基于频谱特征混合Transformer的红外和可见光图像融合
2024-11-04陈子昂黄珺樊凡








摘 要:为了解决传统红外与可见光图像融合方法对细节与频率信息表征能力不足、融合结果存在模糊伪影的问题,提出一种基于频谱特征混合Transformer的红外和可见光图像融合算法。在Transformer的基础上,利用傅里叶变换将图像域特征映射到频域,设计了一种新的复数Transformer来提取源图像的深层频域信息,并与图像域特征进行混合,以此提高网络对细节与频率信息的表征能力。此外,在图像重建前设计了一种新的令牌替换模块,动态评估Transformer令牌的显著性后对消除得分较低的令牌,防止融合图像出现伪影。在MSRS数据集上进行的定性和定量实验结果显示,与九种最先进的算法相比,该算法具有较好的融合效果。
关键词:图像融合; Transformer; 频谱特征; 红外图像; 可见光图像
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2024)09-043-2874-07
doi:10.19734/j.issn.1001-3695.2023.11.0599
Infrared and visible image fusion based on spectral feature hybrid Transformer
Chen Zi’ang, Huang Jun, Fan Fan
(Electronic Information School, Wuhan University, Wuhan 430072, China)
Abstract:Aiming at the problem of insufficient representation capability for details and frequency information in traditional infrared and visible image fusion methods, this paper proposed a fusion algorithm based on spectral feature hybrid Transformer. The algorithm utilized the Fourier transform to map image domain features to the frequency domain. Then the novel complex Transformer extracted deep-frequency information from the source images and mixed them with the features of the image domain to enhance the representation capability for edges and details. Additionally, the algorithm used a token replacement module to evaluate the saliency of Transformer tokens and eliminate the tokens with lower scores to prevent the presence of artifacts in the fused image. Qualitative and quantitative experiments conducted on the MSRS dataset demonstrated that the proposed algorithm exhibits superior fusion performance compared to nine state-of-the-art methods.
