数据流计算研究进展与概述
2021-11-30范志华李文明叶笑春范东睿
范志华,李文明,叶笑春,范东睿*
1.中国科学院计算技术研究所,计算机体系结构国家重点实验室,北京 100190
2.中国科学院大学,计算机科学与技术学院,北京 100049
引言
传统冯·诺依曼架构从提出至今已有70 多年,作为主流的计算机架构,几十年间学术界、产业界围绕其开展了多种多样的探索研究。近年来,随着社会和科学技术的不断发展,大量新型应用对计算需求远超从前,比如网络服务、人工智能、AIoT(Artificial Intelligence and Internet of Things)等高通量应用场景,在这些新的应用场景的催化下,计算机的发展进入新的黄金时代。然而,冯·诺依曼架构基于全序程序执行的指令控制流计算模型,在存储访问和并行处理等方面表现出固有的局限性,“存储墙”等问题日益严重,制约了计算机性能的提升。
在解决冯·诺依曼计算机的串行指令执行和访存瓶颈问题过程中,出现了数据流(Dataflow)计算思想。因其天然的并行性、低访存需求等结构优势,近些年重新得到了学术界和工业界的青睐。数据流计算的概念由麻省理工学院的Jack.B.Dennis[1]等人首先提出,后由以高光荣教授为代表的数据流研究人员将其完善、发展。文献[2]是国内最早的数据流计算研究成果。图1 展示了从上世纪70年代至2020年计算机领域重要会议和期刊中,标题含有数据流关键词的研究论文数量,可以发现数据流计算经历发展的低谷期,现在又重新回到研究人员的视野中。后摩尔时代的到来将为数据流计算的发展带来前所未有的机遇,数据流计算的创新即将进入下一个黄金时代。

图1 数据流计算相关论文数量Fig.1 Number of papers related to dataflow computing
回溯历史,本文将数据流计算的发展历程概括为三个阶段。第一阶段是数据流计算的起源阶段(20世纪90年代以前),此阶段数据流计算的研究聚焦在数据流计算理论和数据流程序执行模型,比如数据流线程模型、数据流同步模型、数据流存储模型。随着数据流计算相关理论的完善,数据流计算进入第二阶段(90年代至2010年),该阶段的研究重点是数据流编译技术和并行机系统。许多研究人员基于当时已有的处理器或系统展开了数据流计算机的研究,比如基于数据流思想的并行机系统,多核、多线程的数据流编译技术。随着工艺和应用场景的发展,传统计算机架构的发展遇到瓶颈,数据流计算进入第三阶段(2010年以后),第三阶段的研究重点是数据流编译技术和数据流硬件架构。基于数据流思想的处理器、协处理器等芯片被提出,并在人工智能、网络服务、科学计算等高通量应用领域发挥出独特的优势。由这三个阶段,我们可以发现数据流计算的研究是完整的、系统的、成体系的。它的研究重点经历了由计算理论、到软件技术、到硬件芯片的变化。
本文首先回溯数据流计算的起源,介绍数据流计算的概念,包括第一个具有重要意义的数据流计算语言、数据流计算机模型,静/动态数据流以及重要的数据流计算理论。然后,从软件系统和硬件架构两方面分别介绍了标志性的里程碑工作。最后,根据数据流计算的研究进展,总结并讨论了数据流计算的趋势和挑战,对未来数据流计算的研究提供参考,希望给该领域的研究人员带来一定的启发。
1 数据流计算的起源
数据流计算模型是冯·诺依曼模型的一种替代方案。在冯·诺依曼模型的概念中,数据只是被加工的对象,其核心思想是把程序像数据一样存储在计算机中,在程序计数器(Program Counter, PC)的控制下逐条执行。数据流计算把冯·诺依曼计算机中程序和数据的关系颠倒过来了,数据相关性形成的数据流图就是可执行的机器指令,取消了程序计数器的概念。数据流计算突出了数据的主导作用,这是其对传统计算机架构的重大突破。
