基于序列标注的中文分词、词性标注模型比较分析
2013-04-23刘一佳车万翔张梅山
刘一佳,车万翔,刘 挺,张梅山
(哈尔滨工业大学 计算机学院 社会计算与信息检索研究中心,黑龙江 哈尔滨 150001)
1 引言
分词、词性标注是诸如信息抽取、信息检索、句法分析、语义角色标注等众多中文自然语言处理任务的第一步。统计中文分词主要有两类方法。第一类是基于字的中文分词。在基于字的分词方法中,字是算法处理的基本单位。中文分词被转化为字序列的序列标注问题[1]。这一类方法给句子中的每个字标注一个标识词边界的类别。多种序列标注算法都可以用来解决基于字的中文分词问题[2]。中文分词的另一类方法是基于词的中文分词。Zhang等人[3]提出利用词特征和柱搜索解码的中文分词方法。这种方法在句子的词序列空间中搜索一个最优词序列。词性标注问题也是一种典型的序列标注问题,与基于字的分词类似,词性标注问题也可以使用序列标注算法解决[4]。
由于汉语中没有显式的词边界,词性标注前需要进行分词,这种先分词后词性标注的串行方法会造成误差传播问题。即错误的分词结果影响词性标注的性能。为了解决误差传播问题,Ng等人[5]最早提出使用联合模型解决分词—词性标注问题的方法。在其方法中,分词—词性标注联合任务被转化成基于字的序列标注问题。这种方法给句子中的每个字标一个可以标识词边界与词性的类别。随后,Zhang等人[6]将基于词的中文分词推广到分词、词性标注联合问题上,提出基于词的联合模型。
虽然联合模型已经在多项研究中被证明具有很好的性能,但其存在解码过程中搜索空间过大问题。过大的搜索空间导致的较低的算法效率很大程度上限制了联合模型的应用。是否存在一种比较快速的方法,可以从一定程度上利用联合模型的特性,在较小损失性能的情况下,达到甚至超过串行模型的速度?从问题的这个特性出发,本文尝试使用分类方法解决分词—词性标注联合问题,由于分类方法不进行全局优化,可以很大程度地提高预测速度。为比较两种方法的性能与速度,本文分别实现了串行模型、分类联合模型。经实验分析发现,分类联合模型与串行模型各自存在优势和劣势,虽然性能差异不大,两种模型却提供了不同的错误类型。
为了进一步利用两种方法的特点,本文尝试使用Stacked Learning框架融合两种方法。本文实现了这一融合模型,并在几种数据集上进行实验。结果表明,融合后的模型在各数据集上都获得了准确率的提升。本文也将融合模型和相关前沿工作在CTB5.0和CTB7.0上进行了对比,均取得了最好的结果。
