基于集中注意力接受场网络的偏振成像伪装目标检测
2024-11-04徐国明陈奇志刘綦马健王峰







摘 要:
针对伪装物体分割中图像识别鲁棒性较差,模型泛化性不强的问题,受神经科学中人类视觉系统接受场结构的启发,提出一种基于集中注意力接受场网络的偏振成像伪装目标检测方法。根据偏振成像目标探测需要,构建了能有效遏制背景噪声以及获取目标细节特征的偏振成像数据集。方法基于识别与定位网络框架,通过改进特征提取模块和解码器模块,该模块利用了偏心度和感受野大小之间的关系,涵盖多尺度的目标信息,可以有效提高伪装目标特征的可分辨性和鲁棒性。实验验证利用自建数据集在多个典型目标上进行,并与经典算法进行分割结果的主观视觉与客观评价指标对比,对比实验结果验证了该方法的有效性。
关键词:偏振成像;伪装目标分割;机器视觉;卷积神经网络;数据集
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)09-040-2854-06
doi: 10.19734/j.issn.1001-3695.2023.10.0574
Polarization imaging camouflage target detection based on focused attention receptive field network
Xu Guoming1,2,3, Chen Qizhi1, Liu Qi1,2, Ma Jian1,2, Wang Feng3
(1.School of Internet, Anhui University, Hefei 230039, China; 2.National Engineering Research Center for Agro-Ecological Big Data Analysis & Application, Anhui University, Hefei 230601, China; 3.Anhui Province Key Laboratory of Polarized Imaging Detecting Technology, Hefei 230031, China)
Abstract:
Aiming at the problems of poor image recognition robustness and poor model generalization in camouflaged object segmentation, inspired by the receptive field structure of the human visual system in neuroscience, this paper proposed a polarization imaging camouflage target detection method based on the receptive field network of focused attention. According to the polarization imaging target detection needs, it constructed the polarization imaging dataset that could effectively contain the background noise as well as obtain the detailed features of the target. The proposed method based