面向多租户数据中心的联邦学习架构下通信开销优化方法
2024-11-04程华盛敬超





摘 要:为降低多租户数据中心联邦学习架构下的高通信开销问题,提出一种基于三元演化模型参数的通信开销优化算法。首先,建立面向多租户数据中心的联邦学习架构模型来实现数据隐私保护;其次,针对联邦学习架构的引入导致租户和数据中心交互产生了过高的通信开销问题,提出一种基于三元演化模型参数的通信开销优化算法,通过结合最优局部模型和三元向量化模型参数的演化方向来减少租户与数据中心模型参数传输之间的冗余通信;同时,基于联邦学习的隐私研究论证分析了在传输通信过程中所提算法能有效保障参与训练租户的隐私信息。最后,实验结果表明,所提方法在保障训练精度的前提下,相比于联邦平均对比算法能有效降低30%的冗余通信开销。
关键词:多租户数据中心; 联邦学习; 通信开销优化; 三元演化模型参数
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)09-036-2823-08
doi:10.19734/j.issn.1001-3695.2024.01.0002
Optimization method for communication overhead in federated learningarchitecture for multi-tenant data center
Cheng Huashenga, Jing Chaoa,b
(a.School of Computer Science & Engineering, b.Guangxi Key Laboratory of Embedded Technology & Intelligent System, Guilin University of Technology, Guilin Guangxi 541004, China)
Abstract:To address the issue of high communication cost under the federated learning framework in multi-tenant data centers, this paper proposed an optimization algorithm based on ternary evolutionary model parameters. Firstly,it constructed a federated learning architecture tailored to multi-tenant data centers for data privacy protection. Secondly, in response to the excessive communication overhead stemming from the implementation of the federated learning framework, which increasing interactions between tenants and the data center, it proposed an optimization algorithm that utilized ternary evolutionary model parameters. This algorithm aimed to reduce redundant communication in the exchange of model parameters between tenants and the data center by integrating the optimal local model with the evolutionary direction of ternary vectorized model parameters. Moreover, by analyzing privacy research based on federated learning, the algorithm effectively ensured the privacy of tenants participating in the training during the communication process. Finally, experimental results demonstrate that, while maintaining training accuracy, the proposed method can effectively reduce redundant communication costs by 30% compared to the federated averaging baseline algorithm.
