融合字特征的平滑最大熵模型消解交集型歧义
2010-07-18任惠林鸿飞杨志豪
任惠,林鸿飞,杨志豪
(大连理工大学计算机科学与技术学院,辽宁大连116024)
1 引言
自动分词是中文信息处理的基础,歧义切分问题是分词过程中需要解决的难点之一(另一难点是未登录词识别)[1],它直接影响分词系统的精度。从歧义字段的构成上看,分词歧义可以分为两种类型:即交集型歧义和组合型歧义。其中交集型歧义是文本中主要切分歧义类型,约占全部歧义的 85%以上,有关它的定义可以参考文献[2-3]。近年来,交集型歧义的切分问题吸引了众多研究者目光,迄今为止,多种方法被提出,这些方法大体可分为三类:基于规则的方法、基于实例的方法和基于统计的方法。
基于规则的方法利用人工编写的语法规则消解交集型歧义,取得了一定的效果[4]。但人工编写不可避免会遇到系统性、有效性、一致性和可维护性等规则系统的“天然”问题困扰[5],如今面对互联网上大规模真实文本处理的压力,纯规则的方法基本被抛弃。
基于实例的方法事先搜集歧义字段及其正确的切分形式形成实例库[6-7],文献[3,8]在库中还存储实例的上下文信息,歧义消解通过库检索即可实现。基于实例方法简单有效,但其消歧能力依赖于库中实例的数量,泛化能力弱,常常作为其他方法的补充。
为克服上述两类方法的缺陷,研究人员尝试了多种统计的方法。有指导的概率统计方法通过计算待消歧字段所有可能的切分路径的概率,并把概率最大者作为消歧字段的消解结果[9-10];无指导的统计方法利用互信息和 t-测试差解决歧义切分问题[11];有些研究人员将歧义消解问题转化为分类问题,通过分类模型来消解歧义[2,12-13]。上述方法均取得了较好效果,但也存在一些问题,主要集中在消歧知识不足、消歧对象受限、消歧精度有待提高和模型特征难以获取四个方面。
近年来,最大熵模型被广泛用来解决各种自然语言处理问题,如:分词[14]、词性标注[15]、实体识别[16]、Chunk识别[17]、句法分析[18]和机器翻译[19]等,对上述问题都达到或超过了其他方法的最好结果。与其他统计机器学习方法相比,最大熵方法能够将各种不同的知识融合在统一的算法框架中,且独立于特定的任务,具有模型简洁、通用和易移植的优点。鉴于该方法在上述诸多自然语言处理题上都取得了相当优异的性能,我们也采用它来解决交集型歧义。我们首先将交集型歧义的消解问题转化为一个二分问题,然后利用融合丰富字特征的最大熵模型来解决该分类问题。此外,为了克服建模时的数据稀疏问题,我们引入了不等式平滑技术[20]和高斯平滑技术[21],它们都是通过放松标准最大熵建模时的特征期望等式约束来改善数据稀疏问题。