社会标注及其在信息检索中的应用研究综述
2010-07-18靳延安李瑞轩文坤梅辜希武卢正鼎段东圣
靳延安,李瑞轩,文坤梅,辜希武,卢正鼎,段东圣
(1.华中科技大学计算机科学与技术学院,湖北武汉430074;2.湖北经济学院信息管理学院,湖北武汉430205)
1 引言
标注(Annotation①according toWordNet,a)note,annotation,notation:a comment(usually added to a text);b)annotation,annotating-the act of adding notes.)是阅读者对文档内容的一种理解和概括,或者是对文档内容发表的观点、态度并提出建议的一种途径。也有学者把标注理解为“做记号”,记号可以是与其所标示的内容完全独立的符号系统,也可以是与所标示的内容存在直接关系的词语,但至少可据此理解“标注”具有标示作用,可提高查找的便利性,具有一定的标引功能。
通常意义上的标注是个体行为。在Web 2.0中,网络用户自由选择标签(字词或短语)来标注网络资源的个体行为被Internet汇集在了一起,形成了社会标注(SocialAnnotation)。这个时候,社会标注可以看作是社会大众对某个目标的理解、观点或者看法,比如对网站的可用性和友好性的评论。社会标注的兴起是以提供标注服务的网站(如Delicious①http://Del.icio.us,Flick r②http://www.flickr.comConnotea③http://www.connotea.org、CiteULike④http://www.citeulike.org、Digg⑤http://www.diig.com)的流行为标志的,这些网站允许用户选用简短的字词对自己喜爱和关注的网页进行标注并保存在个人账号中,极大地方便了用户对个人网络资源的管理和组织。
近年来在SIGIR、WWW 以及其他刊物和会议上有越来越多的研究工作开始关注社会标注。到目前为止的研究中,有从以下角度对社会标注进行研究:社会标注的理念和优缺点[1-2]、统计特性[3-4]、社会标注改善搜索性能[5-6]等进行了研究。文献[1]详细阐释了社会标注的理念,认为社会标注是一种元数据,文献[2]认为社会标注由
本文将从社会标注的标注对象、标注方法、分类特性、社区发现等几个方面综述社会标注在信息检索方面的应用研究。在文章的最后对目前存在的问题进行总结,并进一步讨论社会标注将来的研究方向。

图1 社会标注三元组
2 标注对象和标注方法
2.1 标注对象
社会标注作为一种新型网络资源的管理和组织形式,在许多网络应用中发挥着重要的作用,包括Web页面、博客文章、图像以及音视频等在内的越来越多的网络资源都得到了标注。随着对各种资源标注的不断增加,对社会标注的利用、描述、可视化、组织与检索效率以及标注系统等方面的研究也日益激增,特别是对网页资源的研究。
(1)网页资源
在IE和FireFox浏览器中,用户可以将喜欢的并且希望以后常来看的网页收藏到所使用计算机中不同的收藏夹是标注最早的形式。因此,可以将收藏夹看作是用户为了进行网页标引与信息检索的方便而建的索引。社会标注已经成为一种普遍的网络服务,得到许多用户的关注和欢迎,包括Delicious在内的许多支持社会标注的网站都提供了标注网页资源的功能,以便用户在线组织和检索感兴趣的网页资源。
社会标注本身作为一种元数据,所含有的语义信息和标注之间隐含的链接关系可以为计算网页的相关性的重要指标,从而为网页资源的快速定位提供有力支持。另一方面,同一社会标注的使用规模也可以作为结果排序的重要依据。文献[5,7]都在社会标注对搜索性能和质量的改善上做了大量研究。但是,这些研究大都是基于Delicious等网站为研究对象,而且这些网站数据经过规范化、去重以后,规模还非常小。
另外,社会标注的浏览和可视化也是非常值得研究的一个方面。在著名的Delicious网站上,已经有数千万个社会标注。如果这些标注看作是一个社会标注空间的话,如何让用户在如此庞大的空间里轻松自如地浏览就成为一个必须解决的问题。目前,大多数网站广泛采用标注云技术来实现流行标注的浏览,也有一些网站直接使用标注词列表来显示。通常,标注云是从整个标注空间中选择的频繁使用的标注,根据频次的不同使用不同大小和颜色按照字母顺序显示在一个平面上。虽然用户能够从标注云中直接观察到每个标注的热门程度,但是它仅仅能够显示很小部分的标注空间。为了显示整个标注空间,文献[8]使用聚类方法将空间中所有的标注根据语义相近的程度自动进行聚类,这种聚类方便了用户的浏览。而Donaldson等人则在GiveA L-ink.org系统中除了按照传统的语义相似布局标注外,还使用二维的网络图来帮助用户检索相关标注[9],但是笔者认为这种方法在大规模下是否能用有待进一步研究。
(2)博客资源
