表2 描述机器译文质量的特征值
3 实验
3.1 实验数据
为了测试基于ListMLE排序学习方法的机器译文评价方法的性能,我们分别在WMT2010,WMT2011参与系统最多的德英任务和IWSLT’08 BTEC CE ASR任务上进行了实验,前者是新闻文本的德语到英语的翻译任务,而后者是口语文本的汉语到英语的翻译任务。
在WMT德英翻译任务中,2010年共有25家单位参加了评测,包括18家参与单系统任务和7家参与系统融合任务,对他们提交的部分译文进行人工排名评价,得到1 050组评价结果,剔除系统译文排名完全相同的组,获得1 012组评价结果[28];而2011年单系统任务参与单位共有20个,对他们的提交部分译文进行人工排名评价,得到924组评价结果,剔除译文排名完全相同的组,获得905组评价结果[2]。我们以WMT2010 德英任务参加单位提交的译文和译文的人工排名评价结果作为开发集训练排序模型参数,以WMT2011 德英任务的数据作为测试集,测试本文提出方法的预测性能。
在IWSLT’08 BTEC CE ASR翻译任务中,共有14家单位参加了该任务,对他们提交的部分译文进行人工排名评价,得到4 321组评价结果,剔除系统译文排名完全相同的组,获得3 707组评价结果[27]。我们将这些人工评价结果随机分成三份数量近似的数据,任取其中两份作为开发集,一份作为测试集,使用三折交叉验证方法测试本文提出方法的性能。
3.2 实验设置
在实验中,我们不仅将本文提出的方法与BLEU尺度在预测译文质量时的性能进行比较,而且与最近Xingyi Song和Trevor Cohn提出的方法[18]进行比较。Xingyi Song和Trevor Cohn将排序学习中的成对比较方法应用于译文的自动评价,以提高自动评价与人工评价的相关性。在自动评价时,他们使用排序学习中成对比较学习的开源工具包RankSVM,下面实验中将该方法简写为Rank-SVM,并使用该工具包默认的线性核函数。
在性能比较时,我们首先比较不同译文质量评价方法在排名预测上的准确率(Rank accuracy),即多个译文质量之间的自动排名与人工排名一致的比率。在自动排名和人工排名对比时,自动排名得到的系统译文排名次序与人工排名次序完全相同时,才认为自动排名与人工排名一致;如果其中任何一个译文的排名次序不相同,则认为两者不一致。因此,排名预测准确率非常严格,同时比较的粒度也比较大,为了更进一步细化预测性能,我们同时使用了成对比较预测准确率(Pairwise accuracy)。成对比较预测准确率将一组译文排名转化成多对译文质量的两两比较,如果自动评价方法给出的两两比较结果与人工方法相同,则认为二者对这一对译文的评价结果一致。