Key words:image fusion; Transformer; spectral feature; infrared image; visible image
0 引言
由于成像理论的限制,单一传感器难以全面地捕获场景信息,常需要多个模态的传感器协同工作。红外传感器能捕捉场景中的热辐射,可以轻易地检测到场景中的热目标,但其空间分辨率有限、受热噪声影响较大。可见光传感器捕捉场景中的反射光,能记录丰富的纹理和结构信息,但在低光条件下生成的图像质量会显著降低。它们的天然互补性质使得红外与可见光双模态传感器在军事侦察、安防监控、自动驾驶等领域得到了广泛应用[1]。红外与可见光图像融合的目标是整合两种模态图像的互补信息,生成一张纹理丰富、目标显著的融合图像,利于人眼观察的同时,对目标检测、语义分割等高级计算机视觉任务起到促进作用[2]。
在过去几十年里已经出现了许多红外和可见光图像融合方法。它们可以被分为传统方法[3,4]和基于深度学习的方法两类。传统方法利用传统图像处理技术或统计方法来建立融合框架。由于深度学习的快速发展,基于卷积神经网络(con-volutional neural network,CNN)[5,6]、自编码器(auto encoder,AE)[7,8]和生成对抗网络(generative adversarial network,GAN)[9,10]的框架在图像融合领域得到了广泛的研究。近年来,Vision-Transformer[11]在计算机视觉领域取得了巨大的成功,一些学者也探索了其在图像融合中的应用[12,13]。基于CNN的红外与可见光融合算法大多采用CNN模块替换传统融合框架的一些部分。Xu等人[5]提出了一个名为U2Fusion的统一融合网络,可以同时解决多种图像融合任务。Zhang等人[6]设计了一个提取-分解网络将梯度信息和亮度信息解耦并分别优化。文献[14]将特征编解码和特征融合网络分离开,采用两阶段方式进行训练,充分发挥空间-通道注意力融合网络的潜力。Wang等人[15]引入了一个多级配准网络用于处理源图像中的轻微误匹配,并在此基础上进行特征融合。由于图像融合是一个无监督任务,基于CNN的融合方法的性能强烈依赖于损失函数的特定设计。受传统融合算法的启发,基于自编码器的图像融合方法使用编码器和解码器替代传统的特征提取和重构函数。Li等人[16]探索了具有稠密连接的自编码器[8]和多尺度嵌套连接的自编码器,并尝试使用可学习的融合网络替换手工设计的融合规则来提高嵌套结构的性能[7]。Zhao等人[17]将图像分解为背景和细节特征图,然后通过自编码器网络将它们合并成一幅融合图像。生成对抗网络架构在无监督视觉任务中也展现出了强大的潜力。Ma等人[9]首次将生成器和鉴别器之间的对抗训练引入图像融合领域。GANMcC[18]借助多类别鉴别器来维持两种分布的平衡。Liu等人[10]提出了一种面向目标的对抗学习网络TarDAL,可以在实现融合的同时促进目标检测任务。
自2020年Dosovitskiy等人[11]成功将Transformer应用到计算机视觉领域以来,Transformer在目标检测[19]、跟踪[20]等视觉任务中都取得了巨大成功。由于Transformer具有强大的长程建模能力,近年来也已出现基于Transformer的图像融合方法。Rao等人[12]将Transformer模块与对抗学习相结合,设计了空间和通道Transformer以关注不同维度的依赖关系。Tang等人[13]设计了一个包含CNN和动态Transformer的Y型网络,能同时融合局部特征和上下文信息。
