自动构建时间基元规则库的中文时间表达式识别
2010-07-18邬桐周雅倩黄萱菁吴立德
邬桐,周雅倩,黄萱菁,吴立德
(复旦大学计算机科学技术学院,上海200433)
1 引言
时间表达式的识别是信息抽取领域的一项基础性任务,它可以用于事件跟踪,时间关系推理,时序定位等。比如在主题检测与跟踪任务中,可以用时间来定位事件发生的先后顺序;在自动问答系统中,可以用来回答和时间相关的问题如“多久,何时”;在机器翻译任务中,时间顺序的定位可以让译文更加顺畅易读;甚至在网页结构分析方面,也在研究如何用时间表达式特征去提高分析正确率。近几年来,时间表达式的识别和规范化由于在时序方面的重要应用,涉及的语种也从起初包含的英语、汉语和阿拉伯语,扩展到韩语[1]、法语[2]和西班牙语[3]等。
随着对时间表达式的关注度逐渐提升,陆续出现了许多相关的评测。自从2004年N IST(National Institute of Standards and Technology)的TERN(Time Expression Recognition and Normalization)评测问世之后,ACE 2005(Automatic Content Extraction)和Sem Eval 2007(Semantic Evaluations)评测也相继将其纳入自己的任务中,时间表达式评测的标准也日益成熟。
TERN评测包含两个任务,其中 TER(Time Expression Recognition)主要完成语料中时间表达式的边界识别任务,而TEN(Time Exp ression Normalization)则完成时间表达式的规范化工作,即为每个识别出边界的时间表达式按照Timex2①Timex2标注方案,TIDES 2005 Standard for the Annotation of TemporalExpressions.规范标注属性值。本文研究第一个任务,即时间表达式的边界识别。
时间表达式识别中两种最为常用的方法是基于人工构建规则的方法和基于机器学习的序列标注方法。
基于人工规则的方法方面,李文婕等人在文章[4]中做了比较具代表性的尝试,文章提出建立一些语法规则和补充限定规则,通过规则匹配方式识别时间表达式。直到最近,仍有文献[7]使用基于规则的方法,通过对点时间、段时间、集合时间等不同类型的时间短语平行识别,完成时间表达式的边界识别任务。基于规则的方法使用起来非常简单,而且规则易于理解,便于扩展和更新。但是最大的缺点就是人工工作量较大,早期的方法完全使用人工方式来构建规则,后期则先通过一些机器标注方法对文本进行预处理,然后对处理后的标注结果构建规则,虽然在一定程度上减少了人力,但仍不能适应实际应用要求。