对于数据驱动的分词—词性标注系统来讲,从数据中抽取的特征很大程度地影响了系统的性能。为了能够公平对比,在实现过程中,本文尽量保证各系统使用相似的特征集合,相同的特征映射、特征检索方式,以期对各系统给出公平的运行速度方面评价。
本文后续章节的组织结构如下。第2节介绍串行模型;第3节介绍分类联合模型;第4节介绍融合模型;第5节为实验及结果;第6节为结果分析;第7节给出结论以及下一步工作。
2 串行模型
2.1 模型
作为研究的第一步,本文在序列标注框架下分别实现了一个分词器和词性标注器,并用它们组成分词—词性标注串行模型。
本文串行模型中的分词器是一个基于字序列标注的分词器。分词器给句子中的每个字标注词首(B)、词中(M)、词尾(E)和单字成词(S)四个类别中的某一个,以表示这个字的词边界。形式化地描述这一方法如下。给定一个字长度为n的字序列c,y∈yn是对这个字序列的一个标注序列,其中Y = {B, M, E, S}。基于字的中文分词模型可以定义为如式(1)的最优化问题。
其中,φ是对字局部特征与类别标注进行映射的函数。例如,对于句子“我是中国人”,i=3的情况下,φ将特征字符串“bigram=是中,tag=B”在特征空间对应的一维置为1。θ是模型的参数向量。
类似的方法可以用来描述词性标注模型。对于一个长度为n的词序列w,词性集合,y∈n是对这个词序列的一个词性标注序列。词性标注模型可以定义为求最优标注序列的问题。
2.2 参数估计
本文使用一种在线机器学习算法框架MIRA[7]对参数θ进行估计。算法1显示MIRA的训练过程。在训练过程中,算法依次处理每个训练实例。对于一个训练实例,算法根据当前模型对这个实例预测最优的K个序列标注结果。并在满足一定约束条件下,用这个K个结果尽可能小幅度地更新参数。
算法1MIRA算法流程
输入:
一组训练实例{(xt, yt), t=1, 2, …, n}
1: 初始化: θ←(0, …, 0)
2: fori=1, 2, …, do
3: for t=1, …, n do
4: 预测最优的K个结果
bestk(y)=argmaxy∈ynΦ(c, y)θ
5: 按照优化目标
obj. min ||θt+1-θt||
st. Φ(c,y)θt+1-Φ(c,y)θt≥L(y,y′),
∀y′∈bestk(y)
更新参数
6: end for
7: end for
在MIRA算法框架中,需要定义一个损失函数L(y, y′)来描述算法对于错误的敏感程度。本文将L(y, y′)定义为序列y′相对于y错误标注的个数。
2.3 特征
在分词特征方面,本文参考了张梅山等人[8]的论文,并从一定程度上化简了其中的词典特征。本文的分词器使用的特征列表如表1所示。