Key words:multi-tenant data center; federated learning; optimization of communication cost; ternarizing evolution of model parameters
0 引言
数字经济迅速发展使得获取、处理和存储的数据量也将呈指数增长,这就造成数据中心的需求也随之日益增加。建造全新的数据中心,不仅要考虑场地和设备等问题,还需要配套数据存储、处理及管理等设施,从而消耗大量的费用和资源。近些年来,大量企业用户为减少数据中心在建造以及维护上的资源开销,选择以租赁的形式租用数据中心服务器来运营和处理业务需求,以这种模式运营的数据中心被称为多租户数据中心(multi-tenant data centers,MTDC) [1]。它比私有数据中心更具有成本效益和灵活性,所以MTDC得到了广泛的应用。
由于在电力需求和管理方面上更具有灵活性,多租户数据中心逐渐成为电力紧急需求响应(emergency demand response,EDR)的关键参与者之一[2]。在紧急情况下,电网协调各租户响应需求快速削减或转移负荷,以防止重大紧急损失。现有的EDR机制依靠传输响应的需求量以及相应的报酬来激励租户[3],或通过改进智能算法优化电力成本[4]满足电力需求响应,然而在传输交互过程中租户的隐私信息可能会被不值得信赖的租户或中间运营商获取,从而造成严重的隐私泄露问题,这也成为租户参与EDR的顾虑之一。联邦学习是一种新兴的分布式机器学习架构[5],主要是在不接触参与训练租户本地数据的情况下,共同合作训练机器学习模型。为此,本文在多租户数据中心场景下引入联邦学习(federated learning,FL)架构来处理该问题。
在联邦学习过程中,参与训练的租户会根据本地数据进行模型训练生成局部模型,云端服务器聚合局部模型并更新全局模型,通过多轮迭代收敛全局模型精度到预期精度。然而,随着联邦学习模型训练轮数的增加,为了达到预期精度会产生大量的通信开销,给通信带宽资源造成了严重的负担。因此,本文基于多租户数据中心联邦学习架构下的高通信开销的场景,提出了一种基于三元演化模型参数的通信优化算法,降低联邦学习过程中的通信开销。本文的主要贡献如下:
a)为了实现多租户数据中心场景下租户的数据隐私保护,本文引入了联邦学习架构,建立面向多租户数据中心的联邦学习架构模型来保障用户隐私。
b)为了降低联邦学习架构引入的交互通信开销问题,在面向多租户数据中心场景下提出一种三元演化模型参数的通信优化算法来降低其交互通信开销。
c)针对隐私保护需求,用理论论证和分析了基于三元演化模型参数的通信优化算法,分析结果表明在传输通信过程中,所提方法能够有效保障参与联邦学习训练租户的隐私信息。
d)通过仿真实验验证了所提方法的有效性,实验结果表明,所提算法在满足训练精度达到预期精度的前提下,相比于联邦平均等对比算法,能有效减少冗余的交互通信开销。
1 相关工作
近些年来,为了鼓励多租户数据中心的租户参与电力需求响应,很多研究人员都专注于设计激励机制[6~9]。然而忽略了在需求响应过程中,由于租户的通信交互导致的隐私保护问题,联邦学习可以有效解决这类问题。目前已有一些研究采用联邦学习解决隐私问题。文献[10]提出了一个隐私保护框架,允许多个用户在组合数据集上训练深度学习模型,而无须共享本地数据集。处于隐私保护的考虑,文献[10]提出了两种用于交换模型参数的网络拓扑(主-辅拓扑和完全连接拓扑),通过标准传输层安全保护其他训练用户、中心服务器和用户之间的通信隐私。文献[11]设计了一个结合多方联合学习给定目标的系统,系统中每个本地用户异步地将其数据集上获得的局部梯度部分共享给中心服务器。然而,虽然训练数据没有在用户之间共享,但攻击者可以收集交换的梯度值,并推断特定用户的训练数据集的敏感信息。然而这项工作没有考虑安全通信来保护梯度免受内部攻击以及相应的通信成本开销问题。张泽辉等人[12]为保护数据隐私,将同态加密算法技术和联邦学习相结合,提出联邦深度神经网络模型,该模型通过对其权重参数的同态加密保证了数据的隐私性。周炜等人[13]为参与训练的用户提供隐私保护,提出基于区块链的去中心化、安全、公平的联邦学习模型,该模型主要用于保护协同合作训练用户的中间参数隐私,在多方协作的环境下保障了各参与方的隐私信息。从以上研究中可以发现,现有工作通过联邦学习架构在一定程度上保证了用户的隐私性,但为此产生了不必要的冗余通信开销,加大了通信传输开销。