虽然以上算法都实现了图像融合的基本功能,但其中还存在两个被忽视的问题。a)现有方法对细节与频率信息的表征能力仍存在不足,在一些可见光纹理变化迅速的区域,融合结果会被红外噪声污染而导致失真。许多研究表明,自然图像的特性可以很容易地用傅里叶频谱来捕捉。图像傅里叶变换后的幅度谱能描述各个方向上重复结构出现的强度,而局部相位能提供物体在形状、边缘和方向上的详细信息[21]。但结合傅里叶变换的复数域Transformer在红外与可见光图像融合中的应用还尚未被探索。b)在特征融合阶段,现有算法仅考虑了显著特征的整合,却忽略了源图像中有害信息的去除。导致一些算法的融合结果中存在模糊或伪影。在图1所示的场景下,由于光照不足,可见光图像无法提供关于行人目标的任何有效信息,导致FusionGAN[9]、UMF-CMGR[15]和YDTR[13]的融合结果出现了热目标模糊或暗淡的问题。除此之外,受红外热噪声的影响,FusionGAN和UMF-CMGR的融合结果在绿色框所示区域出现了较严重的伪影。
为了解决上述问题,本文提出了一种基于频谱特征混合Transformer的红外和可见光图像融合算法,称为FTMNet。与传统的Transformer架构不同,FTMNet在多头自注意力结构的基础上增加傅里叶变换及其反变换的复数通路,并将图像域和频域的令牌(token)进行混合。复数操作并不等同于简单的双维实值操作,而是通过实部和虚部之间的相互作用编码了具有正则化效应的隐式连接。由于复数表征的冗余性,复数网络具有更好的泛化能力和信息提取能力[22]。对于图像融合任务来说,增强细节与频率信息能让融合图像的边缘与纹理清晰度提高,故可以通过给网络补充复数频谱信息的方式达到此目的。此外,在融合两模态的深度特征之前,设计了令牌替换机制对两个模态中显著性较低的令牌进行替换,以消除源图像中包含的潜在有害信息,提高融合图像的信息量。从图1可以看出,FTMNet生成的融合图像红外目标清晰,对比度高,且在背景区域克服了伪影的问题。本文贡献可以总结如下:
a)提出了一种用于红外和可见光图像融合的频谱特征混合Transformer,设计了复数通路将傅里叶频谱信息引入特征提取网络,有效地提高了方法对细节与频率信息的表征能力。
b)设计令牌替换机制,动态评估令牌信息的显著性得分并替换低分令牌,消除图像源中包含的无效信息,减少融合结果中的噪声和伪影。
c)主观与客观实验证明了本文方法相对于先进的对比算法具有优势。目标检测实验验证了本文方法能够有效地促进高级计算机视觉任务。
1 视觉Transformer
2017年,Vaswani等人[23]首次提出了Transformer的概念,采用了多头自注意力(multi-head self-attention, MSA)机制来捕捉自然语言处理(natural language processing, NLP)中的长距离依赖关系。自此,Transformer在NLP领域取得了广泛的应用。Dosovitskiy等人[11]成功将Transformer应用到计算机视觉领域,称为视觉Transformer(vision Transformer,ViT)。为了适应Transformer编码器的输入要求,ViT将图像分割为16×16的小块,经过线性变换和位置信息嵌入后形成一个图像块序列,再将这个图像块序列像NLP中的词序列一样输入Transformer网络执行目标检测。由于其强大的全局上下文特征探索能力,研究者对ViT进行了各种改进以适应其他计算机视觉任务。Wang等人[24]设计了金字塔结构的视觉Transformer(PVT)以增强特征提取能力,同时引入了空间归约注意力机制以减少深度网络引起的计算成本。除了网络结构的探索,研究人员还致力于提高Transformer的计算效率。Xie等人[25]提出了一种具有轻量级MLP解码器的分割框架。通过去除位置编码,该方法避免了由于位置编码的插值而引起的性能退化。在目标检测领域,MSG-Transformer提出了一种信使令牌,用于提取本地窗口的信息并实现跨区域信息交换,从而满足检测跨越多个窗口的大型目标的需要[26]。Wang等人[27]提出了一种名为TokenFusion的多模态特征对齐和融合方法,该方法动态识别并替换不具信息的令牌,进而对跨模态特征进行聚合。
