基于背景差分与目标检测的视频火焰检测算法
2024-12-05李帅帅王涛









摘要:针对目前基于深度学习的火焰检测任务中存在的识别准确率低、冗余计算较多的问题,提出一种基于ViBe与轻量级目标检测算法的火焰检测算法VYfire。首先,针对火焰的动态特征,通过引入自适应阈值的ViBe算法,提取完整的动态区域;其次,利用集成了轻量化模块FasterNet和加权双向特征金字塔网络BiFPN的YOLOv5s作为检测基准模型,对动态区域进行检测,实现火焰的精准框定。实验结果表明,改进后的检测模型较YOLOv5s平均检测精度提升了1.1%,参数量下降了15.4%,浮点运算次数下降了18.4%。并且VYfire在测试视频集上保持较高检测速度的同时达到了95.57%的平均召回率和0.77%的平均误检率,能够满足火焰检测任务的实时性和精度要求。
关键词:深度学习;火焰检测;ViBe
中图分类号:TP311文献标识码:A文章编号:1673-1794(2024)05-0001-04
作者简介:李帅帅,安徽理工大学计算机科学与工程学院硕士生,研究方向:目标检测(安徽淮南232001);通信作者:王涛,滁州学院无人应急装备与灾害数字化重建安徽省联合共建学科重点实验室教授,博士,硕士生导师,研究方向:应急技术与管理(安徽滁州239000)。
基金项目:安徽省重点研究与开发计划“智能化复合射流及凝胶细水雾关键技术与装备研究”(2023g07020007);安徽省高等学校科研计划项目“留守儿童溺水突发事件敏捷预警建模与响应技术研究”(2022AH051101)
收稿日期:2024-03-27
传统火灾检测主要依赖温湿度、烟雾和一氧化碳传感器监测环境变化,从而判断火灾的发生[1]。随着视频监控和计算机视觉技术的不断发展,基于视频图像的火焰检测技术逐渐受到了研究者关注。
其中,Kosmas等[2]利用支持向量机(SVM)分类器,结合火焰的运动规律、特殊纹理、颜色概率以及闪烁频率等特征来进行火灾检测。Foggia等[3]则采用专家系统,基于火焰的形状、颜色和运动特征构建了一套火焰规则集合,虽然提高了检测准确性,但也相应增加了误报率。王彦朋等[4]针对ViBe算法进行了改进,利用三帧差分原理与ViBe算法融合,更好地提取视频前景,并构建了一个基于火焰纹理、面积、形状和闪烁的熵值加权火焰识别模型。上述基于人工特征提取的火焰检测方法能在一定程度上检测火焰,但存在检测精度低、易误检或漏检的问题。此外,由于实际场景中的背景复杂性很高,人工设计的火焰静态特征存在大量冗余信息。