on the recognition and localization network framework, which could effectively improve the discriminability and robustness of camouflaged target features by improving the feature extraction module and the decoder module, which exploited the relationship between the eccentricity and the size of the receptive field to cover multi-scale target information. The experimental validation carries out using a self-constructed dataset on multiple typical targets and comparing the subjective visual and objective evaluation metrics of the segmentation results with classical algorithms, and the results of the ablation experiments validate the effectiveness of the present segmentation method.
Key words:polarization image; camouflaged object segmentation; machine vision; convolutional neural network; dataset
0 引言
偏振、干涉、衍射都是光的重要物理特性,其中偏振是指相对于光的传播方向,光的振动方向是不对称的,地表或者大气层的物体在受到光的反射、散射、投射和电磁辐射的时候会产生相对应的偏振信息,偏振信息可用于分析物体的形状、表面粗糙程度、纹理走向以及材料的理化特性等。偏振成像技术相对于传统的成像技术,提供了二维空间的光强分布、光谱谱线和偏振信息,不仅可以完整解析出物体的特征信息,而且可以抑制噪声,对环境有更好的适应性。在20世纪,西方国家开始进行偏振成像的相关实验,Tooley[1]提出将偏振成像应用于复杂环境中的目标识别,并对人造目标和自然环境的偏振特征进行描述;Chenault等人[2]通过实验提出了偏振图像有利于降低散射光对成像的影响;Boffety等人[3]提出了适用于多波段的偏振图像的对比度优化方法,进一步提高了目标和背景的对比度;Short等人[4]提出用于提取偏振图像的局部梯度幅度值和方向特征的人脸识别算法。在实际应用于伪装目标检测过程中,偏振光在和目标发生作用后,根据反射和透射光可以提取目标的表面粗糙程度、边缘细化差异以及内部结构的情况,从而获得更具优势的被测目标的图像特征和相关信息。
最近几年,伪装目标检测研究出现了爆炸式增长,部分原因是对警戒色和模仿的研究越来越多,同时也是视觉感知和目标检测等相关领域快速发展的必然趋势。传统意义上的伪装识别是指试图了解不同形式的伪装所涉及的近似机制,还需要综合考虑心理和生态环境的因素,这可以理解自然选择和施加在伪装上的约束,它们都影响伪装策略的优化和进化。从更广泛的意义上说,伪装已经被人类所采用,最显著的是应用于军队和猎人,同时它也影响了社会的其他部分,例如,医学诊断(如息肉分割[5]和肺部感染分割[6])、工业(如在自动生产线上检查不合格产品)、农业(如蝗虫检测,以防止入侵)、安全和监视(如搜索和救援任务以及恶劣天气中针对自动驾驶的行人或障碍物的检测)、科学研究(如稀有物种发现)和艺术(如逼真的融合和娱乐艺术)等不同领域,具有广泛且有价值的应用。目前,越来越多的研究人员对伪装感兴趣,在生物学、视觉心理学、计算机科学和艺术之间产生了更多的跨学科联系。
