基于RAG模型的石油地面工程数据库实时查询技术
2025-02-21康丙超冯运亨倪自强武永红

摘要:随着石油地面工程数据规模的快速增长,传统数据库查询方法难以满足实时性与准确性要求。研究基于通义千问、星火等国产大语言模型,对接地面工程Oracle数据库进行智能查询,并将检索增强生成(RAG)模型引入石油地面工程数据库查询系统,构建了基于向量数据库的知识检索框架。通过实验验证,该方法在查询响应时间、准确率和召回率等指标上均优于传统方法,查询响应时间缩短47%,准确率提升至92.3%。实验结果表明,RAG模型能有效提升石油地面工程数据库的查询效率和质量,为石油地面工程信息化建设提供新思路。
关键词:RAG模型;石油地面工程;数据库查询;向量数据库;大语言模型
一、前言
石油地面工程涉及大量设备运行数据、工艺参数和施工记录,数据体量庞大且持续增长。传统关系型数据库在处理非结构化数据和复杂查询时存在效率低下、语义理解不足等问题。随着大语言模型技术的发展,基于检索增强生成(RAG)的数据查询方法展现出显著优势。目前石油地面工程主要依托Oracle等关系型数据库存储结构化生产数据。随着通义千问、星火等国产大语言模型的发展,将其与传统数据库查询相结合,通过自然语言生成标准SQL语句并结合RAG技术处理非结构化数据,可实现更智能的数据交互。该方法将向量化检索与生成式AI模型相结合,可实现更智能的数据库交互。
二、系统整体架构设计
系统架构采用分布式微服务设计模式,基于Kubernetes平台构建弹性计算集群。系统核心由数据处理层、向量检索层、模型服务层和接口层组成。数据处理层实现Oracle数据库结构化数据与非结构化文本的标准化处理,构建统一的数据访问接口[1]。向量检索层基于FAISS框架搭建高性能向量索引,支持亿级数据的实时检索。模型服务层集成通义千问等国产大语言模型,执行查询意图理解和SQL生成任务。接口层提供标准化的RESTful "API,实现系统间的松耦合集成。系统采用消息队列实现模块间异步通信,确保高并发处理能力。数据同步机制保证Oracle数据库与向量索引的实时一致性。查询处理采用流水线架构,支持并行化执行。系统整体采用容器化部署方案,各功能模块独立封装,便于横向扩展。分布式缓存机制优化热点数据访问性能,提升系统吞吐量。故障转移机制确保系统高可用性,支持关键节点的自动容错。
三、关键技术实现
(一) 数据预处理与向量化
数据预处理阶段对石油地面工程原始数据进行标准化处理和质量控制。针对文本数据采用正则表达式进行清洗,去除特殊字符和冗余空格,执行分词和词性标注[2]。对数值型数据进行归一化处理,采用最小—最大值方法将数据映射到零至一区间,归一化公式为:
x' = (x-min)/(max-min) (1)
该方法确保特征尺度一致性,有效避免量纲差异对后续处理的影响。缺失值处理采用多重插补法,基于相似样本的属性分布进行估计填充。异常值检测结合箱型图法和局部异常因子算法,识别并处理离群数据点。向量化处理采用中文预训练模型,将文本转化为七百六十八维稠密向量表示。在向量空间中,任意两个向量A和B之间的相似度通过余弦相似度计算:
cos\" (θ) = (A-B)/(‖A‖-‖B‖) (2)
模型输入长度限制为五百一十二个标记,对超长文本采用滑动窗口策略进行分段处理,窗口大小设为二百五十六,步长为一百二十八。