视觉Transformer的结构可以被分为编码器和解码器两部分,编码器和解码器都由多个Transformer块组成。编码器中的Transformer块通常执行特征降维和提取,而解码器中的Transformer块通常执行特征升维和恢复。在图像输入网络之前,首先要通过分块嵌入层将它切分为小块,并通过线性变换转换为特征令牌,记为X=linear(crop(I))。其中I为原始图像,linear为线性变换。对于每个Transformer块来说,输入令牌通过三个可学习的线性变换被分解为query(Q)、key(K)和value(V)三个向量。随后,为了捕获像素间的长距离依赖,可通过式(1)计算自注意力权重。
3 实验
3.1 实验配置
3.1.1 数据集
实验在MSRS数据集上进行。MSRS数据集[29]提供了1 444对已配准的红外和可见光图像。数据已经被创建者分为训练集和测试集,分别包含1 083和361对图像。其中的80个样本还具有车辆和行人的检测标签。
3.1.2 训练细节
在输入端,本文将640×480×3的RGB可见光图像转换到YCbCr色彩空间,并将Y通道归一化到[0,1]作为网络的输入。红外图像是单通道的灰度图,所以无须进行色彩转换,经归一化后直接输入网络。在输出端,本文再将单通道的融合结果与可见光的Cb、Cr色彩通道结合,反变换得到RGB彩色图像。本文采用Python语言和PyTorch平台对所提深度学习网络进行实现。所有的实验都在NVIDIA TITAN RTX GPU和3.50 GHz Intel Core i9-9920X CPU上进行,CUDA版本为10.1,PyTorch版本为1.7.1,图像预处理和后处理采用OpenCV 3.4.2实现。训练的batch size设为1,epoch设为160。参数由Adam优化器进行更新,学习率为2×10-4。本文模型的超参数包括消除阈值θ以及损失函数中的平衡参数。实验中λ=0.2,α=10,β=1,θ=0.02。
3.1.3 评估指标
为了客观地评估融合性能,本文采用了熵(EN)、空间频率(SF)、标准差(SD)、平均梯度(AG)、差异相关性和(SCD)和视觉信息保真度(VIF)六种指标[30]。EN源自信息论,用于衡量信息量, 属于基于信息熵的指标。SD反映了像素分布的离散程度,SF和AG分别用于衡量图像的频率和梯度信息的丰富度,它们属于基于图像特征的指标。SCD是一种基于相关的指标,利用融合图像与源图像之间的差异来评估融合方法传递的互补信息量。VIF是一种基于自然场景统计理论的高级图像融合质量指标,用于衡量视觉保真度,属于基于人类感知的指标。这些指标在评估融合图像质量时具有互补性,可以从多个方面提供有关融合图像细节、对比度、视觉保真度等方面的信息,所有上述指标都是正向指标。
3.1.4 对比算法
本文选择了近年来的9种方法进行定性和定量比较。其中GTF[3]是传统方法;DenseFuse[8]、DIDFuse[17]、RFN-Nest[7]、SDNet[6]、U2Fusion[5] 和 UMF-CMGR[15] 基于CNN设计;FusionGAN[9]采用了GAN结构;YDTR[13]是基于Transformer的方法。对比实验中的9种对比算法均通过开源的代码和算法模型获取它们的融合图像。
3.2 MSRS数据集上的对比实验
3.2.1 定性比较
为了直观评估本文方法和对比算法的融合性能,本文展示各算法在四个典型场景下的融合结果,如图6~9所示。
在每幅图中,用红色框突出显示热目标区域,用绿色框突出显示包含丰富纹理的区域。在图6中,只有DensFuse和本文方法能同时保留红色框中的行人及其背后车辆的亮度。而在绿色框标记的密集地砖区域,只有本文方法能很好地保留该重复结构,其他算法则出现了不同程度的模糊。一方面,本文设计的频谱特征混合网络能提取频率特征,对地砖的重复结构具备更强的表征能力。另一方面,红外图像在该区域信息量极低,本文的令牌替换模块会丢弃这部分信息并用可见光的令牌将其替换,故FTMNet能提高融合图像的信息量,进而取得更好的视觉效果。图7 展示了一个白天的场景。