基于RSCU与QRSCU的F/10和 G/11木聚糖酶家族密码子偏好性的比较
2010-03-15赵静静齐斌丁利娟唐旭清
赵静静, 齐斌,2, 丁利娟,3, 唐旭清*
(1.江南大学理学院,江苏无锡214122;2.无锡职业技术学院,江苏无锡214122;3.无锡市青山高级中学,江苏无锡214100)
木聚糖酶是可将木聚糖降解成低聚木糖和木糖的一类酶的总称,它可以将木聚糖降解为寡聚木糖、木糖和少量单糖,其主要分为 F/10和 G/11两个家族。F/10和 G/11木聚糖酶家族在空间结构上属于两种不同的折叠类型。F/10家族木聚糖酶三维结构为(α/β)8折叠桶类型。G/11家族木聚糖酶三维结构为β折叠片为主所构成的单个结构域。目前木聚糖酶广泛应用于工业领域,比如制浆造纸、饲料加工、酿酒、烘焙食品、制备功能性低聚糖、临床、环境保护等领域。
由于木聚糖酶在工业应用方面的重要作用,长期以来,人们对其做了大量研究[1-5]。在对F/10和G/11木聚糖酶的研究中,其重要的内容之一便是对其同义密码子的研究。比如,刘亮伟等人[1,3,5]用生物信息学的方法,研究了 F/10和 G/11木聚糖酶氨基酸二联体同最适温度、最适p H值的关系、木聚糖酶的分子进化以及用主成分分析的方法对F/10和 G/11木聚糖酶分类等一系列的问题。作者则是综合了石秀凡等人[6]基于氨基酸编码方法下对同义密码子偏好性及朱平等人[7-8]基于拟氨基酸基因编码方法下对同义密码子的偏好性的研究成果,运用两种编码方法,进行编程,分别计算RSCU和QRSCU,得出两种编码方法下同义密码子都偏好使用以g/c结尾的密码子,而且基于拟氨基酸基因编码方法下,其结论更加明显。
1 材料与方法
1.1 数据库的构建与编程
根据文献[1]中Swiss-Prot数据库中木聚糖酶的登录号,寻找 GenBank和 EMBL-EBI数据库中对应的编码序列,建立木聚糖酶基因的编码序列库.文中取了F/10木聚糖酶家族的28条序列,总共包含13 790个密码子,GC占编码区碱基总数的48.2%。G/11木聚糖酶家族的33条序列,总共包含12 077个密码子,GC占编码区碱基总数的50.6%。
F/10木聚糖酶的编码序列库(28条序列):O59859,P07528,P26223, P29417, P33559,P40942, P40943, P40944, P45703, P51584,P56588,Q60041,Q60042,Q00177,Q60037,Q12603,P14768, P07986, P10478,P23556,P23360, P07529, P48789, P49942, P23030,O60206,P23557。
