词义标注一致性检验系统的设计与实现
2010-07-18乔剑敏张仰森
乔剑敏,张仰森
(北京信息科技大学智能信息处理研究所,北京100192)
1 引言
词义标注是语料库建设中的一个关键环节。保证了词义标注的质量,语料库的应用价值才能得到体现,其应用才能可靠、高效。要保证词义标注的质量,对词义标注结果的检验和处理,是非常重要的一环,它为词义标注的质量把关。只有这个关把好了,“商品”才能体现其价值,才能“出售”,否则,“商品”即使生产出来了,也没有其使用价值。目前,词义消歧的研究已有很多,有基于词典的消歧[1],具体分为基于机读词典和义类词典的消歧,有基于规则的消歧[1],有基于语料库的消歧,具体分为有指导的消歧方法[2]和无指导的消歧方法[2],还有各种综合利用的方法[1]等,每种方法都有各自的优缺点,不能百分之百保证消歧正确。对词义消歧结果的评判,停留在用精确率、召回率等指标去评价一个词义消歧算法或系统的好坏,对词义消歧结果的校对也停留在人工校对上,而如何让机器去校对,并进行错误纠正,目前的研究还不多。基于这些问题,本文提出了词义标注一致性检验的方法研究。
2 系统概述
词义标注一致性检验,就是判断同一词语在上下文相同或相似的语境中,其词义标注是否一致。由于非多义词只有一个意思,因此检验其一致性只需看这个词语的词义标注是否是它所属的意思即可;而对多义词,有几个意思,判断其一致性比较复杂,因此我们的一致性检验针对多义词进行试验。由于名词、动词等不同词性的词语在语句中有其各自的使用规律,且同一词性的词语也因词语不同而使用规律不同,因此,不能将所有词语一概而论,要区分对待。因此,我们抽取了10个动词多义词进行小范围试验。这 10个动词多义词来自待校验语料——《人民日报》语料,该语料已进行了词语切分、词性标注及词义标注这些处理。我们的具体做法是:先将多义词的语句从待校验语料中抽取出来,通过语句相似度计算将相同或相似的语句聚类;同时另一方面,我们建立词义标注标准模式库,里面存有多义词的标注及对应的宾语集合;最后,将经过聚类的语句与标准模式库里的宾语进行匹配,如果没有直接匹配的宾语,则通过词语相似度计算去匹配,校验语料中的词义标注。系统的各模块流程图如图1所示。

图1 系统模块流程图
目前的语句相似度计算方法的研究已有很多,但经理论分析及实验证明,这些方法都不适合真实语料中的语句相似度计算。因为语料中的语句比较冗长,具有多重短句,语句格式层次多,语法不单一等特点,所以分析起来比较困难。我们研究语句相似度计算方法,应针对其所处的应用系统的实际功能需求,从待研究对象的自身特征出发。同样,我们评价一个语句相似度计算方法的好坏,也不是孤立评价,而要看它是否满足应用系统的实际需要。因此,针对语料中的语句的自身特点,本文提出了面向真实语料的语句相似度计算方法。
3 多义词语句抽取及聚类
3.1 多义词语句抽取及聚类方法分析
完整的一句话,我们抽取短句,短句是指中间有若干停顿的一个长句中的一个断句;然后在短句中抽取宾语,对宾语利用《知网》进行相似度计算,得到的结果就是两句话的相似度;依据相似度值的高低对语句聚类,聚在一块的语句为语境相同或相似的句群。
