浅谈搜索引擎的体系结构与索引技术
2010-07-27徐舒
徐舒
(杭州师范大学钱江学院 电气机械工程系 计算机科学与技术专业,浙江 杭州 310012)
1 搜索引擎的分类
1.1 目录式搜索引擎
目录式搜索引擎(也称分类式搜索引擎)主要通过人工发现信息,由编辑人员根据信息资源的内容按一定的主题进行分类组织,并形成信息摘要,将信息置于事先确定的分类框架中,组织成一层一层的分类目录,目录下面有更具体的子目录。信息的类别也由大到小、由粗到细,整个搜索引擎形成了一个层次型的类别目录。用户可以逐层浏览,选择不同的主题对网络信息进行过滤,所选择的主题类别越小,信息的相关性就越高,用户就越有可能找到自己所需要的信息。这类搜索引擎的性能主要取决于对所获取网页的人工归类或自动分类算法的精确度如何。其代表有:Yahoo,LookSmart,Open,Directory,GoGuide等。例如,中文雅虎(Yahoo)有14个一级目录,最深有6级子目录,其使用的是手工录入方式得到Web页面摘要信息,而非全页面内容信息。其形成的具体方式是:首先维护人员对新Web站点进行浏览,然后对浏览内容进行内容提取,并形成摘要信息和关键字,最后将这些信息分类进行存储。由于Yahoo的普及程度非常高,因此现在Yahoo系统的维护人员不再需要到Internet上去寻找新Web站点,而是由新Web站点的发布者主动通过页面提交本站点的有关信息,系统的维护人员只需要对这些提交的信息进行归类存储,然后对外发布公开。
Yahoo给用户提供了两种查询方式:漫游查询和关键词自动搜索。漫游查询即用户利用浏览器在Yahoo的Web页面上按主题目录进行逐层深入地查找所需要的内容信息。关键词自动搜索方式是系统根据用户提交的查询关键词,自动对目录树结构进行搜索查找,返回符合条件的结果集。目录式搜索引擎的突出特点是具有比较好的信息质量,但由于采用手工进行Web页面信息的获取和维护,所以存在以下不足:信息覆盖率低,信息实时更新不够及时,目录维护耗费的人力资源大;基于关键词而非全文进行查询,可能在查询时造成某些相关信息的遗漏;采用漫游查询方式的效率不高,并且由于目录查询树结构的不断增大,查询某一特定主题的代价和时间开销会越来越大。
为了解决目录式搜索引擎存在的问题,人们引入了人工智能技术,用机器人(也称之为Robot,Spider,Wanderer,Worm)代替手工去发现、加工、整理信息,这样就出现了机器人搜索引擎。
1.2 机器人搜索引擎
为了解决目录式搜索引擎存在的问题人们引入了人工智能技术用机器人代替手工去发现加工整理信息这样就出现了机器人搜索引擎,机器人搜索引擎不需要人工收集信息而是由一个被称作"机器人"的计算机程序在网络上不停地爬行和搜索,依据一定的网络协议在Internet中自动获取网页信息并通过对网页内容和特征的分析采用一定的策略组织信息并建立自己的索引数据库为用户提供查询务。HotBot,InfoSeek,Google,Excite、天网等就是这类检索系统的典型代表。
1.3 元搜索引擎
由于单个搜索引擎的覆盖范围往往不会太广,为了找到自己所需要的信息,用户常常需要使用多个搜索引擎,以期望找到更多、更全、更准确的信息。但由于不同的搜索引擎在其查询语法以及接口界面上往往不同,需要用户重新学习和适应不同的检索方法,这给用户使用多个搜索引擎带来了极大的不便。为了解决这个问题,研究人员开发了元搜索引擎。元搜索引擎统一了不同搜索引擎的查询接口,由统一的元搜索引擎接口对用户提交的查询请求进行处理,分别将其转换为符合底层搜索引擎查询语法要求的子查询,同时向多个搜索引擎提交查询的结果,由底层搜索引擎在各自的索引数据库中进行查询。在各个搜索引擎返回检索结果后,元搜索引擎将子查询结果进行汇总、去重、重新排序等处理,最后向用户返回最终的检索结果。