基于机器学习的序列标注方法方面,D.Ahn[5]和K.Hacioglu[6]分别进行了尝试。他们首先将语料进行预处理,比如分词、词性标注、前后词提取、首字母提取等,接着有选择地抽取特征,建立特征向量,通过预先选定的分类器(CRF[5]或者SVM[6])训练模型。然后对测试语料使用已经训练好的模型进行时间表达式的标注。实验表明,这种方法在中文时间表达式识别方面有着不错的表现。近年来,也有一些更新颖的方法出现,比如哈尔滨工业大学的贺瑞芳等人[8],通过依存句法分析的标注结果结合预先定义的触发词表对中文时间表达式进行识别,然后运用TBL模型修正建立在依存句法分析上的规则集合。采用序列标注方法最大的特点就是可以充分利用已标注上下文信息,使得识别召回率较高。但是这类系统过分依赖标注语料的质量,又无法充分利用时间表达式格式相对稳定的特点,仅仅利用一些局部特征信息构建规则。因此,序列标注方法较少被使用于时间表达式识别任务。
综上所述,基于规则的方法需要人工构建大量规则,代价非常高,且扩展性和领域适应性差;而采用序列标注方法则无法解决训练语料数据稀疏和词序依赖这两个缺点,很难达到较高的识别性能。
本文基于训练标注语料自动学习规则,并通过错误驱动思想对规则库进行剪枝,既有效地利用了上下文信息,又达到了较高的自动化程度。在ACE07中文语料上的实验结果显著超过了现有水平,F-score达到89.9%。
本文结构安排如下:第2节,主要介绍中文时间表达式识别系统的详细设计结构以及我们所提出的“时间基元”的概念和自动学习结合错误驱动剪枝的规则库构建算法,即auto-pattern算法。第3节,介绍本文所设计的几个实验,相关的评测方法和评测结果,并进行原因分析。最后,全文总结并提出未来工作的设想。
2 时间表达式识别的基本原理和方法
2.1 中文时间表达式识别系统结构
本文所设计的中文时间表达式识别系统(详见图1)主要包含五个步骤:
1)对训练语料进行预处理,抽取所有已标注的时间表达式。
2)将这些从标注语料中抽取的表达式进行分词,构成“时间基元”集合,达到降低粒度以便构建细粒度的正则规则②正则规则:正则表达式形式的规则。全文亦使用“正则规则”进行表述。的目的。
3)通过预定义的规则转换机制,自动将“时间基元”转化为与其对应的正则规则,形成自动学习规则库。
4)运用错误驱动思想,根据规则评价函数对规则剪枝,消除规则库中的“噪声”,生成最终规则库。
5)最终规则库中的规则通过正则表达式匹配,识别测试语料中的时间表达式,将识别出的相邻表达式进行合并,完成时间表达式的识别任务。
其中1)~4)构成规则学习模块,5)单独构成规则应用模块。
学习模块中,基于“时间基元”构建规则的设计降低了规则的粒度,可以识别更多细粒度时间表达式,提高了识别系统的召回率,因此,就需要在应用模块中将相邻的被系统所识别出的表达式进行合并,构成连续完整的时间表达式。这也符合时间表达式由基本时间单元(“时间基元”)组成的感性认识。
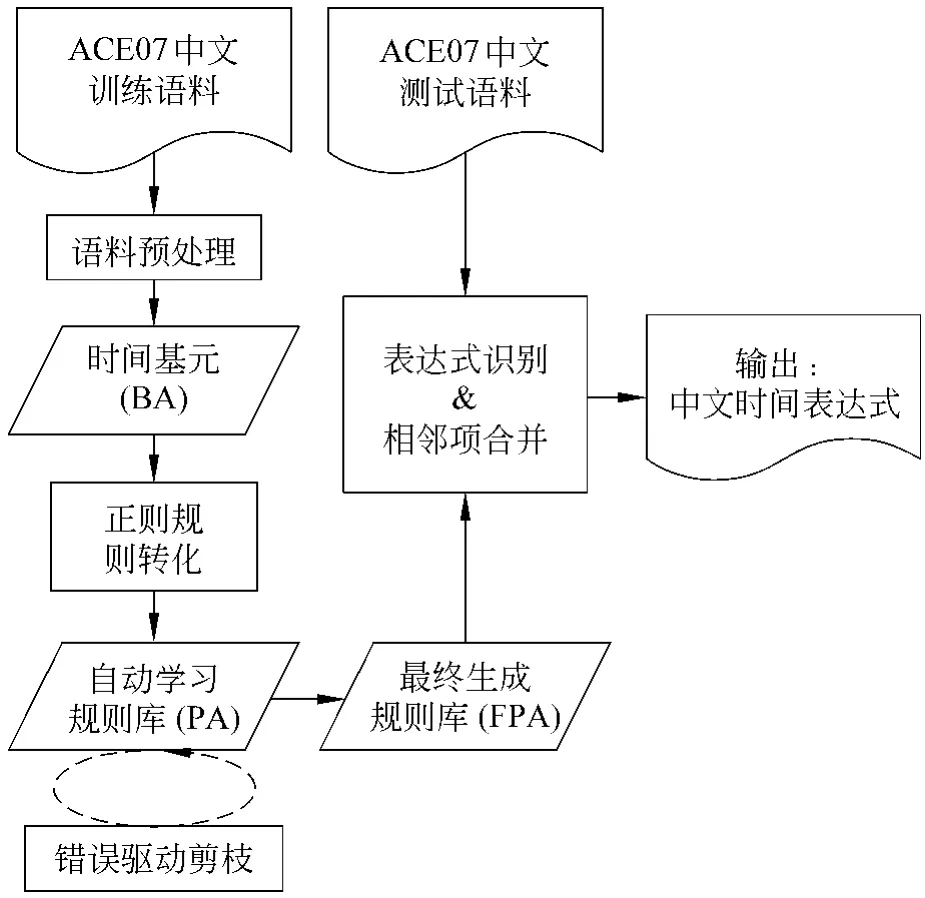
图1 中文时间表达式识别系统结构图
2.2 “时间基元”
“时间基元”,即基本时间单元,是构成时间表达式的最小组成单元。比如“2008年5月12日下午2点48分”这个时间表达式中,就包含2008年、5月、12日、下午、2点、48分六个时间基元。
以往时间表达式识别方法,大都构建完整的时间表达式识别规则,然后对整块表达式进行识别,这样构建的规则往往会有粒度过粗的缺点,无法识别出很细的时间表达式,而且如果测试语料中,组成表达式的时间单元按照现有形式之外的方式进行组合,那么规则将匹配失效,从而导致系统召回率较低。
