一种引入元路径相似性度量的材料实体检索方法
2024-11-04黄华泽胡紫璇游进国黄星瑞陶静梅易健宏




摘 要:近年来,随着材料数据的积累以及“材料基因组计划”的普及,面对大量需要处理和管理的材料数据,快速准确地检索并获取相应信息已成为一个重要问题。传统的检索方法由于仅能查询某一材料的相关信息,并且存在检索结果不全面、无法处理复杂语义关系等问题,难以获取相似程度较高的材料。为了快速、准确地找到与某种材料相似的材料,提出可度量不同节点的加权材料相似度计算模型WM-PathSim。首先,使用metapath2vec学习材料节点的嵌入表示;其次,引入TFIDF-CBOW模型学习材料路径实例的存在概率,进而计算不同元路径的权重;最后,加权求和符合条件的元路径得到最后的相似性度量,来预测不同材料之间的相似程度。在真实数据集上的结果表明,在不同的路径关系中,所提模型相比于基线方法在性能上有较大提升,其AUC和precision指标分别提升了0.37~5.02百分点和1%~7.33百分点,说明所提模型得到材料间的相似程度更加准确和有效,从而能够获得相似材料。
关键词:材料相似度;metapath2vec;TFIDF-CBOW;元路径权重
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)09-030-2781-06
doi:10.19734/j.issn.1001-3695.2023.12.0630
Material entity retrieval method introducing similarity measure based on meta-path
Huang Huaze1,Hu Zixuan1,You Jinguo1,2,Huang Xingrui1,Tao Jingmei3,Yi Jianhong3
(1.Faculty of Information Engineering & Automation,Kunming University of Science & Technology,Kunming 650500,China;2.Yunnan Key Laboratory of Artificial Intelligence,Kunming 650500,China;3.Faculty of Material Science & Engineering,Kunming University of Science & Technology,Kunming 650093,China)
Abstract:In recent years,with the accumulation of material data and the popularization of the“material genome project”,it has become an important issue to retrieve and obtain the corresponding information quickly and accurately in the face of a large amount of material data that needs to be processed and managed.However,traditional retrieval methods can only query information related to a certain material,and there are problems such as incomplete retrieval results and inability to handle complex semantic relations,making it difficult to obtain materials with a high degree of similarity.In order to find materials similar to a certain material quickly and accurately,this paper proposed a weighted material similLPrcCDPw0Ff7cewjxTdHvA==arity