基于时空兴趣点和主题模型的动作识别
2011-08-24罗立民
胡 斐 罗立民 刘 佳 左 欣
(1东南大学计算机科学与工程学院,南京 210096)
(2武警江西省总队司令部,南昌 330025)
(3上海交通大学图像处理与模式识别研究所,上海 200240)
人体动作识别在智能视频监控、视频注解、虚拟现实、人机交互等领域中具有广阔的应用前景,已经成为计算机视觉和模式识别领域的研究热点[1-3].目前,基于视觉的人体行为分析可分为2个层次的任务:①底层的特征提取和表示;②高层的行为识别和建模.从图像序列中提取出能够合理表示人体运动的特征,对行为识别和理解至关重要.
传统的动作表示方法,如基于边缘或形状的静态特征、基于光流或运动信息的动态特征以及基于时空体等方法,其准确性往往受到跟踪和姿态估计精度的影响,在运动物体较多或背景比较复杂的场景下,该类特征的鲁棒性面临挑战.最近,很多研究者提出了一些新的基于时空兴趣点(角点)的动作表示方法.文献[1]将Harris角点检测思想扩展到时空域,得到一种时空兴趣点(space-time interest point)的检测方法并用兴趣点构成的点集来表示动作.文献[2]提出一种基于 Gabor滤波器的时空兴趣点检测算法.这些算法克服了跟踪以及姿态估计精度的影响,能有效地反映出动作的运动信息以及外观信息.同时,概率主题模型近年来在计算机视觉领域得到了广泛应用,该模型源自文本处理领域,也可以应用于图像以及其他多维数据的识别、分类和挖掘等.文献[3]提出利用时空兴趣点以及概率主题模型LDA(latent Dirichlet allocation)进行动作识别,文献[4]则利用光流特征和改进的LDA进行动作识别.
本文提出了一种新的动作识别算法,在提取视频时空兴趣点的基础上,利用3D-SIFT描述算子建立兴趣点的样本特征集合,采用k-means的方法生成码本,利用概率主题模型LDA将每个兴趣点划分为不同的动作类别,从而实现了较复杂情况下的动作识别.
1 动作表示
1.1 兴趣点检测
本文采用基于Gabor滤波器和高斯滤波器相结合的时空兴趣点检测方法[2].首先使用高斯滤波器在空间域上对图像进行滤波,然后使用一维Gabor滤波器在时间域上对图像进行滤波,得到响应函数:
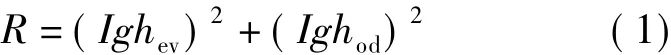

图1 Weizmann数据库上兴趣点检测结果图
1.2 3D-SIFT描述算子
3D-SIFT描述算子是由Scovanner等[6]提出的一种三维时空梯度方向直方图,可以看作是经典的尺度不变特征变换描述算子(2D-SIFT)从静态图像到视频序列的扩展,能够更好地减少缩放、旋转等仿射变换以及噪声带来的影响.本文采用3DSIFT的特征描述方式准确地捕捉到视频数据的时空特性本质.
首先,通过增加时间轴上的梯度信息将SIFT描述算子从二维扩展到三维,每一个像素点的梯度定义如下:
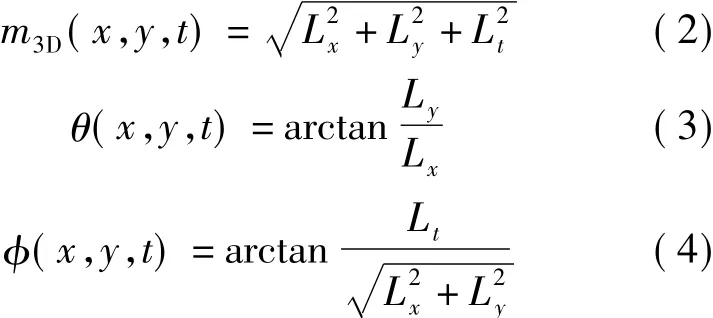
式中,Lx,Ly和Lt分别为x方向、y方向和时间轴t方向上的一阶导数;m3D为像素点在(x,y,t)方向上的时空梯度.每一个像素点对应一个(θ,φ),其中θ∈(0,2π),φ∈( -π/2,π/2).(θ,φ)描述了空间和时间上的梯度方向.对时空体中的所有像素,统计θ和φ,然后利用这些像素点的(θ,φ)就可描述这个兴趣点的特征.具体方法如下:将θ分为8个等级,φ分为4个等级,每一个像素点对应一个32维的直方图向量.本文使用2×2×2时空体来描述这个时空兴趣点,因此该兴趣点可得到一个1×256维的特征向量.