博客是一种日志性质的网站,主要由按新旧顺序排列的带有日期的文章及对应的评论组成,不同的博客之间通过链接、评论和反向链接互相联系,带有明显的社区特性。在博客中,对于社会标注的研究主要集中在社会标注对博客文章的分类作用、标注方法、标注可视化和主题相关性。文献[10]从Technorati①http://www.technorati.com,一个著名的博客搜索引擎。从2002年至今,Technorati的博客索引量已经达到1.33亿篇。网站收集了使用率最高的350个标注进行分析,发现标注对博客文章进行粗略的分类很有帮助,但对于一篇具体的博客则不然。Gilad M ishne基于合作过滤的方法开发了A utoTag自动标注工具,用户在标注博客时,该工具可以推荐更为合适的标注。在此基础上,通过配合博客信息发布的相关控制机制,可以使得用户的标注过程更加简单,而且可以保证标注的质量[11]。但是,对于利用标注来组织博客资源的有效性,以及什么样的功能适合使用社会标注(或者说博客的创作者和读者从社会标注可以获得什么好处)的研究很少看到有发表。
(3)图像资源
随着标注对象的进一步扩展,如何利用标注来提高检索图像资源的效率也成为国内外学者较为关注的问题。图像作为最重要也是最常见的资源类型往往在数量和格式上以惊人的数量存在。与文本资源相比,图像资源占用空间更大,能提取出来的特征维数更多。如何建立对高维的海量数据的最优索引从而提高数据检索效率也越来越成为图像分析和检索领域的热点。目前,图像检索技术主要有基于文本的检索方法(TBIR:Text-based Im age Retrieval)[12]、基于图像内容的检索方法(CBIR:Contentbased Image Retrieval)[13]和基于语义的检索方法(SBIR:Semantic-based Image Retrieval)[14]。
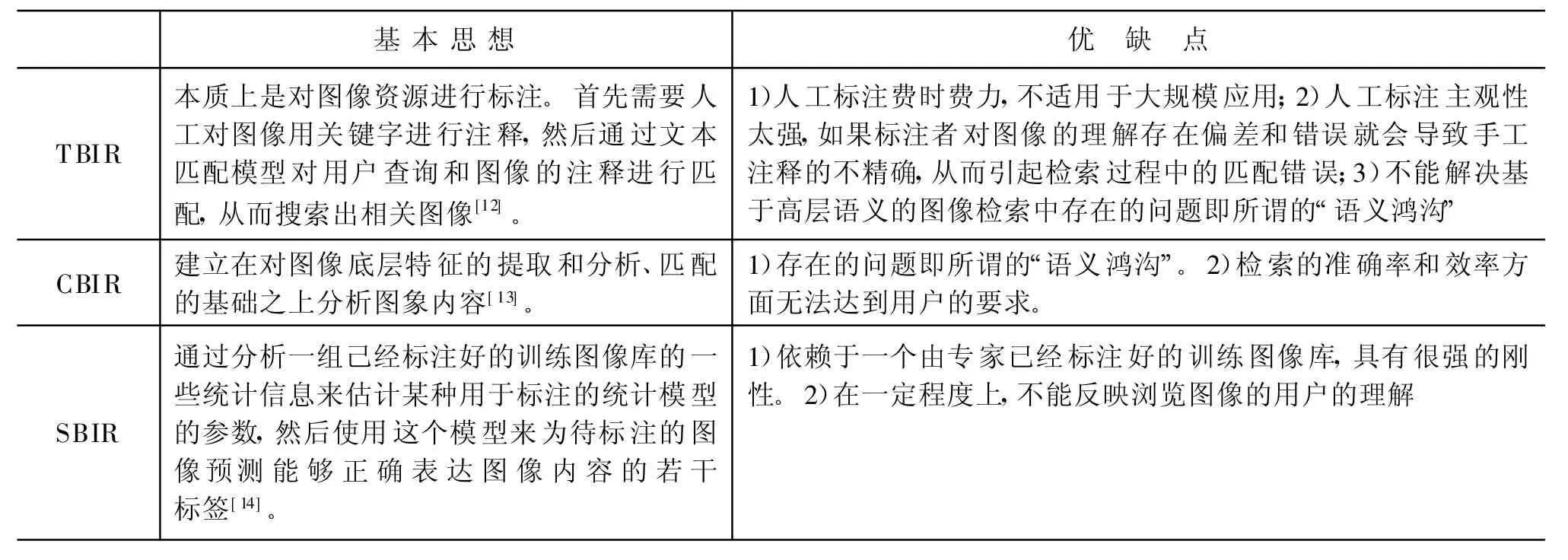
表1 图象检索技术比较
从表1可以看出,每种方法都有缺陷,但是如果能够结合TBIR的人工标注和SBIR能够解决“语义鸿沟”的优点,将会对图像资源的检索性能有更大的提高。文献[15]认为社会化网络文本就好像现实社会中某一特定群体的背景信息,使用个性化的社会化网络文本对图像进行标注能够提高人们标注图像的效率。
随着Web2.0的发展,越来越多的用户利用社会标注来组织和检索的网页、图像、信息和博客资源。但是,对于多媒体资源的标注却比较少见。目前,针对多媒体信息的检索的主要技术是将多媒体资源与对应的文本空间进行映射,转换成文本空间进行检索。
笔者认为如果把社会标注的分类特性和语义特性用在多媒体检索系统中,将会大大提高多媒体信息检索的效率。
2.2 标注方法
根据Delicious报告,在整个网络空间中被标注过的文档仅仅占到相当小的一个比率,已经被标注过的网页比率不足万分之一,这样就造成了社会标注的稀疏性问题。如何提高网页、博客、图像等资源的社会标注普及率,使社会标注更好地服务于信息资源的组织和检索,从而成为了一个必须解决的问题。社会标注主要有两种方法:一种是手工标注,广泛应用于网页、博客、图像资源的标注;另外一种就是自动标注,适用于语义网中资源和资源关系的标注。
手工标注最早出现在博客服务中,用户完成博客文章的撰写时,往往被要求自由选择一些简短的词对博客文章进行分类。目前流行的Delicious等提供社会标注服务的系统也都采用的是这种方法,允许用户可以很容易地根据自己的喜好自由选取合适的关键词对网络资源进行标注、分类,不依赖于某个受控的词汇表。显然,由于不同用户会选取不同的词来进行标注,这样会产生一义多词[16]或者一词多义[17]等问题,同时,标注可能呈现发散性而不利于信息的组织和检索。为此,许多学者致力于帮助用户推荐标注[18-20],以提供标注的准确性和收敛性。
目前,网络资源增长迅速,加之语义Web呼之欲出,手工标注不可能满足大规模标注网络资源的需要。为了解决社会标注的稀疏性,就必须通过自动或者半自动的方法在系统后台标注网络资源,或者在前台对用户进行社会标注的推荐[10-11,19-22],从而提高标注普及率,解决数据的稀疏性。自动标注方法的一般思路是在整个网络空间中寻找与当前文档内容相关的文档,从这些相关文档中汇聚成当前文档候选的社会标注;然后从这些候选的标注中按照某种标准筛选出最恰当的社会标注。文献[22]分别使用非监督机器学习聚类、基于词典的方法和基于计算相关性的实验方法三种方法对政界文档进行了自动标注,并对三种方法的应用及优缺点进行了对比。
但是有学者认为自动标注违背了Web2.0的开放精神[23],和提取关键字没有区别。需要指出的是,绝大多数的社会标注直观上可以看作是与文档内容相关的关键词;但是社会标注与传统意义上的关键词又是截然不同的。传统的关键词基本上是从文档本身抽取出来的,本质上反映了文档作者对该文档的概括;而社会标注则是在网络社会环境下产生的,是由使用者产生的,反映的是使用者对文档的理解,社会标注可以不出现在文档中,具有一定的社会属性,比如传播性。