而实际上,通过对大量时间表达式结构的深入分析,我们发现,时间表达式往往由独立代表特定时间概念的基本单元(“时间基元”)所组成,也就是说时间基元与时间基元之间的搭配相对松散,没有很强的先后依赖关系。
正是因为时间表达式这种弱依赖的特点,我们选择了对时间基元建立正则规则,然后将识别出的表达式进行相邻项合并,最终构成完整结构的时间表达式。
2.3 人工构建启发式规则库
中文时间表达式虽然不如英文那样具有良好的书写规范和很固定的格式,但是也是有一定规律性可循。过去基于规则的研究方法都是利用这个特点,构建了大量的人工规则进而完成识别任务的。然而由于每篇文章构建规则的方法不同,最终的规则库也不发布,因此很难重复他人的研究工作进行对比实验,我们只好根据自己的研究经验构建一部分启发式规则,作为人工启发式规则库。
根据我们对TERN任务的归纳,中文时间表达式大体分为七种类型(见表 1)。针对每个不同类型,我们各自构建了一批人工规则,作为启发式规则库。这些人工规则,能够通过正则表达式匹配方式①本文全部使用Standard Java Developm ent K it 6.0正则表达式引擎,通过正则匹配模式,完成表达式识别。识别出许多中文时间表达式。
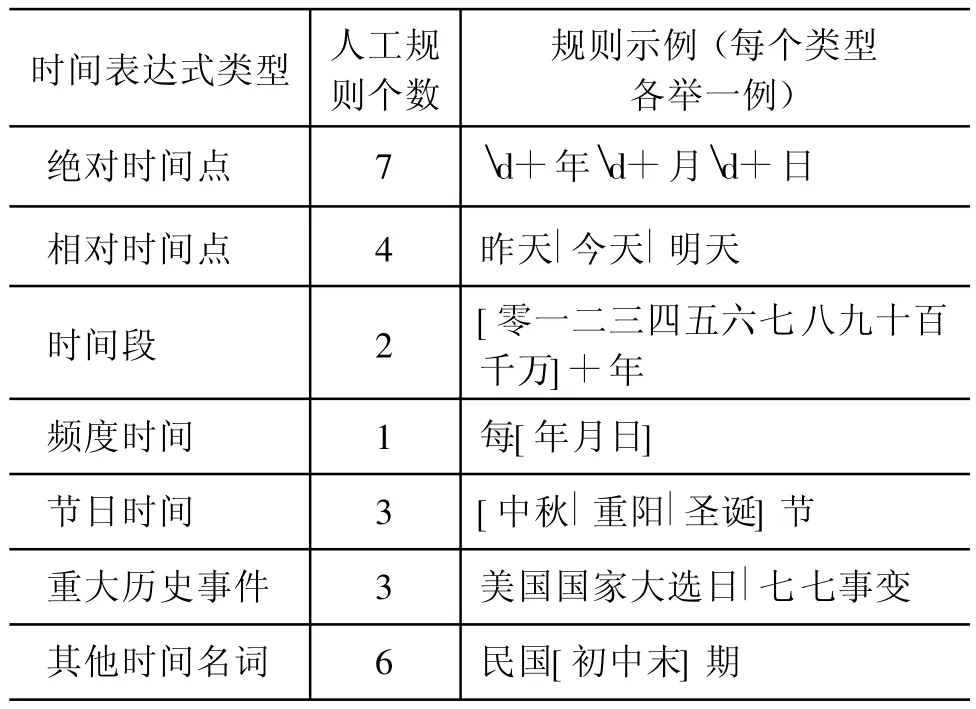
表1 人工规则示例
最终,我们整合所有七种类型的人工构建的启发式规则,得到人工启发式规则库
2.4 基于训练语料自动学习规则
高正确率的人工规则并不能达到很高的综合性能(F-score),主要是因为人工规则覆盖能力低,导致召回率较低。而如果充分利用训练语料覆盖广泛的特点,就能非常有效的提高召回率。在这一部分,我们将自动抽取训练语料中的“时间基元”,并通过预定义的转化规则将其转化成目标正则规则,全自动完成规则库的构建,其中不包含人工过程,使系统有较好的可移植性,将来可以施加较少的变动去适应其他领域的应用。
1)标注语料预处理
对XM L格式的标注语料进行解析,仅保留Timex2节点。接着,对节点进行清洗,得到训练语料中全部中文时间表达式的字符串集合
该集合中的每一个元素就是一个已标注的时间表达式E Ai。
2)生成“时间基元”集合
就需要将每一个完整的已标注时间表达式按照基本时间单元的概念分解为若干时间基元,即将全部时间基元去冗余整合,得到“时间基元”集合
这里需要指出的是,虽然本文提出了“时间基元”的概念,并在其基础上自动构建正则规则完成时间表达式的识别,然而“时间基元”尚未给出明确的规范,因此按照怎样的标准将已标注时间表达式分解成若干对应的时间基元,可以有很多选择。
为了使整套系统包含最少的人工干预,达到较高的自动化程度,我们选择使用比较成熟的自动中文分词系统①本文所使用的中文分词系统是复旦大学媒体计算与Web智能实验室基于M UC-6语料所设计并构建的中文分词系统。对已标注时间表达式进行分词,将分词后的细粒度短语作为“时间基元”。这样既达到了分解较长的完整时间表达式,降低目标短语粒度的目的,同时又较好的解决了系统自动化的需求。
3)正则规则转化
使用预先设定的三个转换规则RT1,RT2,RT3,将BA中所有的时间基元转化为对应的正则规则。RT负责将“时间基元”转化为正则规则,每个RTi包括识别和转化两个部分。
