基于全局频域池化的行为识别算法
2024-11-04贾志超张海超张闯颜蒙蒙储金祺颜之岳



摘 要:目前基于3D-ConvNet的行为识别算法普遍使用全局平均池化(global average pooling,GAP)压缩特征信息,但会产生信息损失、信息冗余和网络过拟合等问题。为了解决上述问题,更好地保留卷积层提取到的高级语义信息,提出了基于全局频域池化(global frequency domain pooling,GFDP)的行为识别算法。首先,根据离散余弦变换(discrete cosine transform,DCT)看出,GAP是频域中特征分解的一种特例,从而引入更多频率分量增加特征通道间的特异性,减少信息压缩后的信息冗余。其次,为了更好地抑制过拟合问题,引入卷积层的批标准化策略,并将其拓展在以ERB(efficient residual block)-Res3D为骨架的行为识别模型的全连接层以优化数据分布。最后,将该方法在UCF101数据集上进行验证。结果表明,模型计算量为3.5 GFlops,参数量为7.4 M,最终的识别准确率在ERB-Res3D模型的基础上提升了3.9%,在原始Res3D模型基础上提升了17.4%,高效实现了更加准确的行为识别结果。
关键词:3D-ConvNet; 人体行为识别; 全局平均池化; 离散余弦变换
中图分类号:TP319 文献标志码:A
文章编号:1001-3695(2024)09-042-2867-07
doi:10.19734/j.issn.1001-3695.2023.11.0596
Action recognition algorithm based on global frequency domain pooling
Jia Zhichao1, Zhang Haichao1, Zhang Chuang1,2, Yan Mengmeng1, Chu Jinqi1, Yan Zhiyue1
(1.College of Electronic & Information Engineering, Nanjing University of Information Science & Technology, Nanjing 210044, China; 2.Jiangsu Key Laboratory of Meteorological Observation & Information Processing, Nanjing 210044, China)
Abstract:The current 3D-ConvNet-based action recognition algorithms generally use GAP to compress feature information. However, it leads to issues of information loss, redundancy, and network overfitting. To address these issues and enhance the retention of high-level semantic information extracted by the convolutional layer, this paper proposed an action recognition algorithm based on GFDP. Firstly, DCT shows that GAP is a special case of feature decomposition in the frequency domain. Therefore, the algorithm introduced more frequency components to increase the specificity between feature channels and