融合表字段的NL2SQL多任务学习方法
2024-11-04刘洋廖薇徐震



摘 要:现有的自然语言转SQL(NL2SQL)方法没有充分利用数据表的字段信息,而这对于问题的语义理解和SQL语句的逻辑生成有着重要作用。为了提高SQL生成的整体准确性,提出一种融合数据表字段的NL2SQL方法(FC-SQL)。首先,利用BERT预训练模型对问题和数据库表字段进行合并编码表示;其次,采用多任务学习的方式,结合并联和级联的方式构建多任务网络,以预测不同子任务;最后,针对条件值提取子任务,通过融合字段信息计算问题中词与表字段的相似度,并以相似度值作为权重来计算每个词语作为条件值的概率,从而提高条件值预测的准确率。在TableQA数据集上的逻辑形式准确率与SQL执行准确率分别达到88.23%和91.65%。设计消融实验验证表字段信息对于模型的影响,实验结果表明融入表字段后,条件值抽取子任务效果有所提升,进而改善了NL2SQL任务的整体准确率,相较于对比模型有更好的SQL生成效果。
关键词:多任务学习; 自然语言转SQL; 自然语言处理; 表字段
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)09-033-2800-05
doi:10.19734/j.issn.1001-3695.2023.12.0629
Multi-task learning method for NL2SQL with fused table columns
Liu Yanga, Liao Weia, Xu Zhenb
(a.School of Electronic & Electrical Engineering, b.School of Mechanical & Automotive Engineering, Shanghai University of Engineering Science, Shanghai 201620, China)
Abstract:Existing NL2SQL approaches do not fully utilize the information of data table columns, which plays an important role in the semantic understanding of the problem and the logical generation of SQL statements. This paper proposed an NL2SQL method that fused data table columns(FC-SQL) to improve the overall accuracy of SQL generation. Firstly, this method utilized BERT to merge the problem and database table columns for encoded representations. Secondly, it used multi-task learning approach to construct a multi-task network by combining parallel and cascade to predict different sub-tasks. Finally, for the conditional value extraction sub-task, this method computed the similarity between the words in the problem and the table columns by fusing the information of the columns, and it used the similarity value as a weight to compute each word as the conditional value probability of each word as a conditional value, thus improving the accuracy of conditional value prediction. The logical form accuracy and SQL execution accuracy