calculation model WM-PathSim that could measure different nodes.Firstly,it learned the embedding representation of material nodes by using metapath2vec.Secondly,it introduced the TFIDF-CBOW model to learn the existence probability of material path instances,and then calculated the weights of different meta-paths.Finally,it obtained the weighted summation of eligible meta-paths as the final similarity measure to predict the similarity between different materials.The results on the real datasets show that the proposed model has a greater performance improvement compared with the baseline method in different path relations,and its AUC and precision metrics are improved by 0.37~5.02percentage and 1~7.33points,respectively,It indicates that this model is more accurate and effective in obtaining the degree of similarity between materials,and thus enabling the acquisition of similar materials.
Key words:material similarity;metapath2vec;TFIDF-CDOW;meta-path weight
0 引言
材料科学是一个涉及多学科交叉的领域,涵盖了物理学、化学、材料工程等多个领域,它的研究对象是各种材料及其性质、结构、制备、加工、应用等方面。随着材料基因组计划以及材料基因工程[1]的推广,有大量的实验数据、文献、专利等信息需要进行处理和管理,如何快速、准确地检索和获取相关数据[2]成为了一个重要的问题。
传统的关键词匹配检索方法是将用户输入的意图与文本中的关键词进行匹配以达到检索所需目标的效果。但这种方法往往存在着一些局限性,如检索结果不全面、无法处理多义词和同义词、难以处理复杂的语义关系等,进而导致搜索结果的准确性和全面性受到限制。为了克服传统检索方法的不足以及快速、准确地获取材料知识,研究人员提出了许多知识检索技术,其中基于元路径相似度计算的知识检索是一种比较有效的方法,其利用元路径的相似性度量可以帮助用户发现材料潜在的关联性和相关性。
元路径[3]是异质信息网络中的一种重要概念。异质信息网络[4]是一种由不同类型的节点和边组成的网络,其中节点和边都具有不同的属性和类型。目前异质信息网络在材料科学相似性度量方面还没有被系统地研究,而传统的异质信息网络的相似性度量方法主要基于元路径。元路径指的是由多个不同类型的节点和边组成的路径,比如在社交网络中,一个由用户、社交关系和兴趣爱好节点组成的路径就是一个元路径。元路径的相似性度量可以用于许多任务,在挖掘丰富语义信息方面具有广泛的应用前景,其中包括分类[5]、聚类[6]、相似性搜索[7~12]。通过定义不同的元路径,可以捕捉异质信息网络中不同类型节点之间的关系。
1 相关工作