“数据流”作为一种计算机并行性探索的概念,使用数据流来表示计算机程序最早出现在20 世纪60年代[3-4],数据流计算语言[5-7]、数据流计算机体系结构[6,8]的早期研究在20 世纪70年代开始展开,本文把数据流计算模型简称为数据流计算。在数据流计算中,程序用数据流图(Dataflow Graph, DG)来表示,数据流图是一个有向图,由不同类型的节点(node, 也称actor[5,7,9-10])和连接节点的边组成。如果边的一端不连接任何节点,则为输入/输出。节点表示计算过程,连接关系表示节点之间的数据依赖关系,该依赖关系可以定义为数据的“生产者”与“消费者”。当数据流图中的一个节点获取了其需要的所有操作数时,即可被调度执行,结果传递给其下游“消费者”节点。与冯·诺依曼计算机相比,数据流计算以图的形式描述了计算任务的并发执行全过程, 同时数据可以按照数据流图中边的指向直接传递到下游节点,不需要缓存到存储器中,能够解决控制流指令串行以及访存瓶颈等问题,充分挖掘并利用计算机程序中数据级并行性和指令级并行性。
图2 是文献[5]中的一个由数据流思想表示程序片段的例子。在这个示例中,长方形的节点表示操作,小的实心圆表示连接,大的实心圆表示程序初始时的配置或者输入数据。程序由L1 和L2 开始,L1 被激活(fire)时,将数据a 复制并发送到A1 和A3,L2 被激活时,将数据b 传递至A1 和A4。L1和L2 节点以任意顺序被激活之后,A1 节点即可激活,因为A1 节点已经获得了所需的2 个源操作数。当A1 的计算完成之后,L3 节点即可被激活,程序将按照“数据驱动”的方式执行。节点的激活仅由该节点所有的输入决定,因此可以降低同步的开销。
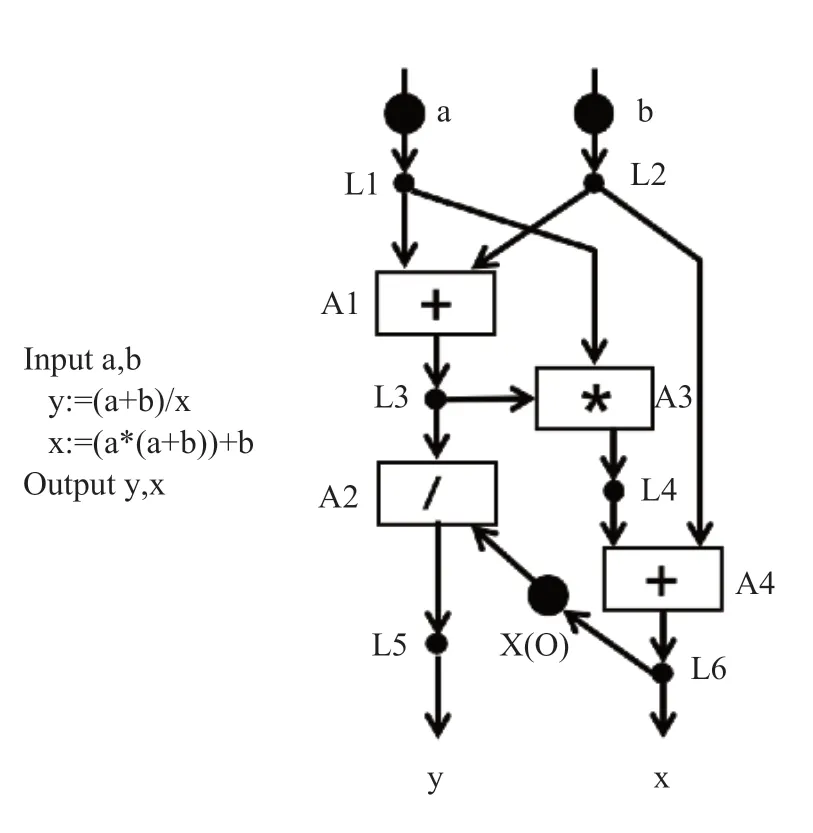
图2 第一个数据流程序表示Fig.2 The first dataflow program
为使上述数据流语言能表示分支和循环程序,Dennis[5]定义了2 种连接原语和6 种不同的节点原语,完善了数据流计算语言。数据连接(Data link)负责传递参与运算的数据,而控制连接(control link)传输为“真”或“假”的令牌(token),该令牌由专门的生成器(Decider)生成,生成器根据其输入的值得到对应的令牌。另外,令牌的另一种产生方法是使用图3(8)的布尔运算单元生成。令牌与T-gate、F-gate、Merge 一起控制数据的流向。对于T-gate,当其输入的令牌为真时,将输入边的数据直接传递给输出边;当输入的令牌为假时,输出边将没有数据。相似的,当输入的控制表示为假时,F-gate 将输入边的数据传递给输出边。Merge有三个不同的输入,一个令牌、另外两个分别与T 和F 端口相连的输入,Merge 原语根据控制表示的值,将T/F 端的输入传递给输出端口。使用上述数据流计算语言,即可表示计算机中的循环和分支程序。
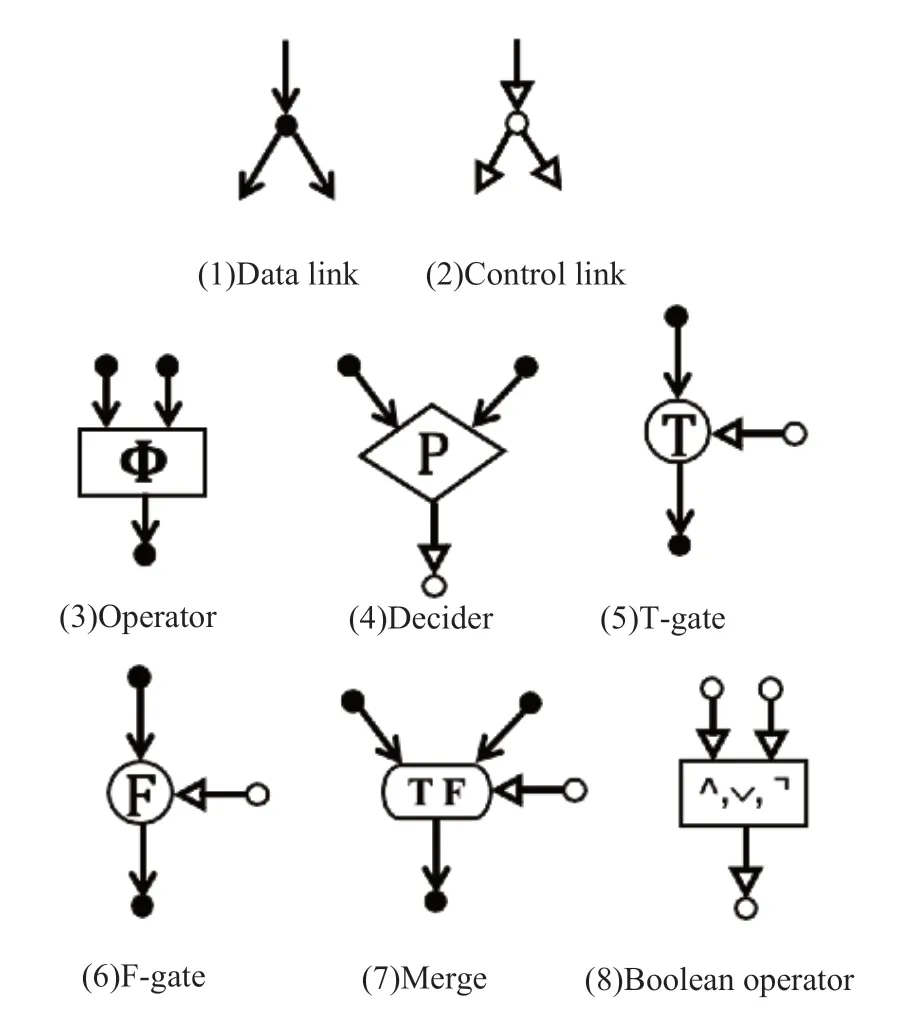
图3 第一个数据流语言Fig.3 The first dataflow programming language
为支持数据流程序执行模型和数据流语言,Dennis[5]等提出了图4 的数据流处理器模型,基本思想是将数据流图转换为一种本质上同构但更适合在实际硬件上执行的结构。在该模型中,存储器被划分多个基本块(Cell block),每个基本块存储数据流图中的一个节点,也就是一个指令。当基本块包含了一条指令及其操作数,仲裁网络(Arbitration Network)便将其打包为运算包(operation packets)的形式发送给运算单元(operation unit)进行计算。运算结束后,分配网络(Distribution Network)将计算得到的结果(data packets)根据地址送回对应的寄存器,此次计算结束后,一个或多个基本块将被激活。另外,Dennis 增加了多层存储的概念,将基本块视为cache,为数据流处理器增加了指令存储和访存网络。由于数据流图的主要特征是节点的参数在各条边上流动,所以类似于 Dennis 架构的机器也被称为 Argument-flow 机器。Dennis 等人开创了数据流研究的先河,在学术界引起了数据流计算的研究热潮,对编程模型[11-15]、计算机体系结构[14-15]、应用程序[16,18]和系统软件[15,17]都产生了深远的影响。

