融合双目信息的队列姿态检测
2024-11-04赵继发王呈荣英佼





摘 要:为实现队列姿态动作的准确评估,针对训练场景中踢腿高度等三维人体姿态特征难以准确测量的问题,提出融合双目信息的队列三维姿态特征检测方法。方法分为2D姿态估计和双目立体匹配两个阶段。为提高2D人体姿态检测精度,设计基于改进HRNet网络的2D姿态估计模型。首先,在主干网络引入空间通道注意力,增强特征提取能力。特征融合层采用自适应空间特征融合模块,融合网络多尺度特征。其次,采用无偏数据处理方法进行热图编解码,减小数据统计误差。最后,在模型训练时采用由粗到细的多阶段监督方法,提高关键点的检测准确率。在2D姿态估计模型基础上,采用标准相关匹配函数实现双目立体匹配,再通过坐标变换得到三维人体姿态。实验结果表明,改进的姿态估计网络有较好的精度,在COCO数据集精度达到77.1%,在自制的队列训练数据集上精度达到86.3%,相比原网络分别提升2.2%和3.1%。在三维人体姿态的踢腿高度实验中,该方法测得平均相对误差为2.5%,充分验证了算法的有效性。
关键词:图像处理; 双目视觉; 注意力机制; 姿态估计
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)09-041-2860-07
doi:10.19734/j.issn.1001-3695.2023.11.0595
Queue posture detection with fusion of binocular information
Zhao Jifa1, Wang Cheng1, Rong Yingjiao2
(1.School of Internet of Things, Jiangnan University, Wuxi Jiangsu 214122, China; 2.Science & Technology on Near-surface Detection Laboratory, Wuxi Jiangsu 214000, China)
Abstract:In order to realize the accurate evaluation of queue posture and action, aiming at the problem that it is difficult to accurately measure the three-dimensional human posture characteristics such as kick height in the training scene, this paper proposed a queue three-dimensional posture feature detection method based on binocular information. The method is divided into two stages: the 2D pose estimation stage and binocular stereo matching stage. In order to improve the accuracy of 2D human pose detection, it designed a 2D pose estimation model based on the improved HRNet network. Firstly, it introduced