1.3 码本表示
由于人体的外观、行为方式以及视频拍摄角度等存在各种差异,因此同一种动作在不同视频中产生的兴趣点不尽相同,但针对同一种动作,这些兴趣点的特征具有相似性.因此从兴趣点的特征集合中,提取更高层、能够代表相同动作的特征模式,将有助于动作识别.
本文引入文本分类中“词袋”(bag of words)的思想,即在得到时空兴趣点位置的基础上,采用kmeans聚类算法对训练数据集中提取出的特征集合进行聚类,生成码本.所有时空单词组成的集合w={w1,w2,…,wN}称为时空码本,其中 N 为聚类中心的个数.对于不同的动作视频,视频中的每个兴趣点通过聚类被划分为不同类别的单词,这样,一段视频可以看成是由一些单词(兴趣点)构成的一篇文档,在后续的动作识别过程中通过计算兴趣点的特征并建立概率主题模型可实现对视频的分类.
2 基于概率主题模型的识别
概率主题模型来源于文本处理领域,认为一个文档是由一系列的主题组成的,而每个主题又是由一系列的关键词组成.区别于传统的词袋模型,主题模型强调文档是由文档-主题-关键词3层关系组成.文档不是仅由单个主题组成,而是由多个主题组成.同样,在视频的人体动作识别领域,视频片段可以看作是由不同的动作类别(主题)构成的文档,每个动作类别由一系列表示这个动作类别的兴趣点(关键词)所组成.
2.1 LDA主题模型
本文采用目前被广泛使用的概率主题模型LDA[7],其文档被表示为隐藏主题(latent topics)的随机混合,如图2(a)所示.对于视频集合D中的任意一段视频 w={w1,w2,…,wN},LDA 模型使用如下方法生成:
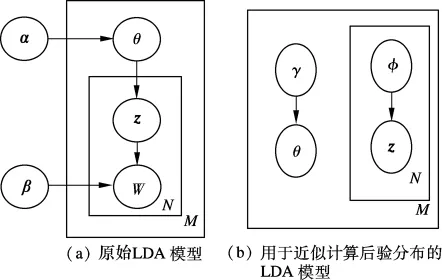
图2 LDA模型
①选择N,这里N为视频的长度(包含单词的个数),且 N ~Poisson(ξ).
②选择θ,其中θ表示当前视频片段真正的主题混合成分,且θ~Dir(α).
③对N个单词中的每一个单词wn,
a) 选择一个主题 zn,zn~Multinomial(θ);
b)选择一个单词wn,其中wn来源于一个在zn,β 条件下的多项分布.其中,βij=p,假定p的Dirichlet分布和主题zn的维数都为k.
④在给定α,β的情况下,主题的混合参数θ,N个主题的变量z,以及N个单词的一个联合分布为
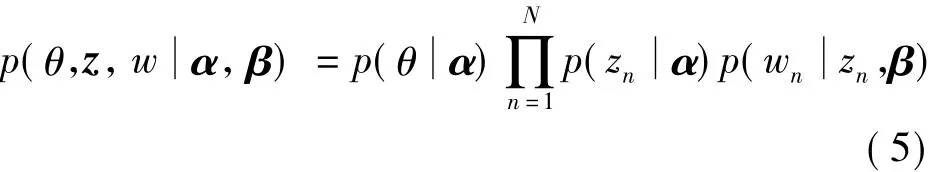
2.2 动作识别
在LDA模型中,主要问题就是给定w,α,β的情况下,求解θ,z的后验分布:
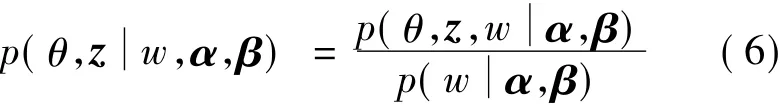
直接计算这个分布很困难,首先使用文献[7]中提出的变分EM算法计算,具体过程如下:
①首先将原始的LDA模型进行扩展,如图2(b)所示.
