Apriori算法在保险业中的应用
2010-07-27于燕丽
于燕丽
(1.中国海洋大学 信息科学与工程学院,山东 青岛 266071;2.青岛理工大学琴岛学院 计算机工程系, 山东 青岛 266106)
1 引言
客户作为企业的一种资产,对提高企业竞争力的重要性日益增加。在当前竞争激烈的商业时代,所有公司都纷纷从以产品为中心转向以客户为中心,保险业格外突出。如何找出新客户、失去的客户及老客户尤其是给公司带来最大利润的20%的“黄金客户”各属性间的关联规则[1],同时又能以用户易理解的形式概括出来,这是决策者策划营销产品的关键。保险公司经过多年发展,已积累了大量宝贵的客户数据资源,如何处理这些海量数据,更好地汇总、分析这些历史数据并从中挖掘出业务内在规律,将其变为有用的信息和商机,将会主导未来相当长时间内各个保险公司的工作战略。
数据挖掘(Data Mining,简称 DM),简单的讲就是从大量数据中挖掘或抽取出知识。一个通用的定义是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中提取人们感兴趣的知识,这些知识是隐讳的、事先未知的、潜在有用的信息。[2]
常用的数据挖掘方法有:(1)关联分析。(2)序列模式分析。(3)分类分析。(4)聚类分析。(5)孤立点分析。在这些分类方法中,关联分析方法由于自身的优点而广被使用。
2 数据挖掘在保险公司客户管理中的应用
2.1 Apriori算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法[3]。其核心是基于两阶段频集思想的递推算法。该算法的基本思想:
2.1.1 找出所有的频繁项集:根据定义,这些项集出现的频繁性至少和预定义的最小支持度一样,即满足Support不小于Minsupport的所有项目子集。
2.1.2 由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。挖掘关联规则的总体性能由第一步决定。
频繁项集的生成原理:从包含每个项的C1中找出1项频繁集的集合L1。然后,连接LK-1产生K项候选集的集合CK,并根据Apriori性质删除那些具有非频繁子集的候选集。最后,扫描数据库一次,统计候选集的支持计数,与最小支持计数相比,形成频繁集。[4]

表1 数据样本
2.2 数据挖掘在某保险公司中的应用
2.2.1 数据预处理
现有某保险公司统计的个人投保数据若干,从中取出10人的三维数据作为解释说明算法应用代表,将这些数据作为抽样数据分析关联规则,以供公司决策层使用。数据见表1。
在表1中编号表示投保人保单号的唯一标识。insurance表示该保险公司的个人保险的类型:A(养老保险类),B(意外伤害保险类),C(未成年保险类)。
age和income为连续数值型数据,对其进行离散化、分组:age 分为 a:1-18,b:19-30,c:31-45,d:46-60,e:61-80 共 5 组 ;income 分为 m:1200-6000,n:6000-120000,o:12000-36000,p:36000以上共 4组。A 用 x表示,B用y表示,C用z表示。通过数据预处理转换后得到的数据见表2。
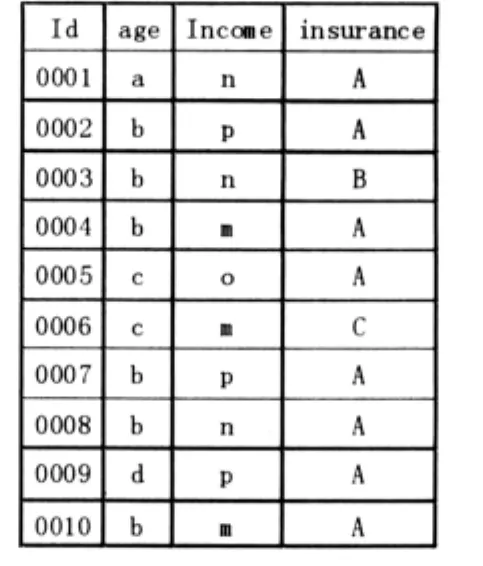
表2 数据预处理后的数据项目集
经过数据预处理之后,将一些对结果影响不大的数据预先清除掉,以便提高算法的效率。
2.2.2 算法的实现:对以上数据进行Apriori算法,求出频繁集,求出置信度。然后由置信度得到年龄、收入、险种之间的关联关系。因此,当有客户上门时,我们就可以对症下药了。这对企业的工作的展开有很大的推动作用。
表3是算法的核心内容:
2.2.3 算法的结果
进行Apriori算法,得到的结果如图程序运行结果下(图1):
通过算法的运行,我们得到了如上的结果。从图中可以看出,年龄在19岁-30岁、收入在1200元-6000元的客户和年龄在31岁-45岁、收入在6000元-12000元的客户买意外伤害类保险的可能性都是100%。当然,通过运用Apriori算法,我们还会得到其他类似的关联关系,这些都对企业的决策有着重要的指导作用。

表3

图1 程序运行结果
3 结束语
本文在一个有1000条记录的客户数据集上测试了该算法。 所以对于这一数据集来说,该方法的结果还是有实用价值的。如果有规模更大的企业,它的客户记录应该更多,这样用更多的数据训练可能会提高该方法的准确性。
[1]罗华等.数据挖掘与数据仓库技术及其在保险业中的应用.微计算机信息 2004
[2]陈京民.数据仓库与数据挖掘技术[M].电子工业出版社,2002.8
[3]洪玉峰,汤静煜.数据挖掘技术及工具发展和应用.北京统计,2004.12
[4]邵峰晶、于忠清.数据挖掘原理与算法[M];中国水利水电出版社;2007.6