对于给定元路径p的对象间相似性问题,一些测量方法已被提出。PathCount度量的是两个实体在网络中连接路径的数量,可以用来衡量它们之间的相关性和相似性。PathSim[7]是一种基于路径的相似性度量方法,用于衡量异质图中两个相同类型实体之间的相似度。与PathCount不同,PathSim不仅考虑了元路径的路径实例数量,还考虑了实例之间的相似性。Lao等人[8]在2010年提出了一种带有路径约束的随机漫步(path-constrained random walk,PCRW)模型,用于衡量丰富的科学文献元数据所构造有向图的实体接近性。尽管可以用PCRW模型来衡量不同种类对象之间的相关性,但是PCRW具有非对称性质,使其无法作为相关性测量的工具。SimRank[9]是一种对称相似性度量算法,通过两个对象的相邻对象相似度来评估两个对象的相似度。HeteSim[10]是最近提出的基于元路径的SimRank的扩展,它能够根据所给元路径来度量任何一类节点对间的相似性。Yang等人[11]在2018年提出了一种加权异构信息网络(weighted heterogeneous information network,WHIN)及加权元路径的方法,并针对WHIN提出一种基于语义路径的相似性度量模型WgtSim。随着加权异构信息网络的出现,如何度量这种新型网络中对象之间的相似度仍有待研究。
Yuan等人[13]提出了一种基于网络架构搜索的异构信息网络元路径搜索方法,可搜索到更适合不同异构信息网络和推荐任务的元路径。SAHE[14]衡量每个元路径在其自身语义空间上的相对相似度关系,聚合相似度关系以获得节点相似度并计算嵌入。Zhang等人[15]提出了一种用于top-k相似度搜索的双通道CNN,以根据不同的元路径为节点生成结构和内容嵌入。Zhou等人[16]将元路径的实例抽象为语义单元,并考虑它们之间的交互以发现更深层次的语义信息。Zhai等人[17]提取了描述原始异构信息网络基本连接模式的异构信息原子,有助于获得主要的元路径或元结构。GoT[18]由元路径构建、元路径内融合、元路径间融合和语义注释推荐四部分组成,可充分利用结构和语义信息,有效提升了推荐准确性。
在材料领域,材料相似性度量可以应用于相似材料搜索,帮助科学家快速找到与他们研究的材料相似的某些材料,并获取相关信息。同时能够用于推荐材料,根据用户输入的材料性质或需求,检索与其相似的某些材料,并进行推荐。
基于元路径相似度计算的材料实体检索方法将材料领域的知识和信息以网络的形式进行结构化和表示,通过计算查询节点与网络中其他节点之间的元路径相似度来判断它们之间的相关性。相比于传统基于关键词的检索方法,基于元路径相似度计算的材料实体检索方法可以更全面、准确地表达查询信息,并且可以将分散在不同文献、数据库等的信息进行整合和融合,提供更为精准的查询结果。
因此,基于元路径相似度计算的材料实体检索方法具有广阔的应用前景,可以为材料科学家、工程师和决策者提供更为便捷、快速、准确的材料实体和信息,促进材料科学领域的进步和发展。
2 材料异质信息网络模型的建立
2.1 材料异质信息网络的建模
本文采用材料名、性能名、性能值、文献来源作为不同的节点类型,因此采用材料异质信息网络进行建模。利用网络中的元路径描述节点之间的复杂语义关系,既可通过不同的元路径得到不同的语义信息,也可根据元路径相似度进行材料实体相似搜索。该模型可细粒度地挖掘不同对象之间的联系,并且找到不同材料的特征表示,进而统一刻画材料特征,有助于进行相似材料的检索。
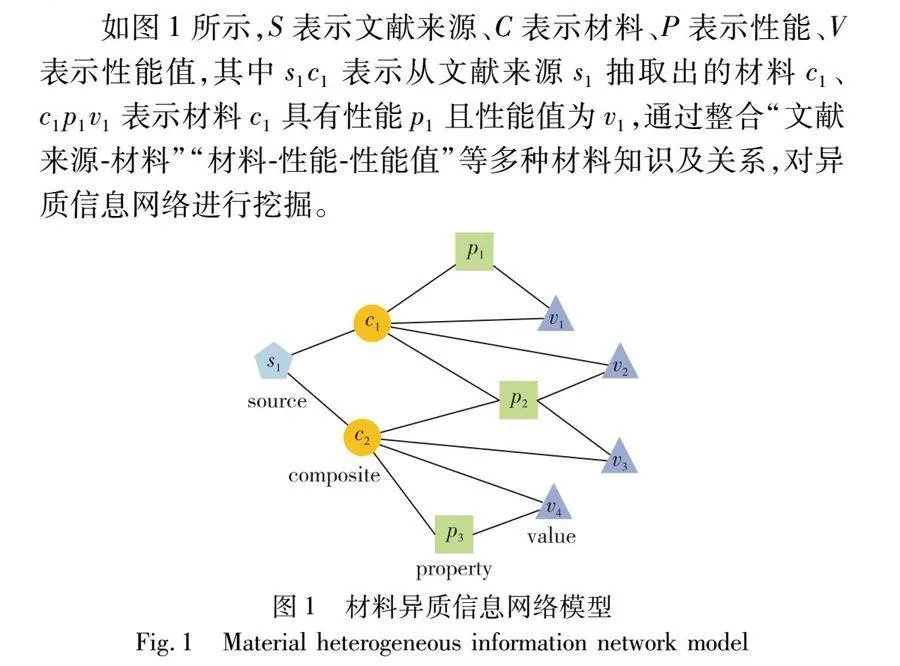
如图1所示,S表示文献来源、C表示材料、P表示性能、V表示性能值,其中s1c1表示从文献来源s1抽取出的材料c1、c1p1v1表示材料c1具有性能p1且性能值为v1,通过整合“文献来源-材料”“材料-性能-性能值”等多种材料知识及关系,对异质信息网络进行挖掘。
定义1 材料异质信息网络。用MN=(C,P,V,S,E)表示,其中:
a)C={c1,c2,…,cn}为材料节点集合。
b)P={p1,p2,…,pn}为性能节点集合。
c)V={v1,v2,…,vn}为性能值节点集合。
d)S={s1,s2,…,sn}为文献来源节点集合。
e)E={Esc∪Ecp∪Epv∪Ecv}是模型中所有边的集合。其中描述材料与文献之间的语义关系为Esc={e(s,c)|s∈S,c∈C},即该材料是从某篇文献中抽取出来的;Ecp={e(c,p)|c∈C,p∈P},其蕴涵了材料与不同性能之间的语义联系,即该材料所抽取出的性能;Epv={e(p,v)|p∈P,v∈V}描述了性能和性能值之间的语义关系,即某性能对应的性能值;为保证某材料能够对应准确的性能值,建立Ecv={e(c,v)|c∈C,v∈V}关系,表明某材料抽取出的性能值。