在进行语料多义词语句抽取时,我们不是以完整的一句话为单位,而是以一个短句为单位进行抽取。因为语料中完整的一句话一般都包含若干短句,按照汉语的表达习惯,每个短句又可以表达一个意思,有自己独立或完整的语法、格式,这些非多义词所在的短句对表达多义词的语境意思作用不大,甚至根本没用;且由于短句可以自成一个独立或完整的语法体系或一个意思表达体,则整个句子就是这些独立体的顺序组合体,而不是能够抽取出单一的主谓宾等,所以通过分析完整句子来研究多义词的语境意思不具有可行性,当然排除完整句子只有一个短句组成的情况,比如语料中下面的句子:
应{ying4}/v!C 老挝人民民主共和国/ns主席/n 坎代◦西潘敦/nr 的/ud 邀请/vn ,/w d 中国/ns 国家/n 主席/n 江/nrf 泽民/nrg 今天/t 乘/v!A 专机/n 抵达/v 万象/ns ,/w d 开始/v 对/p 老挝/ns 进行/vx国事/n 访问/vn
这个句子由三个短句组成,而我们要分析多义词“乘”的语境,只需抽取第二个短句即可。
在抽取了多义词所在的短句之后,经过分析发现,一句话中,在表达动词多义词某个意思的语境时,宾语起着决定性的作用。多义词的某个意思,决定了它可以带的宾语范畴,反过来,通过宾语,就可以判断这个多义词的语境。因此,在本文计算语句相似度时,先通过一些规则确定宾语范围,再对宾语进行相似度计算,算得的值代表两句话的相似度。如下两句话:
(1)他/rr 高度/d 评价/v 普里马科夫/nr在/p 任/v 俄/jn 外长/n 和/c 总理/n期间/f 为{wei4}/p!B2 发展/v 中/jn 俄/jn
关系/n 所/us 做/v!2 的/ud 大量/m 工作/vn
(2)做/v!2 群众/n 的/ud 思想/n 工作/vn
判断这两句话相似否,我们看宾语“工作”即可,两句话中“做”的语境都是“做工作”。
那么语句中的其他成分对表达动词多义词的语境意思有作用吗?通过下面的分析,我们认为这种作用不大。
按照汉语的表达习惯,一个完整正确的语句,不一定非要主谓宾俱全,或者多重主谓宾交叉出现,或者主语、宾语不是单一的词语,而是又一个短句。另外,主语与谓语之间,可能夹杂很多附加成分,如补语、状语等,因此,主语与谓语之间的衔接并不紧密,而谓语与宾语之间,宾语一般紧随谓语之后,不会相距太远,联系较紧密。《人民日报》语料中的语句,多是几个短句组成一句话,各个语句成分比较分散,主语与谓语之间的距离可能较远,很多情况主语与谓语不在一个短句内,因此分析起主语来比较困难。再者,《人民日报》文章是报道实事的,而不是关于故事、科幻等的,如:小草也会微笑,大树也会说话,因此排除一些拟人等特殊化用法,《人民日报》语料语句的主语一般是人、组织等常规主语;而且,不管主语是什么,只要是人,就可以配谓语“插”、“乘”、“吃”、“穿”等,没有哪个主语专属哪个谓语。至于语句的其他成分,如定语、状语、补语等,在《人民日报》的语料中,更是变化多端,难以分析。如:
◦无主语:
★ 而今/t ,/w d 转变/v 思路/n 做/v!2 山水/n!1 文章/n 初/f 显/v 成效/n,/w d 一个/mq 山水/n!1 相映成趣/iv 的/ud 新/a 兰州/ns 渐渐/d “/wyz 立/v!2”/w yy 了/ul 起来/vq 。/w j
