中国机器翻译研究的机遇与挑战
——第八届全国机器翻译研讨会总结与展望
2013-04-23杜金华宗成庆
杜金华,张 萌,宗成庆,孙 乐
(1. 西安理工大学 自动化与信息工程学院,陕西 西安 710048; 2. 中国科学院自动化研究所 模式识别国家重点实验室, 北京 100190;3. 中国科学院软件研究所, 北京 100190)
1 引言
自从20 世纪90 年代初IBM的研究人员Peter Brown等提出IBM模型以来[1],基于统计的方法逐渐成为机器翻译研究的主流。这一方法极大地推动了机器翻译技术的发展。近年来,相继涌现出了多种类型的统计机器翻译模型,例如,基于短语的翻译模型[2-3]、层次短语的翻译模型[4]及基于句法的翻译模型[5-9]等,其翻译质量也在不断提高。2002 年之后,翻译质量自动评估方法BLEU[10]的出现极大地推动了统计机器翻译技术的发展,同时也有效降低了人工评价的成本。这些年来,随着统计机器翻译尤其是基于短语的机器翻译在技术上的日趋成熟和稳定,统计机器翻译技术不断地向实用化和商业化迈出有力的步伐。因此,技术的快速发展逐渐使人们树立起对机器翻译的信心,社会对机器翻译的需求开始日益增大,期望也越来越高。然而,从学术研究角度看,无论是基于短语的翻译模型,还是基于句法的翻译模型,在经历了一个快速发展阶段之后,现有的理论方法和技术模型对于翻译性能的提高已开始显露“瓶颈”;从产业化和实用化的角度看,社会对更加实用的机器翻译系统有迫切需求,而机器翻译的结果相对于人类的要求,差距仍然非常大。因此,对于机器翻译的研究人员来说,在兴奋地看到机器翻译系统评测的BLEU分值越来越高,Google、百度、有道等一批企业开发的在线机器翻译系统的性能日新月异的同时,所面临的各种挑战也越来越多、越来越大。那么,机器翻译学术界将如何在激烈的竞争中占有一席之地?中国机器翻译研究的出路和突破口在哪里?面对如此沉重的话题我们不得不暂时停下匆忙的脚步静静地想一想,抬起头来仔细地看看前进的方向,不要让自己因为走得太远而忘记了为什么要走、去向何方?
基于上述状况,中国中文信息学会于2012年9月20~21日在西安理工大学召开了第八届全国机器翻译研讨会(CWMT2012)*研讨会网址:http://zdh.xaut.edu.cn/cwmt2012/。全国机器翻译研讨会已经成功召开七届,大大推动了我国机器翻译研究与应用的发展[11-12]。本次研讨会既没征集论文,也没有组织机器翻译评测,而是邀请学术界和工业界从事机器翻译研究和开发的同行就机器翻译的理论方法、应用技术和评测活动等若干问题进行深入的研讨,其目的是希望与会的专家、学者和工业界人士能够在认真思考和热烈讨论的过程中碰撞出思想的火花,为进一步推动中国机器翻译领域的发展产生积极的作用,同时为中国机器翻译下一步的发展寻找新的突破口。
本届研讨会分设6个专题研讨,分别是: (1)机器翻译理论方法;(2)机器翻译应用;(3)语音翻译;(4)少数民族语言与机器翻译;(5)机器翻译评测;(6)系统展示。本文将详细介绍各个专题研讨的焦点问题和成果。
本文其余部分的组织如下: 第2节主要对每个专题的主题发言进行归纳和分析;第3节对专题研讨中与会者所关注的焦点问题和讨论过程进行了介绍,并给予相应的分析和总结;第4节简单介绍系统的展示环节;最后给出本次研讨会的总结与展望。
2 专题报告
本节分别介绍6个专题发言的情况,并对其做简要分析。
2.1 机器翻译理论方法
该专题主要从科学问题研究的角度出发,对当前机器翻译研究中所涉及的理论方法进行分析,并对几个热点问题的研究状况进行了讨论。厦门大学的史晓东教授和东北大学的朱靖波教授主持了该专题研讨。
