New Hybrid Parallel Algorithm for Variable-sized Batch Splitting Scheduling with Alternative Machines in Job Shops
2010-03-01ZHAOYanweiWANGHaiyanWANGWanliangandXUXinli
ZHAO Yanwei , WANG Haiyan WANG Wanliang, and XU Xinli
1 Key Laboratory of Mechanical Manufacture and Automation of Ministry of Education, Zhejiang University of Technology, Hangzhou 310014, China
2 College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310014, China
Notations
i —Job index,
j —Operation index,
k —Batch index,
l —Machine index,
N —Total number of jobs,
Si—Original batch size of job i,
ni—Total number of operations of job i,
M —Total number of machines,
bij—Total number of alternative machines for the jth operation of job i,
NB—Total number of sub-batches,
L —Length of the chromosome,
Np—Population size,
CR —Crossover probability,
1 Introduction
Under the batch production mode in a real manufacturing environment, a job consists of a batch of identical parts in the production scheduling problem, and there may exist alternative machines for operations. By splitting the original batch into many smaller sub-batches, these smaller sub-batches can be processed on different machines simultaneously, with all parts in one sub-batch processed altogether and the processing time of a sub-batch defined to be the sum of processing time of each part in that sub-batch,sharing only one set-up time, so that a faster completion can be obtained. That’s how batch splitting, also called lot streaming in many researches, arises.
Batch splitting in flow shops can be equal (all sub-batches of a given job are of equal size), consistent(sub-batch sizes vary within a job but are the same for all machines), or variable (sub-batch sizes can change from machine to machine)[1]. And these three types of batch splitting can be applied to job shops too. Most of the existing researches on the batch splitting scheduling problem concerns the former two kinds of batch splitting.PAN, et al[2], studied the equal-sized batch splitting scheduling problem with set-up time and alternative machines, with the batch size for each sub-batch fixed in advance. SUN, et al[3], adopted a novel encoding method in genetic algorithm(GA) to optimize both the number of sub-batches for each job and the sub-batch processing order simultaneously when solving the equal-sized batch splitting job shop scheduling problem with set-up time and alternative machines. LOW, et al[4]performed comparisons between equal-sized batch splitting and consistent-sized batch splitting in the batch splitting scheduling problem with the number of sub-batches and the sizes of sub-batches fixed beforehand. MARTIN[1]proposed a heuristic to get the number of sub-batches for each job and the size of sub-batches in the consistent-sized batch splitting scheduling problem in flow shops. Although most of these researches solved the batch splitting scheduling problem by fixing the number of sub-batches, or the sub-batch sizes, or both, their achievements still provided important basis for a further study.
On the basis of the above researches, we focus our attention on variable-sized batch splitting, trying to obtain both the optimum number of sub-bathes for each operation per job and the optimum batch size for each sub-batch in the batch splitting scheduling problem with set-up time.
There is much scope for evolutionary algorithms for batch splitting scheduling problems. Among all kinds of evolutionary algorithms, DE is a newly-developed simple and efficient population-based heuristic, introduced by STORN, et al[5], and has been extensively investigated and improved to solve flow shop scheduling problems and job shop scheduling problems[6–9], but not including the batch splitting scheduling problem yet. Considering that the sum of values of genes in one chromosome remains the same before and after mutation in differential evolution (DE),when chromosomes are of equal length and have the same total value of genes, this paper adopts DE to solve the batch splitting problem, so that the sum of the batch sizes of all the sub-batches for any operation of any job remains the same as the original batch size of that job when values of genes in chromosomes represents batch sizes of sub-batches.
The paper is organized as follows. The formulation for the variable-sized batch splitting scheduling problem with alternative machines is established in section 2. In section 3,a new hybrid parallel algorithm, with a global search procedure, based on self-adaptive DE and genetic crossover operator, and a problem-dependent local search procedure,is brought forward to solve both the batch splitting problem and the batch scheduling problem. Simulation and results are presented and comparisons are drawn in section 4,followed by conclusions in section 5.
2 Problem Description and Formulation
Consider N jobs in a scheduling system. Each job consists of a batch of identical parts, and is planed to be processed in its predefined operation sequence. And there may exist alternative machines for operations.
To simplify the problem and make full use of alternative machines, we assume that jobs are all available at time zero,and the batch number of sub-batches for the jth operation of job i is equal to the total number of alternative machines for that operation, so that chromosomes in the algorithm can be of equal length. Each sub-batch requires one machine out of a set of its alternative machines, and a machine should be set up before it starts a processing procedure for a sub-batch.
A mathematical model for the variable-sized batch splitting scheduling problem is developed in this paper.Values of ϕijkl, φijklandare listed as follows:


The mathematical model is established as follows:

Eq. (1) specifies the objective to minimize the makespan,defined by the maximum finish time of processing procedures for the latest operations. Eq. (2) ensures that the sum of the batch sizes of all the sub-batches for an operation of a job remains the same as the original batch size of that job. Eq. (3) shows that a machine is allowed to be set up for a sub-batch for an operation of a job before all the parts in the sub-batch finish the processing procedure for its predecessor operation of the same job, so that when all the parts in the sub-batch are ready, the machine can start processing procedure immediately. Note that there is an add-up notation in Eq. (3), owing to the rule presented in section 3.1 that all sub-batches within an operation of a job are sequenced in an increasing order of batch index.However, the machine starts the set-up procedure for a sub-batch only after, at least, it finishes the processing procedure for the predecessor sub-batch in the processing sequence on that machine, as is shown in Eq. (4). If the predecessor and successor sub-batches in the processing sequence on a machine are to deal with the same operation of the same job, the successor sub-batch does not need set-up procedure on that machine. Eq. (5) describes that when a sub-batch for an operation of a job needs set-up procedure, the set-up procedure couldn’t be interrupted once started. Eq. (6) provides the relationship between the start time of processing procedure and the finish time of set-up procedure for a sub-batch, which certainly specifies the sequence between the set-up procedure and the processing procedure for any given sub-batch. Eq. (7)shows that processing procedure for a sub-batch couldn’t be interrupted once started.
3 New Hybrid Parallel Algorithm
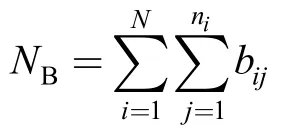
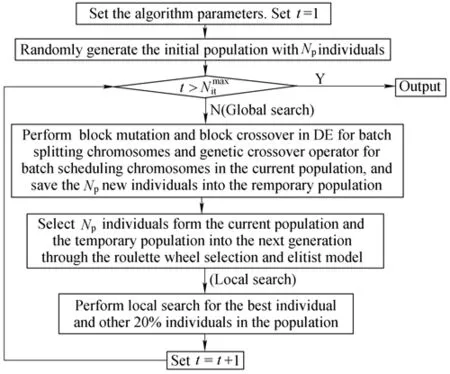
Fig. 1. Framework of the proposed algorithm
3.1 Individual representation
Parallel chromosome coding method is adopted to represent an individual, one called batch splitting chromosome, composed by batch sizes of NBsub-batches,and the other called batch scheduling chromosome,containing sequence information of NBsub-batches.