除了比较句子级别的预测准确率,我们还比较了不同的自动评价方法与人工评价的系统级别(system-level)相关性。自动评价结果和人工评价结果系统级别的相关性通过斯皮尔曼等级相关系数(Spearman’s rank correlation coefficient)计算。
其中n是参与排名的系统数,di是第i个系统人工评价给出的排名和自动评价尺度给出的排名之间的差值。
3.3 实验结果
表3和表4分别给出了在WMT德英任务上,不同的译文自动评价方法排名预测准确率和成对比较预测准确率。首先,我们在RankSVM方法和ListMLE方法中仅使用与BLEU相同的特征,即n元文法的准确率(n=1,…,4)和译文的简短惩罚系数。由于BLEU尺度对这5个特征值取固定的权重,因此不需要开发集,这里主要是为了性能对比起见;而RankSVM方法和ListMLE方法可以看作是在开发集上调整这5个特征的权重,然后对测试集上译文质量排名进行预测。尽管只使用了与BLEU尺度相同的特征,但是排序学习中RankSVM方法和ListMLE方法在测试集上均对预测准确率有一定的提高,并且ListMLE方法提高的幅度比RankSVM方法大。

表3 在WMT 德英任务上排名预测准确率
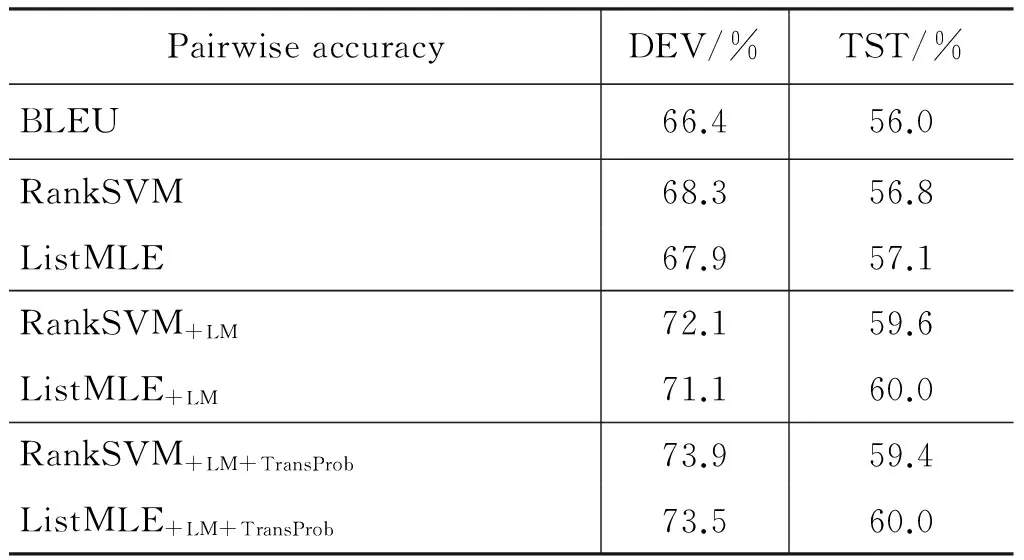
表4 在WMT 德英任务上成对比较预测准确率
进一步,我们把描述翻译流利度的语言模型特征引入RankSVM方法和ListMLE方法中,在测试集上,RankSVM+LM在RankSVM的基础上分别对排名预测准确率和成对比较预测准确率提高0.7%和2.8%,而ListMLE+LM在RankSVM+LM的基础上,分别提高0.2%和0.4%。当引入描述翻译忠实度的双向翻译概率特征时,预测准确率得到了进一步的提高。最终,ListMLE+LM+TransProb比BLEU尺度在测试集上对排名预测准确率和成对比较预测准确率分别提高2.4%和4.0%。以上结果表明,基于ListMLE方法的机器译文自动评价方法能显著地提高译文质量预测的准确率,并且引入的语言模型特征和双向翻译概率特征对提高译文质量预测准确率也有较大的帮助。
需要说明的是,由于RankSVM开源工具包采用的是一种成对比较的排序学习方法,它的优化目标是成对比较预测准确率,因此,在表4中,Rank-SVM 方法在开发集上成对比较预测准确率比ListMLE方法高,但是在测试集上,ListMLE方法仍然比RankSVM方法预测准确率高。这可能是由于RankSVM方法在开发集上过学习而导致的。