微软亚洲研究院的刘树杰博士主要介绍了一种基于图的一致性翻译方法。在一般的多系统融合或者重排序问题中,传统的方法主要依据机器翻译系统输出的N-best列表提取翻译候选的一致性特征,而对于源语言端结构化的一致性信息未加以考虑。刘树杰所提方法的基本出发点是针对一致性信息,如果两个源语言句子比较相似,那么它们的目标语言句子也应当比较相似。因此,可将SMT看作结构学习问题,通过相似的源语言句子的翻译候选提取基于图的一致性特征,然后使用基于图的半监督方法和结构化的标记传播算法将一致置信度作为特征加入SMT常用的对数线性模型中。最后将该模型应用于SMT的重排序和解码过程,显著提高了SMT的翻译性能。
清华大学的刘洋博士从面向统计机器翻译的知识获取角度阐述了当前基于统计方法的知识获取的自动化程度不断提高,同时在语言层次上不断加深,强调了从互联网或其他数据源自动获取高覆盖率、深层次翻译知识的重要性和挑战性,同时也提出了采用半监督学习方法将有限的专家知识与无限的互联网数据有效结合起来的思路。
中国科学院计算技术研究所的谢军博士主要分析了现有的依存树到串的翻译模型的不足之处,即现有的翻译规则在调序、时态、语态及处理非组合短语等方面存在的局限性,说明了规则表示在一定程度上决定了翻译模型的能力,可以通过引入词义信息、词汇化上下文、结构化上下文等知识进一步改进规则表示,同时也分析了成分树和依存树包含的知识具有一定的互补性,理论上可以基于两种树结构设计新的规则表示,从而更好地兼容两种树结构的优点。
中国科学院自动化研究所的张家俊博士作了题为“统计机器翻译的问题与思考”的主题发言,主要就目前统计机器翻译研究的两个热点和难点问题作了探讨: (1)如何最大程度地克服句法翻译模型的局限性;(2)如何从非平行语料中获取有效的翻译知识。针对第一个问题,他从三个方面进行了分析,首先对于同时利用源端与目标端句法知识的情况,提出了源端采用模糊算法,而目标端精确使用句法知识的方法,即弱化的模糊树到精确树的翻译模型,从而可以在一定程度上提高传统串到树模型的翻译性能。其次,针对句法规则中由于终结符的过分泛化而导致的歧义问题,提出了利用双语词汇化的同步树替换文法,同时采用生成式模型和判别式模型以降低规则的过分泛化现象,从而达到显著提高翻译性能的目的。但词汇化的引入也增加了解码的复杂度,如何找到一个平衡点是需要解决的难题。最后,针对句法分析模型与翻译模型之间的不兼容问题,即句法树由单语句法分析器产生,而词语对齐是由平行语料学习获得的,如何找到一种有效的方法能够将基于单语句法树的结构与基于词对齐的信息进行一致性处理,提出了以词对齐的双语语料为输入,无监督地学习兼容词对齐信息的目标语言句法树结构,并验证了该方法在串到树翻译模型上明显优于传统的句法树方法。另外,张家俊也提出了是否可以找到一种更有效的方法同时学习词对齐信息与句法树结构的思路。针对第二个问题,现状是虽然存在大规模的源语言或目标语言的单语语料,然而多数情况下却无法获得面向新数据领域及新语言对的高质量双语平行数据。因此,能否可以直接从非平行语料中学习翻译模型?这是一个开放问题,也是一个难点问题。张家俊就此问题提出了自己的见解,他认为可以考虑采用无监督的词典学习方法以及根据词典和大规模单语语料用机器学习方法来学习翻译规则。
来自新加坡信息通信研究所(I2R)的张民博士就目前统计翻译翻译研究的一些开放问题和焦点问题进行了阐述,例如,建模、模型的泛化能力、结构异构、机器学习方法在SMT的适应等,提出了下一步可能的重点研究方向,例如,面向MT的多语言文法归纳、基于非平行语料库的SMT及基于语义的SMT等。
最后,苏州大学的周国栋教授就基于句法的翻译模型对翻译性能的贡献与其引入的模型复杂性这一对矛盾进行了细致、深入的分析,他认为目前句法知识的贡献并不显著,主要表现在两点: 一是短语系统可以很好地获取局部句法知识;二是句法系统所获取的长距离句法知识非常粗浅。尤其是对汉语来说,其句法和语义之间差距太大,虽然近年来在句法翻译模型方面有一定的进展,但是其语言模型却因为太复杂而少有涉及。因此,对于句法系统的研究无论是在降低模型复杂度上,还是在如何更有效地利用句法知识上,还有很长的路要走。
2.2 机器翻译应用
机器翻译应用专题主要由工业界同行从工业应用的角度对当前MT系统在产品化、产业化过程中的优势及不足之处进行了分析。本专题由微软亚洲研究院的李沐博士和百度公司的马艳军博士共同主持。