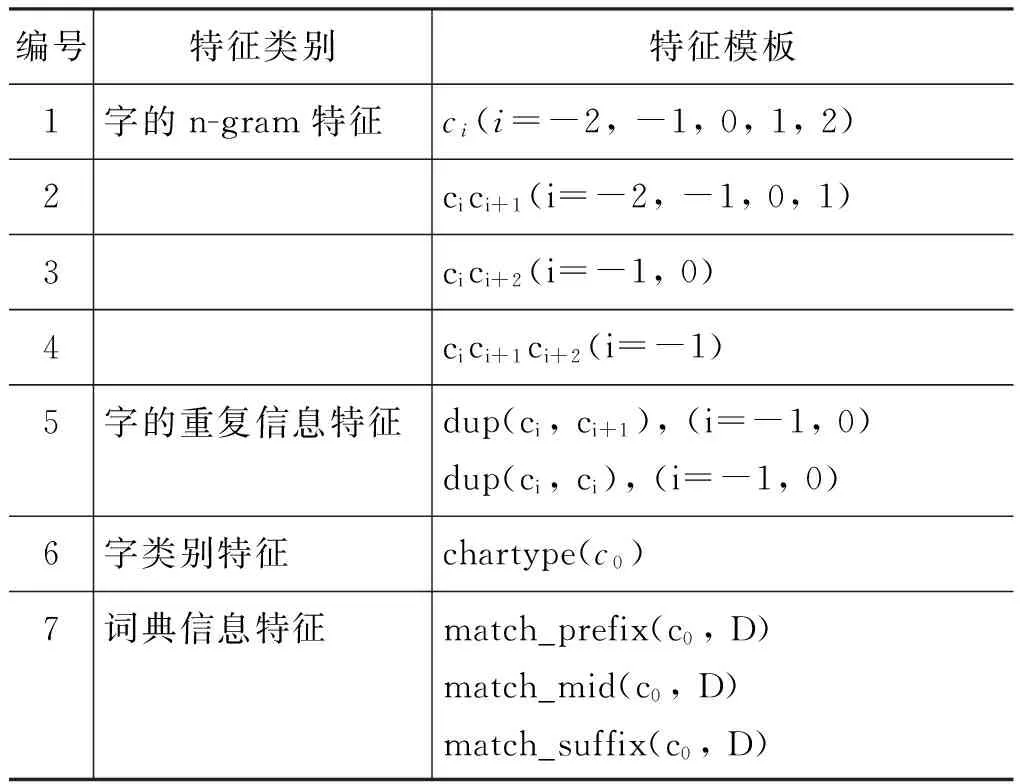
表1 分词器使用的特征
其中,下标代表特征模板中的字与待标注字的相对位置。dup(x, y)表示x, y是否为相同字,chartype(c)表示c的字类型,字类型的定义如表2所示。本文使用的词典特征主要有三类,match_prefix(c0,D)表示以c0为词首的句子片段在词典D中匹配的最长的词,match_mid(c0,D)表示以c0为词中而match_suffix(c0,D)表示以c0为词尾。本文使用的词典通过训练语料构造。构造方法是抽取训练语料中出现的频率大于等于5的词以及其词性构成词典。
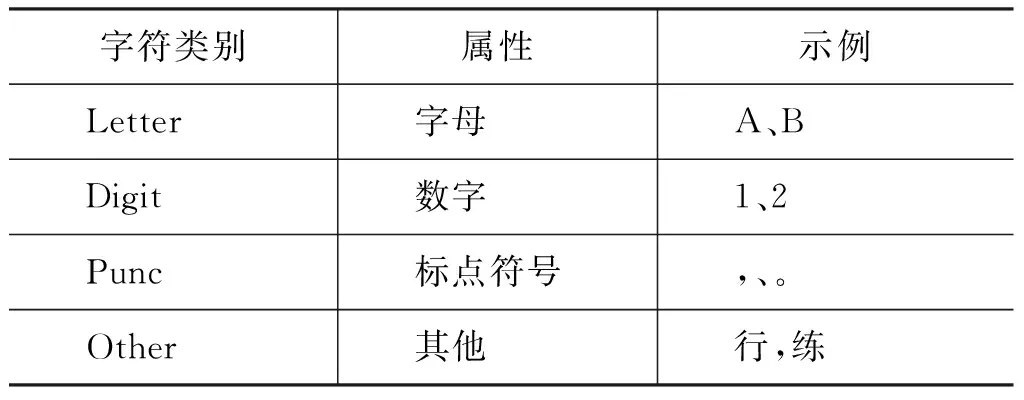
表2 CRF中文分词模型中所使用的基本特征
本文词性标注器使用的特征如表3所示。
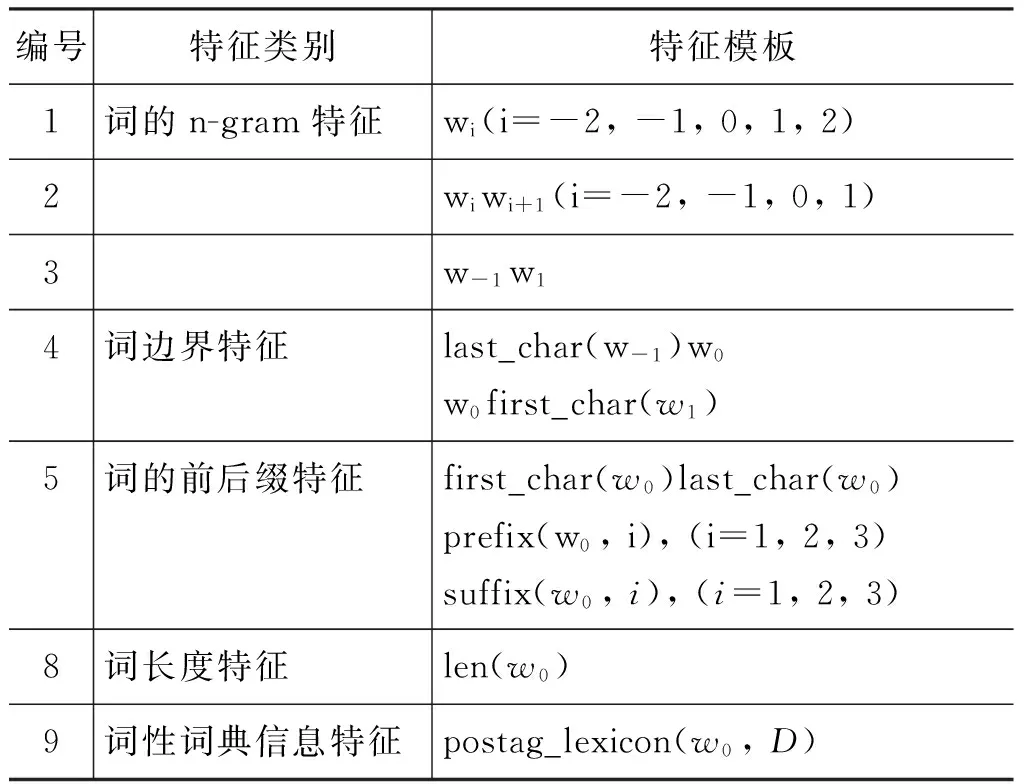
表3 词性标注器使用的特征
其中,last_char(w)代表词w的最后一个字,first_char(w)代表词w的第一个字。len(w)代表词w的长度。对于长度大于5的词,本文将其作长度为5处理。prefix(w,i)代表词w长度为i的前缀,suffix(w,i)代表词w长度为i的后缀。postag_lexicon(w0, D)表示w0在词典中的词性信息。这里,词典的抽取方法与前面分词中用到的词典相同。
3 联合模型
3.1 模型
联合模型可以避免误差传播问题,并且可以利用词性标注的信息帮助调整分词结果。基于字的联合模型给句子中的每个字标一个可以标识词边界与词性的类别。例如,b-n表示这个字是一个名词的词首,i-m表示这个字是一个数词的词中或词尾。由于基于字的联合模型是一种分类任务,可以使用分类方法解决。最简单的分类模型是线性分类模型,本文在此处使用一个线性分类模型预测一个字的词性与词边界。形式化地表示本文的分类联合模型如式(2)所示。
3.2 特征
除了使用与前面分词器相同的特征,本文的分类联合模型还使用了已预测词的信息,表4显示了分类联合模型使用的已预测词信息特征。

表4 联合模型使用的新特征
其中,在算法从左向右运行预测第i个字的类别时,前i-1个字的类别已经得到预测。由于其预测结果包含切分与词性标注信息,当前字的前一词及其词性可以通过这种预测推导得出t-1的前一字的词性。len(w-1)表示前一词的长度。与词性标注模型相同,本文也对这个长度进行了归一化。
4 系统融合
4.1 方法