G/11木聚糖酶的编码序列库(33条序列):O43097,P00694,P09850,P17137, P18429,P23031,P26220, P26515, P29127, P33557,P33558,P35811, P36217, P36218, P45705,P45796,P48791, P48824, P54865, P55328,P55329,P55330, P55331, P55332, P55333,P55334,P55335,P77853,P83513,Q06562,Q12667,Q53317。
文中所用的数据都是用C语言编程完成的。
1.2 密码子的相对使用度
1.2.1 氨基酸编码方法及RSCU 同义密码子是指编码同一种氨基酸的两个或两个以上的密码子。自遗传密码破译以来大量的研究发现,同义密码子的使用与基因表达存在着密切的关系。作者用密码子的相对使用度来研究密码子的偏好性。
由文献[6]知,基于氨基酸编码方法下的同义密码子的相对使用度(RSCU)计算公式为:RSCU=同义密码子的观测数/同义密码子的期望数,同义密码子的期望数=氨基酸的同义密码子出现次数/编码此种氨基酸的同义密码子数。
1.2.2 拟氨基酸基因编码方法及QRSCU 基因组遗传密码字典自确立以来,在40年的科学研究中被不断的扩充和完善。作为生命组成不可缺少的一个部分,该遗传密码显示出了它在进化上的复杂性和适应性,但也充分地显示了人类在遗传密码认识上的局限性。正因为这些原因,人们完全揭示遗传密码内在特性的道路还很漫长,还需要进行不断的研究和尝试。目前,有学者从另一角度对此进行了大量探讨,其中拟氨基酸基因编码方法就是一个重要形式。
定义1:令WC≡{tgg,tgt,tga,tgc},RS≡{agg,agt,aga,agc},LF≡{ttg,ttt,tta,ttc},M I≡{atg,att,ata,atc},ED ≡{gag,gat,gaa,gac},-Y≡{tag,tat,taa,tac},KN ≡{aag,aat,aaa,aac},QH≡{cag,cat,caa,cac},S’≡{tcg,tct,tca,tcc},R’≡{cgg,cgt,cga,cgc},L’≡{ctg,ctt,cta,ctc}。Let ZU={G,V,ED,A,WC,LF,-Y,S’,RS,M I,KN,T,R’,L’,QH,P},则ZU称为拟氨基酸集,这里,-Y为新终止子,但是(tga∈)WC不是终止子[7]。
由文献[8]知,基于拟氨基酸基因编码方法下同义密码子的相对使用度(QRSCU)也相应被提出,其计算公式为:QRSCU=同义密码子的观测数/同义密码子的期望数,同义密码子期望数=拟氨基酸的同义密码子出现次数/编码此种拟氨基酸的同义密码子数。
1.3 密码字的偏好性强度划分