reduce the information redundancy after information compression. Secondly, to better suppress the overfitting problem, the algorithm introduced the batch normalization strategy to the convolutional layer and extended it to the fully connected layer of the action recognition model with ERB-Res3D as the skeleton to optimize the data distribution. Finally, this paper verified the proposed method on the UCF101 dataset. The results reveals that the model’s computational load is 3.5 GFlops, with 7.4 million para-meters. The final recognition accuracy improved by 3.9% based on the ERB-Res3D model and 17.4% based on the original Res3D model. This improvement effectively achieves more accurate behavior recognition results.
Key words:3D-ConvNet; human action recognition; global average pooling; discrete cosine transform
0 引言
随着智能手机、便携式设备的普及,以及短视频APP的蓬勃发展,每个人都可以成为短视频的生产者。视频的内容包含人们生活的方方面面,其中以人为中心,旨在分析出视频中人与人、人与物互动时表现出的动作类别的技术,被称为人体行为识别(HAR)技术。HAR是利用模式识别技术进行视频理解的重要研究方向[1~3],在智能安防、人机交互、智慧教育等领域都有着重要的应用[4~6]。
近年来,基于深度学习的行为识别方法层出不穷,其中主流的方法大致可以分为三类,即基于Two-Stream[7]的行为识别方法、基于RNN[8]的行为识别方法和基于3D-ConvNet[9]的行为识别方法。现在,有的研究依旧使用光流来描述视频中的运动信息[10, 11],但这对计算和存储要求较高,不利于数据集大规模的训练和部署,因此3D-ConvNet开始作为建模视频中时间信息的重要手段。在基于3D-ConvNet的行为识别方法中,诸如Res3D[12]、I3D[13]、R(2+1)D[14]、TSM[15]等众多算法模型大都以ResNet[16]为基础骨架,而ResNet在卷积层向全连接层过渡时,采用全局平均池化对最末层卷积输出的特征图进行信息压缩,只保留一个均值表示该通道特征图所蕴涵的高级语义信息。这种做法虽然实现了较大程度的信息压缩,减少了后续全连接层的参数量和浮点运算量,但当不同通道的特征图均值相同时,原本表示不同特征信息的特征图就会表达出相同的语义,使得压缩后的均值特征缺乏多样性,从而产生信息损失和信息冗余的问题[17]。