伪装物体分割(camouflaged object segmentation,COS)[7]的目的是分割检测出伪装在环境中的目标。传统的伪装检测是根据物体的一些低级的特征信息(如纹理等)来区分伪装目标和背景,与其他的检测目标相比,检测效果的鲁棒性较低。伪装目标的检测与通用目标检测(generic object detection,GOD)[8]有所区别,GOD的目标更加广泛,既可以是伪装的,也可以是显著的。COS和显著性目标检测(salient object detection,SOD)[9]的检测目的有点相似,COS是对伪装目标把输入的特征分成伪装目标和背景的二分类分割,SOD则把输入特征分为显著物体和背景,从某种程度上来说COS和SOD分割的目标是完全相反的。
利用人类识别目标时的直接目标特征,多种基于传统特征提取的伪装目标检测方法被提出。1998年,Tankus等人[10]提出的非边缘感兴趣区域机制,是针对伪装目标检测最早的算法,被应用于自然环境中的人工伪装目标。Zhang等人[11]通过引入前景和背景建模,提出了在贝叶斯框架下执行完整的伪装目标检测;Beiderman等人[12]提出通过空间相干光束(如激光)照射分类、识别或识别的被遮挡物体的景物,从物体反射出二次散斑图案,基于随机散斑图案的时间跟踪,提取物体的时间特征;Galun等人[13]提出自下而上的聚合框架来解决伪装纹理分割,该框架将纹理元素的结构特征与过滤器响应相结合;Hall等人[14]研究了不同伪装对人类计算机任务中捕食检测、识别和捕获三个阶段的影响。
然而,传统的伪装检测方法难以有效地区分对比度较低的伪装场景,存在特征提取耗时、特征表征能力弱、检测效果差等问题。随着基于深度学习的目标检测成为当前研究的热门,伪装目标检测方法开始在特征提取和检测效果上获得更好的结果,能够有效地增强伪装目标检测模型的鲁棒性。现有的大部分基于深度学习的伪装目标检测方法首先采用卷积神经网络,如VGG(visual geometry group)[15]、ResNet(residual neural network)[16]、Res2Net[17]等进行特征提取,然后通过增强特征,提高伪装目标检测的性能[18]。Fan等人[19]通过搜索注意力机制和部分解码器组件对伪装目标的前景和背景的模糊区域进行定位和提取。Lyu等人[20]提出使用LSR(localization,segmentation and ranking)来对目标进行定位,并在不同图像的伪装级别,按照预设评价指标划分伪装目标。Mei等人[7]提出基于分心挖掘的 PFNet(positioning and focus network)模型,能够有效地去除前景和背景中异质干扰,提取含有更加丰富信息的伪装目标的特征。Mao等人[21]使用Swin Transformer作为backbone提取伪装目标的特征,通过将结合残差注意力和密集金字塔池化的监督结构来降低主干网络不直接提供空间监督的影响。Zhu等人[22]提出基于双流式分散注意力网络BSANet,通过区分前景和背景以获得更加细化的边缘特征,减少目标的丢失。Pang等人[23]提出使用三重结构获取伪装目标的差异化特征的网络ZOOMNet,利用不同的尺度聚合模块和分层混合尺度模块增强特征,获取更加准确的预测。