近年来,基于深度学习的视频火焰检测受到广泛关注。相较于早期图像检测方法,基于深度学习的火焰检测方法能够提取到更深层次的火焰特征。石磊等[5]将SSD的基础网络使用DenseNet网络进行替换,对小目标火焰的检测能力得到提高,但存在数据集过拟合现象。金程拓等[6]通过在YOLOX中引入ECA注意力模块、使用SIoU损失函数和GELU激活函数等手段,提高了模型对火焰烟雾的提取能力和检测精度。Wu等[7]通过改进NMS与SPP模块,提高了算法对小火焰目标的检测效果,但对于形似火焰的灯光仍存在较高误检率。为克服单个网络模型在复杂背景条件下特征提取的局限性,Xu等[8]采用了EfficientNet和YOLOv5两个模型并行协同检测火灾,提高了检测精度和召回率,但集成模型增加了模型参数和计算冗余。相较于早期图像检测方法,基于深度学习的火焰检测算法能够尽可能多地提取火焰深层静态特征,减少人工特征提取的冗余信息与误差。
以上基于深度学习的火灾检测算法模型复杂且计算量大,并且在实际应用中可能因光线变化、环境背景复杂的影响和特征提取网络的局限性导致误检。针对该问题,文章提出一种基于改进ViBe算法和轻量化YOLOv5s的视频火焰检测算法,该算法能够在保持较低计算冗余和误检率的同时,提高检测的准确率,并适用于复杂背景下的火焰检测。
1 VYfire算法流程
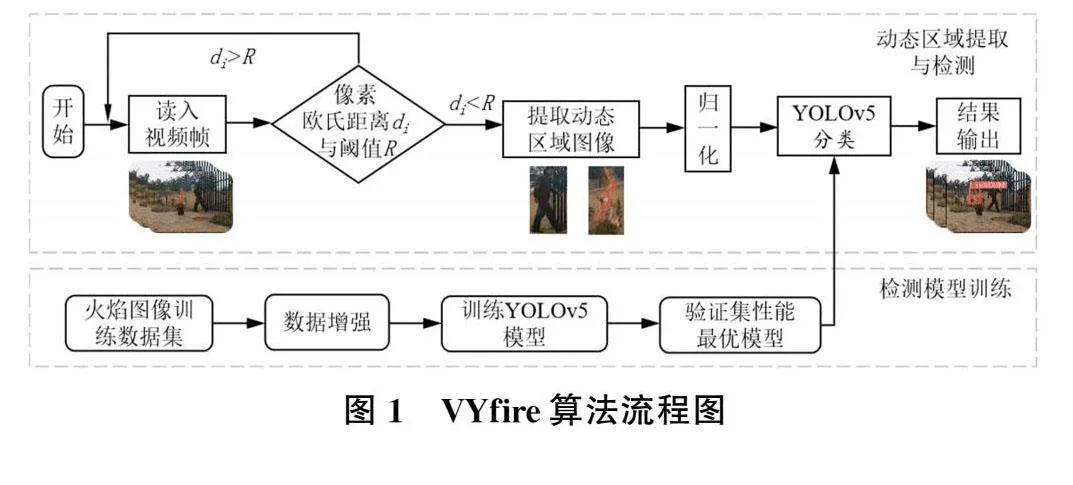
VYfire算法是ViBe与YOLOv5s的融合算法,包括改进ViBe算法动态区域提取和轻量化YOLOv5s火焰目标检测两个部分,主要流程为:1)通过改进的ViBe算法对运动区域图像进行提取,排除静态背景的干扰;2)对处理后的视频帧中动态区域使用训练后的YOLOv5s模型进行检测,若动态区域中存在火焰,则对目标区域进行框定。整体算法流程如图1所示。
2 ViBe运动前景提取
图像形火灾监测常利用固定视角的监控,具有背景相对稳定的特性。考虑到火焰的动态特征,若能将动态区域进行提取并单独进行检测,不仅能消除复杂背景对检测的影响,降低误检率,还能降低后续对目标检测算法的性能需求。
结合检测实时性的需求,选择背景差分ViBe算法作为运动前景提取算法。ViBe算法是一种像素级视频背景建模算法,与其他差分算法相比具有更小的内存占用量与计算量。主要包括背景初始化、前景检测和背景更新三个部分。
ViBe算法中的匹配阈值(R0=20)适用于大多数目标或场景,但固定的匹配阈值在火焰目标像素分类中表现不佳,易导致背景噪声增加。为了提高像素分类的准确性,本研究提出一种计算像素背景模型变化程度的度量方法。该方法以变化程度为基础,对高动态像素区域设置较低匹配阈值,减少该区域中对背景与前景像素的误判;对低动态像素区域设置较高的匹配阈值,提升该区域中对细微前景变化分割的敏感度。
以某像素(x,y)为中心,取其相邻5×5像素区域建立背景样本集Mi(x,y),像素(x,y)背景模型的平均灰度值与标准偏差为:
式中:N为样本集中样本个数;g(x,y)表示背景样本集的平均灰度值;σ(x,y)表示背景样本集的标准偏差。比较相邻时间间隔内,同位置两像素背景样本集的变化程度为:
式中:t为时刻;cg、cσ为相邻时间间隔内像素(x,y)背景样本集平均灰度和标准偏差各自的差值;cmix为背景样本集的变化程度;α1和α2为调节参数,表征平均灰度差值和标准偏差差值在衡量因子中的贡献度。新的匹配阈值可以表示为:
式中,R(x,y)为像素(x,y)的匹配阈值;R0为初始匹配阈值;λ为调节背景模型的更新速率因子;γ为设置的比例因子。
使用引入自适应阈值前后的ViBe算法对不同场景下的火焰视频进行动态区域提取,提取到的火焰区域如图2所示。图2(a)为火焰视频中的某帧,图2(b)为使用未改进的ViBe算法对视频处理后的二值图,图2(c)为使用改进后的ViBe算法对视频处理后的二值图。由图可知,引入自适应阈值的ViBe算法提取到的火焰动态前景区域噪声点明显减少,并且提取到的动态区域更加完整。
3改进YOLOv5s火焰检测模型
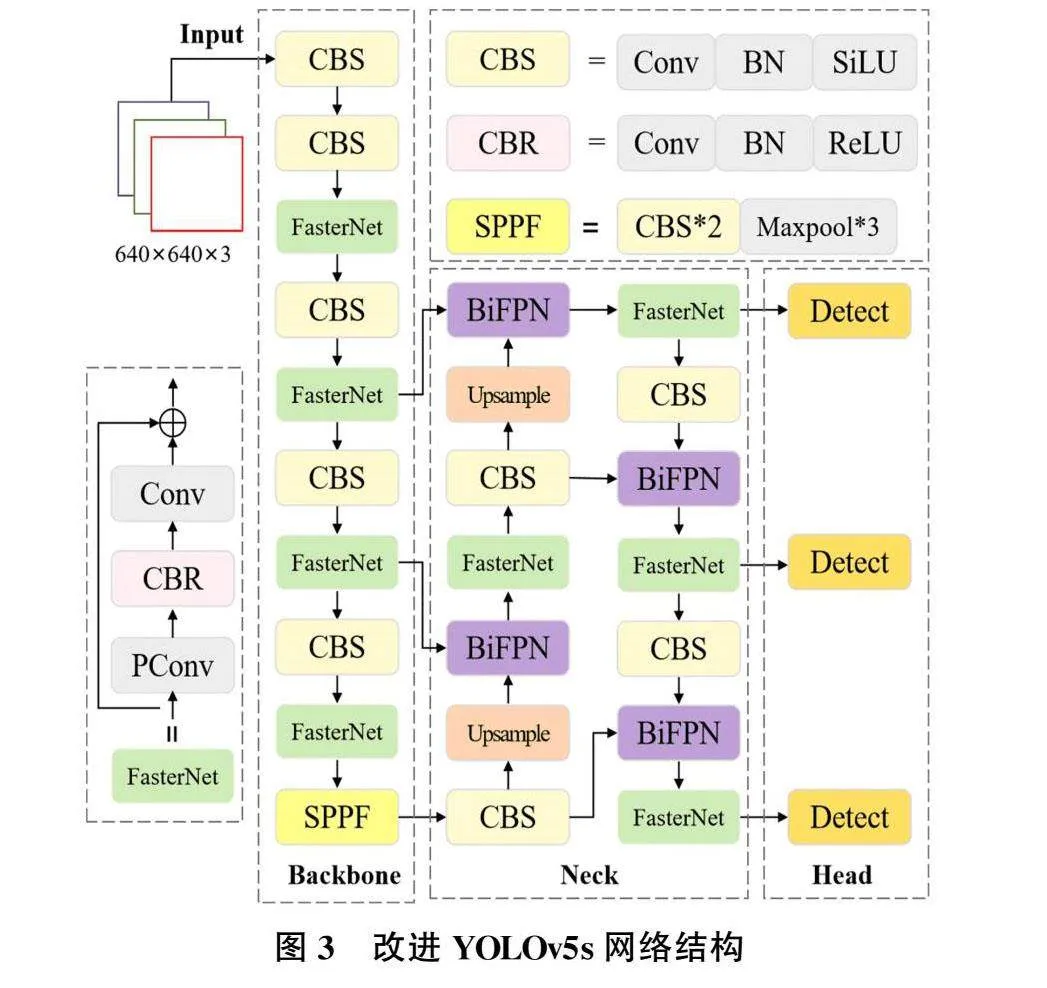
YOLOv5s网络模型在目标检测任务中有着优异的效果,但由于深度学习模型计算量大,并存在火焰早期目标较小、图像背景环境复杂等情况,进一步提高了检测难度。为了提升火焰的检测精度并进一步降低网络参数数量,本研究基于YOLOv5s改进视频火焰检测网络模型。该模型对于YOLOv5s网络进行了两个不同部分的改进,一是通过引入轻量化FasterNet模块融入YOLOv5s骨干与颈部层进行轻量化改进,降低网络模型的参数数量和计算复杂度。二是将颈部原Concat层替换为BiFPN特征融合算法,将浅层的特征图进行特征融合,提升对低像素小目标的检测精度。改进后的网络结构如图3所示。
3.1融合FasterNet模块
在卷积神经网络CNN中,随着网络深度的增加和特征通道数的增多,卷积操作的计算量和冗余计算也会急剧上升,导致计算资源的浪费和效率的降低。部分卷积[9](Partial Convolution,PConv)的核心思想是在进行卷积操作时,选择性地只在部分输入通道上进行常规卷积(Conv)操作,而对其他通道不变,利用特征映射中的冗余性,PConv能够在不损失较多信息的前提下,有效降低计算成本。相较于Conv,PConv能够更有效地提取空间特征,并且计算量更低,能够充分利用计算资源,计算方式如图4所示。
对于给定输入数据I∈Rc×h×w,使用一个k×k普通卷积计算输出,完成一次卷积所需的浮点运算次数(Floating point operations,FLOPs)如下:
式中,F为完成一次卷积所需的计算量,h为高度,w为宽度,k为卷积核大小,c为进行卷积运算的特征图通道数。
部分卷积PConv仅对部分输入通道采用Conv进行空间特征提取,并保持其余通道不变。假设取cplt;c个连续通道作为整个特征映射的代表进行计算,完成一次卷积所需计算量计算式如下:
可知PConv比Conv具有更低的浮点运算量。为了充分利用来自所有通道的信息,通过在一个3×3PConv后接两个1×1PWConv,并且只在中间层后加入归一化层(BN)和激活层(ReLU)保持特征多样性,构建了FasterNet模块,如图4所示。通过在主干网络中引入FasterNet模块能够在大幅减少冗余计算的同时,更高效地提取空间特征。
3.2引入加权双向特征金字塔网络
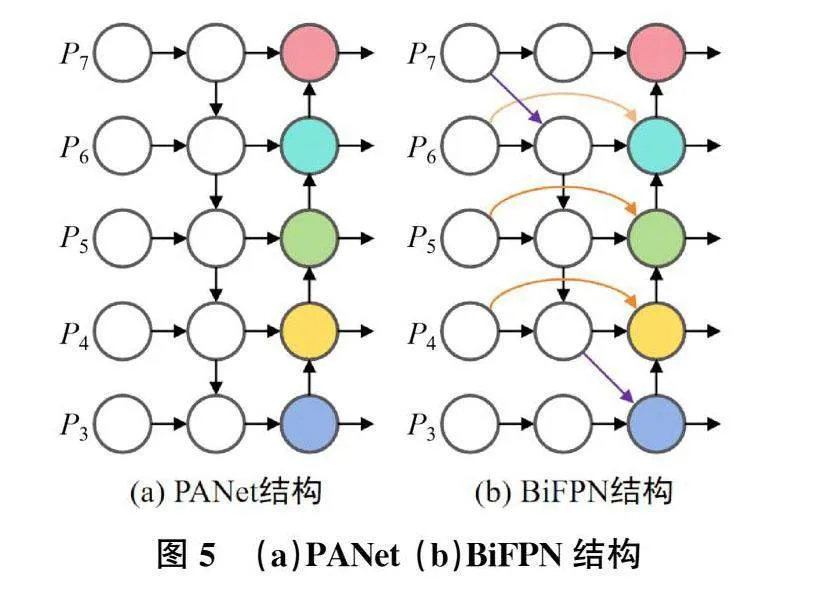
在YOLOv5中网络的Neck采用PANet[10]的网络结构,PAN网络是自下而上,从低分辨率的特征图开始向上采样,采用级联的方式进行特征融合,可以保留更多的细节信息[11]。PANet采用融合多尺度特征图像的方式,增强对不同尺度目标的检测能力,其结构如图5(a)所示。由于主干特征提取网络输出的特征图尺度各异,通常浅层的高分辨率特征图携带丰富的细节信息,对于小尺度目标的检测更具优势。而深层的小尺度特征图则携带更多的语义信息和更大的感受野,更适用于大尺度或复杂目标的识别。
加权双向特征金字塔网络(BiFPN)进一步推进了这种多尺度融合方式,采用高效的双向跨尺度连接机制,使得不同尺度的特征图能够相互传递信息,实现有效的特征融合,从而提升模型的性能与效果。因此,本研究采用BiFPN结构替换YOLOv5s网络模型中的PANet结构,以增强网络模型的多尺度适应能力,如图5(b)所示。
4实验结果与分析
4.1实验配置
本研究实验环境以pytorch为框架,采用Py-thon3.7编程语言,使用CUDA11.3版本加速训练;硬件环境:CPU型号R7-6800H,16G-DDR5内存,GPU型号为NVIDIA GeForceRTX30608G。训练参数设置:Epochs为150,初始学习率为1e-2,权重衰减值为5e-4,Batchsize设为16。
4.2数据集
本研究实验数据集来自网络搜集、土耳其Bilkent大学(https://homepages.inf.ed.ac.uk/rbf/CVonline/)和韩国Keimyung大学(https://cvpr.kmu.ac.kr/)公开的火焰视频库。包括火焰图片和火焰视频随机抽帧提取得到的图片共5380张火焰图像构成本次实验的数据集。其中训练集含4842张图片,测试集包括538张图片,部分数据如图6所示。
4.3改进YOLOv5s实验结果