与[1]的强度划分相似,计算出两个家族中编码序列在氨基酸编码方法和拟氨基酸基因编码方法下密码子偏好性数值后,为了区分两个木聚糖酶家族在两种编码方法下密码子偏好性差异及分析密码子偏好使用情况,分别对其进行了强度划分.因此做如下规定:
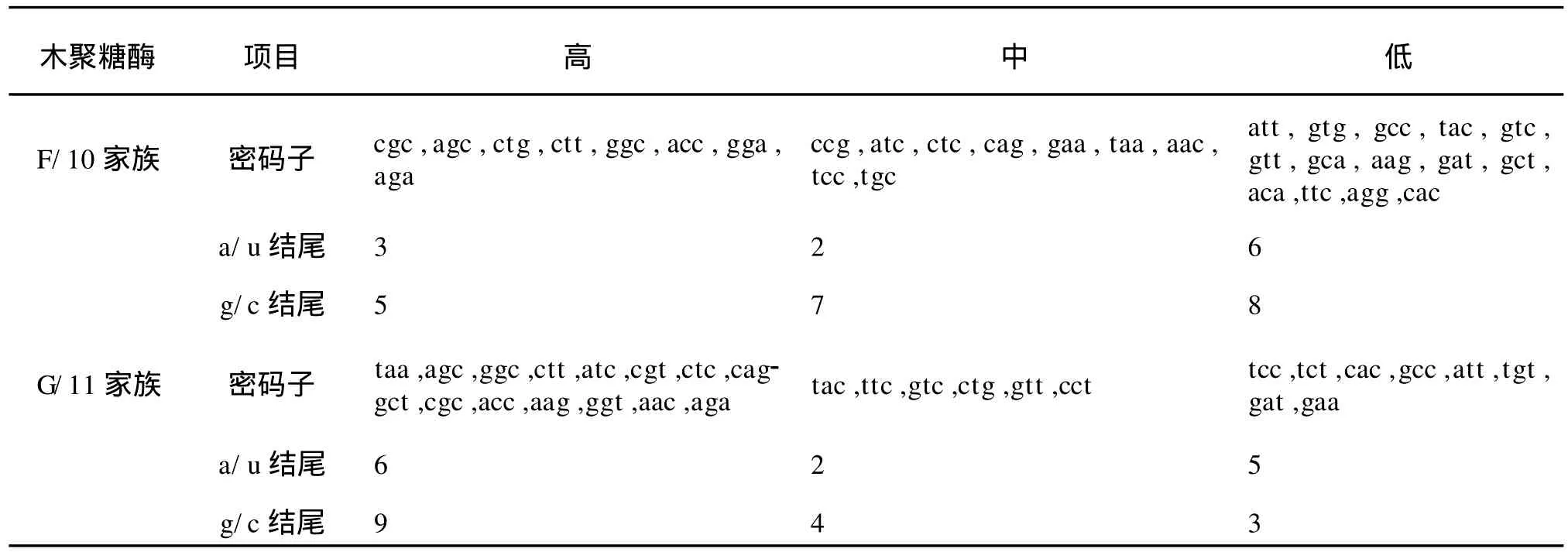
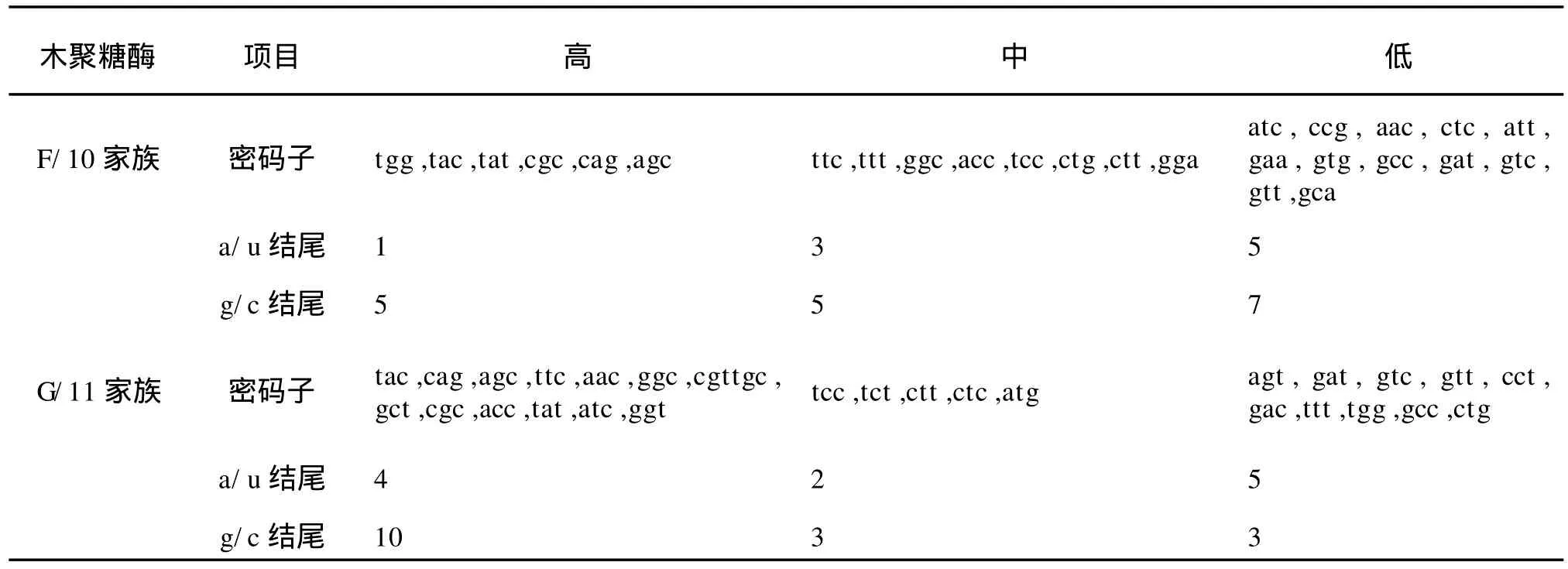
1)基于氨基酸编码方法下以 G/11家族中偏好性最高值2.0和最低值0.181 8为标准,将这两个数据之间的差距划分为4个等级,划分如下:A无偏好性:RSCU≤1.0;B低度偏好性:1.0 2)基于拟氨基酸基因编码方法下以F/10家族中偏好性最高值2.808 899和 G/11家族中偏好性最低值0.010 8为标准,将这两个数据之间的差距划分为 4个等级,划分如下:A无偏好性:QRSCU≤1.05;B低度偏好性:1.05≤QRSCU≤1.3;C中度偏好性:1.3≤QRSCU≤1.4;D高度偏好性:QRSCU≥1.4。见表3、4。 根据1.1节中所建立的数据库,包括 F/10木聚糖酶的编码序列库(28条序列)和 G/11木聚糖酶的编码序列库(33条序列),按1.2节所给出的公式进行计算,得出相对使用度RSCU和拟相对使用度QRSCU表,见表1~2。 表1 基于氨基酸编码方法下F/10和G/11的密码子偏好情况Tab.1 Codon bias of F/10 and G/11 based on amino acids coding method 续表1 续表1 表2 基于拟氨基酸基因编码方法下F/10和G/11的密码子偏好情况Tab.2 Codon bias of F/10 and G/11 based on quasi-amino acids coding method 续表2 续表2 高度和中度偏好密码子类型见表3~4。 表3 基于氨基酸编码方法下F/10与G/11木聚糖酶密码子偏好性Tab.3 Codon bias of F/10 and G/11 xylanase based on amino acids coding 表4 基于拟氨基酸基因编码方法下F/10木聚糖酶密码子偏好性Tab.4 Codon bias of F/10 and G/11 xylanase based on quasi-amino acids coding 由表1所列出的基于氨基酸编码方法下F/10木聚糖酶家族和G/11木聚糖酶家族的同义密码子的相对使用情况可以看出: 1)在 F/10木聚糖酶家族中除了{R,D,E,Stop}家族偏好使用a/t结尾的密码子外,所有的氨基酸均偏好使用以g/c结尾的密码子。