基于卷积神经网络的多字体字符识别*
2011-12-17吕刚
吕 刚
(金华广播电视大学理工学院,浙江金华 321000)
0 引言
卷积神经网络(Convolutional Neural Networks,CNNs)是近年发展起来的一种高效识别方法,已经成为众多科学领域的研究热点之一,特别是在模式分类领域.由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了广泛的应用.CNNs在字符识别领域的应用一直非常成功.例如,在Mnist字库的识别上,CNNs一直保持着最佳的识别率.
文献[1]用一个4层的卷积神经网络 LeNet-5对Mnist进行识别实验,获得了98.4%的识别率,2层BP网络的识别率是87%;文献[2]通过对训练集字符作弹性形变处理,卷积神经网络在Mnist上的识别率达到99.6%,2层BP网络的识别率是99.1%,支持向量机(SVM)的识别率是99.4%;文献[3]运用大规模卷积神经网络和基于能量模型的稀疏表示在Mnist上达到99.61%的识别率;文献[4]通过结合大规模神经网络和2个阶段的特征提取获得了99.47%的识别率.值得一提的是,文献[4]并没有对训练集作弹性形变等预处理.
然而,基本BP算法的收敛速度较慢,往往需要几百次迭代才能收敛到满意的结果.本文首先介绍了一个典型的卷积神经网络——Simard网络;其次在Simard网络的基础上,采用随机对角Levenberg-Marquardt算法,有效地提高了Simard网络的收敛速度;以改进后的Simard网络为基础进行实验,分析了网络结构对网络性能的影响;最后成功地把改进的Simard网络应用到多字体字符的识别上,在极大提高识别速度的基础上取得了较好的识别率.
1 卷积神经网络
卷积神经网络可以看成是一个结构化的BP网络,融合3种结构性的方法实现位移、缩放和扭曲不变性.这3种方法分别是局域感受野、共享权值和空间域或时间域上的次采样.局域感受野是指每一网络层的神经元只与上一层的一个小邻域内的神经单元连接,通过局域感受野,神经元可以提取初级的视觉特征,如方向线段、端点、角点等;权值共享是指同一个特征图中的神经元共用相同的权值,使得卷积神经网络具有更少的参数,局域感受野和权值共享使得卷积神经网络具有平移不变性,每个特征图提取一个特征,对特征出现的位置不敏感;次采样可以减少了特征图的分辨率,从而减少对位移、缩放和扭曲的敏感度.
1.1 Simard 网络
文献[1]给出了一个结构比较简单、规模较小的卷积神经网络LeNet-5;文献[5]改进了LeNet-5的结构;文献[2]则提出了简化的LeNet-5的结构,以下简称Simard网络.
根据Simard的实验,边缘扩充对性能的提高不明显(实际上Mnist字库本身留有4个像素的边缘),因此,输入结果变成了29×29的图像.卷积层和次采样层作了合并,C5被取消了.这些改进大大减少了网络规模,提高了单次迭代的速度.
1.2 对Simard网络的改进
Simard采用基本的BP规则作网络训练,网络的收敛速度较慢,往往需要几百次迭代[1].本文采用文献[5]提出的随机对角Levenberg-Marquardt算法对网络作训练,这一算法需要的迭代次数明显比基本的BP算法少.随机对角Levenberg-Marquardt算法的公式为

式(1)中:ε是全局的学习率,一般取初始值0.01,ε太大会使网络无法收敛,太小则会降低收敛速度,且使网络更容易陷入局部极小值,训练过程中可以用启发式规则改值,根据训练集的大小可以调整样本数量,文中随机选取化过大.
对于单个样本,计算的误差是否小于当前平均误差的1/10,对权值的影响很小,本文对这样的样本不计算反向传播,降低了单次迭代所需的时间.
另外,为了满足实验需要,本文输出层单元数为34.
2 实验
以百度贴吧验证码的识别为例,验证Simard网络的多字体字符识别性能.初始学习速度是0.01,若在多次迭代后,网络性能没有提高,则降低学习速度;另外,对Simard网络的各层在规模上作了适度修改,尝试寻找最佳的网络规模.
2.1 实验数据
百度贴吧验证码的例子如图1所示,由4个数字或字符构成的验证码,具有旋转、缩放、扭曲形变、简单粘连和多字体变化等特点.点击验证码边上的“看不清楚”按钮会产生一个新的验证码,随机改变4个字符的旋转尺度、缩放比例、扭曲程度以及字体大小,但不改变4个字符的编码.例如,字符“ABCD”,刷新后还是“ABCD”,只是呈现的外观有所变化.基于这个因素及粘连字符出现的比例不高(实验中测定的错误分割的概率约42%,即平均刷新一次就可以正确分割),以刷新验证码代替粘连分割,如果一个验证码不能被分割成4个连通区,就刷新它.

