基于规则的机器翻译技术综述
2011-05-18袁小于
袁小于
(重庆师范大学数学学院,重庆 沙坪坝 401331)
机器翻译(Machine Translation,MT)是借助计算机程序将文字或语音从一种自然语言翻译成另一种自然语言的技术.机器翻译是早期人们研究自然语言识别的中心课题之一,是人工智能研究的重要成果,其历史可以追述到上世纪的50年代初期.但是由于当时人们认为只要“找出两种语言间的对应词,然后经过简单的语法分析调整词序就可以实现翻译”[1],使机器翻译的研究工作走入了死胡同,因为机器翻译的结果很难达到预期的效果,以至于1966年美国科学院在一个报告中指出:“在可预见的将来,机器翻译不会获得成功”[1].
根据实际应用,机器翻译可以简单地分为文本翻译和语音翻译.文本翻译是以词-词、句-句、篇-篇的模式实现翻译任务的.语音翻译则还得使用语音识别技术(Automatic Speech Recognition,ASR)和语音合成技术(Text To Speech,TTS)或者真人语音库技术,才能从源语音生成目标语音,语音转换时具有更高的灵活性和不规则性,比文本翻译难度更大.相比文本翻译的大概可用的情况,语音翻译技术还远远没有达到实用的阶段.因此,本文限定讨论机器翻译就指文本机器翻译,以下同.
根据机器翻译获得知识的方式,机器翻译发展到现在可以分为两类[2]:一类就是基于人工获取知识的方法或者基于规则的方法,这是传统的经典机器翻译方法;另一类是基于机器自动学习知识的方法,分为非参数方法(或实例方法)与参数方法(或统计方法)两种.下面以英汉机器翻译为例回顾一下经典机器翻译技术中使用的各种技术.
1 基于规则的机器翻译技术
经典的基于规则的机器翻译技术主要包括源语言的文本处理、词典构成、文本分析,源语言到目标语言的词典查询翻译,目标语言文本生成等技术.
1.1 源语言文本处理技术
文本处理技术主要是针对输入的源语言文本,通过断句和格式保留操作,把多句或整篇文章分成机器能够处理的单元.
1.1.1 符号断句处理技术
断句处理主要是以代表整句结束信息的句号、问好、叹号、省略号以及回车换行符号为标记,将文章切分出单句[3].
1.1.2 格语法文本处理技术
“格”指底层结构中,每一个名词与跟它有关的动词之间的句法语义关系.这种关系一经确定就固定不变,不管他们经过了什么转换操作[4].
1.1.3 词或短语切分技术
将句子切分为词或短语,其中短语切分概率化技术,改变了其他切分技术认为所有的短语切分都是等概率的思想,提高了准确度[5].
1.1.4 格式保留处理技术
源语言文本中的特殊标记字符通常分隔了不同的单词、句子,在原文意思的表达中起到很关键的作用.因此,在进行文本处理的时候,必须采用相应的办法将这些符号保留,在翻译成目标语言文本之后再插入对应的位置.
1.2 机器翻译词典构成技术
词典是经典机器翻译系统的基础资源,是进行句法分析、目标语言文本生成的依据.可以说,一个词典的好坏就决定了机器翻译系统的优劣.
1.2.1 一般机器翻译词典构成技术
词典以词项为中心,把以该词项有关的短语、习语组织到同一词条下,并编制有关索引,以利查询.英汉机器翻译词典构成的基本结构如表1所示.

表1 英汉机器翻译词典基本结构
吴保民等在Matlink翻译实验机器中对各个字段的功能和原则做了初步的定义[6],词典的索引采用了哈希散列算法.
1.2.2 格框架机器翻译词典技术
基于菲尔摩的格语法理论建立格框架,在格框架中不仅有语法信息,还有语义信息,且语义信息是整个框架的主体[4].一个格框架由一个主要概念和一个辅助概念构成.格框架以词条的形式有机地编排于格词典之中.
1.3 文本分析技术
文本分析技术的功能和任务是解决源语言句子和目标语言句子的结构问题,即确定句子主谓宾等结构,以便确定词与词之间的关系使之构成短语,再确定短语之间的关系使之构成更大的短语或组成句子.
1.3.1 浅层句法(词法)分析技术
浅层句法分析是指对源语言语句作词性标注后所进行的短语级句法分析,而不是完整的句法结构分析,其结果称为Chunk序列[7].郭永辉等给出了一种基于GLR算法的分析技术[8],在Matlink英汉机器翻译系统的句法分析中发挥了稳定的功能.