而在 G/11木聚糖酶家族中除了以g/c结尾的密码子偏好使用外,有6种氨基酸偏好使用以t结尾的密码子。 2)F/10与 G/11木聚糖酶家族中,在由两个密码子组成的氨基酸中,其中{a,t,c}{a}{c}所含密码子数量远大于{a,t,c}{a}{t};{g}{a}{t}所含密码子数量远大于{g}{a}{c};{a,c}{a}{g}所含密码子数量远大于{a,c}{a}{a};{g}{a}{a}所含密码子数量远大于{g}{a}{g}。 由表3所列出的氨基酸编码方法下 F/10与G/11木聚糖酶家族的密码子的偏好性还可以得出如下结论: 1)两个家族都偏好使用以g/c结尾的密码子,与以前的研究结果一致。F/10家族中除了ctg,gga外高度偏好性的密码子都包含在 G/11中。这说明F/10相对集中在几种主要的密码子,而 G/11密码子偏好性种类更加多样,这与分子进化的结果相互印证。 2)F/10家族17个主要偏好性密码子(高度、中度)中有12个以 g/c结尾,只有5个以a/t结尾,显示了氨基酸偏好使用以g/c结尾的密码子。G/11家族21个主要偏好性密码子(高度、中度)中有13个以g/c结尾,只有8个以a/t结尾,也显示了密码子偏好使用以g/c结尾的密码子。当然,这种效果还不是太好。 3)虽然高度偏好的密码子g/c结尾的大于a/t结尾的,但随着密码子偏好程度降低,以a/t结尾的密码子数目与以g/c结尾的密码子数目趋于接近,而且以上结果与[1]中结果一致。 由表2所列出的拟氨基酸基因编码方法下F/10与G/11木聚糖酶家族的密码子偏好性可以看出: 1)F/10和 G/11木聚糖酶家族在{G,RS,S’,-Y,T,KN,QH,LF,MI,V,L’,WC}这些拟氨基酸家族中都偏好使用以g/c结尾的密码子。拟氨基酸{A,R’,P}在F/10木聚糖酶家族中偏好使用以g/c结尾的密码子,而在 G/11木聚糖酶家族偏好使用以t结尾的密码子,以g/c结尾的密码子次之。 2)F/10木聚糖酶家族中除了{ED}外,所有拟氨基酸都偏好使用以g/c结尾的密码子,G/11木聚糖酶家族中除了{R’,ED,A,P}外,所有拟氨基酸都偏好使用以g/c结尾的密码子。 3)F/10与 G/11木聚糖酶家族中,当密码子的第一位碱基为a时,则拟氨基酸偏好使用以c结尾的密码子。 4)F/10木聚糖酶家族中,除了第二位碱基为g外,当第一位碱基为t时,拟氨基酸偏好使用以c结尾的密码子。而 G/11木聚糖酶家族中,当第一位碱基为t时,所有的拟氨基酸都偏好使用以c结尾的密码子。 5)F/10与 G/11木聚糖酶家族中,当第一位碱基为g时,除了第二位碱基为t的密码子外,其它的都避免使用以g结尾的密码子. 