首先李沐博士从微软的机器翻译服务和本地化词典服务两个方面介绍了机器翻译在微软产品中的应用。就翻译服务而言,机器翻译服务的核心是围绕着统计机器翻译系统展开,采用统计机器翻译技术和大规模数据驱动技术,应用于MSDN翻译服务、与搜索引擎集成的翻译服务、与浏览器集成的翻译服务、与Office集成的翻译服务、可定制的翻译服务、面向移动应用平台的翻译服务等多个方面。针对本地化服务问题,不仅需要提供词典查询,同时机器翻译的功能也是必不可少的。总之,统计机器翻译技术在微软的产品中不仅得到了广泛应用,而且将会逐渐满足更多的社会需求。
来自中国科学院计算技术研究所橙译中科的骆卫华博士分别从创业与机器翻译产业化两个角度,结合用户的实际需求、翻译市场发展趋势、不同用户对MT的期望及先驱创业者所带来的教训和经验等几个方面,对机器翻译在商业化的过程中所产生的问题和解决方案做了深入探讨。他认为,当前翻译市场发展迅速,市场对MT的需求广泛而多样,真正实用的翻译系统需要MT与其他技术的融合,才能真正满足客户需求。同时,MT的可行商业模式仍需不断摸索和探索,成功的技术转化和商业模式还需要很长的路要走。
针对信息检索中的翻译问题,马艳军博士做了关于“机器翻译在搜索引擎中的应用”的报告,他结合机器翻译技术在百度产品中的应用,主要阐述了在线翻译、垂直搜索、跨语言检索等方面机器翻译的使用情况。马艳军认为在当前互联网已经成为主要信息交流和交换平台的背景下,翻译技术所面临的挑战主要有翻译质量(抗噪性、覆盖率和时效性)、移动应用、电子商务、SNS应用等,同时指出翻译技术可以作为通用技术为其他技术人员所用,如用户输入的查询改写、句子简化和音译等方面。
最后,来自中国电子信息产业发展研究院(CCID)的肖健研究员首先介绍了机器翻译在CCID的历史和当前的进展状况,指出机器翻译在军事情报分析领域广泛应用的现状,而且对于多语言的信息浏览和信息提取是必不可少的。军事领域要求机器翻译结果具有更好的可读性和准确度。结合机器翻译未来需求的发展趋势,肖健指出了一个金字塔形状的翻译市场正在形成,即受成本限制,只有10%的任务需要人工翻译,70%的文档需要机器翻译,而中间20%的信息则会采用后编辑(post-editing)方式进行翻译。由此,可以预测未来将会形成一个很大的机器翻译市场,并创造出译后编辑的工作岗位,从而大大地提高了翻译人员的工作效率。
2.3 语音翻译
语音翻译技术是集语音识别、口语翻译和语音合成为一体的一项技术,也是当前移动互联时代最受瞩目的影响人类生活的重大技术之一。本专题由中国科学院自动化研究所的徐波研究员做了“对语音翻译现状的认知以及展望”的主题报告。他回顾了语音翻译技术的发展历程,结合中国科学院自动化研究所研发的“紫冬口译”语音翻译系统的经验,深入分析了语音翻译应用的定位、框架和实现,并对存在的问题提出了可能的改进措施。
自20世纪80年度末以来,语音翻译技术一直备受各国政府和研究机构关注和重视。然而,回顾过去,语音翻译技术的发展不是非常迅速。早期的语音翻译仅仅在天气信息、观光旅游、购物和旅馆预订等限定领域实验研究,语料库规模较小,口语识别的鲁棒性以及翻译的鲁棒性不够高,主要以研究、系统演示和展示为主。随着移动互联网的发展和推广,以及国际合作在技术共享、语料建设等方面的发展,语音翻译在近几年得以快速发展。中国科学院自动化研究所作为国际口语翻译联盟(C-STAR)的七个核心成员之一,主要从事汉语和其他语言的互译及资源建设工作,先后成功地开发了汉、日、英双向旅游对话语音翻译系统原型(2001年)、中韩口语电话翻译演示原型系统(2002年)、汉英双向语音实时互译系统(2004年)等,并于2007、2008、2009年在IWSLT 国际口语翻译评测的汉英翻译任务中均取得优异成绩。
2012年6月中国科学院自动化研究所在伦敦U-STAR组织的23国语言同声翻译技术展示会上成功地发布了一款涵盖语音和文本两种翻译模式的汉英互译软件——紫冬口译1.0版本(ZTSpeech 1.0)。该软件支持安卓和iPhone手机平台,其框架流程如图1所示。
