KubeTea:面向容器云环境的轻量级多维度微服务应用调度框架
2024-11-04李宗霖何俊江李汶珊吕虓兰小龙李涛



摘 要:容器云中,应用和资源调度始终是集群管理的重点。如何在提高资源利用率的同时保证应用服务质量是目前行业积极探索的问题之一。针对该问题,提出一个面向容器云环境的轻量级多维度微服务应用调度框架。该框架设计了非侵入式的网络调用观测方法,并基于观测和监控数据定义亲和性、热点值(HV)和热路径(HP)来指导调度决策。为平衡资源利用率和应用QoS,该框架在调度的垂直方向上提出弹性余量控制机制(elastic slack controller,ESC),在水平方向上考虑了微服务亲和性;并设计了扩散导向的自动伸缩策略(diffusion-oriented autoscaling strategy,DOAS)以缓解应用出现的QoS下降。实验表明,该框架与主流的Kubernetes原生调度工具相比,在集群资源利用率方面提高21%,同时能降低23%的应用端到端时延,实现资源利用率和应用QoS的平衡。
关键词:资源调度; 容器; 微服务; 可观测性; 云原生
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)09-032-2794-06
doi:10.19734/j.issn.1001-3695.2024.01.0009
KubeTea:lightweight multi-dimensional microservice application schedulingframework for container cloud environments
Li Zonglin1, He Junjiang1, Li Wenshan1,2, Lyu Xiao1, Lan Xiaolong1, Li Tao1
(1.School of Cyber Science & Engineering, Sichuan University, Chengdu 610065, China; 2.School of Cybersecurity, Chengdu University of Information Technology, Chengdu 610225, China)
Abstract:In container clouds, application and resource scheduling has always been a key focus of cluster management. One of the active explorations in the industry is how to improve resource utilization while ensuring application service quality. This paper proposed a lightweight microservice application scheduling framework for container cloud environments. This framework designed a non-intrusive network call observation method and defined affinity, hot value(HV), and hot path(HP) based on observation and monitoring data to guide scheduling decisions. To balance resource utilization and application of QoS, the framework proposed the ESC mechanism in the vertical direction of scheduling and considered microservice affinity in the horizontal direction. Furthermore,it designed the DOAS to alleviate the QoS degradation of applications. Experimental results show that compared with the mainstream Kubernetes native scheduling tool, this framework improves resource utilization by 21% while reducing end-to-end application latency by 23%, achieving a balance between resource utilization and QoS application.