on the TableQA dataset reach 88.23% and 91.65%, respectively. This paper designed ablation experiments to verify the effect of table columns information on the model. The experimental results show that the incorporation of table columns improves the effectiveness of the conditional value extraction sub-task, which in turn improves the overall accuracy of the NL2SQL task and provides better SQL generation compared to the comparison model.
Key words:multi-task learning; NL2SQL; natural language processing; table columns
数据的规模和多样性持续增长,使得数据分析和挖掘在各领域变得日益重要。例如,金融、医疗、零售和能源等行业均依赖于高效的数据查询来进行关键决策。但传统的数据查询方式主要依赖于结构化查询语言,给非技术背景的用户带来了较大的学习成本。为了缩短技术与非技术用户之间的差距,自然语言转SQL(NL2SQL)技术应运而生,不仅可以提高查询的效率,还能促进跨学科和跨行业的合作。
尽管NL2SQL技术在最近几年取得了许多进步[1~3],但在实际应用中仍面临诸多挑战,如跨领域知识的获取、自然语言的模糊语义解析,以及处理复杂嵌套查询等。针对这些难点,一些基于深度学习的端到端方法被广泛应用,例如序列到序列模型(Seq2seq)[4]和树状网络模型[5]等。这些方法可以直接学习输入查询与输出SQL之间的对应关系,取得了不错的效果。
当前,研究人员正在探寻更加高效和准确的NL2SQL方法。比如借助基于BERT[6]的预训练模型,通过迁移学习等方法使得模型进一步提高其泛化能力[7]。由于这些技术的出现,未来的NL2SQL系统可能不仅能够解决复杂的查询问题,还能在数据安全等方面提供更强大的支持,这将进一步推动其在商业和科研领域的广泛应用。
1 相关工作
NL2SQL目前作为自然语言处理的焦点子领域,其目的是将输入的查询问题转换为数据库可以解析和执行的SQL语句。这个转换过程对于确保高效的数据库交互尤为关键,NL2SQL示例如图1所示。
在该领域的早期研究中,主流方法主要采用流水线策略。Yih等人[8]提出了一种基于流水线的语义解析方法,将自然语言问题转换为与知识库中的实体和关系相对应的查询图。这种策略在一定程度上简化了问题,但是模块之间的依赖性可能导致错误的连锁反应。使用端到端的神经网络模型可以捕捉语义解析任务的全局特征,以克服流水线方法的局限性[9]。端到端方法也面临数据需求量大、解释性差等问题[10],结合两种方法的优点进行模型设计仍然是NL2SQL研究的重要方向。
随着深度学习在自然语言处理领域的广泛应用,NL2SQL技术取得了进步。基于深度学习的NL2SQL模型能够处理不同数据库表格和复杂跨领域的自然语言查询。比如利用预训练模型来帮助提高模型的泛化能力和准确率[11]。Xu等人[12]提出的SQLNet是在WikiSQL数据集[13]上一个比较知名的基准模型,是最早使用模板填充方法的模型。
为了解决数据表信息没有被利用的问题,Yu等人[14]提出了TypeSQL模型,利用数据库中的类型信息来更好地理解自然语言问句中的实体和数字。Hwang等人[15]使用SQLova模型借助预训练模型,提高了序列生成的效果。同样地,He等人[16]提出的X-SQL模型也使用了预训练模型,不同的是使用了MT-DNN(multi-task deep neural networks)[17]模型代替BERT,并利用上下文进行增强结构化表示。Lyu等人[18]提出的HydraNet模型将NL2SQL问题分解为列级别的排序和解码,然后用简单的规则将列级别的输出组合成一个 SQL 查询。