Randomly generate bijintegers within the range [0, Si]that satisfy Eq. (2) as Sijkfor the jth operation of job i,where i = 1, 2,…, N,j = 1, 2,… , ni, and k = 1,2, …,bijAll the batch sizes of these NBsub-batches constitute the batch splitting chromosome, denoted by chromosome1,with its length L = NB, is shown as follows:
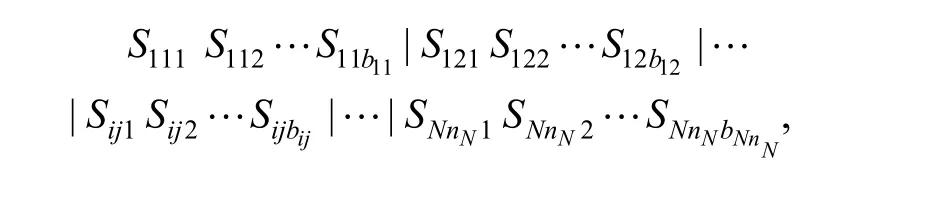
where Sijkstands for the batch size of the kth sub-batch for the jth operation of job i. We denote Sij1Sij2… Sijbijon chromosome1 as the sub-batch size array for the jth operation of job i, where i = 1,2 , …,N andValues of zero are allowed in the batch splitting chromosome. The sequence of these NBsub-batches in chromosome1 constitutes the batch scheduling chromosome, denoted by chromosome2, with the length L. For the batch splitting scheduling problem listed in Table 1, Fig. 2 and Fig. 3 are examples for the batch splitting chromosome and the batch scheduling chromosome for the problem respectively. Genes on chromosome2 are in “ij” format, referring to the jth operation of job i, and gene “ij” appears bijtimes overall.We specify the batch index to gene “ij” according to the time “ij” appears from left to right on chromosome2, which infers that all sub-batches within an operation of a job are sequenced in an increasing order of batch index. For example, the third gene “21” on chromosome2 in Fig. 3 form left to right represents the second sub-batch for the first operation of job 2, since the gene appears the second time from left to right, and the size is 4, which can be seen from chromosome1 in Fig. 2.
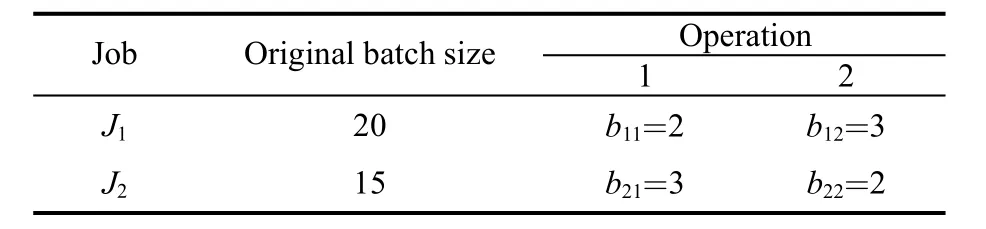
Table 1. Batch splitting scheduling problem

All the sub-batches for the jth operation of job i are required to be sequenced ahead of any sub-batch for the j′t h operation of job i when j< j′, which means that all the sub-batches for all previous operations of a job are scheduled before any sub-batch for the current operation of that job. Then the time when parts with certain size accomplishes the processing procedure for the predecessor operation of a job can be obtained according to the completed arrangement of all the sub-batches for the predecessor operation of the job, which is needed in Eq. (3),when handling a sub-batch for the current operation of the same job.
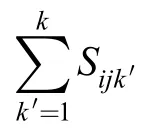
3.2 Fitness function
Eq. (1) is the objective to minimize the makespan. The fitness function is designed as
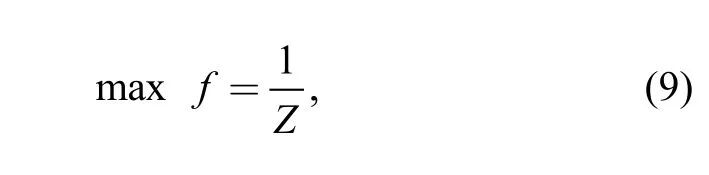
3.3 Global search procedure
An individual is composed of a batch splitting chromosome and a batch scheduling chromosome, due to the finding that the sum of values of genes in one chromosome remains the same before and after mutation in DE and powerful optimization ability of GA for scheduling,they evolve using DE and genetic crossover operator respectively. We denote chromosome1hand chromosome2has the batch splitting chromosome and the batch scheduling chromosome from individual h respectively.
3.3.1 Evolution procedure for the batch splitting chromosome
A self-adaptive DE-based evolution procedure is designed for the batch splitting chromosome in this section.
(1) Evolution procedure. A DE with block mutation and block crossover is adopted for the batch splitting chromosome, and the current population evolves according to the following steps in one cycle.
Step 1: Set individual index h = 1.
Step 2: For individual h in the current population,randomly generate three integers within [1, Np], denoted by d1, d2and d3, where Nprepresents the population size. d1, d2and d3are different from each other, and different from h.Carry out the evolution procedure for chromosome1 from individual h according to the following sub-steps:
Step 2.1: Randomly generate an integer within [1, N ] as r1and another integer within [1,1rn ] as r2, and set job index i = 1 and operation index j = 1.
Step 2.2: If i = r1and j = r2, execute step 2.3. Otherwise,execute step 2.4.
Step 2.3: Carry out block mutation and block crossover for the sub-batch size array for the jth operation of job i on chromosome1h:
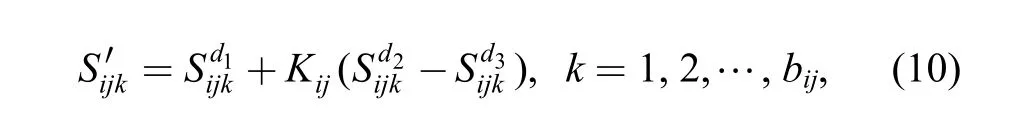
To make sure that Si′jkis within [0, Si], the value of Kijhas to satisfy the following two equations. And we randomly choose a value that satisfies these two equations as Kij:
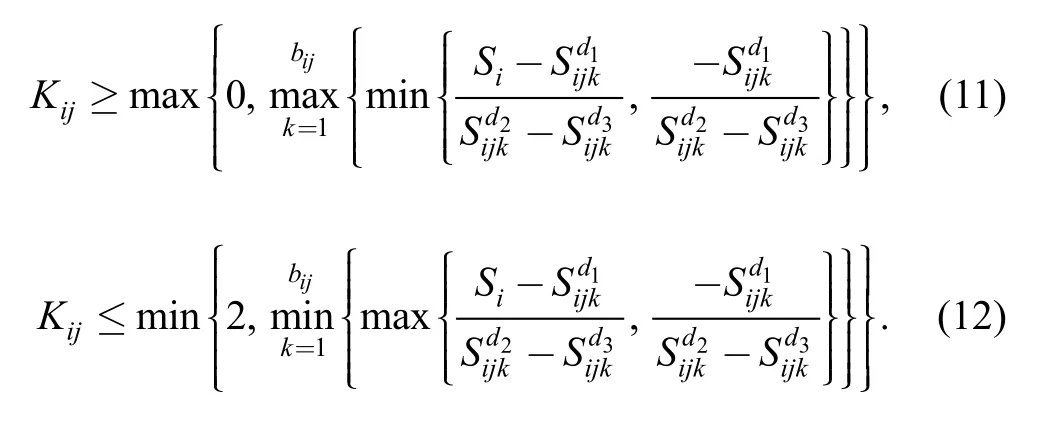
Since batch sizes in this paper are integer numbers,needs a delicate modification. Set SUM = 0, and from k = 1 to k = bij, performand SUM =and if k = bij, performSUM. “[·]” means to get the nearest integer number. In this way, all thein the new array is adjusted to integer numbers, and still satisfy Eq. (2), where k = 1, 2,···, bij.Select the new array into a temporary chromosome,denoted by newchro1h. Execute step 2.5.