Key words:resource management; container; microservice; observability; cloud native
0 引言
将应用容器化后上云是目前互联网服务部署的主流方式[1]。同时,应用快速迭代的需求使微服务架构被广泛采用[2]。大型单体应用在划分成多个微服务模块并容器化后,有助于DevOps的实践[3, 4],进而适合部署在资源高度共享的容器云中。运维人员通常会为应用申请远超其所需的资源配额[5],一方面导致云租户成本增加[6],另一方面加剧数据中心资源利用率本就不高的情况[7]。提高数据中心资源利用率、实现降本增效,始终是云计算领域持续跟踪的问题[8],各大云厂商也在如何调度云上应用和资源进行了丰富实践[9]。
在管理大型云上集群时,提高资源利用率和应用服务质量这两个目标从技术视角看是矛盾的,因此在两者间求得平衡是需要解决的问题[10]。
在集群中,应用的调度工作包含对应用资源使用指标进行监控和观测,根据数据给出调度决策并执行两个主要步骤,资源在该流程组成的闭环中不断调配到各应用实例。观测集群和应用状态是调度决策和资源分配的基础,实现微服务的可观测性对于分析微服务之间的关系十分重要[11],可以使调度工作更加有效。实现可观测性的手段包括在应用代码中嵌入链路追踪框架或是部署Sidecar容器[12,13]。前者能够最为准确地捕获微服务间产生调用的位置,但会给开发人员带来额外的负担,对应用不透明;后者能够避免侵入到应用代码层面,但会加剧本就复杂的云原生网络,并带来更多资源开销。在现有研究工作中,调度方式按照资源分配维度可分为垂直方向和水平方向,按照执行时间点分为响应式和预测式。响应式调度手段的主要思想是根据设定的资源使用阈值分配资源,在此基础上的研究多将资源利用率和各项观测指标建模成多目标优化或是控制理论问题[14~16],在资源和负载出现变化后执行调度。而预测式的调度方案多是利用机器学习方法,提前预测未来可能变化的负载,在负载变化来临前调度[17~19]。上述方法大都需要针对特定场景建立数学模型或是使用大量数据训练机器学习模型来产生调度决策。
本文针对上述问题提出一个轻量级的调度框架,并在垂直(针对单个副本的资源配额)和水平(调整服务副本数量)两个维度设计了调度策略,贡献如下:
a)设计了一种非侵入式的网络,调用观测方法生成微服务调用图。区别于传统常用可观测性实现方式对应用不透明和增加资源开销,该方法用轻量化的手段实现微服务间调用的可观测性,并基于观测和监控的信息定义亲和性,综合指导调度决策。
b)提出了一种ESC和基于亲和性的多维度调度方法来优化资源分配。与传统仅在单一维度的调度工作相比,该方法在水平方向和垂直方向,同时把应用服务质量(quality of service,QoS)也纳入考量,以获得提升资源利用率和保证QoS的平衡,并设计了DOAS提高QoS。
c)KubeTea在Kubernetes集群中进行实现,并通过实验验证了该框架能在提高资源利用率的情况下优化应用服务质量。在资源利用率提升21%的同时,应用的端到端延迟降低23%。
1 背景与研究现状
1.1 微服务架构分析
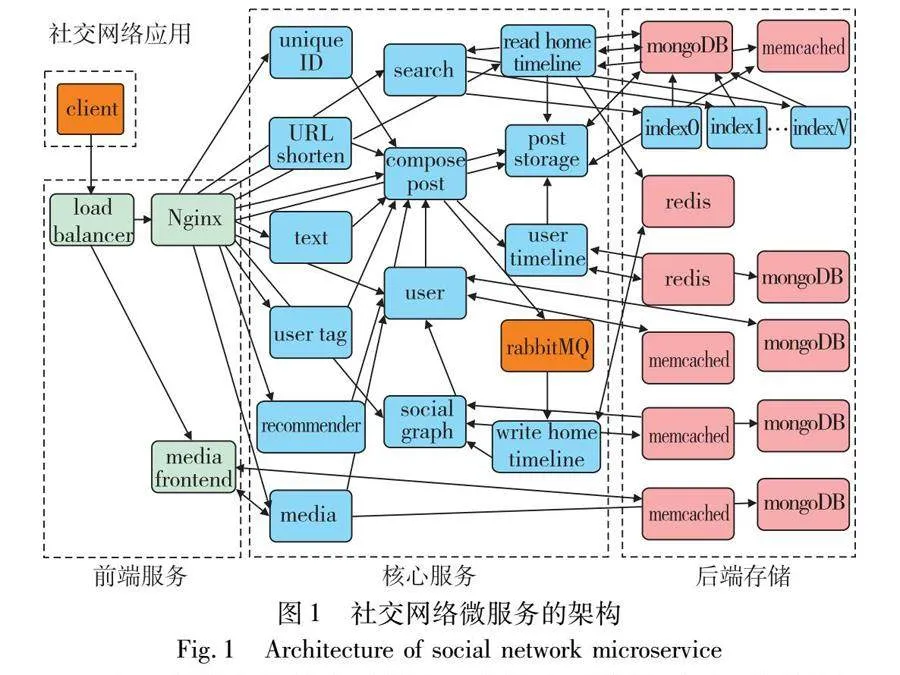
以典型的微服务架构社交网络应用[20]为例,如图1所示,该应用被划分成数十个微服务。微服务架构在解耦复杂应用的同时也带来服务治理的挑战。首先,微服务通常使用RESTful API或RPC调用进行通信,错综复杂的网络请求导致某一微服务模块的服务质量下降就会影响整个应用的端到端延迟;其次,微服务应用不同的API,对应的后端调用链路表现出一定的动态性,产生相异的调用拓扑[21],例如图1中“搜索”和“提交文章”功能对应不同的调用链路。在特定API的QoS下降时,对应调用路径上的微服务应用都需要被排查。因此,实现微服务应用的可观测性、分析应用不同的微服务间调用关系能使调度决策更为准确有效。
上述微服务的特点对调度工作提出了挑战:如何通过调度降低端到端延迟以获得更好的QoS。本文提出一个非侵入式的观测方法,通过分析微服务间调用链路优化副本的放置以提升应用的服务质量。
1.2 相关工作
从Borg[22]中积累的集群管理经验催生了如Kubernetes[23]和Autopilot[24]等云数据中心管理着数十亿的容器化应用的编排工具,为用户提供基础的容器伸缩和调度能力。就调度容器化应用来说,包含垂直方向和水平方向两个维度的自动伸缩,前者指对单一实例的副本配额进行增减,后者则体现在对某一微服务的副本数量进行增减。调度工作依赖对集群及容器实例状态的监控和观测,所得到的数据用于支撑调度决策。
1.2.1 监控和观测相关工作