2.2 材料元路径的描述
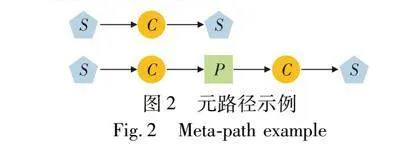
元路径定义作为一种有效利用异构信息和挖掘语义的工具,将网络模型中的两类对象连接起来,广泛应用于异构信息网络分析。元路径可以描述节点间的语义信息,下面以图2为例描述材料异质网络的元路径。
这些路径包含不同的语义,如SCS路径是指不同来源文献下的同一种材料,而SCPCS路径表示不同来源文献下拥有同一种属性(性能)的材料。
定义2 材料关系。根据材料异质信息网络模型中的节点类型,节点间具有四类关系R={R1,R2,R3,R4}:R1为面向材料文献抽取出的材料,定义为来源关系;R2为材料所包含的性能,定义为拥有关系;R3为某性能所对应的性能值,定义为性能数值关系;R4为某材料对应的性能值,定义为材料数值关系。
定义3 材料元路径。在材料异质信息网络模型MN=(C,P,V,S,E)中,材料元路径描述为
P=SR1C,CR2P,PR3V,CR4V
其中:R={R1,R2,R3,R4}为节点间的关系。
定义4 材料路径实例。对于材料元路径P,如果存在真实路径p={vi,vi+1∈S∪C∪P∪V|viRjvi+1},其中对于任意i,模型节点vi与vi+1之间关系为Rj,故路径p是材料元路径中的一条路径实例。对于满足条件p的集合称为元路径的实例集合。
材料异质信息网络模型具有的元路径如图3所示。
具体元路径语义信息如表1所示。
3 基于元路径相似性度量的材料实体检索
本文提出基于可度量任意节点的加权求和材料相似度计算模型WM-PathSim框架,如图4所示。首先,使用metapath2vec[19]学习节点的嵌入表示;其次,设计了一种TFIDF-CBOW模型学习元路径对语义表达的贡献程度,对符合条件的元路径的权重进行计算;最后,加权求和多条元路径并通过PathSim进行相似度度量,来预测不同材料之间的相似程度。接下来,将详细介绍上述每个步骤。
3.1 基于metapath2vec的路径表示
为了获得隐藏在不同网络中的不同语义特征,本文使用metapath2vec,一种异构嵌入表示学习方法,学习材料、性能、性能值节点的表示。通过考虑节点类型,获得了材料异质信息网络中的嵌入向量,以促进材料预测。
metapath2vec算法用于引导随机游走仅在特定类型节点之间的游动,以获得包含节点语义信息的嵌入向量。
为了将不同类型的节点投影到相同的特征空间中,将元路径合并到随机游走生成器中,以对节点的邻居进行采样。材料元路径P定义为
P=V1R1V2R2V3R3…VtRtVt+1…R4Vl
其描述了V1和Vl之间的潜在语义关系(假设路径的长度为l)。例如,考虑材料异质网络,元路径“材料-性能-性能值-性能-材料”表明两种材料可能对同一性能具有类似的性能值。因此,这两种材料应该在低维特征空间中保持接近,节点vt的转移概率公式如下:
p(vi+1|vit,P)=1|Nt+1(vit)|(vi+1,vit)∈E,vi+1∈Nt+1(vit)0(vi+1,vit)∈E,vi+1Nt+1(vit)0(vi+1,vit)E(1)
其中:Nt+1(vit)表示节点vit的Vt+1类型邻居。
在异构网络上通过metapath2vec遍历所有的元路径,得到所有元路径的路径实例集合,可为每个节点导出一个维数为r的低维表示。
3.2 基于TFIDF-CBOW模型的元路径权重计算
CBOW[20]模型通过词向量间的空间相似度来衡量文本语义上的相似度,为丰富了词向量对词之间关系以及词本身的意义表示,本文提出了一种TFIDF-CBOW模型以体现当前词汇在全文信息中的重要程度和词汇位置在分类能力中的作用:
Xw(i)=TFIDF×CBOW(w(i))(2)
通过遍历元路径,获取所有路径实例,并将其作为语料库输入改进模型。通过学习与训练,获得中心节点与其他节点同时存在的可能性。元路径存在的概率是通过节点出现概率来确定的。它表达了路径对语义表达式的贡献,概率将被用作路径的权重。