多任务学习可以共享参数和表示,让模型学习到更丰富和更通用的语言知识。McCann等人[19]使用了一种多任务问答网络结构,通过使用多种注意力机制来共同学习多任务表示。本文在多任务学习的基础上,通过在BERT模型的输入序列中融合表字段,提出FC-SQL方法,使得模型能更好地理解数据库结构信息,并利用表字段来提高子任务的预测效果。
2 研究方法
2.1 模板定义
目前针对单表场景下的NL2SQL任务,模板填充是较为常用的方法[12,15,16]。在单表查询场景中,基于模板填充的方法能够较好地完成自然语言到SQL的转换。这种方法依赖预定义的查询模板及其对应的填充规则,将SQL生成任务分解为多个子任务,每个子任务对应模板中的一个槽位进行填充。相比其他方法,基于模板的方法可以明确查询语义结构,且无须考虑多表场景下的内连接、外连接等操作,有利于利用预训练语言模型更好地完成信息提取。因此考虑到基于模板填充方法在单表场景下的优势,本文也采用这种方法来研究单表场景的NL2SQL任务。
首先需要设计一个查询模板以捕捉自然语言查询中的关键信息。在模板设计时,应平衡查询语法的灵活性与数据库结构的复杂性,使模板系统能够覆盖不同类型的查询需求。设计的模板应包含多个槽位,对应SQL查询语句的组成元素,如表名、字段、操作符等。模板形式可以表示为
SELECT [列1,列2,…] FROM [表名] WHERE [条件1,条件2,…]
方括号中的内容为槽位,用于填充实际值。与具体数据库结构信息相结合,模板需要预定义各种字段和操作符的候选值,具体的定义方式如图2所示。$AGG代表聚合函数,取值为{“”,“AVG”,“MAX”,“MIN”,“COUNT”,“SUM”},空字段表示该选择列无聚合操作;$COL代表被选择的列和条件中被选择的列;$OP代表条件运算符,在数据集中给出的取值为{“>”,“<”,“=”,“!=”},本文中进行实验评估时,将精确匹配“=”换为“like”模糊匹配,$VALUE代表条件值任务;$CONN代表条件连接符,取值为{“”,“and”,“or”},空字段表示无条件连接符。
2.2 编码层
使用BERT预训练模型来学习多任务表示,将自然语言查询和数据库字段进行合并表征,目的是将问题和数据库信息转换为上下文相关的向量表示,以便后续的SQL生成层进行语义解析。本文采用了Chinese-BERT-WWM模型,该模型在大规模的无标注文本上进行了预训练,可以学习双向语义表示,并捕捉单词和句子在不同上下文中的语义信息。
2.2.1 融合表字段的输入序列
为适配BERT模型,对问题和数据表字段进行了预处理,构造模型的输入序列。首先使用WordPiece分词器对查询语句进行分词,WordPiece通过在词表中选择最大化语言模型似然概率的两个子词,从而生成新的子词。
假设由n个子词组成的句子T=(t1,t2,…,tn),ti表示第i个词,那么句子T的语言模型似然值可以表示为所有子词概率的乘积:
log P(T)=∑ni=1log P(ti)(1)
假设将相邻的子词a和b合并为新的子词c,然后合并前后句子的似然值变化为
log P(tc)-(log P(ta)+log P(tb))(2)
似然值的变化相当于两个子词之间的互信息。WordPiece每次选择互信息值最大的两个相邻子词进行合并,优先合并在语料中常见的相邻子词对。合并两个子词后,将它们替换为一个新的子词,并更新词汇表。这个过程迭代进行,直到达到预定词汇表大小。一旦词汇表构建完毕,WordPiece就可以用于将新的文本分成子词序列。分词完成后,将分词后的问句和字段按如下特定格式拼接成一个序列:
[CLS]问题查询[SEP]字段1 [SEP]字段2 [SEP]…
例如,对于查询“北京的人口是多少?”和字段[“城市”,“人口”],经过上述预处理后,得到的BERT模型输入序列为
[CLS]北京 的 人口 是 多少 ? [SEP]城市[SEP]人口[SEP]
通过在输入序列中加入数据表字段,BERT能够在编码过程中捕获与数据库结构相关的重要信息。[CLS]和[SEP]等特殊符号用于表征句子边界。预处理方式遵循BERT标准输入形式,为模型提供了有效的输入序列。
2.2.2 BERT编码
将处理好的序列输入到BERT模型中进行编码。在编码过程中,BERT模型会为输入序列中的每个词(包括问题和字段)生成一个固定长度的向量表示。假设BERT模型的层数为L,那么对于输入序列X=(x1,x2,…,xn),BERT模型的输出是一个包含L层的列表,记作E(l)=(e(l)1,e(l)2,…,e(l)n)(l=1,2,…,L),其中e(l)i表示第l层的第i个编码表示。选择BERT输出的最后一层,即E(L)=(e(L)1,e(L)2,…,e(L)n)作为最终的编码结果,并获得以下三个部分的表示(对应图5中BERT编码输出后的三个部分):