离散余弦变换作为有损压缩的核心成员之一,在深度学习领域中具有广泛的应用。研究者们发现将数据转换至频域,以频域视角重新思考数据的处理流程,通过引入更多的频率分量来充分利用网络中的数据信息,能够对CNN模型的性能有很好的改善效果。其中,李长海[18]以数据预处理为切入点,认为常见的预处理主要针对RGB图像进行数据增强、归一化等,单一的RGB图像表达的时空特征有限,因此李长海利用DCT将空域中的RGB图像数据变换到频域,并作为CNN的输入来提取频域特征,再与原RGB图像为输入的时域通道提取的时空特征相融合,丰富模型的特征信息,进而提高模型性能。Qin等人[19]提出了FcaNet,在注意力机制中以频域视角重视全局平均池化,通过引入多个频率分量来充分利用CNN提取到的特征信息,弥补GAP造成的特征损失,最终在ImageNet、COCO等图像分类任务中表现出了较好的效果。Yang等人[20]基于DCT卷积,提出了CDF-Net,能够有效提取和融合输入样本的频域和空间特征。Yu等人[21]在不压缩信道的情况下,将频域信息与空间信息相结合,提出了一种基于频空域转换的服装分类网络,该算法有效地提高了服装分类的准确率。
针对上述GAP中存在的特征损失问题,以及研究者们在频域视角里对人体行为特征提取尚未深入研究,本文提出了一种基于全局频域池化的人体行为识别算法。一方面,通过离散余弦变换分析了全局平均池化出现信息损失和信息冗余问题的原因是全局平均池化在压缩特征信息时只保留了最低频率分量而没有考虑其他频率分量带来的影响,本文通过引入多个低频分量提出了全局频域池化方法,来丰富算法模型降采样后特征信息的多样性。另一方面,引入卷积层的批标准化策略并拓展至全连接输出层,降低了模型过拟合的风险。最终在UCF101数据集上进行消融实验,验证全局频域池化对模型的性能具有提升效果。
1 方法
1.1 全局平均池化的频域分析
为了能够将时域中的GAP映射在频域中,本文采用在图像处理领域经常使用的离散余弦正变换DCT-Ⅱ和反变换DCT-Ⅲ,其中二维DCT表达式为
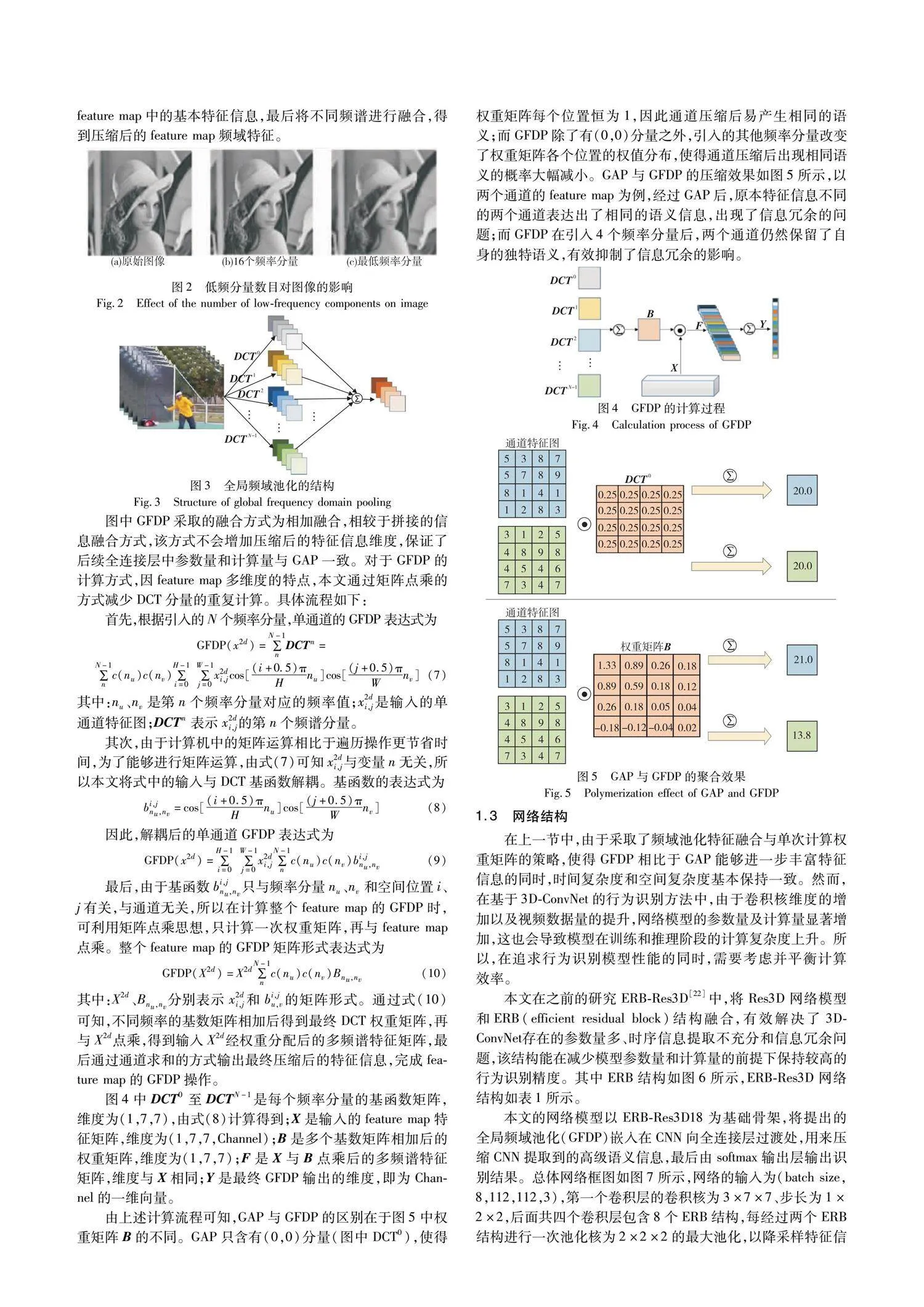
由上述计算流程可知,GAP与GFDP的区别在于图5中权重矩阵B的不同。GAP只含有(0,0)分量(图中DCT0),使得权重矩阵每个位置恒为1,因此通道压缩后易产生相同的语义;而GFDP除了有(0,0)分量之外,引入的其他频率分量改变了权重矩阵各个位置的权值分布,使得通道压缩后出现相同语义的概率大幅减小。GAP与GFDP的压缩效果如图5所示,以两个通道的feature map为例,经过GAP后,原本特征信息不同的两个通道表达出了相同的语义信息,出现了信息冗余的问题;而GFDP在引入4个频率分量后,两个通道仍然保留了自身的独特语义,有效抑制了信息冗余的影响。
1.3 网络结构
在上一节中,由于采取了频域池化特征融合与单次计算权重矩阵的策略,使得GFDP相比于GAP能够进一步丰富特征信息的同时,时间复杂度和空间复杂度基本保持一致。然而,在基于3D-ConvNet的行为识别方法中,由于卷积核维度的增加以及视频数据量的提升,网络模型的参数量及计算量显著增加,这也会导致模型在训练和推理阶段的计算复杂度上升。所以,在追求行为识别模型性能的同时,需要考虑并平衡计算效率。
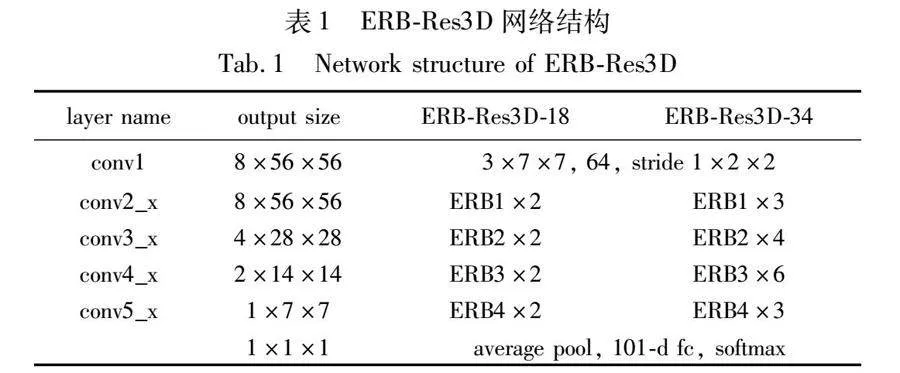
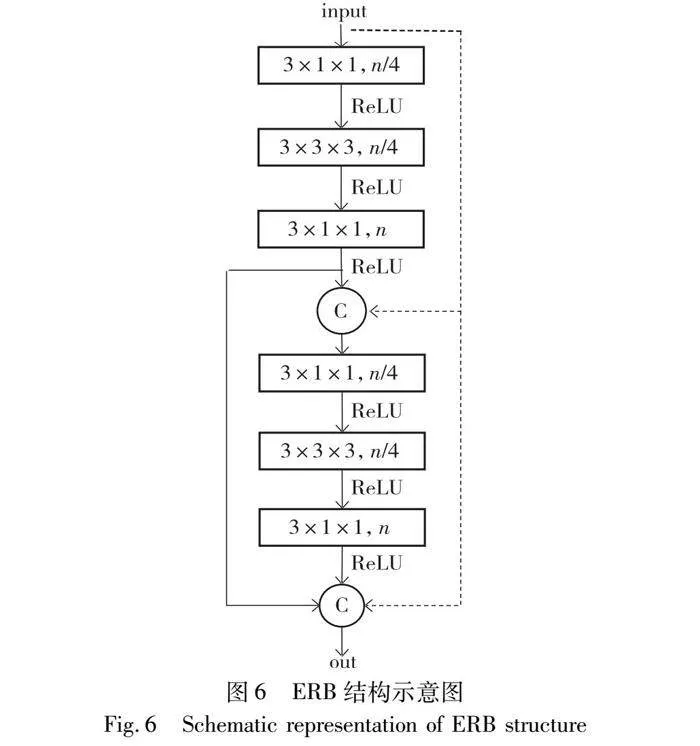
本文在之前的研究ERB-Res3D[22]中,将Res3D网络模型和ERB(efficient residual block)结构融合,有效解决了3D-ConvNet存在的参数量多、时序信息提取不充分和信息冗余问题,该结构能在减少模型参数量和计算量的前提下保持较高的行为识别精度。其中ERB结构如图6所示,ERB-Res3D网络结构如表1所示。
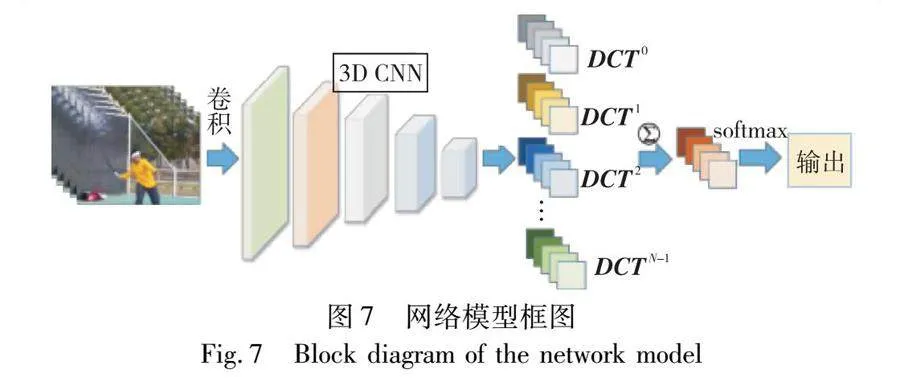