Stacked Learning是一种元学习算法框架。这种框架使得机器学习算法可以利用一个训练实例周围的实例的类别特征,从而在序列标注等问题上取得更好性能[9]。这种算法框架可以很好地融合多种机器学习模型。Stacked Learning框架由两层组成。第一层包含一个或多个模型g1,g2,…,gk组成。对于一个输入x,每个模型给出一个输出值gi(x)。输入和第一层各模型的输出组成一个向量〈x, g1(x), g2(x), …, gk(x)〉,作为第二层预测函数的输入。第二层由一个预测函数h组成。h接受第一层的输出并根据它预测x的输出。
本文利用Stacked Learning框架融合两种分词—词性标注方法。融合模型由两个分词—词性标注系统组成。模型的第一层由第3节中实现的分词—词性标注联合模型JointL组成。第二层由第2节中的串行模型加入第一层模型产生的指导分词、词性特征重新训练获得。
在应用Stacked Learning框架训练融合模型时存在一个问题。当使用第一层模型JointL标注训练语料时,会得到与标准答案高度一致的结果。但是,如果用JointL去预测其他数据,却不能达到相同的性能。因此,不能使用由训练数据训练出的模型直接为训练数据提供指导特征。这一问题的一种解决方法是在训练数据上使用N-fold交叉验证。将训练数据S划分成均等的N个不相交子集S1,…,SN。对于每个子集Sl,使用S-S1训练一个JointL,l,然后用它标注Sl,获得这一子集上的指导特征。
4.2 特征
除原串行模型特征,融合模型中使用的指导特征见表5和表6。
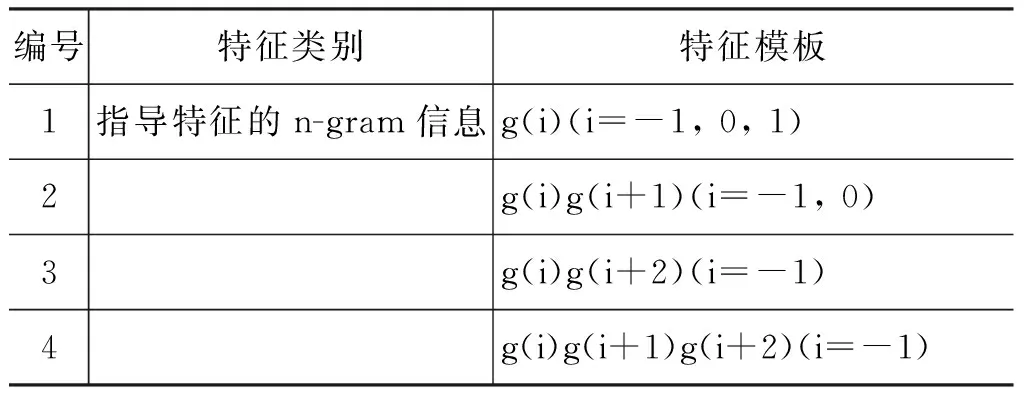
表5 分词的指导特征

表6 词性标注的指导特征
其中,g(c)表示字c的指导特征。第二层模型的分词器主要利用指导特征的n-gram信息。而在词性标注器主要利用指导特征在词边界上的信息。举例来讲, 对于句子片段“涉嫌_VV 运动员_NN 打假球_VV的_DEC 丑闻_NN”。第一层模型的输出编号结果为“涉_B-VV 嫌_I-VV 运_B-NN 动_I-NN员_I-NN 打_B-VV 假_I-VV 球_B-NN 的_B-DEC丑_B-NN 闻_I-NN” 。训练第二层分词模型的过程中,当抽取“球”字的特征时,“g(-1)=I-VV”,“g(0)=B-NN”,“g(1)=B-DEC”等特征被抽取。在训练词性标注模型的过程中,当抽取“打假球”的特征时,“g(last_char(wi))g(first_char(wi+1))=I-NN/B
-VV”,“g(first_char(w0))g(last_char(w0))=B-VV/B-NN”等特征被抽取。