Step 2.4: Randomly generate a real number within [0,1] as r3. If r3≤CR, return to step 2.3. Otherwise, select the sub-batch size array for the jth operation of job i on chromosome1hinto newchro1h, and execute step 2.5.
Step 2.5: If j<ni, perform j = j + 1. Otherwise, perform i = i+1.
Step 2.6: If i ≤N, return to step 2.2. Otherwise,newchro1hnow is a complete batch splitting chromosome.Put newchro1hinto the temporary population.
Step 3: if h<Np, perform h = h + 1, return to step 2.
(2) Adaptive crossover probability CR. To improve the performance of the algorithm, we introduced the distribution variance of fitness value Ω in Ref. [10] that reflects the diversity of population to adjust the probability of crossover adaptively. Ω is defined as
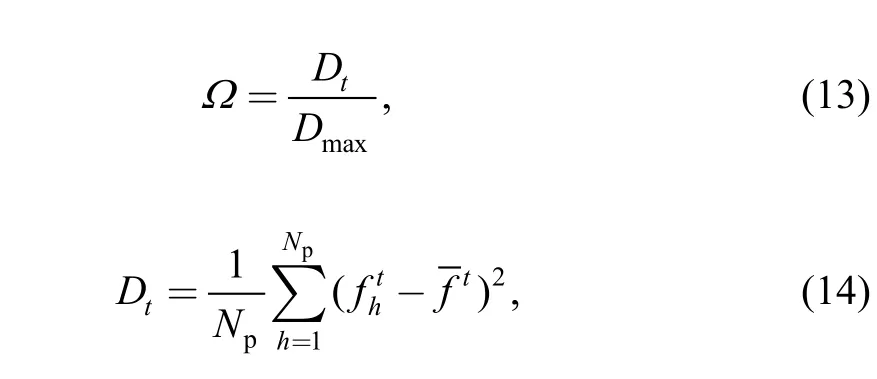
wheretD represents the variance of fitness value, and
We can see from Eq. (13) that the value of Ω varies from 0 to 1, and the higher Ω is, the better for the population in terms of the diversity of population. The adaptive crossover probability is designed in this paper as follows:
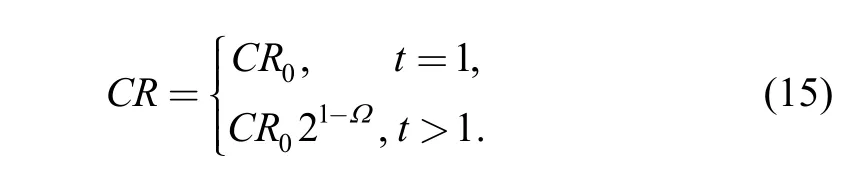
The value of CR is adjusted adaptively within [CR0,2CR0] according to different value of Ω when evolving.When the diversity of population degrades, meaning that the value of Ω grows lower, CR is adjusted to a higher value to raise the exploration ability of the algorithm.Otherwise, when the diversity of population upgrades,meaning that the value of Ω grows higher, CR is then adjusted to a lower value to improve the exploitation ability of the algorithm.
3.3.2 Evolution procedure for the batch scheduling chromosome
Randomly divide the current population into Np/2 groups in one cycle, with two batch scheduling chromosomes in each group, and genetic crossover operator is performed for two chromosomes in each group. Assume that two parent chromosomes in a group are denoted as chromosome2pand chromosome2q, respectively. Perform the following steps.
Step 1: Randomly generate an integer within [1, N] as r1and another integer within [1,1rn ] as r2. Find two blocks on chromosome2pand chromosome2qthat have least number of genes but contain all the sub-batches for the r2th operation of job r1. For the problem in Table 1, if parent chromosomes are shown in Fig. 4 and r1= 1 and r2= 2,blocks covered with shadow in Fig. 4 are the blocks that have least number of genes but contain all the sub-batches for the second operation of job 1.

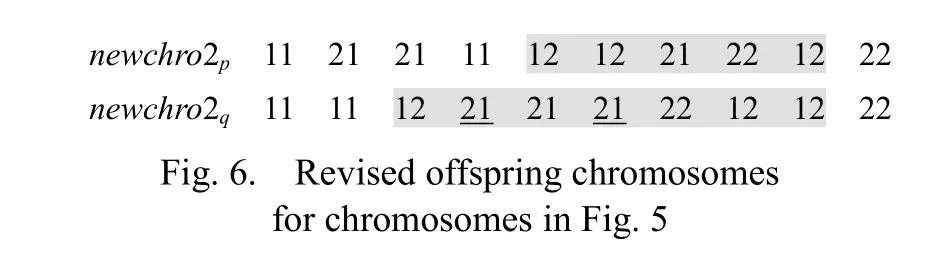
Step 2: Exchange two blocks on chromosome2pand chromosome2q, and two offspring chromosomes are obtained, denoted by ch romosome2 ′pand chromosome2q′,respectively. Offspring chromosomes generated from the parent chromosomes in Fig. 4 are shown in Fig. 5.

Step 3: Delete redundant genes and insert missing genes within the newly inserted blocks on ch romosome2 ′pand chromosome2q′. When inserting a missing gene, insert the missing gene before the genes that represent any following operations of the same job and behind the genes that represent any previous operations of the same job within the block if those genes exist in the block. The revised offspring chromosomes, denoted by newchro2pand newchro2qrespectively, are selected into the temporary population. The revised offspring chromosomes for chromosomes in Fig. 5 are presented in Fig. 6, where genes with underlines stand for the missing genes.