本文的另一大特色是我们选择基于字的特征而不是基于词的特征作为消歧知识。我们这样做基于如下理由:首先基于字的特征可以直接从未切分文本中获取,这使得本文的算法可以在任何自然语言处理应用中直接应用,大大降低了本算法的应用难度。基于词特征的消歧算法在应用时另外需要一个单独的分词程序。其次,基于字的特征比基于词的特征更加紧凑,这是因为中文词是一个开放集,真实文本中未登录词的比例比生字要高得多。第三,我们观察到在分词任务上,字特征比词特征更加有效[14]。我们相信在组合型歧义消解问题上依然有效,因为在解决这两个分类任务时都需要相同的知识源。最后,基于字的特征可以产生丰富的单字、双字、多字这样交叠性特征,而最大熵模型最大的优点就是能够将各种特征融合到一个统一的框架,通过逐步增加特征来提高性能。
本文提出的方法较好地弥补了前人工作的一些不足。首先,模型特征融合了丰富的消歧特征,这些特征不仅包含歧义字段及其上下文信息,还包含歧义字段与其上下文相混合信息。以前的方法仅仅利用歧义字段及其前后词、词性和互信息作为消歧知识源[2,12-13],消歧知识的不足使消歧对象受限,也制约了消歧性能。文献[13]仅能消解三字长伪歧义,而文献[12]仅能消解三字长伪歧义和部分三字长真歧义,而本文不仅能处理伪歧义,也能处理真歧义;不仅能消解三字长歧义,也能消解其他长度的歧义,同时使消歧性能也大幅度的提高。其次,我们使用基于字的特征,这些特征无需统计、分词及词性标注等深层处理,可直接从文本中抽取,大大降低了算法应用难度。而以前的方法或需要统计信息,或需要词汇和词性信息作为特征[12-13],在歧义消解时需要词汇词性等深层信息,分词和词性标注的错误不可避免地传播到歧义消解阶段。最后,以前的方法[2,12-13]都没有采取平滑措施缓解数据稀疏问题,而本文通过采用平滑措施来放松模型中的特征期望约束,有效缓解数据稀疏问题,使得消歧性能得到进一步提高。
我们在第三届国际分词竞赛的四个数据集上进行了测试,分别获得了96.27%、96.83%、96.56%、96.52%的消歧正确率,对比实验表明:丰富的特征使消歧性能分别提高了5.87%、5.64%、5.00%、5.00%,平滑技术使消歧性能分别提高了0.99%、0.93%、1.02%、1.37%,不等式平滑使分类模型分别压缩了38.7、19.9、44.6、9.7。我们的方法在四个不同的数据集上获得了相同的结论,证明了我们方法在不同数据集上的一致性。
2 利用不等式最大熵模型消解交集型歧义
2.1 问题定义
本文将交集型歧义消解问题转化为分类问题,分类空间定义在歧义字段的FMM和BMM切分结果Of和Ob中。这样交集型消解问题可以转化为一个二分问题:
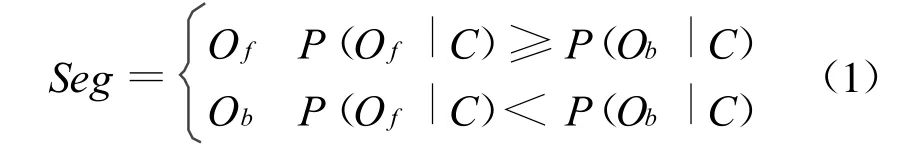
其中,Seg(Seg∈{Of,Ob})是歧义字段的消歧结果,P(O f|C)表示在条件C下歧义字段切分结果为Of的概率,P(Ob|C)表示在条件C下歧义字段切分结果为Ob的概率。这样,消歧过程就是根据公式(1)选择较大概率的过程。
2.2 最大熵模型
最大熵原理要求建模时拟合所有已知事实,而对未知事实不做任何附加假设。与其他的统计机器学习方法相比,最大熵模型能够方便将各种不同的知识(特征)融合在一个统一的算法框架而不需要在这些特征之间存在任何独立性假设。最大熵模型能够应用于任何分类问题,对于交集型歧义消解任务而言,它为歧义字段的每种分类结果(Of,Ob)产生一个条件概率,该条件概率可以通过公式(2)计算得到:
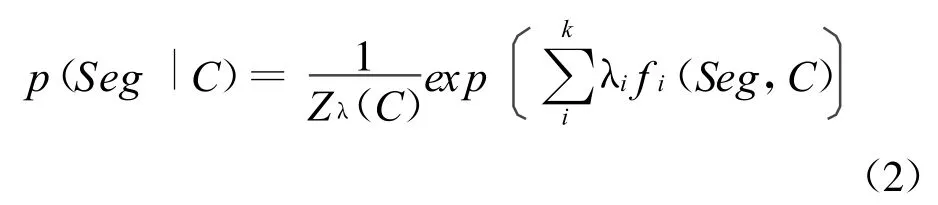
其中C表示了歧义字段拥有的特征集,Seg是歧义字段的分类结果,Zλ(x)是正规化常数。fi表示了第i个特征,k是该歧义字段拥有的特征总数,最大熵建模时要求每个特征的经验期望值与模型估计期望值相等。即:
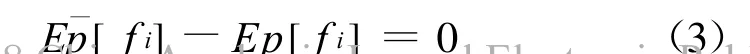
前者为 fi在训练样本中的经验期望值,后者是fi在模型估计时的模型期望值。
2.4 模型平滑与特征选择
从某种程度上讲,最大熵模型也是一种最大似然对数模型,同其他最大似然估计方法一样,当训练数据比较稀疏时,模型也会过度拟合训练数据,这说明应用最大熵法解决NLP任务也需要进行平滑。当前各种平滑算法被引入最大熵模型[21]。文献[21]在多个NLP任务上,考察了高斯平滑技术与其他平滑技术,测试结果表明:高斯平滑技术在所有NLP任务上都获得同等或者优于其他其他方法的性能。该方法本质上是利用高斯先验分布通过公式(4)来惩罚那些正值或负值很大的权重,使模型更少拟合训练数据。
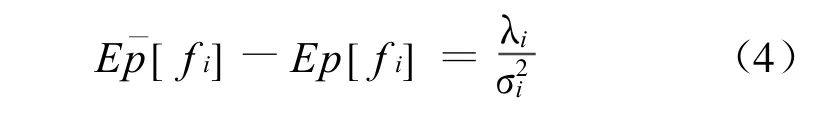
最近文献[20]提出一种称为不等式平滑技术的胖约束,通过赋予期望约束一定宽度的滑动范围来放松该公式(3)所规定的特征期望约束:
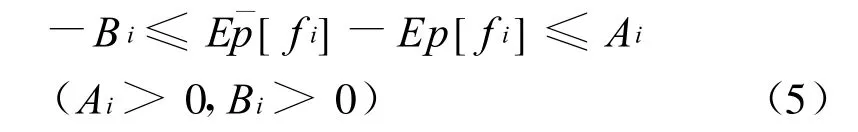
公式中Ai,Bi是第i个特征的宽度滑动范围,通过该滑动范围,可以放松每个特征的期望相等约束(传统最大熵模型规定每个特征的理论期望值应该与通过训练语料计算得到的该特征的期望相等),使得模型不会过度拟合训练数据。
文献[20]在两个文本分类任务上比较了不等式平滑技术和高斯平滑技术,测试结果表明采用不等式平滑技术比结合频度折扣的高斯平滑技术更优,本文也通过实验对各平滑技术在缓解模型数据稀疏问题上的效果进行了对比。