识别部分RT_Ri:用于对时间基元BAi中特定短语进行识别。
转化部分RT_Ti:对表达式中被第一部分识别的短语进行转化,生成最终的正则规则PAi。
预设的三个转换规则,如下:

比如,我们将第一条转换规则作用于时间基元:BAi=“5年”。按照RT1的识别规则RT_R1可以将BAi中的“5”识别出来,进而再通过 RT_T1将 5转化为“d+”,这样转化后的 PAi=“d+年”。
下表是RTi的应用示例。
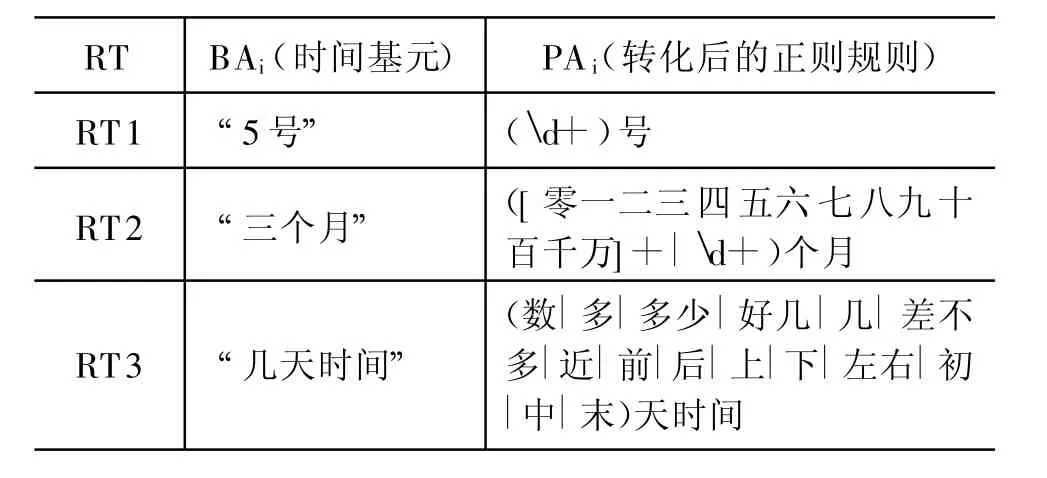
表2 正则规则转化示例
就这样,每个时间基元短语依次通过全部三个RT的识别与转化规则处理。最终,生成自动学习阶段的正则规则集合:
4)识别结果相邻项合并
在时间表达式的识别阶段,我们使用每条基于“时间基元”构建的正则规则进行时间表达式的识别,再将位置相邻的被识别表达式进行相邻项合并,就会得到最终识别结果。
“时间基元”的特性就是基于每个相对独立的基本时间单元进行规则构建,这样割裂了时间表达式的整体性。然而,将相对独立的识别结果进行合并,就会产生出许多新的搭配与组合,即生成许多新的完整的时间组合,扩大了时间表达式的识别范围。
2.5 基于错误驱动思想的规则库剪枝
基于训练语料自动获取与转化所学习到的正则规则已经可以很好地完成时间表达式的识别任务。然而,与人工规则相比,自动学习的规则在正确率方面有着明显的降低,虽然召回率有所提升,但是整体性能F-score提高并不够明显。最主要原因就是学习过程中,由时间表达式分词、“时间基元”构建、正则规则转化等引入了大量噪声,造成了正确率的大幅度降低。
比如,训练语料中的一个样本BAj=“10.1”(中国国庆节),作为时间表达式被提供给自动学习模块,跟着,RT_R1=“d+”可以将10和1识别,进而通过RT_T1=“d+”将 BAj转化为PAj=“d+.d+”。那么在测试阶段,所有小数形式的表达式,如“3.14”,“10.00”,“25.25” ……都会被误识 ,产生这种噪声的原因就是PAj质量不高①如果规则识别出的正确表达式较少,错误表达式较多,该规则是质量不高的。该问题可以通过简单的限制条件加以解决,然而为了在自动学习过程中不引入任何人工干预,我们完整保留自动生成的所有规则。。对此,我们需要对规则库进行剪枝。
我们通过引入规则评价函数Score(PAi)来对规则库中的规则进行打分,修剪那些导致系统性能降低的规则而留下对系统识别性能贡献大的规则,auto-pattern算法正是在这种错误驱动思想指导下,设计了最后的规则库剪枝部分。
下图即为基于错误驱动思想进行规则库剪枝的流程图。
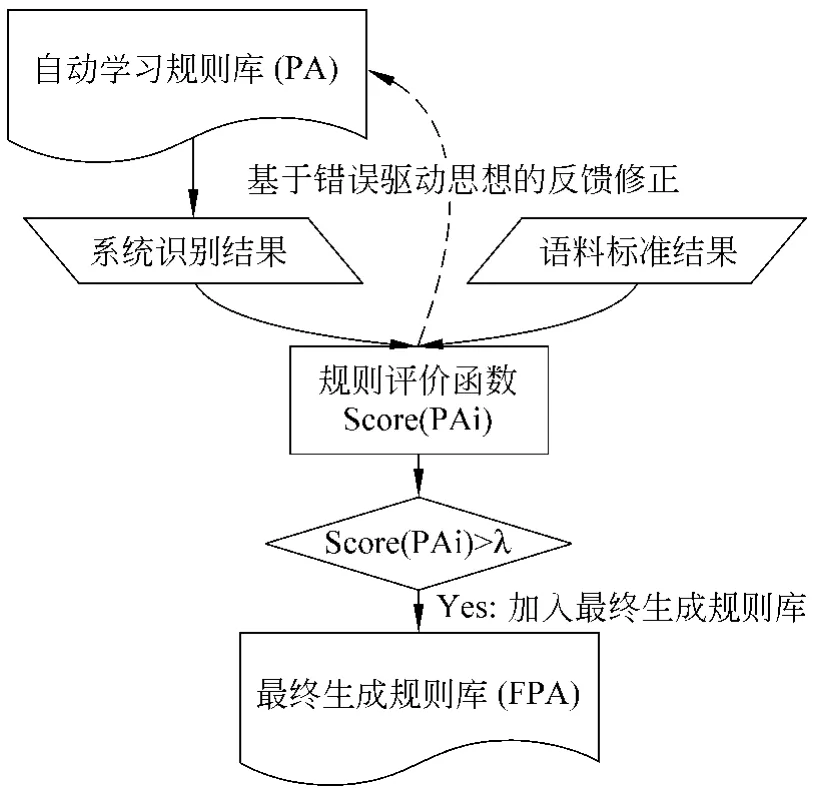
图2 基于错误驱动思想的规则库剪枝
基于错误驱动思想对规则库剪枝的具体算法如下:
输入:input={PAi}
输出:output={FPAi}
评价函数:Score(PAi)
评价阈值:λ
1)首先,顺次执行识别过程,input中的每个规则PAi,到训练语料中进行正则匹配,识别语料中的中文时间表达式,所有被识别出的表达式生成针对该规则的系统识别结果,记为Sys_PAi={,,……,},|Sys_PAi|为其计数。
