基于排序学习的微博用户推荐
2013-04-23彭泽环韩先培
彭泽环,孙 乐,韩先培,石 贝
(中国科学院 软件研究所 基础软件中心,北京 100190)
1 引言
社交网络(Social Network)是目前互联网上最热门的应用之一,其核心在于用户与用户之间的关系以及通过这些关系形成的巨大用户社交图谱。这种关系既可以是双向的,如Facebook中的好友关系必须双方认可才能建立;又可以是单向的,如Twitter中的关注(follow)关系。社交网络的质量不仅取决于用户的数量,同时也取决于用户间的关系是否充分和准确,构建充分的用户关系是社交网络需要解决的核心问题之一。目前,建立用户间关系主要手段有传统搜索、从已关注用户的社会关系进行拓展以及熟人推荐等方法。
除上述手段外,用户推荐也是帮助用户建立关系的一种有效的手段。自社交网络应用发明起,为用户推荐其可能感兴趣的用户的研究就成为众多研究人员关注的热点[1-3]。用户推荐对发展用户社交圈、加强用户社交联系,完善社交网络生态系统具有重要的意义。
要进行高效的用户推荐,通常要综合利用微博中多方面的用户信息,例如,用户的人气、用户的活跃度、用户标签、用户评论转发、关注的用户群、被关注用户群等。目前大多数微博系统进行用户推荐时只是简单地统计间接关注用户的个数,这种推荐方法偏向于推荐名人,因此在实际应用中常难以推荐真正感兴趣用户。为了取得更好的用户推荐结果,在本文总结归纳了微博中影响用户推荐的四大类用户信息,包括用户内容信息、个人信息、交互信息和社交拓扑信息,并研究了提取每类信息相关特征的方法,最后采用排序学习的框架融合多特征进行用户推荐。
本文安排如下:
第2节介绍近年来社交网络推荐问题的研究成果及排序学习方法;第3节详细介绍本文总结的四大类影响用户推荐的信息,并就各类信息若干特征的实际意义及计算方法进行详细说明,最后综合利用多个信息特征,提出一个基于排序学习的用户推荐框架;第4节用实验比较本文四类信息对用户推荐效果的影响大小并比较综合不同类别信息的推荐效果差异,实验数据来自腾讯微博真实的用户数据。第5节对本文进行总结,分析并提出下一步的工作重点和研究问题。
2 相关工作
针对微博的社交性特点研究人员提出大量的推荐算法,微博中的推荐对象既可以是信息也可以是用户,本文研究的推荐对象是用户。
Geyer比较在一个企业社交网络中的推荐“about you”相关对象的方法,证明基于社交关系的推荐效果好于基于内容的推荐[4]。Sinha比较两种电影书籍推荐方法,一种是源于朋友的推荐,另一种是协同过滤推荐,实验结果证明用户更偏好朋友熟人的推荐[5]。Guy认为在社交网络中可以为用户构建两个子网络——相似用户网络(similarity)熟悉用户网络(familiarity),通过比较Lotus系统中两个子网络的推荐情况,证明基于熟悉用户网络的推荐效果要好于传统的基于相似用户网络的推荐[6]。Zhou等人提出一种基于标签图的社区检测模型以建模用户兴趣,用户兴趣进一步被表示成离散主题分布模型,兴趣相同的用户相似性也大,用户之间的相似度用主题分布模型的KL-divergence距离计算,最后基于用户间的KL距离进行用户推荐[1]。Chen等人比较社交网络中四种推荐因子(内容、内容+链接关系、朋友的朋友、其他关系网中的关系)的推荐效果,并采用跟踪用户行为和问卷调查的方法对推荐结果评测分析,得出以下结论: 基于内容的推荐倾向于推荐有共同兴趣爱好的陌生人、基于社交网络的推荐倾向于推荐熟悉的人、用户常常比较关注推荐的原因[2]。
总的来说,目前社交网络用户推荐研究采用的信息特征通常比较单一,没有综合利用多种信息特征,因此推荐效果不尽人意。本文抽取微博中四类信息十个特征并综合利用这些信息特征进行用户推荐,其中用户内容信息、用户个人信息在之前的研究中应用的较为广泛;而用户交互信息较少用于用户推荐,用户社交拓扑信息中四个特征也是首次被联合用于用户推荐。
排序学习的本质是用机器学习中的分类方法或回归方法解决排序问题。传统的排序算法通常是构造一个排序函数实现排序,以文档检索为例,对查询q,搜索引擎根据排序函数计算文档与查询(q,d)的相关度得分,然后根据相关得分返回文档列表。传统的排序模型在参数较多情况下常常需要采用经验方法调节参数,难以获得理想的排序结果,排序学习方法通过挖掘特征内在支配排序的信息很好的解决了这一问题。目前排序学习方法包含三大类: pointwise、pairwise、listwise方法[7]。