spatial channel attention in the back-bone network to enhance feature extraction capabilities. The feature fusion layer used an adaptive spatial feature fusion module to fuse multi-scale features of the network. Secondly, it used the unbiased data processing method to encode and decode the heat map to reduce the statistical error of the data. Finally,it adopted a coarse-to-fine multi-stage supervision method during model training to improve the detection accuracy of key points. Based on the 2D pose estimation model, it used the standard correlation matching function to achieve binocular stereo matching, and then obtained the 3D human pose through coordinate transformation. The experimental results show that the improved pose estimation network has better accuracy, the accuracy of the COCO dataset reaches 77.1%, and the detection accuracy of the self-made queue training dataset reaches 86.3%, which are respectively 2.2% and 3.1% higher than the original network. In the kick height experiment of the three-dimensional human body posture, the average relative error measured by the proposed method is 2.5%, which fully verifies the effectiveness of the algorithm.
Key words:image processing; binocular vision; attention mechanism; pose estimation
0 引言
传统队列训练中士兵姿态动作的标准性都由教官人眼主观评判,无法对士兵队列动作进行量化判断。基于计算机视觉评估队列训练姿态,能够实现更高效的队列训练。由于队列训练场景存在人体尺度变化大、光照不均以及遮挡等问题,传统姿态估计方法难以实现复杂场景的姿态检测[1]。近年来,基于深度学习的2D姿态估计方法快速发展,姿态检测效果显著提升,被广泛应用于复杂场景的人体姿态检测[2]。