2)接着,将系统识别结果与标注语料结果进行比较,即将Sys_PAi和训练语料的标注结果进行配对,如果某个对应着标注结果中的一个时间表达式,那么该结果就是一个被规则PAi正确识别的表达式,加入到 True_PAi中;反之,该表达式就是一个对应于规则 PAi的误识表达式,加入到False_PAi中。这两个关键参数|True_PAi|和|Fa lse_PAi|构成评价函数的重要组成部分。
3)然后,根据预定义的规则评价函数Score(PAi)对当前规则PAi进行打分。
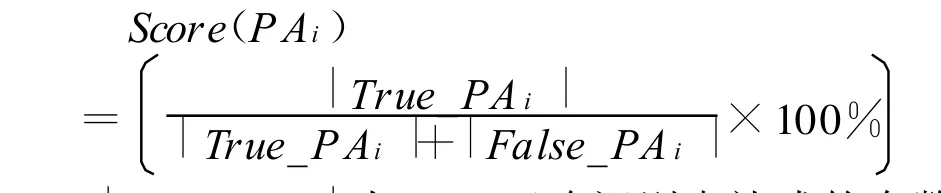
|True_PAi|为PAi正确识别表达式的个数,|False_PAi|为其误识表达式个数。
这样,以每条规则的Score值为参考标准,效果比较好的规则分数就会比较高,反之亦然。
4)最终,得分Score(PAi)超过阈值λ的规则PAi,保留在原规则库中,记为 FPAi;低于阈值λ的,对该规则进行剪枝,完成对规则库的修正。
迭代每条规则,对规则库剪枝,得到FPA={FPAi},i=1,2,…,n就是auto-pattern算法最终生成的正则规则库。
在整个过程中,阈值λ的选择起着尤为重要的作用,如果选择过高,则有效规则被剪枝的可能性就越高;如果选择过低,则不会对目标规则库有多大的提升作用,也就并没达到基于错误驱动思想的反馈式修正目标规则库的目的。
3 实验
3.1 ACE07评测语料以及TERN评测方法
目前,对于时间表达式的处理领域,最广泛采用的标准就是 Timex2标注规范。ACE07中TERN任务就是采用Timex2作为其评价标准。
ACE07中文语料的基本统计数据如下。
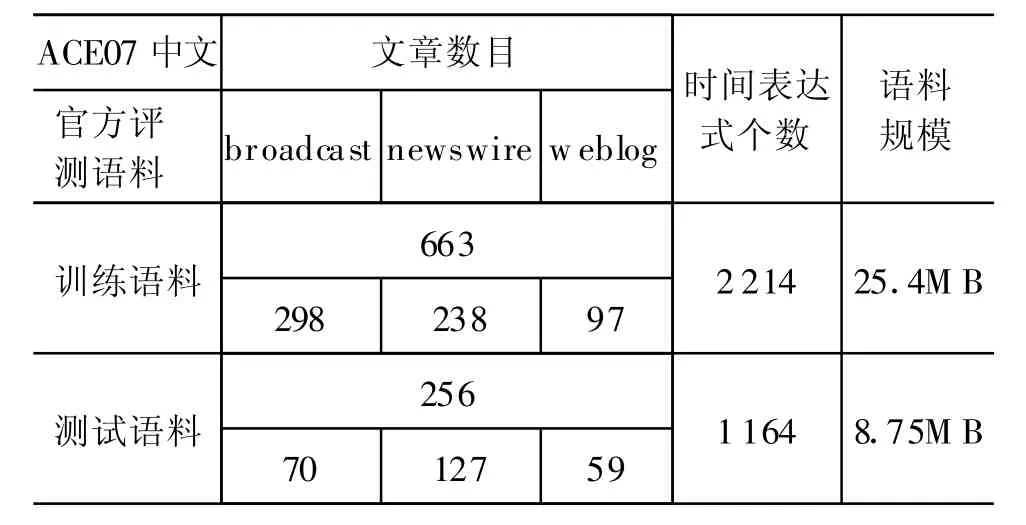
表3 ACE07中文语料统计信息
ACE评测有着悠久的历史,在命名实体领域更是最为权威的评测之一,每年都有来自全球的许多单位参评,参评语种包括英语、阿拉伯语、汉语等多种语言。TERN任务是ACE07评测中一个很重要的评测项目,也有多家单位参与了TERN任务的评测。
该任务采用自然语言处理领域中经典的“PRF评价标准”,具体评价方法可见ACE07 Evaluation Plan①The ACE 2007 Evaluation Plan:Evaluation of the Detection and Recognition of ACE Entities,Values,Temporal Expressions,Relations,and Events.。
3.2 基于人工启发式规则的评测结果
对于人工启发式规则的评测,我们找了不同的人员按照Timex2七个类别构建了初始正则规则,正则表达式外延相同的规则只保留一个,我们得到26个规则,构成人工规则库。
使用这些规则,到测试语料中识别时间表达式,并将识别结果与已标注时间表达式进行对比,再使用经典“PRF评价标准”进行性能检验,评测结果见表4。
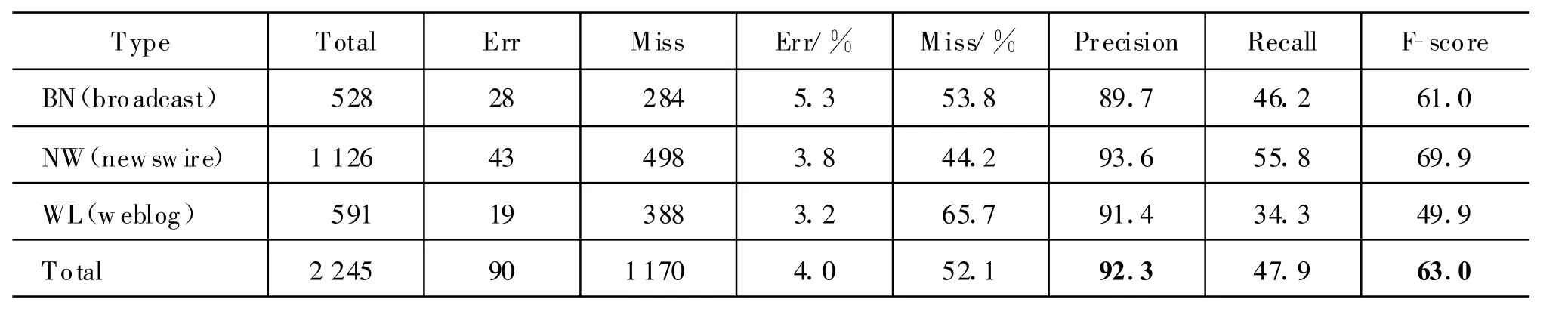