可以发现,GTF、FusionGAN和RFN-Nest在红外目标周围出现了明显的模糊和伪影。虽然SDNet的结果中的红外目标亮度最为突出,但它在背景区域的色彩失真严重影响了视觉效果。FTMNet在保证红外目标显著性的同时能在绿色框标记的区域取得最强的对比度。由于细节与频率信息的增强,对应融合图像的边缘与纹理清晰度的提高,所以在该场景下地面裂纹清晰可见,没有受到红外噪声污染。在较黑暗的场景00726N中,FTMNet能更好地保持车辆区域的对比度。在图9所展示的场景下,FTMNet融合结果中的行人目标不仅亮度最高,还具备自然的色彩,没有出现模糊或失真。此外,在绿色框所标识的区域,背景树木的纹理细节清晰,和可见光图像的观感一致。通过无效令牌的消除,本文模型可以动态评估两种模态特征的重要性,进而消除源图像中包含的潜在有害信息。因此,本文融合结果中不会出现颜色失真、热目标暗淡和纹理模糊等常见问题。
3.2.2 定量比较
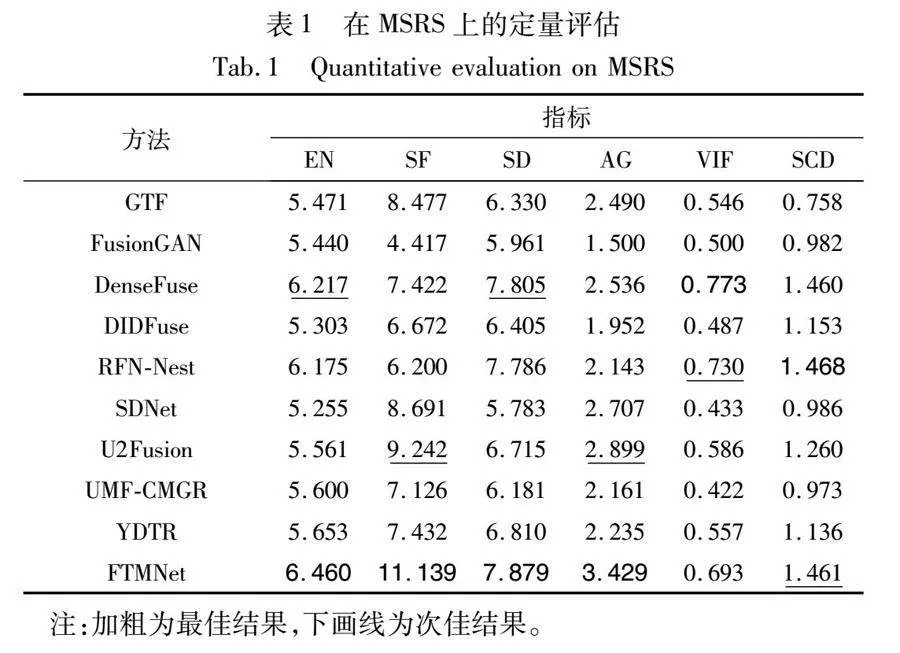
在MSRS数据集上的定量指标比较结果如表1所示,表中数值是在全部361张测试数据上的平均值。本文方法在EN、SF、SD、AG指标上获得第一,在SCD指标上取得第二,在VIF指标上取得第三。EN的优势代表了本文方法的融合结果能保留最大的信息量。SD的优势表明融合结果的像素离散程度最高。最高的AG说明融合结果的梯度信息丰富,纹理清晰。值得一提的是,本文方法在SF上取得了较明显的优势,超越第二名20%,相比最差的方法提升了252%。这与本文理论分析一致,因为本文方法引入了傅里叶变换并设计了复数通路来补充频率信息,所以融合结果的空间频率得到了大幅提高。在VIF指标上,本文方法落后第一名0.08。得益于DenseFuse和RFN-Nest在网络中引入的稠密连接和多尺度嵌套连接,其方法的视觉保真度更高。在SCD指标上,本文方法以0.007的微弱优势落后于RFN-Nest,意味着本文方法从源数据中转移的信息占比较高,对融合图像的噪声和伪影有一定抑制效果。总的来说,FTMNet的客观指标具有较强的竞争力。
3.3 运行效率
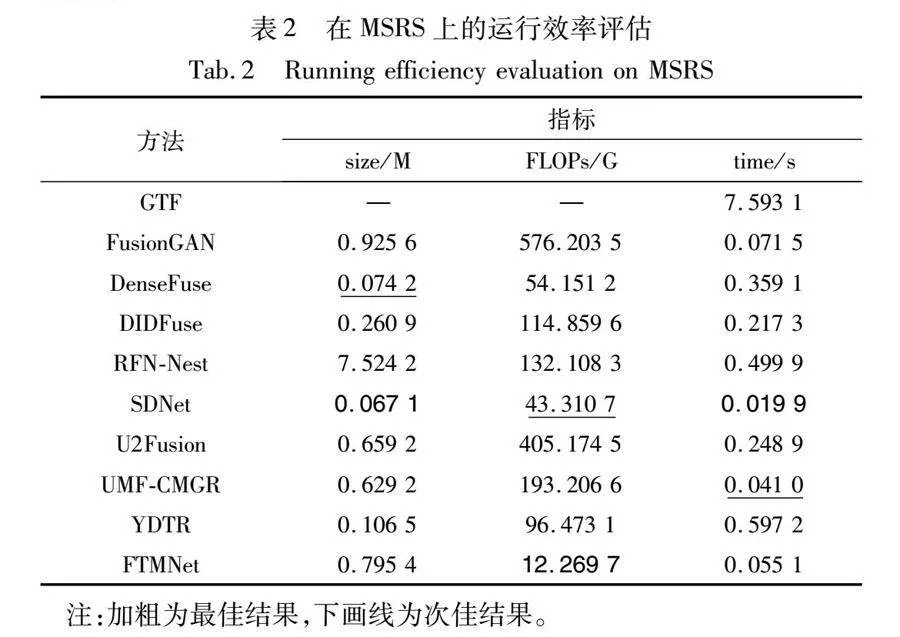
图像融合的后续计算机视觉应用对实时性能有很高的需求,例如目标检测和目标跟踪。运行效率是评估图像融合方法优劣的一个关键指标。本文从模型参数量、浮点运算次数(FLOPs)和运行时间三个角度评估算法的时间复杂度和空间复杂度。除了GTF是传统算法以外,其他所有深度学习算法都经过GPU加速。
评估在MSRS数据集上进行,输入图像的尺寸为640×480。评估结果总结在表2中。本文方法具有最小的FLOPs,但在执行速度方面仅排名第三。SDNet算法的运行速度最快,达到了实时应用的要求。由于本文方法设计了频谱特征混合网络,在复数运算相关的部分运算量都为原本的两倍,所以实时性没有达到最优。此外,通过进一步探究发现,式(8)(9)中与令牌替换策略相关的令牌索引寻址和令牌替换操作耗时较长。如果禁用替换过程,平均运行时间将减少到0.040。这表明与令牌替换的时间成本不容忽视,运行效率仍有优化的空间。
3.4 目标检测性能
本节探究FTMNet在高级计算机视觉任务中的积极作用。配合MSRS数据集中的目标检测标签,本文采用流行的检测模型YOLOv7对不同图像融合算法的红外、可见光和融合图像进行检测。如图10所示,该场景包含一个行人和两辆汽车,其中有一辆汽车在图像中较小且距离较远。由于模态的限制,单凭红外或可见光图像都无法识别出全部目标。然而,DenseFuse、RFN-Nest、U2Fusion、YDTR和FTMNet的融合结果可以有效促进目标检测任务,同时检测出三个目标。图11展示了一个白天的场景。可以看出,只有FTMNet能检测出远处的两个小目标。总的来说,大多数算法生成的融合图像都能取得比单张红外或可见光图像更好的检测效果,这证明了图像融合是有意义的,且本文方法能对高级计算机视觉任务起到较好的促进作用。