笔者认为对网络资源进行自动标注必须依赖于既有专家分类和已有的标注空间即大众分类,以避免“冷启动”[24]问题。社会标注自动标注的一般过程如图2所示。当爬行器获取到某个网络资源时,首先判别是否和某个专家分类一致。如果一致,利用专家分类进行标注;如果不一致,则和大众分类进行比较,如果一致则取大众分类中的标签进行标注。否则,对网络资源进行标注学习(即利用提取关键字和信息抽取技术)获得该资源的标签。
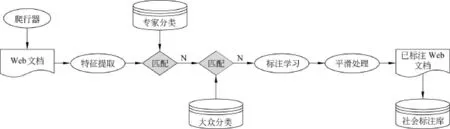
图2 社会标注自动标注过程
3 社会标注与分类
3.1 社会标注的分类特性
在Web 2.0中,每个用户可根据自己的理解自由选择一些词来标注和组织网络资源,或者参与对任一资源的推荐、评论。例如:截至2009年8月7日,豆瓣成员已经为电影《海角七号》创建了1 985个标注,使用次数最多的前八个标注为台湾电影、《海角七号》 、台湾 、爱情、范逸臣、2008、中孝介、电影[25]。如果采用传统分类方法,电影《海角七号》可以分入电影或台湾电影,而不可能分入“《海角七号》、范逸臣、中孝介”这样的类目。但是在社会标注系统中,由于使用这些标注词的用户大量存在,因此可以通过大众标注建立新的分类,这种分类就是大众化分类。和传统的资源描述方法相比,社会标注采用的是自然语言,即依据大众口头词汇对资源予以标记,不需专用词表,省去传统文献标引的查重、概念分析、查表选词等工作过程,用户标注时不受限制、自由发挥,可以从不同角度,以不同方式对同一对象发表自己的观点和评价,使得被标注对象的每一个部分都可能被关注到[26]。例如:电影《海角七号》既有“台湾电影”这样的标注,也有“爱情”(描述内容)、“2008”(上映年度)这样的标注。
综上所述,可以看出社会标注能够更全面、更彻底的揭示资源,形成的标注结果更符合大众的需求。另一方面,当这些具有相同社会标注的资源汇集在一起形成一个标注空间时,可以视社会标注为这些资源的分类类目,具有分类特性。
目前,关于社会标注具有分类特性的研究有很多[10,27-28]。但是,对于社会标注分类特性的利用却很少,大多集中在信息资源的组织方面[26-27]。笔者认为,除了社会标注的分类特性还可以满足用户搜索定位资源的需求。
3.2 社会标注的分类缺陷
随着Internet的出现,海量的网络资源使得利用受控语言进行分类和标注的可操作性变得越来越差。严格来讲,社会标注和分类是两个对立的概念,文献[29-30]对两者做了全面的比较。传统的信息资源往往依赖于由专家预先定义良好的受控词汇、分类表、词典和本体库,是自上而下的由少数资源控制者集中控制主导的分类。而社会标注是大众自发的使用用户自由选择的词对网络信息进行标识和共享,是自下而上的由广大用户集体智慧和力量主导的分类。在整个社会标注空间中,所有社会标注都是共享的,空间中没有明确的、系统的指导原则和范围注释说明。因此,不同的用户以不同的方式在使用标注词时,会产生固有的歧义。比如:Delicious中的标注“filtering”的有[1]:
◦Last.FM-Your personal music network-Personalized on line radio station
◦ InfoWorld:Collaborative know ledge gardening
◦ Wired 12.10:The Long Tail
◦Oh M y God It Burns!Practical Applications of the Philosopher's stone.For d runks.Brita filtermakes bad vodka into good vodka
◦Introduction to Bayesian Filtering
尽管这些页面都标注为“filtering”,但含义相差很大,比如用水净化伏特加酒和贝叶斯统计分析是两个完全不同的主题。再比如ANT(社会学中的Actor Netw ork Theory理论)和ANT(基于Java的build工具)。
另外,传统的自顶向下的分类具有严格的层次性,分类中最基本的词间都有关系,如有上位类、下位类。而社会标注的分类呈现出一种扁平的结构,标注之间是平等关系,标注词的选择不受任何限制,标注内容与标注对象之间的关系并不明显。层次的缺乏将导致不能很好地定位某特定标注,也没有办法揭示标注之间复杂的关系,从而容易妨碍宏观把握知识的体系结构,进而导致失去很多查找新资源的途径。当然,目前流行的社会标注服务都提供了相关标注功能,从一定程度上缓解了标注平面性所带来的缺陷,但没有从根本上解决层次缺乏的问题。因此,有学者指出,可以利用标注隐含的概念为标注建立层次关系[27]。
由上面分析可知,由于社会标注在分类上的随意性和缺乏层次性,造成社会标注在应用上存在不能快速精准定位资源的缺陷。对此,笔者认为可以考虑在用户添加标注后,利用人工智能和本体(Ontology)的方法对该标注进行分析定位,并向用户显示其所处的树状,甚至网状的知识体系结构,从而方便用户从整体上认识该问题。
4 社会标注在信息检索中的应用