表4 基于人工启发式规则的评测结果
从结果分析,正确率很高而召回率却非常低,正确率高是因为人工构建的规则经过精挑细选,完全符合时间表达式的基本形式,因此在识别时会得到很高的正确率,而由于人工构建的限制,不可能靠人力来找到所有覆盖中文时间表达式的正则规则,进而构建出完备的规则库,因此召回率很低。
3.3 基于时间基元自动学习规则的评测结果
这一部分,我们通过auto-pattern算法的第一部分来自动学习规则。基于ACE07中文训练语料,从中我们抽得2 214个已标注时间表达式,进而得到881条基于“时间基元”转化而来的正则规则。
使用这些细粒度规则,识别ACE07测试语料中基于“时间基元”正则规则的中文时间短语,再根据算法说明,将相邻的时间短语进行合并,构成完整的时间表达式。最后,将这些合并后的表达式与已标注结果进行对比,得到测试结果见表5。
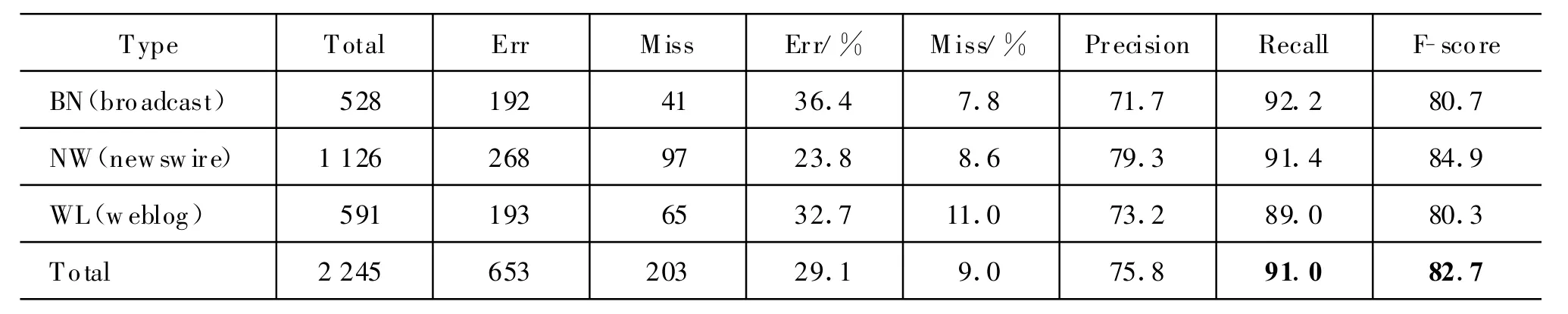
表5 基于自动学习规则的评测结果
实验结果显示,与人工启发式规则相比,基于“时间基元”自动学习的规则的确在召回率方面得到较大幅度的提升,升幅达89.9%,可是却也损失了相当一部分正确率,其降幅达到17.8%。然而综合性能F-score 31.2%的提高,表明自动学习方法得到的规则在整体识别性能方面的确有较好的表现。
“时间基元”规则,经过独立匹配和相邻项合并,产生很多训练语料外的新搭配,因此系统召回率有明显提高。然而,其正确率的下降,也反映出基于“时间基元”所学习的规则产生了大量细粒度的非时间表达式规则,使得系统识别出许多错误的结果。错误驱动剪枝部分,将会有效地修剪掉那些错误的规则,留下高正确率的有效规则。
与人工构建规则方法相比,自动学习方法不仅未加入任何人工过程,节约了人力消耗,而且有效地提高了召回率,识别正确率却由于训练语料噪声的引入而有所降低。但总体来看,系统整体性能F-score确有所提高。
3.4 基于错误驱动思想剪枝规则的评测结果
这一部分,按照auto-pattern算法的设计,通过错误驱动思想对规则库进行剪枝,并考察识别整体性能F-score与剪枝阈值λ之间的关系,见图3。
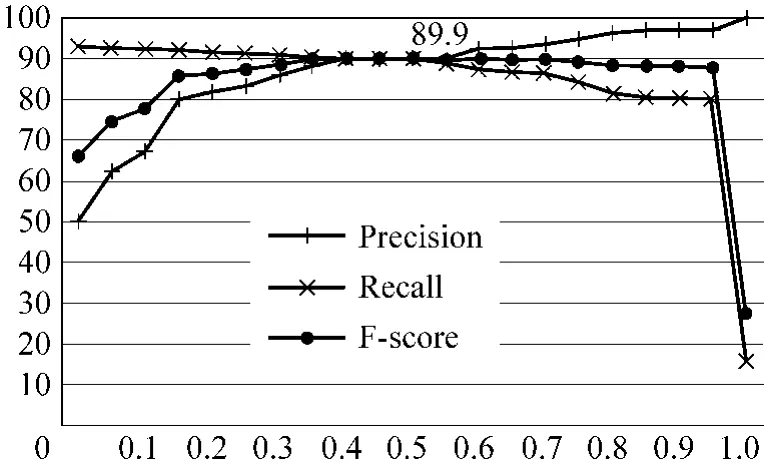
图3 调整阈值的评测结果
从λ=0开始,随着阈值的不断升高,被系统剪枝的规则也逐渐增多,规则库识别覆盖范围也会随之缩减,因此召回率慢慢下降,同时由于噪声的不断削减,识别正确率自然上升。直到λ=0.6时,召回率的升高和正确率的下降使 F-score达到峰值89.9%。随着λ的继续升高,越来越多的规则被剪枝,识别覆盖能力缓慢降低,但规则库中的噪声却越来越少,最终,留下的少量极高精度的规则使得识别正确率达到100%。
同时,阈值λ∈[0.15,0.95]的区间内,系统整体识别性能F-score基本都可以达到85%以上;更进一步,λ∈[0.30,0.70]的区间内,正确率和召回率也都维持在一个相对稳定的范围里。这说明基于错误驱动思想的规则剪枝部分,对参数的敏感性比较低,参数阈值λ在一个很大的区间范围内,都会使系统的整体识别性能保持在一个相对较高的程度。
3.5 与其他方法比较