4.3.1评价指标
为了评估改进YOLOv5s检测模型对火焰目标的检测能力和性能,本研究使用平均精度均值(Mean AveragePrecision,mAP),模型参数量Pa-ram,浮点运算次数FLOPs对模型进行评估。
式中,P为精确率;R为召回率;C表示类别数量;由于本研究检测目标仅火焰一类,因此i、C取值为1;APi表示第i个类别的平均准确率,作为检测精度指标,mAP值越高、漏检率越低,模型性能越好。
4.3.2消融实验
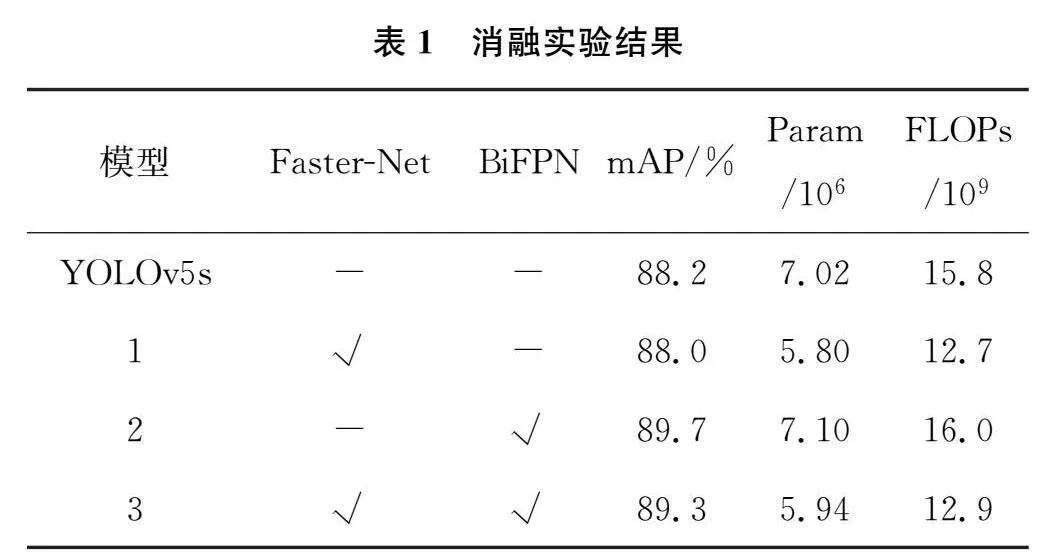
为了验证本研究改进YOLOv5s火焰检测算法的各优化部分对算法的影响,以YOLOv5s为基准模型并使用相同训练方式开展消融实验,其中“√”表示模型中使用该方法,“-”表示模型中未使用该方法,实验结果如表1所示。
根据表1的消融实验结果可看出,引入Fast-erNet模块后的平均检测精度较YOLOv5s降低了0.2%,参数量下降了1.22M,浮点运算次数下降了3.1GFLOPs。引入BiFPN后的平均检测精度较YOLOv5s提升了1.5%,参数量上升了0.08M,浮点运算次数上升了0.2GFLOPs。二者同时引入后的平均检测精度较YOLOv5s提升了1.1%,参数量下降了1.08M,浮点运算次数下降了2.9GFLOPs。可以看出改进后的YOLOv5s可以在保持较高精度的同时有效降低计算成本。
4.3.3对比实验
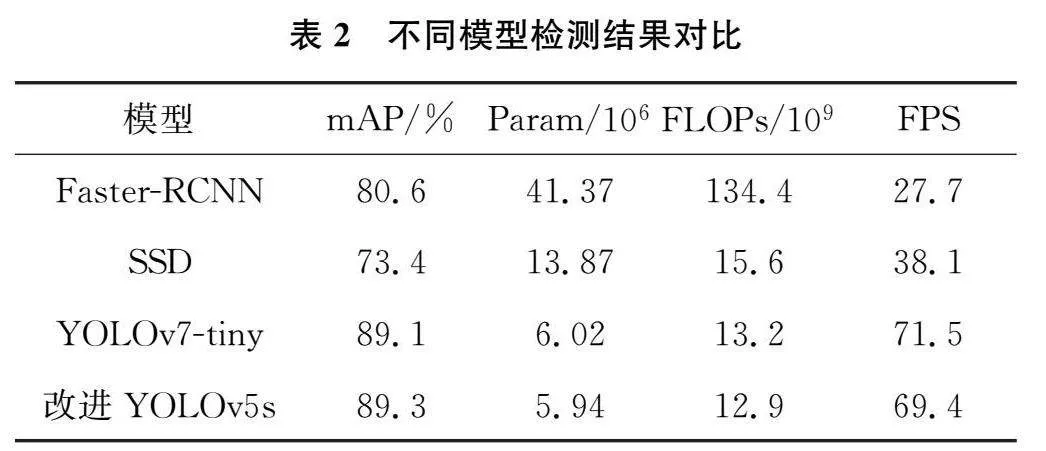
为了验证本研究改进YOLOv5s算法的检测性能,与Fatser-RCNN、SSD、YOLOv7-tiny在相同实验环境与评估标准下进行比较,实验结果如表2所示。可以看出,改进YOLOv5s算法相对于Fatser-RCNN、SSD、YOLOv7-tiny,在平均检测精度提高的同时,参数量和计算量有较大幅度的降低,并且保持较高帧率,能够达到火焰检测算法的轻量化和检测速度需求。
4.4 VYfire算法实验结果与分析
图7为Fatser-RCNN、SSD、YOLOv7-tiny与本研究VYfire的部分实验检测结果对比图。图7(a)为文献[12]算法检测效果,图7(b)为原始YOLOv5s检测效果,图7(c)为本研究算法检测效果。可以看出,上述三种算法检测与定位效果类似,但文献[12]算法部分帧框定范围过大、YOLOv5s在部分帧出现了对非火静态物体的误检。与之相比,VYfire置信度相对更高、框选更精准、也能避免对静态区域的误检,进一步证明了VYfire算法在火焰检测方面的有效性。
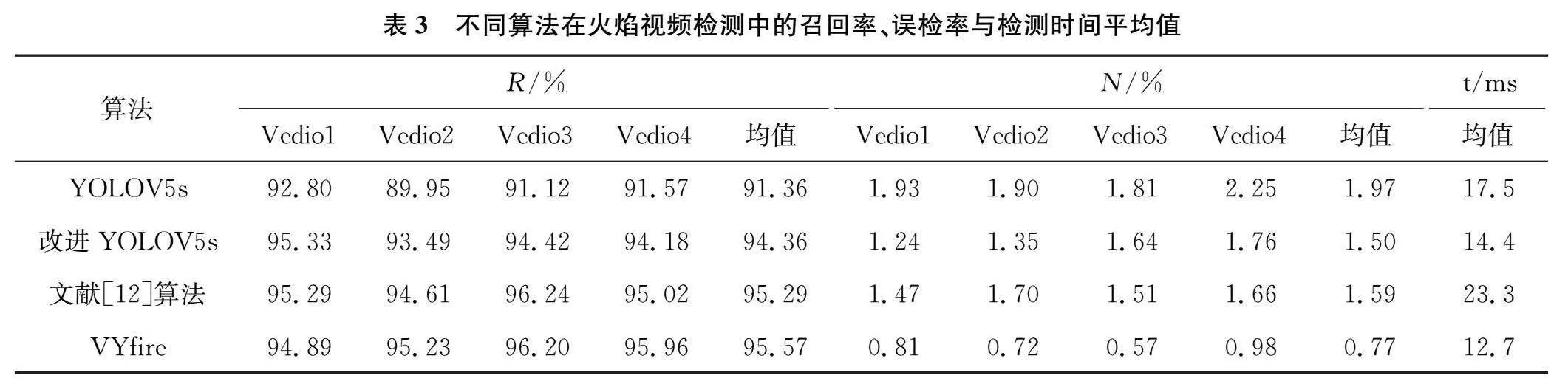