a)整体语义表示:使用e(L)1即[CLS]对应的向量作为整个输入序列的语义表示h[CLS]。
b)词序列表示:在经过BERT编码后的输出表示中得到词序列表示hi,用来描述问题中第i个token。
c)字段表示:本文首先将每个字段的词向量通过一个全连接层得到新的表示,然后结合 [CLS] 标记的向量计算注意力权重。对于第i列,其在输入序列中对应的词为xi1,xi2,…,xik,这些词在全连接层后的表示为coli1,coli2,…,colik,[CLS] 标记在全连接层后的表示为clsi。使用colij和 clsi计算每个词的注意力权重αij。
αij=exp(colijclsi)∑kj=1 exp(colijclsi)(3)
然后,第i列的表示通过加权求和得到。
Ci=∑kj=1 αijcolij(4)
最后,将Ci与[CLS]对应的向量相加,得到最终的字段表示Ccol。
Ccol=h[CLS]+Ci(5)
2.3 多任务网络构建
本文将结合并联和级联来构建多任务网络。在并联结构中,多个任务共享相同的特征表示层并同时进行预测输出,这意味着不同任务可以共享网络层的语义特征,如图3所示。
图3 多任务网络中的并联结构
Fig.3 Parallel structure in a multi-task network
相比于并联结构,级联结构中的各个任务则是按顺序逐一进行的,在这种结构下,一个任务的输出会直接成为下一个任务的输入,如图4所示。这种结构适用于任务之间有明确的依赖关系,后面的任务可以充分利用前面的任务学习到的特征。
本文构建的网络模型结合两种结构分别预测不同的子任务。具体的SQL组成部分包括选择列数、条件个数、条件连接符、条件值、聚合函数、条件运算符、选择列、条件列,如图5所示,分别对应图中S-NUM、W-NUM、W-CONN、W-VAL、S-AGG、W-OP、S-COL和W-COL。“⊙”表示点积运算。从图5中可以看出,S-NUM、W-NUM、W-CONN、W-VAL、S-COL和W-COL子任务采用并联结构,因为这些子任务之间互不影响,共享多任务表示层以同时进行预测;而S-AGG和W-OP的预测则采用级联结构,这两个子任务的输入利用之前预测出的S-COL和W-COL结果,而不是直接从共享表示层获得,因为SQL的选择子句中只会对选择列进行聚合操作,条件子句中每个条件列都对应着一个条件运算。相比于直接从表示层获得输入,利用选择列和条件列的结果分别预测聚合函数和条件运算符,这种级联结构可以更好地利用不同子任务间的关系,从而生成更符合语义的SQL查询语句。
其中,预测选择列数和条件个数有助于模型更好地解析自然语言查询的结构。预测选择列数可帮助更好地生成SQL查询的SELECT部分,因为自然语言查询不会明确指出需要的选择列数和条件列数;预测条件个数则用于帮助更好地生成WHERE子句,这两项预测可以增强模型对查询结构的理解。
2.4 子任务预测
将经过BERT编码后的输出表示作为后续子任务预测的输入序列。
1)选择数目与条件数目 使用输入序列第一个词的嵌入h[CLS]来预测,公式如下:
3)聚合函数和条件运算符 根据预测出的选择列与条件列,从字段嵌入Ccol中取出对应的特定列Csel和Cw,分别表示预测出的选择列与条件列,然后通过线性层将选择列与条件列嵌入映射为聚合函数和条件运算的概率分布,公式如下:
2.5 融入表字段的条件值抽取
在条件值预测部分,首先计算问题和字段的向量相似度。相比欧氏距离等其他度量方式,内积运算简单高效,可实现大规模的相似度比较,同时在此任务中可以准确评估问题与字段向量在BERT编码语义空间中的相似性。因此本文选择内积的方式,可以有效地评估问题中的词与字段在语义级别的匹配程度。公式如下:
Ssim=hiCTcol(13)
S=softmax(Ssim)(14)
其中:hi是问题中第i个token;Ccol是字段表示;Ssim是计算出问题中每个词和字段之间的相似度。当一个词的嵌入与某一列的嵌入具有相同的向量方向时,这两者的语义相似度便被认为较高。
为进一步提炼这些相似度信息,进行了归一化处理,形成概率分布S,表示每个词与各列的关联概率。这一概率分布被视为权重,与值标签的概率进行融合,产生每个词作为值标签的加权概率。再将每个词的嵌入经过线性层转换为值标签的预测,公式如下:
是线性层的权重参数;Sj表示的是第j个字段与问题词的相似度;Stags是问题中第i个token被选为条件值的概率。计算值标签得分时,会对每个词与所有列(由j索引)的相似度取最大值。总的来说,将经过BERT编码后的问题和字段向量,通过内积的方式计算问题中每个词与每个字段的相似度,计算每个词作为条件值的概率,以此来完成词与字段的匹配过程,筛选出候选条件值。
例如,对于问题“2012年厦门住宅土地成交了多少宗?”,首先用BERT对整个问题进行编码,得到问题向量X。假设问题中的词“2012年”对应的词向量为X1,字段“年份”的词向量为Y,经过X与Y的内积运算后,可以发现X1与Y的相似度比其他词向量与Y的相似度更高,这意味着“2012年”与“年份”字段在语义上最匹配,便可以将“2012年”作为条件值的候选值。
3 实验结果分析
本文使用的实验数据集是一个中文的文本到SQL的数据集TableQA[20],该数据集总共包含了约4万条文本到SQL的训练样例和约4千条测试样例,主要包含金融和通用领域的数据。在金融领域方面,数据集中的样例包含股票、基金、银行等金融领域数据;通用领域数据集的文本查询涉及到教育、医疗、房产等日常领域,具有一定的复杂性和多样性。
3.1 整体准确率对比
本文在验证集和测试集上使用了以下三个指标来进行评估:
a)逻辑形式准确率(logic form accuracy,LX):生成的SQL语句与数据集标签完全一致的比例。
LX=完全预测正确的SQL数量SQL总数量(16)
b)执行准确率(execution accuracy,EX):生成的SQL语句在数据库中执行后得到正确结果的比例。
EX=执行正确的SQL数量SQL总数量(17)
c)平均准确率(mean accuracy,MX):取逻辑形式准确率和执行准确率的平均值。
MX=LX+EX2(18)
本文对比的基线模型包括SQLNet[12]、TypeSQL[14]、SQL-ova[15]、X-SQL[16]、HydraNet[18],这些基线模型使用了不同的编码器、注意力机制、预训练模型等技术,以解决不同SQL生成场景下的难点,例如单表查询、多表查询、复杂查询等。
从表1中可以发现,SQLNet和TypeSQL模型在TableQA数据集上的表现较其他模型较差。其中,SQLNet模型没有利用数据表中的实际内容,仅依赖于查询语义;而TypeSQL模型仅使用了数据表字段的数据类型信息,没有利用字段名称等其他信息。相比之下,SQLova、X-SQL和HydraNet引入了BERT等预训练语言模型来理解查询语句语义,总体效果较好,但并没有充分利用数据表本身的字段信息,仅将表字段名称作为输入序列的一部分。
本文构建的模型在验证集上的逻辑形式准确率(LX)达到88.62%,执行准确率(EX)达到91.76%。与表现最好的基线模型HydraNet相比,在验证集上的LX和EX指标分别提高了5.97和3.12百分点。同时在测试集上,LX和EX分别达到88.23%和91.65%,相比HydraNet提升了5.72和3.02百分点。
3.2 改用模糊匹配执行SQL语句
通过观察数据集中的查询语句和对应的数据库表格数据,发现存在一些查询语句中的实际条件值与数据库中存储的数据以及标签不完全对应的情况,如表2所示。例如,问题“芒果的剧的总播放量达到了多少”中包含的条件值为“芒果”,而数据表中实际存储的是“芒果TV”,在执行SQL语句时,使用精确匹配无法匹配到结果。因此本文将“=”精确匹配替换为了“like”模糊匹配,进行文本匹配时可以匹配关键词而不要求完全等价。那么查询的条件语句部分由“where播放平台=‘芒果’”改为“ where播放平台like‘%芒果%’”,则可以匹配到“芒果TV”这条数据。实验结果如表3所示,验证集和测试集上的执行准确率(EX)分别提高了0.2和0.17百分点,使用模糊匹配实现了更好的容错性。
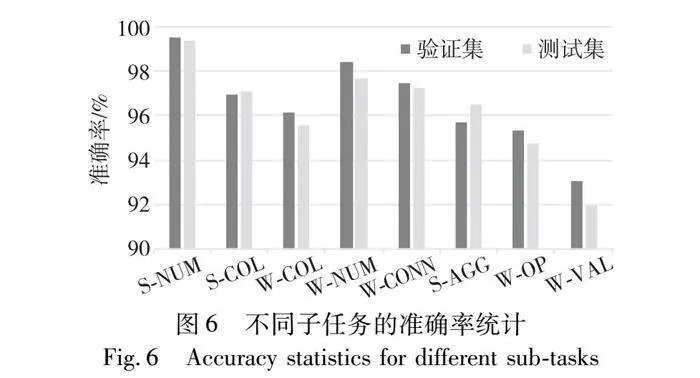
3.3 子任务准确率
为了进一步分析本文模型各模块的效果,测试了模型在各个子任务上的准确率,具体结果如表4和图6所示。从表4中可以看出,本模型在各个子任务上均取得了较高的准确率,例如S-COL、W-COL和S-AGG等子任务的准确率都达到95%以上,证明了模型可以有效地抽取自然语言查询中的关键信息。并且可以注意到,S-NUM、W-NUM和W-CONN这三个子任务的准确率相比于其他子任务偏高,都达到97%以上。这三个子任务均使用BERT输入序列中第一个词的嵌入h[CLS]来预测,这也说明经过BERT编码后的序列能很好地表示上下文语义信息。