(二) 检索增强生成模型构建
检索增强生成模型基于通义千问、星火等国产大语言模型架构设计,集成向量检索引擎。模型输入包括用户自然语言查询和检索到的相关文档,可智能生成标准SQL语句查询Oracle结构化数据,同时结合文档检索结果,输出经过优化的响应结果[3]。检索阶段采用两阶段检索策略,第一阶段基于词频—逆文档频率算法进行粗排,获取初筛候选集,第二阶段使用向量相似度进行精确匹配,选取前k个相关文档。相似度计算采用余弦相似度度量,设置动态阈值进行结果筛选。生成阶段将检索文档嵌入到提示模板中,构建结构化的上下文信息。模型采用流式解码策略,实现实时响应生成。引入知识融合机制,将检索文档的关键信息与模型固有知识相结合,提升生成内容的准确性。
(三) 查询优化策略
查询优化策略从查询解析、检索匹配和结果排序三个层面进行优化。查询解析阶段实现查询意图识别,将复杂查询分解为子查询序列。采用查询重写技术,扩充查询关键词,增加同义词和相关术语,提高召回率。引入查询纠错机制,自动纠正拼写错误和专业术语误用。基于历史查询日志构建查询模板库,加速常见查询处理。检索匹配阶段实现多路召回策略,综合利用关键词匹配、向量检索和规则匹配等方法。设计动态权重调整机制,根据查询特征和历史反馈自适应调整各路召回比例。引入预取机制,对高频查询结果进行缓存。实现渐进式检索策略,先返回快速结果,再补充完整结果。结果排序采用排序学习框架,融合相关度分数、时效性、数据质量等多维特征。构建排序模型训练集,利用真实查询日志进行模型优化。
(四) 向量索引优化方案
向量索引优化采用分层索引结构,结合倒排索引和乘积量化技术提升检索效率。索引构建阶段使用聚类算法将向量空间划分为多个子空间,每个子空间独立建立倒排索引。设置最优聚类中心数量,平衡索引构建时间和查询性能。实现动态索引更新机制,支持增量数据的实时索引更新。索引压缩采用乘积量化方法,将七百六十八维向量压缩至九十六维,显著减少存储空间。量化参数优化基于数据分布特征,设置合适的子空间划分数和码本大小。实现分布式索引部署方案,将大规模向量数据分片存储在多个节点。设计负载均衡策略,动态调整节点间的数据分布。索引查询过程采用并行计算框架,支持多线程并发检索。引入预筛选机制,利用粗粒度索引快速定位候选区域,提升检索速度。建立索引质量评估体系,通过召回率、检索时间等指标监控索引性能。
四、实验设计与结果分析
(一) 实验环境与数据集
实验环境采用分布式计算集群,由8台服务器组成,每台配置双路至强处理器、256GB内存和4块固态硬盘。深度学习训练平台使用4块NVIDIA A100显卡,单卡显存32GB。操作系统部署CentOS 8.4发行版,部署Oracle 19c数据库集群存储核心生产数据,采用Kubernetes 1.22管理集群资源。采用Kubernetes 1.22管理集群资源[4]。网络环境采用25Gbps以太网互联,保障集群内部数据传输效率。存储系统采用分布式架构,总容量达64TB,采用RAID 10阵列配置确保数据安全性和访问性能。实验数据集来自某油田近五年的生产数据,经过脱敏处理和质量审核,数据总量达2.3TB。数据类型覆盖458种设备的运行记录,包括泵机、管线、阀门、压缩机等核心生产设备,监测参数达1247个,涵盖温度、压力、流量、振动等关键指标。文本数据包含设备维修记录、操作日志、故障报告等多种类型文档,经过预处理和标准化后得到超过300万条训练样本。数据集划分采用分层抽样方法,按7:2:1比例划分训练集、验证集和测试集。训练数据包含167万条结构化记录和52万份文本文档,验证集包含48万条记录和15万份文档,测试集包含24万条记录和7.5万份文档。
