小型《楚辞》汉英平行语料库的创建与应用
2012-11-06刘孔喜
刘孔喜
(湖北民族学院外国语学院,湖北恩施445000)
小型《楚辞》汉英平行语料库的创建与应用
刘孔喜
(湖北民族学院外国语学院,湖北恩施445000)
现阶段《楚辞》英译研究主要体现在具体的词汇考辨及其翻译研究、基于文化视角的定性研究等方面。要进一步扩展研究广度与深度,可借助语料库技术的辅助作用。《楚辞》汉英平行语料库的创建,或能方便翻译学者充分利用语料库的诸多优势,全面、系统地对其进行研究。本文尝试性地进行小型《楚辞》汉英平行语料库创建,探讨语料划分、标注、对齐、检索设置等操作的可行性方案,以期为全面、系统进行《楚辞》英译研究提供一条有效途径,通过数据分析和定性阐释相结合,获得客观可信的研究结果。
《楚辞》;平行语料库;创建;应用
一、引言
《楚辞》作为中国诗歌文学的源头之一,对汉语和中国文学的影响深远,研究者众多,也已有许多著名英译版本出现,译界也逐渐加大对《楚辞》英译的研究。现阶段《楚辞》英译研究主要体现在具体的词汇考辨及其翻译研究、基于文化视角的定性研究等方面。要进一步扩展研究广度与深度,可借助语料库技术的辅助作用。将语料库运用于翻译研究的视角或能为《楚辞》英译研究打开新的思路。语料库与翻译研究相结合的首倡者Mona Baker从翻译研究角度对语料库建设和语料库语言学研究提出了特殊要求和设想。她认为与翻译研究有关的语料库有三类:平行语料库,多语语料库和可比语料库[1]。其中,平行语料库(parallel corpus)收集某种语言的原创文本和相应的翻译成另一种文字的文本。由于既涉及原文又涉及译文并且能够体现某种对应关系,双语平行语料库有可能比较便利地研究译文的语言特性和译者的文体等诸多因素,因此对翻译研究最有用。Tognini Bonelli曾经指出,平行语料库的最大用处是将翻译好的成品展现给人们,从这些成品中人们可以了解不同语言之间的相似之处和不同之处,而这是单语语料库所无法提供的[2]。自廖七一[3]等学者开始引介语料库与翻译研究以来,王克非[4]等学者大力推广,国内学者逐渐重视语料库在翻译研究上的应用,特别是将语料库应用在典籍英译研究上,如刘泽权[5]等,给了本研究很多启示,此类成果颇丰,不一一列出。
在学习他人研究思路的基础上,本研究首先是选取部分有代表性的汉英文本,尝试性地进行小型《楚辞》汉英平行语料库创建,探讨语料划分、标注、对齐、检索设置等操作的可行性方案,以期为全面、系统进行《楚辞》英译研究提供一条有效途径,通过数据分析和定性阐释相结合,获得客观可信的研究结果。
二、《楚辞》平行语料库的创建
著名语料库语言学家辛克莱(Sinclair)指出:“任何语料库研究都是从建立语料库本身开始的。语料库要包括什么内容以及如何组织选取语料将影响以后的所有步骤”[6]。平行语料库的建成是要使语言学家能对比两种文本在词汇、句子和文体上的差异,例如,两个文本长度上的区别,两个文本词汇的对应程度,均能反映语言翻译行为中的特征,归纳出其中的等值关系,研究翻译腔产生的原因和特点。为便于研究,建立的《楚辞》汉英平行语料库的双语语料库应可分可合,既可作为一个中文语料库对应任何一个英文译本的双语平行语料库,又可作为各译本的单语语料库,分别用于汉英对照和英英对照研究。在实现各文本句子层面的对齐并标注后,待技术成熟,该语料库将会使研究者实现语句的自动链接式平行对应检索,以及对应用语料库进行各项研究与统计分析,具体包括形符与类符统计,词频排列,词长、句长、句数、句型、文体等语言特色的对比分析。
小型《楚辞》汉英平行语料库的创建具体拟分以下几个步骤进行:
(一)语料库的设计