图4 第一个数据流计算机模型Fig.4 The first abstract model of dataflow computer
Argument-flow 机器的一个缺点是需要过多访问存储空间和进行操作数复制,Argument-fetch[19]数据流机器的提出正是为了解决这一问题,该架构与数据流图的直接实现的不同之处在于,指令从存储器或寄存器中获取数据,而不是让指令将操作数(Token)存入后续指令的“操作数接收器”中。在 Argument-fetch 机器中,数据值未附加到特定指令单元,可以存储在任何位置。这意味着指令单元必须包含对那些位置的引用。数据不再从一个指令单元“流”到另一个指令单元,流动的只有信号。而且设计了执行指令单元程序的 PE(Processing Element)结构,以及PE 内部的 4 级流水结构。此后,针对数据流计算机性能的研究也相继展开。一部分研究聚焦在程序的性能与数据流图的关系,比如对数据流图进行流水来探索并行度[20-22],文献[20]证明了一个平衡的数据流图可以最大流水;另一部分着力于探索程序性能与数据流图到硬件结构的映射方式之间的关系[23-24],寻找最优调度和缓冲分配是一个NP完全问题。
基于Argument-flow 和Argument-fetch 模型的数据流计算架构被大量提出[19-25],这些架构可分为两类:静态数据流和动态数据流。在静态数据流架构中,连接指令之间的边仅能承载一个从源指令给出的令牌,且任何时刻对一个节点而言,只能有一个该节点的实例(instance)在执行。通信路径不具有缓冲功能,在输入数据就绪且输出通道未被占有时,操作可以触发执行,否则输出路径的阻塞将会延迟操作执行。静态数据流同一时刻只允许执行一个线程。
在动态数据流架构中,标签实际上与令牌关联,以便可以区分与一个节点的不同实例相对应的令牌。这使得一条边能够同时携带多个令牌,通信路径具有的缓冲功能可以减少输出端阻塞带来的影响。同时,它使用唯一的标签来标记区分不同线程的数据,允许多个线程同时执行,当操作数就绪且数据的标签匹配后,操作可以被触发执行,从而表达出更多的并行性。
对于数据流计算架构的分类,还有许多其他方法。比如根据数据流图中节点的指令数,可以分为粗粒度数据流和细粒度数据流。细粒度数据流中,数据流图的每个节点表示一条指令,比如Argumentflow 机器[19]、SPU[26]。当程序变得复杂、执行部件规模变大之后,细粒度的映射、调度的开销和设计复杂性增加,因此,粗粒度数据流结构出现,在粗粒度数据流中,数据流图的节点表示一段指令,如Codelet 模型[18]、RISC-NN[27]。
类比Flynn 的分类方法,数据流架构还可分为单图单数据(SGSD)模型、单图多数据(SGMD)模型、多图多数据(MGMD)模型。单图单数据(SGSD)模型指的是在单个数据集上执行单个数据流图的计算,例如Argument-flow 机器。单图多数据(SGMD)模型指的是在空间分布的多个数据集上执行单个数据流图的计算,该模型多用于向量计算应用和流式计算应用,比如数字信号处理[28]。多图多数据(MGMD)模型指的是在多个数据集上执行多个数据流图(来自于多个或者同一任务)的计算。例如Wavescalar[29],它采用具有匹配功能的FIFO 作为PE 之间的异步通信通道,MGMD 模型主要利用线程级并行。
数据流计算是一个宏大的概念,不但涉及底层的芯片设计,还包括数据流语言、编译和系统结构设计,其突出的优点是并行性高、同步开销低、访存开销低、片上逻辑简单。控制流计算机有些改进方法也吸取了数据流计算的思想,因此出现了一些Dataflow-inspired 或 Dataflow-like 技术,其中最容易混淆的是流式计算(Stream processing)[30-31]。流式计算是将应用中的计算和数据分离,重新组成一条流水线型的计算链,通过开发多个层次上的并行性和充分利用各级存储层次的局部性,得到较高的计算性能。所谓流式计算实际上是指无边界的连续数据的处理,它仍然是控制流计算,不是基于数据流模型,而是源于Hoare 的CSP 计算模型[32]。