5 实验
5.1 实验设置
本文实验在CTB5.0、CTB7.0、CoNLL09和《人民日报》(PKU)四个数据集上进行。其中CTB7.0与CoNLL09两数据集按照各自官方文档中提供划分方法划分。1998年全年《人民日报》语料按7∶1∶2的比例划分训练集、开发集和测试集。CTB5.0根据Wang等人论文中[10]的方法划分。表7中给出各数据集的统计情况。
表7PKU、CoNLL09、CTB5.0、CTB7.0四个数据集的统计情况

数据集句子数词数数据集句子数词数PKU524661397535CTB5.03488008CoNLL09257773154CTB7.0279659955
对第2节中的串行模型Pipeline(MIRA)的训练, 本文设置迭代次数上限为30, 并且在开发集上获得最优模型。分类联合模型Joint(LIBLINEAR)与MIRA的训练过程类似,也通过在开发集上测试获得最优模型。在评价各系统性能方面,本文参考了之前的研究结果,使用标准F值评价各系统结果的准确率。对于分词任务,准确率(P)等于正确切分的词的个数除以输出结果中词的个数,召回率(R)等于正确切分的词的个数除以人工标注的语料中词的个数。分词任务的准确率为Seg-F=2PR/(P+R)。对于分词—词性标注联合问题,准确率(P′)等于正确切分且正确标注词性的词的个数除以输出结果中词的个数,召回率(R′)等于正确切分且正确标注词性的词的个数除以人工标注的语料中词的个数。联合任务的的准确率为 Overall-F=2P′R′/(P′+R′)。
本文全部实验使用的机器配置为: Intel(R) Xeon X5650 2.67GHz,24G RAM。
5.2 实验结果
表8显示各系统在三种数据集上的性能。从表8中可以看出,在各数据集上,应用融合模型都取得了最好的准确率。融合后的模型使得准确率获得了提升。在速度比较方面,分类联合模型的速度最快,在分词—词性标注联合任务上达到350句/s的速度。而串行模型的解码速度近似为315句/s,融合模型的解码速度近似为160句/s。

表8 在《人民日报》语料上各模型性能
注: Pipeline(MIRA)代表串行模型,Joint(LIBLINEAR)代表分类联合模型。Stacked(LIBLINEAR+MIRA)为融合模型。
5.3 与前人工作比较
本文比较了融合模型与其他方法的准确率。前人工作的结果直接从提出该方法的论文中获得。表9显示了本文的融合模型与其他方法的对比结果。其中,Ours代表本文的融合模型。在这一项对比中,本文的系统在分词、词性标注两项任务上的得分都取得了最好的成绩。可以说,本文融合模型具有很好的性能。