2.5 特征选择
特征选择的任务是从训练样本所有特征中挑出期望值能被可靠估计的特征,不是所有的特征对分类能力都有贡献,太多的特征不仅会增加模型的训练时间,而且导致模型过度拟合训练样本。常用的特征选择方法有:基于信息增益的方法及其近似算法[22]和基于频度折扣的方法[15,17]。基于信息增益的方法每次选择使模型熵增加最多的特征,使得每次特征选择阶段都要计算所有特征的信息增益,因此耗时较多;基于信息增益的近似算法认为加入一个特征后的模型仅依赖于原来的模型和参数λ,该方法比较快,但是不能保证每次加入模型的特征都是最好的;基于频度折扣的方法事先根据经验设定或者根据开发集来调节折扣阈值K,特征选择时认为频度小于或等于K的特征都不可靠,只挑选那些频次大于 K的特征,但是 Walter Daelemans et al.[23]指出低频特征也包含对分类有贡献的信息。所以,我们在采用基于频度折扣的特征选择方法时,不是事先设定一个固定的阀值,而是在一定范围内穷举所有可能的阀值,根据开发集来确定最佳阀值。另外,不等式平滑技术能够将特征选择与参数估计无缝结合在一起,从模型中除去那些权重为零的特征而不会影响模型的分类行为。Kazam a和Tsujii[20]演示了不等式平滑技术在特征选择上比频度折扣方法更优,我们在实验中采用该方法。
2.6 参数估计
参数估计用来求解公式(2)中参数λ,参数估计常用的方法有:通用迭代算法(GIS)[24]、改进的迭代算法(IIS)[22]、梯度法和变度量法及其变体等。文献[25]在四个NLP任务上考察了 GIS、IIS、梯度法和有限存储变量尺度法(LMVM)(变度量法的一种变体),结果显示:对于NLP分类问题,LMVM性能最好。文献[20]测试了限界约束有限存储变量尺度法(BLMVM)(LMVM 一种变体)[26]也证实了类似结论,并指出,在真实NLP数据集上,BLMVM能在更短的时间达到收敛,而且分类性能有所提高,因此我们在实验中使用BLMVM进行参数估计。
3 特征表示
3.1 利用临界切分法切分文本
歧义检测是消解歧义的前提。目前歧义检测的主要方法有:双向最大匹配法[27]、最小分词法[28]、全切分法[29]和临界切分法[30]等。前两种方法都存在检测盲点,全切分法虽然无检测盲点,但它的切分路径随文本长度成指数增长,而临界切分法不仅能检测出所有歧义,而且其切分路径只随文本长度成线性增长。文献[3]详细介绍了上述每种方法优劣并给出了相应的检测实例。