在神经科学相关的领域,人们发现在视觉皮层中人体接受场的大小是视网膜图中呈正相关的偏心率函数。根据这个发现可以认为,越接近中心的区域更容易识别物体的特征,并且大脑在对于小的空间变化时具有不敏感性[24]。因此,本文基于目标与背景的偏振特性差异,设计一种人类视觉相关融合物理结构的接受场模块来增强轻量级网络的特征表示,采用自建的基于伪装的偏振数据集,充分利用偏振图像增强物体的对比度、降低背景噪声并获取丰富细节特征的特性,提高伪装物体的识别率。
1 相关工作
1.1 群接受场模块
接受场建模是神经科学领域一种重要的感官科学工具,用于预测人的生理反应和构建大脑的计算模型。接受场这一概念原先是由视觉神经领域专家Sherrington[25]描述皮肤上可以引起挠抓反射的区域,提出接受场可以方便地用于指定所有的感受点的集合,在适当的刺激下,一种特殊的反射运动可以被唤起。Hartline[26]最先将这一概念引入视觉神经元。在过去的几十年里,许多研究者应用接受场模型来表征人类视觉皮层的反应。人类通过使用神经科学仪器经常能观测到多个神经元产生集合反应,因此这些模型通常被称为群接受场模型,即pRF(population receptive field properties)模型。
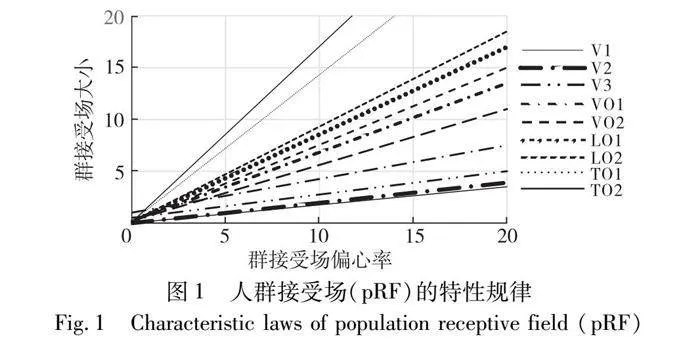
在视网膜中,视觉系统实现了偏心和感受野大小之间的关系。这种关系也可以在非人灵长类动物的单位测量中观察到。利用功能磁共振成像和pRF模型,可以在皮层的许多视野映射中测量这种关系。在每个皮层图中,pRF的大小和偏心量一起增加。不同视野图的pRF大小增加速率不同(图1),pRF的大小与不同实验的偏心率呈正相关,不同映射的pRF的大小有较大的差异,V1的最小,TO1和TO2的群接受场要大得多。pRF大小作为视网膜位图偏心的函数。这一观察结果已经被重复证明了很多次[27]。
接受场模型有两个有价值的特性。首先,关键pRF参数(接受场位置和大小)具有在刺激帧中指定的可解释单位,这使得能够直接比较使用不同仪器估计的模型参数。第二,接受场可以在个体被试者中进行估计。因此,有意义地比较两个被试者之间的模型参数是可能的,相同的被试者在不同的条件下,或者相同的被试者用不同的仪器测量。这两个特性提供了坚实的科学基础,并支持实际应用。基于上述特性,在深度学习中,为伪装目标的特征提取提供了一种新的思路,根据人眼在每个刺激帧中对于不同目标的不同反应,使用大量数据集进行训练,可以有效地建立网络模型模拟真实人眼的识别架构。
1.2 偏振成像
强度、波长和偏振是光的三个基本特性。光波是横波,其矢量的振动方向垂直于光的传播方向,而偏振光的光矢量的振动方向不变或规则变化。偏振照相机用于在多偏振状态下捕捉光的强度。
自然界中,光在传输过程中电矢量振动的空间分布具有一定的对称性,如图2所示。当横波的振动矢量偏向于某些方向产生的现象被称为偏振。当电矢量的振动在某些固定方向的时候,可以得到四个方向(0°,45°,90°和135°)的线偏振光,如图3所示。
2.2 接受场模块
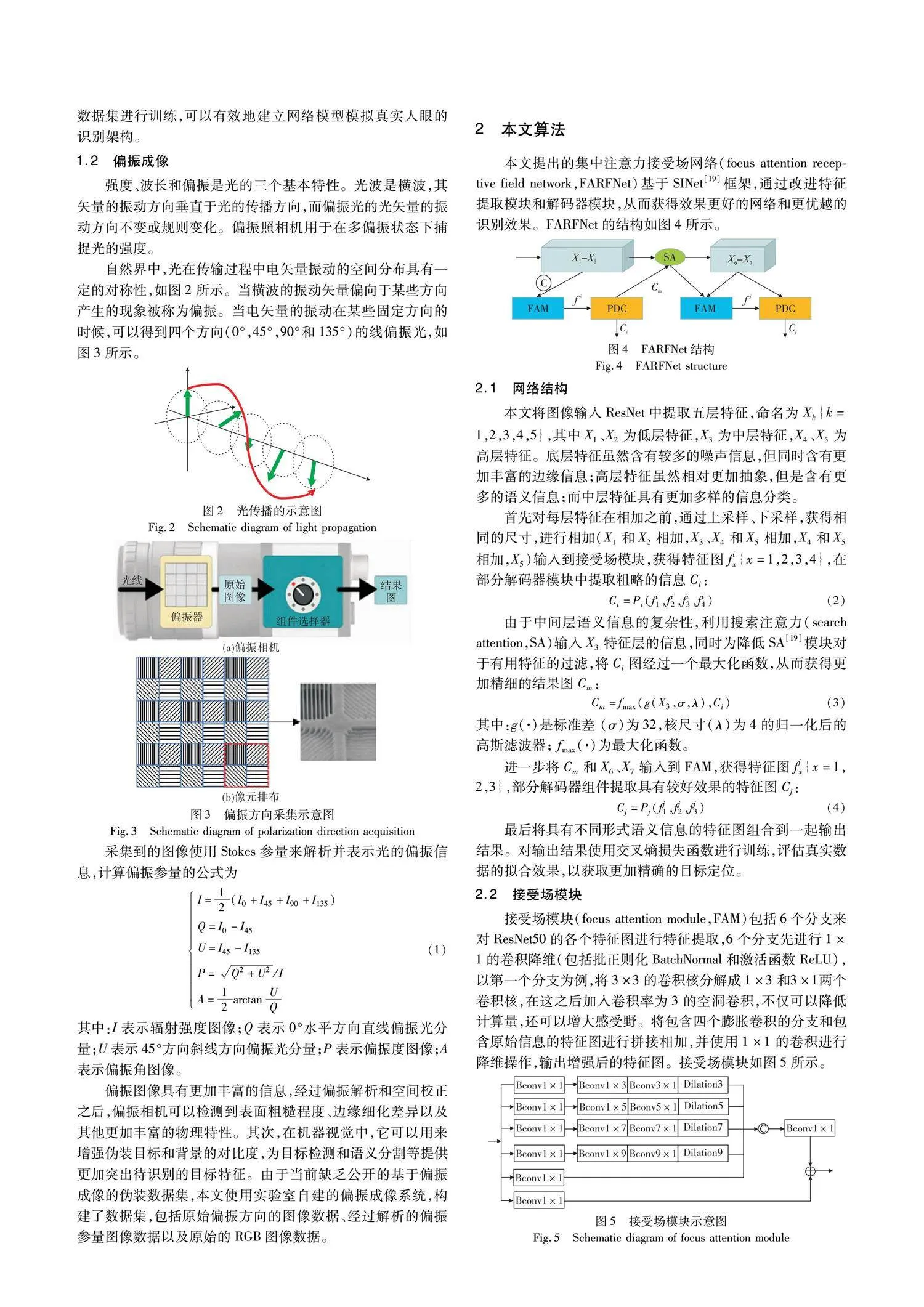
接受场模块(focus attention module,FAM)包括6个分支来对ResNet50的各个特征图进行特征提取,6个分支先进行1×1的卷积降维(包括批正则化BatchNormal和激活函数ReLU),以第一个分支为例,将3×3的卷积核分解成1×3和3×1两个卷积核,在这之后加入卷积率为3的空洞卷积,不仅可以降低计算量,还可以增大感受野。将包含四个膨胀卷积的分支和包含原始信息的特征图进行拼接相加,并使用1×1的卷积进行降维操作,输出增强后的特征图。接受场模块如图5所示。