本文的网络模型以ERB-Res3D18为基础骨架,将提出的全局频域池化(GFDP)嵌入在CNN向全连接层过渡处,用来压缩CNN提取到的高级语义信息,最后由softmax输出层输出识别结果。总体网络框图如图7所示,网络的输入为(batch size,8,112,112,3),第一个卷积层的卷积核为3×7×7、步长为1×2×2,后面共四个卷积层包含8个ERB结构,每经过两个ERB结构进行一次池化核为2×2×2的最大池化,以降采样特征信息,最终最后一个ERB的输出维度为(batch size,1,7,7,1536),然后由GFDP压缩每个通道的特征信息,使得全连接层的输入维度为(batch size,1536),最后由softmax函数输出识别结果。同时为了使网络模型更好地适应每个batch size的输入数据,本文在所有卷积层和全连接层后都加入了批标准化(BN)来标准化数据。
2 实验与分析
2.1 数据集
本文选用UCF101行为识别数据集[23]进行实验验证。该数据集中的视频主要从You Tube中获取。行为类别涉及人与物体交互、单纯的肢体动作、人与人交互、演奏乐器、体育运动五个方面,共包含101类行为动作。每类动作被分为25组,每组包含一个动作的4~7个视频,共13 320个视频,总计时长约有27 h。数据集部分行为实示例如图8所示。
对于UCF101数据集的划分,官网有3种训练集和测试集的划分策略。本文选择split01方法进行划分,其中训练集共有9 537个视频序列,约占数据集总量的70%,测试集共有3 783个视频序列,约占数据集总量的30%。实验时先通过训练集训练模型参数,最后用训练好的模型在测试集上的识别精度作为最终的实验结果。
2.2 实验设置
2.2.1 实验环境
本文在Intel CoreTM I5-9400F,NVIDIA GeForce GTX 1600 SUPER(6 GB),2.9 GHz CPU、64位Windows 10操作系统上进行实验,采用Python语言编程,TensorFlow-Slim轻量级库搭建神经网络模型。
2.2.2 超参数设置
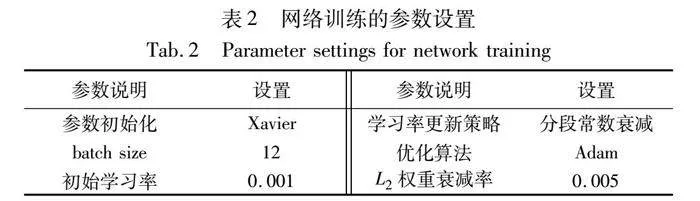
训练阶段,使用Xavier方法[24]初始化网络参数,采用小批量数据(mini-batch)进行训练,根据显卡性能batch大小设置为12。学习率的调整采用分段常数衰减策略,前50个epoch设置为0.001,之后每20个epoch衰减为原来1/10,直至网络收敛;反向传播时,采用交叉熵损失函数衡量网络损失,使用Adam优化算法[25]更新模型参数,采用L2正则化和BN[26]两种策略防止网络出现过拟合。网络训练的参数设置如表2所示。
测试阶段,首先等间隔地抽取测试集中一段视频的8帧图像,并采用中心剪裁的方式处理抽取到的图像序列作为网络输入,然后通过前向传播输出101个行为分类得分,最终取得分最高的类别为预测结果。
2.3 消融实验
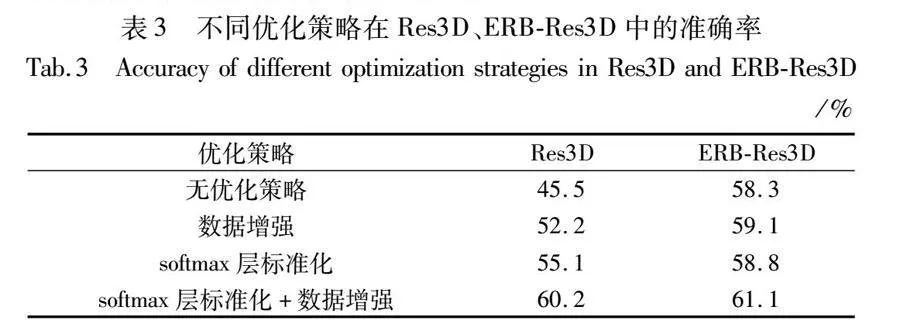
在对Res3D网络进行改进时,本文采取了一系列的优化手段,有引入的数据增强、ERB模块以及softmax层标准化,也有本文设计的全局频域池化。为了充分验证四个策略,无论是单独使用还是结合使用都对模型的性能有提升效果,本文先沿用最初的GAP操作,以UCF101为基准数据集,按照官方提供的split01划分训练集和测试集,通过数据增强、softmax层标准化在原始Res3D模型和ERB-Res3D模型上的表现,验证除全局频域池化之外的三个优化策略的有效性(对于全局频域池化对模型的影响将在下一节探索)。不同的优化策略在两个模型中的准确率如表3所示。
首先按列分析,从表中数据可知,数据增强、softmax层标准化单独使用时,无论是在Res3D模型中还是ERB-Res3D模型中,识别准确率都高于无优化策略时的模型,而且当两种策略结合使用时,对识别准确率会有进一步的提升。但对于不同模型,两者单独使用时虽都有明显的效果,但提升的幅度却因模型而异。其中在Res3D模型中,softmax层标准化提升的准确率比数据增强高了2.9%,表明在Res3D中softmax层标准化发挥的作用更大;在ERB-Res3D模型中,数据增强提升的准确率只比softmax层标准化高了0.3%,两者相差无几,表明在该模型中两种策略都发挥了自身该有的作用。