本文中,我们利用临界切分法切分文本,并将切分得到的临界段作为部分消歧知识源。文献[30]给出了临界切分法的定义并证明:给定词表,对于任意文本,无论该文本怎样被切分,临界点都是文本中所有非歧义的切分边界,相邻两临界点间字符构成一个临界段。临界切分法的示例见图1。
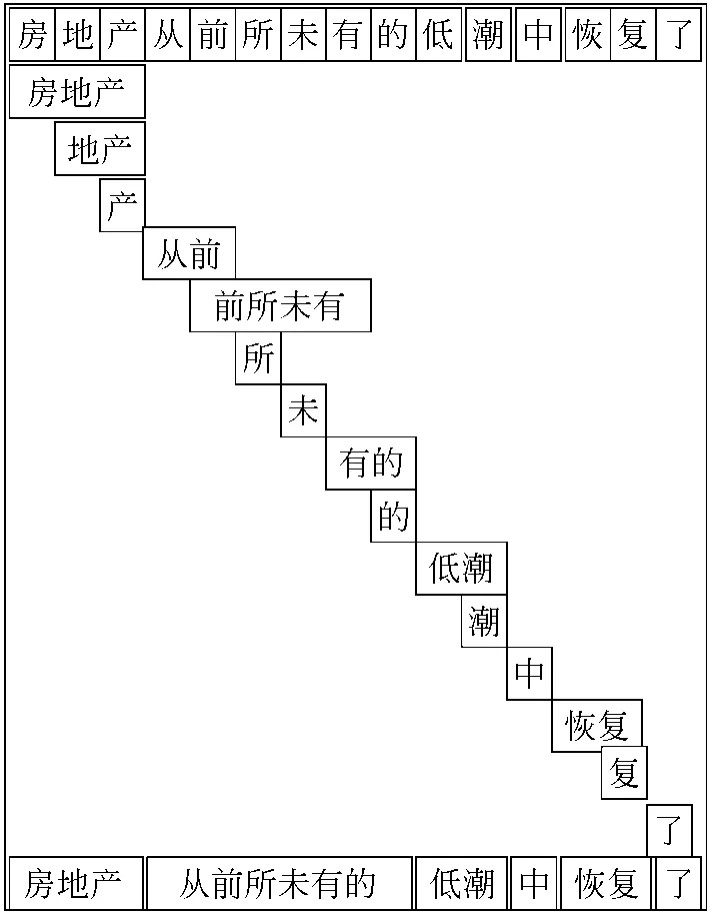
图1 临界切分法示例
算法先逐字正向最大匹配待切分文本,再检查匹配得到的词之间是否相互交叉覆盖关系,并将交叉覆盖的词凝聚成更长的串,如:“地产”、“产”和“房地产”被凝聚成“房地产”;“从前”、“前所未有”、“所”、“未”、“有的”、“的”被凝聚成“从前所未有的”,直到所有串之间不存在任何交叉覆盖关系。临界切分法将文本分割成临界段序列,不同临界段中的字符不相关,而所有相关的字符都必然包含在同一临界段内。
3.2 特征模板
最大熵模型分类能力取决于是否选择合适足够的模板,为此我们设计了丰富的基于字的特征模板。并把它们分为歧义字段上下文信息模板,歧义字段自身信息模板和混合信息模板。这些模板详细定义见表1。
这些模板中,C表示文本中的字符。模板1表示歧义字段周围六个字符,模板4中Cs表示歧义字段的第一个字符,Ce表示歧义字段最后一个字符。模板2表示歧义字段周围三个临界段,我们用CF0表示歧义字段自身,这些临界段可以通过3.1中临界切分法获得。模板6表示歧义字段自身包含的汉字体个数。模板1、3、4、6、7独立于具体语言,因为这些模板能够应用于任何语言,并且当它们作用于具体的训练数据时,特征值能从模板中自动获取。而模板2和5依赖于具体语言。

表1 交集型歧义消解用的模板特征定义
4 实验
4.1 实验数据准备和歧义字段分布
实验数据来自第三届国际分词竞赛提供的四个训练语料和测试语料。我们从四个训练语料中分别抽取交集型歧义字段及其特征(特征模板见表1)形成样本空间作为训练集,从四个测试语料中抽取交集型歧义字段及其特征作为测试集。歧义检测采用临界切分法,临界切分法所用的词表直接从各自训练语料中获取。因为本文主要考察最大熵模型的分类能力,对于那些切分结果不在分类空间(O f或Ob)中的歧义字段,我们将它们从样本中剔除出去。表2显示了各个训练集、开发集和测试集中的交集型歧义分布情况。
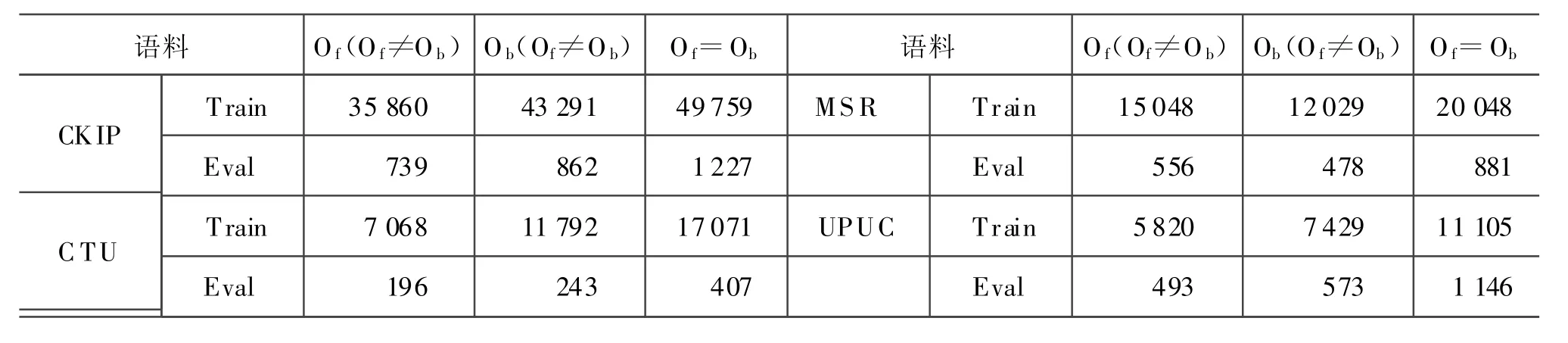
表2 训练集、开发集和测试集中的交集型歧义分布情况
4.2 模型训练和控制参数调节