有一些计算技术与数据流计算有一些相似性。Google TPU[33]处理器的成功使得上世纪80年代提出的脉动阵列(Systolic array)[34]获得新生。脉动阵列虽然不是典型的数据流计算机,不具有数据流计算的通用性,但可以认为是数据驱动的计算。
2 数据流计算的研究
数据流计算的研究涵盖了计算机科学的方方面面,数据流计算从理论、软件系统到硬件架构的生态是完整的,但是各层次的技术发展是不平衡的。例如,直到近十年,才设计并实现了数据流的芯片;自Codelet 执行模型提出后,数据流的程序执行模型没有得到新的突破和创新。
数据流计算的生态缺少标准化、统一化的定义。例如,至今没有统一的数据流计算机软/硬件接口定义,每款数据流芯片都有自己的数据流指令、编译器,使得许多数据流芯片或者编译器不能兼容其他数据流工作,这是数据流生态与X86、ARM 生态的重要区别和弊端,这也是阻碍数据流计算机走向商用和通用的一个重要因素。数据流计算的研究缺少开放式联盟、社区等组织的存在。
经过多年的研究,数据流计算已不是与传统冯氏架构对立的存在。很多研究工作将两者结合,做出了将数据流和控制流协同设计的创新性工作,以及数据流与脉动阵列融合的工作。
本节将对数据流计算的重要研究成果进行介绍,将从数据流软件栈和数据流计算系统/芯片两个方面展开介绍和讨论。表1 是数据流计算具有代表性的研究成果。
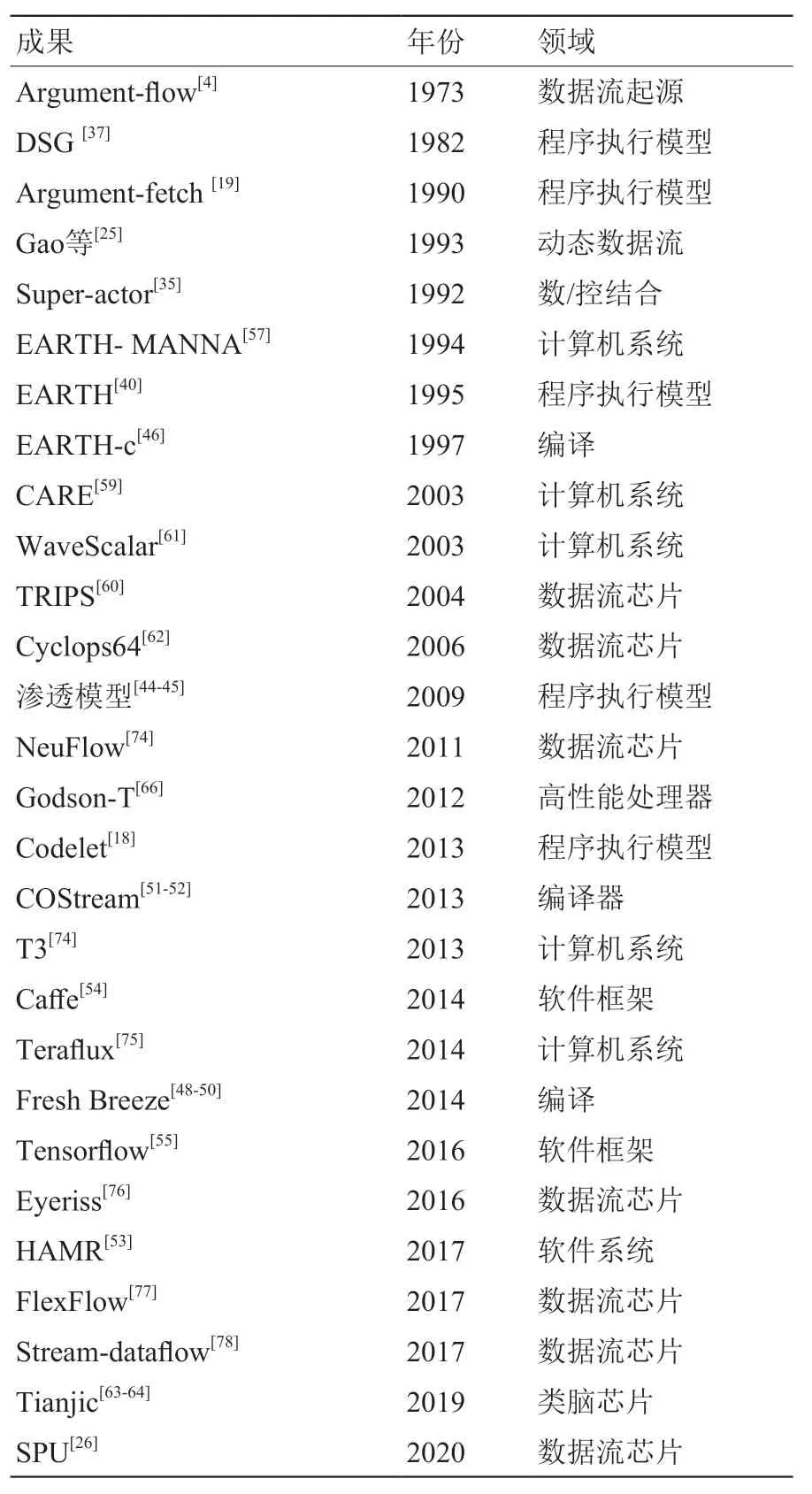
表1 数据流计算代表性研究成果Table 1 Representative works of dataflow computing
2.1 软件系统研究进展
本节将总结介绍数据流计算在软件上的具有标志性的研究发展,包括编译系统、程序模型、运行时系统以及编程语言。
纯数据流图的操作模型可以很容易地扩展以支持冯·诺依曼风格的程序执行[35-36]。数据流图中的一个 actor 的集合可以组装成一个线程,该线程在自己的私有程序计数器的控制下顺序执行,而线程的激活和同步是数据驱动的。新的混合模型灵活地结合了数据流和控制流,以及在理想的级别上利用并行性。
很多工作对argument-flow 和argument-fetch 数据流原理进行了扩展。一条指令完成之后将发布一个事件(Event)(称为信号)来通知依赖于该指令结果的其他指令,这实现了一种改进的数据流计算模型,称为数据流信号图(Dataflow Signal Graphs)[37]。该架构通过数据流软件流水线来支持高效的循环执行,以及对线程功能的激活,结合了静态和动态数据流模型的优点来定义线程模型。
基于数据流信号图模型,高光荣教授等人提出了 EARTH(Efficient Architecture for Running Threads)模型[38-39]。纯数据流模型的编程模型是基于语义模型的,在该语义模型中,执行任何操作都不会产生其他影响。EARTH 超越了纯粹的数据流模型,对single assignment[40]样式进行了扩展,使得在相同线程中的写入操作可以被视为对内存的普通“更新”。线程之间的数据流式的同步确保了数据的生产者和消费者的依赖顺序是正确的。在EARTH 模型的发展和实现的过程中,位置一致性(Location Consistency, LC)[41-43]作为顺序一致性衍生的模型也取得 进展。