为了减少通信开销成本,国内外研究人员提出了关于提高联邦学习过程中通信效率的解决方案:文献[14~16]通过缓解同步冲突来减小通信压力;文献[17,18]采用流水线化逐层参数传输来进行高效通信;文献[19~21]提出优化不同参数组的传输顺序来提高通信效率;文献[22]则建议将梯度积量化为仅1位传输,以此来提高10倍的通信速率;Alistarh等人[23]提出QSGD方法,试图找到精度和梯度压缩比之间的平衡来降低传输消耗;Konen等人[24]采用了概率量化方法,使量化值成为初始值的无偏估计量来减小通信负担;唐伦等人[25]提出一种阈值自适应的梯度通信压缩机制,在保证深度学习任务完成准确性的同时,通过减少梯度交互通信次数,有效地提高了模型的整体通信效率;文献[26]设计了在给定压缩比的情况下,分别选择正梯度更新和负梯度更新的一部分,以满足给定的压缩比率,同时在聚合后保持预期梯度;文献[27]针对物联网异构系统,参考改进的联邦平均算法,提出了一种基于层次联邦学习体系结构的用户分配和资源分配优化方案,减少边缘节点和中心服务器之间的通信轮数,从而加快联邦学习训练速度,降低通信开销。上述研究在提高通信效率方面有了很大的提升,减轻了联邦学习训练过程中的通信负担,但在实际的训练过程中,没有考虑租户的隐私信息泄露等问题,从而大大降低了租户参与需求响应的积极性。
从以上研究可以发现,现有工作不是用较高的通信成本换取对于租户个人隐私的保护,就是为解决通信效率问题而忽视隐私问题。本文综合考虑了隐私安全和通信开销优化问题,建立面向多租户数据中心的联邦学习架构模型,并提出基于三元演化模型参数的通信优化算法。
2 系统模型及问题描述
2.1 联邦学习架构模型
图1展示了多租户数据中心的联邦学习架构(multi-tenant data center with federated learning framework,MFF),主要包括以下三种角色:a)全局云端数据中心,一般用来发送或接收模型参数实例;b)出租数据资源以及管理服务的本地数据中心;c)参与训练的租户。MFF架构主要用于监控全局云端数据中心、本地数据中心以及租户的通信传输过程。该架构运行的主要过程是:假设在进行第t-1轮模型训练过程时,参与该轮训练的租户数量为n∈{1,…,N}。当进行第t轮训练时,本地数据中心获取全局云端数据中心初始化的上一轮全局模型参数Gt-1m,将初始化模型参数传输给每个租户,租户则根据本地数据集训练模型,当训练模型精度收敛到阈值后,本地数据中心会将租户训练产生的局部模型Ltn={Ltn,m|m∈1,…,M且n∈1,…,N}上传至全局云端数据中心。最后,由全局云端数据中心聚合局部模型形成全局模型Gtm={Lt1,…,Ltn|n∈1,…,N},当全局模型精确度达到预先设置的阈值精度θt后,则将此全局模型作为下一轮训练的初始化全局模型,开始新一轮的训练。
2.2 基于MFF架构的通信传输协议模型
为了更好地保护租户在需求响应过程中的个人隐私信息,同时为减轻响应需求过程中给租户造成的通信负担,在MFF架构中建立一种通信传输协议模型,如图2所示。该协议构建于TCP/IP协议上,主要是在本地数据中心和租户两者之间来实现消息传输,传输的主要过程是:租户首先对本地数据集训练过程中的样本函数损失值进行评估得到一个评估成本Ctn(n∈{1,…,N}),将其发送给本地数据中心,本地数据中心根据适配函数Atn选择出最优局部模型Ltn*,m(n*∈{1,…,N})后,参与该轮训练的剩余租户则通过该通信传输协议向本地数据中心发送三元向量化模型参数Vtn(n∈{1,…,N})。采用MFF架构的通信传输协议在传输过程中只有当租户发送模型参数m的三元向量演化方向发生变化时,才需要发送相应的数据包指令给本地数据中心,因此在通信传输过程中,有效减少了MFF架构的通信传输协议的带宽占用。该协议采用全双工通信传输方式,其中租户和本地数据中心承担消息的发送者和接收者的角色,而MFF架构则以消息的代理者身份对通信过程进行实时的监督管理,消息的发送者同时也可以是接收者。
此时式(13)便演变成一个非线性方程,要想在租户n本地数据集上推断出模型参数信息也就等效于求解该非线性方程。从全局云端数据中心已知的信息来看显然无法求解该非线性方程,从而在全局云端数据中心角度实现了数据隐私保护。