输入层的输入节点初始化向量由隐藏层进行累加和,得到输出层的Huffman树。Huffman树上,每个叶节点表示一个目标词,每一目标词还具有指示编码规则的通路。采用逻辑回归的方法,沿着左子树游走,对Huffman树进行1编码;沿着右子树走,Huffman树编码是0。同时各非叶节点都表示二分类问题。使用各叶节点所对应Huffman代码,并进行二分类处理,计算所述任意两节点同时发生的可能性。通过两个节点出现的概率确定元路径实例存在的可能性。最后,判断当前元路径是否存在概率。
对一条路径实例的存在概率计算:
pk=∏mi=1pl,j=∏mi=1euj∑Vj′=1euj′(3)
其中:pk表示目前这一条路径实例存在的可能性;m为元路径长度;V为材料异质网络中的节点数;pl,j为输出层中节点j和窗口内任一节点数的概率值;uj表示通过TFIDF-CBOW得到的输出。
最后,得到该元路径的存在概率。公式为
Pt=∑ni=1(Pt)in(4)
其中:n是路径实例数量;Pt表示目前这条元路径存在的可能性。
经由元路径的存在概率,计算出不同的符合条件的元路径的权重后,加权求和计算得到最后的相似性度量。元路径权重计算公式为
Wt=Pt∑kt=1Pt(5)
其中:t是目前的元路径;k代表符合条件的元路径的条数。
3.3 基于PathSim的元路径融合相似性度量
PathSim算法仅考虑了元路径中相同类型节点之间的关系,而忽略了不同类型节点之间的关联程度,同时亦未考虑同一节点间可能存在的相似语义所带来的影响。但是材料异质信息网络包含了许多不同种类的节点与边,为此提出一种可以测度任意种类节点与边之间相似性的建模方法,通过分析不同种类节点之间及与边在拓扑上的关系来描述材料信息资源。材料相似性度量计算公式如下:
s(mi,mj)=2×|{pmi→mj:pmi→mj∈P}||{pmi→mi:pmi→mi∈P}|+|{pmj→mj:pmj→mj∈P}|Tmi=Tmj|{pmi→mj:pmi→mj∈P}|+|{pmj→mi:pmj→mi∈P}||{pmi→mi:pmi→mi∈P}|+|{pmj→mj:pmj→mj∈P}|Tmi≠Tmj(6)
其中:pmi→mj表示mi和mj间的路径实例数;pmi→mi表示mi和mi间的路径实例数;pmj→mj表示mj和mj间的路径实例数;s(mi,mj)表示mi和mj的材料相似性;Tmi=Tmj表示节点类型相同;Tmi≠Tmj表示节点类型不同。
利用线性融合方法,通过式(5)(6)实现了元路径的加权求和,获得了一种基于PathSim的元路径融合相似性度量算法:
s=∑kt=1Wtst(mi,mj)(7)
该计算模型通过引入权重,细化了不同元路径对相似性度量的影响,解决PathSim算法在节点类型及元路径的局限性,从而利用网络的异构性来预测不同材料之间的相似程度。
4 实验结果与分析
4.1 数据来源
本文选取的数据集为AMiner[21]和CMC。a)AMiner数据集。包括论文、作者、引用文献和概念四种类型的节点,论文-作者、论文-引用文献和论文-概念三种类型的边。b)CMC数据集。通过使用Elsevier Scopus API方式抓取的2011—2022年有关铜基复合材料的文献作为原始数据,并采用基于规则匹配的正则化方式抽取相应的实体、关系信息,最终由抽取出的实体、关系数据构成CMC材料数据集。其包括复合材料、性能名、性能值以及文献来源四种类型的节点,四种类型的边包括复合材料-性能名、复合材料-性能值、性能名-性能值和复合材料-文献来源。数据集的统计信息如表2所示。
其中数字代表对应节点和边的数目。在AMiner数据集中,p1a1p2元路径表示论文p1和p2都由作者a1撰写,CMC数据集元路径语义信息可见表1。此外,图5是从材料异质信息网络中构建而成的最小生成树,其说明了CMC数据集中不同实体之间的相互作用。
4.2 评价指标
为了对算法进行有效性和准确性评估,在实验中,分别用AUC和precision对整体和局部的元路径相似性算法进行测度[12]。AUC指标是从全局出发度量算法精确度的指标,定义如下:
AUC=n′+0.5n″n(8)
其中:n为所有的组合比较次数;n′表示正样本的得分大于负样本的得分的组数,本文实验将随机抽取测试集边的数目设置为正样本得分,不存在的边的数目设置为负样本得分;n″代表二元组中正负样本的得分相等的组数。
m表示预测标签和实际标签相同的数量,若在前K个预测结果中有m个结果是准确的,那么准确率precision值则被定义为
precision=mK(9)