社会标注具有以下4个特性:(1)标引特性:社会标注使用者(非创建者)为了方便日后对Web资源的查找进行的标引;(2)分类特性:当标注相同Web资源的社会标注汇集在一起时,无疑形成了对Web资源的大众分类;(3)资源发现特性:当用户浏览相关社会标注时,可能发现新的Web社区,这些社区聚合了具有相同主题的Web资源;(4)语义特性:社会标注是使用者对Web资源内容的一种理解、观点和概括,因此带有很强的语义。显然,这4个特性都可以帮助用户找到预期的信息,因此,社会标注对Web用户和搜索引擎都有重要的意义,可以利用社会标注来进行信息检索。一方面用户可以得到更快更准确的搜索结果,另一方面在对Web上信息资源按照各种不同的类别存储的前提下,搜索引擎自身能够更有效率地进行检索并返回结果。
4.1 社会标注与分类搜索
分类搜索是最早出现的一种网络信息检索方法,Yahoo!被认为是分类搜索的鼻祖。原理上,它与基于爬虫的搜索完全不同,比如Google。基于爬虫的搜索通过从互联网上提取的各个网站的信息(以网页文字为主)建立索引数据库,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。而分类搜索是基于人工标引的检索方法。它以科学、实用的分类目录为工具,以规范化的自然语言为类名,在对网络信息归纳、概括的基础上,以网站为单元,提供经过专家评价和人工整序的网络信息。所有网站在分类体系中同聚异分,各有所属,纵向成枝,横向成网,只需按图索骥,同一类属或相关主题的信息即可循类以求。
用户从不同的观点对网页进行标注,这些标注通常是对相关网页的很好的总结。比如:Delicious中Amazon主页的所有标注中位居前5的是shopping、am azon、books、music 和 store。这些标注准确的描述了页面,并可以看作是计算相似性的新的元数据。因此,当大众用户的社会标注汇集在一起,就形成了对资源的分类。可以利用社会标注的元数据特性来搜索和定位Web资源。文献[31]介绍了如何通过将标注、分类和浏览加以集成,以便提高终端用户进行联合检索的效率。文献[32]从标准规范到具体应用,具体描述了社会标注理念在软件组件搜索引擎中的应用情况,并指出社会标注理念可用于改进搜索质量。Hak Kim等人研究指出,通过形式化的概念分析,提出一种新方法用于在标注博客的标注中实现具有上下文关系的社会标注,并建立概念层次[27]。
笔者认为,在分类搜索中,社会标注可以用于信息资源的分类显示、标注的分类显示和搜索结果的分类显示等方面,并将提高分类的能力。但是利用社会标注进行分类搜索需要注意:由于社会标注分类没有统一的分类标准,相同标注或相似标注在不同的分类体系中的标注含义不尽相同,因此相同或相近的网页可能分属不同的标注层次。可以利用标注隐含的概念为标注建立层次关系,有了标注的层次,就可以实现分类搜索在性能和质量上的大幅度提高。但同时存在由于标注“垃圾”所带来的层次过多所造成的负担。
4.2 社会标注与语义搜索
网络搜索的实现技术有两种:一种技术是前文所提到的分类搜索;另一种技术就是全文检索。这两种搜索技术有着本质区别。而语义搜索属于全文检索的一种,与之对应的是关键字检索。目前流行的大部分搜索引擎如Google、百度都属于关键字检索。但是,由于关键字不能充分的表达语义信息,导致搜索结果无法保证语义的相关度,其效果远不能使人满意。
如何有效地填补”语义鸿沟”,实现语义搜索?语义搜索最早出现在上世纪80年代SIGIR会议论文中[33],但由于研究始终受制于语义信息处理发展水平的局限。随着自然语言处理、人工智能的发展,尤其是语义网技术的兴起与发展,语义搜索近来得以迅速发展。尽管到目前为止对语义检索在概念上仍没有统一的界定,但不同的研究却有着共同之处,语义搜索就是基于对信息资源的语义处理来实现效率更高的检索。语义信息的提取和处理可以是基于语义网方法与技术的,也可以是基于自然语言处理技术的。近两年,从语义信息提取和处理角度进行研究实现语义搜索,从而提高语义级检索效率和服务质量已经成为检索领域的研究难点和最为关键的问题。
目前,国内外对此问题的研究具有代表性的有:基于潜在语义索引(Latent Sem antic Indexing)模型的方法[34]、基于词典(Thesaurus)的方法[35-36]、基于本体和语义标注的方法[37-39]。笔者认为社会标注本身就携带有很强的语义信息,它与生俱来的低门槛、易使用等优点必将会成为填补“语义鸿沟”的最有发展潜力并且具有广阔应用前景的新技术。
在某种程度上,可以用社会标注代替传统的关键词[5,7]或与关键词一起[40]理解内容的语义并搜索语义相关的信息。基于大众化分类和社会语义信息的语义搜索在国外才刚刚起步,在国内尚处于萌芽状态,具有广阔的发展空间。将社会标注与语义搜索结合进行研究是一种新的发展态势。在国外,有少数学者围绕社会标注和语义Web做了一些研究。文献[27]研究了社会标注在语义Web中的应用,通过形式化的概念分析,构建了一种用于在标注博客的标注中实现具有上下文关系的社会标注新方法,并在标注中建立起概念层次。G ruber等人试图综合运用本体和社会标注的优势,构建社会标注中各种标注词的本体[41]。A l-Khalifa等人则提出在创建语义元数据的过程中开发社会标注的价值,指出通过分析社会标注中的各种标注,在虚拟社群中创建新的标注以及由机器抽取关键词并确立关键词之间的关系,可以进一步挖掘出社会标注的潜在价值[29]。