3.5 消融实验
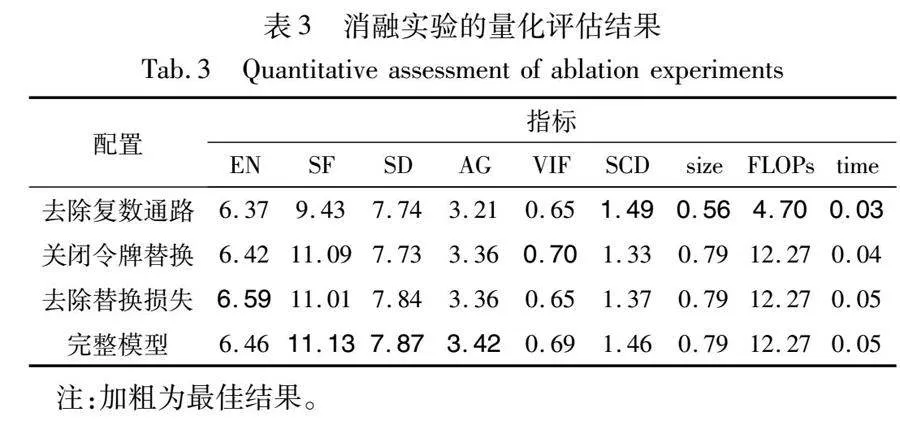
本文方法的有效性主要依赖于频谱特征混合网络中的复数通路和令牌替换策略。本文进行了一系列消融实验来验证特定设计的有效性。定性结果展示在图12中,定量评估结果报告在表3中。
3.5.1 复数通路的消融实验
本文去除了频谱特征混合网络中的复数通路,不再执行FFT和IFFT,同时将所有复数层用普通的层替换,只保留原始的多头注意力和前馈网络。如图12(c)所示,融合结果在红外目标附近出现了较明显的模糊,这是因为去除了复数通路后频率信息捕获能力不足,导致梯度变化较大的位置无法重现红外图像的锐利边缘。完整模型的SCD比去除复数通路后的模型略低,这是因为SCD衡量的是融合图像与源图像的差异,而复数通路为模型补充了额外的细节和频率信息,导致融合图像中的信息并不完全忠于源图像。去除复数通路后模型的参数量降低约30%,浮点运算量大幅下降,这是因为本文在频谱特征混合网络中引入的复数运算计算量为普通运算的两倍。综合来看,完整模型牺牲了运行效率,但主观和客观表现都是最佳的。
3.5.2 令牌替换的消融实验
本文关闭令牌替换过程,直接将Tlir和Tlvi的加和送入重建模块。可以发现,关闭令牌替换后有害信息无法被去除,融合结果中的红外目标亮度不如完整的模型,同时可见光纹理也出现对比度降低的情况。关闭令牌替换后的模型VIF略高于完整模型,但绝对差距仅有0.012,相对差距为1.7%,可认为是训练中的随机性导致。令牌替换策略相关的令牌索引寻址和令牌替换操作耗时较长,但这些操作不属于浮点运算,故size和FLOPs没有变化。
3.5.3 损失函数的消融实验
去除替换损失后的模型表现出更高的EN,这是因为去除替换损失后网络执行令牌交换的频率降低,而令牌替换在执行时会将网络认为的无效信息用对立模态的信息覆盖,该覆盖操作会在一定程度上降低数据通路中的总信息量,导致信息熵EN略微下降。虽然去除替换损失后EN指标更高,但其余指标都低于完整模型。
4 结束语
本文提出了一种基于频谱特征混合Transformer的红外和可见光图像融合方法,名为FTMNet。通过引入傅里叶变换及其反变换的复数通路,给网络补充复数频谱信息,提高了算法对细节和频率信息的表征能力。此外设计了令牌替换机制对红外与可见光模态中显著性较低的令牌进行替换,从而消除图像中包含的潜在有害信息,防止融合图像中出现模糊和伪影。实验证明了本文方法在视觉效果、客观指标和运行效率上都具有一定的优越性。此外,目标检测实验表明FTMNet的融合结果对高级视觉任务有促进作用。
参考文献:
[1]Zhang Hao, Xu Han, Tian Xin, et al. Image fusion meets deep learning: a survey and perspective[J]. Information Fusion, 2021, 76: 323-336.
[2]Tang Linfeng, Yuan Jiteng, Ma Jiayi. Image fusion in the loop of high-level vision tasks: a semantic-aware real-time infrared and visible image fusion network[J]. Information Fusion, 2022, 82: 28-42.
[3]Ma Jiayi, Chen Chen, Li Chang, et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31: 100-109.