4.3 实验结果
本文使用目前常用的一些元路径相似性度量算法来比较基于PathSim的加权求和材料相似度计算方法WM-PathSim。
a)PathSim[7]。其用于计算异质信息网络中不同节点之间的相似度。它考虑了网络中节点之间的路径以及路径的长度,利用路径相似性来计算节点之间的相似度。
b)HeteSim[10]。与PathSim不同,HeteSim能够更好地处理不同类型节点之间的相似性计算问题。HeteSim使用了一个基于矩阵的方法来计算相似性,同时还考虑了节点在不同路径中的重要性以及路径之间的权重。
c)AvgSim[22]。其为一种基于平均相似度的相似性计算方法。它通过正向随机游走和反向随机游走在两个节点之上的概率取算术平均值。
d)WgtSim[11]。其为一种基于加权路径相似性的节点相似度计算方法。通过比较两个用户对项目的偏好,使其能够准确地度量属于同一类型的对象的相似度。
为了说明基于PathSim的加权元路径相似度计算方法能够实现任何节点的相似性度量,实验分别在对称元路径和非对称元路径上进行。
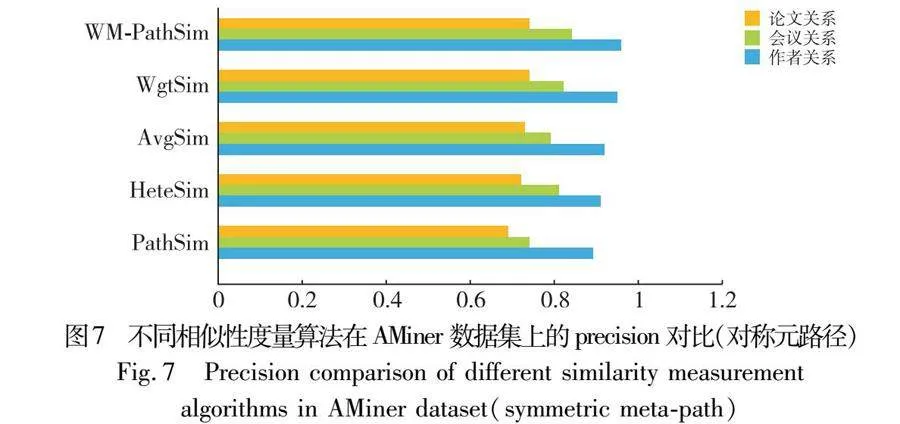
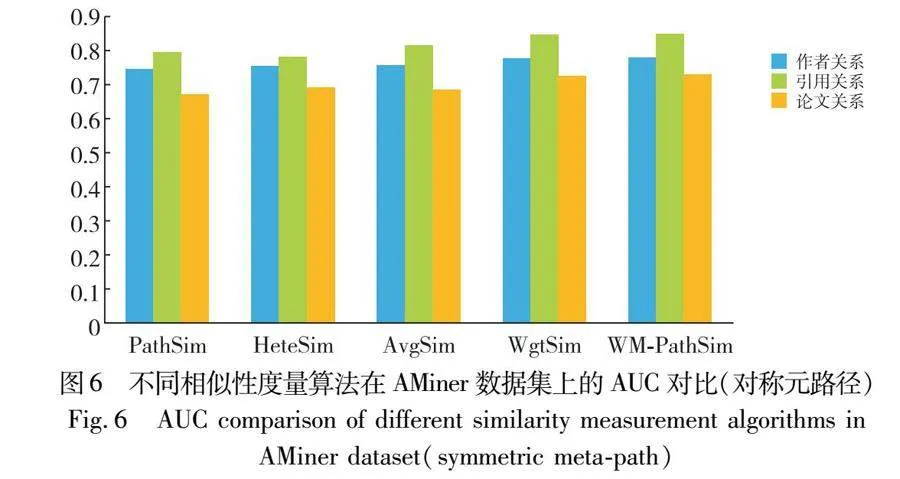
首先利用不同路径关系,在对称元路径中分别对算法准确率进行了验证。对于AMiner数据集,作者关系的元路径是APLPA,引用关系的是LPAPL,论文关系的元路径采用PAPLPAP。就全局相似度的测度结果而言,通过与PathSim、HeteSim、AvgSim、WgtSim算法作比较,如图6、7所示,该研究模型AUC值分别平均增加5.02百分点、4.3百分点、3.34百分点、0.37百分点;从局部精度的计算结果来看,本文模型精度值分别比其他算法高7.33百分点、3.33百分点、3.33百分点、1百分点,说明本文算法对相似度的测量具有较高的精度,测量效果较好,结果如图6、7所示。
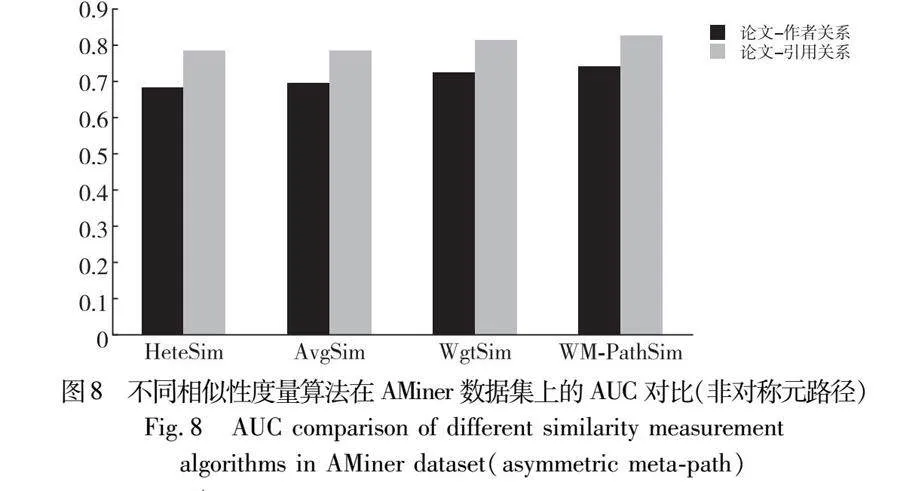
然后验证非对称元路径相似性度量准确率。由于PathSim只能度量同种类型节点,所以后面的实验是通过HeteSim、AvgSim、WgtSim算法与本文WM-PathSim算法作对比,如图8、9。针对AMiner数据集,论文-作者关系的元路径为APLPCP,论文-引用关系的元路径为APCPL。对比实验结果发现,WM-PathSim比其他三种算法具有更高的性能,AUC分别提升了4.99百分点、4.48百分点和1.47百分点;对比precision值,WM-PathSim较HeteSim有2百分点的提升,较AvgSim来说降低了1百分点的准确率,与WgtSim相比并无改进。这是因为precision通常只从局部考虑算法的准确率,而AUC是对算法准确性的总体测度。因此,WM-PathSim对非对称元路径具有较好的整体度量结果,实验结果如图8、9所示。
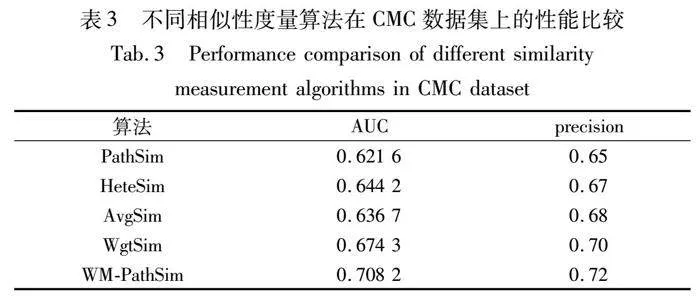
通过在不同路径关系下对模型的性能进行对比分析后,将基准模型与WM-PathSim应用于CMC数据集进行AUC和precision对比,结果如表3所示。
可以看出,相比于基准模型,WM-PathSim准确度有所提升,其AUC和precision值分别提高6.4百分点和4.5百分点,说明该模型适用于材料数据集,对之后相似材料查询有所帮助。
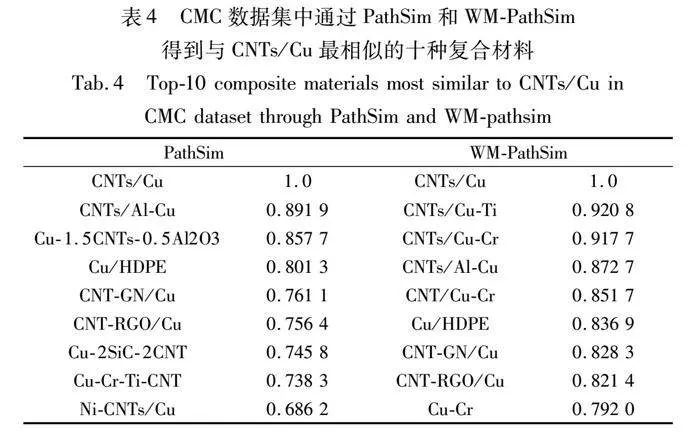
分别使用PathSim和WM-PathSim计算与某种复合材料相似的复合材料top-10,以CNTs/Cu为例,表4展示在CMC数据集中与CNTs/Cu最为相似的前十种复合材料。如表4所示,通过WM-PathSim计算得出的材料相似度略高于由PathSim计算得出的结果,说明本文模型的有效性。对于结果的分析比较,在下节案例分析中展开。
4.4 材料实体检索实验结果分析
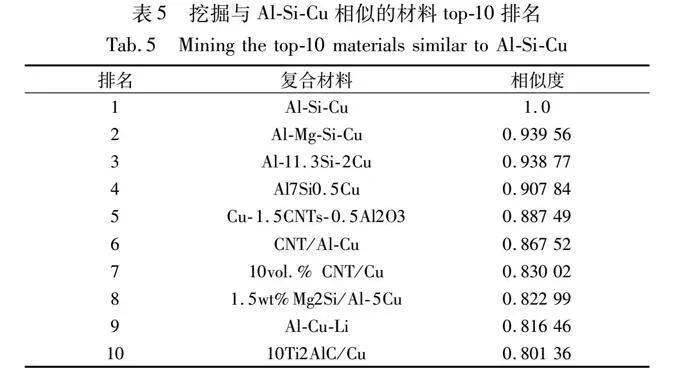
本文以Al-Si-Cu为例,使用WM-PathSim计算得到的与Al-Si-Cu相似的材料top-10排名如表5所示。