设计该语料库,也就是先要确定研究目的,明确利用《楚辞》汉英平行语料库来研究什么问题,对该库的建设非常重要。因为研究目的决定着语料的选取、对齐方式以及语料标注等。具体到本研究所选语料,作为较有代表性的典籍文本,《楚辞》原文具有多义性,包举一切古代文化气概,风格严肃,代表着民族文化品格[7]。那么,《楚辞》的英译在文体风格以及富含文化意蕴的典故、人称、各类植物名的比喻性用法等方面的翻译是否到位,能否经得起考证,各译本之间的差异表现形式怎样,此类问题就成为《楚辞》英译研究的重点。基于此,在语料对齐方面,鉴于《楚辞》原文本的特点,我们主要采取句级对齐;在语料赋码标注方面,我们重点针对包含典故的文化词汇、人称、各类植物名等英汉对照进行标注。当然,“从用户角度讲,语料标注得越详尽越好,而标注者则还需要考虑标注的可行性”[8]。基于这两者的结合,我们目前求得一种“妥协”,先考虑这些方面的标注。除词汇外,《楚辞》句型上的文化因素也是可研究对象,如“兮”字句型,这留待以后的研究中进一步拓展完善。
(二)文本收集及电子化
语料收集最重要的一点就是力求语料的代表性与经典性。最好是收集原语文本和译语文本的全文。如果无法收录全文,可以采用随机抽样的方法选择,也可以采用人工调查抽样的方法选择。根据《楚辞》英译版本所选篇章规模不一以及其汉语版本本身也存在收录不同的特点,本语料库选取那些知名译者都翻译过的《楚辞》篇章的中英文文本进行收录。或者说,主要选择原始语料《楚辞》中已无争议或争议较少的屈原作品作为主要研究对象。在本研究的初创阶段,暂选取包括杨宪益(夫妇)[9]、卓振英[10]、霍克思(David Hawkes)[11]等学者的《楚辞》英译本,其中主要有《离骚》等。所涉篇章,均采取全文收录。
在确定好所选文本后,收集上述《楚辞》英译文本,便开始进行中英文语料的输入。部分语料可以通过现有的电子文本获得,如直接从网络上下载原文及译本。不可直接获得电子文本的则通过手动输入或扫描的方式,将纸质文档转化成电子文档。为保证语料库的语料质量以及研究的可靠性,这些过程需要人工逐一检查订正。比如,笔者通过网络检索搜集到杨宪益(夫妇)版的《楚辞》英译本的电子文本,同时对照该译者在外文出版社于2001年出版的《楚辞》英译纸质版逐字逐句核对,确保文本的准确性。在搜集齐所需文本后,将所有语料以纯文本文件(.txt)保存。
(三)双语语料的预编辑
语料的预编辑也是不可缺少的一步。从网上下载的语料文本可能有错误,也可能有一些诸如文本来源或版权信息等冗余信息,在预编辑时需要将它们从正文中除去。也可能会有空行,可以使用MS Word的查找替换功能,将“^p^p”替换为“^p”(^p为换行符或段落标记)即可删除这些空行。此外,更重要的是,由于大部分语料库软件都只能分析处理纯文本文件,而在纯文本文件中无法保存斜体、加粗、加下划线、加着重号等格式,也无法保存表格、图形等正文内容,也无法在每页的底部显示脚注等注释信息。因此,在对语料进行预编辑的时候,要对这些无法保存到纯文本文件中同时又包含重要信息的内容进行补偿或增加注释。
在对齐之前,将汉英两种语言的文本分成句子,每个句子的界定为:以句号、问号、感叹号、分号(含这些符号加引号)结尾的一串字符。这一过程可以采用任何一种具有“查找”和“替换”功能的文字处理软件来完成。本研究初创阶段采用手动方式完成这一过程,以确保汉英两种语言的文本在句子水平上对齐。此外,这一过程还包括各文本格式的统一。
(四)语料对齐
对于平行语料库而言,首先要对语料进行对齐工作,这也是各种应用对平行语料库的一个最基本的需求。对齐是指在原文和译文之间建立对应关系。有多种对齐方式,比如篇章对齐、段对齐、句对齐和词对齐。篇章对齐和段对齐都只是粗略的对齐,可研究的翻译现象不是很多。虽然词对齐最有用,尤其是对于翻译批评,但由于中英文句序的巨大差异,很难实现词对齐。因此,句对齐是一种比较理想的选择。尤其是鉴于《楚辞》原文本的特点,创建本语料库主要采取句级对齐。
在初创阶段,我们实现原文与常见且知名的三个译本(霍译、杨译、卓译)的文本在句子层面的对齐(其他译者的文本将在后续研究中继续进行处理)。如不考虑到对齐软件的话,在上述语料的预编辑阶段我们就可以对少量文本进行人工对齐。以《楚辞》中的《离骚》篇及英译为例,研究者手动方式将《离骚》汉语原文与英语译文文本逐句对齐,并在句前标上相应数字序号,使文本对照清晰可见,图例如下:
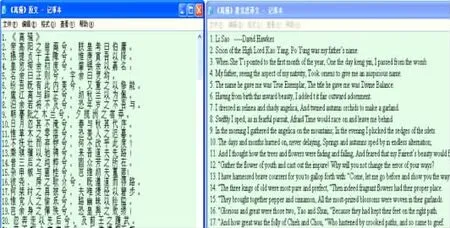
图1 《离骚》汉英纯文本文件对齐