该模块由inception改进而来,受到膨胀卷积和分支结构影响,本文根据偏振图像的特点以及扩大感受野的角度,新增加了一个9×9的分支结构。经过实验验证发现,多尺度特征的丰富性有助于特征提取,场景中的伪装目标在更加优化的特征提取模块的作用下,各项结果指标有明显提高。
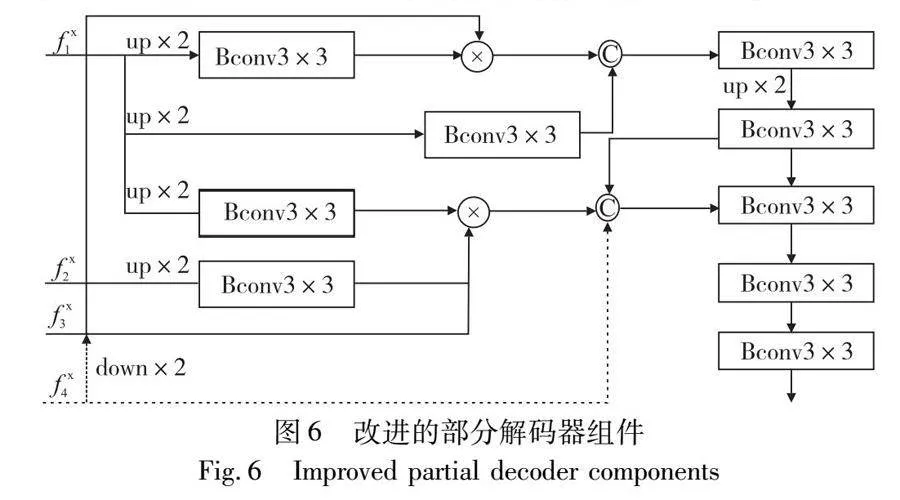
2.3 部分解码器组件
从FAM中获取的候选特征输入到部分解码器组件(partial decoder components,PDC)组件中,分别对输入的不同层的特征进行上采样和下采样,以获得相同大小的中间层特征图,逐元素相乘的方式降低相邻元素之间的差距。考虑到底层特征和高层特征的特性,本文将含有更多边界信息的底层特征通过降维加入到有更多语义信息的底层特征进行元素乘法,以获得更好的输出结果。改进的部分解码器组件如图6所示。
2.4 损失函数
本文模型的损失函数使用交叉熵(cross entropy loss)[27],CELoss能够更好地收敛,传递的梯度信息能够更均匀,能够有效地比较不同的分布概率在同一个随机变量下的差异程度,在机器学习中就表示为真实概率分布(即输出特征图)与预测概率分布(手动打标的GT图像)之间的差异。模型的预测结果与CELoss的值呈负相关,CELoss的值越小,模型预测效果就越好。对Ci和Cj上采样后,本文的总损失函数定义为
L=LiCE(Ci,G)+LsCE(Cj,G)(5)
其中:LCE为FARFNet定义的损失函数;L为总损失函数;G为Ground Truth图像对应的特征图;Ci、Cj为输出放大的特征图。
CELoss采用了类间竞争机制,擅长学习不同标签之间的分类信息,相对于其他传统语义分割的多标签不同种类的预测,COS不用考虑非正确的标签预测概率的准确性,能够更加专注于正确的标签预测概率。针对伪装的二分类问题只有目标和背景的情况,只需要识别伪装的目标信息,所以有效地减少或者避免了CELoss的不足与缺点。
3 实验结果与分析
3.1 实验数据集
由于种种原因,当前基于伪装的偏振数据集公开极少,为支持本文伪装目标检测算法,构建基于伪装迷彩的偏振数据集,利用该数据集对FARFNet进行训练。
偏振伪装图像由偏振相机采集,如图7所示,采集的图像分辨率为5.0 MP,2448×2048 px,帧率为24 fps,采用CMOS单声道传感器,如图7所示。该传感器能同时采集0°、45°、90°和135°四个偏振方向的图像。
本文的数据集包括2 800张自建图像和从网络上搜集的200张与伪装相关的图像,3 000张数据通过翻转、旋转、平移和抖动四种几何变换进行增强,扩充到15 000张,数据集按照9∶1划分为训练集和测试集,数据集中所有的伪装目标包括迷彩服、装甲车、坦克车和部分小动物的自然伪装,包含有较丰富的环境特点:a)不同时间段,早晨、正中午、傍晚、夜晚;b)不同场景,枯草坪、绿草坪、小树林、林间小道、水泥地等;c)伪装目标,针对不同环境,制造更适合目标伪装的角度,获取包含各个尺度伪装目标的数据集,偏振伪装数据集部分图像标注与解析如图8所示。
3.2 实验环境
本文设计的实验环境参数具体如表1所示。
3.3 评价指标和实验参数设置
为了更好地验证FARFNet的算法性能,评估改进后的算法模型,本文选用了6个常见的评价指标,具体指标描述如表2所示。