其次按行分析,对于数据增强和输出层标准化两种优化策略,无论是不使用、单独使用还是结合使用,ERB-Res3D都表现出了比Res3D更好的性能,这再次印证了ERB模块对模型性能的提升效果。但是逐行分析可知,在无优化策略时,相较于Res3D的准确率,ERB-Res3D有12.8%的提升;单独使用数据增强和softmax层标准化时分别有6.9%、3.7%的提升,两者共同使用时有0.9%的提升,准确率提升的幅度随着优化策略的增加而减弱,表明ERB模块在过拟合较严重的网络中能表现出更好的效果,体现了ERB隐含的解决过拟合的能力,而且当数据量充足、网络不存在过拟合问题时,ERB也可减少模型的参数量和浮点运算量,实现轻量化。
最后,综合分析表中数据,以Res3D模型无优化策略为基准,当数据增强、softmax层标准化和ERB三种策略单独使用时,准确率分别为52.2%、55.1%和58.3%,相较于基准的45.5%都有不同程度的提升,表明三种策略都对模型性能的提升有效,而且当三种策略共同使用时,准确率达到了61.1%,在所有方案中表现出了最好的效果。因此在接下来的实验中,将以三种策略共同使用时的Res3D模型为基础骨架,探索全局频域池化中不同类型和不同数量的频率分量对识别结果的影响。
2.4 频率分量的选择实验
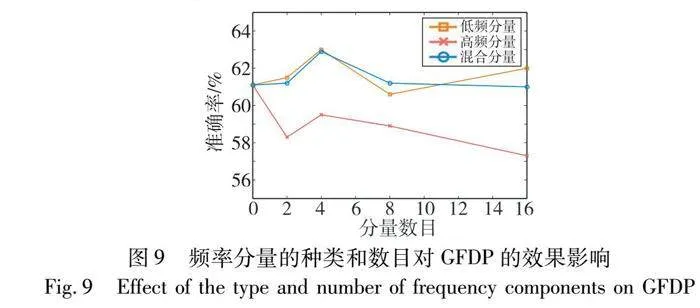
从图1中图像在频域中的频谱分布可知,低频分量蕴涵了绝大部分图像信息,因此理论上,当全局频域池化引入有限低频分量时,feature map压缩后的特征信息更丰富,进而更能提升模型的性能。为了验证低频分量在全局频域池化中的效果,本节设置实验,从低频分量、高频分量以及混合分量(低频、高频混合)三类频率分量出发,观察引入不同数目的分量时模型的识别准确率,验证低频分量对全局频域池化的有效性,同时探究分量数目对全局频域池化的影响。
对于引入的频率分量数目,因Res3D最终输出的单通道特征图维度是(1,7,7),所以在频域中共有49个频率分量,本次实验通过分别引入1、2、4、8、16个频率分量来观察全局频域池化对模型性能的影响,最终确定合适的频率分量数目,实验结果如图9所示。首先,对于分量的类型,低频分量和混合分量明显比高频分量表现的效果要好,且低频分量效果整体更佳,表明模型对低频分量蕴涵的特征信息更加敏感。当引入高频分量时,模型与引入1个分量(GAP)相比,识别准确率不升反降,表明高频分量虽然也包含特征图的相关信息,但并不适合模型性能的提升,所以应尽量减少高频分量的引入;其次,对于引入的分量数目,从图中可以看出引入2个或者8个分量的准确率相近,当引入4个分量时,无论低频分量还是高频分量、混合分量,都在该类型分量中表现最好,表明引入分量的多少,并非与模型表现出的效果呈正比,选择合适数目的分量才能实现最佳的识别效果。
2.5 与其他行为识别方法比较
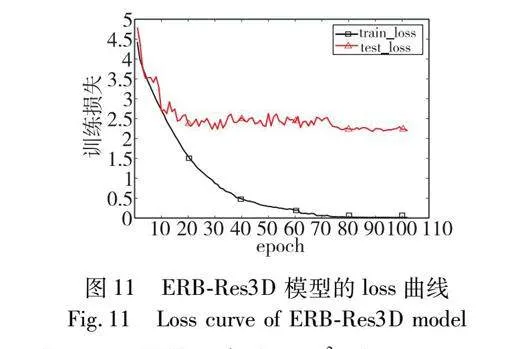
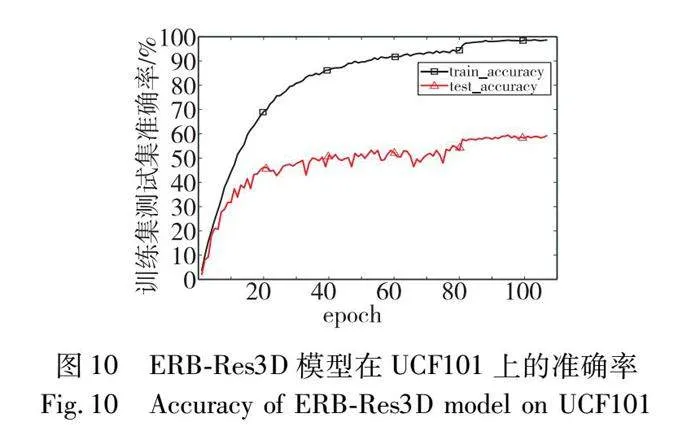
经上述的消融实验和频率选择实验,本文以ERB-Res3D模型为基础骨架,选择引入4个低频分量的全局频域池化和softmax层标准化为最终的行为识别模型。首先,模型的识别准确率和loss曲线如图10和11所示。
前80个epoch的学习率为10-3,在0~20 epoch中训练集和测试集的准确率上升幅度较大,但在21~80 epoch中训练集准确率和损失值变化较为平缓,且呈现出缓慢上升的趋势,测试集的准确率和损失值振荡明显,表明模型不稳定;在80 epoch之后学习率为10-4,无论是训练集还是测试集,准确率和loss值均在开始时有较大幅度的变化,之后振荡幅度逐渐趋于平缓,模型逐渐稳定。最终训练集和测试集的准确率分别保持在99.6%和62.3%左右,且loss值分别在0.01和2.22上下浮动。
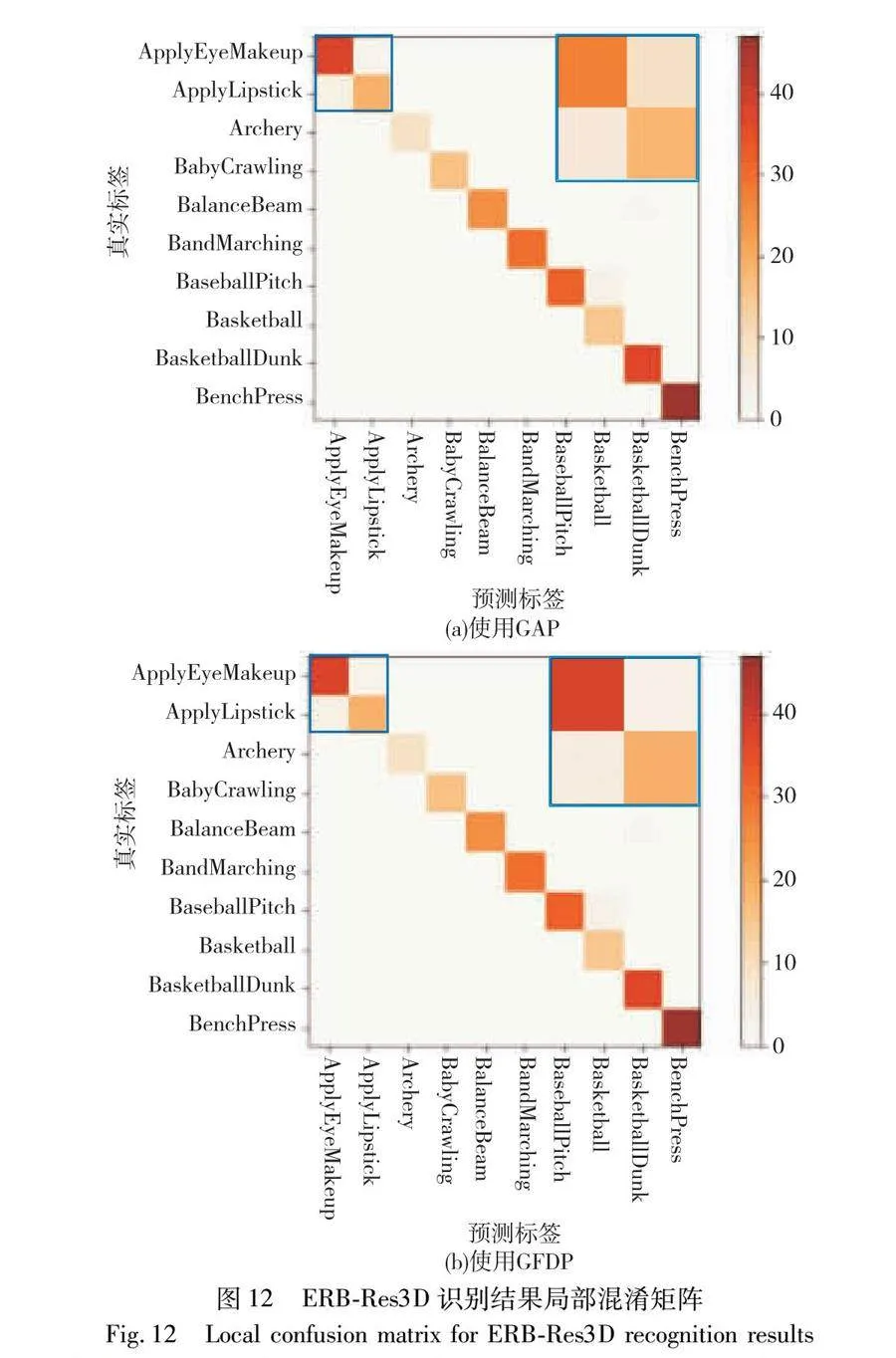