b)租户角度。参与训练的各租户之间被认为是互相不了解彼此数据集的私有信息。参考用于更新全局模型参数的式(2),当且仅当以下两种情况同时发生时,任一租户n才能推断出特定租户n*的本地数据集的隐私信息。
(a)租户n已经知道全局云端数据中心要求特定租户n*发送其局部模型用于更新全局模型参数;
(b)当特定租户n*发送其局部模型后,其他租户则全部发送全零的参数三元向量值。也就是确保全局云端数据中心更新的全局模型参数恰好全部来源于特定租户n*的局部模型实例。
由于各租户之间的本地数据集都是各不相同且都同样重要,其本地数据在参与训练过程中也会向不同方向演化发展,模型参数的三元向量演化方向自然也各不相同。显然,上述两种情况也不会同时发生,从而从租户角度保证了数据隐私安全。
c)防止租户之间协同合作层面。在训练过程中,基于三元演化模型参数的通信优化算法除了能保护特定租户的数据隐私之外,还能防止N-2个租户之间协同合作,恶意推断剩余租户的隐私信息。
假设共有N个租户参与训练,试想在一种极端情况下,当有N-1个租户串通恶意推断剩余租户的私人数据隐私,此时违背了b)中训练租户角度的论断。在实际训练过程中,租户间的本地数据集都属于非独立同分布类型,模型参数演化相对于上一轮的变化也并不相同。
假设有N-2个租户恶意串通,剩余2个租户为诚实可信的。根据适配函数的选择,本地数据中心在两个诚实可信的租户之间请求其中一个租户发送局部模型作为最优局部模型实例。此外,由于本地模型训练的发展要求,剩余的1个可信租户也可能发送非零的三元向量值。此时,恶意串通的租户也不能由此推断出特定租户本地数据集的隐私信息。因此,在训练过程中有效防止了租户之间恶意串通推断特定租户的数据隐私。
5 实验及结果分析
5.1 实验设置
本实验采用Python编程语言实现基于三元演化模型参数的通信优化算法,使用多线程技术以及安全套接字编程实现多租户数据中心场景下,租户、本地数据中心以及全局云端数据中心之间的通信传输,传输三元向量化模型参数采用部署基于MFF架构的通信传输协议来实现。为了验证所提算法的性能,借鉴了现有的实验方法[10,32],采用手写数字识别的标准MNIST数据集以及含有标签的CIFAR-10数据集进行仿真对比。在每次实验中,为考虑实验结果的实际有效性,将数据集的80%用于训练模型,20%用于随机测试。同时,为了客观地对所提算法进行评估,本轮实验结果是在20次独立实验的基础之上选取平均值作为最终实验结果。
5.2 对比算法及评价指标
5.2.1 对比算法
为了评估所提算法的性能以及传输通信过程中的通信开销,本文选择联邦平均算法、联邦学习训练中并行梯度下降算法、卷积-联邦学习网络算法以及改进的联邦平均算法作为CTPF的对比方案。
a)联邦平均算法(federated averaging, FedAvg)。联邦平均算法[32]是联邦学习中经典的基准算法,其特点体现在云端服务器会加权平均训练用户本轮次的模型参数梯度并加上前一轮聚合后的模型参数,采用局部随机梯度下降的方法优化本地模型,最后聚合局部模型进行全局模型参数更新作为下一轮次的初始化模型参数。
b)联邦学习训练中并行梯度下降算法(parallel gradient descent algorithm in federated learning,Parallel-FL)。相比于传统的数据分布和使用方式,当下的海量数据若仍要保存在本地,则需要研究在本地实现并行梯度下降方法。然而,对于存储体量庞大又需要保护用户隐私的数据节点,则需要在联邦学习训练中实现并行梯度下降方法。并行梯度下降算法[33]主要是当完成一个本地数据块的计算后,就会执行一次通信,获取更新后的参数值,每次迭代会选取目标函数下降最快的方向逐步向最优解靠拢,直到完成目标问题的优化任务。
c)卷积-联邦学习网络(convolutional neural networks-federa-ted learning,CNN-FL)。卷积-联邦学习网络[34]采用含有4个卷积层和2个全连接层的简单CNN来训练模型,在进行训练时,用户首先在本地数据集上进行梯度计算和参数更新,在每次训练迭代结束后,汇总每个训练用户累积的更新参数并用于最终的联邦模型更新。
d)改进的联邦平均算法(communication-efficient FedAvg,CE-FedAvg)。改进的联邦平均算法[27,35]主要采用分布式Adam优化技术代替传统的随机梯度下降以此减少通信轮数,同时采用模型压缩技术来减少达到目标精度所需的通信开销,解决了联邦学习在物联网边缘计算的高效通信问题。
5.2.2 评价指标