表5和表6分别给出了在IWSLT’08 BTEC CE ASR任务上,不同的译文自动评价方法排名预测准确率和成对比较预测准确率。由于在IWSLT’08 BTEC CE ASR任务上,每个源语言句子有16个参考译文,而在WMT德英翻译任务中,每个源语言句子仅有1个参考译文,因此,在IWSLT’08 BTEC CE ASR任务上不同译文评价方法的预测准确率均比在WMT德英任务上高。
表5在IWSLT’08BTECCEASR任务上三折交叉验证平均排名预测准确率

RankaccuracyDEV/%TST/%BLEU39.039.0RankSVM41.741.7ListMLE41.941.7RankSVM+LM44.144.1ListMLE+LM45.145.0RankSVM+LM+TransProb48.147.8ListMLE+LM+TransProb48.348.3
表6在IWSLT’08BTECCEASR任务上三折交叉验证平均成对比较预测准确率
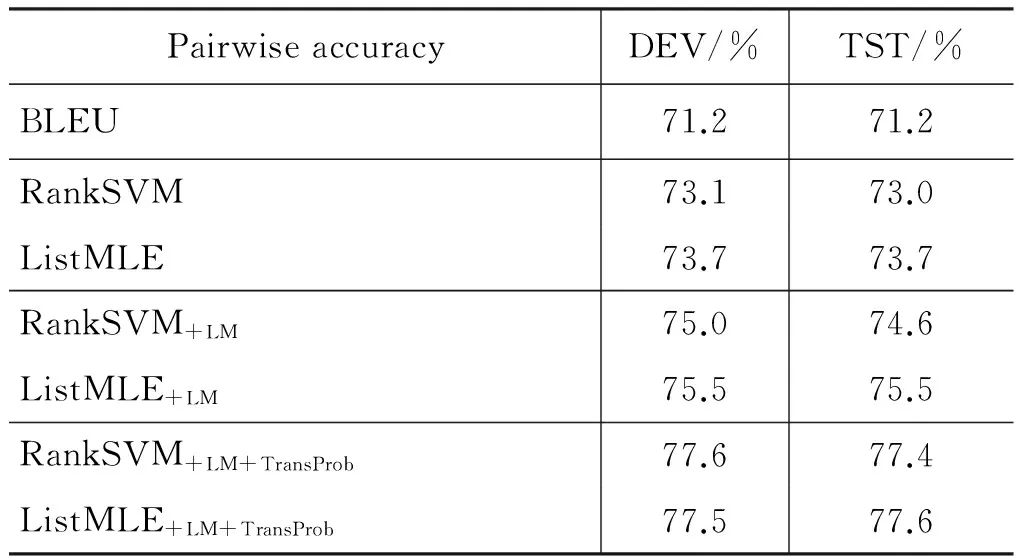
PairwiseaccuracyDEV/%TST/%BLEU71.271.2RankSVM73.173.0ListMLE73.773.7RankSVM+LM75.074.6ListMLE+LM75.575.5RankSVM+LM+TransProb77.677.4ListMLE+LM+TransProb77.577.6
在测试集上,使用所有特征的List-MLE+LM+TransProb方法比BLEU尺度对排名预测准确率和成对比较预测准确率分别提高9.3%和6.4%,比RankSVM+LM+TransProb分别提高0.5%和0.2%。以上实验结果同样证实,基于ListMLE方法的机器译文自动评价方法能显著地提高译文质量预测的准确率。
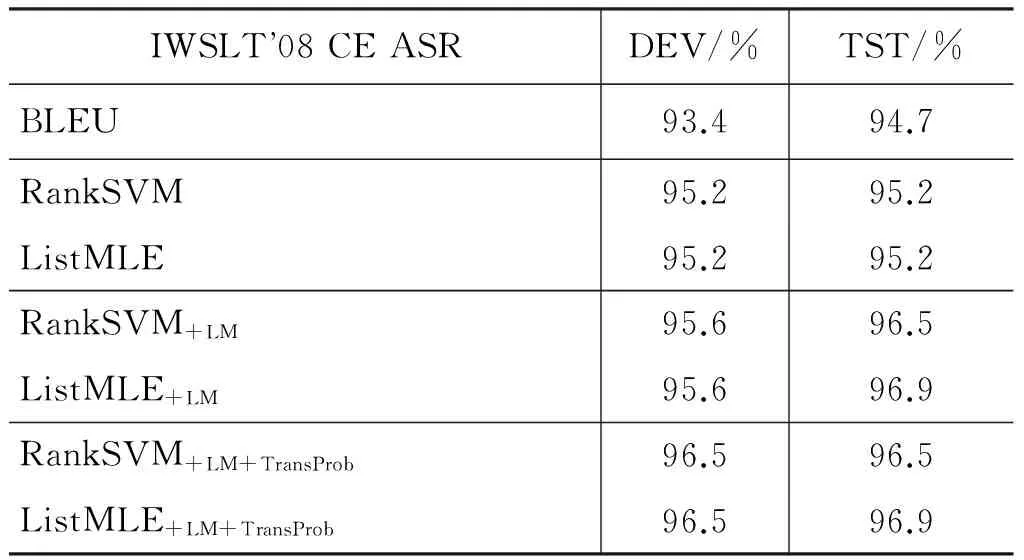
表7和表8分别给出了在评价WMT德英任务和IWSLT’08 BTEC CE ASR任务上的多个翻译系统的输出译文质量时,不同的自动评价方法的结果与人工评价的系统级别相关性。在WMT德英任务,与BLEU尺度相比,基于RankSVM方法和ListMLE方法的译文自动评价方法均对系统排名的预测准确率有较大幅度提高,其中ListMLE方法的提高幅度最大,当引入语言模型特征和双向翻译概率特征后,系统级别的相关性进一步提高,在测试集上提高了33.4%。在IWSLT’08 BTEC CE ASR任务上,我们给出了一轮交叉验证时,不同的自动评价方法与人工评价方法的系统级别相关性。由于评价的翻译系统数较少(14个),基于ListMLE方法的译文评价方法在BLEU尺度的基础上提升的幅度较小,最终在测试集上只提高2.2%。但是,与基于RankSVM的自动评价方法相比,我们发现基于ListMLE方法的译文评价方法仍然对系统级别的相关性提高幅度最大。