3.3.3 Selection procedure
After evolution procedures are performed for the current population, newchro1hand newchro2hconstruct a new individual h, and there are Npnew individuals in the temporary population. Select Npindividuals out of 2Npindividuals from the current population and the temporary population into the next generation through the roulette wheel selection and elitist model[11].
3.4 Local search procedure
An Insert-based local search method based on the individual representation proposed in this paper, is brought forward to gain a better performance. Suppose that individual h in the current population is selected to perform the local search, execute the following steps:
Step 1: Randomly generate an integer within [1, L] as pos and a natural number within [0, 1] as r3, where L stands for the length of chromosome. Assume that the posth gene on chromosome2hfrom left to right represents the kth sub-batch for the jth operation of job i. Set g = k,= ch romosome1hand=chromosome2h.
Step 2: If r3= 1, execute step 3. Otherwise, r3must be zero. Perform the forward search procedure:
Step 2.1: If j>1, find the gene that representing the bi(j–1)th sub-batch for the ( j−1)th operation of job i on, and denote the position as pos1. Else, if j = 1, set pos1= −1.
Step 2.2: If the (pos−1)th gene onfrom left to right refers to a sub-batch for the jth operation of job i, exchange the values of Sijgand Sij(g–1)onand execute g = g−1. Execute= Insert(, pos, pos–1).
Step 2.4: Execute pos = pos−1. If pos>( pos1+1),return to step 2.2. Otherwise, stop the local search for individual h.
Step 3: Perform the backward search procedure:
Step 3.1: If j<ni, find the gene that representing the first sub-batch for the ( j+1)th operation of job i onand denote the position as pos2. Else, if j = ni, set pos2 = L +1.
Step 3.2: If the ( pos+1)th gene onfrom left to right refers to a sub-batch for the jth operation of job i, exchange the values of Sijgand Sij(g+1)onand execute g = g+1. Execute= Insert(, pos, pos+1).
Step 3.4: Execute pos = pos+1. If pos<(pos2−1),return to step 3.2. Otherwise, stop the local search for individual h.
In the above steps, Insert(chromosome, u, v) means to insert the gene at the uth position in the vth position on chromosome from left to right.
3.5 Analysis of the complexity of the proposed algorithm
Consider a batch splitting scheduling problem, with population size Npand maximal iteration number Nmaxit. In the proposed algorithm, decoding procedure, calculation procedure for adaptive crossover probability CR, evolution procedure for the batch splitting chromosomes, evolution procedure for the batch scheduling chromosomes, selection and local search are concerned in one cycle, and their time complexities are o(NpL), o(Np), o(NpL), o(0.5NpL2), o(2Np2)and o(0.2NpL) respectively. Therefore, the total time complexity for the proposed algorithm is:
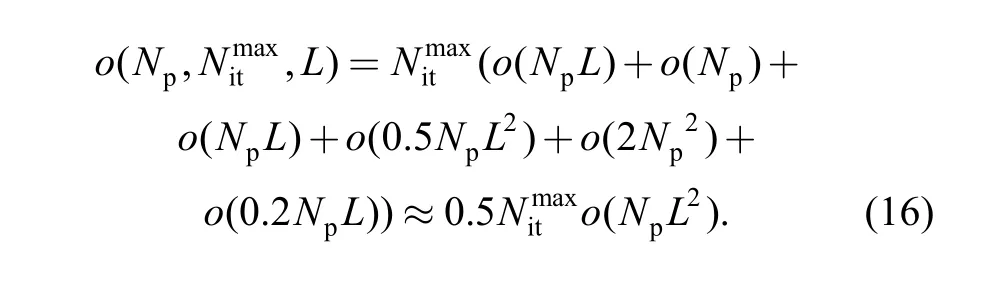
From Eq. (16), we can see that the maximal iteration number and population size, especially the length of chromosome affects the computational burden of the algorithm greatly.
4 Experiments and Analyses
4.1 Application of the proposed algorithm to test instances
To evaluate the performance of the proposed algorithm,we adopt scheduling data in Refs. [2, 12–13] to construct the following four test problems:
Problem 1 (denoted by P1): The problem is composed of 4 jobs and 6 machines, and the original batch size for each job is 8. The unit processing time for operations on alternative machines is shown in Table 2, and set-up time for an operation of a batch on a machine is equal to its unit processing time on the same machine.
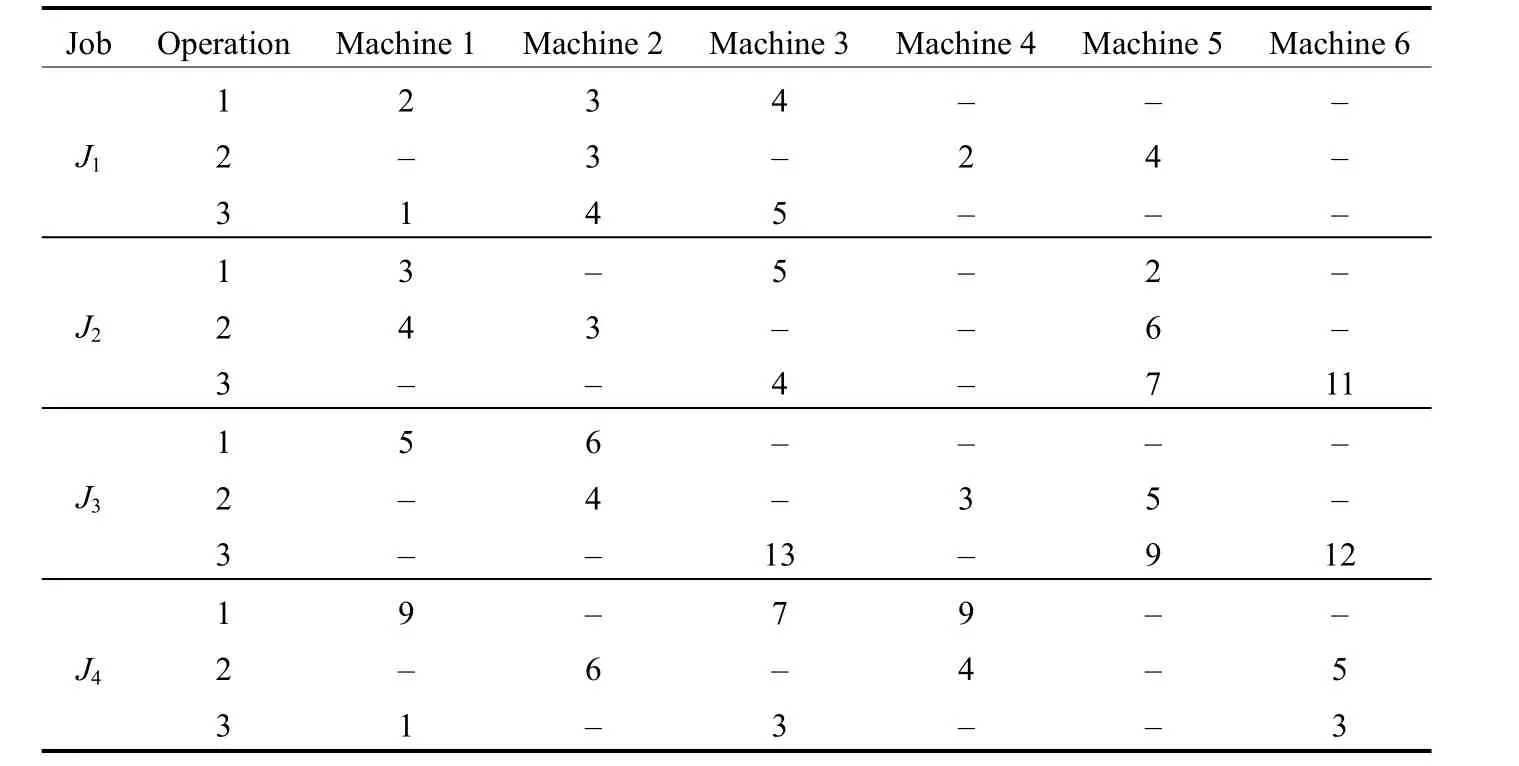
Table 2. Unit processing time for operations on alternative machines s
Problem 2 (denoted by P2): The problem is composed of 4 jobs and 6 machines, and the original batch size for each job is 20. The unit processing time for operations on alternative machines is shown in Table 2, and set-up time for an operation of a batch on a machine is equal to its unit processing time on the same machine.