调度工作需要依靠如CPU、内存、网络等指标的数据[25~28],获取这些数据的手段称为监控。对于微服务架构应用来说,还需考虑服务间调用关系[16,29],以反映微服务之间的亲和性。捕获此类网络调用关系的能力用可观测性来表述。实现微服务调用可观测性的第一种方法是使用 Zipkin、Jaeger这类链路追踪框架[12],该类框架在程序代码中发起跨服务调用的位置处埋点,在应用发起调用请求时上报数据。另一种方法是使用以Istio为代表的Sidecar技术,在Pod中注入代理容器[13],代理容器和业务容器位于同一Pod中并且共享网络命名空间,通过接管业务流量来实现可观测性。本文KubeTea设计了一种非侵入式的观测方法,既节省了开发人员的工作量又避免了Sidecar容器额外的资源消耗。
1.2.2 应用与资源调度相关工作
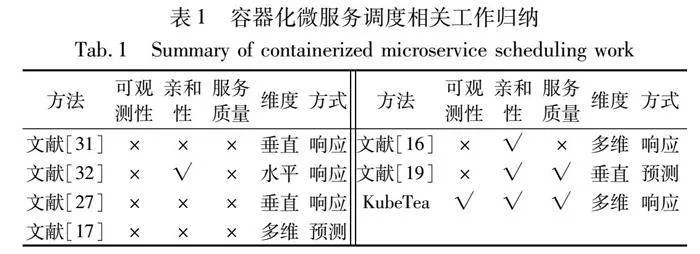
在面对动态的负载时,往往分配超出应用实际所需的资源配额以保证其稳定性,但这会导致不必要的资源浪费[30]。为改善这种情况,VPA[31]和HPA[32]作为容器云中使用最为广泛的调度框架,分别从水平和垂直两个维度根据设定的阈值自动为应用分配资源。文献[22, 33]将在线应用和离线任务进行混部以提高资源利用率,但大部分小规模数据中心没有混部条件。文献[17, 18]为优化服务质量,采用机器学习预测的方法提前为应用扩容,不过一些研究对机器学习在面对动态且无规律的负载时是否能胜任预测工作存有争议[19, 34]。文献[14, 15, 27]把调度决策抽象成多目标优化任务、Baarzi等人[16]利用控制理论中的PID算法辅助调度工作,但这类方法要对特定应用进行数学建模并涉及复杂的参数调优。本文对近年来容器化微服务应用调度的相关工作进行了整理,如表1所示。表1从是否有可观测性组件、是否考虑微服务亲和性、是否考虑服务质量、调度维度以及调度方式这五个方面进行了归纳。
与现有工作相比,本文将微服务调用可观测性的实现纳入调度框架中;基于可观测性的能力,KubeTea将微服务亲和性和服务质量纳入调度决策的参考依据;同时实现了水平方向和垂直方向上多维的调度决策能力。
2 KubeTea的设计与实现
KubeTea整体架构如图2所示,其包含三个主要模块,工作流程有以下四步:
a)监控和观测模块获取集群状态数据,包括时序监控指标和观测到的微服务间调用信息,这些数据在状态分析模块处理。
b)状态分析模块利用时序数据表征微服务对资源的使用模式,主要指导垂直方向的自动伸缩。以图结构展现网络调用数据,来分析出微服务之间的联系,支撑跨节点的水平自动伸缩。
c)基于分析结果,自动伸缩模块在垂直或水平方向进行调度工作,必要时会联合两个维度执行DOAS以缓解SLO违规。
d)自动伸缩模块实现了Kubernetes的client-go接口,将最终的决策下发执行,变更集群中应用的资源配额和副本数量。
KubeTea在上述四个步骤的循环中工作,以应对动态变化的工作负载,在提高资源利用率的同时保证应用服务质量。
2.1 监控和观测模块
该模块抓取集群中节点以及应用的状态,捕获并存储实时数据以供状态分析模块分析,数据源是Prometheus[35]和Hubble[36]。前者监控CPU和内存的使用情况,后者用于实现微服务间调用的可观测性。
为避免1.2.1节所述的代码及Pod侵入带来的弊端,本文利用Hubble提供的eBPF[37]程序接口设计并实现了非侵入式的网络调用观测方法,原理如图3所示。
同一宿主机上容器共享OS内核的特性使eBPF技术在内核空间就能观测到容器间的网络调用信息,Hubble提供了gRPC服务端接口来使用eBPF的观测能力。KubeTea在状态分析模块中实现了hubble-gRPC-client,针对性地捕获网络调用上游和下游Pod信息,并统计不同微服务间的调用频率。
2.2 状态分析模块
该模块基于收集到的监控和观测数据提出三个定义来具体反映微服务间的状态关系,用于指导调度决策。
a)亲和性(affinity)。两个微服务间调用越频繁,亲和性越高,调用频率相近时,具有双向调用特性的两个微服务亲和性高。亲和性体现在微服务之间,但由于容器运行在某个节点上,亲和性关系会传递到微服务与节点之间。
b)热点值(HV)。HV用于反映某个微服务的服务质量变化对整个应用的影响程度,本文以微服务上下游数量为依据。图1中在出现服务质量下降时,“Nginx”和“compost post”微服务对其他微服务的影响显然比“media”大。
c)热路径(HP)。HP用于表示出现SLO违规的API涉及的微服务调用链路。应用接受不同API请求时会有不同的微服务模块参与响应,为定位各API调用涉及到哪些微服务,KubeTea会逐一有间隔地向不同API发起调用,观测参与响应的微服务并与API之间建立映射。在特定API出现SLO违规时便可快速找出对应的调用链路,此时该链路就是HP。