为了充分验证VYfire算法的性能,采用召回率R、误检率N和检测时间平均值三个评价标准对实验结果进行分析评价。将文献[12]算法、改进前后YOLOv5s与VYfire算法进行对比。对比结果如表3所示。
由表3可知,VYfire算法能够实现更高的平均召回率和更低的平均误检率。表中文献[12]算法、原始YOLOv5s以及改进YOLOv5s算法虽然能达到较高的召回率,但误检率也相对较高。由于ViBe算法提取运动前景的操作,剔除了场景中的大量静止物体,减少复杂背景对检测模型的影响,有效降低误检率。同时引入了BiFPN的检测网络能够提取到更深层次的火焰静态特征,实现对不同尺度大小目标更好的检测效果。
5结语
针对现有火焰检测算法存在的误检率较高、冗余计算较多的问题,本研究提出了一种能够排除复杂静态背景影响的火焰检测算法VYfire。首先通过引入自适应阈值的ViBe算法,提取完整的动态前景区域,以排除静态复杂背景对检测的干扰;其次利用引入轻量化模块FasterNet和加权双向特征金字塔网络BiFPN的YOLOv5s检测模型对提取的动态区域进行检测。实验证明,改进后的检测模型较YOLOv5s平均检测精度提升了1.1%,参数量下降了15.4%,浮点运算次数下降了18.4%。并且VYfire在测试视频集上达到了95.57%的平均召回率和0.77%的平均误检率,并且能保持较高的检测速度,符合火灾监测任务的高精度和常态运行需求。
[参考文献]
[1]JIN C,WANG T,ALHUSAINI N,etal.Videofiredetectionmethodsbased on deeplearning:datasets,meth-ods,andfuturedirections[J].Fire,2023,6(8):315.
[2]K.DIMITROPOULOS,P.BARMPOUTIS,N.GRAM-MALIDIS.Spatio-Temporal flame modeling and dynamic texture analysis for automatic video based fire detection[J].IEEE Transactions on Circuitsand Systems for Video Technology,2015,25(2):339-351.
[3]P.FOGGIA,A.SAGGESE,AND M.VENTO.Real-time f-iredetectionforvediosurveillanceapplicationsusingacom-bination ofexpertsbased on color,shape,and motion[J].IEEE Transactions on Circuits and Systems for Video Technology,2015,25(9):1545-1556.