在国内,围绕本体与社会标注的研究也开始出现。利用语义标注工具对现有的大量信息进行标注,将使得页的内容成为机器可识别的数据,从而构成语义的基础。但是,这些标注工具绝大部分只支持手工标注,少数支持半自动标注(需要用户指导标注学习过程)。笔者认为,将社会标注与语义Web相结合,推出更为智能化、更为个性化、更易于操作以及更加有利于组织和利用信息的方法与技术,将是未来社会标注领域较为前沿的研究课题。
4.3 社会标注与搜索性能
在过去的十年中,关于提高搜索质量的研究有许多。这些研究大都集中在:1)根据查询和文档的相似性进行排序。目前,这种技术包括产生锚文本、抽取元数据、分析链接关系和挖掘用户日志等。2)根据链接关系计算得出的文档质量。
在提升互联网搜索的用户体验上已经有很多前人的工作,其中大部分都专注于改进搜索结果的相关排序,已经提出了很多模型来估计查询和文档之间的相似度[42]。在现代搜索引擎的研究中又出现了很多利用元数据来增强相似度排序性能的模型,比如文档标题[43]、锚文本[44]、以及用户查询日志[6]等,这些方法都或多或少地提升了互联网搜索的性能。另外,网页的静态质量也可被用来改进搜索。Brin和Page提出了PageRank[45]利用链接结构从网页创建者的角度去衡量网页的质量。最近也有人开始利用独立于网络链接结构的页面内容布局和用户在页面停留的时间来综合衡量网页的质量进行排序[46]。
具体来讲,在提升网页搜索效率上有两方面的表现:社会标注是不同用户对主题相关的网页资源的一种具有语义的概要性描述,可以作为相似排序的依据;同一标签的使用量可以看作是主题网页的数量规模,这个数量规模可以作为评价网页重要性的依据。文献[47]对来自社会标注系统的各种数据进行开发与抽取,构建了可以提高检索效率和改进检索性能的概念模型,同时,首次将网站的点击排名和社会标注对同一网站的标注强度结合在一起来改善搜索效果。文献[48]指出,社会标注为信息过滤和信息检索领域开创了新局面,可以被进一步应用到数字资源的相关度排序中。作者从定性的角度,构建了一个概念模型和一项评估机制,研究了标注系统Q tag的性能,并指出系统通过提供用户标注来实现资源相关度排序并支持用户使用更具有共享性的标注来表达自身的意见与观点。
4.4 社会标注与资源发现
近几年关于社会网络的研究方兴未艾,已经有一些研究工作[10,49]开始关注社会标注所具有的社区特性,但研究成果还不多。社区(Community)就是网络中结点的集合,社区中的节点之间具有紧密的连接,而社区之间则为松散的连接[50-51]。因此,可以通过分析三元组将使用相同标注的用户看作是一个用户社区,也可以将具有相同标注的资源看作是一个主题社区,还可以将具有相近语义的社会标注看作是一个标注社区。文献[10]抽取了使用率最高的350个标注进行分析,判断同一标注所标注的所有博客网页是否具有主题上的相关性。李昕[49]等人正是从社会标注形成的社区中试图自动发现社会大众共同的兴趣。从更加深刻的角度来看,具有社会标注的Web资源共享是一种知识的发现与共享。只要这些Web资源被其他用户用同一个社会标注标记过,用户就可以通过标注发现自己以前并不知道的Web资源,而这些新发现的网页对用户来说往往更有价值。基于社会标注具有的社会性和潜在的语义,构建特定领域的社会网络,并在社会网络中进行语义搜索将对搜索的查准率、召回率和排序产生深远的影响。
目前,关于社区发现的策略和方法主要有两类,一类是从社会网络本身的结构出发,也就是利用图形理论,通过一些算法来发现社区,这类算法偏向于封闭数据。比如利用图分割问题(Graph Partitioning Problem)的谱分解(Spectral bisection)的方法[52-53]、Kernighan-Liu(KL)方法[54],凝聚的和分裂的层次聚类法[50,55],基于边中介性的GN 算法[51,56]等等。另一类,从包含社会网络的资源出发,利用共现性(Cooccurrence)构建社会网络[57-58]。这一类普遍是计算两个资源共同出现的频率,当频率高于某个阈值时,认为它们属于同一社区。两类方法中谱平分、KL方法、层次聚类法需要指定社区的规模大小和社区的数目。基于边中介性的GN方法虽然不需要指定社区规模大小和数目,但是算法时间复杂度比较高O(m2n),并且该GN算法强迫任何一个节点必须属于一个社区,而不考虑是否真正有意义。
以上方法有一个共同的缺陷就是都没有考虑领域知识。共现性虽然表面上不存在以上问题,但是由于共现性存在数据规模的稀疏性问题,必须合理做平滑处理。
5 存在问题和未来研究方向
目前,虽然社会标注应用比较广泛,但是由于难以对其语义进行管理和应用,社会标注的利用还远远不能让人满意。目前在社会标注研究领域依然存在如下问题和挑战:
(1)社会标注缺乏统一规范