2.3 自动伸缩模块
该模块为容器化微服务应用的调度作出决策,通过垂直维度和水平维度的自动伸缩,实现在提高资源利用率的同时优化应用的QoS。
2.3.1 垂直自动伸缩
垂直自动伸缩调整单一实例的资源配额以快速响应负载变化。KubeTea在垂直方向设计了ESC,通过为实例动态调整余量(slack)使资源利用率提高,同时面对不同负载时保证QoS。Slack的计算方法见式(1),通过资源的给定配额与一段时间内平均使用情况来表示。相应地,新配额则通过式(2)进行计算。
slack=quota-Avg(utilization)[interval]quota(1)
new_quota=avg(utilization)[interval]×(1+slack)(2)
从资源能否压缩角度来看,CPU是可压缩资源,而内存是不可压缩资源,内存不足会导致内存溢出(out of memory,OoM),应用无法正常运行。因此,将CPU和内存的slack初始值分别设置为0.1和0.2,为内存资源预留更多的余量。
在出现SLO违规时,伴随负载突增或资源紧张,需要增加slack为微服务配置更多的资源以缓解SLO违规的情况。ESC采用算法1动态调整slack及资源配额。该算法的核心思想是对出现SLO违规的应用配置更多的资源余量。由于某些情况下需要多次增加slack才能缓解SLO违规,为加快应用服务质量的恢复速度,本文使用一个负载和资源余量slack的映射表w2s来缓存历史出现过的负载情况和对应的slack数据。当应用工作负载降低并且不再出现SLO违规时,ESC会相应降低slack来提高资源利用率。其余正常情况下按照当前slack为应用配置资源即可。相较于其他响应式调度策略,ESC将服务质量纳入资源分配的参考范围内,在出现服务质量下降时适当牺牲资源利用率为应用提供更多的资源保障。
算法1 ESC弹性余量控制算法
输入:初始余量slack_init;负载到余量映射表w2s。
输出:新的资源配额new_quota。
func ESC(slack_init, w2s):
slack:=slack_init // 初始化
statusInfo:=GetObversedInfo() // 获取当前应用状态
if IsSLOViolated(statusInfo) // 如果出现SLO违规
slack += slack_init // 增加 slack
w2s.Record(statusInfo,slack) // 记录当前负载状态
// 如果没出现SLO违规且工作负载比上一次违规时的低
else if LoadLevel(state_info)<w2s.PreviousLoadLevel()
slack-=slack_init
new_quota:=Reallocation(slack)
return new_quota
2.3.2 水平自动伸缩
水平自动伸缩主要应对节点资源不足以创建新副本以及单副本申请的资源超过最大限额的情况。水平自动伸缩主要解决的问题是选择哪个节点来放置新的或清理不需要的实例副本。KubeTea使用算法2进行新副本放置节点的选择。在监控和观测模块收集到信息后,状态分析模块从观测到的微服务间调用信息,识别待调度微服务的上下游依赖微服务,对上下游微服务按照调用次数和调用是否具有双向性排序,从而衡量微服务间的亲和性。由于水平伸缩涉及到跨节点部署,该动作能够影响应用包含的微服务间通信时延。本文通过给出的affinity这一定义,将亲和性程度高的微服务调度到同一物理节点或相近物理节点以降低应用端到端时延,提高应用的服务质量。与常规在水平方向进行调度的工作相比,KubeTea将微服务间调用可观测性的实现纳入调度框架的一部分,通过水平自动伸缩变更资源配置的同时,利用affinity放置新服务实例以求降低微服务间通信的时间开销。
算法2 新实例副本部署节点选择算法
输入:待调度的微服务srv。
输出:优选的节点node。
func NodeSelect(service):
callInfo:= GetCallInfo(srv) // 获得上下游调用信息
// 从callInfo中分析上下微服务
srvList:=callInfo.UpDownStreamSrv(callInfo)
srvList.SortByCountAnd2Way() // 根据调用次数和双向性排序
for s:= range srvList
if s.NodeIsAvailable()
return s.Node
2.3.3 扩散导向的自动伸缩策略DOAS
本文提出DOAS旨在缓解应用出现的SLO违规。通过为应用增加资源配额以缓解QoS下降,有以下两种选择:
a)为构成应用的所有微服务增加资源配额。这种方式可能导致不必要的资源开销,如图1中“提交文章”功能对应的API出现SLO违规时,为“media”微服务模块增加资源并不能缓解,此时额外的资源开销是无效且浪费的。
b)为相关的微服务增加资源配额。同样考虑图1中“提交文章”功能的API出现SLO违规,对该API涉及的调用链路上的微服务增加资源配额能缓解QoS下降的情况。因此就需要定位到哪些微服务需要扩容。
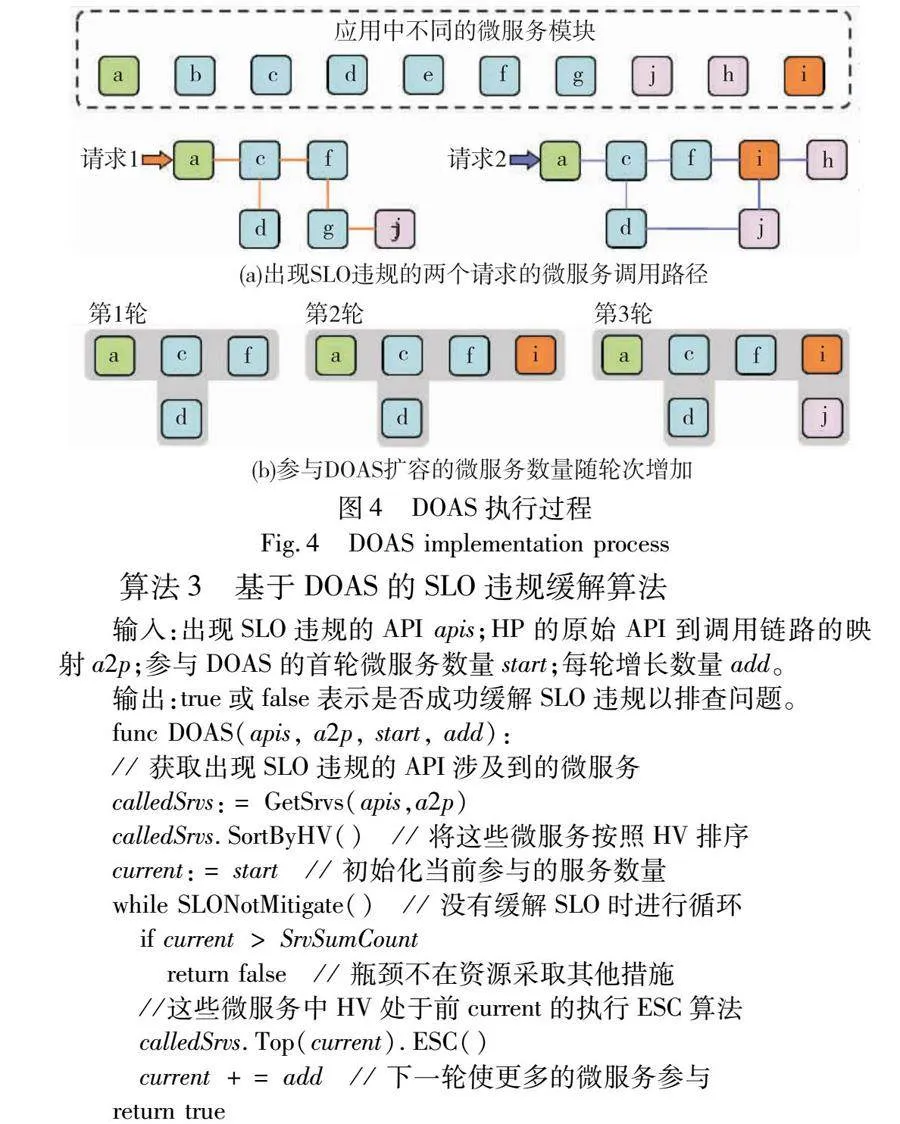
b)即本文提出的DOAS,通过扩容尽可能少的微服务来缓解SLO违规,避免非必要的资源开销。本文通过定义HP对需要扩容的微服务进行定位,结合HA,逐渐将参与扩容的微服务范围扩大。DOAS的执行逻辑如图4以及算法3所示。
算法3 基于DOAS的SLO违规缓解算法
输入:出现SLO违规的API apis;HP的原始API到调用链路的映射a2p;参与DOAS的首轮微服务数量start;每轮增长数量add。
输出:true或false表示是否成功缓解SLO违规以排查问题。
func DOAS(apis, a2p, start, add):
// 获取出现SLO违规的API涉及到的微服务
calledSrvs:= GetSrvs(apis,a2p)
calledSrvs.SortByHV() // 将这些微服务按照HV排序
current:= start // 初始化当前参与的服务数量
while SLONotMitigate() // 没有缓解SLO时进行循环
if current > SrvSumCount
return false // 瓶颈不在资源采取其他措施
//这些微服务中HV处于前current的执行ESC算法
calledSrvs.Top(current).ESC()
current += add // 下一轮使更多的微服务参与
return true
如图4(a)所示,微服务架构应用中,不同的API请求对应不同的后端微服务,当某API出现SLO违规时,可以直接将出现资源紧张的微服务范围缩小到该API对应的调用链路上。在算法3中使用a2p记录API到其调用链路涉及到的微服务之间的映射关系,该关系也是由KubeTea的监控和观测模块所捕获的。DOAS选取部分微服务执行ESC算法,为其增加资源配额,选取微服务的过程可以形象地用图4(b)这三轮阴影的扩散来表示。由于API出现的服务质量下降可能由该调用链路上的多个微服务所导致,所以DOAS的流程会执行多轮,按照HV排序来增加微服务执行ESC,直至SLO违规得到缓解。
对应到算法3,首先规定参与DOAS的首轮微服务数量start以及每轮新增加的数量add,每一轮次中参与扩容的微服务数量为current,按照HV降序方式让前current个微服务执行ESC来扩容,逐步扩散至更多的微服务直至SLO违规得到缓解。KubeTea通过这种思路用尽可能少的资源开销来缓解应用出现的服务质量下降。
3 实验评估与结果分析
本文KubeTea主要使用Go语言实现,并以自定义控制器的形式部署在Kubernetes集群中以开展实验评估。
3.1 实验设置
a)集群设置。本文实验所部署的Kubernetes集群有1个控制平面节点和5个工作节点,Kubernetes版本为1.26.3。节点均运行在虚拟机中,处理器型号为Intel Xeon CPU E5-2650 v4@2.20 GHz,控制平面节点配置为16vCore和16 GB RAM,工作节点配置为8vCore和16 GB RAM。
b)应用设置。本文使用社交网络应用[14]参与实验,如图1所示,该应用包含20余个不同的微服务模块。其典型的架构设计能反映微服务的特征,该项目还为微服务架构的研究提供了一系列的基准应用和工具。
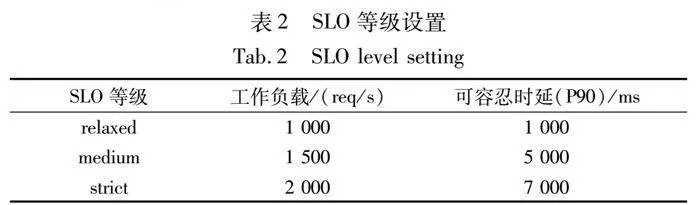
c)负载设置。实验中负载以请求每秒(req/s)表示,设置范围从0~2 500 req/s以分析KubeTea应对负载变化的表现。同时如表2所示,实验定义3个级别的SLO以验证DOAS的效果。
d)评价指标。实验使用资源利用率和端到端时延这两大指标衡量KubeTea的表现,上文提及的应用服务质量在实验中以应用端到端时延表示。资源利用率定义为资源实际使用量和资源配额的比值,例如为一个Pod分配1 GB内存,实际使用512 MB,则该Pod内存资源利用率为50%。端到端时延为发起API调用到收到响应的时间差,后文中P50、P90和P99时延代表实验中时延数据统计上的50、90和99分位数。通过这两个指标度量KubeTea在提高资源利用率和保证应用服务质量上的表现。
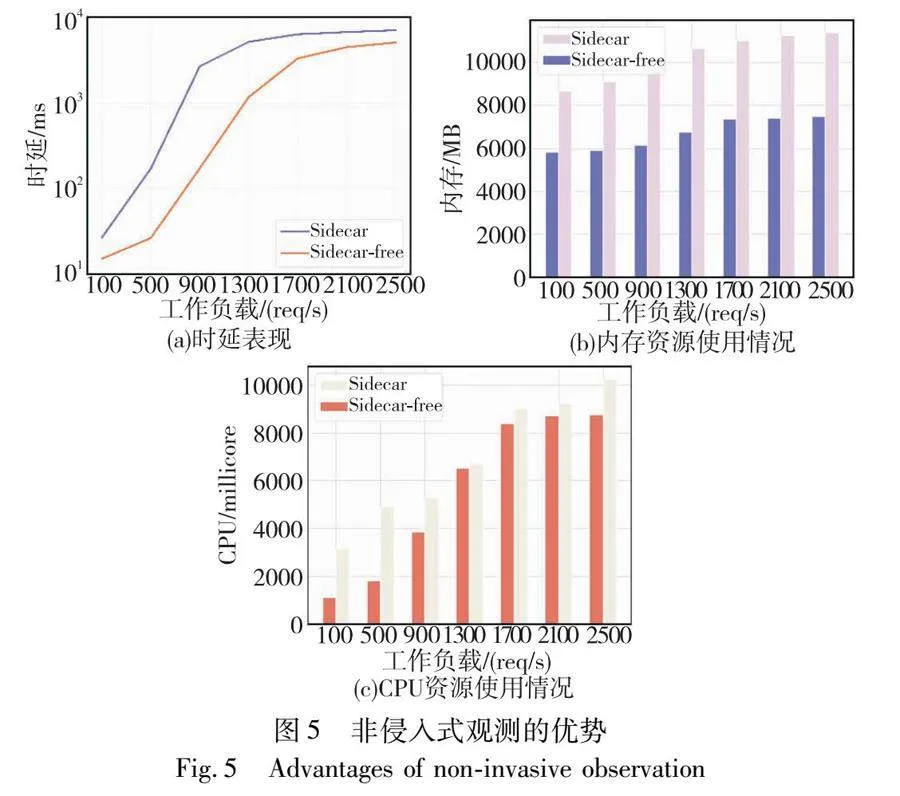
3.2 非侵入式观测带来的优势