[4]王彦朋,柴文,王晓君.基于熵值加权支持向量机的火焰检测方法[J].太赫兹科学与电子信息学报,2021,19(3):458-464.
[5]石磊,张海刚,杨金锋.基于改进型SSD的视频烟火检测算法[J].计算机应用与软件,2021,38(12):161-167.
[6]金程拓,赵永智,王涛,等.基于改进YOLOX轻量级的烟雾火焰目标检测方法[J].滁州学院学报,2023,25(5):40-45.
[7]WU Z,XUE R,LI H.Real-time vedio fire detection vi-amodifiedYOLOv5network model[J].Fire Technology,2022:1-27.
[8]XU RJ,LIN H F,LU K J,etal.AForestFireDetectionSystem Based on Ensemble Learning[J].Forests,2021,12(2):217.
[9]CHEN J R,KAO S H,HE H,etal.Run,don'twalk:chasing higher FLOPS for faster neural n-etworks[C]//IEEEConferenceonComputerVisionandPatternRecogni-tion.Vancouver:2023:12021-12031.
[10]LIUS,QIL,QIN HF,etal.Path aggregation networkforinstancesegmentation[C]//IEEE Conferenceon Computer Vision and Pattern Recognition.Salt Lake City,2018:8759-8768.
[11]WANG G,FANG H,WANG D,etal.Ceramic tile surfacedefectdetection based on deeplearning[J].CeramicsInter-national,2022,48(8):11085-11093.
[12]ROHIT R,POOSHKAR R,PRABHAT K,etal.Featurebased video stabilization based on boos-ted HAAR Cascade and representative point matchingalgorithm[J].Image and VisionComputing,2020,101:103957.
责任编辑:陈星宇