a)在检验所提算法训练模型的精度和训练损失值方面,通过将提出的CTPF算法与FedAvg、Parallel-FL、CNN-FL以及CE-FedAvg算法进行对比,以此来说明所提算法是在保证训练精度和训练损失值不低于对比算法的前提下,降低其交互通信开销。
b)为验证所提算法的通信开销有效性,本文通过计算交互通信过程中的数据量作为评估标准,通过对比CTPF和Fed-Avg、Parallel-FL、CNN-FL以及CE-FedAvg在实际通信传输中产生的交互通信数据量来说明五种算法在通信开销方面的差异。租户和数据中心之间进行通信传输产生的数据量主要取决于传输局部模型的大小、模型参数三元向量演化后的大小以及租户的数量。在参与联邦学习任一阶段训练中,需要将初始全局模型实例下发至租户,等该轮次训练完成后,其中某个租户将训练得到的最优局部模型上传,其余租户则发送模型参数的三元向量演化情况。理论上认为传输一位模型参数的三元向量值需要消耗4 bit,而传输整个局部模型实例则需要消耗64 bit及以上。因此,每轮次训练过程中,租户和数据中心之间通信传输产生的数据总量计算如式(14)所示。
Dtotal=Dn*+∑n≠n*DN-116(14)
其中:D是传输局部模型实例所消耗的数据量大小;N为参与该轮训练的租户数量。
c)为表明CTPF在全局迭代时间方面的优越性,本文对比CTPF和FedAvg、Parallel-FL、CNN-FL以及CE-FedAvg算法在达到相同训练精度下的全局迭代时间,以此来体现各算法之间模型训练时间上的差异。
5.3 实验结果对比与分析
5.3.1 性能对比
为确定最优局部模型与三元向量化模型参数在全局模型迭代过程中最佳的同步比例系数ω,本文动态地调整最优局部模型和三元向量化模型参数在全局模型聚合过程中的迭代次数,得到不同ω取值下的全局模型精度,具体结果如表1所示。
从表1中可以明显地注意到当ω取值为1时,测试的全局模型平均精度达到了最高值,而随着ω取值越偏离1,其测试精度也会相应地降低。这是因为在全局模型的聚合过程中,往往是在最优局部模型的基础上,利用模型参数的三元向量演化方向加以修正,两者相互结合,在逐轮的迭代更新以后才能达到预期精度。若只是单方面增加三元向量化模型参数的迭代次数或者最优局部模型的迭代次数,缺少最优局部模型作为基础或者三元向量化模型参数演化方向作为修正,得到的全局模型精度反而会逐渐降低。因此,综合全局模型的测试精度考虑,本文确定ω取值为1。
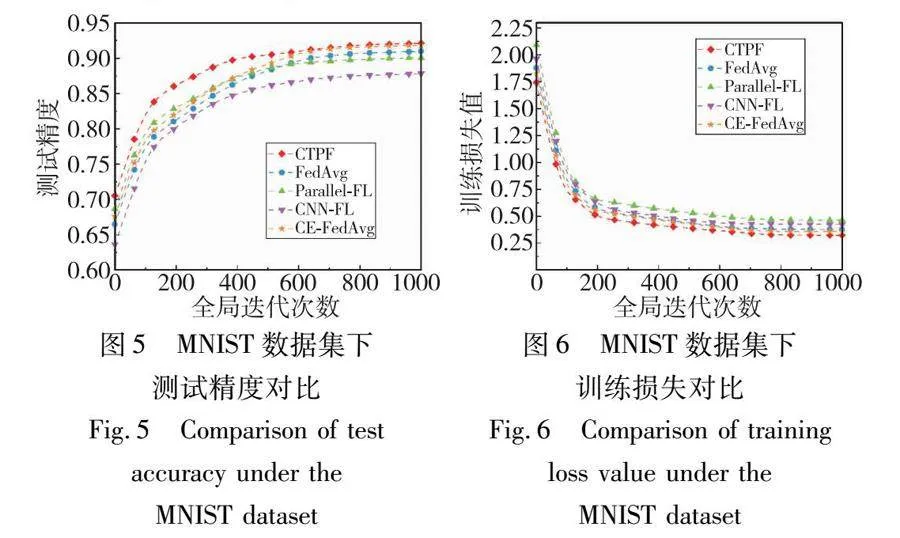
在训练过程中,为验证所提算法在不同数据集上的性能表现,选择对比CTPF和FedAvg、Parallel-FL、CNN-FL以及CE-FedAvg在CIFAR-10和MNIST数据集上的测试精度以及训练损失值。每次训练执行1 000次全局迭代,对应的测试精度以及训练损失值如图3、4所示。根据图3可以看出,在CIFAR-10数据集下,CTPF相对于其他对比算法而言,其测试精度达到96.14%,而其他算法的测试精度均未超过95%。根据图4可以看出,在CIFAR-10数据集下,CTPF的训练损失值相比于其他对比算法也降到了最小值。这是因为在全局模型的聚合过程中,CTPF在最优局部模型的基础之上,根据三元向量化参数的演化方向来加以修正,减小了训练过程中由于参数的异构性所造成的误差,而FedAvg、Parallel-FL以及CNN-FL仅仅在相同配置的参数条件下进行训练,聚合过程中并没有采用其他方式进行优化,CE-FedAvg虽然采用分布式Adam优化技术和模型压缩技术减少通信轮次和每一轮需要加载的数据量,但在实际训练过程中却降低了模型精度的要求,使得最终聚合的全局模型在测试精度和训练损失值性能上都不及CTPF。
为了考察CTPF以及对比算法在MNIST数据集下的测试精度和训练损失值性能,结果如图5、6所示。根据图5、6可以看出,CTPF在训练精度以及训练损失值上明显优于其他对比算法。同时,相比于CIFAR-10数据集,在MNIST数据集上CTPF的训练效果都有所下降。这是因为在应用MNIST数据集训练时,首先将MNIST数据集分割为数据独立同分布(independent identically distribution,IID)和非数据独立同分步(non-independent identically distribution,Non-IID)两种类型。在IID类型中,先将数据集打乱,然后为租户随机挑选一定数量的样本用于训练,而在Non-IID类型中,则根据数据标签对数据集排序,然后将其划分为不等份的数据切片,分配一定数量的数据切片给租户用于训练。在联邦学习场景下,由于租户本地数据集的差异性,会不可避免地导致训练数据呈现非独立同分布。而在Non-IID数据集上进行模型训练则会一定程度上导致训练精度降低。此外,由于CE-FedAvg在训练过程中采用分布式Adam优化技术,加速了在Non-IID数据集上的收敛性,所以在测试精度和训练损失值性能上也会优于其他对比算法。