相较于Sidecar这类Pod层面侵入的方式,本文设计的非侵入式观测资源友好且能提高应用的QoS。实验对比了Sidecar模式和本文使用的Sidecar-free模式下资源使用及应用延迟方面的表现。Sidecar模式下部署Istio实现可观测性,Sidecar-free模式下使用KubeTea来观测网络调用。如图5(a)所示,本文提出的非侵入式观测方法在端到端时延上最大有超过3 000的降低。图5(b)(c)表明在资源使用方面,与Sidecar-free模式相比,Sidecar容器会额外使用超过50%的CPU和内存资源。随着业务容器的增加,倍增的Sidecar容器数量还将带来更多的资源开销,也会增加集群网络平面复杂程度。
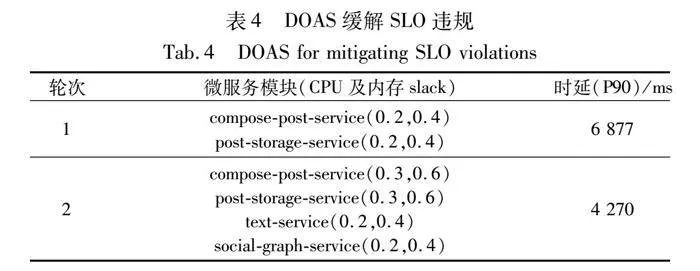
3.3 热值HV和热路径HP的表征及其对DOAS的效果
实验将“/compost-post”和“/read-home-timeline”两个API生成的对应调用链路作为HP。表3为KubeTea所观测到的调用链路中涉及到的微服务模块,并按照HV降序排列。实验过程中对DOAS的start和add参数均设置为2,使用表2中medium等级触发“/compose-post”API的SLO违规。如表4所示,经过两轮的DOAS,SLO违规情况得到缓解。
3.4 资源利用率分析
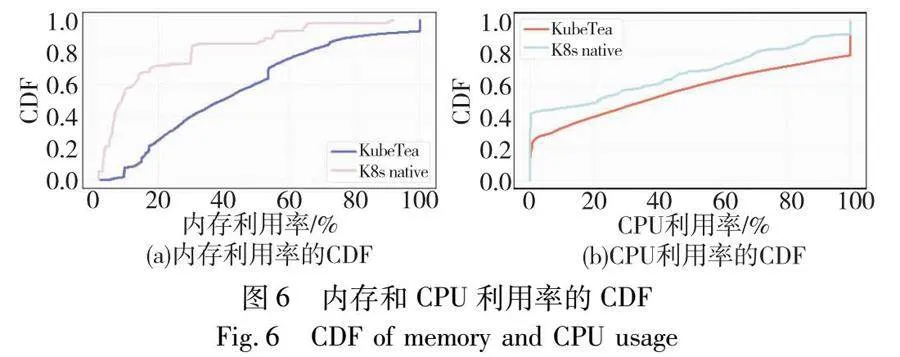
图6展示了KubeTea与Kubernetes原生调度器在内存和CPU上的资源利用情况。实验中用Kubernetes原生的VPA配置“auto”模式来提供推荐的容器资源配额。
本文ESC能动态地为容器合理配置资源,在CPU和内存资源利用率上均有提升。实验发现对于低内存需求的Pod,原生的VPA对内存推荐配额较高,导致内存资源浪费,KubeTea在内存利用率方面高出26%。ESC同样能在应用空闲时压低CPU配额,实验表明CPU的利用率有17%的提升。
3.5 端到端时延表现
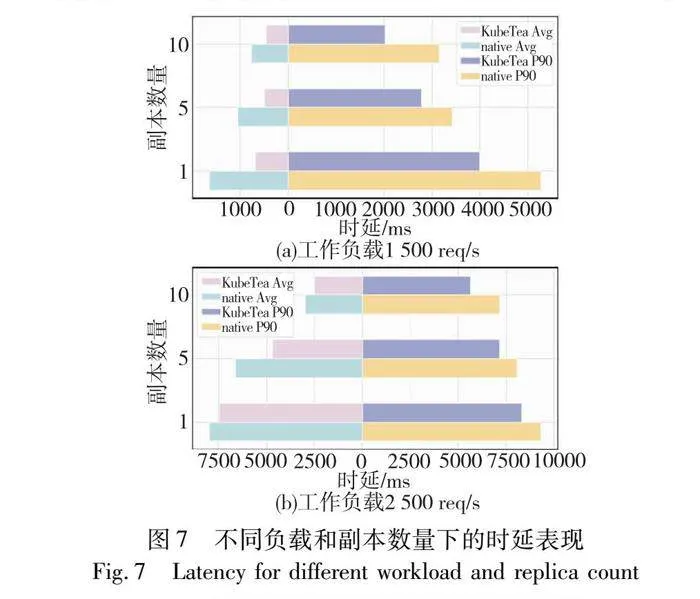
为验证KubeTea使用亲和性策略指导水平扩缩容的优势,本文将其与Kubernetes 原生HPA进行了对比实验。实验在1 500 req/s和2 500 req/s的负载下对应用进行了端到端时延测试,并设定不同的副本数量以分析服务间调用时延对应用整体QoS的影响。KubeTea在处理跨节点自动伸缩时,基于亲和性的策略将相互调用频繁的实例调度到同一节点上,进而有效地降低网络时延。如图7所示,在KubeTea的调度下,应用平均端到端时延和P90时延分别有33%和20%的下降,对P90时延的优化更加明显。
相对于KubeTea面对SLO违规的主动处理机制,原生的Kubernetes调度机制无法缓解QoS下降。本文在实验中使用了表2定义的SLO等级,并统计整个实验进行中应用的P50、P90和P99的时延,如图8所示。总体时延表现上,KubeTea调度下的应用P90时延改善了23%,P99时延改善了24%。
4 结束语
在容器云环境中部署微服务架构应用时,需要在提高集群资源利用率的同时保证应用服务质量。同时,容器云环境的复杂以及微服务架构的特点给解决这一问题带来了更大的困难。本文提出了一个面向容器化微服务的轻量级多维度调度框架KubeTea。与其他工作相比,本文将微服务的可观测性纳入框架能力中,并且在调度时考虑了微服务间亲和性和应用的服务质量。KubeTea设计了非侵入式的方式实现可观测性,为观测和分析微服务间调用链路提供了轻量的手段。在垂直自动伸缩维度上提出ESC以提高资源利用率,在水平维度基于亲和性策略调度副本以优化应用时延。此外,针对Kubernetes原生调度工具无法主动缓解服务质量下降的问题,本文定义了HV和HP指标并提出DOAS来主动缓解SLO违规。最后通过实验评估,KubeTea提升了21%的资源利用率,同时将应用P90和P99的平均时延降低23%。
参考文献:
[1]中国信息通信研究院. 云计算白皮书[EB/OL]. (2023-09-15) [2024-02-23]. http://www.caict.ac.cn/kxyj/qwfb/bps/202307/P020230725521473129120.pdf. (China Academy of Information and Communications Technology. Cloud computing white paper[EB/OL]. (2023-09-15) [2024-02-23]. http://www.caict.ac.cn/kxyj/qwfb/bps/ 202307/P020230725521473129120.pdf.)