★为{wei4}/p!B1 这项/r 工程/n 所/us 做/v!2 的/ud 任何/rz 努力/an ,/w d都/d 会/vu!B2 使/v!2 安放/v 我们/rr 灵魂/n 的/ud 精神/n 家园/n 更加/dc 美好/a 。/w j
◦主语与谓语不在一个短句内,相距较远:
★为此/d ,/w d 上海/ns 交巡警/j 总队/n 交通/n 科研/n 人员/n 深/d 挖/v潜力/n ,/w d 在/p 信号灯/n 上{shang5}/f!B “/w yz 做/v!2 ”/w yy 足/a 文章/n 。/w j
★问题/n 是/v l!B1 明摆着/lv 的/ud,/w d 就/d 看{kan4}/v!B2 当地/s 有关/vn 部门/n 如何/ryw 查处/v 了/y ,/w d是/vl!B1 做/v!1 表面文章/ln ,/w d 还是/c 狠抓/v 落实/vn 。/w j
综上所述,我们把判断动词多义词的意思的重点依据,放在宾语上。抽取宾语的方法是通过大量的语句分析,总结出一些规则来实现的,具体如下:
◦宾语一般为名词,有时为代词;
◦当紧挨待校验动词后面有另一个动词且再往后有“的”出现,则将这个动词与“的”之间的词语忽略掉;
例如:做/v!3 造福/v 人类/n 的/ud事/n
不要/d f 做/v!2 破坏/v 和平/a 进程/n的/ud 事/n
◦紧挨待校验动词后面的词语不是动词时,则往后找动词,将找到的第二个动词后面的词语忽略掉;
例如:还/d 应{ying1}/vu!B 看到/v 我们/rr 可以/vu 做/v!2 工作/vn 改善/v 客观/n 环境/n 的/ud 一面/f
党员/n 义务/n 卡/n 就/d 是/vl!B1农村/n 党员/n 把/p 每月/r 为{w ei4}/p!A 村民/n 群众/n 所/us 做/v!2 的/ud事/n 记/v 在/p 各自/rr 的/ud 义务/n卡/n 上{shang5}/f!B
◦如果词“的”存在,且不是语句最后一个词,则将“的”之前的词语忽略掉;
例如:为{wei4}/p!B2 厂子/n 的/ud 兴旺发达/lv 做/v!2 了/ul 不/df 少/a 力所能及/i 的/ud 工作/vn
◦如果有两个或两个以上名词连续挨着,则忽略掉前面的名词,保留最后一个名词;
例如:带/v!1 着/uz 感情/n 做/v!2 思想/n 政治/n 工作/vn
◦宾语一般出现在动词后面,所以开一个窗口,截取待校验动词后面4个词语,判断有没有名词,如果没有名词出现,则截取该动词左边两个词语,判断有没有名词,如果没有,则认为其余名词距离该动词太远,不能算作宾语,认为该动词没有带宾语。
例如:士兵/n 退役/vn 工作/vn 做/v!2得/ue 好不好/l
还有/v 很多/m 工作/vn 要/vu!2 做/v!2
另外有些语句,没有名词出现,按没有宾语处理。例如:做/v!2 得/ue 不/d f 到位/vi
经过上述规则筛选,虽然我们开设窗口,确定的是宾语的范围,但往往也只有一个宾语被抽取出来。