2D人体姿态估计是一种基于RGB图像数据来检测人体骨骼关键点的方法[3]。目前主流姿态估计方法有RSN[4]、Hourglass[5]、ViTPose[6]、HRNet[7]等方法。RSN网络采用密集连接结构,充分融合特征的空间信息和语义信息,提高姿态估计精度。Hourglass网络通过重复上下采样操作,堆叠多个Hourglass模块提高网络表达能力,而反复上下采样会导致大量有效特征丢失。针对有效特征丢失问题,Zou等人[8]提出了结合CBAM注意力[9]的层内特征残差类模块IFRM学习有效的通道与空间特征,Hua等人[10]提出仿射模块affinage block与残差注意力模块RAM,取代上采样操作来获得高分辨率特征,这两种方法均有效缓解了特征丢失问题,提高了网络性能。ViTPose是基于Vison Transformer结构的人体姿态估计模型,该模型具有非常好的可拓展性。通过增大模型规模,引入额外数据集等方法, ViTPose-G*在人体姿态估计任务中达到了最先进水平。但随着模型增大,模型训练与推理对硬件设备有更高的要求,不便于实际场景的应用与部署。HRNet网络采样多分支并行结构,不仅保留不同尺度的特征信息,并在不同层次和尺度进行特征融合,充分利用高分辨率特征的空间信息和低分辨率特征的语义信息,有效提高模型的表达能力。
二维姿态估计模型一般采用有监督方法进行训练,根据标签类型分为基于坐标回归和基于热图回归[11]。基于坐标回归的方法忽略了关键点周围区域的空间信息,这对关键点的预测精度有较大的影响。为了得到更高精度的姿态估计模型,目前的主流姿态估计方法都采用基于热图回归的方法预测关键点坐标。但是,基于热图回归的模型对标签坐标进行编解码和翻转策略时,数据存在统计误差[11],导致模型的检测精度下降。为缓解数据误差的影响,提高模型的鲁棒性与检测精度,Huang等人[12]提出了一种采用分类和回归相结合的方法进行编码解码,实现无偏数据处理(UDP),提高了现有姿态估计方法的关键点检测精度。
注意力机制能够自适应学习特征权重系数,对网络更关注的区域分配更大权重以增强重要特征[13],在基本不增加参数的情况下提高特征提取能力。Yuan等人[14]在Vison Transformer结构中提出一种轻量高效的注意力,能够有效地对局部细粒度信息编码和全局空间信息聚合,大幅提高了ViTs模型在ImageNet分类任务的精度。在尺度变化剧烈的场景中检测小尺度目标往往比较困难。为了提高小尺度目标的检测效果,Liu等人[15]提出自适应空间特征融合(adaptive spatial feature fusion,ASFF)网络改进特征融合模块,使模型融合多尺度特征图权重,充分利用浅层特征与深层特征,提高对小尺度目标的检测精度。
队列训练正步前进时,还需要检测步幅、步速及踢腿高度等三维人体姿态特征,根据2D姿态估计结果无法得到准确的量化判断。但在多视图环境下,利用多视图匹配能实现人体姿态的三维重建[16]。在双目视觉中,立体匹配是实现立体视觉的关键步骤,根据匹配函数作用范围,可分为局部匹配与全局匹配。全局匹配效率较低,而局部匹配缺乏全局参数导致匹配精度较差[17]。Hirschmuller[18]提出半全局立体匹配方法(semi-global matching,SGBM),通过聚合多个路径代价进行匹配,较好地兼顾匹配精度和效率。Hosni等人[19]采用分割算法选择待匹配区域,有效提高局部匹配精度。基于2D姿态估计模型预测结果选择待匹配区域,对左右视图的人体关键点进行局部匹配,既避免全局匹配的计算消耗,又充分利用了姿态估计模型性能,很好地平衡了整体算法检测精度与检测速度。