上述的执行模型都会遇到扩展性问题,即随着计算机群规模扩展,难以保证代码实际运行性能达到计算机的理论计算峰值,因此,文献[18]提出了基于代码段的程序执行模型 Codelet。代码段指机器指令的集合, 当以一个代码段的所有依赖项 (数据和资源需求) 都得到满足时就可以执行了,并作为处理器计算单元的最小资源调度单位。换句话说,”代码段” 是Codelet 执行模型中最小且不可分的调度量。一个代码段一旦被调度至一个计算单元并开始运行后, 这个计算单元将长时间被此代码段独占, 且不会被其他机器指令抢占。针对Codelet 这种非抢占式计算功能, 计算机体系结构和软件系统需要提供配套的功能支持并由此提高计算资源的利用率。Codelet 模型明确了代码段与线程的关系,支持弹性的粒度大小。同时强调在多核、众核系统中,运行时环境应该与操作系统有更明确的分工,操作系统负责基本的硬件管理,而运行时环境应该成为更为重要的角色,负责多核、众核上的任务调度、内存管理、负载平衡等。
为了缓解日益加剧的“存储墙”对高性能算法在多核和众核体系结构上执行性能的影响,基于数据流的渗透模型(Percolation Model)[44-45]被提出。渗透模型利用众核体系结构存在的并行为计算操作提供数据访问的局部性,是一种高度融合并行性和局部性的延迟容忍的性能优化技术。渗透模型要求对算法中的计算和访存操作分离。通过解耦计算和访存,并行算法可以:(1)通过访存任务和计算任务之间的多级流水隐藏存储访问的开销;(2)组织和分配不同的访存任务来适应存储层次结构中的不同访问延迟。
数据流程序编译器也取得了明显进展,EARTH- C[46]、Fresh Breeze[47-50]、COStream[17,51-52]是 典 型 代表。文献[46]基于EARTH 模型设计了EARTH- C编译器,该编译器能够从一个C 语言程序开始,编译生成一个并行的数据流线程程序。EARTH-C 编译器可以分为三个主要阶段:第一阶段由标准 McCAT 的转换和分析组成;第二阶段,对循环进行重组和转换,以便利用函数/线程级别的并行性;第三阶段将程序分割到适当的线程中,然后生成目标代码。Fresh Breeze 编译器会对 funJava 程序的每个方法 (函数)进行逐一编译, 以生成实现该方法的一组代码段(Codelet 模型)。Fresh Breeze 编译器的编译过程包括三个部分。第一步是将funJava 的方法 (函数) 转换为数据流图,以表示该方法所包含的计算过程;第二步是对源代码中的每种方法 (函数) 的各个循环迭代语句,派生出一组与之对应的并行执行的代码段;最后构建最佳机器代码, 以实现每个代码段。COStream 是一种面向数据流编程的编程语言与编译系统。目标语言根据目标结构不同生成不同底层语言,如C、C++(在x86 平台上执行)和OpenCL(在GPU 上执行)以及 Javascript(在跨平台的浏览器中执行)等,编译器通过调用底层语言编译器生成对应目标平台的可执行文件。它实现了对数据流图最基本的抽象,方便数据流程序的编写。
许多程序框架、代码库也受到数据流思想的启发。HAMR[53]实现了一个基于数据流的分布式大数据系统,同时支持批处理和流处理。 HAMR 完全基于内存计算而设计,以减少不必要的磁盘访问开销;任务调度和内存管理以细粒度的方式探索更多的并行性;异步执行可以提高计算资源使用效率,还可以使整个集群的工作负载平衡更好。MapReduce 编程模型源于函数式编程语言和 MPI/OpenMP 等并行框架,而HAMR 基于数据流编程模型 Codelet。早期的深度学习框架如Caffe[54]已经使用 DAG 数据流图来表示算法,其中的点由不同层(如卷积等)构成。Tensorflow[55]的数据流图中的节点表示操作,可以是乘法、加法等底层计算,以便于灵活高效的组织算法。尽管上述工作并非完整的数据流系统,但充分体现了数据流作为一种可靠、简单且功能强大的并行计算模型,由于其独特价值,不断在新的应用场景中体现。
2.2 数据流系统和芯片研究进展
本节介绍具有代表性的数据流硬件系统和数据流芯片的研究进展。
数据流计算模式提出后,早期被应用到EARTH[38]中。EARTH 抽象机由通过网络连接的EARTH节点组成。图5展示了EARTH抽象机的结构,每个节点都有以下五个基本组件:执行单元(EU)、同步单元(SU)、两个队列(RQ 和EQ)、本地存储和网络接口。同步单元用于调度和同步线程,以及处理远程访问,EU 和SU 通过两个队列进行通信,EU 和SU 共享本地内存。最初,EARTH 是一个抽象机,并非具体实现的计算机系统,其最初是在模拟平台上实现的,但是,加上EARTH-c 编译器的配合,使得EARTH 成为了一个完整的、具有里程碑意义的单核数据流计算机系统模型。