其次,为了方便观察模型对不同类别的识别精度,本文将ERB-Res3D模型不使用GFDP和使用GFDP时,在UCF101测试集上的预测结果分别绘制成混淆矩阵,如图12所示。
图12为ERB-Res3D在UCF101数据集前10种类别的识别结果局部混淆矩阵,横坐标为模型预测的行为标签,纵坐标为真实行为标签。通常情况下,当预测标签与真实标签相同即为识别正确,在混淆矩阵中为对角线的位置。从图中可以看出,对于大部分行为类别,ERB-Res3D模型识别正确的样本个数远大于识别错误的样本个数(图中颜色越深,表示数值越大),但也存在少部分行为识别误差较大。
为了更好地证明GFDP的有效性,对比图12(a)与(b),可以看出本文模型在对角线位置上的色度更深,表明识别正确的数量更多。特别是左上角中动作存在相似性的apply eye makeup(化眼妆)和apply lipstick(涂口红)两类行为,本文模型预测结果基本集中在正确位置(对角线),而ERB-Res3D模型会有一定的概率错误地识别两类行为。图13为ERB-Res3D识别结果具体样本案例,在同一样本案例下,使用GFDP能够准确识别出原先识别错误的视频样本,表明本文模型在区分相似行为时能够表现出更高的鲁棒性。
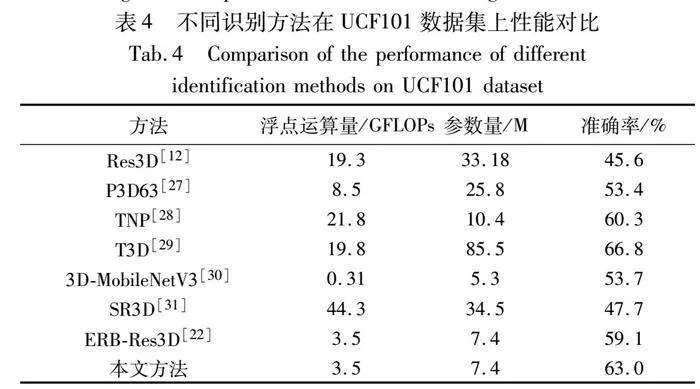
最后,为了验证所提模型的优势,将本文模型与当下流行的行为识别方法分别在浮点运算量、模型参数量和识别准确率三个性能指标上进行比较,其结果如表4所示。
从计算量和浮点运算量上分析,相比于ERB-Res3D方法,本文方法参数量并没有增加,浮点运算量上增加了DCT变换带来的计算量,由于数值较小可基本忽略,所以在这两个性能指标上与ERB-Res3D方法对比其他行为识别方法的分析相同。从表4中可以看出,本文方法最后的浮点运算量对比基准模型Res3D下降了81%,而参数量也降低了77%,可以直观地看出模型具有很好的轻量化效果。
对表中数据综合分析可知,本文方法的识别准确率对比ERB-Res3D方法提高了3.9%,对比基准模型Res3D提高了17.4%;T3D的准确率最高,比本文方法高了3.8%,但浮点运算量和参数量却是本文的5.7倍和11.6倍;3D-MobileNetV3的计算量和浮点运算量最低,但准确率比本文方法低了9.6%。结果表明,本文方法在维持计算量和浮点运算量的基础上,提升了模型的识别准确率,使模型表现出了更高的性能。
3 结束语
针对3D-ConvNet中全局平均池化存在的信息损失和信息冗余问题,为了更好地保留卷积层提取到的高级语义信息,本文提出了一种基于全局频域池化的人体行为/D6pyHNKQwWeQ25dqRQ9LmGV4pd8R7KUwKUK17s8Rhg=识别算法。一方面,由离散余弦变换分析了全局平均池化出现信息损失和信息冗余问题的原因是全局平均池化在压缩特征信息时只保留了最低频率分量而没有考虑其他频率分量带来的影响,并通过引入多个低频分量提出了全局频域池化方法,来丰富算法模型降采样后特征信息的多样性。另一方面,引入卷积层的批标准化策略并拓展至全连接输出层,降低了模型过拟合的风险。在相关数据集上的消融实验可以看出,引入四个低频分量的全局频域池化对模型性能的提升效果最佳。最终的实验结果表明,本文方法可以利用较低的浮点运算量和参数量实现更高的识别准确率。
下一步的研究方向可以从更加细粒度的角度出发,先观察每个频率分量单独使用时模型表现出的性能,然后按照性能提升的幅度,从高到低依次引入不同数目的频率分量,以便更好地补充特征信息,解决信息损失问题。随后,可以延伸至卷积神经网络中非全局的最大池化和平均池化,以寻找更为优越的降采样技术。
参考文献:
[1]朱相华, 智敏, 殷雁君. 基于2D CNN和Transformer的人体动作识别[J]. 电子测量技术, 2022, 45(15): 123-129. (Zhu Xianghua, Zhi Min, Yin Yanjun. Human action recognition based on 2D CNN and Transformer[J]. Electronic Measurement Technology, 2022, 45(15): 123-129.)
[2]张银环. 基于IA-Net的人体行为识别方法[J]. 国外电子测量技术, 2022, 41(6): 52-59. (Zhang Yinhuan. Human action recognition method based on IA-Net[J]. Foreign Electronic Measurement Technology, 2022, 41(6): 52-59.)
[3]Ahn D, Kim S, Hong H, et al. STAR-Transformer: a spatio-temporal cross attention transformer for human action recognition[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE Press, 2023: 3319-3328.
[4]Mobasheri B, Tabbakh S R K, Forghani Y. An approach for fall prediction based on kinematics of body key points using LSTM[J]. International Journal of Environmental Research and Public Health, 2022, 19(21): 13762.
[5]梁绪, 李文新, 张航宁. 人体行为识别方法研究综述[J]. 计算机应用研究, 2022, 39(3): 651-660. (Liang Xu, Li Wenxin, Zhang Hangning. Review of research on human action recognition methods[J]. Application Research of Computers, 2022, 39(3): 651-660.)
[6]Mo Jianwen, Zhu Rui, Yuan Hua, et al. Student behavior recognition based on multitask learning[J]. Multimedia Tools and Applications, 2023, 82(12): 19091-19108.
[7]Simonyan K, Zisserman A. Two-Stream convolutional networks for action recognition in videos[C]//Proc of the 27th International Confe-rence on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 568-576.
[8]Wang Xianyuan, Miao Zhenjiang, Zhang Ruyi, et al. I3D-LSTM: a new model for human action recognition[J]. IOP Conference Series: Materials Science and Engineering, 2019, 569(3): 032035.
[9]Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3D convolutional networks[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2015: 4489-4497.