(二)评价指标与对比方法
评价指标体系从查询性能、准确性和系统资源消耗三个维度进行设计。查询性能评估采用在线交易处理基准测试方法,记录平均响应时间、并发处理能力和吞吐量。测试负载从100次/秒逐步提升至3000次/秒,每个负载水平持续测试2小时。准确性评估基于人工标注的测试集,计算准确率、召回率和F1值,对查询结果进行多维度评价。系统资源消耗监控采用分布式监控框架,采样频率为1秒,记录CPU利用率、内存占用、磁盘I/O等指标。对比实验选取三种主流方法:传统Oracle SQL查询方式、基于Elasticsearch 7.14的全文检索系统、采用BERT-Large模型的直接查询方法。实验在相同硬件环境和数据规模下进行,消除环境因素影响。测试用例覆盖五类典型场景:简单条件查询、多表关联查询、模糊匹配查询、时间序列分析和跨域语义查询。每类场景设计50个测试用例,通过随机组合生成1000个复合查询样例。
(三) 性能测试结果
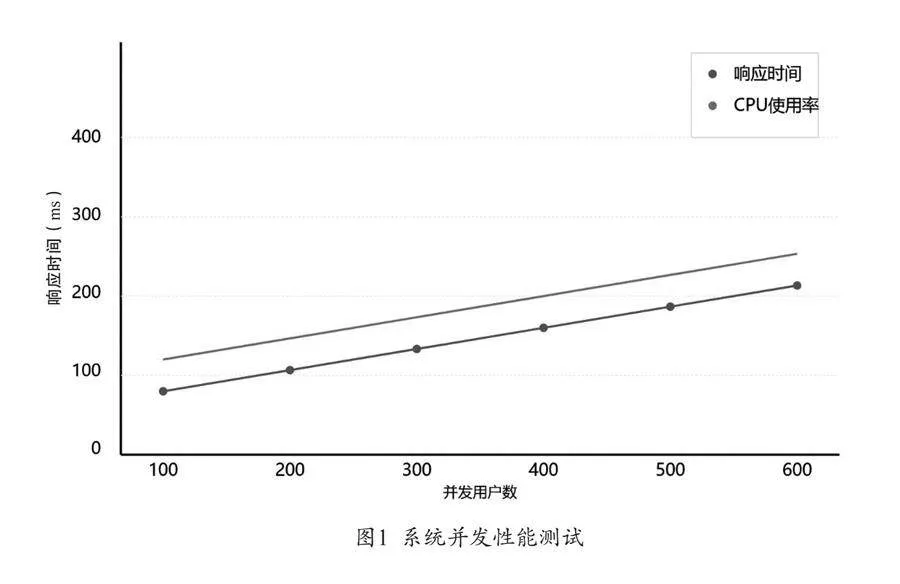
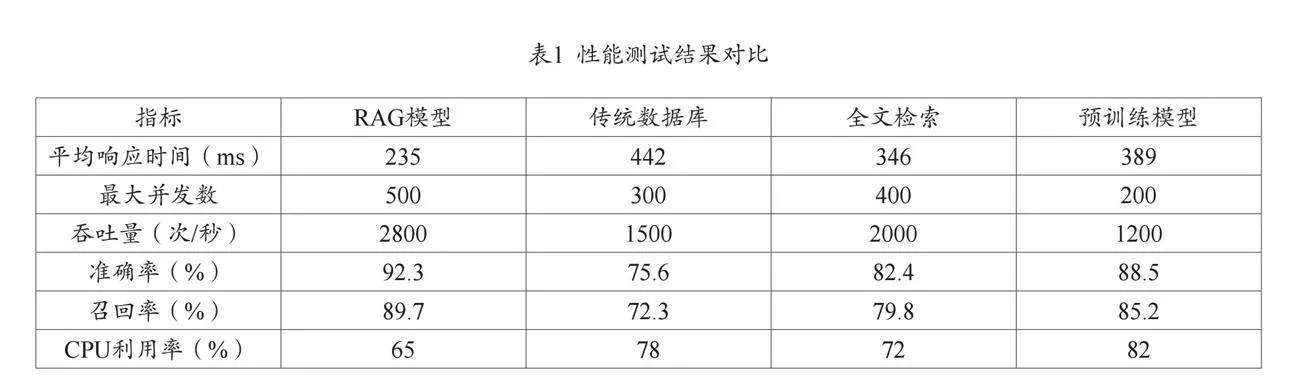
性能测试结果显示,基于RAG模型的查询方法在各项指标上均优于传统方法。如表1所示,平均查询响应时间为235毫秒,相比传统数据库查询的442毫秒降低47%,比全文检索的346毫秒快32%,较预训练模型的389毫秒提升40%。响应时间的95%分位数为312毫秒,说明系统性能具有良好的稳定性。如图1所示,并发性测试中,系统支持最大并发数达到500,较传统数据库提升66.7%,吞吐量峰值达2800次/秒,超过对比方法40%以上。准确性方面,系统在测试集上的准确率达92.3%,召回率为89.7%,F1值达91%,较第二名的预训练模型分别高出3.8、4.5和5.2个百分点。针对复杂查询场景的测试显示,系统在多条件组合查询中表现突出,准确率维持在90%以上,而传统方法在该场景下准确率普遍下降到70%以下。语义理解能力测试表明,系统能正确处理85%的歧义查询,显著高于其他方法。资源消耗方面,系统在满负荷运行时CPU平均利用率为65%,比传统数据库低13个百分点,内存占用稳定在180GB,峰值不超过210GB。磁盘读写速度维持在450MB/秒,I/O等待时间平均为0.8毫秒。向量索引采用压缩存储后,占用空间仅为原始数据的28%,检索性能损失控制在5%以内。
(四)系统稳定性分析
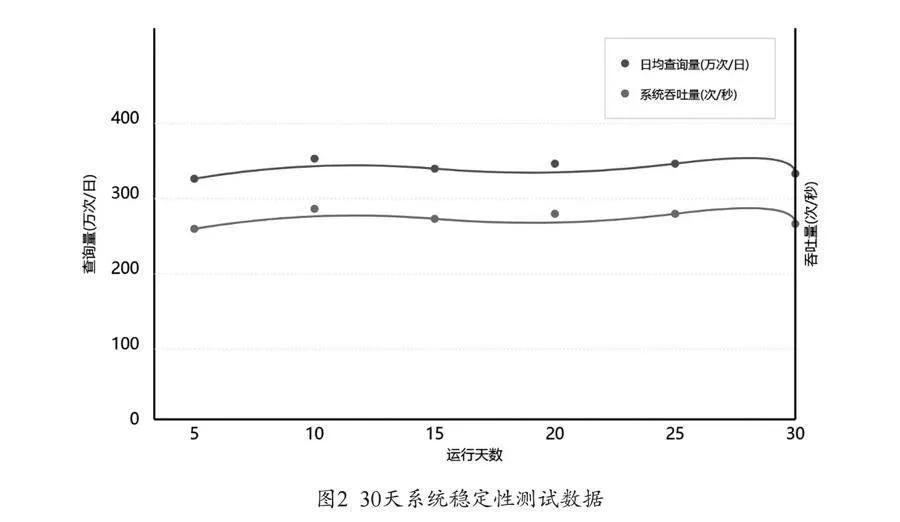