在实验中,我们比较了结合频度折扣的标准最大熵模型(Cut-off)、高斯最大熵模型(Gaussian)和不等式最大熵模型(Inequality)三种平滑技术,模型中的参数λ采用BLM VM[26]进行估计,最大熵模型软件包来自互联网[31],实验中所使用的版本为1.3.2。该软件包提供了这三种模型的训练和测试接口,这样我们能够在同等基础上比较这些模型的性能。实验中我们来计算消歧正确率(消歧正确率=(利用最大熵算法正确消歧的个数)/(测试语料中交集型歧义的个数))。由于最大熵模型中需要事先确定某些控制参数,我们利用开发集在一定范围内以穷举的方式搜索最好的控制参数,也就是说,当模型在开发集上达到最佳性能时,即可得到最佳控制参数。标准最大熵模型的控制参数是频度阈值cthr,
我们在[0,5]范围内以步长为1的递增方式进行穷举式搜索;高斯最大熵模型的控制参数是方差σ,虽然公式(4)允许我们为每种不同的特征采用不同的方差,在实验中我们使用相同的方差,并在[100,1 000]范围内以步长为100的递增方式进行穷举式搜索;不等式最大熵模型的控制参数是宽度因子W,虽然公式(5)允许每种特征的宽度因子可以不同,实验中我们为所有特征设置相同的宽度因子W,并分别在[10-5,10-1]区间中以10倍递增方式和[0.1,1]区间以步长为0.1的递增方式进行穷举式搜索。实验中我们采用公式(6)来计算每个宽度值:

表3给出了各种模型在各个开发集上的最优控制参数值。
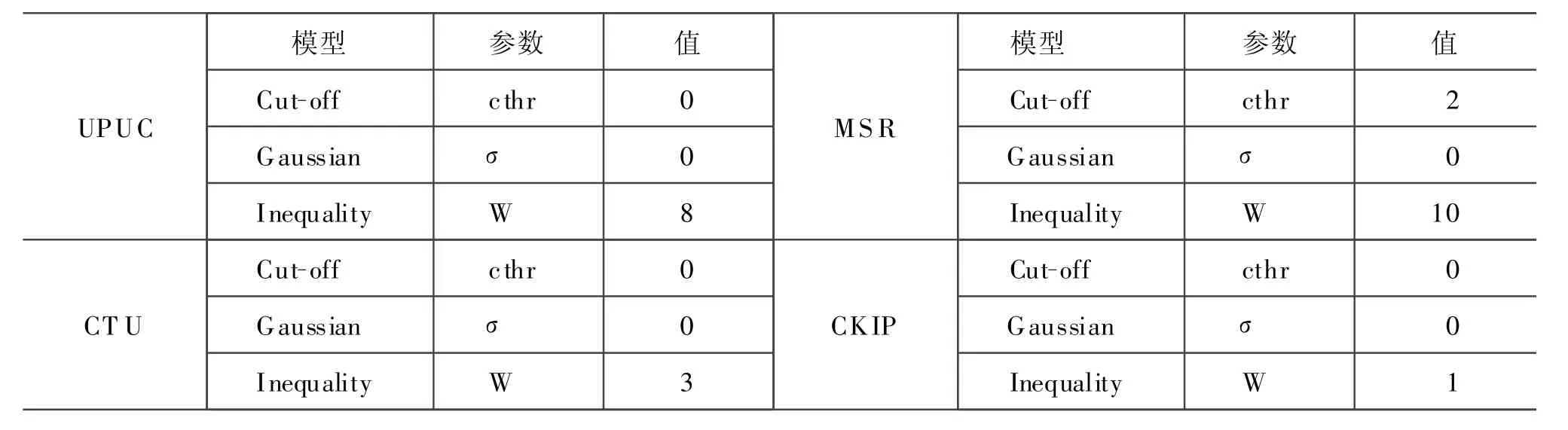
表3 最优控制参数一览表
4.3 测试
利用得到的各种最优模型对测试集进行测试。表5显示了不等式平滑技术的特征选择能力,相比最优Cut-off模型,不等式平滑技术能有效压缩模型规模。
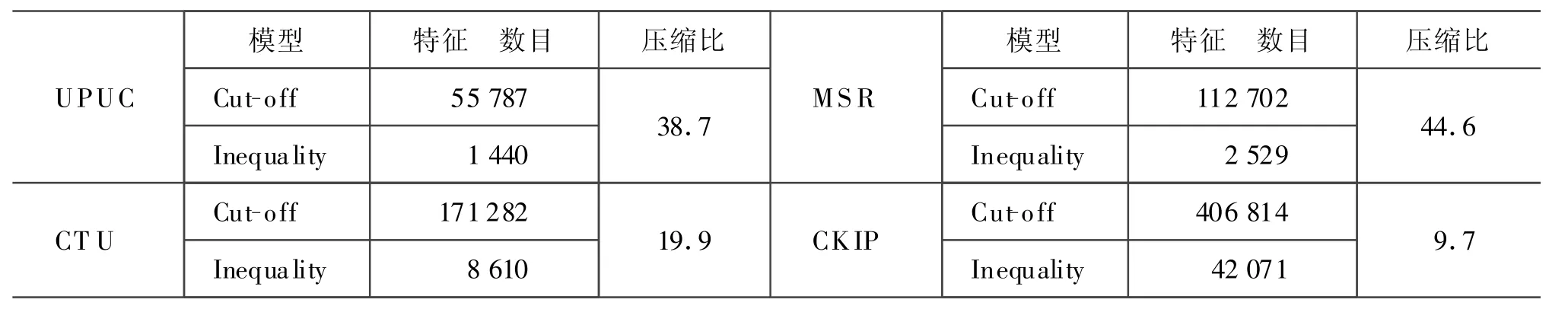
表5 不等式平滑技术的特征选择能力
为了考察丰富的语言知识对消歧能力的贡献,我们仅仅采用CFn(n=-3,-2,-1,1,2,3)作为消歧使用的特征,采用最优Inequality模型上对4个测试语料进行了测试,结果如表6所示。
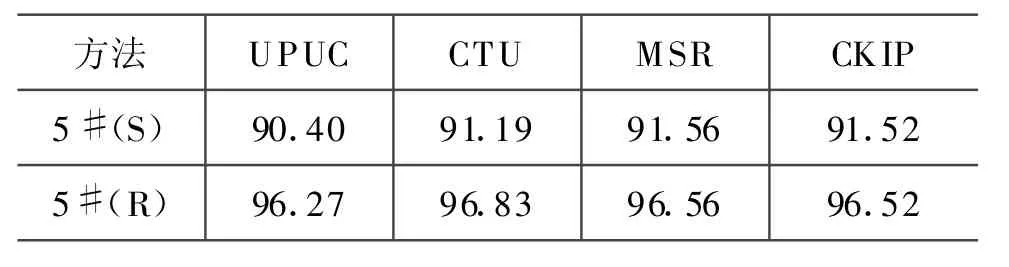
表6 简单特征和丰富特征不同消歧能力的比较
可以看出,丰富的语言特征对于消歧性能有显著的影响,在各个测试子集上,后者比前者至少提高5%。
5 结论和未来的工作
我们采用最大熵法消解中文文本中交集型歧义,取得了优异的性能,使用最大熵法消解在训练集中未出现的交集型歧义字段,也达到很高的性能,说明模型具有很强的泛化能力,实验还验证了高斯平滑和不等式平滑技术比单纯的频度折扣具有更强的分类能力,而高斯平滑和不等式平滑技术之间不分伯仲,同时还揭示出丰富的语言知识对消歧性能有显著的影响。实验所采用的高斯模型和不等式模型的控制参数比较简单,每种特征使用相同的控制参数,没有体现出模型的优势,所以在更大规模语料上采用更复杂的控制参数是有待深入的工作。另外本文与其他基于分类的方法[2,12-13]一样,分类空间限制在Of和Ob,遗漏了切分结果不是Of和Ob的歧义字段,我们可以采用其他方法如基于实例的方法来处理这些歧义,或者将这些歧义字段单独作为一类,这也是今后需要尝试的工作。