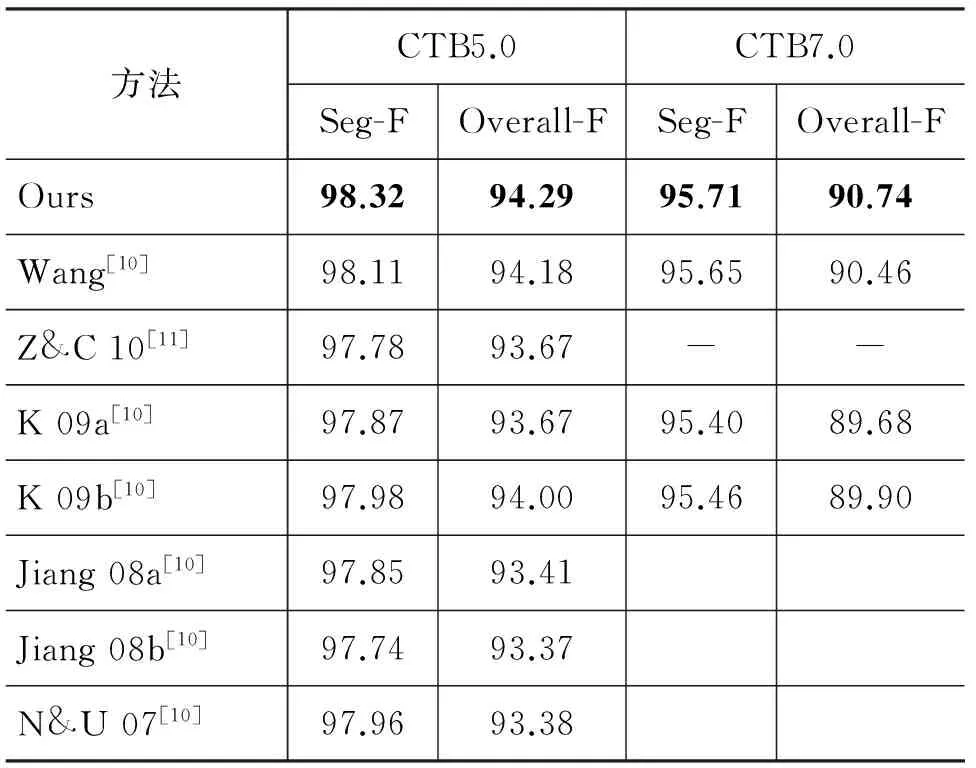
表9 融合模型的准确率/%与前人研究成果在CTB5.0和CTB7.0数据集上的比较
6 结果分析
6.1 速度分析
系统的时间性能是本文关心的一个重点。本文在各系统的运行过程中打印时间戳, 用以衡量系统各部分的运行时间。在MIRA序列标注模型的解码过程中,采用Viterbi算法。为了能够公平对比各系统性能,本文在解码过程中并未使用任何剪枝策略。
一般来讲,系统对句子进行分词词性标注的过程可以归纳为两个主要部分,即特征抽取(FE)部分和预测部分(PD)。影响特征抽取速度的主要因素有特征维度和特征映射算法性能。而解码算法的速度主要与其搜索空间有关。为了能够给出各系统速度的公平分析。本文在实现各个系统的过程中,特征映射的部分都由gnu: : hash_map*http://www.sgi.com/tech/stl/hash_map.html实现。并通过使用相似的特征模板保证各个系统间特征维度相似。
本文使用《人民日报》语料的测试集测试各系统的解码时间。由于这一数据集较大,可以比较稳定地反应各系统的解码时间。各系统在《人民日报》5.2万句测试语料上解码时间如表10所示。通过比较串行模型与联合模型,虽然串行模型的特征抽取时间相对短于分类联合模型,但分类联合模型在这一项比较中仍具有解码速度的优势。通过比较上述系统的运行时间,可以发现,使用分类模型解决分词—词性标注联合问题可以在接近其他系统特征抽取时间的情况下,大幅度减少预测时间。从而获得很快的速度。
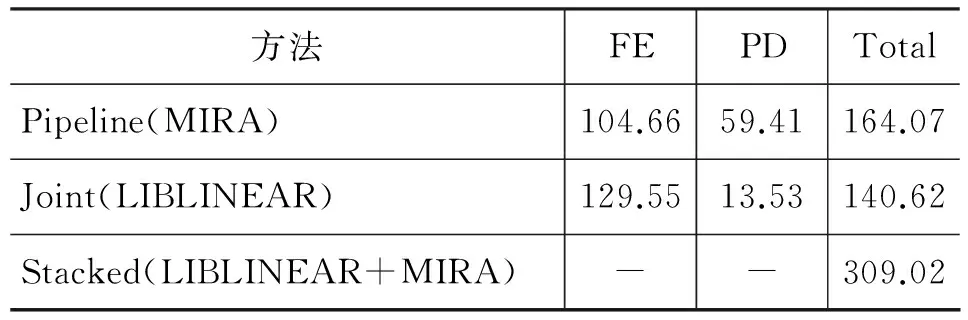
表10 各模型在《人民日报》测试集上的解码时间/s
6.2 结果分析
为分析串行模型与联合模型结果的差异,本文从不同词频词召回率,串行模型与联合模型误差类型两个方面对两种模型的输出结果进行了比较。同时,通过比较串行模型与融合模型的误差类型和误差数,证明融合模型可以利用两种模型的特性提高性能。
本文对两种系统的错误分布进行了比较。图1显示了两种模型的错误分布。图中的点代表某一句子。它的横坐标的值为串行模型中的联合任务准确率,纵坐标值为分类联合模型中的联合任务准确率。图1中的数据点的分布比较均匀地分布在y=x这条直线上两侧,说明两种模型的错误分布不同。这种错误分布的差异可以为两种模型的融合提供更丰富的特征,从而获得更好的性能。
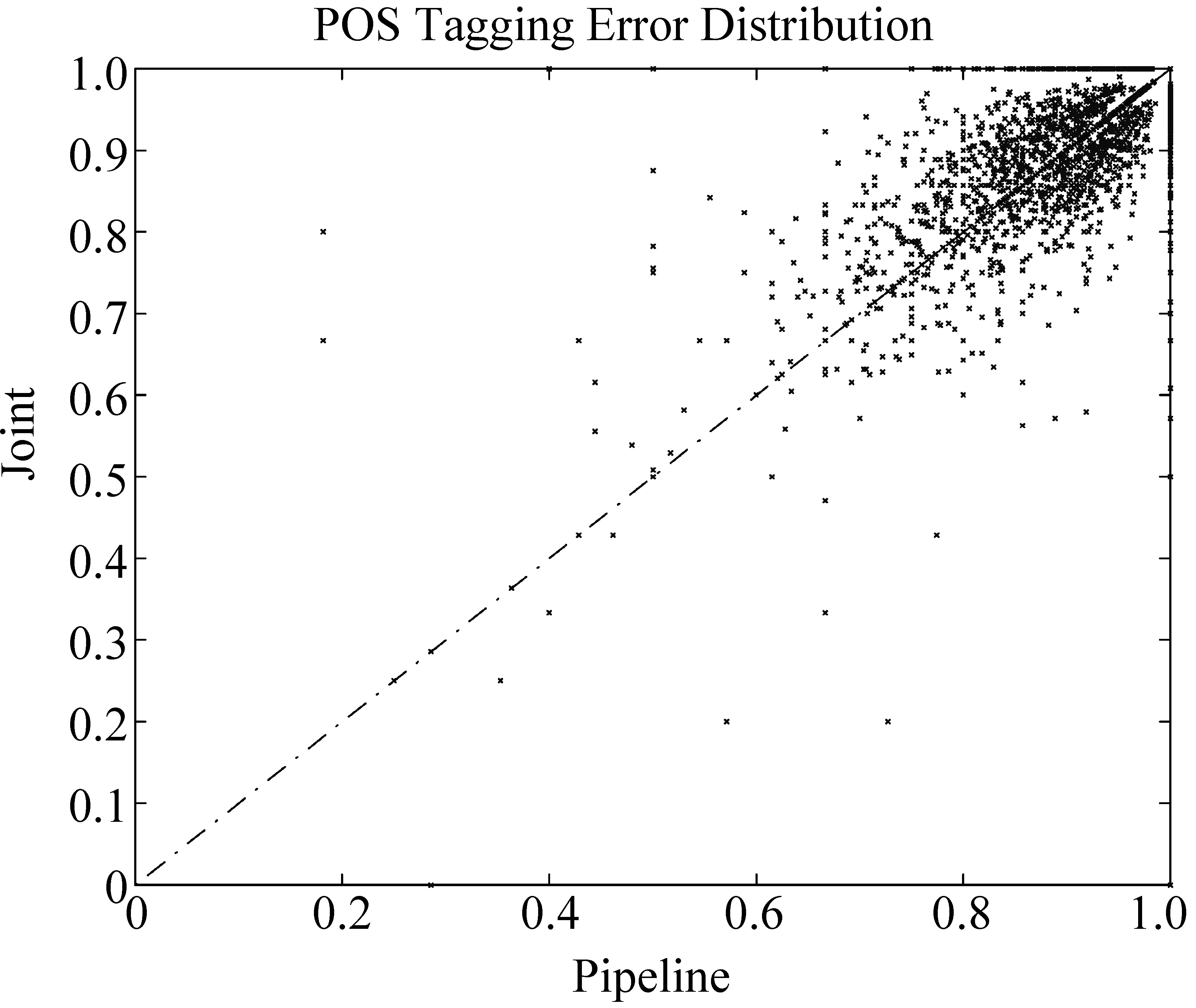