3.2 面向语料语句的相似度计算
确定了宾语的范围之后,两句话的相似度就归结为宾语的相似度了。本文参考并改进文献[3-7]的方法,提出了如下语句相似度计算方法。我们也对别的语句相似度计算方法做了考察并设计程序进行了实验,但发现已有语句相似度计算方法并不适合《人民日报》语料中的语句,因为《人民日报》语料中的语句有其自身特点,所以我们提出了本文的宾语相似度代表语句相似度的计算方法。首先对《知网》进行简单介绍。
3.2.1 《知网》中的知识表示方法
《知网》与一般的语义词典不同,它对词语的解释不是通过具体的文字描述,而是通过“概念”和“义原”的结构化的组织来进行[8]。在《知网》中,对词语的描述如图2:
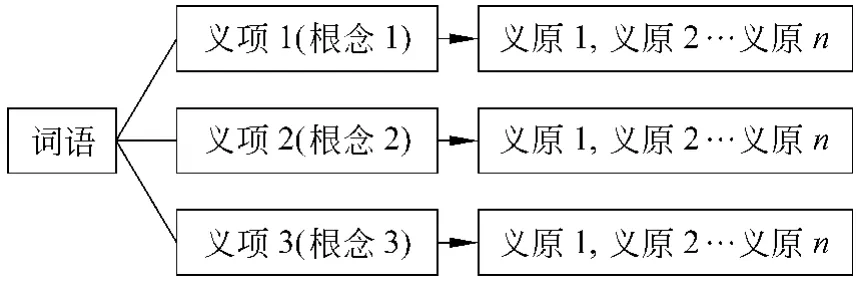
图2.《知网》词语定义结构分解图
一个词语可以有一个或多个义项解释,每个义项释义叫“概念”,而每个概念又由一个或几个“词汇”通过一定的“法则”组织在一起来定义。这些“词汇”即是“义原”。
上面提到的“法则”即是知识描述语言(Know ledge Database M ark-up Language即 KDM L),它有其自身的一套复杂的规范体系,用来组织义原对词语义项进行描述。
3.2.2 义原相似度的计算
《知网》将义原归类,每个类是一个树状结构,树的节点代表义原。由于不在同一棵树下的义原不属同一类,按本文系统要求,则处在同一棵树下的两个义原具有一定的相似度,不在同一棵树下的两个义原相似度为0。
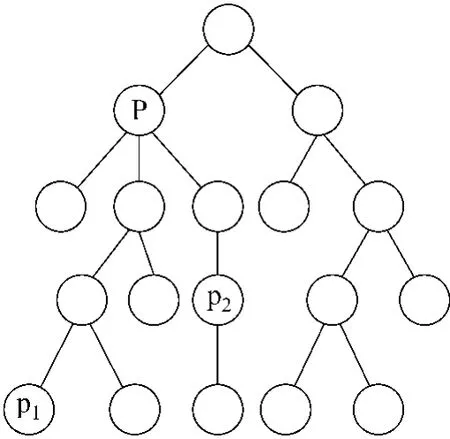
图3 义原树状图
如图3所示,P1,P2代表两个义原,P为它们向上追溯的第一个公共节点。则 P1和P2的相似度为:

α为可调节参数,len1、len2为 P 到P1、P2的路径长度,deep(P)为P节点在整个义原树中所处的层次(根节点为第一层),deep(tree)为这棵义原树的深度。
将以P为根节点的子树单独拿出来,自P节点往下分叉,每走一步,则代表P1,P2的差异多一个,且一个差异赋予一个权值α,P处相似度为1,则用1减去差异α(len1+len2),剩下的为P1和 P2的共同部分,即相似度,这个相似度对于P子树来说是绝对的;又P子树是整个义原树的一部分,所以再乘以“部分在整体中所占的权重”,即deep(P)/deep(tree),最后所得结果为P1,P2在整个义原树中的相对相似度。
3.2.3 概念相似度的计算
设概念d1由 t个义原P11,P12,P13…P1 t组成,概念d2由k个义原P21,P22,P23…P2k组成。

β1,β2为可调节参数,β1+β2=1,β1>β2。
概念相似度的计算将第一独立义原与剩余所有义原作为两部分分别计算。《知网》里,概念的第一义原描述的是概念的最主要的属性归类,也是按本系统的功能而需要提取的词语的属性归类,所以β1定义得比较大。
3.2.4 词语相似度的计算
词语W 1有n个概念定义:d11,d12,d13…d1n;W2有m个概念定义:d21,d22,d23…d2m。W1与W2的相似度取所有概念相似度中的最大值:

3.2.5 语料语句相似度的计算