从图6中可以直观看出,W-VAL较其他子任务准确率偏低,主要是因为本次实验数据集中存在部分问题的条件值与标签值不一致的情况。例如,3.2节实验中的问题举例,此问题对应的标签值给出的仍是“芒果TV”,与数据表中存储的数据相同。这会导致模型即使正确抽取出问题中的条件值也会被认为是错误的,因为无法与条件值标签对应。数据集中此类情况的存在,是导致条件值抽取准确率偏低的一个主要原因。
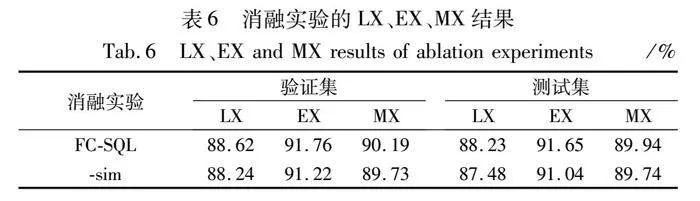
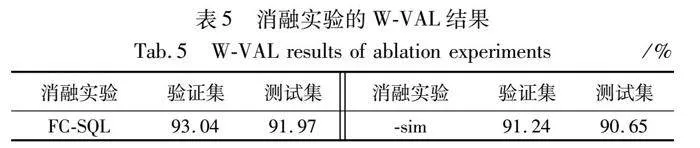
3.4 消融实验
为了验证引入问题中词与表字段相似度(以下简称sim)的有效性,本文进行了消融实验,“-sim”表示不计算词与表字段相似度。结果如表5和表6所示。在不使用sim模块的情况下,验证集上和测试集上的条件值准确率分别下降了1.8和1.32百分点;在验证集上的LX和EX分别下降了0.38和0.54百分点,测试集上的LX和EX分别下降了0.75和0.61百分点。这说明引入sim不仅提高了条件值(W-VAL)预测的准确率,也提升了整体的准确率。
4 结束语
在NL2SQL任务中,表字段信息对于生成准确的SQL查询有重要作用,现有的方法通常没有充分利用表字段的信息。针对这个问题,本文提出FC-SQL方法,主要包括两个部分:编码层和子任务预测层。在编码层,使用BERT模型对自然语言查询和数据库表字段进行合并编码,得到上下文相关的多任务表示;在子任务预测层,采用多任务学习的方式,结合多任务网络中的并联和级联结构分别预测不同的子任务。在条件值抽取模块,通过计算问题中词与表字段之间的相似度,增强了词语和数据表字段之间的匹配能力。在TableQA数据集上进行了实验评估,并与多种现有NL2SQL方法对比,结果表明本文模型有更好的表现。最后进行消融实验,验证了引入词与列相似度的有效性。
本文方法也存在一些局限性和不足之处。相似度计算的方式比较单一,未来可考虑采用更多的计算方式(如注意力机制)来进行对比分析;问题理解过程中存在的一些如语义歧义、省略等现象也会对模型的理解能力产生影响,后续工作可以尝试在数据预处理阶段改善这些问题。
参考文献:
[1]赵志超, 游进国, 何培蕾, 等. 数据库中文查询对偶学习式生成SQL语句研究[J]. 中文信息学报, 2023, 37(03): 164-172. (Zhao Zhichao, You Jinguo, He Peilei, et al. Generating SQL statement from Chinese query based on dual learning[J]. Journal of Chinese Information Processing, 2023, 37(3): 164-172.)
[2]何佳壕, 刘喜平, 舒晴, 等. 带复杂计算的金融领域自然语言查询的SQL生成[J]. 浙江大学学报:工学版, 2023, 57(2): 277-286. (He Jiahao, Liu Xiping, Shu Qing, et al. SQL generation from natural language queries with complex calculations on financial data[J]. Journal of Zhejiang University:Engineering Science, 2023, 57(2): 277-286.)
[3]曹金超, 黄滔, 陈刚, 等. 自然语言生成多表SQL查询语句技术研究[J]. 计算机科学与探索, 2020, 14(7): 1133-1141. (Cao Jinchao, Huang Tao, Chen Gang, et al. Research on technology of generating multi-table SQL query statement by natural language[J]. Journal of Frontiers of Computer Science and Technology, 2020,14(7): 1133-1141.)