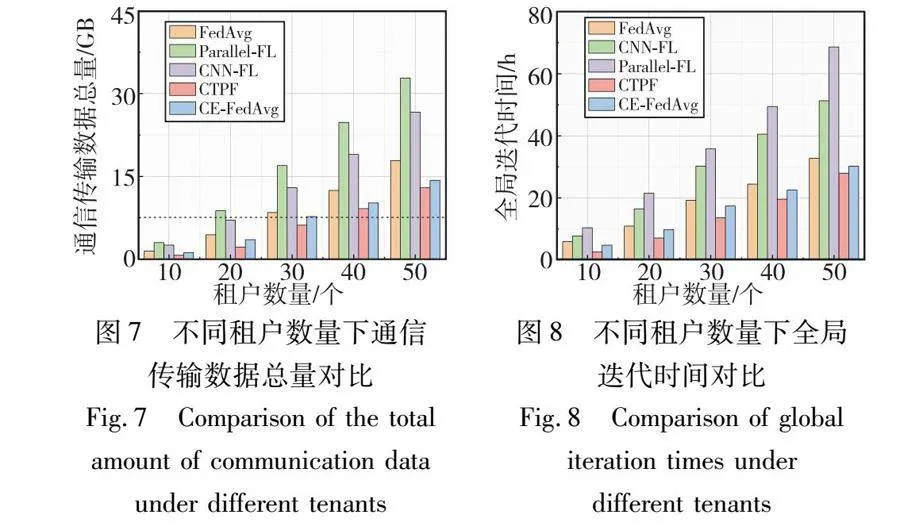
为验证CTPF在传输过程中减少通信开销的有效性,选择对比CTPF与FedAvg、Parallel-FL、CNN-FL以及CE-FedAvg在不同数量的租户参与训练过程中,根据式(14)计算的通信传输数据总量。在单位传输成本相同的情况下,可以通过对比不同租户数量下的通信传输数据总量来验证通信开销成本的有效性。通过图7可以发现,CTPF的通信传输数据总量都明显低于其他对比算法,这是因为相对于常规的通信传输而言,CTPF是结合一个最优局部模型和三元向量化局部模型参数来替代不必要的局部模型实例传输,所以大大减少了通信传输数据总量。而Parallel-FL是当完成一个本地数据块的计算后,就会执行一次通信,获取更新后的参数值,因此Parallel-FL在不同数量租户参与的训练中产生的通信传输总量占比达到最高。CE-FedAvg相比于FedAvg是采用模型压缩技术来减少每一轮需要加载的数据量,但依然传输局部模型实例,相比于传输三元向量化模型参数所产生的通信传输数据量还是有所提高,使得在最终产生的通信开销上不及CTPF。
为表明CTPF在全局迭代时间方面的优越性,通过图8可以对比看出,在达到预设的目标测试精度下,CTPF要优于其他对比算法。这是因为在传输过程中只有当租户发送模型参数m的三元向量演化方向发生变化时,才需要通过MFF架构的通信传输协议发送相应的数据包指令给本地数据中心,而Parallel-FL算法在本地数据块完成训练后就会执行一次通信传输从而更新参数,所以Parallel-FL算法所需的全局迭代时间也会达到最高。CE-FedAvg相比于CTPF则由于在传输过程中产生较高的通信数据量而造成全局迭代时间也会相应地延长,使得在全局迭代时间上不及CTPF。
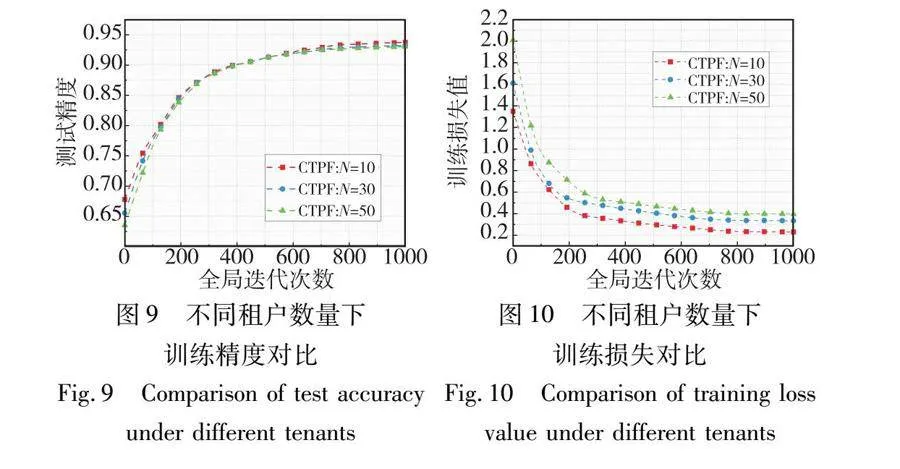
5.3.2 租户数量对所提方法的影响性分析
为了考察提出租户数量的增加对提出方法的影响,在同一轮次的全局迭代更新中,将参与训练的租户数量由10个逐步增加至50个,以此来验证在大规模多租户数据中心下,租户数量对于整体模型的训练精度以及训练损失值的影响。实验结果如图9、10所示。由图9可以看出,随着参与训练的租户数量逐步增加,整体模型训练精度也会随之小幅度地下降,仅为0.7%,但整体模型的训练精度都趋近于95%。此外,由图10可以看出,随着租户数量的逐步增加,整体模型的训练损失值也有细微的差别。这是因为随着参与训练的租户数量增加,参与训练的模型参数也相应增加,全局模型的聚合除了依赖于最优局部模型之外,还需要其他租户的模型参数三元演化情况。那么,租户计算模型参数的三元演化方向时会消耗部分带宽资源,使得传输模型参数的带宽能力下降。同时,在所传输的三元模型参数中,有部分模型参数演化情况同上一轮相比没有太大变化,而受其他大部分反方向变化的模型参数影响,全局模型的精度有所下降。因此,随着租户数量的增加会对所提算法的测试精度和训练损失值造成一定的影响。
6 结束语
本文的主要工作是为了实现多租户数据中心下的数据隐私保护。首先,建立了一种基于联邦学习架构的多租户数据中心架构;其次,为了优化引入联邦学习架构带来的冗余开销问题,提出一种基于三元演化模型参数的通信优化算法,结合最优局部模型实例和三元向量化局部模型参数来更新全局模型,并通过传输三元向量化的模型参数来减少传输不必要的完整局部模型实例;最后,通过实验对比经典的方法证明了提出算法的优越性及有效性。
目前本文的研究重点是针对多租户数据中心场景下,降低本地数据中心和租户之间传输过程中的通信开销问题。忽略了在地理分布式大规模数据中心之间云端通信传输过程中,有可能导致通信资源增幅过度溢出,造成不可忽视的通信负担。所以,下一步工作重点将考虑设计实现地理分布式大规模数据中心云端通信传输优化系统。
参考文献:
[1]Chi Ce, Zhang Fa, Ji Kaixuan, et al. Improving energy efficiency in colocation data centers for demand response[J]. Sustainable Computing: Informatics and Systems, 2021, 29: 100476.