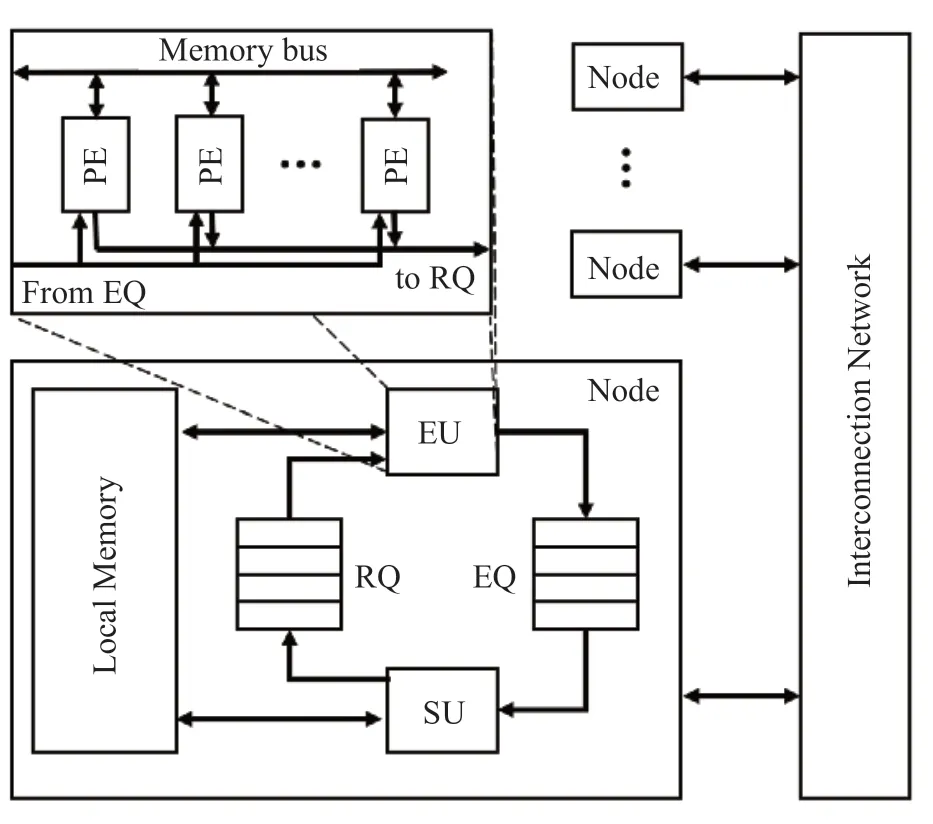
图5 EARTH 抽象机模型Fig.5 Abstract model of the EARTH
MANNA 2.0 是90年代早期在德国柏林的 GMD-FIRST 平台上开发的用于非数值和数值应用的大规模并行架构[56],Hum 等人在MANNA 上搭建了EARTH-MANNA[57]系统,是EARTH 抽象机的第一个具体实现。该系统的一个节点包含了2 个50MHz 的Intel i860XP RISC 处理器[58],每个处理器有16KB 的片上数据缓存和 16K 的指令缓存。这两个处理器在一个公共总线上共享 32MB 的DRAM,并使用总线监听和 MESI 协议保持内存保持一致性。EARTH- MANNA 一方面是基于数据流原理的多线程系统,更重要的意义是证明了数据流系统可以使用现成的处理器有效地实现。
CARE[59]的独特之处在于其混合了数据流架构和冯·诺依曼架构,CARE 体系结构及其处理器核心如图6 所示。处理器核心按照其流水线阶段划分为获取单元、解码器单元、分发/发布单元、缓冲区,然后是功能单元(FUs),最后是写回单元。处理器核心其实是一个乱序执行引擎和一个乱序的发射单元,允许多个线程竞争解码时间,没有提交单元来对指令进行排序,编译器和组成机构之间的协议保证了相关指令之间不会存在控制冲突和内存冲突。一方面,CARE 非常适合支持多线程多处理器执行;另一方面, CARE 的体系结构模型还可以通过增加“调度基本量”来更好地利用调度窗口,同时避免了过高的复杂性。
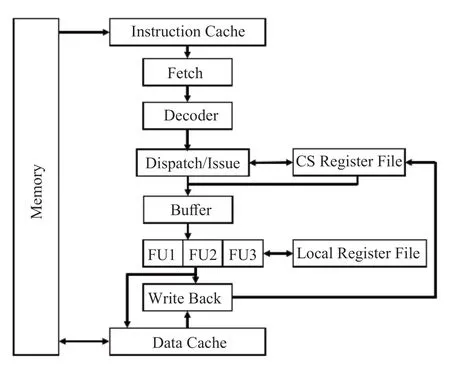
图6 CARE 架构及其流水线Fig.6 The architecture of CARE and its pipeline
TRIPS[60]架构由德克萨斯大学奥斯汀分校的Madhu Saravana Sibi Govindan 等人开发研制。TRIPS提出背景是计算机体系结构的研究转向了多核架构,多核架构的挑战在于如何编程,多核程序的设计比单核程序设计要复杂。TRIPS 的设计目标是首先通过指令级并行提高单线程的性能,其设计了具有显式的数据流图执行 (EDGE) 指令集,在多个粒度探索程序的并行性,最后,TRIPS 探索了可扩展的多核数据流架构。图7 是TRIPS 的结构组成,TRIPS 架构也是目前数据流架构、CGRA、AI 芯片的重要参考对象。
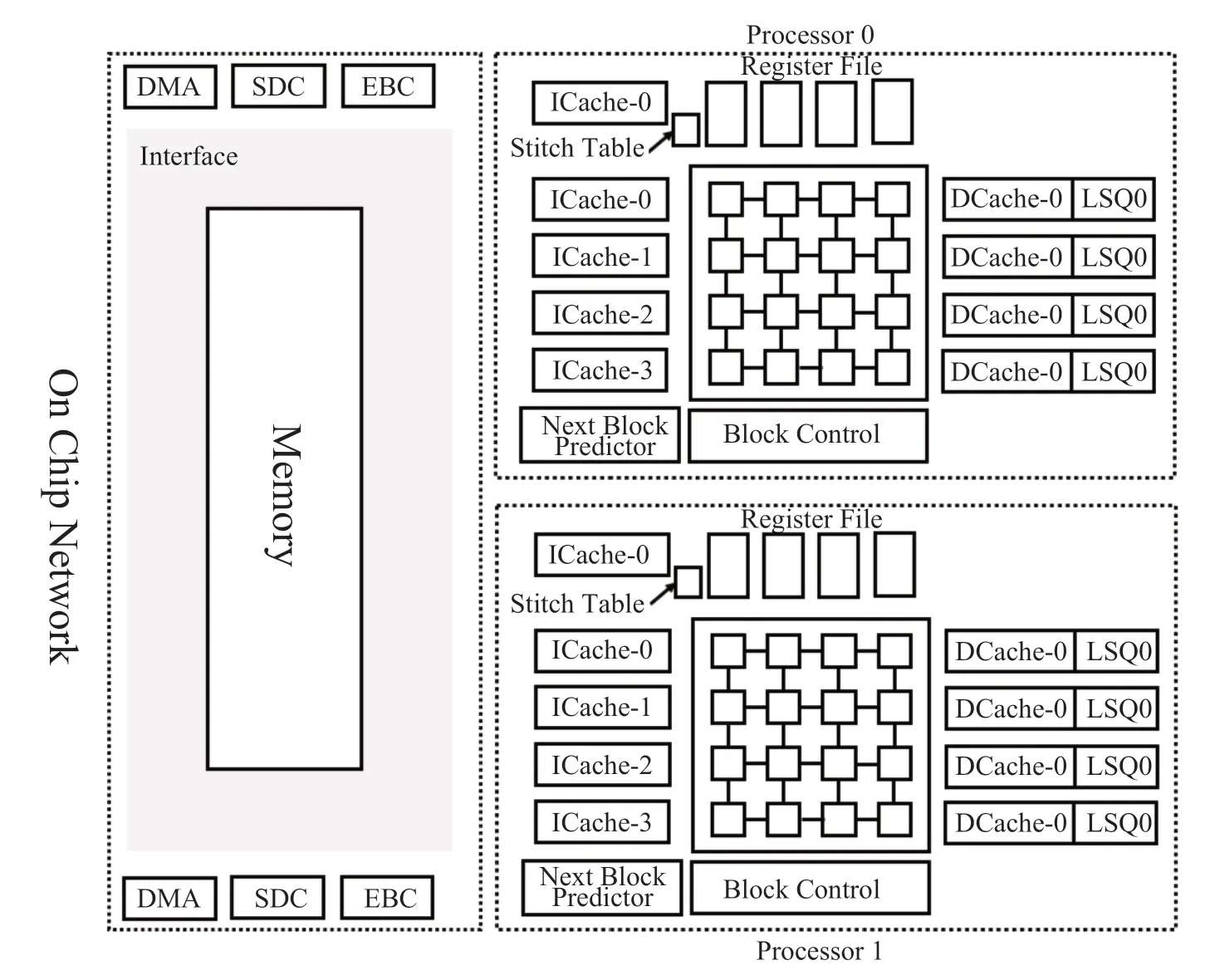
图7 TRIPS 架构Fig.7 The architecture of TRIPS
WaveScalar[61]是一种基于 Cluster 的可扩展的数据流结构。WaveScalar 的基本组成部分为 Cluster。整个处理器可以由任意个Cluster 组成,并通过二维网络互连。每个 Cluster 是一个完整的简单的处理单元,这种分块组织方式能使设计快速收敛并且降低验证需要的开销。同时,这种组织方式能在非集中控制下完成计算,每个 Cluster 独立完成自己的运算,能降低网络传输延迟。 Wave Scalar 以动态的方式将指令映射到执行阵列中,将相互依赖的指令映射到相邻或者相同 PE 上,以降低操作数的传递延迟;没有依赖的指令映射到不同 PE 上,以挖掘指令的并行性。
IBM 的“蓝色基因”项目构建了一系列超级计算机, 包括分阶段实施的两类不同的体系结构:BlueGene 和Cyclops64,其中,后者Cyclops64[62]采用了数据流计算思想,提出了程序执行模型感知的线程虚拟机 (Thread Virtual Machine, TVM),通过用户级程序直接管理硬件资源,设计开发了微线程库TNT(Tiny Threads),这影响了后来的NVIDIA 的CUDA 编程模型。