Problem 3 (denoted by P3): The problem is composed of 6 jobs and 6 machines, and the original batch size for each job is 10. The unit processing time and set-up time for operations on alternative machines is shown in Table 3.
Problem 4 (denoted by P4): The problem is composed of 6 jobs and 6 machines, and the original batch size for each job is 20. The unit processing time and set-up time for operations on alternative machines is shown in Table 3.
Some related achievements concerned with these problems can be found in Refs. [2, 12–13]. The optimum makespan for P1 obtained in Ref. [12] was 87, and the optimum numbers of sub-batches were 1, 3, 5 and 4 for J1,J2, J3and J4respectively, using the proposed algorithm that first optimized the number of sub-batches for each job, and then scheduled those sub-batches based on equal-sized batch allocation method (PS: the optimum makespan in Ref.[12] for the problem with no batch splitting should be 141 instead of 140, as is shown in its gannt chart). In Ref. [2],the obtained optimum makespans for P2 were 345, 216,196 and 194 when the number of sub-batches for each job was fixed to 1, 2, 4 and 5, respectively, using equal-sized batch allocation method. P3 was solved in Ref. [13] based on the genetic algorithm and the simulated annealing algorithm, with the number of sub-batches and the sizes of sub-batches fixed in advance, and the optimum makespan was 243 for P3 with no batch splitting.
To evaluate the performance of the proposed algorithm and confirm the effectiveness of the local search procedure and the adaptive crossover operator, we set= 200,Np=50 and CR0=0.3, and solve the four test problems. The proposed algorithm has been coded with Visual C++ .NET 2003 and runs on a PC with a Pentium 2.53 GHz processor and a 1.00 GB RAM under Windows XP 2002. The results obtained over 20 runs are shown in Table 4, where BMN,WMN, No.BMN and AvT.CPU denote the best makespan,the worst makespan, the number of the best makespan obtained among 20 runs and the average computational time in seconds over 20 runs respectively. “ALGRM1” in Table 4 refers to the hybrid parallel algorithm proposed in this paper. And “ALGRM2” is the algorithm as same as ALGRM1, except that the local search procedure is not included. “ALGRM3” is the algorithm as same as ALGRM2,except that the crossover probability CR in ALGRM3 is fixed to CR0throughout evolution.
The increase of the size of problem from P1, P2 to P3,P4 adds to the complexity of the batch scheduling problem,while the increase of the original batch size for each job adds to the complexity of the batch splitting problem. It can be observed that the variable-sized batch splitting technique provides considerable makespan reduction, compared with results without batch splitting in Refs. [2, 12–13]. All these three algorithms can obtain excellent optimization outcomes, especially ALGRM1 and ALGRM2 that even surpass, or at least are not worse than the existing achievements in Refs. [2, 12–13]. From Table 4, we can see that ALGRM1 can always outperform the other two algorithms for all test problems in terms of optimization power, and ALGRM3 consumes least computation effort.Apparently, ALGRM1 derives great benefit from the local search procedure and the adaptive crossover operator, and provides better solutions within reasonable time limit,compared with ALGRM2 and ALGRM3.