社会标注由用户随意标注,通常比较模糊且简短不规范,尽管可以被用户理解,但是从信息检索的角度看还不能被充分利用。笔者认为应该从两个层面规范社会标注:一是社会标注的使用。目前,社会标注只针对单个词汇的,不允许标注中出现空格。因此,在标注时,要规范标注的单复数、连接符号、词形、词性等。二是标注的层次,适当增加等级类目,以提供快速精确定位信息资源。
(2)挖掘社会标注的语义
社会标注是由大众产生,当这些标注汇集在一起时,由于缺乏规范和层次性,使得很难从大量的社会标注以及它们对应的网页中建立起层次结构的语义关系。如果要形成社会标注的语义关系,就必须需要理解社会标注与专家分类体系之间到底有怎样本质的联系,必须消除社会标注的由于不规范所造成的各种缺陷:歧义缺陷(不同学科、不同专业、不同国家和地区、不同语境中对同一标注词理解差异而形成的歧义,例如:农业领域中,如果都用“鸡毛菜”作为标注,一种意思是上海地区人们称小白菜为“鸡毛菜”,而在植物学中,“鸡毛菜”是一种亚热带行海藻,属石花菜科);同义缺陷(同一概念所用标注词不同而导致相关信息查全率的降低,例如:马铃薯、土豆、洋芋);同现缺陷(无法处理相关标注词同现而带来的复杂概念表达的欠缺,例如:红的、圆的水果);语法缺陷(无法处理不同标注词之间语法关系表达的损失,比如写文章和写的文章);权重缺陷(不同标注词出现的先后顺序表达的缺失)。目前,关于标注缺陷的研究集中在前面两个,对于后面的缺陷鲜有研究。
(3)社会标注稀疏性问题的解决
许多研究都以Delicious为研究对象,仅有很少的一部分研究主题与Web信息检索有关。文献[5]和[47]提出了修改包括标注在内的搜索算法,然而这两个研究都没有论证Delicious是否能够产生足够数量、质量来支持他们的方法。对于诸如如何利用大众分类和专家分类自动标注网络资源,提高社会标注的普及率,进而来提高标注资源的搜索这一类面向社会标注的语义搜索应用,尚未引起业界广泛的关注和研究。
(4)垃圾社会标注的处理
目前,在提供社会标注的系统中,存在大量恶意的、无用的垃圾社会标注,这些垃圾标注十分不利于对网络资源的共享、检索、定位。对于垃圾社会标注,BibSonomy主要依靠手工检查和删除[3],其他很多提供此服务的社会标注系统也是采用手工方式。因此,能够自动检测垃圾社会标注是当前社会标注利用必须解决的一个问题。
(5)标注粒度问题
如今,提供社会标注的系统可标注的对象局限于某个网页或某篇文章。但有时对人们真正有用的信息只是其中的一部分,一个段落甚至一句话,因此,用户在通过标签找到该资源后,仍需要花一定的精力去寻找对自己有价值的那部分内容。这时,可以考虑让用户定位资源中的“相关内容区域”,例如,若干个段落、若干句子、图或表等,使资源内的具体内容单元可以被区分和单独标引。当然,也要避免标注粒度太小而带来标注负担的问题。
(6)信息检索
社会标注在信息检索中的应用研究还很少,仅有的成果集中在分类搜索和利用社会标注隐含链接来计算网络资源相关性和结果排序方面。但是,关于社会标注在信息检索的用户界面表示、语义信息挖掘及可视化方面还鲜有研究。另外,将社会标注的资源发现能力应用在信息检索中也是有待进一步研究的一个热点。
6 结束语
随着提供社会标注服务系统的急剧增加,对社会标注服务的应用研究越来越成为研究领域关注的问题,目前人们已经在这方面做了大量的工作,本文对最近几年来国内外在该领域的主要成果进行了回顾与总结,综述了社会标注的研究现状,包括社会标注的标注对象、标注方法及其分类特性、在信息检索中的应用等等,并在综述的同时指出仍然存在的问题和将来进一步研究的方向。总的来说,对社会标注的研究仍然处于刚刚起步的阶段,离商业应用还有很长的路要走,仍然有大量关键的问题还需要做深入细致的研究。
[1] M athes A.Fo lksonom ies-Cooperative Classification and Communication through Shared Metadata[OL].http://www.adammathes.com/academic/computermediated-communication/folksonomies.htm l.
[2] Lambiotte R.and Ausloos M.Collaborative Tagging A s A Tripartite Network[C]//Proceedings of the International Conference on Computational Science.Sp ringer-Verlag,2006:1114-1117.
[3] Cattuto C.,Schm itz C.,Baldassarri A.,et al.Network Properties of Folksonom ies[J].AICommunications Journal,Special Issue on Network Analysis in Natural Sciences and Engineering,2007,20(4):245-262.