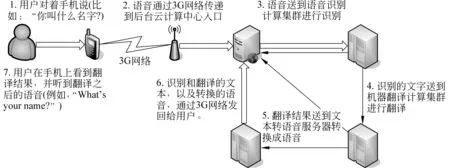
图1 紫冬口译的平台框架流程图
紫冬口译(ZTSpeech)具有以下特点: (1)基于云计算的统计语音识别和统计翻译模式;(2)面向通用领域,有较高的识别和翻译鲁棒性;(3)利用超大规模数据、超大规模计算和超大规模存储资源; (4)针对有准备的语音(Prepared Speech),其自然度介于书面语和口语之间。该系统集中体现了中国科学院自动化所在语音识别、机器翻译和语音合成等几方面多年来的技术积累和研究成果,并通过云服务模式使得在线系统进行迭代式改进,其识别和翻译的性能不断提高。
尽管语音翻译的性能得到了显著提高,但目前仍存在较多问题,例如,双语口语平行语料匮乏,虽然可以从网络获取大规模数据,但存在数据领域适应、噪声等问题;中文分词及中文口语的特点对翻译效果会产生严重影响。可能改进的途径主要有: 针对海量语料的深度处理及分类筛选,挖掘出高质量、分领域的口语双语语料;开发出针对中文口语的分词及文本处理工具,以适应口语翻译的特点;融合浅层分析的口语翻译系统和翻译模板的层次短语翻译系统;建立系统化、工程化的调试程序来改善系统。基于此,在未来五年内,面向人类沟通交流的语音翻译应用会有更大的发展。
2.4 少数民族语言与机器翻译
该专题由内蒙古大学的那顺乌日图教授和青海师范大学的陈玉忠教授主持,主要从少数民族语言的多语种机器翻译技术、语言资源建设等方面的进展及面临的挑战进行了介绍和分析。
新疆大学的吐尔根教授从中亚诸多语言的共性出发,指出中亚诸多语言基本上属于阿尔泰语系的突厥语族,差异性较小,可以构造中亚诸多语言之间的机器翻译模型以及翻译软件,从而为汉语—中亚诸多语言间机器翻译打下坚实基础。目前,新疆多语种机器翻译研究亟需解决的问题主要有中亚诸多语言资源的建设、编码自动识别和转换技术、多语言深层次的形态分析方法等,可以考虑首先从资源缺乏的突厥语族语支内语言间的机器翻译方法入手,对中亚诸多语言间的统一翻译进行建模。同时,在以上研究基础上开展面向新疆多语言业务的云计算服务平台构建技术的研究。
中国科学院计算技术研究所的姜文斌博士就少数民族语言处理和翻译问题,结合他所在课题组已经开展的前期工作,主要从少数民族语言本身的复杂性进行了分析和阐述。从语言学的角度看,主要存在三个问题,即拼音语言的拼写校对问题,如蒙语、维语等,可能的解决方案是借助语言学规则加统计排歧的拼写校对方法来改进词语对齐、规则抽取或者使拼写校对系统输出候选词图结构来进一步改进翻译解码过程;分词和分句问题,如藏语等。藏语的分词、分句问题已经得到很好的解决,但是对于机器翻译仍存在许多问题,可能的解决方案是利用分词系统输出高质量且稀疏的词图,然后进行基于词图的词对齐、翻译规则抽取和概率估计等;黏着语的形态分析问题,如蒙语、维语等。黏着语词汇形态变化丰富,在翻译时需进行形态分析,虽然问题本身解决得尚好,但仍存在形态分析和拼写校对纠结在一起的问题。将词干和词缀的缀接比作是句法构造过程也许是一种好的解决思路。
中国科学院合肥智能机械研究所的李淼研究员和内蒙古大学的那顺乌日图教授分别从少数民族语言机器翻译资源与技术瓶颈的角度,分析了当前民文机器翻译存在的主要问题。他们首先介绍了目前少数民族语言机器翻译的研究现状,指出虽然取得了一定的进展,但仍存在较多问题,例如,语料资源短缺、人才资源短缺和语言处理技术落后等。那顺乌日图教授指出,资源匮乏仍是制约民文机器翻译发展和实用化开发的瓶颈问题,可以尝试从政策扶植、市场拓展、扩大应用、建立少数民族语言资源联盟等几方面着手,逐步完善当前民文机器翻译的不足。李淼研究员指出,机器翻译系统离实用仍相差甚远,尤其是针对少数民族丰富语言特征的自动翻译技术,短期内难以有较大的突破。在今后的工作中,可以借鉴在线翻译技术和实时语音翻译技术等采用的大规模计算方法来改进少数民族机器翻译的性能。
2.5 机器翻译评测