综上,针对队列训练场景中三维人体姿态特征检测问题,本文设计了基于改进HRNet的姿态估计模型PoseHRNet,再融合双目姿态信息实现队列三维姿态检测,主要工作如下:
a)提出了空间通道注意力SCA,实现细粒度信息编码和全局空间信息聚合,增强主干网络的表达能力,并且改进了主干网络的特征融合层,通过自适应空间特征融合模块ASFF聚合多尺度特征。
b)重新设计损失函数,在模型训练阶段实现由粗到细的多阶段监督,提高关键点的检测准确率。
c)根据关键点预测结果选择待匹配区域,有效平衡了左右视图匹配的精度与速度,实现高效的三维人体姿态估计。
1 基于PoseHRNet的2D姿态估计方法
本文算法重点关注队列训练时二维人体姿态检测,针对二维人体姿态估计任务,提出一种改进网络模型PoseHRNet。该模型在HRNet基础上引入了空间通道注意力SCA和自适应姿态特征融合ASSF模块,构建多阶段损失函数,并采用无偏数据处理方法UDP进行热图编码和解码,提高模型检测准确性和鲁棒性。
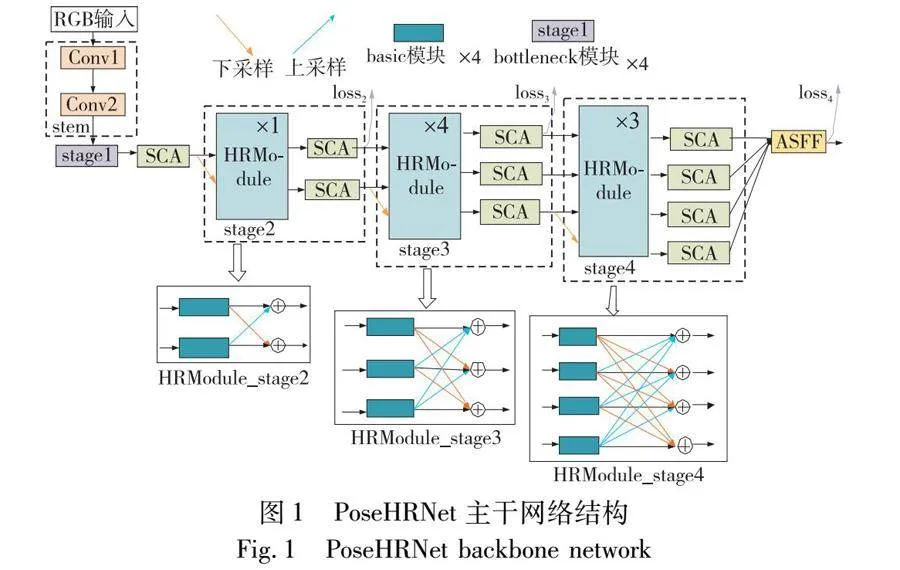
1.1 PoseHRNet的网络结构
PoseHRNet的主体网络结构如图1所示,网络分为四个阶段,分支数依次增加,最后输出四条不同尺度的特征分支。首先输入RGB图片经过两个步长为2的3×3卷积的基础层Stem预处理后,分辨率降为1/4,通道数由3通道增加到64通道。第一条主分支全程保持1/4高分辨率,下采样的子分支通过分辨率减半通道数加倍的方式充分表征特征。第一阶段由四个bottleneck模块和SCA注意力组成。后面的三个阶段都有若干个HRModule和SCA注意力模块组成,每个阶段之间,会采用一个下采样模块增加输出分支。第四阶段末尾采用ASFF模块自适应融合4个不同尺度的特征分支生成17个表征人体关键点热图。
HRModule是由四个basic模块和特征融合模块组成。特征模块融合模块将各个分支输出的不同尺度特征通过上采样和下采样操作达到同一尺度进行融合。每个输出支路特征都融合所有输入分支特征,有效减少了特征传递过程中的信息丢失问题。basic模块由两个3×3卷积和一条残差连接组成。bottleneck模块由1个3×3卷积和两个1×1卷积和一条残差连接组成,特征通道数先减小为输入的1/4再恢复到输入的通道数。basic模块和bottleneck模块均来自ResNet[20]的残差模块,通过残差连接有效解决了主干网络加深导致的梯度消失问题。
算法1 PoseHRNet人体姿态估计算法
输入:预处理后的RGB图像I。
输出:人体关键点坐标Coord。
1) function PoseHRNet(I)
2) S ← stem (I) /*通过stem层卷积操作提取输入图像I的底层特征S*/
3) S_1 ← stage1(S) /*stage1通过4个bottleneck模块进一步提取图像特征,得到S_1*/
4) S_1 ← SCA(S_1) /*SCA注意力汇聚局部空间特征与全局语义信息*/
5) for k=2 to 4 do
6) S_k ← stage_k(S_{k-1}) /*stage_k通过HRModule模块提取更高层次的特征S_k*/
7) S_k ← SCA(S_k)
8) end for
9) Predheatmap ← ASFF(S_4) /*ASFF模块聚合多尺度特征,得到预测热图结果*/