Tianjic 芯片[63-64]是第一款融合支持基于计算机科学的人工神经网络与受神经科学启发的类脑模型(主要是 SNN)的人工智能芯片,该芯片采用了多核结构、可重构计算模块和数据流驱动的计算方式,并采用了混合的信息编码方案,既能适应基于计算机科学的机器学习算法,又能方便地实现脑启发网络和多种编码方案。
REVEL[65]面向具有规约特性的矩阵运算,设计了一款脉动阵列和数据流计算相结合的芯片。该工作解决了数据流架构只能并行化内部循环(innerloop)的问题,设计了一种称为归纳数据流的执行模型,它从以下两个方面扩展了传统的数据流模型:定义了规约依赖模式和规约访存模式。该工作充分结合了脉动阵列的高效性和数据流架构的灵活性。
国内的中国科学院计算技术研究所高通量团队最早于2005年开始了众核数据流处理器的研究,目前为止已成功研发了多款数据流芯片,其中最具有代表性的有Godson-T 处理器、SPU 和DPU 芯片。
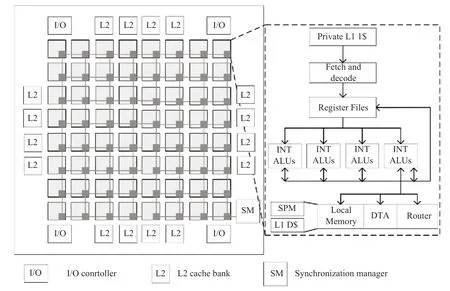
图8 Godson-T 架构Fig.8 The architecture of Godson-T
2009年成功流片的Godson-T[66]处理器系统受到数据流思想启发,抛弃基于目录的cache 一致性,采用基于锁的弱一致性作为片上存储模型。此外,Godson-T 支持数据流的细粒度同步指令操作,针对Cholesky 分解、LU 分解等细粒度通信频繁的应用取得了很好的并行效果。
SPU[26]是一款面向科学计算的数据流加速器,项目启动于2013年。SPU 处理器采用细粒度数据流执行模型,由一个RISC 处理核、一个 DMA 控制器和一个数据流加速部件组成。RISC 核和数据流加速器之间采用主核-加速器的工作模式。SPU 从图内并行(inner-graph)、流水线并行(pipeline)和图间并行(inter graph)三个层次挖掘程序的并行性,提高了功能部件的利用率。此外,基于SPU 还展开了许多数据流相关的研究工作[67-73]。
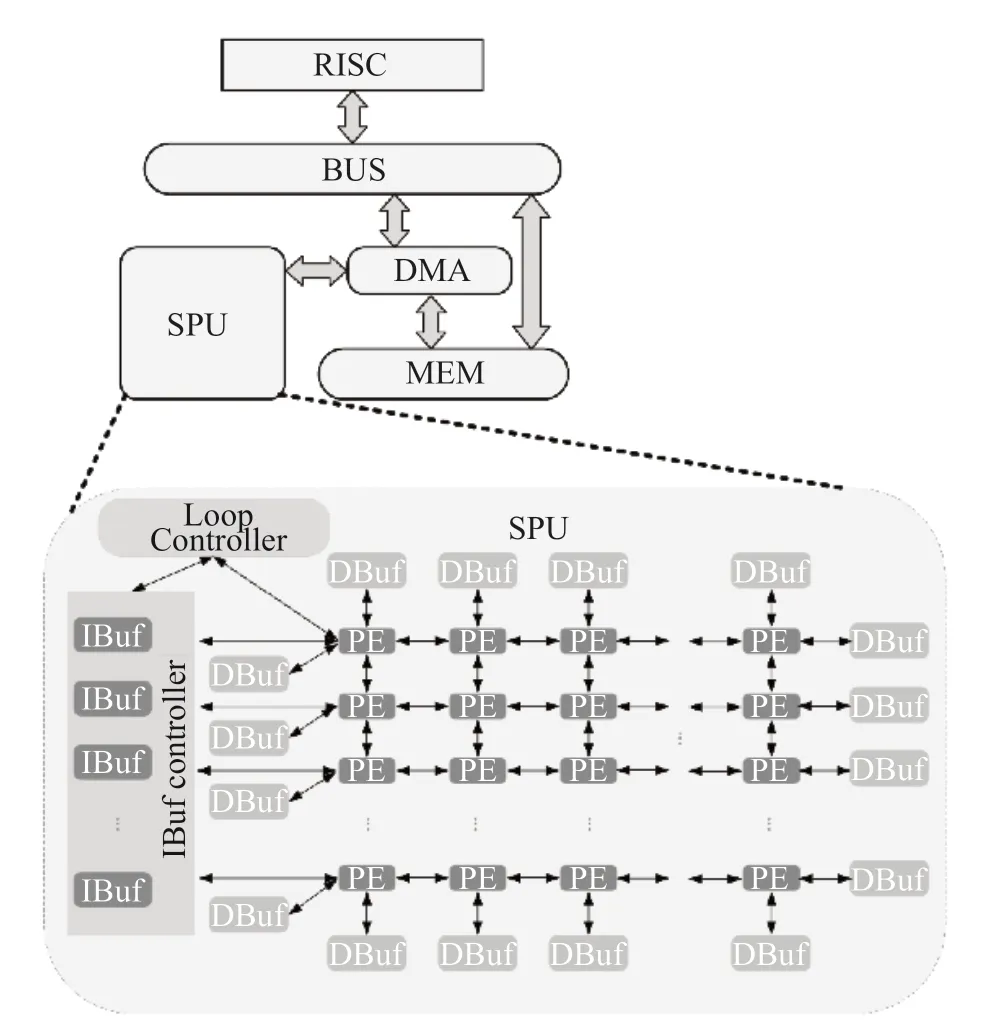
图9 SPU 架构Fig.9 The architecture of SPU

图10 DPU 架构Fig.10 The architecture of DPU
2011年高通量团队启动DPU 系列数据流处理器芯片的研发,并于2013年成功流片面向高通量音视频处理领域的DPU-m 芯片,2020年成功流片面向数字信号处理领域的DPU-s 及图处理领域DPU-g 芯片。DPU 系列处理器芯片采用粗粒度数据流执行模型,在通用性/性能/能效等方面进行了良好的设计权衡,在高通量数字信号处理、音视频处理、科学计算、人工智能以及加解密等应用场景都取得良好表现。DPU 在单个处理单元中,对流水线进行了优化设计,充分保障指令 ready 与 fire 的顺畅执行,减少空泡的产生。且通过 SIMD 的结构设计,提高了数据的执行吞吐能力。其次,执行单元规模上进行了合理的设计,保障了合适的数据流动的距离和并发执行能力。
2.3 数据流体系结构优势分析
数据流结构的计算模式与传统控制流完全不同。在传统控制流处理器中,指令按照程序计数器顺序执行,即指令序列规定了发射/提交顺序。但在数据流计算模式中,只要指令所需的操作数准备好了,这条指令即可被执行。在数据流计算中,程序是以数据流图表示的,每条指令的执行结果直接传递到另外一条指令,作为目的指令的操作数,指令与指令之间通过依赖边来建立依赖关系,从而形成数据流图。与传统的控制流结构相比,数据流的优势主要体现在如下四个方面:
(1)并行性高:传统控制流结构在执行过程中虽然也允许乱序执行和多发射执行,但是仍然只能在指令窗口内选取可执行的指令执行,并行度受限;而在数据流结构中程序被完全展开成数据流图的形式,所有指令的执行没有强制顺序,操作数到齐即可发射执行,并没有指令窗口滑动控制执行顺序的需要,所以可以在整体程序范围充分挖掘指令级并行。