本文算法的模型由Adam optimizer训练,初始学习率设置为0.000 1,每30个epoch迭代反向传播学习的速率降低10%,网络共迭代1 200次,批处理大小为16。
3.4 实现结果分析
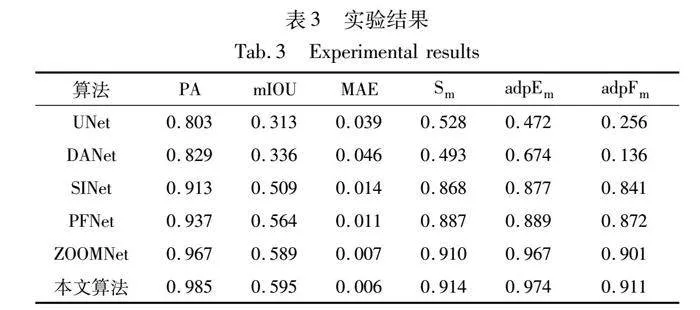
本文使用表2中的PA、mIOU、MAE、Sm、adpEm、adpFm作为评价指标,分别与UNet、DANet、SINet、PFNet和ZOOMNet进行比较,得到的实验结果如表3所示。
从表中可以看出,本文算法在所有指标上均有一定提升,相对于UNet、DANet、SINet、PFNet和ZOOMNet的PA值提升了0.182、0.156、0.072、0.048和0.018,mIOU提升了0.282、0.259、0.086、0.031和0.006,MAE减小了0.033、0.04、0.008、0.005和0.001,Sm提升了0.386、0.421、0.046、0.027和0.004,adpEm值提升了0.502、0.3、0.097、0.085和0.007,adpFm值提升了0.655、0.775、0.07、0.039和0.01,从数据上可以直观地看出效果提升。图9是方法对比的预测图,从图中也可以看出预测图接近GT真值图。
3.5 对比实验
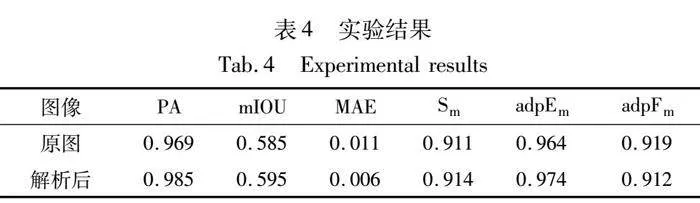
本文对采集到的伪装偏振数据集使用Stokes参量进行解析后,对获得的偏振参量图像进行实验。为验证偏振图像在本文算法中的有效性,将采集的原始图像同样放入网络中测试并进行对比,结果如表4和图10所示。根据表中实验数据可知,偏振参量图像在测试后的结果上总体优于原图,PA、mIOU、MAE、Sm和adpEm分别提升了0.016、0.01、0.005、0.003和0.01,adpFm降低了0.007。除了adpFm,总体较原图都有所提升,而adpFm的差值很小,对于整体模型的实验效果没有很大的影响。由此可以得出结论,偏振解析后的图像在本文的伪装目标检测算法中有较好的实验效果,这对偏振成像技术与深度学习目标检测方法相结合进行智能探测研究具有重要的参考价值。实验结果对比如图10所示。
4 结束语
本文提出一种基于接受场模型的偏振成像伪装目标检测方法,其在各个评价指标上都优于其他算法,充分说明该方法能够实现更好的检测和识别效果,为基于伪装的偏振图像的目标检测研究提供了一种数据支撑和新的思路。本文主要考虑伪装数据集和接受场模块对于网络模型的改进与提升,充分利用了偏振图像的优点,获取更加丰富的图像特征。下一阶段的主要任务是减少网络模型参数量,在保证利用目标偏振特性的同时,提高算法检测效率并改进网络以增加边缘检测的效果,这对该领域研究的应用转换具有重要意义,相关工作正在进行中。
参考文献:
[1]Tooley R D. Man-made target detection using infrared polarization [J]. Proc of SPIE-The International Society for Optical Engineering, 1990, 1166: 52-59.
[2]Chenault D B,Pezzaniti J L. Polarization imaging through scattering media [J]. SY Technology,2000,4133: 124-133.