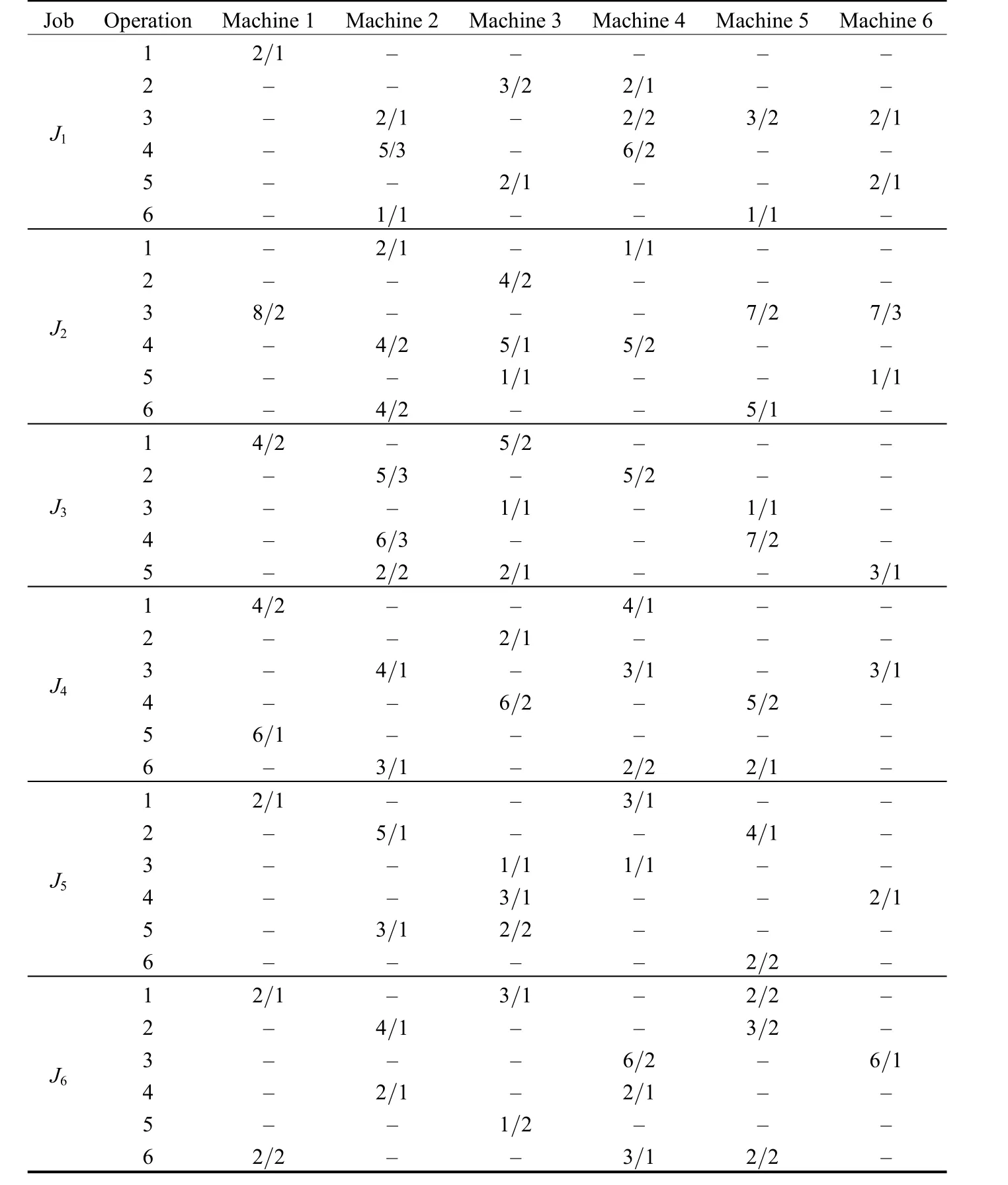
Table 3. Unit processing time/set-up time for operations on alternative machines s

Table 4. Results for these four test problems through three algorithms
The batch splitting approach in this paper tends to split the original batches into sub-batches of variable size, and compared with Ref. [2] and Ref. [12], we can get that variable-sized batch splitting is better than equal-sized batch splitting. This is probably because the variable-sized batch splitting in this paper takes care of different processing capabilities of alternative machines sufficiently,and the tradeoff between minimizing the total set-up time(achieved by reducing the number of sub-batches) and minimizing the idle time on machines (achieved by reducing batch sizes, or by increasing the number of sub-batches) is well dealt with. We consider that the conclusion acquired by LOW, et al[4]with the number of sub-batches and the sizes of sub-batches fixed in advance for experiment (five instances were prepared in advance covering these two batch allocation methods) is not suitable for general situations.
Optimum solutions to batch splitting for these four test problems through ALGRM1 are presented in Table 5, and the corresponding Gantt charts are shown in Figs. 7–10.From Table 5, we can see that the original batch of J1in P1 is split into 3, 3, 2 and 3 sub-batches for the four operations respectively, and the optimum batch sizes for the respective three sub-batches for the first operation are 0, 1 and 7,which means that the actual optimum batch number for the first operation of J1is 2. Sub-batches with size 0 are not displayed in Gantt charts.
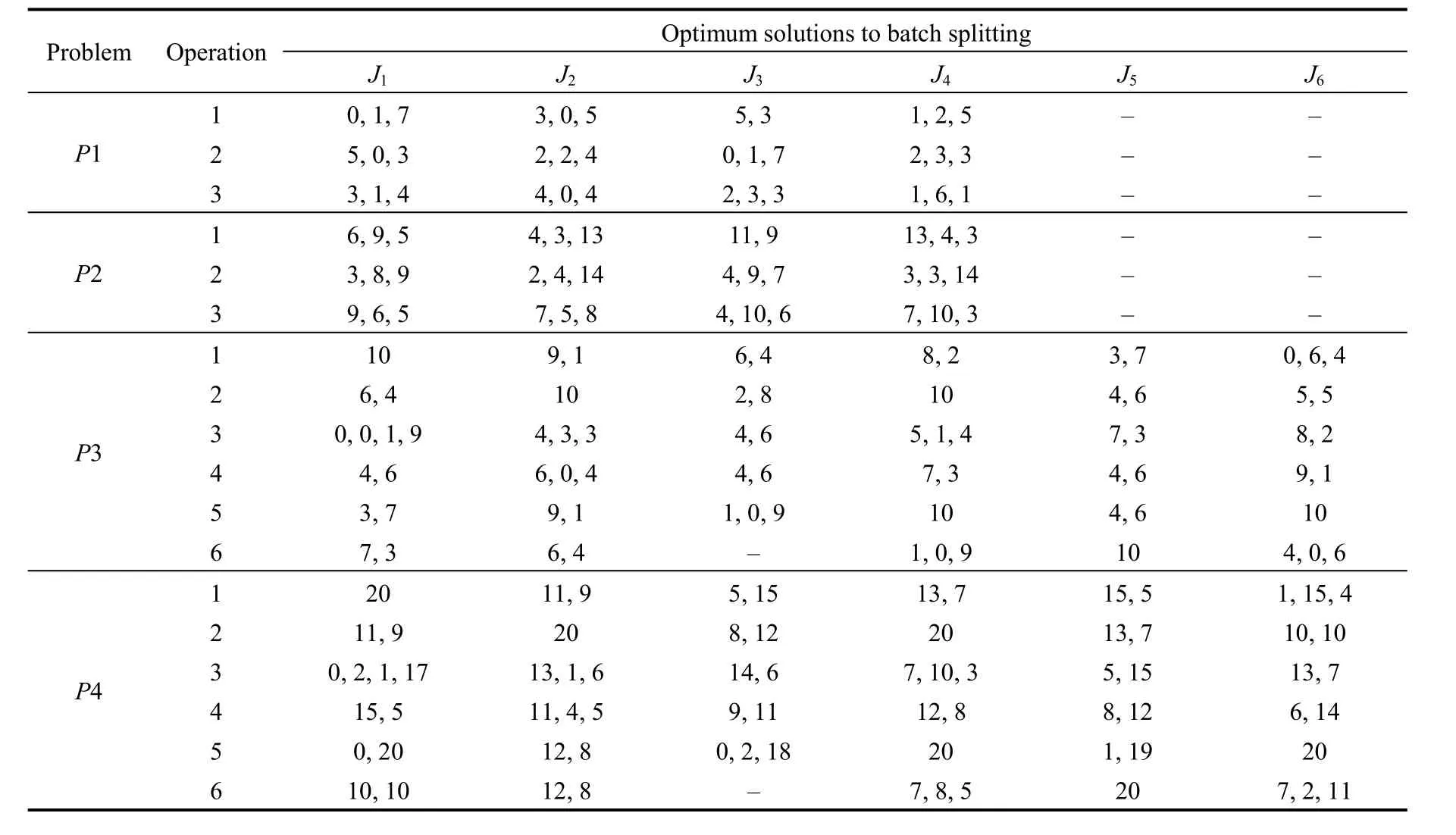
Table 5. Solutions to batch splitting for these four test problems through ALGRM1

Fig. 7. Gantt chart for P1

Fig. 8. Gantt chart for P2

Fig. 9. Gantt chart for P3

Fig. 10. Gantt chart for P4
E1 in Gantt charts means machine 1, and E2 means machine 2, etc. Panes labeled with “s” in Gantt charts stand for set-up procedures, while those labeled with notations in“abc” format represent processing procedures, where “a”refers to a job index, “b” refers to an operation index, and“c” represents a sub-batch. Take Fig. 7 for example. The pane that labeled with “311” on machine 1 in Fig. 7 stands for the processing procedure for the first operation of the first sub-batch of J3, and the front pane labeled with “s”adjacent to it stands for the set-up procedure for the same operation. Combined with Table 5 and the time axis, we can get that the processing machine for the first operation of the first sub-batch of J3, with sub-batch size 5, is machine 1 after machine allocation, and the set-up procedure starts at time 0 and ends at time 5, and the processing procedure starts at time 5 and ends at time 30.As for the pane labeled with “213” on machine 5 in Fig. 7,there is no front pane labeled with “s” adjacent to it,meaning that the third sub-batch for the first operation of J2dose not need set-up procedure on machine 5, since the predecessor sub-batch in the processing sequence on that machine is of the same job and the same operation.