元搜索引擎系统一般都没有自己的索引数据库,而是以一个代理的角色,利用其它搜索引擎的数据库来进行服务。在层次上,元搜索引擎要比机器人搜索引擎和目录式搜索引擎要高。元搜索引擎系统的底层搜索引擎可以是机器人搜索引擎,也可以是目录式搜索引擎。元搜索引擎的优点是返回结果的信息量更大、更全,其查全率较高,解决了单个搜索引擎覆盖范围相对狭窄的局限,缺点是不能够充分利用下层搜索引擎的排序功能,用户需要做更多的筛选。这类搜索引擎的代表是MetaCrawler,SawyScarch,InfoMarket等。
2 搜索引擎的工作原理和体系结构
2.1 搜索引擎的工作原理
以机器人搜索引擎为例。机器人搜索引擎的工作过程分为三大步:一是在网上发现信息,如www网页、Newsgroup文章、FTP文件等等;二是把发现的信息收集到本地,经过信息分类和索引等加工处理把信息存储在本地数据库;三是提供服务,即通过相应的算法和接口在本地数据库中查找到信息,并以一定的形式返回给用户。搜索引攀主要由三个模块组成,分别为搜集模块,预处理模块和服务模块。搜索引擎三段式工作流程如图1所示:
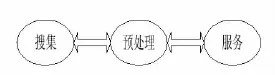
图1 搜索引擎三段式工作流程
其中搜集模块即为网页搜集,由网络爬取器自动完成。预处理是对抓取到的原始网页数据进行索引处理,获得索引数据库。服务指的就是检索系统,为用户提供查询服务。
2.2 搜索引擎的体系结构
由图2可知,搜索引擎主要由搜集器,索引器,检索器,日志分析器组成。搜索引擎先由搜集器到网上搜集网页原始数据,然后由索引器对原始数据进行处理,建立索引数据库,最后由检索系统向用户提供查询服务。这其中还有日志分析器对过程进行记录,便于日后对用户行为进行分析,获得有用信息,有助于改进系统。
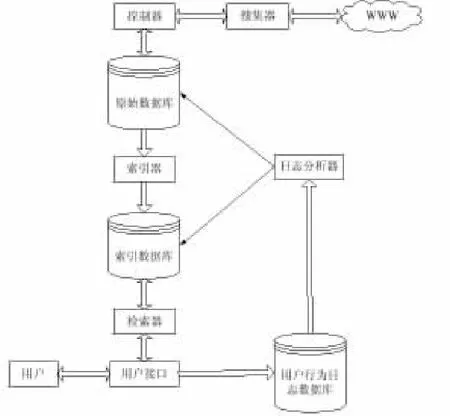
图2 搜索引擎体系结构
3 搜索引擎索引技术
信息索引就是从已发现的网页中提取一些特征,以便用户很容易地检索到所需的信息。即通过一定的方法产生一个索引项集合来作为一篇文档或查询请求的内部表示。
索引的方法主要分为两种:一种基于关键词的索引;另一种是基于概念的索引。第一种是大多数搜索引擎使用的方法,是从文档中提取重要的词作索引。在文档中顶部出现的词以及在整个文档中出现多次的词可以认为是比较重要的。第二种方法与前种不同之处在于试着了解语义,用一个词能代表许多意义相近的词,这样既节省了索引空间,也为检索时可返回有关主题的所有文档,甚至这些文档中的词与检索词并不精确匹配。Excite是当前网络中比较著名的基于概念检索的搜索引擎。本文中仅介绍基于关键词的全文索引,也就是对每篇文档全文提取关键词进行索引。建立索引需要进行两方面的技术处理:关键词的提取,建立倒排文档索引。
分词就是从每个页面文档中提取一定数量的关键词或者知识。为了提取关键词或知识,必须分割出单个词或句子。可以通过对英文文章或句子的语法和语义分析来提取出该文章的主要意思。但这些方法都是基于英文本身就有明显的词间分割这个事实上的,因而英文根本不存在分词问题。但对于汉语等无明显词间隔的语言来说,必须要先对原文进行分词,然后再提取它。
中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解,其处理过程就是分词算法。现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
[1]刘琨,郑有才.搜索引擎剖析[J].微机发展,2005.
[2]化柏林.Google搜索引擎技术实现探究[J].现代图书情报技术,2004.
[3]郭少友.元搜索引擎的原理和设计[J].情报科学,2005.