由表4所列出的拟氨基酸基因编码方法下F/10与 G/11木聚糖酶家族的密码子偏好性还可以得出如下结论: 1)两个家族都偏好使用以g/c结尾的密码子,这与以往研究结果一致。F/10家族中除了tgg外高度偏好性的密码子都包含在 G/11中。说明F/10相对集中在几种主要的密码子,而 G/11密码子偏好性种类更加多样,这与分子进化的结果相互印证。 2)F/10家族14个主要偏好性密码子中(高度、中度)有10个以 g/c结尾,只有4个以a/t结尾,显示了拟氨基酸基因偏好使用以g/c结尾的密码子。G/11家族19个主要偏好性密码子中(高度、中度)有13个以g/c结尾,只有6个以a/t结尾,也显示了拟氨基酸偏好使用以g/c结尾的密码子,且该结果比在氨基酸编码方法下效果还要好; 3)虽然高度偏好的密码子g/c结尾的大于a/t结尾的,但随着密码子偏好程度降低,以a/t结尾的密码子数目与以g/c结尾的密码子数目趋于接近,而且以上结果也与[1]中结果一致。 首先,根据上面的研究,给出基于氨基酸编码方法与基于拟氨基酸基因编码方法下的密码子偏好情况对比见表5。 表5 两种编码方法下密码子偏好性对比Tab.5 Codon bias comparison of two kinds of coding method 1)基于氨基酸编码方法下F/10家族有{D,E,Stop}3种氨基酸偏好使用以a/t结尾的密码子,其余的都偏好使用g/c结尾的密码子。基于拟氨基酸基因编码方法下 F/10家族只有{ED}偏好使用以a/t结尾的密码子,其余的都偏好使用g/c结尾的密码子; 2)基于氨基酸编码方法下 G/11家族有{L,A,P,R,C,D,E,Stop}八种氨基酸偏好使用以a/t结尾的密码子外,其余的都偏好使用g/c结尾的密码子。基于拟氨基酸基因编码方法下 G/11家族中除了{R’,ED,A,P}四种拟氨基酸偏好使用以a/t结尾的密码子外,其余的都偏好使用g/c结尾的密码子; 3)两种编码方法都体现了氨基酸更偏好使用以g/c结尾的密码子,而且以c结尾的密码子比以g结尾的密码子更偏好使用,且两种编码方法下F/10木聚糖酶的密码子偏好性都优于 G/11木聚糖酶的密码子偏好性; 4)由表5我们还可以得出基于拟氨基酸基因编码方法比基于氨基酸编码方法能更好的体现密码子偏好性,与文献[8]的结论一致。 同义密码子的使用并非随机的均匀的,其具有一定的偏好性,作者通过计算RSCU与QRSCU分析了 F/10及 G/11木聚糖酶家族密码子偏好性,结果发现: 1)密码子偏好性与生物进化密切相关。由表3与表4可知,两种编码方法下几乎全部的 F/10高度偏好性密码子都包含在 G/11中,G/11比F/10家族中偏好性密码子种类多。同样的由表5可以看出无论是基于哪种编码方法 F/10家族都比 G/11家族更偏好使用以g/c结尾的密码子。