[4]周怡, 马佳义, 黄珺. 基于互导滤波和显著性映射的红外可见光图像融合[J]. 遥感技术与应用, 2021, 35(6): 1404-1413. (Zhou Yi, Ma Jiayi, Huang Jun. Infrared and visible image fusion based on mutual conductivity filtering and saliency mapping[J]. Remote Sensing Technology and Application, 2021, 35(6): 1404-1413.)
[5]Xu Han, Ma Jiayi, Jiang Junjun, et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2020, 44(1): 502-518.
[6]Zhang Hao, Ma Jiayi. SDNet: a versatile squeeze-and-decomposition network for real-time image fusion[J]. International Journal of Computer Vision, 2021, 129: 2761-2785.
[7]Li Hui, Wu Xiaojun, Kittler J. RFN-Nest: an end-to-end residual fusion network for infrared and visible images[J]. Information Fusion, 2021, 73: 72-86.
[8]Li Hui, Wu Xiaojun. DenseFuse: a fusion approach to infrared and visible images[J]. IEEE Trans on Image Processing, 2018, 28(5): 2614-2623.
[9]Ma Jiayi, Yu Wei, Liang Pengwei, et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48: 11-26.
[10]Liu Jinyuan, Fan Xin, Huang Zhanbo, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5792-5801.
[11]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. (2021-06-03). https://arxiv.org/abs/2010.11929.
[12]Rao Dongyu, Xu Tianyang, Wu X J. TGFuse: an infrared and visible image fusion approach based on transformer and generative adversarial network[J/OL]. IEEE Trans on Image Processing. (2023-05-10). http://doi.org/10.1109/tip.2023.3273451.
[13]Tang Wei, He Fazhi, Liu Yu. YDTR: infrared and visible image fusion via Y-shape dynamic Transformer[J]. IEEE Trans on Multimedia, 2023, 25: 5413-5428.
[14]陈伊涵, 郑茜颖. 基于注意力机制的红外与可见光图像融合网络[J]. 计算机应用研究, 2022,39(5): 1569-1572,1585. (Chen Yihan, Zheng Qianying. Infrared and visible image fusion network based on attention mechanism[J]. Application Research of Computers, 2022, 39(5): 1569-1572,1585.)