3 基于排序学习的微博用户推荐
3.1 微博用户推荐关键信息
本文中的用户推荐任务指向用户u推荐其可能感兴趣的用户v。相关定义如下:
u: 接受推荐的用户;
v: 待推荐用户,将v推荐给u,为避免歧义,下文用“对象”表示;
follower:u关注v,u就是v的follower;
followee:u关注v,v就是u的followee;
u的人气: 关注u的用户数。
通常,判断一个用户与另外一个用户的关联需要考虑多方面的因素,本文使用了影响用户推荐的四类关键用户信息: (i)用户内容(UC),主要指用户产生的文本信息;(ii)用户个人信息(PI),这些信息包括标签、用户人气、用户发布微博数等;(iii)交互信息(IA),指用户间转发、评论、提及等交互行为的频次;(iv)社交拓扑信息(ST),包括用户节点的入度信息和出度信息,即微博用户的关注关系和被关注关系。下面对各类信息的作用、直观表征及相关特征抽取方法做详细说明:
(1) 用户内容(UC)
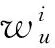
(2) 用户个人信息(PI)
用户个人信息指微博中表示用户个人特征的一组属性,例如用户生日、性别、地理位置、标签、用户人气、发布微博数等等。用户个人信息在传统的信息推荐中是支持用户模型构建的主要信息。本文采用标签、用户人气、发布微博数三个主要属性并且用两个特征来表示用户个人信息。
标签特征T
标签是用户在完善个人资料时指定的一组描述用户兴趣爱好的关键字,是表征用户兴趣爱好的一种有效手段。本文将标签作为建立用户兴趣关联的一个媒介,用户相同标签越多,用户与标签关联度越大,则用户越相似,推荐得分也越高。本文中,用户u与对象v的标签特征T计算方法采用式(2)。
其中C表示用户u、v共同的标签集合,t∈C,w(u,t)表示标签t与用户u的关联度,直观上t出现在u的关注用户中的频率越高,用户u与t关联越大。计算时w(u,t)初值为1,标签t每出现在一个u的关注用户中w(u,t)值增加0.1,最后对T值归一化处理。
信息贡献度特征P
信息贡献度指用户对整个社交网生态系统中信息产生、传播的贡献程度,信息贡献度大的用户常常具有较多关注者且发布微博的数量较多。直观上用户的人气越高、发布微博频率越高,用户信息贡献度越大,引起其他用户关注的可能性也越大。本文采用信息贡献度特征指标融合用户人气、发布微博数两个属性,计算方法采用式(3)。
其中number表示用户发布、转发微博数量,popularity表示用户的人气,最后对P进行归一化处理。
(3) 交互信息(IA)
用户交互是指微博用户间的信息交互行为,包括留言、回复、转发、评论、提及等动作。交互信息直观地反映用户间社交关联的强弱,交互越频繁则用户关联度越高。用户u如果转发或评论过用户v的微博,那么u可能对v有一定的兴趣,且评论转发的次数越多兴趣越大,u关注v的可能性也越大;用户u如果提及v时通常也意味着u对v具有较大的兴趣。本文采用转发次数(Re)、评论次数(Co)、提及次数(At)三个特征表示交互信息。
(4) 社交拓扑信息(ST)
社交拓扑信息指社交拓扑图中用户节点间相互连接所蕴含的信息,包括用户节点的出度信息(关注关系)和入度信息(被关注关系),社交拓扑信息是目前社交网络中拓展用户的关系主要依据,也是目前用户推荐研究中应用的主要信息之一。每个用户都有入度信息和出度信息,因此对两个微博用户(向用户u推荐对象v)而言,可以通过图1中四种连接方式构成四个社交拓扑信息特征,其中特征(1)广泛用于社交网络各类推荐研究中[2,5-6]。本文综合使用这四个特征表示社交拓扑信息以用于用户推荐,具体描述如下。

图1 两用户建立联系的四种方法
图1中椭圆表示推荐直接相关用户u和v,圆表示中间用户m,m∈M,箭头表示单向关注关系,通过中间用户M建立起u与v的社交联系。四种特征直观含义及中间用户的意义分别是:
特征(1)通过二度关注关系建立u、v间的关联,直观上如果u关注的用户中很多人关注了用户v,则u关注v的可能性较大。中间用户集合为M1,对任意的m∈M1,m既是u的followee又是v的follower;