自从2002年自动评价准则BLEU提出以后,机器翻译译文质量自动评价取得了快速发展,机器翻译评测活动已经成为国内外机器翻译研究和应用的直接推动力。本专题由哈尔滨工业大学的杨沐昀博士和中国科学院计算技术研究所的吕雅娟博士主持并做报告。
杨沐昀博士回顾了机器翻译自动评价十年来的发展和现状,指出机器翻译的发展已成为自动评价为导向的建模研究,一般采用多种自动评价指标验证成果、考量性能,因此,自动评价已成为机器翻译中的关键因素之一,但仍存在较多问题和挑战,例如,1)语言学特征能否解决评价问题?2)用户选择什么样的译文?杨沐昀博士结合两个实验,分别分析了以上两个问题。实验1主要衡量语言学特征在自动评价中的作用,通过在词汇层、短语层、句法层和篇章层选定了55种语言学错误,采用152个人工翻译样本和324个机器翻译样本,以SVM回归模型进行特征融合,初步得出相比于自动评价特征,语言学特征能部分提升评价性能,并且字符串相似度特征(BLEU、NIST等)与语言学特征形成互补,融合后效果更好。实验2主要考察了翻译用户的选择与自动评价的关系,通过向翻译人员提供299句来自5个不同自动翻译系统的翻译结果,自主选择一个译文修改并完成人工翻译,得出如下两个结论: (1)在系统级方面,一般自动评价的得分越高,被选择编辑的句子数量越多,说明在系统性能有显著性差异时,自动评价准则是有区分度的;(2)在句子级方面,无论在与人工评价的相关性方面,还是句子使用率和句子的编辑量上,NIST和METEOR要显著高于BLEU和TER,这为自动评价的优化目标提供了一个有价值的参考。最后,对于未来机器翻译自动评价方法和技术的研究方向,杨沐昀指出翻译自动评价也许不存在唯一解,需要从三个不同的角度开展研究: ①从翻译模型训练角度,需要具有良好的数学特性、满足不同学习算法的评价方法;②从机器翻译研究人员的角度,需要某种“白箱”评价技术;③从翻译用户的角度,需要经济、可靠、能够体现用户满意度的指标。
吕雅娟博士首先对前几届机器翻译评测的情况进行了回顾。她指出,前几届测评的主要目标是推动研究单位间的实质性交流,推进我国机器翻译技术的发展。然后,吕亚娟分别从组织方式、项目设置和评价方法等方面介绍了历届评测活动,并根据历届评测结果的统计分析得出如下结论: (1)翻译质量逐渐由提高显著到提高不显著;(2)各参评单位的差距逐渐缩小;(3)随着越来越多研究机构加入测评活动,统计翻译技术已经得到普及和关注。针对目前测评活动中存在的问题,如传统项目近两次评测进展不显著,各单位技术交流不够深入,很多单位利用开源系统、缺少技术特点,自动评测指标BLEU有时不能很好地评价翻译结果等,吕亚娟提出了2013年机器翻译评测的设想,主要包括: (1)参评系统提交关键步骤中间结果,以促进参评单位间更深入的技术交流;(2)组织方提供基线(Baseline)系统、源代码和中间数据,减少低水平的重复;(3)采用“众包”的方式引入参加评测的单位参与的人工评测和新的自动评价准则,探索更合理的评价方法。最后,吕亚娟发布了2013年机器翻译评测方案和时间结点,并就具体事宜和与会者进行了讨论。
3 专题研讨
六个专题报告之后,每个专题分别邀请了几位专家就当前相关的研究热点、难点及开放问题与与会学者进行了讨论。本文就讨论中所关注的几个问题归纳如下。
3.1 句法知识的作用
无论是对于句法知识如何融入基于短语的机器翻译模型或是纯粹的基于句法的机器翻译系统,句法知识究竟能发挥多大作用,一直是一个饱受争议的话题。张家俊博士的报告指出句法知识有助于提高机器翻译的性能,但是句法模型也存在一定的局限性,如规则中终结符过分泛化的现象严重、规则规模较大等。周国栋教授在报告中指出: 句法翻译系统对于性能的提高是否值得使其模型的复杂度过高?针对这一问题,专家们的解释是: 不同的方法都有其特点,并非一定要有最好的结果才认为它是好的方法。关于句法方面的研究,方向是对的,但仍需继续往深度和广度发展。同时,句法不是使用一些组合就可以得到的,它需要一些语料,而且考虑到机器翻译研究的健全性,也应该要引入句法知识。