语句相似度的计算归于了宾语相似度计算,而抽取出的宾语范围里,可能有不只一个宾语,则将句1的n个宾语与句2的m个宾语两两配对,进行计算,最后取一个最大值,作为两句话的相似度值,最大值对应的两个宾语,分别为两句话的宾语。
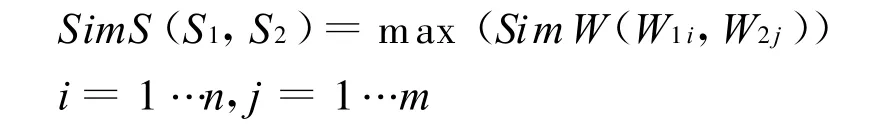
3.2.6 其他语句相似度的计算方法
目前,已有多种语句相似度计算方法,如:基于向量空间模型VSM的方法[9],基于语义依存的相似度计算方法[9],基于语义距离的句子相似度计算[9],多层次融合的相似度计算方法[10]等等。我们研究并设计了一种多层次融合的语句相似度计算方法,下面简单介绍。
Step1:关键词抽取
一般认为,一句话的关键词包括名词、代词、动词和形容词,这些词即可表达一句话的主要意思,因此首先将待计算的语句进行关键词抽取。
Step2:基于词表面特征相似度计算
一句话可以从不同的角度去研究,我们将词形、句长和结构相似度归为词表面相似度。分别计算如下:
(1)词形相似度
(2)句长相似度
(3)结构相似度
(4)基于词表面特征相似度
将(1),(2),(3)三方面的相似度综合起来,得到基于词表面特征的相似度。
Step3:语义相似度计算
计算完了词表面特征的相似度,再利用《知网》计算语句的深层相似度,即语义方面的相似度。
Step4:词表面特征和语义相似度的结合
我们从表层和里层分别考察完相似度后,将词表面特征相似度和语义相似度结合起来,得到语句相似度。
经过实验发现,这种语句相似度计算方法比较适合语句结构比较规范,语句成分比较少的单句,对《人民日报》语料的复杂语句并不适合。如:“我爱吃香蕉”和“我喜欢吃苹果”的相似度为1.000 000;而对《人民日报》里的语句,如:“他/rr 高度/d评价/v 普里马科夫/nr 在/p 任/v 俄/jn外长/n 和/c 总理/n 期间/f 为{wei4}/p!B2 发展/v 中/jn 俄/jn 关系/n 所/us做/v!2 的/ud 大量/m 工作/vn ”和“为{wei4}/p!B2 基本/ad 实现/v 两/m 纲/n目标/n 做/v!2 了/ul 大量/m 工作/vn ”的相似度为0.439 008。
因此,对《人民日报》语料,我们设计了宾语相似度代表语句相似度的方法。
4 词义标注的一致性检验
4.1 标准模式库
本系统的设计中,需要一个库作为模板,来进行一致性检验。对于特定的谓语,宾语既然决定了语句语境,则我们以宾语为基础,建立标准模式库。
经过对大量语句的分析,我们发现,多义词的每个释义对应的宾语有一定的规律,如:“做”有三个释义,“(1)制做;写作”对应的宾语大多为与书、文章有关的和具体物品;“(2)从事某种工作或活动”对应的宾语大多为事件、活动之类的;“(3)充当,担任;用做;结成”对应的宾语大多为人物之类的。并且,对于特定的《人民日报》语料,因语言有其自身特点,许多宾语更是经常、规律地出现。对照着聚过类的语句,我们将语境相同或相似的语句的宾语放在同一个释义下,但同一个释义下的宾语对应的语句语境不一定相同或相似。因此,我们将多义词释义及其对应的宾语作为模式库构建的元素,其组织结构如表1所示。每个多义词的模式库都放在一个独立的文本文件里。