[2]Xu Huiting, Jin Xi, Kong Fanxi, et al. Two level colocation demand response with renewable energy[J]. IEEE Trans on Sustainable Computing, 2019, 5(1): 147-159.
[3]Zhang Lingquan, Ren Shaolei, Wu Chuan, et al. A truthful incentive mechanism for emergency demand response in geo-distributed colocation data centers[J]. ACM Trans on Modeling and Performance Evaluation of Computing Systems, 2016, 1(4): 1-23.
[4]李姗珊, 敬超. 基于改进北极熊算法的多租户数据中心电力成本优化方法研究[J]. 计算机应用研究, 2023, 40(3): 743-749. (Li Shanshan, Jing Chao. Research on power cost optimization method of multi-tenant colocation data center based on improved polar bear optimization[J]. Application Research of Computers, 2023, 40(3): 743-749.)
[5]Zhang Chen, Xie Yu, Bai Hang, et al. A survey on federated lear-ning[J]. Knowledge-Based Systems, 2021, 216: 106775.
[6]Zhou Zhi, Liu Fangming, Chen Shutong, et al. A truthful and efficient incentive mechanism for demand response in green datacenters[J]. IEEE Trans on Parallel and Distributed Systems, 2018, 31(1): 1-15.
[7]Chi Ce, Ji Kaixuan, Marahatta A, et al. An incentive mechanism for improving energy efficiency of colocation data centers based on power prediction[C]//Proc of IEEE Symposium on Computers and Communications. Piscataway, NJ: IEEE Press, 2020: 1-6.
[8]王俐英, 林嘉琳, 宋美琴, 等. 考虑需求响应激励机制的园区综合能源系统博弈优化调度[J]. 控制与决策, 2023, 38(11): 3192-3200. (Wang Liying, Lin Jialin, Song Meiqin, et al. Optimal dispatch of park integrated energy system considering demand res-ponse incentive mechanism[J]. Control and Decision, 2023, 38(11): 3192-3200.)
[9]孙毅, 刘迪, 崔晓昱, 等. 面向居民用户精细化需求响应的等梯度迭代学习激励策略[J]. 电网技术, 2019, 43(10): 3597-3605. (Sun Yi, Liu Di, Cui Xiaoyu, et al. Equal gradient iterative learning incentive strategy for accurate demand response of resident users[J]. Power System Technology, 2019, 43(10): 3597-3605.)
[10]Phuong T T. Privacy-preserving deep learning via weight transmission[J]. IEEE Trans on Information Forensics and Security, 2019, 14(11): 3003-3015.
[11]Shokri R, Shmatikov V. Privacy-preserving deep learning[C]// Proc of the 22nd ACM SIGSAC Conference on Computer and Communi-cations Security. New York: ACM Press, 2015: 1310-1321.
[12]张泽辉, 富瑶, 高铁杠. 支持数据隐私保护的联邦深度神经网络模型研究[J]. 自动化学报, 2022, 48(5): 1273-1284. (Zhang Zehui, Fu Yao, Gao Tiegang.Research on federated deep neural network model for data privacy preserving[J]. Acta Automatica Sinica, 2022, 48(5): 1273-1284.)
[13]周炜, 王超, 徐剑, 等. 基于区块链的隐私保护去中心化联邦学习模型[J]. 计算机研究与发展, 2022, 59(11): 2423-2436.(Zhou Wei, Wang Chao, Xu Jian, et al. Privacy-preserving and decentralized federated learning model based on the blockchain[J]. Journal of Computer Research and Development, 2022, 59(11): 2423-2436.)
[14]Chen Chen, Wang Wei, Li Bo. Round-robin synchronization: mitigating communication bottlenecks in parameter servers[C]//Proc of IEEE Conference on Computer Communications. Piscataway, NJ: IEEE Press, 2019: 532-540.
[15]Cui Henggang, Tumanov A, Wei Jinliang, et al. Exploiting iterative-ness for parallel ML computations[C]//Proc of ACM Symposium on Cloud Computing. New York: ACM Press, 2014: 1-14.
[16]Ho Q, Cipar J, Cui Henggang, et al. More effective distributed ML via a stale synchronous parallel parameter server[C]//Proc of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013: 1223-1231.
[17]Shi Shaohuai, Chu Xiaowen, Li Bo. MG-WFBP: efficient data communication for distributed synchronous SGD algorithms[C]//Proc of IEEE Conference on Computer Communications. Piscataway, NJ: IEEE Press, 2019: 172-180.