无论是基于规则的方法还是基于序列标注的方法,几乎所有相关文章所使用的中文时间表达式识别系统都包含大量的人工过程,因此没办法按照原文的内容重现其实验结果。而且大部分中文领域的文章都使用自行标注的语料进行测试,无法进行对比实验。
在中文公开语料TERN任务评测领域里,将本文的结果与近年来效果最好的系统[9]的评测结果进行对比,具体数据对比如表6、图4所示。
人工启发式规则方法(AP-H)的正确率最高,达到92.3%,但是由于人工构建的限制,该规则库仅覆盖了很小一部分时间表达式,因此召回率很低;基于“时间基元”自动学习规则方法(AP-AN)的召回率最高,达到91.0%,而细粒度的“时间基元”规则包含了一些低质量规则,因此正确率不高。
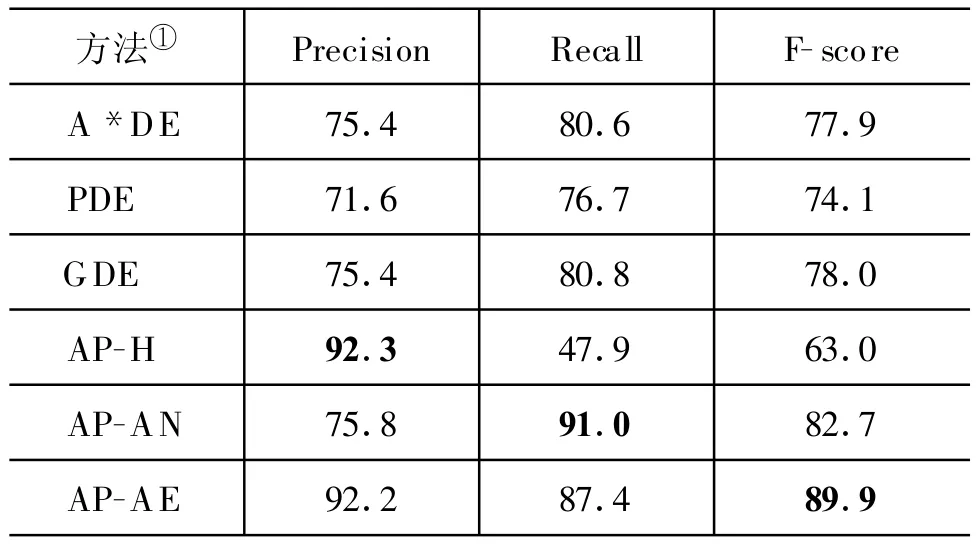
表6 与其他方法进行比较
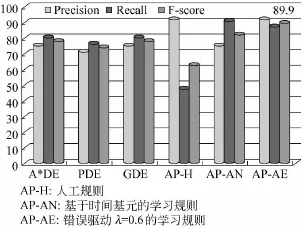
图4 与其他方法进行比较
最终,结合了错误驱动思想进行规则剪枝的高精度规则库,在剪枝阈值λ=0.6时,使 auto-pattern系统的正确率和召回率达到了比较出色的平衡,F-score为89.9%,比其他方法中性能最佳的GDE方法提高了15.3%,这样的性能提升是非常显著的。
4 结论与展望
时间表达式的识别是时间信息时序化过程的前提,也是很多自然语言处理领域问题的基础。本文提出一种自动学习结合错误驱动剪枝的规则库构建算法,亦即auto-pattern算法。本文将机器学习方法应用到规则自动学习与规则库剪枝过程中来,在识别正确率和召回率两方面均获得了较为平衡的优化,进而使中文时间表达式识别的整体性能有较大幅度提升。这种方法不仅解决了基于规则方法的人工消耗问题,同时解决了传统序列标注方法词序依赖和数据稀疏的问题。
根据对时间表达式特性的分析,我们对“时间基元”进行规则构建,并在识别阶段进行相邻项合并,这样的设计能够识别大量训练语料外的时间短语组合,又解决了长规则匹配失效的问题,提高系统召回率。同时,在错误驱动剪枝规则库阶段,对规则库中的大量规则进行修剪,有效的处理了规则学习时所带来的噪声,提高了系统正确率,更有针对性地提高了中文时间表达式识别的整体性能。
实验表明,这种自动学习结合错误驱动剪枝构建规则库算法是行之有效的,而且效果非常理想。同时还要强调本文提出的auto-pattern不仅仅是一个算法,同时是一个自动学习框架,可以很方便的扩展到其他领域。也就是说,auto-pattern作为一个有监督学习框架,只要有相应领域的语料和少量领域知识,该框架就可以构建出基于该领域的一套规则,进而完成特定目标内容的识别工作。
未来,我们将进一步研究如何提高auto-pattern算法的泛化能力,使之适应更广泛的应用领域;同时,还将研究如何将算法深化,进一步解决中文时间表达式的规范化问题。
[1] Seok Bae Jang,Jennifer Baldw in.Inderjeet M ani Automatic TIMEX2 Tagging o f Korean New s[J].ACM T ransactions on Asian Language Information processing(TALIP),2004,3(1):51-65.