[15]Wang Di, Liu Jinyuan, Fan Xin, et al. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration[C]//Proc of the 31st International Joint Conference on Artificial Intelligence. 2022: 3508-3515.
[16]Li Hui, Wu Xiaojun, Durrani T. NestFuse: an infrared and visible image fusion architecture based on nest connection and spatial/channel attention models[J]. IEEE Trans on Instrumentation and Measurement, 2020, 69(12): 9645-9656.
[17]Zhao Zixiang, Xu Shuang, Zhang Chunxia, et al. DIDFuse: deep image decomposition for infrared and visible image fusion[C]//Proc of the 29th International Joint Conference on Artificial Intelligence. 2020: 970-976.
[18]Ma Jiayi, Zhang Hao, Shao Zhenfeng, et al. GANMcC: a generative adversarial network with multiclassification constraints for infrared and visible image fusion[J]. IEEE Trans on Instrumentation and Measurement, 2021, 70: 1-14.
[19]Sun Zhiqing, Cao Shengcao, Yang Yiming, et al. Rethinking Transformer-based set prediction for object detection [C]//Proc of IEEE/CVF International Conference on Computer Vision. Pisca-taway, NJ: IEEE Press, 2021: 3591-3600.
[20]Lin Liting, Fan Heng, Zhang Zhipeng, et al. Swintrack: a simple and strong baseline for transformer tracking[J]. Advances in Neural Information Processing Systems, 2022, 35: 16743-16754.
[21]Oppenheim A V, Lim J S. The importance of phase in signals[J]. Proceedings of the IEEE, 1981, 69(5): 529-541.
[22]Danihelka I, Wayne G, Uria B, et al. Associative long short-term memory[C]//Proc of the 33rd International Conference on International Conference on Machine Learning.[S.l.]: JMLR.org, 2016: 1986-1994.
[23]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[24]Wang Wenhai, Xie Enze, Li Xiang, et al. Pyramid vision Transfor-mer: a versatile backbone for dense prediction without convolutions[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 548-558.
[25]Xie Enze, Wang Wenhai, Yu Zhiding, et al. SegFormer: simple and efficient design for semantic segmentation with Transformers[C]//Proc of the 35th Conference on Neural Information Processing Systems. 2021: 12077-12090.
[26]Fang Jiemin, Xie Lingxi, Wang Xinggang, et al. MSG-Transformer: exchanging local spatial information by manipulating messenger tokens[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 12053-12062.
[27]Wang Yikai, Chen Xinghao, Cao Lele, et al. Multimodal token fusion for vision Transformers[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 12176-12185.
[28]Quan Yuhui, Lin Peikang, Xu Yong, et al. Nonblind image deblurring via deep learning in complex field[J]. IEEE Trans on Neural Networks and Learning Systems, 2021, 33(10): 5387-5400.
[29]Tang Linfeng, Yuan Jiteng, Zhang Hao, et al. PIAFusion: a progressive infrared and visible image fusion network based on illumination aware[J]. Information Fusion, 2022, 83: 79-92.
[30]唐霖峰, 张浩, 徐涵, 等. 基于深度学习的图像融合方法综述[J]. 中国图象图形学报, 2023, 28(1): 3-36. (Tang Linfeng, Zhang Hao, Xu Han, et al. Deep learning-based image fusion: a survey[J]. Journal of Image and Graphics, 2023, 28(1): 3-36.)
收稿日期:2023-11-24;修回日期:2024-01-17 基金项目:国家自然科学基金资助项目(62075169,62003247,62061160370);湖北省重点研发计划项目(2021BBA235)
作者简介:陈子昂(1999—),男,湖北武汉人,硕士,主要研究方向为图像融合与计算机视觉;黄珺(1985—),男(通信作者),湖南祁阳人,教授,博士,主要研究方向为红外图像处理(junhwong@whu.edu.cn);樊凡(1989—),男,江西南昌人,副教授,博士,主要研究方向为红外成像预处理与高光谱图像预处理.