图1 百度验证码例子
因为获得大量标定样本的工作量巨大,因此,本文用一个程序模拟生成百度验证码字符获得训练集,测试集通过已经标定的实际验证码获得.这样做也提高了训练集和测试集的独立性,使得验证结果更有可信度.
模拟生成训练集的程序通过以下步骤实现:
1)遍历系统中的字体,本文为64种字体,排除10种不可用的字体(如Wingdings),实际采用54种;
2)旋转字符图像,角度从 -30~ +30°,以5°为一刻度,共13种;
3)遍历数字和大写字母,排除数字0和字符O这2个易混淆且没在百度验证码中采用的字符,共34个字符,依次用0-33标定,获得训练集1;
4)修改第3步,只遍历数字0-9,共10个字符,依次用0-9标定,获得训练集2;
5)修改第3步,只遍历字母A-Z,去掉字母O,共25个字符,依次用0-24标定,获得训练集3.
训练集中每个字符图像归一化为20×20大小,居中放在28×28的白色背景中,以Mnist的格式保存.图2是部分训练集样本.
图2 部分训练集样本
测试数据的准备分如下3步:
1)从百度获得6 000个验证码图片,删除不能分割成4个连通区的图片,共获得3 509个可用的实验样本;
2)从剩下的图片中随机选取200幅验证码图片,通过求连通区分割得到800个字符图像,按照训练集一样规格制作得到测试集1,作单个字符的识别验证;
3)从前面第1和第2步选剩下的图片中再随机选择500幅作标定,作整体识别率验证.
2.2 收敛速度实验
网络的收敛速度受多方面因素的影响,如初始权值、训练集的质量、网络结构、训练算法等.本文主要研究了网络输出层规模(反映网络能识别的分类规模)和训练算法对收敛速度的影响,结果如图3所示.
图3中,Mnist、训练集2、训练集2-34都是纯数字的训练集,它们的样本个数不同,但是都只包含数字0-9,即分类规模是10.其中:训练集2-34中使用的网络,输出层有34个单元;其他2个训练集使用的网络,输出层是10个单元.从图3中可以看出:
1)随机对角Levenberg-Marquardt算法能极大提高网络的收敛速度.对于Mnist,采用基本BP算法的网络收敛到92%的正确率需要21次迭代(曲线Mnist-sdbp),采用随机对角Levenberg-Marquardt算法的网络则只要3次迭代(曲线Mnist);

图3 不同网络结构下的网络收敛速度
2)网络收敛需要的迭代次数与网络的输出层级实际规模有关(曲线训练集2-34中虽然网络输出层有34个单元,实际使用的是10个),和训练集的大小无关.
另外,训练集1-sub是训练集1的子集,只包含5个字体,共3 525个样本.图3中,训练集1-sub收敛的速度特别慢,进一步的实验表明,这是全局学习率太大造成的.
如图4所示,直接采用固定的全局学习率5e-005,比采用从一个较大值逐渐递减到5e-005的网络收敛得更快.注意,图4中,X轴的刻度是10 epochs.这个实验除了表明固定学习率有时可以获得比递减学习率更好的收敛结果外,还进一步验证了:若训练集中的类别数增加,则网络需要更多的迭代才能收敛.