在抽取出的材料数据中,Al-Si-Cu的屈服强度和拉伸强度在100~400 MPa,硬度在85~95HV。通过WM-PathSim进行相似材料检索时,能够找到与Al-Si-Cu最为接近的元素,并进行相似度排序。其中排名第一的Al-Si-Cu与自身最为相似,其相似度值为1。根据实验结果,进一步对比排名第二至第十的材料机械性能。Al-Mg-Si-Cu的屈服强度在130~200 MPa,硬度为59.5 HV;Al-11.3Si-2Cu的屈服强度和拉伸强度在125~160 MPa;Al7Si0.5Cu的屈服强度为261 MPa,拉伸强度为282 MPa;Cu-1.5CNTs-0.5Al2O3的屈服强度和拉伸强度在324~345 MPa;CNT/Al-Cu的屈服强度和拉伸强度在110~384 MPa;10vol.% CNT/Cu的拉伸强度区间为68~296 MPa,硬度在68~135 HV之间;1.5wt%Mg2Si/Al-5Cu的拉伸强度为315 MPa;Al-Cu-Li的屈服强度和拉伸强度分别为125~632 MPa、253~632 MPa;10Ti2AlC/Cu的拉伸强度为103 MPa。
可以看出,这九种铜基复合材料的屈服强度、拉伸强度以及硬度均与Al-Si-Cu相似,但也存在一定的误差,例如Al-Mg-Si-Cu的硬度为59.5 HV,10Ti2AlC/Cu的拉伸强度为103 MPa,都与上述Al-Si-Cu的机械性能对应的性能值范围不符。这种误差存在的原因主要是本文抓取的文献数据仅来源于通过Elsevier Scopus API的网页抓取,对于如今已经构建完成的材料数据库以及国内外材料科学网站中的结构化、半结构化数据研究薄弱,故构建的CMC数据集数据量不大,致使通过元路径进行材料相似度检索的结果存在偏颇。虽然如此,但通过WM-PathSim抽取出的结果基本合乎实际发展规律,并未得到与Al-Si-Cu不相似的复合材料,并且结果与PathSim相比有了进一步的提升。同时,对于有些复合材料缺失性能数据,如Al7Si0.5Cu、Cu-1.5CNTs-0.5Al2O3等没有有关硬度的性能值,由于这些复合材料与Al-Si-Cu相似,所以可以判断它们的硬度在85~95 HV。
总的来说,本文算法能够发现与某种材料相似的一些材料,可以帮助研究人员快速了解材料的性质、特点和应用范围,为材料的选择、设计和改进提供依据。
5 结束语
针对材料异质信息网络的元路径进行数据分析和挖掘,提出了一种基于PathSim的可度量任意节点的加权材料相似度计算模型WM-PathSim,能够对材料进行相似性比较。首先,需要将材料数据表示为异质信息网络。通过实体关系抽取得到的材料、性能、性能值以及文献来源可以看做图中的节点,而它们之间的关系可以看做图中的边。接下来,定义一组元路径作为图的特征。元路径是一种从一个节点到另一个节点的序列,其中每个节点都具有特定的标签。例如,可以定义元路径材料-性能-性能值表示某一材料所具备性能的性能值。然后,利用metapath2vec获得异质信息网络的路径实例,并通过TFIDF-CBOW计算符合条件的元路径的权重。最后,可以将多条元路径加权求和的相似度作为材料实体检索的相似性度量。对于给定的查询材料,可以计算它与网络中所有材料之间的相似度,并返回相似度最高的材料作为检索结果。实验结果表明,该方法比其他元路径相似性度量算法更加准确和有效。在接下来的研究工作当中,将探索更加精准的相似性度量方法,包括异质信息网络表示学习方法、结合自然语言处理技术的材料实体检索等,以及利用已有的材料相似性计算方法指导材料的预测和设计。
参考文献:
[1]宿彦京,付华栋,白洋,等.中国材料基因工程研究进展[J].金属学报,2020,56(10):1313-1323.(Su Yanjing,Fu Huadong,Bai Yang,et al.Progress in materials genome engineering in China[J].Acta Metallurgica Sinica,2020,56(10):1313-1323.)
[2]Haug A.Acquiring materials knowledge in design education[J].International Journal of Technology and Design Education,2019,29(2):405-420.