特征(2)通过共同的followee建立u、v间的关联,直观上如果用户u、v共同关注的用户越多,二者共性越大,则u关注v的可能性越大。中间用户集合为M2,对任意的m∈M2,m既是u的followee又是v的followee;
特征(3)通过共同的follower建立u、v间的关联,直观上同时关注u、v的用户越多,表示用户u、v间的相似性越大,u关注v的可能性越大。中间用户集合为M3,对任意的m∈M3,m既是u的follower又是v的follower;
特征(4)通过二度被关注关系建立u、v间的关联,与特征(1)的建立关联的方向相反,如果v关注的用户中关注用户u的人越多,表明u、v间共性越大,则u关注v的可能性也较大。中间用户集合为M4,对任意的m∈M4,m既是u的follower又是v的followee。四种特征在结构上相似,因此在计算各个特征值时,均可采取式(4)。
其中i∈{1,2,3,4}为四种方法,Mi为方式(i)
中间用户的集合,w(u,m)和w(m,v)是用户相似度大小,可以直接用两个用户内容或者标签相似度计算,w(m)是用户的重要性指标,可以直接用用户人气表示。
3.2 排序学习推荐框架
目前的用户推荐研究采用的信息都比较单一[1-3],推荐效果欠佳,为此需要能够有效地融合多方面信息的推荐框架。在前3.1节中,本文提出了四大类信息特征,如何高效的综合使用这些信息是达到高性能推荐的关键。而其核心问题是如何处理高维特征问题时的参数估计问题。排序学习方法把用户间推荐得分的计算转化为对一个多特征向量的二分类问题,很好地解决高维特征带来的多参数估计问题,因此本文采用学习排序方法来综合利用多个特征,为每个用户推荐一个对象列表。用户推荐框架如图2所示,图中椭圆表示微博用户,箭头→表示用户的关注关系。训练数据为用户接受/拒绝推荐的历史数据。然后采用排序学习的方法根据训练数据得到推荐模型。测试数据使用的用户数据类型和训练数据相同,对每个用户u,根据推荐模型计算待推荐用户的推荐得分并按照得分降序排列生成最后的推荐列表。
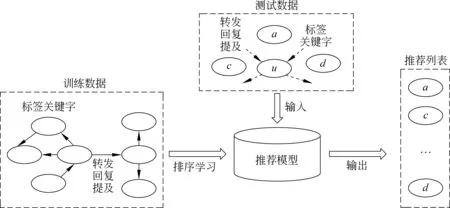
图2 排序学习用户推荐框架示意图
训练数据中的每个用户u都有一组推荐用户,如果u接受推荐的用户i,标记二元组(u,i)的标签为+1,否则为-1,然后选择本文提出的四大类信息中的特征组成特征向量x表示二元组(u,i),这样就生成一个训练实例。训练过程如图3所示。

图3 排序学习用户推荐的训练过程
推荐排序过程和训练过程相似,用户s与每个待推荐的对象i组成二元组,并用特征表示成特征向量x然后用推荐模型计算特征向量被分类为+1标签的概率。
4 实验分析
实验中,本文采用SVM分类器来构建一个微博用户推荐系统。本文进行了多组实验,比较不同类信息对推荐效果的影响并且比较不同信息组合的推荐效果。为了评估实验效果我们用信息检索中平均准确率MAP@n指标来计算推荐列表前n个对象被用户接受的比例。
4.1 数据集
实验数据集来自腾讯微博用户数据,分别采自两个不同的时间点t1和t2。t1时采集每个用户及对象的四大类微博信息,腾讯微博推荐引擎会将一组对象推荐给一个用户,用户对推荐的对象采取接受或者拒绝操作;t2时采集用户对推荐对象的接受(标记+1)、拒绝(标记-1)等记录,每个<用户、对象>为一条记录。将t2时采集的数据分成两部分,一部分用于训练推荐模型,另一部分为测试数据,数据统计情况如下:
• 用户规模18 717个,对象规模6 095个,每个用户或对象的信息包含关键字、标签、发布微博数、对对象的评论/转发/提及次数、关注用户、被关注用户等,其中用户为任意选取的普通用户,对象为一些名人用户、著名机构或组织用户。
•t2时采集的记录数总共2 067 936条,其中接受记录894 830条,拒绝记录1 173 106条。每个用户的记录数为30~1 313不等,其中接受推荐的对象至少为10个,拒绝推荐的对象至少为20个。
• 实验选取13 717个用户的接受、拒绝记录作为训练数据,总共1 536 209条,其余5 000用户的531 727条记录为测试数据。
4.2 结果与分析