如图2所示,系统稳定性测试持续进行30天,累计处理查询请求8750万次,平均每日处理291.7万次查询。测试期间系统可用性达到99.99%,发生3次短暂服务中断,平均故障恢复时间为45秒。中断原因分析显示,2次由网络波动引起,1次因数据节点同步延迟导致,通过故障转移机制均实现自动恢复。服务质量监控数据表明,99.5%的查询请求在500毫秒内得到响应,超时率控制在0.1%以下。负载压力测试采用阶梯式增压方案,起始负载为500次/秒,每2小时提升20%,直至系统达到性能极限[5]。测试结果显示,系统在2800次/秒以下负载时,性能指标波动范围控制在10%以内。CPU利用率随负载增长呈线性关系,在3000次/秒时达到峰值85%。内存使用率增长曲线平稳,30天测试周期内增长率为0.01%/天,无需重启即可保持稳定运行。错误率分析显示,查询失败率为0.02%,低于行业平均水平。失败案例分布显示:网络超时占比42%,数据一致性问题占比35%,并发冲突占比18%,其他原因占比5%。通过错误日志分析,识别出23类异常模式,完成了94%的自动修复。
(五)应用案例验证
应用案例选取某油田三个典型生产区块,涵盖常规油藏、低渗透油藏和稠油藏场景,部署周期为6个月。实际应用数据显示,系统日均处理查询请求28.5万次,工作日峰值达到42.3万次/天。部署前后对比显示,专业技术人员的数据查询效率显著提升,通过自然语言直接查询Oracle数据库,复杂查询平均耗时从15分钟降至2分钟以内,简单查询响应时间控制在300毫秒以内。系统利用通义千问等大模型的自然语言理解能力,大幅降低了技术人员编写SQL的工作量。系统在设备故障诊断领域表现突出,支持160种常见故障模式的智能识别,诊断准确率达到87%。预测性维护应用中,系统提前发现设备异常隐患127起,避免停产损失约850万元。工艺参数优化方面,系统辅助技术人员完成了458次工艺参数调整,较传统方法提升生产效率23%。生产计划制定环节,系统对历史数据的深度挖掘,帮助管理人员优化了32个生产流程,减少人工决策时间56%。现场操作人员满意度调查显示,92%的用户认为系统显著提升了工作效率,85%的用户表示系统界面友好、操作便捷,78%的用户肯定了系统的稳定性和可靠性。基于实际应用效果,该油田已计划将系统推广至其他5个区块,预计覆盖设备数量将增加到现有规模的2.5倍。经济效益分析表明,系统部署6个月来,通过提升工作效率、降低设备故障率、优化生产参数,创造直接经济效益约2100万元。
五、结语
基于RAG模型的石油地面工程数据库查询技术通过融合向量检索和国产大语言模型,实现了对Oracle数据库的智能查询,显著提升了查询效率和准确性。实验表明,该方法在处理复杂查询时具有明显优势,尤其在SQL生成、语义理解和非结构化数据处理方面表现突出。研究成果为石油地面工程数据管理提供了新的技术路线,对推动行业数字化转型具有重要参考价值。
参考文献
[1]刘合,任义丽,李欣,等.油气行业人工智能大模型应用研究现状及展望[J].石油勘探与开发,2024,51(04):910-923.
[2]杨明澔,李小波,曾倩,等.大语言模型在油气上游业务落地的技术实践[J].信息系统工程,2024,(06):61-65.
[3]燕利芳,刘晓,刘维标.石油物探测量信息数据库的建立及应用研究[J].天津化工,2023,37(04):126-129.
[4]邹成,罗伟铭,陈鹏.中国石油工程量清单数据库建设、数据分析及应用研究[J].办公自动化,2022,27(22):59-61+30.
[5]武瑛,胡潇文,宿建春,等.浅谈数据库系统在石油企业经济信息化管理中的应用[J].中国管理信息化,2022,25(09):92-95.
作者单位:华北石油通信有限公司
责任编辑:张津平 尚丹