当然,当需要对大规模的语料进行处理时,有些专门的语料库软件可以对汉英双语文本进行自动对齐,如本研究会应用到的ParaConc软件,以及国内的雪人翻译软件等都可以做到这一点;但为确保研究的准确性起见,经过这些软件对齐的文本也都需要进行人工校对。
(五)语料标注
标注(annotation)也称赋码,就是给语料添加注释或类码这样的信息。语料标注的类型主要包括语篇背景信息、词性、词形、句法分析、语义、语篇结构等。对于本研究所涉语料《楚辞》汉英双语文本,从利于研究角度考虑,可重点标注两类:一类叫词类赋码(tagging),就是对文本中每一个词形(包括标点符号)赋予相应的词类码,即语法码。另一类叫句法标注(parsing),就是对文本中的每一个句子进行句法分析并标注出来。除了这两类赋码之外,还可以添加文本来源、归化、异化、直译、意译、转换、理解及表达等信息,这也可以认为是标注,比如:发现理解错误的地方可以标注<EU>(Errors of Understanding的缩写)、表达错误的地方标注<EE>(Errors of Expression的缩写),还有一些漏译的地方,可以“<S>This paragraph was not translated< /S>”(即“该句未翻译”)。
本研究计划对以上三种文本进行语言、文学和文化方面的标注,标注后的语料库可以进行霍译本、杨译本、卓译本有关语言、文学和古代文化等方面的翻译检索,并进行对比研究。
如前所述,目前我们暂重点针对包含典故的文化词汇、人称、各类植物名等英汉对照进行标注。此外可以标注的还有汉语原文句子有无修辞或习语、谚语,句子的语域(即书面语或口语)也可以作为一个属性进行标注。将标注后的原文及每个译文分别保存为纯文本文件,就建成了标注过的平行语料库。
(六)语料检索
ParaConc是一款由著名语料库专家 Michael Barlow设计的功能强大的平行语料库检索软件,支持汉语及多种形式的双语对照检索。本研究暂时使用的是免费获取的测试版,更多功能的使用需要向开发者购买该软件许可权。该软件最多支持原文与3个不同版本的译文的对照显示,是翻译研究的有利工具。比较完3个不同译文之后,换掉其中1个或2个译文再进行观察研究,就可以研究3个以上不同译文。ParaConc的好处在于既可以进行统计,又可以非常方便地观察分析不同译文。
以《离骚》篇首中“皇”一字英译对比分析为例。运行ParaConc,打开“Load Corpus File(s)”将“Parallel Texts”设为4,将其中1个语料库的语言选为“Chinese”,并“Add”载入汉语原文的语料库文件,将其他3个语料库的语言选为并依次载入3个不同的英语译文语料库文件,即按次序分别为霍克思译文、杨宪益(夫妇)译文和卓振英译文。在“Search”中搜索查找“皇/皇考”,共有10条相匹配的句对,显示的结果如图2所示:

图2 用ParaConc研究分析《离骚》中“皇(皇考)”的翻译情况
(七)网络检索平台的设置
鉴于目前语料规模不够以及配套技术还不成熟,网络检索平台的设置工作留待今后继续完成。
三、《楚辞》平行语料库的应用
在实现对《楚辞》英汉双语语料进行平行对齐并分别予以赋码标注后,就可以利用ParaConc软件来对各译文进行统计和观察分析。据上图2所示,在检索“皇”的翻译情况时,结果显示一共搜索到10个匹配句,只要选中其中一个汉语句子,3个译文中与之对应的句子都会被选中,显示为不同颜色背景。从这些译文可以看出,霍克思、杨宪益(夫妇)和卓振英三位译者对“皇”或“皇考”的处理各不相同。以图2中显示的前三句译文对照为例分析,汉语原文前两句中的“皇”或“皇考”均指“(已故)父亲”,而杨译为“my royal sire”、“my lord”,未能准确理解。而在霍译中,他直接采用“my father”,此外采取音译法直接译出“帝高阳”,不过用的是威妥玛拼音“Kao Yang”。至于卓译文中,体现出了该译者对原文的考辨,给出了原文字面外的信息;除将“皇考”译为“my sire”外,他在英译中指出了“帝高阳”的原名“Zhuanxu”(颛顼),此外采用当今的汉语拼音译出“伯庸”之名。这些体现了三位译者各自的文化身份和所处年代的不同。