在测试数据集上,本文用排序学习框架融合各类信息特征,并进行了四组单信息实验以验证各类信息对推荐的效果差异,其中基于用户内容的推荐系统为基准系统。采用MAP@3、MAP@5、MAP@7、MAP@10等指标评估推荐效果,即分别计算推荐列表的前3、5、7、10个对象中用户接受的平均比例,四组实验结果如表1所示。

表1 使用单类信息用户推荐效果
其中UC为基于微博用户内容向量相似度推荐方法,作为其他三类信息推荐结果的baseline,PI为基于用户个人信息的两个特征的推荐结果,IA为基于用户交互信息三个特征的推荐结果,ST为基于用户社交关系四个特征的推荐结果。由上表可得出如下结论:
• 单类信息推荐效果IA>ST>PI>UC。表明(1)本文总结的PI、IA、ST三大类信息对提升用户推荐均有效,(2)基于排序学习的微博用户推荐可以自由融合一类信息中的多个特征获得较好的推荐性能。
• 基于用户内容的UC组实验推荐效果远不如其他组实验,我们认为可能的原因有两个: (1)普通文本信息中包含大量的歧义、多义、同义、噪音等NLP常见问题;(2)社交网络中用户产生的文本信息中常常包含大量的口语、省略语、符号,这些文本的语义信息很难挖掘,在文本的预处理阶段这类有用的文本信息就被过滤了,这也是近年来微博中基于内容的推荐没用基于社交信息的推荐使用广泛的原因。
• 用户交互信息IA对推荐性能影响最大,我们认为可能的原因是交互信息是一种目的性强的信息,因为用户只与真正感兴趣的用户有评论、转发、提及等动作;此外交互信息中通常蕴含着社交拓扑关系信息,因为用户评论、转发的信息通常是关注用户的关注用户(followee of followee)发布的。
• 用户社交拓扑信息ST在推荐过程中对最终结果影响也较大,印证了这一信息在社交网络中的重要性,也进一步验证了文献[4]中的基于社交拓扑信息推荐明显好于基于内容推荐的结论。
• 基于个人信息PI的推荐充分利用标签建立起用户间的语义关联,但其推荐效果比其他两组实验都差,我们认为可能的原因有: (1)用户标签统计数据显示标签共现矩阵较稀疏,即拥有共同标签的用户占总用户的数量比较小,且具有相同标签的用户间共有的标签数也较小;(2)基于个人信息的推荐只考虑单个用户的信息,而忽略了社交网络的本质——关系,所以其推荐性能均不如IA和ST。
为了综合考虑多个信息联合推荐的性能,本文还进行了四组不同类别信息组合的实验,实验结果如表2所示。

表2 不同类别信息组合推荐效果
表2中IA+ST表示融合交互信息与社交拓扑信息进行推荐,PI+IA表示融合用户个人信息与交互信息进行推荐,PI+ST表示融合个人信息和社交拓扑信息进行推荐,IA+ST+PI表示融合个人信息、社交拓扑信息和交互信息三类信息进行推荐。由表2实验数据可知PI+IA组实验结果四个指标和IA+ST组实验MAP@7、MAP@10两个指标的推荐性能均好于单类信息推荐性能,PI+IA的推荐性能最好,实验结论分析如下:
• PI描述了社交拓扑图中的“点”信息,IA描述了社交拓扑图中的“边”信息,并且是权重较大的重要的“边”,所以二者联合推荐时其推荐性能最优。
• ST描述了社交拓扑图中的所有的“边”信息,这些“边”的权重通常都比IA中的“边”的权重小,所以PI+ST的推荐性能不如PI+IA。
• IA+ST中IA和ST描述的都是社交网络中的“边”信息,忽略了“点”信息,所以其推荐性能也不如PI+IA。
• IA+ST+PI的性能不如PI+IA,我们分析其原因是ST和IA在共同描述“边”信息时并不是相互加强的,IA+ST组实验结果也验证了这点。
综上所述,采用排序学习推荐框架可以方便的融合多个信息进行用户推荐,并且是可行的;但推荐时特征的选取非常重要,并非特征越多推荐性能越优。
5 结论及下一步工作
本文针对微博用户信息特点,总结了影响微博用户推荐的四大类信息,并提出各类信息若干特征的计算方法,结合微博用户数据进行相关实验分析。结果表明,本文提出的基于排序学习的微博用户推荐框架可以综合微博用户各类信息为用户提供高性能的个性化用户推荐。下一步工作中,我们将探索其他特征对微博用户推荐的影响,例如采用用户的重要度、影响力特征表示个人信息,对用户的关注用户进行分组以表征社交拓扑信息等;此外,如何进行特征选择构建高效的多信息融合框架也是下一步的研究方向。