[2] N ikolai Vazov A System for Extraction of Temporal Expressions from French Texts based on Syntactic and Semantic Constraints[C]//Proceedings of the w orkshop on Temporal and spatial in formation processing,2001,Volume 13:A rticle No.14:1-8.
[3] Estela Saquete,Patricio Martinez-barco.Rafael M ufioz Recognizing and Tagging Temporal Exp ressions in Spanish[C]//Workshop on Annotation Standards for Temporal In formation in Natural Language(LREC),2002:44-51.
[4] MingliWu,Wen jie Li,Qin Lu,Bao li Li.A Chinese Temporal Parser for Extracting and Normalizing Temporal Information[C]//International Joint Conference on Natural Language Processing(IJCNLP),2005,Vo lume 3651:694-706.
[5] David Ahn,Sisay Fissaha Adafre,Maarten De Rijke Tow ards Task-Based Temporal Ex traction and Recognition[C]//Proceedings DagstuhlWorkshop on Annotating,Ex tracting,and Reasoning about Time and E-vents,2005.
[6] Kadri H acioglu,Ying Chen.Benjam in Douglas Automatic Time Expression Labeling for English and Chinese Text[C]//Computational Linguistics and Intelligent Text Processing(CICLing),2005,Volume3406:548-559.
[7] 林静,曹德芳,苑春法.中文时间信息的TIM EX2自动标注[J].清华大学学报(自然科学版),2008,48(1):117-120.
[8] 贺瑞芳,秦兵,刘挺,潘越群,李生.基于依存分析和错误驱动的中文时间表达式识别[J].中文信息学报,2007,21(5):36-40.
[9] 贺瑞芳,秦兵,潘越群,刘挺,李生.基于启发式错误驱动学习的中文时间表达式识别[J].高技术通讯,2008,18(12):1258-1262.