4.2 Application of the proposed algorithm to the batch splitting scheduling problem in a speaker workshop
To evaluate the performance of the proposed algorithm in a realistic problem, we adopt a batch splitting scheduling problem in a speaker workshop. The scheduling data is listed in Table 6. Set parameters the same as ALGRM1’s in section 4.1 and solve the problem through ALGRM1. We can obtain that BMN = 43 256, WMN = 48 151, No.BMN = 5 and AvT.CPU = 37.9 over 20 runs. The optimum solution to batch splitting for the realistic problem through ALGRM1 is presented in Table 7, and the corresponding Gantt charts are shown in Fig. 11. Since the set-up time consumed for a sub-batch is relatively short compared with the processing time of the whole sub-batch in this peoblem,set-up procedures are no longer illustrated with separate panes in Gantt chart. Panes labeled with “s” in Gantt chart stand for processing procedures together with set-up procedures.
The results of all the five problems above confirm the validity of the model established in this paper for the variable-sized batch splitting scheduling problem in job shops, as well as the excellent performance of the proposed algorithm. From the data analysis for all test problems,there are several important findings. First, a schedule can be greatly improved through the variable-sized batch splitting technique. Second, the local search procedure and the adaptive crossover operator designed in this paper work effectively to gain a better performance, and our algorithm is capable of providing desirable solution within reasonable time limit. Third, variable-sized batch splitting performs better than equal-sized batch splitting in batch splitting scheduling problem with alternative machines.
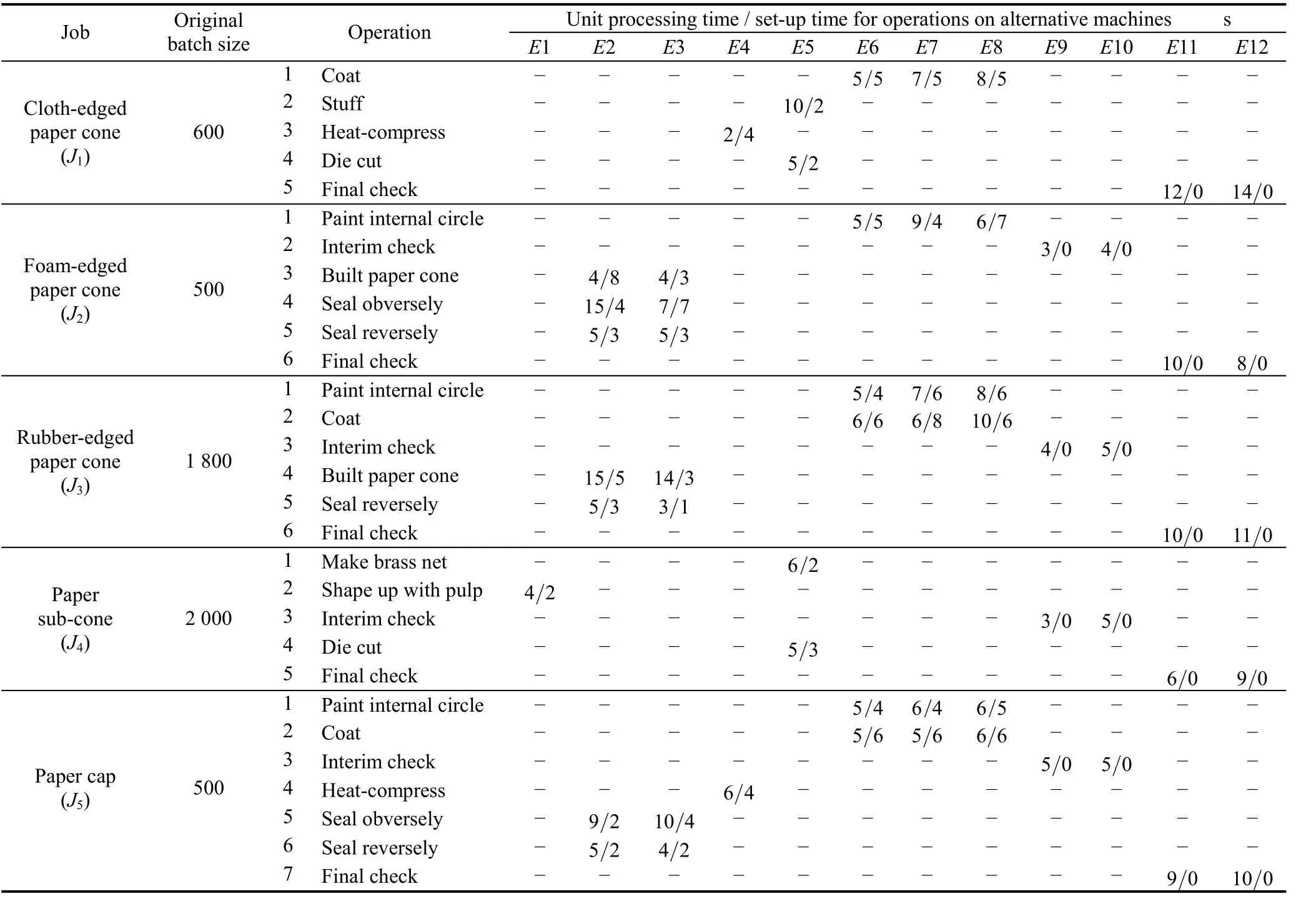
Table 6. Scheduling data in the batch splitting scheduling problem in a speaker workshop
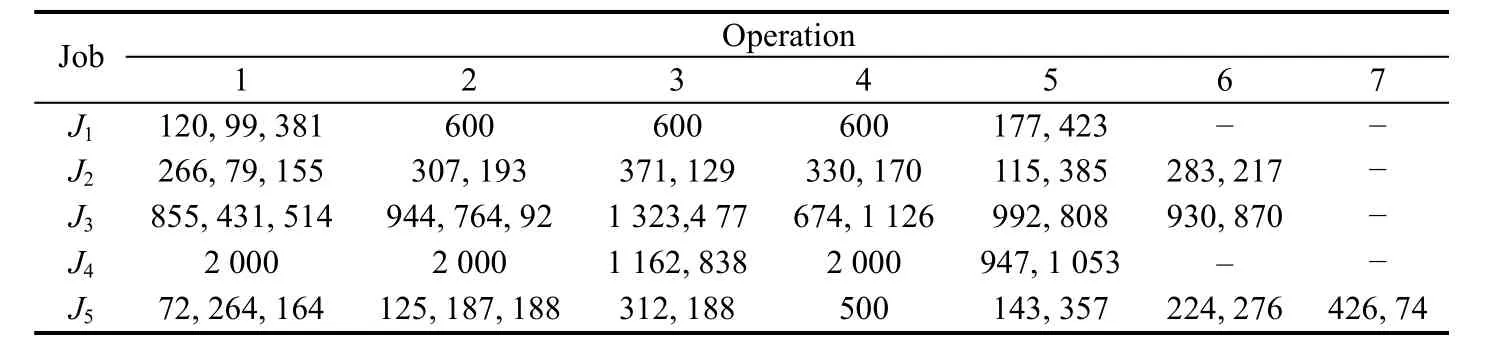
Table 7. Optimum solution to batch splitting for the realistic problem through ALGRM1
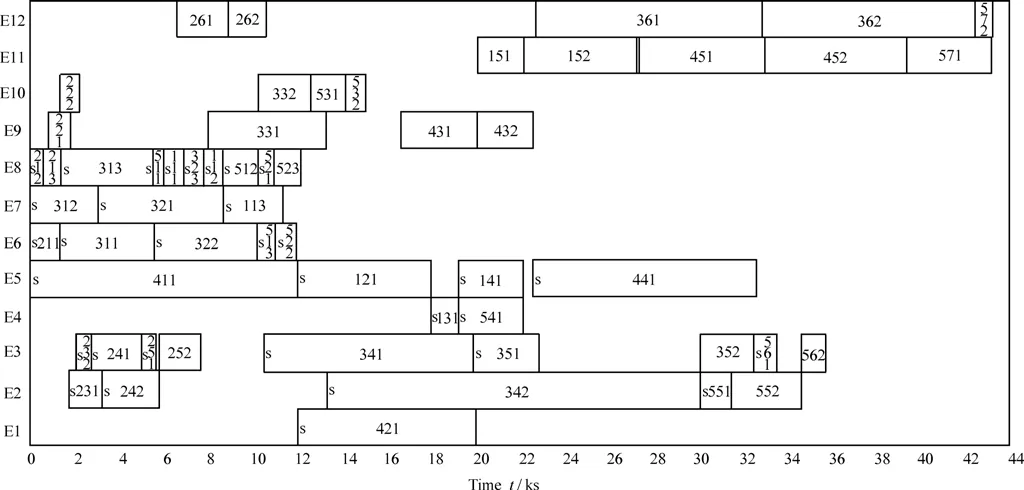
Fig. 11. Gantt chart for the realistic problem
5 Conclusions
(1) A variable-sized batch splitting scheduling problem model with alternative machines, on the basis of predefined batch numbers of sub-batches for each operation per job, is established.
(2) A new hybrid parallel algorithm is proposed to solve both the batch splitting problem and the batch scheduling problem, based on DE and genetic crossover operator. A problem-dependent local search procedure and an adaptive crossover operator are further designed for a better performance.
(3) The experiments of batch splitting job shop scheduling are performed, and the results confirm the validity of the problem model and the excellent performance of the proposed algorithm.
(4) Though the objective in this paper is to minimize the makespan, other objectives are also easily addressed by our approach.