从另一个角度讲,机器翻译的两个基本问题是择词和调序,基于句法的模型最大优势就是在其调序能力上。单纯使用BLEU去评价它的贡献则显得有失偏颇。不可否认的是,基于句法的表达能力比基于短语的表达能力好很多,如果可以提供更多的数据,或者引用方法适当的话,效果会更好。在调序方面,基于句法的模型优于基于短语的模型,其更接近自然语言的表达。我们在使用中由于经常在句法知识的利用和表达上不到位才导致其没充分发挥出作用,而且句法分析器的性能也给句法知识的作用带来负面影响。因此,对于句法知识,应该采取积极的态度去认识、研究和利用,使其发挥最大效能。
3.2 语义知识在机器翻译中的作用
语义知识本身就是一个复杂的问题,可以理解为句法上的一种扩展,分为很多层面,例如,最简单的词级语义、短语级语义等。现有句法结构实际上已经包含一部分语义知识,用于改善基于句法或基于短语统计机器翻译的性能,但没有结构化的框架。由于语义分析在数据学习能力和表达能力方面还存在缺陷或不完善之处,目前做的层面相对较浅。
如果要把语义知识用到机器翻译上,需要从两个层次考虑: 首先要选择一种合适的模型,其次是如何让模型学习数据。从当前的机器翻译研究情况来看,这还是有一定发展前景的,一种思路是在翻译中模拟人的理解过程,同时把人的理解过程按语义处理成不同层级阶段,再用一些方法依次处理。在应用语义方面,不一定必须通过人类语义的模拟和计算来实现,也可以通过现有的搜索技术手段来使用像语句对那样的语义表征对等。
总的来说,对语义知识研究的首要问题是采用什么样的语义形式,这需要满足三个标准: 可计算、表达能力要强、能方便地从数据中学习。基于语义的翻译是实现翻译的最终目标,但仍需要一步步发展,结合多种方法才能实现。
3.3 关于机器翻译应用
在机器翻译应用方面,关注更多的问题是: (1)数据领域对于机器翻译性能的影响,即如何看待通用领域的翻译和特定领域的翻译?(2)训练语料规模的问题,即语料要达到什么数量级或多少语言对才能用?(3)新词处理的问题,即是否有新的技术处理新词?几位工业界的研究者对以上问题与与会学者进行了深入讨论。他们认为,即使在通用翻译领域,某些方面的翻译也不是很尽如人意,还需探索更满足用户需求的搜索引擎。翻译质量好坏可以分为翻译的可读性和翻译的准确度,不同人群对其需求是不同的。在通用翻译领域需要对细节注意,在专业领域也可以优化改进使之更为通用化。其次,关于数据规模问题,如果单纯训练一个开发系统,百万句即可。然而,对不同领域而言,语料的数量级是不同的,对于专业领域,三四百万的以上句对即可满足基本需求。数据规模越大,不代表翻译性能越好;但数据质量越高,翻译性能一般就越好。最后,对新词问题,要与时俱进,不断获取新的训练数据,对有用的新词数据进行自动挖掘,必要时人工提取。
本专题的讨论引申出一个实际问题,即研究机构与企业之间的角色差异与合作问题。我们认为研究单位和公司之间应是一种互相促进、推动的关系,产学研合作是一个适用的手段,可以做到研究与应用的良性发展。研究单位的成果可以促进公司应用的发展,反过来应用也可以推动科研前进的步伐。但由于目标、定位不同,产业、应用的目标是产品化、利益化、快速化,对于基础性的、方法性的较少关心,而数据是企业的优势;研究单位更多关心的是方法、理论层面的研究与创新。所以,在机器翻译发展的道路上,双方需要不断磨合与合作,才能推动中国机器翻译的研究与应用。
虽然国内机器翻译研究已有很大的发展,但在应用市场方面,机器翻译的性能还远未达到客户要求。科研成果能否进行产品化,对客户而言是否有使用价值以及成本问题将会是市场主要考虑的问题,但其应用前景是不可估量的。在实际应用方面,更应开拓辅助翻译市场和本地化翻译市场,将翻译资源引入到翻译流程管理,使用户与机器翻译更好地结合和互动,针对特定行业,加大机器翻译的推广与应用。
3.4 关于少数民族语言