图1 串行模型与联合模型在词性标注上的误差分布
最后, 为了直接说明联合模型与串行模型可以通过模型融合充分利用标注信息提高性能。本文对串行模型与融合模型在CoNLL09上的结果进行了显著性检验,结果显示两模型的p-value<10-5。从统计意义上讲,通过模型融合带来的变化是显著的。
7 结论及下一步工作
本文比较了三种分词—词性标注系统,通过一个简单的线性分类模型对分词—词性标注联合模型进行建模。在性能没有明显降低的情况下,分类联合模型取得了很好的速度。通过对实验分析,本文发现串行模型与联合模型结果的差异。为了利用这种差异,使用Stacked Learning框架将两种模型进行融合。实验对比表明,融合模型取得了非常优秀的分词、词性标注准确率。
未来,我们将尝试对比基于词的中文分词与联合模型。并尝试将基于词的联合模型与其他模型融合。同时尝试使用词性候选集等方法对模型进一步优化,以获得更快的速度。
[1] 张梅山, 邓知龙, 车万翔,等.统计与词典相结合的领域自适应中文分词[J].中文信息学报,2010, 26(2): 8-12.
[2] Nianwen Xue. Chinese word segmentation as character tagging[J]. International Journal of Computational Linguistics and Chinese Language Processing.2003, 8(1): 29-48.
[3] Tseng H, Chang P, Andrew G, et al.A conditional random field word segmenter for sighan bakeoff 2005[C]//Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing. 2005: 171.
[4] Yue Zhang, Stephen Clark. Chinese segmentation with a word-based perceptron algorithm[C]//Proceedings of the 45th ACL.2007: 840-847.
[5] Collins M. Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms[C]//Proceedings of the ACL-02 conference on Empirical methods innatural language processing-Volume 10. 2002: 1-8.
[6] Ng, HweeTou, Jin Kiat Low.Chinese Part-of-Speech Tagging: One-at-a-Time or All-at-Once? Word-Based or Character-Based?[C]//Proceedings of EMNLP 2004. 2004: 277-284.
[7] Yue Zhang, Stephen Clark. Joint Word Segmentation and POS Tagging Using a Single Perceptron[C]//Proceedings of ACL-08: HLT, 2008: 888-896.
[8] Crammer K, Singer Y. Ultraconservative online algorithms for multiclass problems[J]. The Journal of Machine Learning Research, 2003: 951-991.
[9] Cohen W W. Stacked sequential learning[C]//Proceedings of International Joint Conference on Artificial Intelligence. 2005: 671-676.
[10] Wang Y Kazama J, Tsuroka Y, et al. Improving Chinese Word Segmentation and POS Tagging with Semi-supervised Methods Using Large Auto-Analyzed Data[C]//Proceedings of 5th International Joint Conference on Natural Language Processing.Asian Federation of Natural Language Processing, 2011: 309-317.
[11] Yue Zhang, Stephen Clark. A fast decoder for jointword segmentation and POS-tagging using asingle discriminative model[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing.2010: 843-852.