表7在WMT德英任务上不同的自动评价方法与人工评价的系统级别相关性
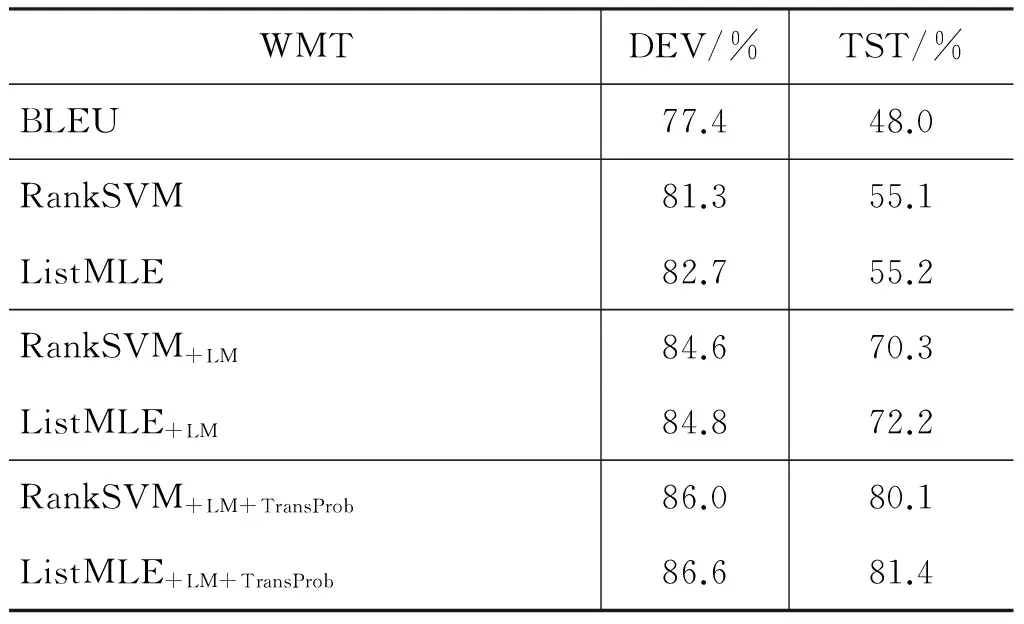
WMTDEV/%TST/%BLEU77.448.0RankSVM81.355.1ListMLE82.755.2RankSVM+LM84.670.3ListMLE+LM84.872.2RankSVM+LM+TransProb86.080.1ListMLE+LM+TransProb86.681.4
表8在IWSLT’08BTECCEASR任务上一轮交叉验证时不同的自动评价方法与人工评价的系统级别相关性
IWSLT08CEASRDEV/%TST/%BLEU93.494.7RankSVM95.295.2ListMLE95.295.2RankSVM+LM95.696.5ListMLE+LM95.696.9RankSVM+LM+TransProb96.596.5ListMLE+LM+TransProb96.596.9
4 总结和展望
本文提出了基于ListMLE排序学习方法的机器译文自动评价方法。实验结果表明,ListMLE方法及本文引入的语言模型特征和双向翻译概率特征能较好地提高自动评价方法与人工评价方法的一致性。
与BLEU尺度相比,基于ListMLE排序学习方法的机器译文自动评价方法能较好的融合多种描述译文质量的特征。因此,未来的工作包括有效地引入更多描述译文质量的句法和语义特征,来进一步提高自动评价方法与人工评价方法的相关性。
[1] Zhifei Li, Chris Callison-Burch, Chris Dyer, et al. An Open Source Toolkit for Parsing-based Machine Translation[C]//Proceedings of the WMT. 2009.
[2] Callison-Burch Chris, Philipp Koehn, Christof Monz, et al. Findings of the 2011 Workshop on Statistical Machine Translation[C]//Proceedings of the WMT, Edinburgh, Scotland, UK, 2011: 22-64.
[3] Chang Liu, Daniel Dahlmeier, Hwee Tou Ng. Better Evaluation Metrics Lead to Better Machine Translation[C]//Proceedings of the EMNLP, Edinburgh, Scotland, UK, 2011: 375-384.