(5) The proposed algorithm could also be used to solve batch splitting scheduling problems with bounded batch sizes by adjusting Eq. (11) and Eq. (12) to get batch sizes within bounds.
[1] MARTIN C H. A hybrid genetic algorithm/mathematical programming approach to the multi-family flowshop scheduling problem with lot streaming[J]. Omega, 2009, 37(1): 126–137.
[2] PAN Quanke, ZHU Jianying. Optimization method for a job-shop scheduling problem with alternative machines in the batch process[J]. Chinese Journal of Mechanical Engineering, 2004,40(4): 36–39. (in Chinese)
[3] SUN Zhijun, AN Jin, HUANG Weiqing. Lot scheduling with multiple process routes in job shop[J]. China Mechanical Engineering, 2008, 19(2): 183–187. (in Chinese)
[4] LOW C, HSU C M, HUANG K I. Benefits of lot splitting in job-shop scheduling[J]. International Journal of Advanced Manufacturing Technology, 2004, 24(9–10): 773–780.
[5] STORN R, PRICE K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces[J].Journal of Global Optimization, 1997, 11(4): 341–359.
[6] ONWUBOLU G, DAVENDRA D. Scheduling flow shops using differential evolution algorithm[J]. European Journal of Operational Research, 2006, 171(2): 674–692.
[7] QIAN Bin, WANG Ling, HUANG Dexian, et al. An effective hybrid DE-based algorithm for multi-objective flow shop scheduling with limited buffers[J]. Computers & Operations Research, 2009, 36(1): 209–233.
[8] NEARCHOU A C. A differential evolution approach for the common due date early/tardy job scheduling problem[J].Computers & Operations Research, 2008, 35(4): 1329–1343.
[9] QIAN Bin, WANG Ling, HUANG Dexian et al. Scheduling multi-objective job shops using a memetic algorithm based on differential evolution[J]. International Journal of Advanced Manufacturing Technology, 2008, 35(9–10): 1 014–1 027.
[10] WANG Chengdong, ZHANG Youyun. Adaptive pseudo-parallel genetic algorithm based on real coding[J]. Journal of Xi’an Jiaotong University, 2003, 37(7): 707–710. (in Chinese)
[11] WANG Wanliang, WU Qidi. Intelligence algorithms of production scheduling and application[M]. Beijing: Science Press, 2007:52–57. (in Chinese)
[12] AN Jin. The job shop scheduling problem with alternative machine in the batch process[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2005. (in Chinese)
[13] LIN Nan, MENG Biao, FAN Yuqing. Hybrid genetic algorithm for multiple process and batch scheduling in job-shop[J]. Journal of Beijing University of Aeronautics and Astronautics, 2007, 33(12):1 471–1 476. (in Chinese)
杂志排行

Chinese Journal of Mechanical Engineering的其它文章
- Dynamic Manipulability and Optimization of a Two DOF Parallel Mechanism
- Design of Robot Welding Seam Tracking System with Structured Light Vision
- New Method to Measure the Fill Level of the Ball Mill I—Theoretical Analysis and DEM Simulation
- Comparative Analysis of Characteristics of the Coupled and Decoupled Parallel Mechanisms
- Multidisciplinary Design Optimization with a New Effective Method
- Reliability Analysis of Electromechanical Systems with Degraded Components Containing Multiple Performance Parameters