这些性质均可用文献[2]中分子进化的观点说明,因为F/10在进化时间上相对于 G/11较长,所以其偏好性趋于均衡; 2)拟氨基酸基因编码方法更能体现密码子的偏好性。文中的表格显示了基于拟氨基酸基因编码方法能更好的体现密码子偏好性,与文献[8]的结论一致。该结论充分验证了拟氨基酸分类对于 F/10和G/11木聚糖酶家族在偏好性上是充分显现的,且与分子进化的观点是一致的,从而对研究蛋白质结构并预测蛋白质的相互作用的分子机制有着重要帮助。 [1]刘亮伟,秦天苍,翟继,等.F/10及 G/11木聚糖酶家族密码子偏好性分析[J].河南农业大学学报,2008,42:223-227.LIU Liang-wei,QIN Tian-cang,ZHAI Ji,et al.Analysis on codon bias in F/10 and G/11 xylanase[J].Journal of Henan Agricultural University,2008,42:223-227.(in Chinese) [2]刘亮伟,秦天苍,王宝,等.木聚糖酶的分子进化[J].食品与生物技术学报,2007,26:110-116.LIU Liang-wei,QIN Tian-cang,WANGBao,et al.Molecular evolution of xylanase[J].Journal of Food Science and Biotechnology,2007,26:110-116.(in Chinese) [3]苏玉春,陈光,白晶,等.木聚糖酶的产生条件优化[J].吉林农业大学学报,2008,30:793-796.SU Yu-guang,CHEN Guang,BAI Jing,et al.Production and growth condition of xylanase fromAspergillus niger[J].Journal of Jilin Agricultural University,2008,30:793-796.(in Chinese) [4]邵蔚蓝,毛忠贵,薛业敏.极端耐热木聚糖酶基因在大肠杆菌中的高效表达[J].食品与发酵工业,2003,29:20-25.SHAO Wei-lan,MAO Zhong-gui,XUE Ye-min.Expression of xylanase B gene of thermotoga maritima inEscherichia coli[J].2003,29:20-25.(in Chinese) [5]刘亮伟,秦天苍,刘新育,等.热稳定性木聚糖酶结构模拟及分析[J].