10) MaxCoord ← argmax(PredHeatmap) /*获取预测热图中的最大值点的坐标*/
11) Coord ← MaxCoord * I_size /*根据原始图像的尺寸I_size将热图坐标转换回原始图像的坐标*/
12) return Coord
13) end function
1.2 空间通道注意力SCA
姿态估计的任务是检测人体关键点的空间位置坐标,而骨骼关键点之间又有特定的空间联系,姿态估计网络需要关注局部空间特征与全局空间特征。本文受CBAM[9]机制启发,设计了空间通道注意力SCA,SCA中的空间注意力模块(spatial attention module,SAM)能够对每个空间位置计算其相邻区域的局部空间信息,通过聚合密集的局部空间信息实现细粒度的空间特征编码。同时SCA通道注意力模块(channel attention module,CAM)采用全局平均池化与最大池化来计算全局通道注意力。SCA模块兼顾了全局上下文信息与局部空间特征,从而有效提升了关键点检测精度,SCA注意力结构如图2所示。
图2空间注意力模块中,给定输入特征图Xi∈RH×W×C,通过对Xi空间位置(i,j)的C维特征向量进行线性投影,将投影后的特征通过reshape操作进行维度变换,得到(i,j)相邻K×K局部窗口区域的空间注意力权重A^i,j∈RK2×K2。VΔi, j∈RC×K2表示以(i,j)为中心的局部窗口特征,与softmax操作后的空间注意力权重A^i,j相乘,得到具有空间信息的局部输出XΔi,j。然后把每个位置窗口内所有通过注意力权重调整过的特征向量累加起来,实现局部空间信息聚合,即对应图中的fold操作,得到具有细粒度空间信息的特征图Xs。
3.3 人体姿态估计实验结果与分析
表1为本文方法和其他姿态估计方法在COCO验证集上的性能对比。
由表1中数据可知,PoseHRNet的检测精度AP为77.1%,模型的参数量和浮点计算量分别为28.83 M和8.05 GFlops。与基线模型HRNet-w32相比,PoseHRNet参数量和浮点运算量少量增加,模型检测平均精度AP提高了2.2%,中小目标检测准确率APM提高了2.8%,在检测精度和模型复杂度之间取得了更好的平衡。表1中ViTPose-G*通过增大模型参数到1 000 M,引入额外数据集AIC,提高输入图片尺寸,在人体姿态估计任务中达到了最先进水平,但实际应用中有诸多限制。与同等规模的ViTPose-B相比,PoseHRNet以更小的模型复杂度达到更高检测精度,便于实际场景的部署与应用。
为验证PoseHRNet在队列训练应用场景中姿态检测的性能,通过在自制队列训练数据进行训练来评估模型的有效性,表2为不同方法在自制数据集上性能比较。
根据表2结果显示,PoseHRNet在自制数据集平均检测精度达到了86.3%。与原基线模型HRNet-w32相比,AP提升了3.1%,AP50和AP75分别提高了2.2%和1.4%。相比其他方法,PoseHRNet取得了更佳检测精度,验证了本文算法在队列训练场景的有效性。二维人体姿态检测结果对三维姿态结果的准确性和可靠性有显著影响,提高二维姿态估计模型的检测精度可以实现更精确的三维队列姿态特征检测效果。
3.4 姿态估计模型消融实验
为研究不同模块对人体姿态估计模型性能的影响,本节基于COCO数据集对各个模块进行消融实验,消融实验结果如表3所示。