近年来,少数民族语言信息处理一直是自然语言处理领域关注的焦点之一,主要表现在: (1)少数民族语言的基本处理技术,如维语的调序、藏语的分词等;(2)语料的获取与语料库构建。吐尔根教授、那顺乌日图教授及姜文斌博士等对以上问题进行了分析,认为汉语使用主谓宾结构,而维语使用主宾谓结构,调序的确是个难题,但日语也是主宾谓结构,因此,可以借助日汉翻译方法,尝试用开源代码来解决这个问题。藏语句子切分塑造空间小,如藏语里带竖线的符号,本身就代表句号、逗号、分号等多种意思,分词处理时,只需将这种竖线对应到汉语的句号、逗号、分号即可。少数民族语言的语料库建设一直是较为关注的问题,而且随着多年来的发展,建立了一定的数据资源,但在规模、标准化、双语平行、资源共享等方面仍有较多的问题,需要国家从政策扶持、经费支持、人员投入及合作交流等方面给予支持。
3.5 关于自动评价准则BLEU
BLEU的提出为推动统计机器翻译研究的发展做出了巨大的贡献,早已成为国际上公认的机器翻译性能自动评价准则,包括NIST评测、WMT评测和国内的CWMT评测,都采用BLEU作为主要的评价标准。但随着机器翻译性能的不断提高,翻译模型的日益多样化,BLEU的不足之处也日益暴露出来,近年来,对BLEU的质疑之声也越来越响亮,如BLEU与人工评价的相关度较低、在句法层面较好的翻译结果而BLEU得分较低等。在机器翻译评测专题环节,与会者就此问题进行了激烈而深入的探讨,认为虽然BLEU存在不足之处,但在目前完全抛弃也不可能,合理的方式应该是在评测活动中首先不以某一个自动评价准则为唯一标准,应引入其他与人工评价相关度更好的自动评价准则综合考量。其次,引入人工评价,不衡量每个结果“有多好”,而是评价哪个结果“更好”。最后,仍需探索其他更合理的评价方法。
4 系统展示
本专题主要展示了当前机器翻译技术和方法在系统或产品方面的应用,参加单位及产品有中国科学院自动化研究所的“紫冬口译”口语翻译系统、东北大学的NiuTrans开源机器翻译系统、北京交通大学的专利在线翻译系统、百度公司的机器翻译系统、微软亚洲研究院的在线字典、字幕翻译及对联等。哈尔滨工业大学的赵铁军教授主持了本专题活动。在全球范围内,统计机器翻译技术已经从实验室走向应用,并且表现出不俗的性能,得到越来越多的关注和重视。因此,在当前移动互联和社会计算的大潮下,统计机器翻译技术成为推动社会进步和文化交融的关键技术之一,具有广阔的应用前景。
5 结论及展望
归纳起来,本次研讨会上最受关注的问题主要包括: (1)句法知识或基于句法的翻译系统进一步发挥作用的空间有多大?(2)如何应对机器翻译应用中的实际问题,如数据领域、新词、数据规模等;(3)如何解决语音翻译中关键信息丢失、口语语序等问题;(4)特别关注面向少数民族语言机器翻译的语料库建设问题;(5)机器翻译评测中自动评价方法及评测的组织形式问题。
对以上问题,与会者进行了热烈而充分的讨论,虽然无法在所有问题上达成共识,但对未来工作的展望是基本一致的,概括为以下四点: (1)机器翻译理论和方法研究是支撑机器翻译技术研究和应用的基础,因此,在大规模数据、移动互联时代,亟需更新的和突破性的理论方法破除瓶颈,以推动机器翻译的发展;(2)机器翻译技术真正实用化才能体现其价值。要更多从用户角度去开发和应用机器翻译系统,才能更好地争取用户,服务于社会;(3)需要采取一定的技术手段,以互联网为主要数据源,获取大规模可用的口语资源、少数民族语言数据,制定规范的数据格式标准,实现资源共享;(4)采用更合理的自动评价准则应用于机器翻译评测活动,同时引入高效的人工翻译方式,以评测促进机器翻译的研究与应用;(5) 机遇与挑战。面对已经来临的移动计算时代和大数据时代这个大机遇,国内机器翻译研究人员应当结合实际需求,提出更有效、更高效的方法或模型,使得机器翻译能真正为社会服务。
综上所述,本次研讨会的成功召开大大加强了我国机器翻译研究者之间的交流,对下一步开展工作具有重要的参考价值。
6 致谢
衷心地感谢在本届全国机器翻译研讨会上精彩发言的所有学者,尤其感谢各专题的组织者(按发音顺序): 陈玉忠、李沐、吕雅娟、马艳军、那顺乌日图、史晓东、徐波、杨沐昀、赵铁军、朱靖波。同时,感谢所有参与本次研讨会的专家和学生。
