基于数据流的指令级功耗建模方法
2010-08-27曹庆年强新建
曹庆年,田 泽,强新建
(西安石油大学计算机学院,陕西西安 710065)
0 引言
目前,基于嵌入式处理器的SoC技术得到了广泛的应用。根据不同应用,利用嵌入式处理器可编程的灵活性,只要配置不同的功能性软件就可改变系统功能,极大地提高了芯片的适用性和应用的普遍性。而嵌入式处理器在增强了系统功能的同时,也给SoC系统的低功耗设计带来了问题。嵌入式处理器硬IP核的保护,使得SoC设计者无法得知其底层最为核心的设计细节,须借助其功耗模型才能对整个系统的功耗进行估计与验证,因此,嵌入式处理器功耗模型成为近来功耗EDA研究的重点之一。
嵌入式CPU的指令级功耗模型可以满足软件功耗估计的要求。一方面,各种SoC应用软件使得CPU要处理各种各样的输入信号,要求功耗模型要保证稳定的计算精度,另一方面,SoC功耗估计通常要包括大量的指令执行,功耗模型必须提供足够快的执行速度。而嵌入式CPU内部的复杂性和外部的应用需求使得指令级功耗建模十分困难。这方面的工作具有一定的探索性,有关文献[1-5]提出一些分解指令级功耗复杂性的办法,相关的算法是针对一些特定情况提出的,没有一个统一的测试基准,其分析和验证结果的精度存在一定问题。因此,本文在研究和分析这些问题的基础上提出了一种简单有效的指令级功耗模型。
1 嵌入式CPU
为了进行CPU的功耗分析,选用一个具有三级流水线的16位RISC处理器μP,其指令集[ARM]兼容ARM 7THUMB。
μP指令系统具有大多数CPU常见功能。其不仅有典型 RISC的一拍执行指令,而且有多拍的Load/Store指令。因此该指令系统具有一定代表性。
μP内部结构由四个模块组成:算术逻辑单元(ALU)、寄存器组(RegBank)、存储器接口(MemInt)和控制单元(CtrlUnit),如图1所示。其执行机制是按照流水线来组织的,分成取指、译码和执行三级,对应各个部件的操作如下:
1)取指:把程序计数器 PC作为地址发送到MemInt单元,把数据作为指令从内存总线上读入到MemInt单元中。
2)译码:通过CtrlUnit单元对指令译码后,转换成各个部件的控制信号。
3)执行:执行读入指令规定的操作,可分成3种:算术逻辑运算(A&L)、写寄存器(WrReg)、访存操作(Ld&St)。

图1 μP处理器结构Fig.1 The architecture ofμP processor
2 现有指令级功耗模型分析
为了展现指令级功耗的变化特点,采用已有算法来描述微处理器μP的能量损耗,并对其利弊进行分析。为了简化起见,此处用电路节点的有效跳变总数来代替具体功耗。关于功耗有如下公式[4]:

其中C UNIT为单位电容,αi为一整数,表示节点i上发生了几次跳变。有效跳变与电路功耗只相差常数倍,因此不改变问题的本质。
2.1 常数模型
常数模型[1]基于指令功耗的统计常数来给出算法软件的功耗估计。对于CISC来说,由于指令/数据缓存、微指令ROM等部件的稳定功耗占平均功耗的主要部分,指令功耗的变化很小,这种模型比较适用。对于RISC来说,大部分功耗消耗在执行指令功能的部件上,指令功耗在一个很大范围内变化,因此需要更细致的功耗模型。
图2给出了常数模型的计算效果(从左到右,依次执行的程序为二分查找、冒泡排序、顺序查找、最大值排序、整数除法、菲波那其数列、梵塔问题),其中所有程序的所有指令的功耗/周期平均值为2 307.02,各个算法功耗相对误差的平均值分布在-20%~10%之间,这说明常数模型仍然有可取之处。然而相对误差的方均根在60%左右,这也说明了这个模型比较粗糙。
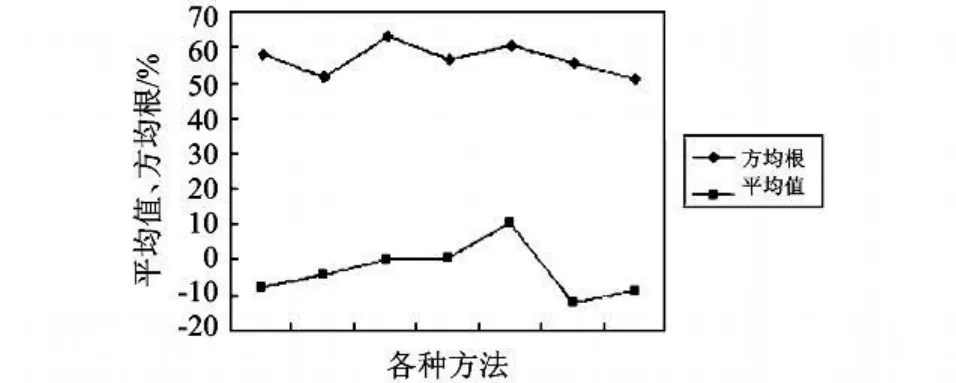
图2 常数模型的相对误差Fig.2 The relative error of constant model
2.2 功能模型
功能模型[2]考虑了具体指令的执行情况,把指令分成取指与译码、数据计算、分支判断、写寄存器和访存操作五个基本功能。按照功能划分在功耗上具有一定的独立性。通过对大量指令的功耗采样可以提取出各个功能消耗的功率常数,从一条指令的功能组合就可以计算出其功率损耗。然而该模型没有对具体算法进行验证,无法判断其在实际应用中的计算效果。
微处理器μP中不含有指令预测单元,因此模型[2]的功能单位只剩下:
1)取指令和译指令(F&D),对应于MemInt与CtrlUnit。
2)算术/逻辑指令(A&L),对应于ALU。
3)寄存器写(Wr Reg)对应于 RegBank(后面有更详细的介绍)。
4)读/写存储器(Ld&St),对应于MemInt。
在该模型功耗模拟中我们发现了图3所示现象,在没有WrReg信号的时候RegBank功耗并没有减小。这说明写寄存器功耗不是RegBank功耗的主要部分,事实上庞大寄存器堆己经使寄存器读出网络的功耗超过了写寄存器的功耗,因此可说对处理器μP而言,以功能单位分解功耗已不再有效。

图3 写寄存器的功耗比较Fig.3 The power comparison of write register
2.3 流水线模型
流水线模型[3]把指令功耗按照流水线进行分解,描述了指令变化造成的各级流水线功耗变化情况。
μP只有三级流水线,难以构造十分完整的流水线模型,以下我们只分析控制信号跳变对μP能耗的影响。因为指令变化就意味着控制信号的变化,所以在一定程度上能够分析流水线模型的特点。
图4把一个16位加法器的功耗采样按照其信号跳变的海明码距排列起来,表现出一种很接近于线性的变化关系,其最大偏离约为100,一般来说这种现象具有一定的普遍性。

图4 信号跳变与功率损耗Fig.4 The signal transitions and power loss
这个模型考虑了CPU的具体结构,因此提供了更准确、更为可信的功耗估计。然而这个模型考虑的只是指令操作的变化情况,没有包括具体操作数的变化情况,使其功耗模型精度受到影响。
3 基于数据流的功耗模型
电路功耗依赖于输入信号的变换,而前述的已有算法大都没有考虑信号的变化,因此,讨论CPU内部信号跳变,即数据流对CPU功耗的影响。
现有的CPU大都用流水线作为指令执行机制,时钟周期很短。从逻辑层级来看,每一级的逻辑门级数不会很高,这样就使得内部信号跳变形成的电路功耗占据绝大部分,也使得使用内部信号跳变对电路功耗的简单估计成为可能。根据对已有功耗模型分析的结果,提出一种基于数据流的功耗模型。
指令功耗模型:

式中,Pc为一功耗常量,设α0=Pc,H(X 0,X′0)=1,j为数据流下标,H(Xj,X′j)为数据流Xj变化的海明码距,αj为拟合系数。并且为了便于分析,把功耗模型中的常数Pc也作为一个数据流。随着数据流中传递数据的变化,Hj(Xj,X′j)的取值也会发生变化,但αj的取值基本恒定。其中,5个数据流分别为:
1)ABUS:从RegBank寄存器中读出数据作为ALU的一组输入信号。
2)BBUS:从 RegBank 、CtrlUnit或 MemInt读出数据作为ALU的另一组输入信号。
3)ALUBUS:ALU的计算结果写回RegBank中寄存器,或者作为地址发送到MemInt。
4)INCBUS:把RegBank中寄存器的内容作为地址经由MemInt输出到外部总线上,并连接一个加法器,自动进行增减量赋值。
5)CTRLBUS:从Ctrl Unit出来的控制信号,负责控制各个部件的各种操作,具有很大的扇出负载。
其矩阵公式变化如下:

H M,N为M个数据流的N次采样,注意到数据流模型的数学构造并不比功能模型更复杂。
图5给出了本文建模方法的流程,一共有4个主要步骤,分别介绍如下:
1)构造μP的门级网表。为了简化起见,我们只选用了ARM7THUMB指令集合。为了保证指令集合功能的完整,添加了部分ARM7TDMI的指令功能。另外由于缺少合适的功耗估计工具,本文中添加了部分功耗估计代码,计算每个节点的有效跳变,并生成程序执行的数据流文件和功耗文件。
2)编制μP的基本算法和编译器。由于没有现成的ARM 7THUMB编译软件,本文的工作包括了一个用 C++实现的 μP的Compiler,负责编译ARM7THUMB指令和附加的一些指令,生成可以为VHDL读入的数据格式。
3)功耗数据的分析。为了理解和分析己有的算法思路,一个图形化的数据分析工具是必不可少的。本文借助于Matlab和Excel进行了大量的数据分析。Matlab长于矩阵算法,而Excel在统计图形显示方面十分出色。
4)功耗模型验证。在功耗模型中应包含一个μP指令的行为模拟器,以仿真内部信号变化。为了简化起见,我们的模型仍然从VHDL模拟器中读出数据流信息进行功耗计算(如虚线所示),然后与模拟器中产生的功耗信息进行比较。

图5 建立及验证功耗模型流程图Fig.5 The flow chart of power model development and validation
4 数据流模型验证
为验证本文模型计算效果,我们采用了7个算法程序作为测试样本。这几个程序包括了所有的指令类型,并分别有所侧重,具有一定的典型性。整数除法、菲波那其数列以计算指令为主,梵塔问题则偏重于调用指令和访存指令,其余程序则比较均匀。
为了简单起见,验证实验统计每条指令实际功耗与估计功耗的相对误差,用统计平均与方均根来衡量本文模型的计算效果。并将其结果与常数模型和功能模型进行比较,见表1和表2。

表1 功耗模型相对误差的平均值比较Tab.1 Power model comparison of the average relative error

表2 功耗模型相对误差的均方根比较Tab.2 Power model comparison of the root mean square relativeerror
从表1和表2可以看出,无论从相对误差的平均值还是从方均根数据来看,常数模型与功能模型的差别是不大的,平均值在土15%之间,方均根则在60%左右。数据流模型相对误差的统计平均值在±10%之间,方均根在整体上小于前两个模型。
5 结论
本文提出用数据流分解指令功耗的建模方法,以此建立的16位处理器核的指令级功耗模型与已有算法相比,考虑了内部信号变化对CPU功耗的影响,反映到验证结果上,减少了平均相对误差和相对误差的方均根,因此具有更加稳定的计算精度,可以为低功耗嵌入式系统的软件设计提供指导。
[1]Russel J T,Jacome M F.Software Power Estimation for High Performance 32-bit Embedded Processors[C]//Washington DC:IEEE Computer society,1998:328-333.
[2]Brandoless C,Fornaciari W.An Instruction-level Functionality-based Energy Estimation M odel for 32-bits Microprocessors proceedings of 37th Annal Design automation conference[C]//New York:ACM press,2000:346-351.
[3]Sami M,Sciuto D,Silvano C,et al.Instruction-level power estimation for embedded VLIW cores[C]//proceedings of 8th International workshop on hardwear softwear codesign.New York:ACM press,2000:34-38.
[4]黄琨,章隆兵,胡伟武,等.一种基于龙芯 CPU的结构级功耗评估新方法[J].计算机研究与发展,2007,44(5):782-789.HUANG Kun,ZHANG Longbing,HU Wei wu,et al.An innovative architecture-level power estimation methodology for Godson processor[J].Journal of Computer Research and Development,2007,44(5):782-789.
[5]朱建,王晓丰.EMSIM中指令仿真与功耗模拟的研究[J].硅谷,2009(2):30-31.ZHU Jian,WANG Xiaofang.Research on EMSIM instruction in simulation and power simulation[J].Sillicon Velley,2009(2):30-31.