[2]Bogner J, Zimmermann A, Wagner S. Analyzing the relevance of SOA patterns for microservice-based systems[C]//Proc of Central European Workshop on Services and Their Composition. Dresden, Germany: RWTH Aachen, 2018: 9-16.
[3]Villamizar M, Garcés O, Castro H, et al. Evaluating the monolithic and the microservice architecture pattern to deploy Web applications in the cloud[C]//Proc of 10th Computing Colombian Conference. Piscataway, NJ: IEEE Press, 2015: 583-590.
[4]Kang Hui, Le M, Tao Shu. Container and microservice driven design for cloud infrastructure devops[C]//Proc of IEEE International Conference on Cloud Engineering. Piscataway, NJ: IEEE Press, 2016: 202-211.
[5]Lu Chengzhi, Ye Kejiang, Xu Guoyao, et al. Imbalance in the cloud: an analysis on alibaba cluster trace[C]//Proc of IEEE International Conference on Big Data. Piscataway, NJ: IEEE Press, 2017: 2884-2892.
[6]Kilcioglu C, Rao J M, Kannan A, et al. Usage patterns and the economics of the public cloud[C]//Proc of the 26th International Conference on World Wide Web. [S.l.]: International World Wide Web Conferences Steering Committee, 2017: 83-91.
[7]Shan Yizhou, Huang Yutong, Chen Yilun, et al. LegoOS: a disseminated, distributed OS for hardware resource disaggregation[C]//Proc of the 13th USENIX Conference on Operating Systems Design and Implementation. Berkeley,CA: USENIX Association, 2018: 69-87.
[8]工业和信息化部. 工业和信息化部关于印发《新型数据中心发展三年行动计划 (2021—2023年)》的通知[EB/OL]. (2021-07-04) [2024-02-23]. https://www.gov.cn/zhengce/zhengceku/2021-07/14/content_5624964.htm. (Ministry of Industry and Information Technology. Ministry of Industry and Information Technology on the issuance of the “Three-Year Action Plan for the Development of New Type Data Centers (2021-2023)”notice [EB/OL]. (2021-07-04) [2024-02-23]. https://www.gov.cn/zhengce/ zhengceku/ 2021-07/14/content_5624964. htm.)
[9]Tirmazi M, Barker A, Deng Nan, et al. Borg: the next generation[C]//Proc of the 15th European Conference on Computer Systems. New York: ACM Press, 2020: 1-14.
[10]美团技术团队. 提升资源利用率与保障服务质量, 鱼与熊掌不可兼得? [EB/OL]. (2022-08-11) [2024-02-24].https://tech.meituan.com/2022/08/11/load-auto-regulator.html. (Meituan Technical Team. Are enhancing resource utilization and ensuring service quality mutually exclusive? [EB/OL].(2022-08-11)[2024-02-23].https://tech.meituan.com/2022/08/11/load-auto-regulator. html.)
[11]Li Bowen, Peng Xin, Xiang Qilin, et al. Enjoy your observability: an industrial survey of microservice tracing and analysis[J]. Empirical Software Engineering, 2022, 27: 1-28.
[12]张齐勋, 吴一凡, 杨勇, 等. 微服务系统服务依赖发现技术综述[J]. 软件学报, 2024, 35(1): 118-135. (Zhang Qixun, Wu Yifan, Yang Yong, et al. Survey on service dependency discovery technologies for microservice systems[J]. Journal of Software, 2024, 35(1): 118-135.)
[13]李海飞, 徐政钧. 服务网格中的级联故障预测方法[J]. 计算机应用与软件, 2021,38(11): 121-130. (Li Haifei, Xu Zhengjun. Cascading failure prediction method in service mesh[J]. Computer Applications and Software, 2021, 38(11): 121-130.)
[14]Narayanan D, Kazhamiaka F, Abuzaid F, et al. Solving large-scale granular resource allocation problems efficiently with pop[C]//Proc of the 28th Symposium on Operating Systems Principles. New York: ACM Press, 2021: 521-537.
[15]Narayanan D, Santhanam K, Kazhamiaka F, et al. Heterogeneity-aware cluster scheduling policies for deep learning workloads[C]//Proc of the 14th USENIX Conference on Operating Systems Design and Implementation.[S.l.]: USENIX Association, 2020: 481-498.
[16]Baarzi A F, Kesidis G. SHOWAR: right-sizing and efficient scheduling of microservices[C]//Proc of ACM Symposium on Cloud Computing. New York: ACM Press, 2021: 427-441.