由表3消融实验结果可知,通过对原始数据无偏数据处理,减小热图编解码过程中统计误差,各项性能指标都有提升,其中检测精度提升1.3%。通过引入多阶段监督,构建各阶段的损失函数并加权求和,使得模型收敛效果更好,检测精度提高0.6%。ASFF模块能够融合多尺度分支特征,引入ASFF后模型检测精度提升1.1%。SCA注意力机制能够更细粒度地提取空间信息与通道信息,有效提升模型检测性能,与基线模型相比,引入SCA模块后,精度提高1.7%。
3.5 三维姿态检测结果与分析
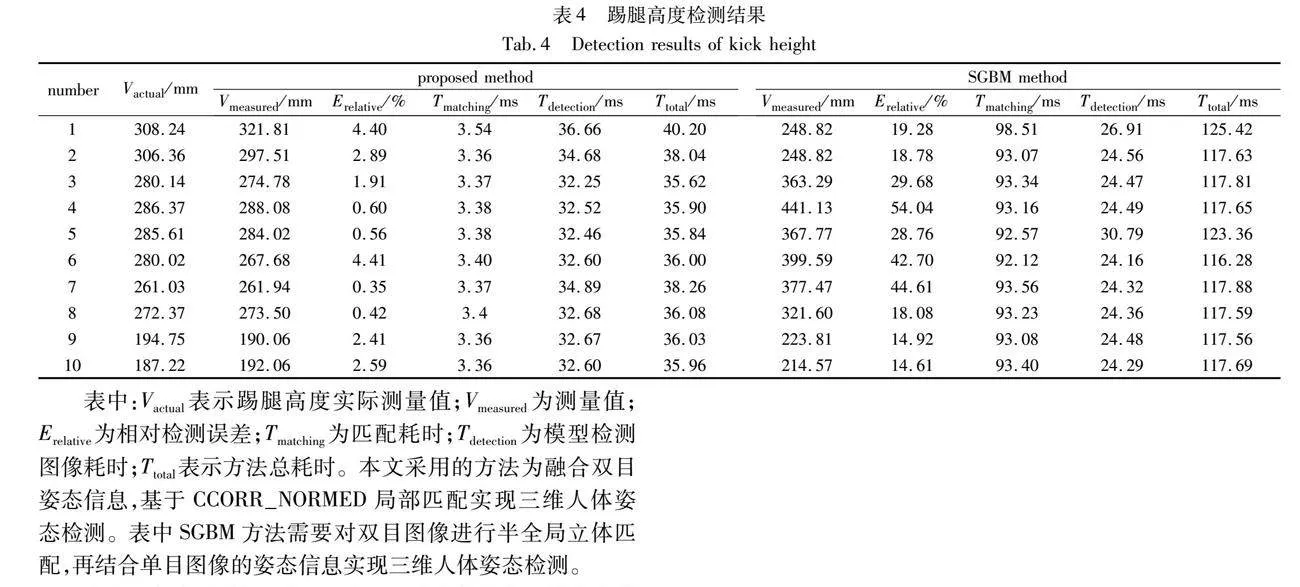
本文对队列训练场景典型的踢腿动作进行检测,采集了28个踢腿动作进行检测,测量踢腿高度与实际踢腿高度,通过比较测量值与实际值的误差验证队列三维姿态检测效果。踢腿高度值实际值通过AimPosition光学定位系统AP-STD-200测量获得,AimPosition在视场范围1~2.4 m内的定位精度为0.12 mm,满足实验需求。
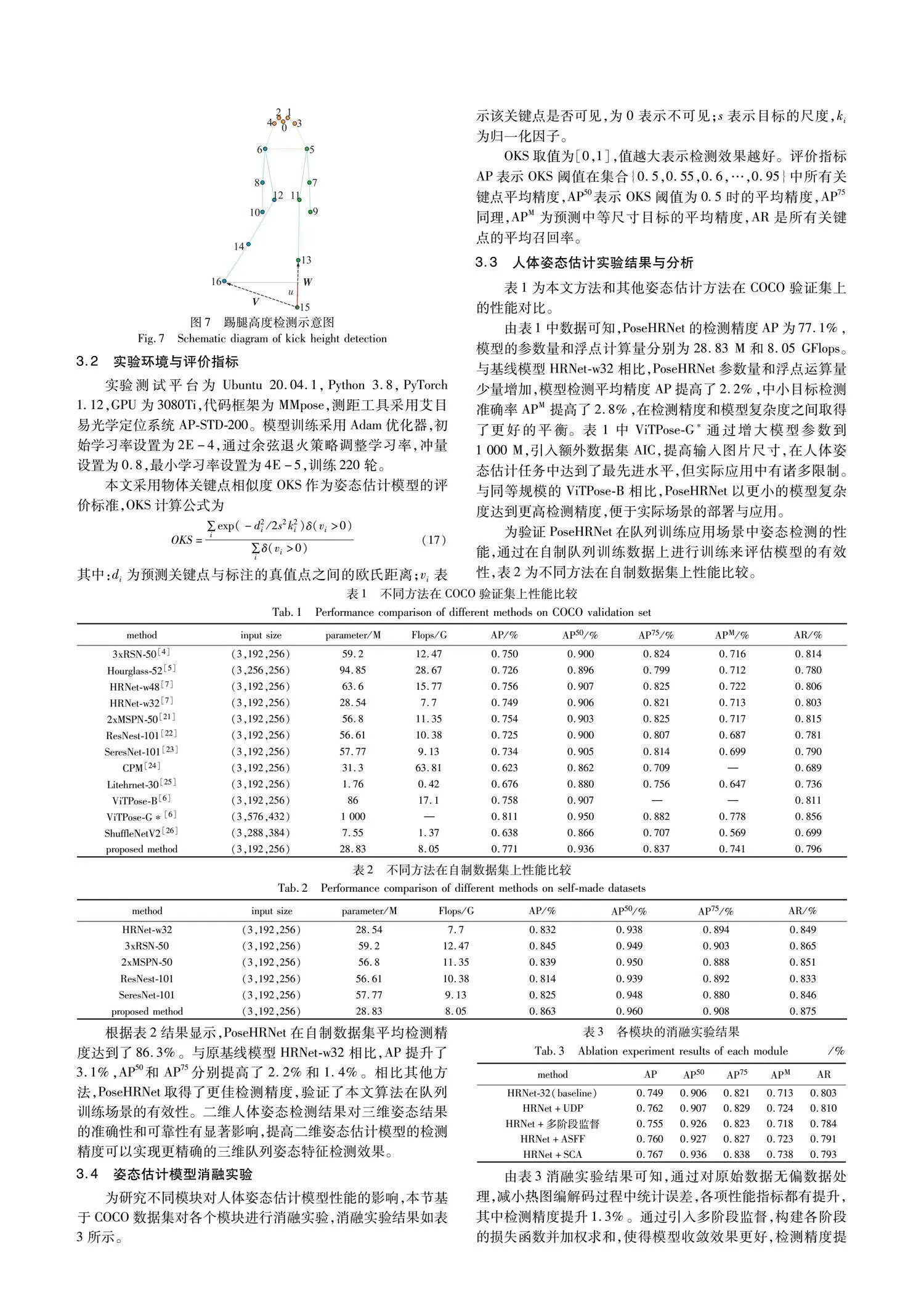
为验证基于CCORR_NORMED的三维姿态估计方法性能,设计了基于半全局立体匹配方法SGBM的三维重建方法作为对比实验。SGBM通过对双目相机左右视图直接进行立体匹配与视差计算,得到左视图的三维点云图,实现二维像素坐标到三维空间坐标的映射。根据姿态估计模型预测的关键点像素坐标即可获得对应的三维空间坐标。两种方法的部分检测结果如表4所示。
表中:Vactual表示踢腿高度实际测量值;Vmeasured为测量值;Erelative相对检测误差;Tmatching匹配耗时;Tdetection模型检测图像耗时;Ttotal表示方法总耗时。本文采用的方法为融合双目姿态信息,基于CCORR_NORMED局部匹配实现三维人体姿态检测。表中SGBM方法需要对双目图像进行半全局立体匹配,再结合单目图像的姿态信息实现三维人体姿态检测。
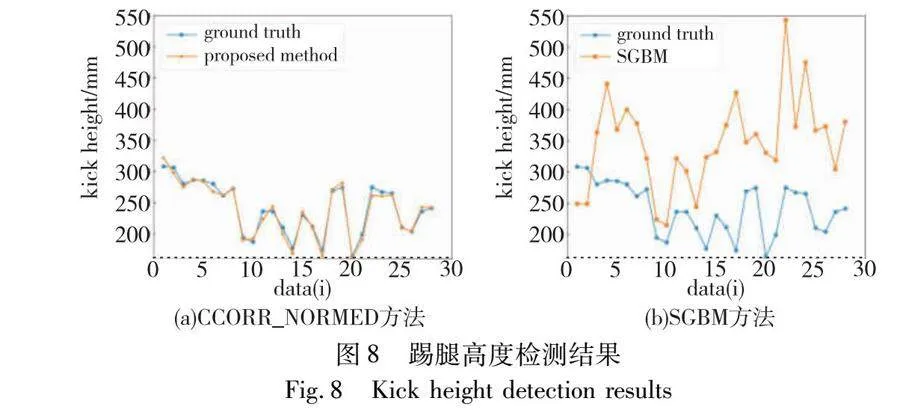
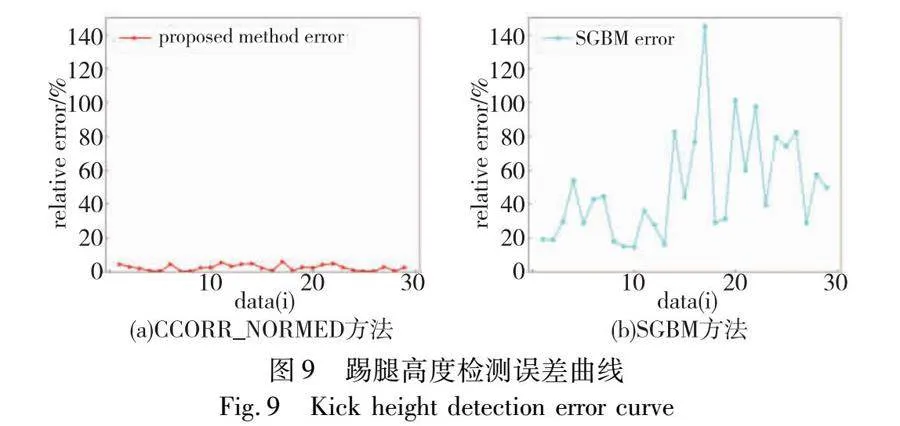
由表4的实验结果可知,融合双目姿态信息的三维姿态检测方法在踢腿高度实验的平均相对误差为2.51%,基于SGBM的三维姿态检测方法的平均相对误差为49.8%。姿态估计网络预测双目姿态信息平均耗时为32.98 ms,而仅计算单目姿态信息平均耗时为24.71 ms。虽然计算双目姿态信息需要耗费更多时间,但基于双目信息进行局部立体匹配大幅度减少计算消耗,整体上以更少的时间消耗达到更高的检测精度,实现了高效的三维人体姿态估计。为更直观地表示两种方法的检测效果,绘制了完整实验的检测结果图与检测误差图,如图8与9所示。
图8(a)为基于CCORR_NORMED的检测值与实际值对比,纵坐标为踢腿高度,横坐标为数据编号,图8(b)为基于SGBM方法得到的检测对比图。图9(a)(b)为两种方法的误差曲线图,纵坐标为相对误差,横坐标为数据编号。从图8和9可以看出,基于CCORR_NORMED方法的检测误差明显更小。分析可知,在2D姿态估计模型的检测结果基础上对关键点进行立体匹配,能够准确快速获得关键点的三维信息从而实现高效的三维姿态检测。传统的SGBM是对全图进行三维重建,不但耗时长,而且受图片的噪点影响大,进而导致局部点检测精度不足。基于CCORR_NORMED的三维姿态估计方法对人体关键点进行三维重建有明显精度优势和速度优势。
3.6 可视化结果分析