杜祝平等还给出了一种基于规则的词法分析技术[5],该规则分为主词类规则、个别词规则和使用数学定理证明中的夹逼原理的规则.
1.3.2 整句句法分析技术
整句句法分析包括产生式通用部分处理和从句处理,主语部分分析,谓语部分分析及其他部分的分析,如费鲲采用的部分分析的思想,将一个句子分成几个语法成分,分别进行分析,并给出句法树[9].而马芳等人则给出了一种基于最大熵基本原理的从句识别方法[10],结合了统计知识和语法规则,使模型训练速度大大加快,识别精度更高.句法分析过程还可以采用依存语法和语则分析来进行,最后生成一棵带短语信息的依存语法树[3].
1.3.3 语义分析技术
此方法借助优选语义学、语言成份的逻辑语义分析、黑板结构等理论,对语言翻译过程中的语义分析,尤其对介词多义词等影响句子意思的部分进行系统分析,可以改善一般机器翻译技术的翻译效果[11].
1.4 机器翻译词典查询技术
在机器翻译中,查阅翻译词典是一个经常进行的行为,其查阅效率是影响翻译速度的关键.因此,如果采用简单顺序搜索算法和二分查找算法,效果都非常的差,所以一般采用哈希表查询方案[6],有3种实现方式,如表2所示.

表2 3种哈希算法实现方案
有关实验表明,在64 K散列空间中,第三个方案的平均查找次数和最坏查找次数均最低,且在3次以内查找成功的百分比最高.
1.5 语义排歧技术
语义排歧是机器翻译必须要逐渐克服的困难之一.这个困难可以说最终影响了基于规则的机器翻译技术的发展.
1.5.1 二元文法
对于有多个词性的单词,需要进行词性消兼(歧)处理.采用二元文法的隐马尔可夫模型和Viterbi算法来取最佳词性[3],该方法通过查找概率库字典,标注各结点单词对应的词性.
1.5.2 常识排歧法
首先对翻译过程中源语言多义词的词义选择是否符合常识给出一条形式化的标准,然后将人们在翻译过程中排歧时所进行的逻辑推理归结为一种机械的集合运算,使之易于机器操作,在此基础上建立义项多元组的概念,利用此多元组来对多义词的翻译进行排歧[12].
1.5.3 其他排歧技术
还有选择最常见含义法,利用词类进行词义排岐,基于选择限制词义排歧,基于共现特征的词义排歧,无指导的词义排歧,基于词典的词义排歧等等[13-14].
1.6 目标语言文本生成技术
1.6.1 目标语言句法分析转换技术
此阶段需要运用上文提到的各种文本分析技术,按照目标语言的语义结构规律对运用机器翻译出来的目标语言短语进行重新排序,即对分析阶段产生的分析树进行调整[7].
1.6.2 目标语言文本生成技术
利用html,xml等文本生成排版技术生成利于阅读的目标语言文本.一个完整的机器翻译系统如图1所示.
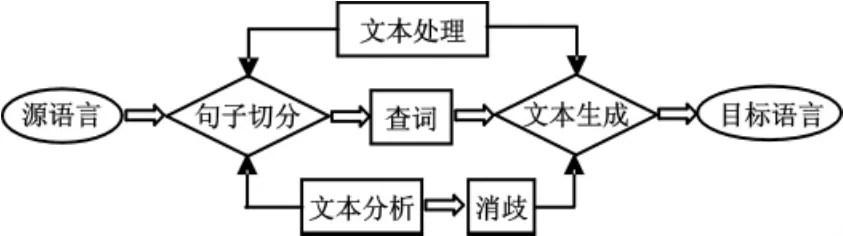
图1 经典机器翻译系统图示
2 经典机器翻译的难点
2.1 词义选择问题即消歧问题
从一个词的多个意思中选择一个恰当的意思和从多个同义或近义的词中选择恰当的词都是机器翻译难以圆满解决的问题.在很多语言中,还有不少由两个或两个以上单词组成的固定搭配,其中的每个单词都有几种不同的意思,而他们结合在一起构成一个搭配时,就会表示更多的可能不同于组成部分的意思.这几种词义选择问题,都是限制机器翻译准确性的重要因素[14-15].