[1] Zhou T, Ma H, Lyu, M., King, I. UserRec: A User Recommendation Framework in Social Tagging Systems[C]//Proceedings of the 24th AAAI Conference on Artificial Intelligence, 2010: 1486-1491.
[2] Jilin Chen, Werner Geyer, Casey Dugan. Make new friends, but keep the old: recommending people on social networking sites[C]//Proceedings of CHI’11: Proceedings of the 27th international conference on human factors in computing systems ACM New York, 2009.
[3] Hiroyuki Koga, Tadahiro Taniguchi. Developing a User Recommendation Engine on Twitter Using Estimated Latent Topics[C]//Proceedings of HCI (1) 2011: 461-470.
[4] Geyer W, Dugan C, Millen D, et al. Recommending topics for self-descriptions in online user profiles[C]//Proceedings of RecSys’08, 2008: 59-66.
[5] Sinha R, Swearingen K. Comparing recommendations made by online systems and friends[C]//Proceedings of DELOS-NSF Workshop on Personalization and Recommender Systems in Digital Libraries. 2001.
[6] Guy I, Zwerdling N, Carmel D, et al. Personalized recommendation of social software items based on social relations[C]//Proceedings of RecSys, 2009: 53-60.
[7] TY Liu. Learning to Rank for Information Retrieval[J]. Foundations and Trends in Information Retrieval, 2009.
[8] K Dindia and D Canary. Definitions and Theoretical Perspectives on Maintaining Relationships. Journal of Social and Personal Relationships[J], 1993, 10(2):163-173.
[9] Malone T, Grant K, Turbak F, et al. Intelligent information sharing systems[J]. Communications of the ACM , 1987, 30(5): 390-402.
[10] J Hu, B Wang, Y Liu. Personalized Tag Recommendation Using Social Contacts[C]//Proceedings of SRS Workshops, 2011.
[11] Ralf Herbrich,Thore Graepel, and Klaus Obermayer. Large Margin rank boundaries for ordinal regression[J]. MIT Press, Cambridge, MA, 2000.