(2)同步开销低:控制流结构中,处理器核之间往往通过全局 barrier 实现同步,属于粗粒度的线程级同步;数据流结构中,程序依靠依赖关系进行细粒度的同步,数据流结构指令操作数的单一赋值特性使得多处理器可以在不需要维护集中存储的一致性的前提下完成数据同步。数据流的细粒度较控制流的粗粒度同步能挖掘更多潜在的并行指令,并且不会对片上存储产生额外的负担,同步开销更低。
(3)访存开销低:数据流结构采用指令与操作数空间绑定的形式,将计算与存储结合,分散式存储,降低对于集中存储的访问压力,数据直接在操作数存储间传递,不需要进行频繁的访存,也不需要将中间的结果在更低的存储层次中反复存取。数据一旦进入片上处理阵列后,产生的中间结果便在处理节点之间按照数据流图的依赖关系流动,直到结果产生,再存入低一级的存储中。
(4)片上逻辑简单:数据流结构直接利用指令级并行充分发挥功能部件的执行效率,省去控制流复杂的并行设计;分支结构由控制依赖转换成数据依赖,无需分支预测的支持;指令与对应数据一一对应,不需要重命名寄存器以及复杂的 cache 层次。综上,数据流结构的片上逻辑简单,可以用更少的面积、功耗实现更高的执行性能。
3 数据流计算发展的挑战和趋势
随着网络服务、人工智能、AIoT 等高通量应用场景的不断兴起,应用处理模式和数据类型发生了巨大的变革,传统冯·诺依曼结构正受到“存储墙”等的限制,针对万物互联、海量数据处理的高并发应用场景,越来越难以持续提高其处理能效比。
以深度神经网络为代表的人工智能算法和数据流计算思想在计算本质上高度匹配。近年来,大量面向人工智能算法的数据流芯片被提出[27,67-74,77-78],人工智能应用无疑是数据流计算最有效的催化剂,必将不断催生出崭新的数据流计算架构。而数据流执行模式,凭借其天然的高并发性和数据与计算的耦合性,也有望打破“存储墙”的限制。
尽管数据流具有诸多优点,但数据流计算的发展也不会是一帆风顺的,仍然面临着巨大的挑战,包括:
(1)数据流计算理论研究。数据流计算理论的进展缓慢,数据流计算理论是数据流芯片、数据流计算机等设计研发的指导思想,为数据流计算的发展提供理论支持。数据流计算理论包括数据流程序执行模型、数据流图优化、数据流图调度/映射方法、线程模型、内存模型、同步模型等。
(2)数据流计算架构的可重构性探索。虽然人工智能应用极大地带动了数据流计算的发展,但是人工智能算法的发展速度远快于数据流新架构的开发周期,所以数据流计算架构的可重构性变得极为重要。另外,高通量应用、科学计算、物联网、区块链等应用场景的兴起对数据流架构的可重构性提出了更高的要求。
(3)软件生态开发。数据流计算从诞生以来,一直以学术研究为主,只有少数成功商用的产品。一个非常重要的原因是与数据流计算配套的软件栈开发进程缓慢。数据流软件栈,包括编程语言、操作系统、编译器等,都需要进行进一步的研究。
在未来,数据流计算的研究人员需要从理论研究、架构设计、软件开发各层面互相结合,共同探索,以满足不同的应用需求,以求数据流计算的进一步的完善与发展。
4 总结与展望
本文回溯数据流计算的起源,对数据流计算的理论研究、软/硬件发展进行介绍,总结了数据流体系结构的特点,并指出,未来的数据流计算的发展需要结合理论研究、架构设计、软件开发。
数据流计算对计算机科学和工程研究的许多领域产生了深远影响。这些领域包括:算法设计、编程语言、处理器设计、多线程架构、并行编译、高级逻辑设计、分布式计算、脉动阵列、流处理器、可重构处理器等,随着大数据和人工智能等新兴应用的兴起,数据流计算的优势日益显现,数据流计算的研究也有望迎来一个新的黄金时代。
致谢
仅以此文纪念高光荣教授(1945-2021)。高光荣教授是数据流计算研究的先驱,在他的指导下,国内的数据流计算取得了重要进展。高光荣教授为我国计算机研究发展做出了杰出贡献,曾获得2013年度中国计算机学会(CCF)海外杰出贡献奖。
利益冲突声明
所有作者声明不存在利益冲突关系。