[10]周生运, 张旭光, 方银锋. 基于行人组运动信息表达的人群异常检测[J]. 仪器仪表学报, 2022, 43(6): 221-229. (Zhou Shengyun, Zhang Xuguang, Fang Yinfeng. Crowd anomaly detection based on pedestrian group motion information expression[J]. Chinese Journal of Scientific Instrument, 2022, 43(6): 221-229.)
[11]Liu Daizong, Fang Xiang, Hu Wei, et al. Exploring optical-flow-guided motion and detection-based appearance for temporal sentence grounding[J]. IEEE Transactions on Multimedia, 2023,25:8539-8553.
[12]Du T, Ray J, Shou Zheng, et al. ConvNet architecture search for spatiotemporal feature learning[EB/OL]. (2017-08-16). https://arxiv.org/abs/1708.05038.
[13]Carreir J, Zisserman A. Vadis Q. Action recognition?A new model and the kinetics dataset[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 4724-4733.
[14]Tran D, Wang Heng, Torresani L, et al. A closer look at spatiotemporal convolutions for action recognition[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 6450-6459.
[15]Lin Ji, Gan Chuang, Han Song. TSM: temporal shift module for efficient video understanding[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 7082-7092.
[16]He Kaiming, Zhang Xia, Ren Shaoqing, et al. Deep residual lear-ning for image recognition[C]//Proc of IEEE Conference on Compu-ter Vision and Pattern Recognition. Piscataway, NJ: IEEE Press,2016: 770-778.
[17]Ehrlich M, Davis L. Deep residual learning in the JPEG transform domain[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 3483-3492.
[18]李长海. 基于深度学习的人体行为识别算法研究[D]. 成都:电子科技大学, 2021. (Li Changhai. Research on human action recognition algorithm based on deep learning[D]. Chengdu: University of Electronic Science and Technology of China, 2021.)
[19]Qin Zequn, Zhang Pengyi, Wu Fei, et al. FcaNet: frequency channel attention networks[C]//Proc of IEEE/CVF International Confe-rence on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 763-772.
[20]Yang Aitao, Li Min, Wu Zhaoqing, et al. CDF-Net: a convolutional neural network fusing frequency domain and spatial domain features[J]. IET Computer Vision, 2023, 17(3): 319-329.
[21]Yu Feng, Li Huiyin, Shi Yankang, et al. FFENet: frequency-spatial feature enhancement network for clothing classification[J]. PeerJ Computer Science, 2023, 9: e1555.
[22]张海超, 张闯. 融合注意力的轻量级行为识别网络研究[J]. 电子测量与仪器学报, 2022, 36(5): 173-179. (Zhang Haichao, Zhang Chuang. Research on lightweight action recognition network fusing attention[J]. Journal of Electronic Measurement and Instrumentation, 2022, 36(5): 173-179.)
[23]Soomr K, Zamir A R, Shan M. UCF101: a dataset of 101 human actions classes from videos in the wild[EB/OL]. (2012-12-03). https://arxiv.org/abs/1212.0402.
[24]Gloro X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//Proc of the 13th International Conference on Artificial Intelligence and Statistics.[S.l.]:PMLR,2010: 249-256.
[25]De S, Mukherjee A, Ullah E. Convergence guarantees for RMSProp and ADAM in non-convex optimization and an empirical comparison to Nesterov acceleration[EB/OL]. (2018-11-20). https://arxiv.org/abs/1807.06766.
[26]Ioffe S, Szeged C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proc of the 32nd International Conference on Machine Learning.[S.l.]: JMLR.org,2015: 448-456.
[27]Qiu Zhaofan, Yao Ting, Mei Tao. Learning spatio-temporal representation with Pseudo-3D residual networks[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 5534-5542.
[28]刘钊, 杨帆, 司亚中. 时域非填充网络视频行为识别算法研究[J]. 计算机工程与应用, 2023, 59(1): 162-168. (Liu Zhao, Yang Fan, Si Yazhong. Research on time Domain unfilled network video behavior recognition algorithm[J]. Computer Engineering and Applications, 2023, 59(1): 162-168.)
[29]Diba A, Fayya M, Sharm V, et al. Temporal 3D ConvNets: new architecture and transfer learning for video classification[EB/OL]. (2017-11-22). https://arxiv.org/abs/1711.08200.
[30]胡希国. 基于视频的轻量级人体行为识别算法研究[D]. 成都: 电子科技大学, 2021. (Hu Xiguo. Research on lightweight human action recognition algorithm based on video[D]. Chengdu: University of Electronic Science and Technology of China, 2021.)
[31]徐鹏飞, 张鹏超, 刘亚恒,等. 一种基于SR3D网络的人体行为识别算法[J]. 电脑知识与技术, 2022, 18(1): 10-11. (Xu Pengfei, Zhang Pengchao, Liu Yaheng et al. A human action recognition algorithm based on SR3D network[J]. Computer Knowledge and Technology, 2022, 18(1): 10-11.)
收稿日期:2023-11-02;修回日期:2024-01-10 基金项目:国家自然科学基金资助项目(62272234)
作者简介:贾志超(2000—),男,安徽天长人,硕士研究生,主要研究方向为深度学习;张海超(1997—),男,河南洛阳人,硕士,主要研究方向为深度学习、行为识别;张闯(1976—),女(通信作者),河北唐山人,副教授,硕导,博士,主要研究方向为光电信息、视觉信息采集与处理(zhch_76@163.com);颜蒙蒙(1995—),女,江苏连云港人,硕士研究生,主要研究方向为深度学习、行为识别;储金祺(1998—),男,江苏泰州人,硕士研究生,主要研究方向为深度学习、目标检测;颜之岳(1999—),男,江苏常州人,硕士研究生,主要研究方向为小目标检测.