致谢 感谢Jun'ichi Tsujii提供最大熵软件开发包。
[1] 黄昌宁.中文信息处理中的分词问题[J].语言文字应用,1997,1:72-78.
[2] Mu Li,Jianfeng Gao,Chang-Ning H uang and Jianfeng Li.Unsupervised training for overlapping ambiguity resolution in Chinese w ord segmentation[C]//Proceedings of the Second SIGHAN Workshop on Chinese Language Processing,Sapporo,2003:1-7.
[3] Qinan Hu,H aihua Pan and Chunyu Kit.2004.An examp le-based study on Chinese word segmentation using critical fragments[C]//Proceedings of the First International Joint Conference on Natural Language Processing(IJCNLP-04),Sanya,Hainan,2004,505-511.
[4] Bing Sw en and Shiwen Yu.A Graded Approach for the Efficient Reso lution of Chinese W ord Segmentation Ambiguities[C]//Proceedings o f 5th Natural Language Processing Pacific Rim Symposium.Beijing,Nov,1999:19-24.
[5] 孙茂松,邹嘉彦.中文自动分词研究评述[J].当代语言学,2001,3(1):22-32.
[6] 孙茂松,左正平.消解中文三字长交集型分词歧义的算法[J].清华大学学报(自然科学版),1999,5:101-103.
[7] Jin Guo.One Tokenization per Source[C]//ACL-98,M ontreal,Canada,1998:457-463.