[18]Zhang Hao, Zheng Zeyu, Xu Shizhen, et al. Poseidon: an efficient communication architecture for distributed deep learning on GPU clusters[C]//Proc of USENIX Annual Technical Conference.[S.l.]: USENIX Association, 2017: 181-193.
[19]Hashemi S H, Abdu Jyothi S, Campbell R. TicTac: accelerating distributed deep learning with communication scheduling[C]//Proc of the 2nd Conference on Machine Learning and Systems. 2019: 418-430.
[20]Jayarajan A, Wei Jinliang, Gibson G, et al. Priority-based parameter propagation for distributed DNN training[EB/OL]. (2019-05-10). https://arxiv.org/abs/1905.03960.
[21]Peng Yanghua, Zhu Yibo, Chen Yangrui, et al. A generic communication scheduler for distributed DNN training acceleration[C]//Proc of the 27th ACM Symposium on Operating Systems Principles. New York: ACM Press, 2019: 16-29.
[22]Seide F, Fu Hao, Droppo J, et al. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs[C]//Proc of the 15th Annual Conference of the International Speech Communication Association.[S.l.]: ISCA, 2014:1058-1062.
[23]Alistarh D, Grubic D, Li J Z, et al. QSGD: communication-efficient SGD via gradient quantization and encoding[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 1707-1718.
[24]Konen J, McMahan H B, Yu F X, et al. Federated learning: stra-tegies for improving communication efficiency[EB/OL]. (2016-10-18) [2024-05-19]. https://arxiv.org/abs/1610.05492.
bnbPSvtPJd2giegZ7KU9Qi4x84DPOwNVwdi2gXqagwU=[25]唐伦, 汪智平, 蒲昊, 等. 基于自适应梯度压缩的高效联邦学习通信机制研究[J]. 电子与信息学报, 2023, 45(1): 227-234. (Tang Lun, Wang Zhiping, Pu Hao, et al. Research on efficient federated learning communication mechanism based on adaptive gra-dient compression[J]. Journal of Electronics & Information Technology, 2023, 45(1): 227-234.)
[26]Dryden N, Moon T, Jacobs S A, et al. Communication quantization for data-parallel training of deep neural networks[C]//Proc of the 2nd Workshop on Machine Learning in HPC Environments. Pisca-taway, NJ: IEEE Press, 2016: 1-8.
[27]Abdellatif A A, Mhaisen N, Mohamed A, et al. Communication-efficient hierarchical federated learning for IoT heterogeneous systems with imbalanced data[J]. Future Generation Computer Systems, 2022, 128: 406-419.
[28]Lin Yujun, Song Han, Mao Huizi, et al. Deep gradient compression: reducing the communication bandwidth for distributed training[EB/OL]. (2020-06-23) [2024-05-19]. https://arxiv.org/abs/1712.01887.
[29]Hsieh K, Harlap A, Vijaykumar N, et al. Gaia: Geo-distributed machine learning approaching LAN speeds[C]//Proc of the 14th USENIX Symposium on Networked Systems Design and Implementation.[S.l.]: USENIX Association, 2017: 629-647.
[30]He Zhezhi, Gong Boqi, Fan Deliang. Optimize deep convolutional neural network with ternarized weights and high accuracy[C]//Proc of IEEE Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE Press, 2019: 913-921.
[31]Wen Wei, Xu Cong, Yan Feng, et al. TernGrad: ternary gradients to reduce communication in distributed deep learning[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 1508-1518.
[32]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of the 20th International Conference on Artificial Intelligence and Statistics.[S.l.]: PMLR, 2017: 1273-1282.
[33]Recht B, Re C, Wright S, et al. HOGWILD!: A lock-free approach to parallelizing stochastic gradient descent[C]//Proc of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2011: 693-701.
[34]Zhu Xinghua, Wang Jianzong, Hong Zhenhou, et al. Federated learning of unsegmented Chinese text recognition model[C]//Proc of the 31st International Conference on Tools with Artificial Intelligence. Piscataway, NJ: IEEE Press, 2019: 1341-1345.
[35]Mills J, Hu Jia, Min Geyong. Communication-efficient federated learning for wireless edge intelligence in IoT[J]. IEEE Internet of Things Journal, 2019, 7(7): 5986-5994.
收稿日期:2024-01-12;修回日期:2024-02-27 基金项目:国家自然科学基金资助项目(62362018);广西重点研发计划资助项目(桂科AB23075116,桂科AB23075175);广西研究生教育创新计划资助项目(YCSW2023350)
作者简介:程华盛(1997—),男,安徽安庆人,硕士研究生,CCF会员,主要研究方向为数据中心通信优化、联邦学习;敬超(1983—),男(通信作者),河南长葛人,教授,博士,主要研究方向为数据中心网络、边缘计算及最优化方法(jingchao@glut.edu.cn).