河南农业大学学报,2007,41:304-308.LIU Liang-wei,QIN Tian-cang,LIU Xin-yu,et al.Modelling and analysis of the structure of thermo stable xylanase[J].Journal of Henan Agricultural University,2007,41:304-308.(in Chinese) [6]管维红,徐振源,朱平.用非线性预测方法研究蛋白质序列的特性(Ⅱ)[J].食品与生物技术学报,2008,27(2):71-75.GUAN Wei-hong,XU Zhen-yuan,ZHU Ping.Nonlinear Prediction Analysis of Properties in protein sequences(Ⅱ)[J].Journal of Food Science and Biotechnology,2008,27(1):103-105.(in Chinese) [7]ZHU Ping,TANG Xu-qing,XU Zhen-yuan.The structure analysis of protein sequence based on the quasi-amino acids code[J].Chinese physics B,2009,1:363-367. [8]朱平,高雷,徐振源.基于拟氨基酸编码方法下的同义密码子的偏好性仍与结合强度密切相关[J].物理学报,2009,6:714-719.ZHU Ping,GAO Lei,XU Zhen-yuan.The usage degree of synonymous codon is close correlated with the strength of combination based on the quasi-amino acid coding[J].Acta Physica Sinica,2009,6:714-719.(in Chinese) [9]石秀凡,黄京飞,柳树群,等.人类基因同义密码子偏好的特征以及与基因 GC含量的关系[J].生物化学与生物物理进展,2002,29:411-414.SHI Xiu-fan,HUANGJing-fei,LIU Shu-qun,et al.The features of synonymous codon bias and GC-content relationship in human gene[J].Prog Biochem Biophvs,2002,29:411-414.(in Chinese) [10]杨潇,胡军,陈祥贵.人类蛋白编码基因外显子谱和同义密码子偏好的研究[J].