[8] Chunyu Kit and Xiaoyue Liu.An Example-Based Chinese Word Segmentation System for CWSB-2[C]//Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing,Jeju Island,2005:146-149.
[9] 孙茂松,左正平,邹嘉彦.高频最大交集型歧义切分字段在汉语自动分词中的作用[J].中文信息学报,1999,13(1):27-34.
[10] 陈小荷.用基于词的二元模型消解交集型分词歧义[J].南京师大学报(社会科学版),2005,6:109-113.
[11] 孙茂松,黄昌宁,等.利用汉字二元语法关系解决汉语自动分词中的交集型歧义[J].计算机研究与发展,1997,5:332-339.
[12] 张锋,樊孝忠.基于最大熵模型的交集型切分歧义消解[J].北京理工大学学报(自然科学版),2005,25(7):590-593.
[13] 李蓉,刘少辉,叶世伟,史忠植.基于SVM 和k-NN结合的汉语交集型歧义切分方法[J].中文信息学报,2001,15(6):13-18.
[14] Nianw en Xue.ChineseWord Segmentation as Character Tagging[J].International Journal of Computational Linguistics and Chinese Language Processing,2003,8(1):29-48.
[15] Adwait Ratnaparkhi.A Maximum Entropy Part-Of-Speech Tagger[C]// Proceedings o f the Empirical M ethods in Natural Language Processing Conference,University of Pennsylvania,1996.
[16] Hai Leong Chieu and Hw ee Tou Ng.Named Entity Recognition with a Maximum Entropy Approach[C]//Proceedings of H LT-NAACL,2003,4:160-163.
[17] Rob Koeling.Chunking w ith Maximum Entropy M ode ls[C]//Proceedings of CoNLL-2000 and LLL-2000.Lisbon,Portugal.
[18] Xiaoqiang Luo.A maximum entropy Chinese character-based parser[C]//EMNLP-2003.2003:192-199.
[19] Franz Josef Och and H ermann Ney.Discrim inative T raining and Maximum Entropy M odels for StatisticalMachine Translation[C]//ACL-2002.
[20] Jun'ichi Kazama and Jun'ichi Tsujii..Maximum Entropy Models with Inequality Constraints:A case study on text categorization[J].M achine Learning Journal special issue on Learning in Speech and Language Technologies.2005,60(1-3):169-194.
[21] Stan ley Chen and Ronald Rosen feld.A survey o f smoothing techniques for M E models[J].IEEE T ransactions on Speech and Audio Processing,2000,2:37-50.
[22] Stephen Della Pietra,Vincent Della Pietra,and John Lafferty.Inducing features of random fields[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1997,19(4):380-393.
[23] Wa lter Daelemans,Antal van den Bosch and Jakub Zav rel.Forgetting Excep tions is Harm ful in Language Learning[J].Machine Learning,1999,34(1-3):11-41.
[24] J.N.Darroch and D.Ratcliff.Generalized Iterative Scaling for Log-Linear M odels[J].The Annals of Mathematical Statistics,1972,43(5):1470-1480.
[25] Robert Malouf.A comparison ofalgorithm s formaximum entropy parameter estimation[C]//Proceedings of CoNLL-2002,Taipei,2002:49-55.
[26] Steven J.Benson and Jorge J.M or′e A limitedmemory variab lemetric method for bound constrained optim ization[R].Technical Report ANL/MCS-P909-0901,A rgonne National Laboratory,2001.
[27] 刘源,梁南元.汉语处理的基础工程-现代汉语词频统计[J].中文信息学报,1986,1(1):17-25.
[28] 王晓龙,王开铸,李仲荣,白小华.最少分词问题及其解法[J].科学通报,1989,13:1030-1032.
[29] 马晏.基于评价的汉语自动分词系统的研究与实现,语言信息处理专论[M].北京:清华大学出版社,2-36.
[30] Jin Guo.Critical tokenization and its p roperties[J].Computational Linguistics,1997,23(4):569-596.
[31] Jun'ichi Tsujii.http://www-tsujii.is.s.u-tokyo.ac.jp/~tsuruoka/maxent/.A simp le Maxent Toolkit[DB/OL].