姿态估计网络检测结果如图10和11所示,共检测17个人体关键点,人体左侧关键点、右侧人体关键点以及头部区域关键点分别采用绿色、蓝色和橘黄色表示(见电子版)。图10给为COCO验证集上的部分检测结果,图(a)是单人有遮挡场景,图(b)是较远距离逆光场景,图(c)为光线较暗场景,图(d)(e)为多人有遮挡的场景。上述结果表明PoseHRNet在单人、多人、有遮挡、弱光照等复杂场景下均能准确检测出人体关键点。图11(a)(b)为自制队列训练数据集的检测效果图,图中给出了单人多人以及不同光照下队列训练场景的人体关键点检测结果,图11(c)还给出了基于SGBM算法得到的深度图。从检测结果可以看出,在复杂场景PoseHRNet都能较准确地检测出关键点位置,达到了预期效果。
4 结束语
针对队列训练场景中三维姿态检测问题,本文提出了融合双目信息的队列三维姿态特征检测方法。通过2D姿态估计模型与标准相关匹配函数实现双目相机左右视图中人体关键点的精确匹配,再利用坐标变换得到人体关键点的三维空间坐标,进而得到三维姿态特征。2D姿态估计模型基于HRNet进行改进,在COCO数据集精度达到77.1%,在自制数据集上检测精度达到86.3%,相比原网络分别提升2.2%和3.1%,本文的改进方法有效提升了2D姿态估计的检测精度。在队列三维姿态检测的踢腿高度实验上,本文基于2D姿态估计模型预测结果对左右视图人体关键点进行局部匹配,匹配平均耗时3.4 ms,测得踢腿高度平均相对误差为2.5%,很好地平衡了三维人体姿态估计的检测精度和检测速度。
参考文献:
[1]张宇, 温光照, 米思娅, 等. 基于深度学习的二维人体姿态估计综述[J]. 软件学报, 2022, 33(11): 4173-4191. (Zhang Yu, Wen Guangzhao, Mi Siya, et al. Overview on 2D human pose estimation based on deep learning[J]. Journal of Software, 2022, 33(11): 4173-4191.)
[2]钟宝荣, 吴夏灵. 基于高分辨率网络的轻量型人体姿态估计研究[J]. 计算机工程, 2023, 49(4): 226-232,239. (Zhong Baorong, Wu Xialing. Research on lightweight human pose estimation based on high-resolution network[J]. Computer Engineering, 2023, 49(4): 226-232,239.)
[3]渠涵冰, 贾振堂. 轻量级高分辨率人体姿态估计研究[J]. 激光与光电子学进展, 2022, 59(18): 129-136. (Qu Hanbing, Jia Zhentang. Lightweight and high-resolution human pose estimation method[J]. Laser & Optoelectronics Progress, 2022, 59(18): 129-136.)
[4]Cai Yuanha, Wang Zhicheng, Luo Zhengxiong, et al. Learning delicate local representations for multi-person pose estimation[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2020: 455-472.