假设每一行都是独立采样于一个可交换的Dirichlet分布,选择一个可以分离的分布:
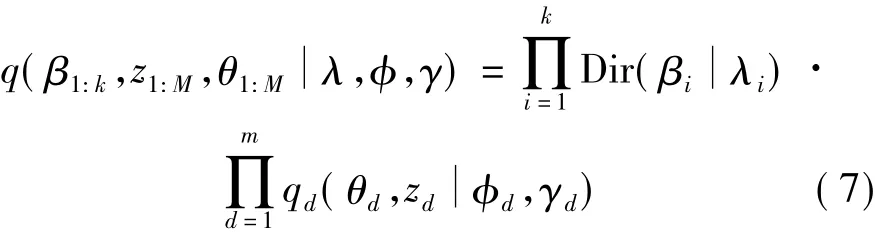
最小化q和p之间的KL-divergence,可得

不断迭代可得到变分参数(γ*,φ*),然后从Dir(γ*(w))中选取一个样本θ,θ中的每一个维度表示该维对应的动作在这个视频片段中所占的比例.真正的混合比例θ*可从Dir(γ*(w))中产生的样本均值得到.参数φn是的近似.由于zn服从Multinomial(θ*),可得到一段视频所属类别的概率分布为
当视频中只有一个动作时,可采用式(8)~(10)计算整个视频片段中的动作类别.通常,一段视频中的情况比较复杂,例如多个人做不同的动作或单个人做一系列不同的动作.在这种情况下,本文提出利用得到的φn(即为每一个兴趣点表示的单词都分配不同的动作类别,这样的表示使得对整个视频的整体分类转化为对当前帧上兴趣点代表的单词的分类.然后判断当前帧上不同类别兴趣点(单词)的个数,当某一类别的兴趣点的数量大于预设的阈值时(本文设置该阈值为5),即表明当前的视频中存在该类动作.这样的分类方法能够对更复杂的视频进行处理,后面的实验验证了这种分类方法的有效性.图3为本文方法的实现流程图.
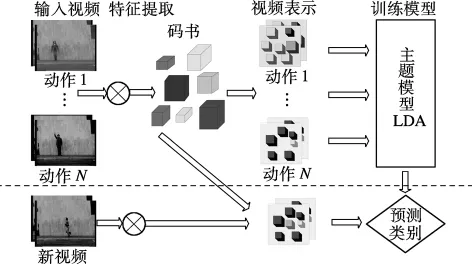
图3 本文方法的实现流程图
3 实验结果及分析
3.1 数据库
对3 个行为数据库 Weizmann[5],KTH[8]以及作者录制的视频数据库分别进行了测试.Weizmann数据库包含10种动作(walk,run,jump,gallop sideways,bend,wave1,wave2,jump in place,jumping jack,skip),每种动作由9个人完成.背景和视角均不变,前景的轮廓信息也包含在数据库中.KTH数据库包含6种动作(walking,jogging,running,boxing,handwaving,handclapping),由25个不同的人构成,每个人在4种场景(户外、户外镜头变焦、户外穿着不同的衣服,以及室内)下进行这6种动作.该数据库共计600个视频,视频空间分辨率为160×120像素,帧速率为25 frame/s,平均视频长度大约4 s.作者录制的动作数据库包含由6个人完成的11个动作,其中包括了在一个场景中有多个动作的情况.图4为这3个数据库的一些样本图像.

图4 数据库例图
3.2 实验结果及分析
首先针对每段视频中仅包含一个人的情况,对不同的数据库分别进行训练,采用留一法 (leave one out)来验证实验效果.训练过程中,KTH数据库以σ=2,τ=2.5为参数进行兴趣点检测,Weizmann数据库以及本文的数据库采用σ=2,τ=2为参数进行兴趣点检测.从视频中抽取出兴趣点后,采用3D-SIFT特征描述方式建立兴趣点样本特征集合,运用k-means聚类算法对样本特征集合进行聚类来建立样本空间的时空码本,然后利用LDA模型进行学习训练.图5为在这3个数据库上的识别混淆矩阵,码本大小均为1 000.

图5 识别混淆矩阵
由于k-means聚类算法的初始类别随机产生,且聚类维数的选取会对识别性能产生影响,本文给出了在码本大小分别为100,500,1 000,1 500,2 000及2 500时对识别率的影响,如图6所示.图6表明,聚类中码本的大小对本文方法的识别率影响较小.为了进一步进行对比,表1给出了在KTH和Weizmann数据库上本文方法与其他方法的识别率比较结果.由表1可看出,本文算法的识别率已达到或超过这些算法.