2.2 层次切分问题
从语言的内部结构来说,很多情况下源语言和目标语言是两种截然不同的语言.要想机器翻译准确,就必须克服结构上的差异,以语义为基础,在句法的辅助下完成翻译过程.层次切分将直接影响句子中意群间的相互关系,如果不正确的切分,就会造成虽然单词或短语的翻译正确,但是整个句子的意思却不合逻辑.也就是说,要恰当地将句子切分为字、词、短语、句子非常不容易.
2.3 特殊句型问题
各种语言中都有很多特有的表达方式或固定结构,如英语中有主语从句、非限定性定义从句、宾语从句等,又进一步加大了英汉翻译的难度[14].
2.4 语言情感问题
语言是表达思想和情感的工具,除非是纯粹的说明性文字,一般的文章中都或多或少的蕴涵作者的喜怒忧思悲恐惊等情愫.而机器通过词典对应查询,按照规则机械地组合拼凑的文字,很难让人读出原作意境.表现原作的情感连人工翻译都难于完美再现,何况是冷冰冰的机器!
3 结语
人类语言的发展从最初的无序到凭经验使用,直到系统总结出各种语言的最适合的表达情感和思想的方法,这种方法就是规则,即语法.基于规则的经典机器翻译技术虽然发展了50多年,现在各种技术也比较成熟,但因为有前节所述天生的弱点,其翻译效果还远远没有达到令人满意的地步.因此,在语言形式化方法的进一步发展、计算机运算处理能力的大幅提高、人工智能真正具有“智能”以及人们对人脑包括人脑学习机能的更多认识的同时,有必要寻求新的翻译转换手段,才能使机器翻译质量逼近人工翻译水平.而前面提到的基于机器自动学习知识的机器翻译方法,使用非参数方法(或实例方法)与参数方法(或统计方法)两种手段开发的各种新的翻译系统,翻译效果在很大程度上弥补了经典机器翻译的部分缺陷.但是,实验和实践都可以看出,这种方法也不是完美的,在对付长句子、特殊句子以及需要合理表达情感的时候,同样也是无能为力的.所以,现在实际的处理方式就是综合使用这几种翻译技术于一个系统中,取长补短,虽然效果逐渐可以达到特定领域的实用水平,不过仍然离完美甚远.
[1]王万森.人工智能原理及其应用:第2版[M].北京:电子工业出版社,2007:234.
[2]赵红梅,刘群.机器翻译及其评测技术简介[J].术语标准化与信息技术,2010(1):36-41.
[3]胡春静,韩兆强.英汉机器翻译引擎的研究与实现[J].计算机工程与应用,2003(29):148-150.
[4]王祁.格语法在英汉机器翻译系统中的应用研究[J].东北大学学报:社会科学版,2005,7(6):455-457.
[5]杜祝平,吴保民,张连海,等.英汉机器翻译系统中基于规则的词法分析[J].信息工程大学学报,2003,4(3):89-92.
[6]吴保民,杜祝平,张连海,等.Matlink英汉机器翻译试验系统中词典的存储结构及搜索算法[J].信息工程大学学报,2001(4):70-74.
[7]周会平,王挺,陈火旺.用LR算法分析汉语的语法关系[J].软件学报,1999,10(9):967-973.
[8]郭永辉,吴保民,王炳锡.一个基于GLR算法的英汉机器翻译浅层句法分析器[J].计算机工程与应用,2004(34):124-129.
[9]费鲲.机器翻译中句法分析的设计与实现[J].计算机工程与设计,2006,27(15):2832-2834.
[10]马芳,吴保民,王炳锡.一种面向英汉机器翻译的从句识别方法[J].信息工程大学学报,2006,7(2):193-196.
[11]戚世远.英汉机器翻译中的语义分析[J].计算机应用与软件,1993(4):54-58.
[12]段绮丽.机器翻译中词义的常识排歧[J].重庆大学学报:自然科学版,2005,28(3):69-71.
[13]鲁孝贤.机器翻译语义排歧的方法[J].中国科技翻译,2007(4):22-25.
[14]王祁,邹冰.现行英汉机器翻译系统存在的问题及解决策略[J].东北大学学报:社会科学版,2003,5(5):388-390.
[15]汤闻励.英汉机器翻译的“可能”与“不可能”[J].广东职业技术师范学院学报,2002(2):84-88.