[4]Iyer S, Konstas I, Cheung A, et al. Learning a neural semantic parser from user feedback[EB/OL]. (2017-04-27). https://arxiv.org/abs/1704.08760.
[5]赵猛, 陈珂, 寿黎但, 等. 基于树状模型的复杂自然语言查询转 SQL 技术研究[J]. 软件学报, 2022, 33(12): 4727-4745. (Zhao Meng, Chen Ke, Shou Lidan, et al. Converting complex natural language query to SQL based on tree representation model[J]. Journal of Software, 2022, 33(12): 4727-4745.)
[6]Devlin J, Chang Mingwei, Lee K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[EB/OL]. (2019-05-24). https://arxiv.org/abs/1810.04805.
[7]Patil R, Patwardhan M, Karande S, et al. Exploring dimensions of generalizability and few-shot transfer for text-to-SQL semantic parsing[C]//Proc of the 1st Transfer Learning for Natural Language Proces-sing Workshop. 2023: 103-114.
[8]Yih S W, Chang Mingwei, He Xiaodong, et al. Semantic parsing via staged query graph generation: question answering with knowledge base[C]//Proc of Joint Conference of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP. Stroudsburg, PA: ACL, 2015: 1321-1331.
[9]Liang Chen, Berant J, Le Q, et al. Neural symbolic machines: learning semantic parsers on freebase with weak supervision[EB/OL]. (2017-04-23). https://arxiv.org/abs/1611.00020.
[10]Herzig J, Berant J. Neural semantic parsing over multiple knowledge-bases[EB/OL]. (2017-04-24). https://arxiv.org/abs/1702.01569.
[11]Katsogiannis-Meimarakis G, Koutrika G. A deep dive into deep learning approaches for text-to-SQL systems[C]//Proc of International Conference on Management of Data. New York: ACM Press, 2021: 2846-2851.
[12]Xu Xiaojun, Liu Chang, Song D. SQLNet: generating structured queries from natural language without reinforcement learning[EB/OL]. (2017-11-13). https://arxiv.org/abs/1711.04436.
[13]Zhong V, Xiong Caiming, Socher R. Seq2SQL: generating structured queries from natural language using reinforcement learning[EB/OL]. (2017-11-09). https://arxiv.org/abs/1709.00103.
[14]Yu Tao, Li Zifan, Zhang Zilin, et al. TypeSQL: knowledge-based type-aware neural text-to-SQL generation[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2018: 588-594.
[15]Hwang W, Yim J, Park S, et al. A comprehensive exploration on WikiSQL with table-aware word contextualization[EB/OL]. (2019-11-11). https://arxiv.org/abs/1902.01069.
[16]He Pengcheng, Mao Yi, Chakrabarti K, et al. X-SQL: reinforce schema representation with context[EB/OL]. (2019-08-21). https://arxiv.org/abs/1908.08113.
[17]Liu Xiaodong, He Pengcheng, Chen Weizhu, et al. Multi-task deep neural networks for natural language understanding[C]//Proc of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 4487-4496.
[18]Lyu Qin, Chakrabarti K, Hathi S, et al. Hybrid ranking network for text-to-SQL[EB/OL].(2020-08-11).https://arxiv.org/abs/2008.04759.
[19]McCann B, Keskar N S, Xiong Caiming, et al. The natural language decathlon: multitask learning as question answering[EB/OL]. (2018-06-20). https://arxiv.org/abs/1806.08730.
[20]Sun Ningyuan, Yang Xuefeng, Liu Yunfeng. TableQA: a large-scale Chinese text-to-SQL dataset for table-aware SQL generation[EB/OL]. (2020-06-10). https://arxiv.org/abs/2006.06434.
收稿日期:2023-12-30;修回日期:2024-02-29 基金项目:国家自然科学基金资助项目(62001282)
作者简介:刘洋(1999—),男,河南信阳人,硕士研究生,主要研究方向为自然语言处理;廖薇(1982—),女(通信作者),江西赣州人,副教授,硕导,博士,主要研究方向为生物医疗与自然语言处理(liaowei54@126.com);徐震(1984—),男,山东聊城人,副教授,硕导,博士,主要研究方向为数据驱动的机器学习.