[4] Cattuto C,Loreto V.,Pietronero L.Sem iotic Dynamics and Collaborative Tagging[J].Proceedings o f the National Academy of Sciences,2007,104:1461-1464.
[5] Shenghua B.,Xian W.Op timizing W eb Search Using Social Annotations[C]//Proceedings of Word Wide Word(WWW 2007).New York:ACM,2007:501-510.
[6] GuiRong X.,Huajun Z.,Zheng C.,Yong Y.,et al.Optimizing Web Search Using Web Click Through Data[C]//Proceedings o f ACM International Con ference on In formation and Know ledge M anagement(CIKM 2005).New York:ACM,2005:118-126.
[7] H otho A.,J schke R.,Schmitz C.,etal.In formation Retrieval in Fo lksonom ies:Search and Ranking[C]//Proceedings of the 3rd European Semantic Web Conference(ESWC2006).M ontenegro:Springer,2006:411-426.
[8] Begelman G.,Keller P.,Smadja F.Automated Tag Clustering Imp roved Search and Exp loration in the Tag Space[C]//W orkshop of Collaborative W eb Tagging atW orld W ide Web(WWW 2006).2006.
[9] Justin J.,M ichaelC.,Benjam in M.,Heather R.,et al.Visualizing Social Links in Exp loratory Search[C]//Proceedings of the 19th ACM Con ference on H ypertext and hypermedia.New York:ACM.2008:213-218.
[10] Brooks C.,Montanez N.Imp roved Annotation o f the Blogosphere via Autotagging and H ierarchical Clustering[C]// Proceedings of W orld Wide W ord(WWW2006).New York:ACM.2006:625-632.
[11] M ishne G.AutoTag:A Co llaborative App roach to Automated Tag Assignment for W eblog[C]//Proceedings of W orld W ide W ord(WWW 2006).New York:ACM,2006:953-954.
[12] Tamura H.,Yokoya N..Image Database System s:A Survey[J].Pattern Recognition,1984,17(1):29-43.
[13] A rnold W.M.S.,MarcelW,Simone S.,et al.Content-Based Image Retrieval at the End o f the Early Years[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(12):1349-1380.
[14] Ben B..Semantic Based Image Retrieval:A Probabilistic A pp roach[C]//Proceedings o f the 18th ACM International Con ference on M ultimedia.New York:ACM,2000:167-176.
[15] Shevade B.,Sundaram H.,Lexing X..Modeling Personal and Social Network Context for Event Annotation in Images[C]//Proceedings of the Con ference on Digital libraries.New York:ACM,2007:127-134.
[16] Ching-man A.Y.,Gibbins N.,Nigel S..Tag Meaning Disambiguation through Analysis of T ripartite Structure of Folksonom ies[C]//Proceedings of the 2007 IEEE/WIC/ACM International Con ferences on Web Intelligence and Intelligent Agent Techno logy w orkshop(W I-IATW 2007).Washington,DC,:IEEE Computer Society,2007:3-6.
[17] 金澎,吴云芳,俞士汶.词义标注语料库建设综述[J].中文信息学报,2008,22(3):16-23.
[18] Robert J.,Leandro M,Andreas H,et al.Tag Recommendations in Folksonomies[C]//Proceedings of the 11th European Conferenceon Princip les and Practice of Know ledge Discovery in Databases.Warsaw,Po land:Sp ringer-Verlag,2007:506-514.
[19] Sigurb B,Roelof V.Flickr Tag Recommendation Based on Collective Know ledge[C]//Proceedings of World Wide Web(WWW 2008).New York:ACM,2008:327-336.
[20] Jian W,Brian DD.Exp lorations in Tag Suggestion and Query Expansion[C]//Proceedings of the 2008 ACM w orkshop on Search in social media.New York:ACM,2008:43-50.
[21] Fuxman A.,Tsaparas P.,Achan K.et al.Using the Wisdom of the Crow ds for Keyword Generation[C]//Proceedings of World W ide W eb(WWW 2008).New York:ACM,2008:61-70.
[22] K lebanov B.B.,Daniel D.,Beigman E..Automatic Annotation of Semantic Fields for Political Science Research[J].Journal of In formation Technology&Po litics,2008,5(1):95-120.
[23] Culotta A.,Bekkerman R.,M cCallum A..Extracting Social Netw orks and Contact In formation from Email and the Web[C]//CEAS-1,2004.
[24] Andrew I.Schein,A lexandrin Popescul,Ly le H.Ungar,David M.Pennock.Methods and Metrics for Co ld-Start Recommendations[C]//Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR 2002).New York City,New York:ACM:253-260.
[25] 豆瓣网关于电影《海角七号》的社会标注页面[OL].h ttp://www.douban.com/sub ject/3158990/?i=0.
[26] 张玫,张晓琳.Connotea中Social Tagging机制研究[J].现代图书情报技术.2007(7):1-4.
[27] Hak L.K.,Suk H.H.,Hong G.K..FCA-based App roach for M ining Contextualized Folksonomy[C]//Proceedings of the ACM Symposium on A pp lied Computing(SAC2007).New York:ACM,2007:1340-1345.
[28] A liakbary S,Khayyam ian M,Abo lhassani H.Using Social Annotations for Search Results Clustering[C]//Proceedings of the 13th International Computer Society of Iran Com puter Conference.Heidelberg,Berlin:Springer,2008:976-980.
[29] Al-Khalifa,Hugh C..Fo lksAnnotation:A Semantic M etadata Tool for Annotating Learning Resources U-sing Fo lksonom ies and Domain Ontologies[C]//Innovations in In formation Technology.Dubai:IEEE,2006:1-5.