此外,在《离骚》中,屈原以自然景物喻人,象征的涵义既深远又完整,花草树木其形象是借以抒写所代表的人物。尤其是用到香草类植物名词时,一般指贤才类的人物,例如”芳、蕙、荃……”。下面以“荃”的英译检索为例:

图3 用ParaConc研究分析《离骚》中植物名词“荃”的翻译情况
在序列号21的原文句中“荃”名为石菖蒲一类香草,实际比喻贤君,但霍克思和卓振英两译本对此采取了直译,即分别为“the Fragrant One”与“The Calamus”,并予以首字母大写。而杨宪益(夫妇)译文则意译为“the prince”,理解正确,同图2示例情况相同。
仅结合上述两例,我们可以发现三译本似乎均呈现直译、意译策略交叉使用,并非单一。图2、3所示杨译直译文究竟是否也像某些学者所言“杨译文为误译”(杨成虎,2004),这里亦不可盲目下定论。从现有语料对比分析来看,单举杨译说明,杨宪益的翻译策略多偏异化,带有杂合,其理解表达能力并非不如其他译者,没搞懂原文的内涵意义,直译也许是有意为之。要彻底了解三位译者的策略及其译文成因,文化因素对其影响如何,这些还需通过语料库做大量实例分析统计。
四、结语
本研究尝试创建小型《楚辞》汉英平行语料库,在研究中将充分利用平行语料库检索功能的优势,为双语对比及翻译研究提供基础。《楚辞》双语平行语料库的建设还只是起步阶段,建设过程存在一定的技术难度。目前研究是建立《楚辞》中文原文与霍译、杨译、卓译的句级对应语料库,以便于进行汉英对照、英英对照研究和互联网自动链接检索。在参照国家社科基金项目阶段成果“《红楼梦》中英文平行语料库的创建”的基础上,借鉴部分思路尝试将《楚辞》汉英双语文本进行语料处理、对齐、标注和设置检索等,最终建成具有一定规模的《楚辞》双语平行语料库。通过大量、真实,且具有比较性的语料(即同一原文的不同译本)进行的翻译研究,利于研究者取得客观的、可供检测的结论,将《楚辞》英译研究拓宽、加深。
[1]Baker M.Corpora in translation studies:An overview and some suggestions for future research[J].Target,1995,7(2):230-236.
[2]Tognini Bonelli E.Corpus Linguistics at Work[M].John Benjamins Publishing Company.2001.
[3]廖七一.语料库与翻译研究[J].外语教学与研究,2000(5):380.
[4]王克非.双语对应语料库研制与应用[M].北京:外语教学与研究出版社,2004:36-53.
[5]刘泽权.《红楼梦》中英文语料库的创建及应用研究[M].北京:光明日报出版社,2010:32-54.
[6]Sinclair J.Corpus,Concordance,Col location[M].Oxford:Oxford University Press/Shanghai:Shanghai Foreign Language Education Press,1991/1999:13.
[7]杨成虎.典籍的翻译与研究——《楚辞》几种英译本得失谈[J].宁波大学学报(人文科学版),2004(4):55-61.
[8]丁善信.语料库语言学的发展及研究现状[J].当代语言学,1998(3):4-12.
[9]杨宪益,戴乃迭.楚辞选:(汉英对照)[M].北京:外文出版社,2001.
[10]卓振英.大中华文库:楚辞(汉英对照)[M].长沙:湖南人民出版社,2006.
[11]Hawkes,D.,Ch’u Tz’u:The Songs of the South:an Ancient Chinese Anthology[M].Boston:Beacon Press,1959.
H1
A
1004-941(2012)01-0122-04
2012-01-10
2010年度湖北省社会科学基金项目“十一五”规划资助课题“《楚辞》英译研究——基于语料库的多维度研究(项目编号【2010】395”)研究成果。
刘孔喜(1981-),男,湖北黄冈人,主要研究方向为翻译理论与实践。
责任编辑:王飞霞