[3]Boffety M,Hu H,Goudail F. Contrast optimization in broadband passive polarimetric imaging [J]. Optics Letters,2014,39(23): 6759-6762.
[4]Short N,Hu S,Gurton P K,et al. Changing the paradigm in human identification [J]. Optics & Photonics News,2015,26(12): 40.
[5]Fan Dengping,Ji Gepeng,Zhou Tao,et al. PraNet: parallel reverse attention network for polyp segmentation [C]// Proc of the 23rd International Conference on Medical Image Computing and Computer Assisted Intervention. Cham:Springer,2020: 263-273.
[6]Fan Dengping,Zhou Tao,Ji Geping,et al. Inf-Net: automatic Covid-19 lung infection segmentation from CT images [J]. IEEE Trans on Medical Imaging,2020,39(8): 2626-2637.
[7]Mei Haiyang,Ji Gepeng,Wei Ziqi,et al. Camouflaged object segmentation with distraction mining [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 8768-8777.
[8]Everingham M,Eslami S A,Van Gool L,et al. The pascal visual object classes challenge: a retrospective [J]. International Journal of Computer Vision,2015,111: 98-136.
[9]Itti L,Koch C,Niebur E. A model of saliency-based visual attention for rapid scene analysis [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,1998,20(11): 1254-1259.
[10]Tankus A,Yeshurun Y. Detection of regions of interest and camouflage breaking by direct convexity estimation [C]// Proc of IEEE Workshop on Visual Surveillance. Piscataway,NJ: IEEE Press,1998: 42-48.
[11]Zhang Xiang,Zhu Ce,Wang Shuai,et al. A Bayesian approach to camouflaged moving object detection [J]. IEEE Trans on Circuits and Systems for Video Technology,2016,27(9): 2001-2013.