[30] Ernst J..What A re the Differences between A Vocabulary,A Taxonomy,A Thesaurus,An Ontology,and A M eta-Model?[OL] :http://www.metamodel.com/article.php?story=20030115211223271;January 15,2003.
[31] Barrow s J.T..Features:Search Considered Integral[J].Queue,2006,4(4):30-36.
[32] VanderleiA.,Durao A.,Martins A,et al.A Cooperative Classification Mechanism for Search and Retrieval Softw are Components[C]//Proceedings of the ACM Sym posium on A pp lied Com puting(SAC2007).Seoul:ACM,2007:866-871.
[33] K raw czak D.,Sm ith P.,Shute S..EP-X:A Demonstration of Semantica lly Based Search of Bibliographic Databases[C]//Proceedings of the 10th annua l international ACM SIGIR con ference on Research and development in information retrieval(SIGIR1987).New York:ACM :263-271.
[34] Furnas G.W.,Deerw ester S..In formation Retrieval Using A Singular Value Decomposition Model of Latent Semantic Structure[C]//Proceedings of the11th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(SIG 1988).New York:ACM,1988:465-480.
[35] Voorhees E.M.Using WordNet to Disambiguate Word Senses For Tex t Retrieval[C]//Proceedings o f the 16th Annual International ACM SIGIR Con ference on Research and Development in Information Retrieval(SIGIR1993).New York:Sp ringer,.1993:173-180.
[36] Voorhees E.M.Query Expansion Using Lexical Semantic Relations[C]//Proceedings of the 16th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR1994),New York:Sp ringer,1994,61-69.
[37] Guha R,M ccool R,M iller E..Semantic search.In:Proceedings of W orld W ide Web 2003(WWW 2003)[C]//New York:ACM,2003:700-709.
[38] Zhang L,Yu Y..An Enhanced Model for Searching in Semantic Portals[C]//Proceedings of World W ide Web 2005(WWW 2005).New York:ACM,2005:453-462.
[39] May field J,Finin T..Information Retrieval on the Semantic W eb:Integrating Inference and Retrieval[C]//Proceedings of SIGIRWorkshop on the Semantic Web(SIGIR2003).New York:ACM :325-334.
[40] W u X.,Zhang L.,Yu Y..Exp loring Socia l Annotations for the Semantic Web[C]//Proceedings of World Wide Web(WWW 2006).New York:ACM,2006:417-426.
[41] G ruber T..Onto logy of Folksonomy:A Mash-up of Apples and O ranges[J].International Journal on Semantic Web and Information Systems 2007,3(1):1-11.
[42] Salton G.,M cGillM.J..Introduction to M odern Information Retrieval[M].New York:M cG raw-H ill,1983.
[43] H u Y.,Xin G.,Song R.,et al..Title Extraction from Bodies of H tm l Documents and Its App lication to W eb Page Retrieval[C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in In formation Retrieval(SIGIR2005).New York:ACM,2005:250-257.
[44] Westerveld T.,K raaijW.,H iemstra D..Retrieving Web Pages Using Content,Links,U rls and Anchors,Pages[C]//Proceedings o f TREC10.2001:663-672.
[45] Page L.,Brin S.,Motwani R,.The Pagerank Citation Ranking:Bringing O rder to the Web[R].Tech-nical report,Stanford Digital Library Technologies Project,1998.
[46] Richardson M.,Prakash A.,Bril E..Beyond Pagerank:Machine Learning For Static Ranking[C]//Proc.of W orld WideWeb(WWW 2006).New York:ACM,2006:707-715.
[47] Yanbe Y.,Jatow t A.,Nakamura S.,et al.Can Social Bookmarking Enhance Search in the Web?[C]//Proceedings o f the Con ference on Digital libraries(DL2007).New York:ACM,2007:107-116.
[48] Lee S.E.,Han S.S..Q tag:Introducing theQualitative Tagging System[C]//Proceedings of the 18th Conference on Hypertextand H yperdedia(HH 2007).New York:ACM,2007:35-36.
[49] Li Xin,Guo Lei,Y ihong,Eric Zhao.Tag-based Social Interest Discovery[C]//Proceedings of World W ide Web(WW 2008).New York:ACM,2008:675-684.
[50] Scott J.Social Netw ork Analysis:A H andbook.2nd edition[M].London:Sage Pub lications,2000.
[51] Girvan M.,Newman MEJ..Community Structure in Social and Biological Networks[J].Proceedings of the National A cademy of Sciences of the United States of America,2002,99(12):7821-7826.
[52] Fiedler M.A lgebraic Connectivity of G raphs[J].Czechoslovak Mathematical Journal,23(2):298-305.
[53] Pothen A.,Simon H.,Liou K..Partitioning Sparse Matrices with Eigenvectors of G raphs[J].SIAM Journalon Matrix Analysis and Application.1990,11(3):430-452.
[54] Kernighan W.,Lin S..An Efficient Heuristic Procedure for Partitioning Graphs[J].Bell System Technica l Journal.1970(49):291-307.
[55] Girvan M.,Newman M EJ..Finding and Evaluating Community Structure in Networks[J].Physical Review E 2004(69),arXiv:cond-mat0308217,2004.
[56] G leiser P.,Danon L..Community Structure in Jazz[DB].arXiv:cond-mat0307434,2003.
[57] Faloutsos C.,KSM,and A.Tomkins.Fast Discovery of Connection Subgraphs[C]//Proceedings of the 10th ACM SIGKDD International Conference on Know ledge Discovery and Data Mining(SIGKDD2004).New York:ACM :118-127.