当然,汉语语言变换很多,几个月的《人民日报》语料不可能将多义词每个释义对应的宾语全部列举,我们在一致性检验时,如果没有直接匹配的宾语,则进行词语相似度计算,与模式库里的某个宾语相似度最高,则跟这个宾语是属于同一类的宾语,则匹配这个宾语归属的释义。所以,模式库里的每个宾语既可直接匹配,又可看作是某一类宾语的代表、标识,每个宾语可作为一个模板。
总之,标准模式库将语境相同或相似的语句的宾语放在同一释义下,可直接匹配,也可通过相似度计算匹配,保证了后面一致性检验的可操作性。

表1 模式库结构
4.2 一致性检验
系统设计的最后一步是一致性检验。聚在一块的句群是语境相同或相似的,将每个语句按照前述的方法抽取出宾语,与标准模式库对照,如果直接与模式库宾语相匹配,则取该宾语对应的释义;如果没有直接匹配到模式库宾语,则将抽取出的宾语与库里的宾语进行相似度计算,取相似度最高的值对应的模式库宾语所属的释义,相当于与此宾语模板相匹配。取出语料原始标注与匹配到的模式库标注对照,校验结果分6种情况,各种情况及其处理办法如下描述所示:


对于聚类的句群及系统校验后显示在界面上的信息,人工也可进行检验并再纠正。界面上的信息经确认后:对于改正标注之后的语句,写回到原语料,替换原语句;对于校验过程中发现的新宾语,追加到模式库里,扩充、完善模式库。
系统对上述6种情况分别有多少语句及校验的总语句数进行统计,并显示在界面上,便于我们总结 、研究 。
5 实验及结果分析
5.1 语句聚类实验结果
实验中公式所用参数取值为:α=0.02,β1=0.7,β2=0.3。α,β1和 β2的值根据我们系统对词语相似程度的要求,经过对公式的演算推导得出;判定两句话相似的阈值取为0.6,也是根据对大量相似语句的相似度值进行考察总结得出;“*”表示一句话的开始;“#”符号后面的词语表示程序判断出的作为两句话宾语的词语。本文抽取“做”这个多义词的语句进行测试。实验结果的截图如图4、图5所示。

图4 “做”相似语句聚类结果1

图5 “做”相似语句聚类结果2
5.2 一致性检验实验结果
一致性检验的各种情况及统计信息如图6、图7所示。
图6 校验结果显示

图7 统计结果
5.3 结果分析
本文中,我们研究了宾语相似度代表语句语境相似度的计算方法,从语句聚类的实验结果可以看出,效果总体上是令人满意的。我们的聚类要求是:语境相同的可以归为一个大类,也可以归为不同的类,这是因为《知网》对词语的定义有其自身规则,我们是利用《知网》,而不是《知网》为我们的需求而量身定做的,所以我们主观认为相似的词语,计算出的相似度也可能不高,如“工作”和“事情”,相似度为0.367 500。所以以“工作”、“事情”为宾语的语句归在了两个类里,但一个类里的是相似的。下面本文逐层对不正确的结果进行分析。
从宾语抽取的的准确与否说起:
1)抽取不准确而导致计算错误的,有以下几种情况:
◦是宾语抽取规则不完备,有待于进一步研究、完善和扩展;
◦语料中的词性标注错误,导致宾语抽取不准确,这样的情况比较少;
◦语料中抽取出的语句也可能不完整,动词与宾语没在一个短句里,但这样的情况是很少数的。