[5]Newell A, Yang Kaiyu, Deng Jia. Stacked Hourglass networks for human pose estimation[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2016: 483-499.
[6]Xu Yufei, Zhang Jing, Zhang Qiming, et al. ViTPose: simple vision transformer baselines for human pose estimation[EB/OL]. (2022-04-26). https://arxiv.org/abs/2204.12484.
[7]Sun Ke, Xiao Bin, Liu Dong, et al. Deep high-resolution representation learning for human pose estimation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press, 2019: 5686-5696.
[8]Zou Xuelian, Bi Xiaojun, Yu Changdong. Improving human pose estimation based on stacked hourglass network[J]. Neural Processing Letters, 2023, 55(7):9521-9544.
[9]Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 3-19.
[10]Hua Guoguang, Li Lihong, Liu Shiguang. Multipath affinage stacked-hourglass networks for human pose estimation[J]. Frontiers of Computer Science, 2020, 14(4): 1447011.
[11]王仕宸, 黄凯, 陈志刚, 等. 深度学习的三维人体姿态估计综述[J]. 计算机科学与探索, 2023, 17(1): 74-87. (Wang Shichen, Huang Kai, Chen Zhigang, et al. Survey on 3D human pose estimation of deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(1): 74-87.)
[12]Huang Junjie, Zhu Zheng, Guo Feng, et al. The devil is in the details: delving into unbiased data processing for human pose estimation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2020: 5699-5708.
[13]李丽, 张荣芬, 刘宇红, 等. 基于多尺度注意力机制的高分辨率网络人体姿态估计[J]. 计算机应用研究, 2022, 39(11): 3487-3491,3497. (Li Li, Zhang Rongfen, Liu Yuhong, et al. High resolution network human pose estimation based on multi-scale attention mechanism[J]. Application Research of Computers, 2022, 39(11): 3487-3491,3497.)
[14]Yuan Li, Hou Qibin, Jiang Zihang, et al. VOLO: vision outlooker for visual recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2022, 45(5): 6575-6586.
[15]Liu Songtao, Huang Di, Wang Yunhong. Learning spatial fusion for single-shot object detection[EB/OL]. (2019). https://arxiv.org/abs/1911.09516.
[16]Qiu Haibo, Wang Chunyu, Wang Jingdong, et al. Cross view fusion for 3D human pose estimation[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2019: 4341-4350.
[17]畅雅雯, 赵冬青, 单彦虎. 多特征融合和自适应聚合的立体匹配算法研究[J]. 计算机工程与应用, 2021, 57(23): 219-225. (Chang Yawen, Zhao Dongqing, Shan Yanhu. Research on stereo matching algorithm based on multi-feature fusion and adaptive aggregation[J]. Computer Engineering and Applications, 2021, 57(23): 219-225.)
[18]Hirschmuller H. Stereo processing by semiglobal matching and mutual information[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2007, 30(2): 328-341.
[19]Hosni A, Bleyer M, Gelautz M, et al. Local stereo matching using geodesic support weights[C]//Proc of the 16th IEEE International Conference on Image Processing. Piscataway,NJ: IEEE Press, 2009: 2093-2096.
[20]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
[21]Li Wenbo, Wang Zhicheng, Yin Binyi, et al. Rethinking on multi-stage networks for human pose estimation[EB/OL]. (2019-01-01). https://arxiv.org/abs/1901.00148.
[22]Zhang Hang, Wu Chongruo, Zhang Zhongyue, et al. ResNeSt: split-attention networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2022: 2735-2745.
[23]Hu Jie, Shen Li, Sun Gang, et al. Squeeze-and-excitation networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2018: 7132-7141.
[24]Wei S E, Ramakrishna V, Kanade T, et al. Convolutional pose machines[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press, 2016: 4724-4732.
[25]Yu Changqian, Xiao Bin, Gao Changxin, et al. Lite-HRNet: a lightweight high-resolution network[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 10435-10445.
[26]Ma Ningning, Zhang Xiangyu, Zheng Haitao, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 122-138.
收稿日期:2023-11-15;修回日期:2024-01-15 基金项目:近地面探测技术重点实验室基金资助项目(6142414220203)
作者简介:赵继发(1998—),男,硕士,主要研究方向为图像处理和姿态估计;王呈(1983—),男(通信作者),副教授,博士,主要研究方向为非线性系统建模与控制、机器学习和数据挖掘(wangc@jiangnan.edu.cn);荣英佼(1978—),女,工程师,主要研究方向为目标检测和信号处理.