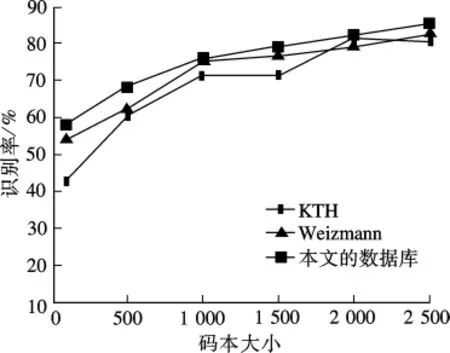
图6 不同码本大小下的平均识别率比较
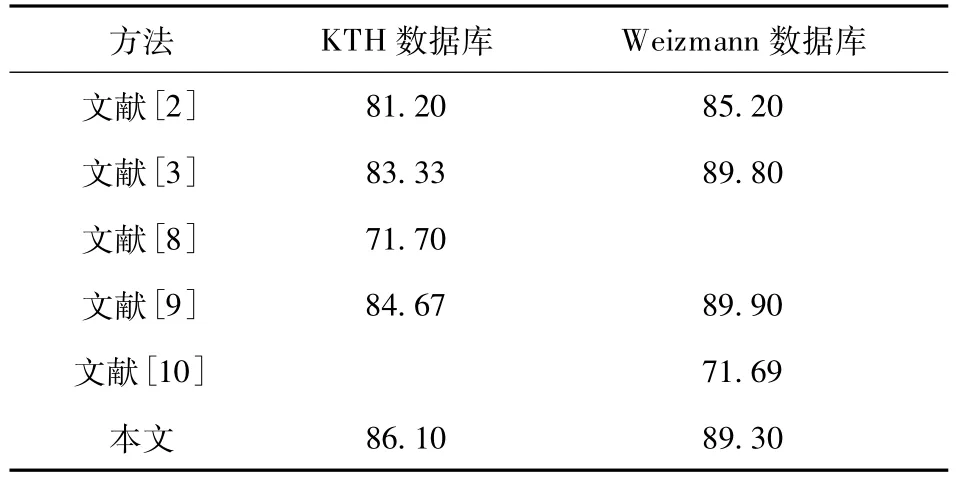
表1 各种方法的识别率结果对比 %
为了进一步验证本文的算法,在2种更加复杂的情况下进行了测试,如图7所示.其中,图7(a)给出的3段视频中,每一段视频都有多个人执行不同的动作.图中的虚线框表示该类动作发生的位置.图7(b)给出的视频是一个人从走到弯腰,再到行走的过程,这个过程包含3个动作.从图中可看出,由于采用了概率主题模型,对每一个时空兴趣点通过推断其主题(动作类别),从而实现了对整个视频中复杂动作的分类.由此可见,本文提出的方法不仅能识别视频中的单个动作,而且当视频中存在多个人完成不同的动作,或是同一个人完成不同的动作等较复杂情况时,也能有效地识别.实验也同时表明抽取兴趣点的时空特征对动作进行表征,能够更好地降低光照变化以及施动者的穿着和动作差异等环境因素造成的影响.

图7 2种更加复杂情况下的测试
4 结语
本文提出了一种新的动作识别算法,在提取视频中时空兴趣点的基础上,利用3D-SIFT描述算子建立兴趣点的样本特征集合,然后运用k-means方法生成码本,并利用概率主题模型LDA对视频进行分类.主题模型将每个兴趣点划分为不同的动作类别,因此该方法不仅能够处理一段视频中包含一个动作的简单情况,同时也可以处理视频中包含多个动作的情况.实验结果验证了该方法的有效性.
References)
[1] Laptev I.On space-time interest points[J].International Journal of Computer Vision,2005,64(2/3):107-123.
[2] Dollar P,Rabaud V,Cottrell G,et al.Behavior recognition via sparse spatio-temporal features[C]//Proceedings of 2nd Joint IEEE International Workshop on VSPETS.Beijing,China,2005:65-72.
[3] Niebles J,Wang Hongcheng,Li Feifei.Unsupervised learning of human action categories using spatial-temporal words[J].International Journal of Computer Vision,2008,79(3):299-318.
[4] Wang Yang,Mori G.Human action recognition by semilatent topic models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(10):1762-1774.
[5]Blank M,Gorelick L,Shechtman E,et al.Actions as space-time shapes[C]//Proceedings of the 10th IEEE International Conference on Computer Vision.Beijing,China,2005,2:1395-1402.
[6] Scovanner P,Ali S,Shah M.A 3-dimensional shift descriptor and its application to action recognition[C]//Proceedings of the 15th ACM International Conference on Multimedia.Augsburg,Bavaria,Germany,2007:357-360.
[7]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3(4/5):993-1022.
[8] Schuldt C,Laptev I,Caputo B.Recognizing human actions:a local SVM approach[C]//Proceedings of the 17th International Conference on Pattern Recognition.Cambridge,UK,2004,3:32-36.
[9] Dhillon P S,Nowozin S,Lampert C H.Combining appearance and motion for human action classification in videos[C]//2009 IEEE Conference on Computer Vision andPattern Recognition Workshops. Miami, FL,USA,2009:22-29.
[10] Liu J Q,Ali S,Shah M.Recognizing human actions using multiple features[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition.Anchorage,AK,USA,2008:4587527.