图4 全局学习率的选择
2.3 泛化性
文献[1]提到,在网络性能达到一定程序后,继续提高网络中各层的规模对网络的识别能力影响不大.本文的实验也验证了这一点.对测试集1采用不同的网络结构进行识别,结果如图5所示.
图5中6-50-100表示采用的网络中C1,C2,H1的规模分别是6,50,100(输出层都是34).从图5可以看出:对于测试集1,需要190 epochs左右才能收敛到最佳结果,继续训练,则网络的泛化能力会表现出在最佳值附近震荡(即使MSE可以一直减小);减小网络规模会降低网络的泛化能力,增大网络规模,没有表现出明显的泛化能力的提高.
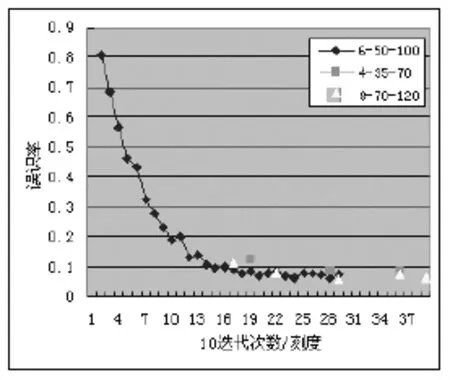
图5 网络结构对泛化性的影响
2.4 对百度验证码的识别结果
根据前面的实验,本文选择6-50-100-34的网络结构对训练集1作190次迭代训练;然后将训练好的网络对500个验证码图片、共2 000个样本作识别实验.获得的误识率为1.6%,整体误识率为6.5%.表明卷积神经网络能对百度验证码进行有效识别,同时也表明,可以把卷积验证码扩展到多字体字符的识别领域.部分误识的样本如图6所示.

图6 部分误识样本
从图6可以看出,造成误识的主要原因有2个:一个是近似字符,有些易混淆字符即使用人眼也很难辨识;另一个是分割造成的.文中用先求连通区,然后在原图截取连通区闭包的方法获得单个字符,实际获得的单个字符图像中可能会包含其他字符的一些像素,这个情况在字符“A”上特别明显,因为闭包是一个长方形,而字符“A”是三角形,所以容易框到其他字符的像素.
3 结论
介绍了一个典型的卷积神经网络——Simard网络,在Simard的基础上,采用随机对角Levenberg-Marquardt算法提高了Simard网络的收敛速度,并用改进的Simard在Mnist字库、程序生成的多字体印刷体字库以及百度验证码进行验证,结果表明:
1)随机对角Levenberg-Marquardt算法能有效提高网络的收敛速度(对Mnist库是7倍左右,见图3);
2)Simard网络能够很好地适应多字体数字和英文字符的识别问题,文中单字符的识别率达到98.4%(误识率1.6%),具有很好的泛化能力;
3)随着训练集样本类别数的增加,网络需要更多的迭代次数才能收敛,而训练集的样本数量和网络训练需要的迭代次数之间没有明显的关系;
4)在网络规模满足样本空间要求后,进一步提高网络规模对网络的识别能力提高很小,但网络规模与单次迭代的时间成正比,因此,需要控制网络规模;
5)固定一个较小的全局学习率,有时可以获得比递减全局学习率更好的收敛速度.
同时,实验也表明,随着训练集中目标类别数的增加,网络收敛需要的迭代次数也明显增加.能否把卷积神经网络用于大字符集(如中文字符)的识别还需要作进一步的实验.
[1]Lecun Y.Generalization and network design strategies[R].Pfeifer:Connectionist Research Group,1989.
[2]Simard P Y,Steinkraus D,Platt J C.Best practices for convolutional neural networks applied to visual document analysis[C]//Proc of the Seventh International Conference on Document Analysis and Recognition.Washington:IEEE,2003:958-962.
[3]Ranzato M A,Poultney C,Chopra S,et al.Efficient learning of sparse representations with an energy-based model[C]//NIPS 2006.Cambridge:MIT Press,2007:1137-1144.
[4]Jarrett K,Kavukcuoglu K,Ranzato M A,et al.What is the best Multi-Stage architecture for object recognition?[C]//Proc of ICCV.Kyoto:IEEE,2009:2146-2153.
[5]Lecun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proc of the IEEE,1998,86(11):2278-2324.