[3]石川,王睿嘉,王啸.异质信息网络分析与应用综述[J].软件学报,2022,33(2):598-621.(Shi Chuan,Wang Ruijia,Wang Xiao.Survey on heterogeneous information networks analysis and application[J].Journal of Software,2022,33(2):598-621.)
[4]Sun Yizhou,Han Jiawei.Mining heterogeneous information networks:a structural analysis approach[J].ACM SIGKDD Explorations Newsletter,2013,14(2):20-28.
[5]Ming Ji,Han Jiawei,Danilevsky M.Ranking-based classification of heterogeneous information networks[C]//Proc of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2011:1298-1306.
[6]Sun Yizhou,Norick B,Han Jiawei,et al.Pathselclus:integrating meta-path selection with user-guided object clustering in heterogeneous information networks[J].ACM Trans on Knowledge Discovery from Data,2013,7(3):1-23.
[7]Sun Yizhou,Han Jiawei,Yan Xiefeng,et al.PathSim:meta path-based top-k similarity search in heterogeneous information networks[J].Proceedings of the VLDB Endowment,2011,4(11):992-1003.
[8]Lao Ni,Cohen W W.Fast query execution for retrieval models based on path-constrained random walks[C]//Proc of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2010:881-888.
[9]Glen J,Widom J.SimRank:a measure of structural-context similarity[C]//Proc of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2002:538-543.
[10]Shi Chuan,Kong Xiangnan,Huang Yue,et al.HeteSim:a general framework for relevance measure in heterogeneous networks[J].IEEE Trans on Knowledge and Data Engineering,2014,26(10):2479-2492.
[11]Yang Chunxue,Zhao Chenfei,Wang Hengliang,et al.A semantic path-based similarity measure for weighted heterogeneous information networks[C]//Proc of International Conference on Knowledge Science,Engineering and Management.Cham:Springer,2018:311-323.
[12]赵宇红,薛维佳.基于元路径加权融合的异构网络相似性度量[J].计算机工程与设计,2021,42(2):309-315.(Zhao Yuhong,Xue Weijia.Similarity measurement of heterogeneous networks based on meta-path-weighted fusion[J].Computer Engineering and Design,2021,42(2):309-315.)
[13]Yuan Peisen,Sun Yi,Wang Hengliang.Heterogeneous information network-based recommendation with metapath search and memory network architecture search[J].Mathematics,2022,10(16):2895.
[14]Zheng Susu,Guan Donghai,Yuan Weiwei.Semantic-aware heterogeneous information network embedding with incompatible meta-paths[J].World Wide Web,2022,25(1):1-21.
[15]Zhang Yun,Yu Minghe,Zhang Tiancheng,et al.Semantic enhanced top-k similarity search on weighted HIN[J].Neural Computing and Applications,2022,34(19):16911-16927.
[16]Zhou Wei,Huang Hong,Shi Ruize,et al.Temporal heterogeneous information network embedding via semantic evolution[J].IEEE Trans on Knowledge and Data Engineering,2023,35(12):13031-13042.
[17]Zhai Xuemeng,Tang Zhiwei,Liu Zhiwei,et al.Sparse representation for heterogeneous information networks[J].Neurocomputing,2023,525:111-122.
[18]Xu Yueshen,Zhao Xinyu,Jiang Zhiping,et al.Intelligent semantic annotation for mobile services for IoT computing from heterogeneous data[J].Mobile Networks and Applications,2023,28(1):348-358.
[19]Dong Yuxiao,Chawla N V,Swami A.Metapath2vec:scalable representation learning for heterogeneous networks[C]//Proc of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2017:135-144.
[20]Mikolov T,Sutskever I,Chen Kai,et al.Distributed representations of words and phrases and their compositionality[C]//Proc of the 26th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2013:3111-3119.
[21]Tang Jie.AMiner:toward understanding big scholar data[C]//Proc of the 9th ACM International Conference on Web Search and Data Mi-ning.New York:ACM Press,2016:467-467.
[22]孟晓峰.基于异质信息网络的相似性度量研究[D].北京:北京邮电大学,2015.(Meng Xiaofeng.Research on relevance measure in heterogeneous information networks[D].Beijing:Beijing University of Posts and Telecommunications,2015.)
收稿日期:2023-12-08
修回日期:2024-03-11
基金项目:国家自然科学基金资助项目(62062046)
作者简介:黄华泽(1999—),男(壮族),云南文山人,硕士研究生,CCF会员,主要研究方向为数据挖掘;胡紫璇(1998—),女,新疆克拉玛依人,硕士,主要研究方向为知识图谱;游进国(1977—),男(通信作者),湖南新化人,教授,硕导,博士,主要研究方向为大数据分析、数据仓库与数据库等(jgyou@126.com);黄星瑞(1996—),男,云南文山人,硕士,主要研究方向为数据挖掘、机器学习;陶静梅(1979—),女,云南昆明人,教授,博导,博士,主要研究方向为新型金属基复合材料、纳米结构材料;易健宏(1965—),男,湖南株洲人,教授,博导,博士,主要研究方向为粉末冶金材料与技术、稀贵金属材料和纳米材料与技术.