[17]宋程豪, 江凌云. 基于负载预测的微服务混合自动扩展[J]. 计算机应用研究, 2022, 39(8): 2273-2277,2315. (Song Chenghao, Jiang Lingyun. Hybrid autoscaling of microservices based on workload prediction[J]. Application Research of Computers, 2022, 39(8): 2273-2277,2315.)
[18]Weng Qizhen, Xiao Wencong, Yu Yinghao, et al. MLaaS in the wild: workload analysis and scheduling in large-scale heterogeneous GPU clusters[C]//Proc of the 19th USENIX Symposium on Networked Systems Design and Implementation. [S.l.]: USENIX Association, 2022: 945-960.
[19]Zhang Yanqi, Hua Weizhe, Zhou Zhuangzhuang, et al. Sinan: ML-based and QoS-aware resource management for cloud microservices[C]//Proc of the 26th ACM International Conference on Architectu-ral Support for Programming Languages and Operating Systems. New York: ACM Press, 2021: 167-181.
[20]Gan Yu, Zhang Yanqi, Cheng Dailun, et al. An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems[C]//Proc of the 24th International Confe-rence on Architectural Support for Programming Languages and Opera-ting Systems. New York: ACM Press, 2019: 3-18.
[21]Luo Shutian, Xu Huanle, Lu Chengzhi, et al. Characterizing microservice dependency and performance: alibaba trace analysis[C]//Proc of ACM Symposium on Cloud Computing. New York: ACM Press, 2021: 412-426.
[22]Verma A, Pedrosa L, Korupolu M, et al. Large-scale cluster management at Google with Borg[C]//Proc of the 10th European Conference on Computer Systems. New York: ACM Press, 2015: 1-17.
[23]Kubernetes Authors. Kubernetes[EB/OL]. (2014-06-06) [2024-01-08]. https://kubernetes.io/.[24]Rzadca K, Findeisen P, Swiderski J, et al. Autopilot: workload autoscaling at Google[C]//Proc of the 15th European Conference on Computer Systems. New York: ACM Press, 2020: 1-16.
[25]Baarzi A F, Zhu T, Urgaonkar B. BurScale: using burstable instances for cost-effective autoscaling in the public cloud[C]//Proc of ACM Symposium on Cloud Computing. New York: ACM Press, 2019: 126-138.
[26]Delimitrou C, Kozyrakis C. Quasar: resource-efficient and QoS-aware cluster management[J]. ACM SIGARCH Computer Architecture News, 2014, 42(1): 127-144.
[27]Mostofi V M E, Krishnamurthy D, Arlitt M. Fast and efficient performance tuning of microservices [C]//Proc of the 14th International Confe-rence on Cloud Computing. Piscataway,NJ:IEEE Press, 2021: 515-520.
[28]Venkataraman S, Yang Zongheng, Franklin M, et al. Ernest: efficient performance prediction for Large-Scale advanced analytics[C]//Proc of the 13th USENIX Conference on Networked Systems Design and Implementation. Berkeley,CA: USENIX Association, 2016: 363-378.
[29]Qiu Haoran, Banerjee S S, Jha S, et al. FIRM: an intelligent fine-grained resource management framework for SLO-oriented microservices[C]//Proc of the 14th USENIX Conference on Operating Systems Design and Implementation. Berkeley,CA: USENIX Association, 2020: 805-825.
[30]Iorgulescu C, Azimi R, Kwon Y, et al. PerfIso: performance isolation for commercial latency-sensitive services[C]//Proc of USENIX Conference on Usenix Annual Technical Conference. Berkeley,CA: USENIX Association, 2018: 519-532.
[31]Kubernetes. Vertical-pod-autoscaler[EB/OL].[2024-02-25]. https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscale/.
[32]Kubernetes. Horizontal pod autoscaling[EB/OL]. [2024-02-25]. https://kubernetes. io/docs/tasks/run-application/horizontal-pod-autoscale/.
[33]Leverich J, Kozyrakis C. Reconciling high server utilization and sub-millisecond quality-of-service[C]//Proc of the 9th European Confe-rence on Computer Systems. New York: ACM Press, 2014: 1-14.
[34]Fu S, Gupta S, Mittal R, et al. On the use of ML for blackbox system performance prediction[C]//Proc of the 18th USENIX Symposium on Networked Systems Design and Implementation. Berkeley,CA: USENIX Association, 2021: 763-784.
[35]Prometheus. Prometheus-from metrics to insight[EB/OL]. [2024-01-08]. https://prometheus.io/.
[36]Cilium Authors. Hubble-network, service & security observability for Kubernetes using eBPF[EB/OL]. [2024-01-08]. https://github. com/cilium/hubble.
[37]eBPF.io. eBPF, dynamically program the kernel for efficient networking, observability, tracing, and security[EB/OL]. [2024-01-06]. https://ebpf.io/.
收稿日期:2024-01-11;修回日期:2024-03-06 基金项目:国家重点研发计划资助项目(2020YFB1805400);国家自然科学基金资助项目(62032002,62101358);四川省自然科学青年基金资助项目(2023NSFSC1395);四川大学专职博士后研发基金资助项目(2023SCU12127)
作者简介:李宗霖(1999—),男,山东临沂人,硕士研究生,主要研究方向为云计算、容器技术、云安全;何俊江(1993—),男(通信作者),四川内江人,助理研究员,硕导,博士,主要研究方向为人工免疫、云计算、网络安全、数据挖掘(hejunjiang@scu.edu.cn);李汶珊(1995—),女,四川广安人,讲师,博士研究生,主要研究方向为数据科学、机器学习、生物信息学;吕虓(1987—),男,贵州正安人,高级工程师,博士研究生,主要研究方向为大数据、网络安全、人工免疫;兰小龙(1989—),男,四川成都人,副研究员,博导,博士,主要研究方向为物理层安全、入侵检测、移动边缘计算;李涛(1965—),男,四川广安人,教授,博导,博士,主要研究方向为人工免疫、云安全、大数据安全、网络信息对抗技术.