2)抽取准确,计算不准确的,情况又有以下几种:
◦如上所述,《知网》中对词语的定义不是为我们的需求量身打造,所以我们认为不相似的词语,而计算出的结果却是相似度高的,而我们认为相似的词语,则结果可能是相似度偏低;
◦抽取出的宾语可能不是一个,所以非真正宾语对计算也具有干扰性;
◦《知网》对词语定义也存在不合理情况,也会导致词语相似度计算不准确。
在一致性检验中,“做”总共有1 253句,为了方便观察结果,我们在校验之前,人工改造并记录了一些各种情况的语句,按照前述情况的顺序,校验结果如表2所示。
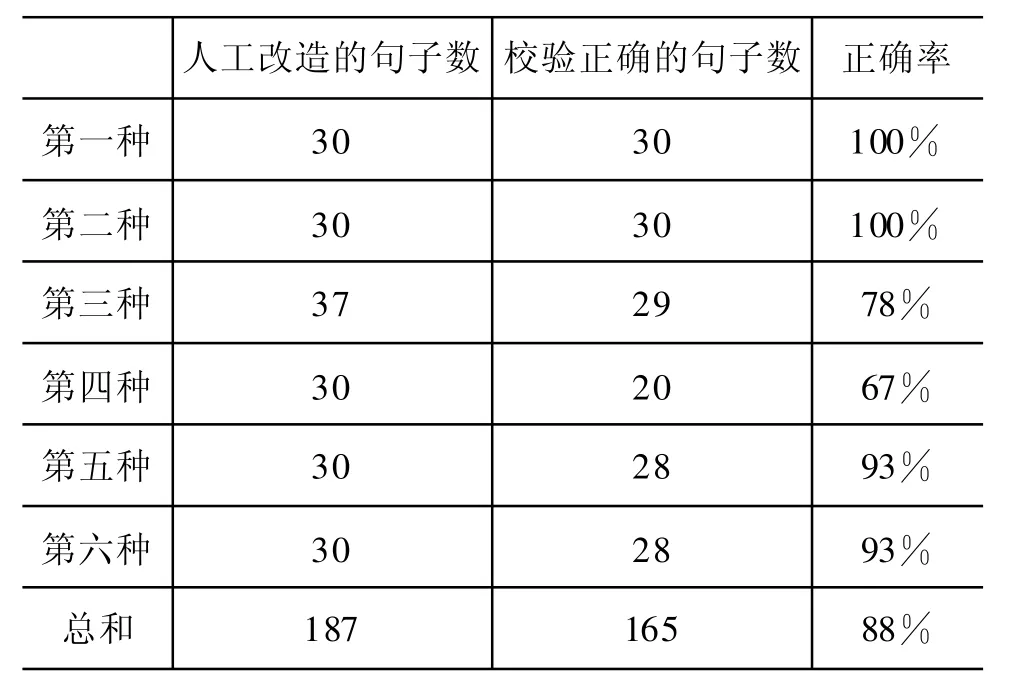
表2 校验结果统计
影响校验结果的因素主要有三个:◦宾语抽取的准确否;◦相似度计算的合理性;◦模式库宾语的代表性及规模。宾语抽取准确是前提,如果不准确了,自然结果不准确;宾语抽取准确了,相似度计算不合理,也找不到正确的义项标注;相似度计算准确了,模式库宾语不具有代表性或宾语数量不够,也同样计算不出合理的相似度值,进而匹配不到正确的标注。
由表可见,结果总体是令人满意的。同时,我们会在上述主要因素及其他方面加强改进。
6 总结
本文在语句聚类,标准模式库建立,一致性检验阶段,非常重要的一个思想是,对一个指定动词,宾语代表了其语境意思,代表了其释义。另一个重要工作是相似度的计算,本文分析研究真实语料的语句特点,研究了现有的相似度计算方法,发现了两者的不相适应性,具体情况具体分析,进而提出了本文的计算方法,将其放在本系统的应用中,效果令人满意。今后,本文需要更多的研究语料中的构句规则、语法、词语信息等方面的内容,完备宾语抽取规则;另外,还要进一步完善、扩展标准模式库;同时,进一步改进相似度计算。通过各方面改进,使系统功能更强。
[1] 李生,张晶,赵铁军,姚建民.词义消歧研究的现状与发展方向[J].计算机科学,2001,28(9):95-98,封四.
[2] 商敏.汉语词义消歧研究[D].大连:大连理工大学硕士论文,2007.
[3] 刘群,李素建.基于《知网》的词汇语义相似度的计算[OL].http://www.keenage.com.
[4] 张奇,黄萱菁,吴立德.一种新的句子相似度度量及其在文本自动摘要中的应用[J].中文信息学报,2005,19(2):93-99.
[5] 王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2005,19(1):12-29.
[6] 李峰,李芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[7] 张玉娟.基于《知网》的句子相似度计算的研究[D].北京:中国地质大学硕士论文,2006.
[8] 董振东.《知网》.http://www.keenage.com[DB/OL].
[9] 赵巾帼,徐德智,罗庆云.汉语句子相似度计算方法比对之研究[J].福建电脑,2007,10:51,68.
[10] 南铉国,崔荣一.基于多层次融合的语句相似度计算模型[J].延边大学学报,2007,33(3):191-194.