[4] Kishore Papineni, Salim Roukos, Todd Ward, et al. BLEU: a Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the ACL, Philadelphia, Pennsylvania, 2002: 311-318.
[5] Callison-Burch Chris, M Osborne, Philipp Koehn. Re-evaluating the role of BLEU in machine translation research[C]//Proceedings of EACL, 2006:249-256.
[6] David Chiang, Steve DeNeefe, Yee Seng Chan, et al. Decomposability of translation metrics for improved evaluation and efficient algorithms[C]//Proceedings of the EMNLP, Honolulu, Hawaii, 2008:610-619.
[7] George Doddington. Automatic Evaluation of Machine Translation Quality Using N-gram Cooccurrence Statistics[C]//Proceedings of the HLT, San Diego, California, CA, USA, 2002: 138-145,.
[8] Satanjeev Banerjee, Alon Lavie. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments[C]//Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, 2005:65-72.
[9] I Dan Melamed, Ryan Green, Joseph P Turian. Precision and Recall of Machine Translation[C]//Proceedings of the HLT-NAACL, Edmonton, Canada, 2003:61-63.
[10] Matthew Snover, Bonnie Dorr, Richard Schwartz, et al. A Study of Translation Edit Rate with Targeted Human Annotation[C]//Proceedings of AMTA, Cambridge, 2006: 223-231.
[11] S Corston-Oliver, M Gamon, C Brockett. A Machine Learning Approach to the Automatic Evaluation of Machine Translation[C]//Proceedings of the ACL, 2001:148-155.
[12] A Kulesza, S M Shieber. A Learning Approach to Improving Sentence-level MT Evaluation[C]//Proceedings of the TMI, 2004:75-84.
[13] Sebastian Padó, Michel Galley, Dan Jurafsky et al. Robust Machine Translation Evaluation with Entailment Features[C]//Proceedings of the ACL, Suntec, Singapore, 2009: 297-305.
[14] Joshua S Albrecht, Rebecca Hwa. Regression for Machine Translation Evaluation at the Sentence Level[J]. Machine Translation, 22 (1-2): 1-27.
[15] L Specia, J Giménez. Combining Confidence Estimation and Reference-based Metrics for Segment-level MT Evaluation[C]//Proceedings of the AMTA, Denver, Colorado, 2010.
[16] Yang Ye, Ming Zhou, Chin-Yew Lin. Sentence Level Machine Translation Evaluation as a Ranking Problem: One Step Aside from BLEU[C]//Proceedings of the WMT, Prague, Czech Republic, 2007: 240-247.
[17] Kevin Duh. Ranking vs. Regression in Machine Translation Evaluation[C]//Proceedings of the WMT, Columbus, Ohio, 2008: 191-194.
[18] X Song, T Cohn. Regression and Ranking based Optimisation for Sentence Level Machine Translation Evaluation[C]//Proceedings of the WMT, Edinburgh, Scotland,2011.
[19] H Li. A Short Introduction to Learning to Rank[J], IEICE Transactions on Information and Systems, vol. E94-D, 2011.
[20] T Joachims, T Finley, C N J Yu. Cutting-plane Training of Structural SVMs[J]. Machine Learning, 2009, 77 (1): 27-59.
[21] F Xia, T Y Liu, J Wang, et al. Listwise Approach to Learning to Rank: Theory and Algorithm[C]//Proceedings of the 25th International Conference on Machine learning, 2008:1192-1199.
[22] Z Cao, T Qin, T Y Liu, et al. Learning to Rank: From Pairwise Approach to Listwise Approach[C]//Proceedings of the 24th International Conference on Machine Learning, 2007:129-136.
[23] T.-Y. Liu. Learning to Rank for Information Retrieval[M], Now Publishers Inc., 2009.
[24] H Li, Learning to Rank for Information Retrieval and Natural Language Processing[M], Morgan & Claypool Publishers, 2011.
[25] R L Plackett, The analysis of permutations[J], Applied Statistics, 1975,24: 193-202.
[26] R D Luce, Individual choice behavior[M], Wiley, 1959.
[27] Michael Paul. Overview of the IWSLT 2008 Evaluation Campaign[C]//Proceedings of IWSLT 2008, Hawaii, USA, 2008:1-17.
[28] Chris Callison-Burch, Philipp Koehn, Christof Monz et al. Findings of the 2010 Joint Workshop on Statistical Machine Translation and Metrics for Machine Translation[C]//Proceedings of the WMT, Uppsala, Sweden, 2010:17-53.