[1] Peter F Brown, Stephen A Della Pietra, Vincent J Della Pietra, et al. The mathematics of statistical machine translation: parameter estimation[J]. Computational Linguistics. 1993, 19 (2): 263-311.
[2] Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of HLT-NAACL. Edmonton, Canada, 2003: 48-54.
[3] Philipp Koehn, Hieu Hoang, Alexandra Birch,et al. Moses: open source toolkit for statistical machine translation[C]//Proceedings of ACL of demo and poster sessions. Prague, Czech Republic, 2007: 177-180.
[4] David Chiang. A hierarchical phrase-based model for statistical machine translation[C]//Proceedings of ACL’05. Ann Arbor, MI, 2005: 263-270.
[5] Kenji Yamada, Kevin Knight. A syntax-based statistical translation model[C]//Proceedings of ACL-EACL’01. Toulouse, France, 2001: 523 530.
[6] Yang Liu, Qun Liu, Shouxun Lin. Tree-to-string alignment template for statistical machine translation[C]//Proceedings of Coling-ACL. Sydney, 2006: 609-616.
[7] Andreas Zollmann, Ashish Venugopal. Syntax augmented machine translation via chart parsing[C]//Proceedings of the WMT, HLT-NAACL. New York, USA, 2006: 138-141.
[8] Min Zhang, Hongfei Jiang, Ai Ti Aw, et al. A tree-to-tree alignment-based model for statistical machine translation[C]//Proceedings of MT Summit XI. Copenhagen, Denmark, 2007: 535-542.
[9] 熊德意,刘群,林守勋. 基于句法的统计机器翻译综述[J]. 中文信息学报, 2008, 22(2): 28-39.
[10] Kishore Papineni, Salim Roukos, Todd Ward, et al. BLEU: a Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the 40th ACL. Philadelphia, USA, 2002: 311-318.
[11] 徐波,史晓东,刘群,等. 2005统计机器翻译研讨班研究报告[J]. 中文信息学报, 2006, 20(5): 1-9.
[12] 赵红梅,吕雅娟,贲国生,等. 第七届全国机器翻译研讨会机器翻译评测总结[J]. 中文信息学报, 2012, 26(1):22-30.