西华大学学报:自然科学版,2008,27.YABG Xiao,HU Jun,CHEN Xiang-gui.Study on the relationship between exonic pattern and codon bias of human protein-coding gene[J].Journal of Xihua University:Natural Science,2008,27(2):79-82.(in Chinese) [11]顾万君,马建民,周童,等.不同结构的蛋白编码基因的密码子偏好性研究[J].生物物理学报,2002,18:81-86.GU Wan-jun,MA Jian-ming,ZHOU Tong,et al.Codon usage in genes coding for protein swith different tertiary structures[J].Acta Biophysica Sinica,2002,18:81-86.(in Chinese) [12]LIU LW,ZHANGJ,CHEN B,et al.Principal component analysis in F/10 and G/11 xylanase[J].Biochem Biophys Res Commum,2004,322:277-280. [13]Xie T,Ding D.The relationship between synonymous codon usage and protein structure[J].FEBS letters,1998,434:93-96. [14]管维红,徐振源,朱平.用非线性预测方法研究蛋白质序列的特性(Ⅰ)[J].食品与生物技术学报,2008,27(1):71-75.GUAN Wei-hong,XU Zhen-yuan,ZHU Ping.Nonlinear prediction analysis of properties in protein sequences(Ⅰ)[J].Journal of Food Science and Biotechnology,2008,27(1):71-75.(in Chinese)2 结果与分析
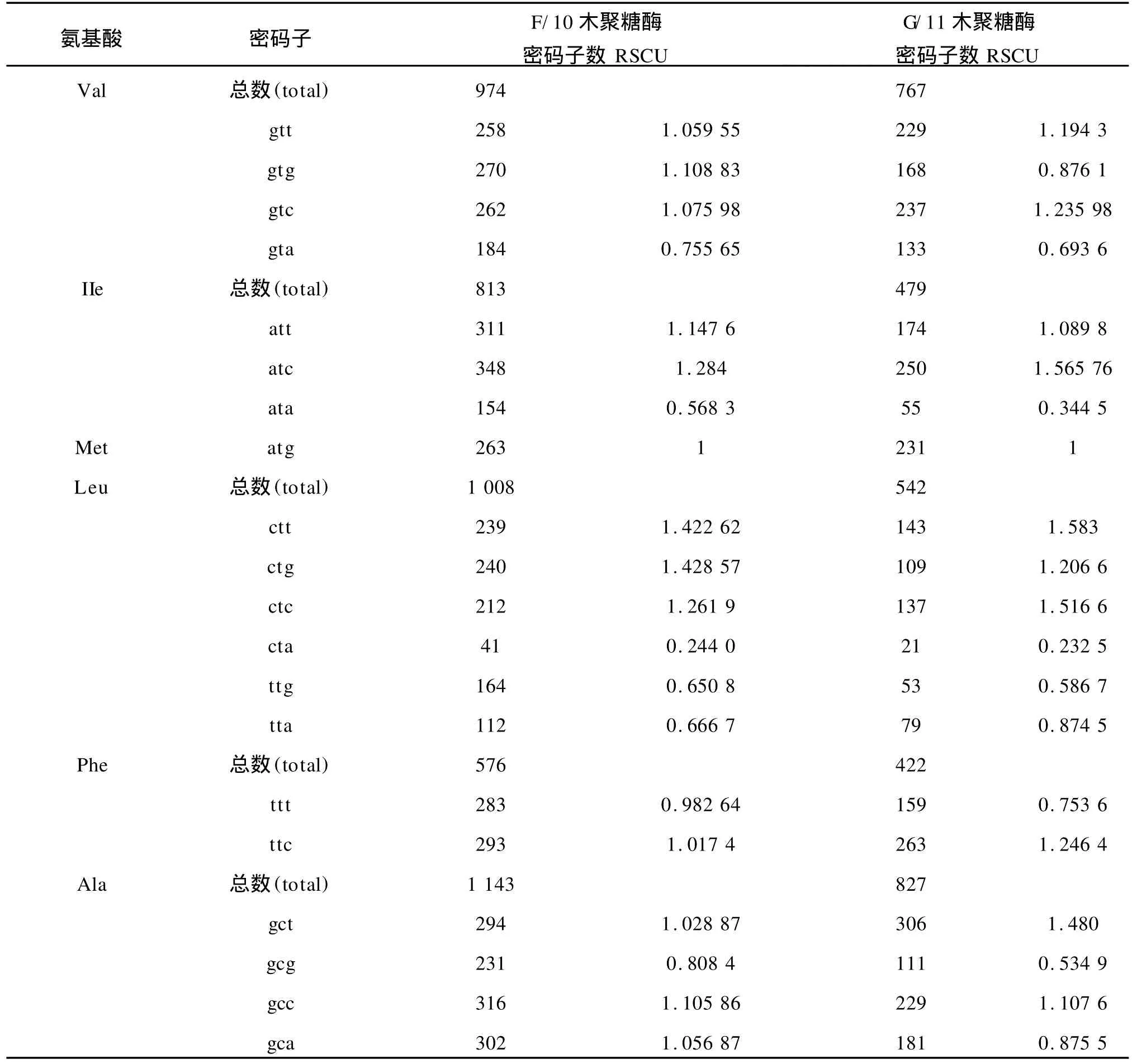
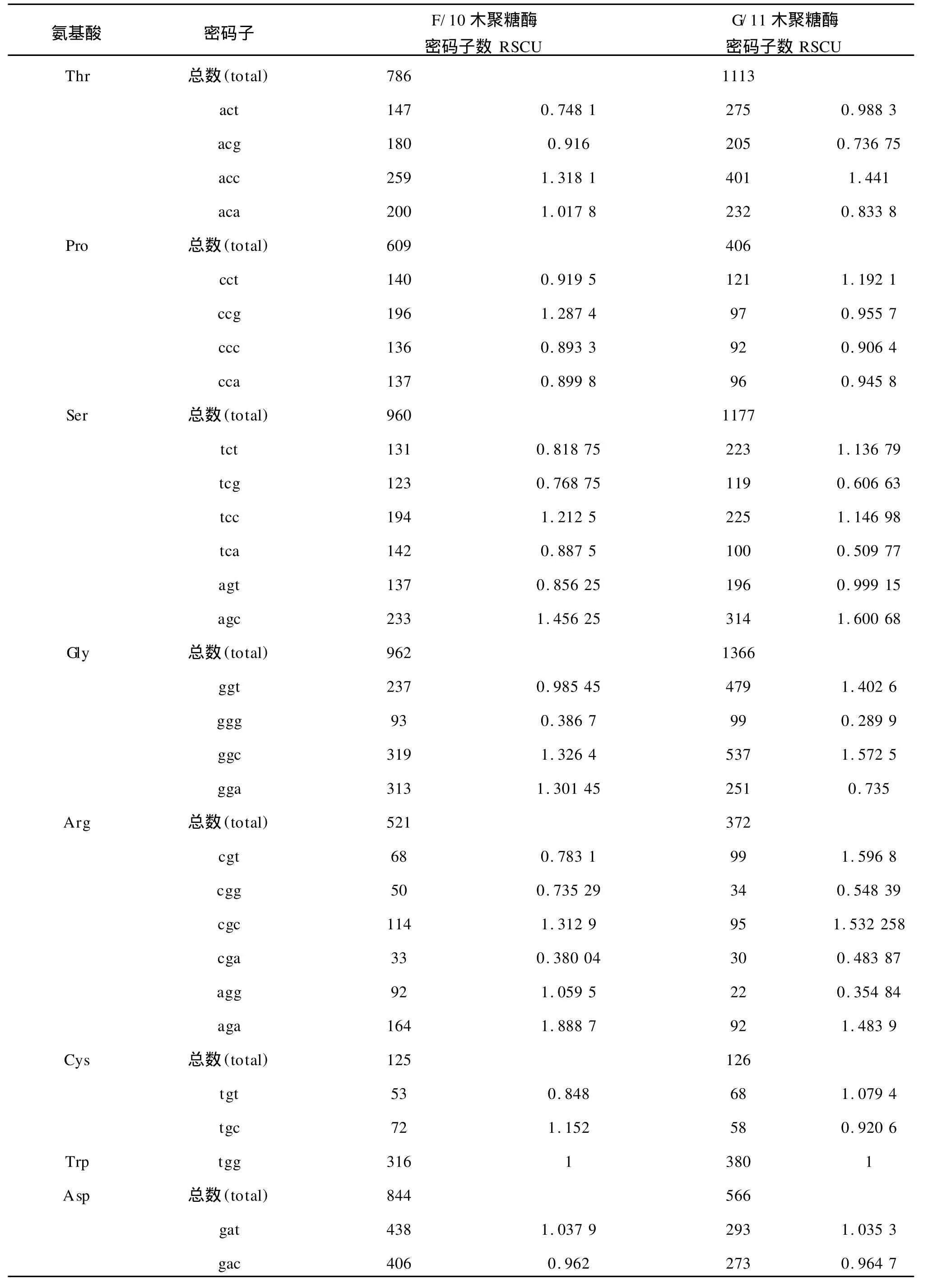
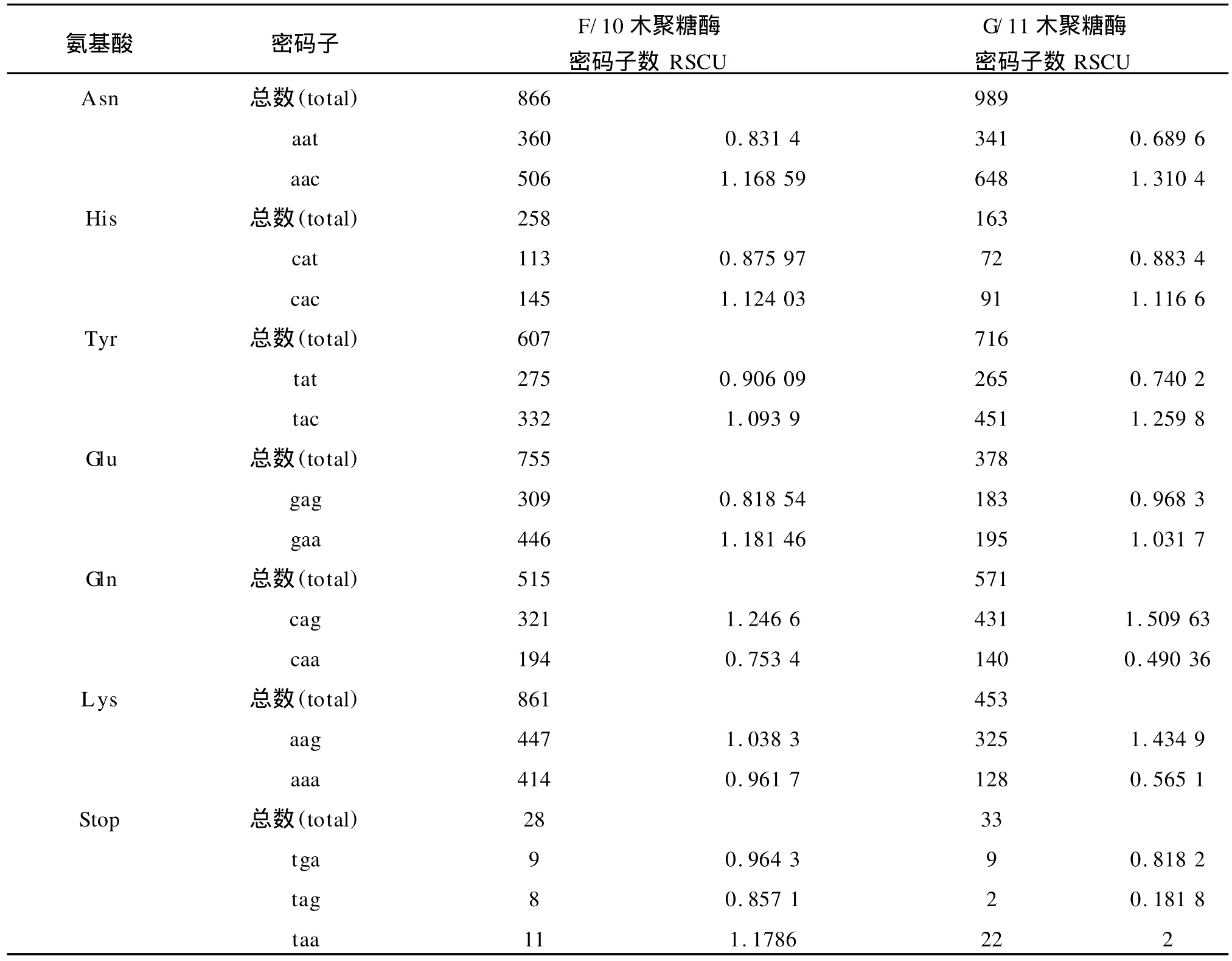
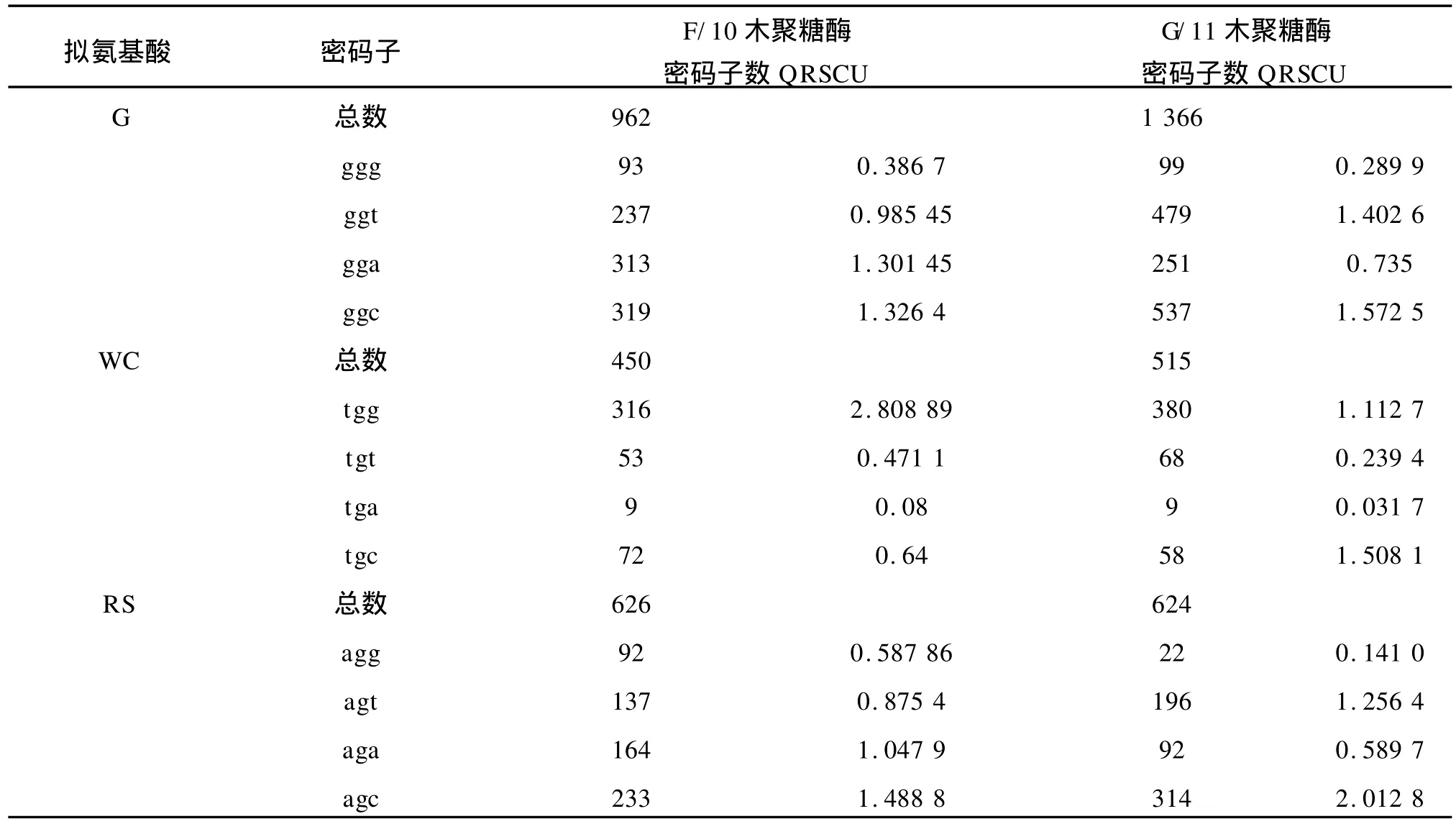


2.1 基于氨基酸编码方法下的密码子偏好情况分析
2.2 基于拟氨基酸基因编码方法下的密码子偏好情况分析
3 结 语