[12]Beiderman Y,Teicher M,Garcia J,et al. Optical technique for classification,recognition and identification of obscured objects [J]. Optics Communications,2010,283(21): 4274-4282.
[13]Galun M,Sharon E,Basri J,et al. Texture segmentation by multiscale aggregation of filter responses and shape elements [C]// Proc of the 9th IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2003:716-723.
[14]Hall J R,Cuthill I C,Baddeley R,et al. Camouflage,detection and identification of moving targets [J]. Biological Sciences,2013,280(1758): 20130064.
[15]Siminyan K,Zisserman A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015-04-10). https://arxiv.org/abs/1409.1556.
[16]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Computer Society,2016: 770-778.
[17]Gao Shanghua,Cheng Mingming,Zhao Kai,et al. Res2Net: a new multi-scale backbone architecture [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2019,43(2): 652-662.
[18]史彩娟,任弼娟,王子雯,等. 基于深度学习的伪装目标检测综述 [J]. 计算机科学与探索,2022,16(12): 2734-2751. (Shi Caijuan,Ren Bijuan,Wang Ziwen,et al. Overview of camouflage target detection based on deep learning [J]. Computer Science and Exploration,2022,16(12): 2734-2751.)
[19]Fan Dengping,Ji Gepeng,Sun Guo,et al. Camouflaged object detection [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 2774-2784.
[20]Lyu Yunqiu,Zhang Jing,Dai Yuchao,et al. Simultaneously localize,segment and rank the camouflaged objects [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 11586-11589.
[21]Mao Yuxin,Zhang Jing,Wan Zhexiong,et al. Transformer transforms salient object detection and camouflaged object detection [EB/OL]. (2021-04-20). https://export.arxiv.org/abs/2104.10127v2.
[22]Zhu Hongwei,Li Peng,Xie Haoran,et al. I can find you! Boundary-guided separated attention network for camouflaged object detection [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2022: 3608-3616.
[23]Pang Youwei,Zhao Xiaoqi,Xiang Tianzhu,et al. Zoom in and out: a mixed-scale triplet network for camouflage object detection [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway,NJ: IEEE Press,2022: 2160-2170.
[24]Liu Songtao,Huang Di,Wang Yunhong. Receptive field block net for accurate and fast object detection [C]// Proc of the 15th European Conference on Computer Vision. Berlin: Springer,2018: 404-419.
[25]Sherrington C S. Flexion-reflex of the limb,crossed extension-reflex,and reflex stepping and standing [J]. The Journal of Physiology,1910,40(1-2): 28.
[26]Hartline H K. The response of single optic nerve fibers of the vertebrate eye to illumination of the retina [J]. American Journal of Physiology-Legacy Content,1938,121(2): 400-415.
[27]Wandell B A,Winawer J. Computational neuroimaging and population receptive fields [J]. Trends in Cognitive Sciences,2015,19(6): 349-357.
收稿日期:2023-10-17;修回日期:2024-01-18 基金项目:国家自然科学基金资助项目(61906118,62273001);安徽省重大专项(202003A06020016);安徽省自然科学基金资助项目(1908085MF208,2108085MF230);陆军装备部十三五预研子课题;安徽省高校自然科学研究重点项目(KJ2019A0906)
作者简介:徐国明(1979—),男,安徽太和人,教授,博导,博士,CCF会员,主要研究方向为偏振成像探测、图像超分辨率;陈奇志(1999—),男(通信作者),安徽合肥人,硕士研究生,主要研究方向为目标检测、偏振成像(315969932@qq.com);刘綦(1978—),女,陕西西安人,副教授,硕士,主要研究方向为智能数据处理、无线传感器网络;马健(1985—),男,安徽颍上人,讲师,硕导,博士,主要研究方向为图像质量评价、计算机视觉;王峰(1972—),男,教授,博士,主要研究方向为新型光电成像探测技术.
