基于鱼群涌现行为启发的集群机器人硬注意力强化模型
2024-11-04刘磊葛振业林杰陶宇孙俊杰





摘 要:生物集群运动模型能使集群机器人涌现秩序,但是所形成的机器人自然集群秩序难以有效地被人工控制,为此提出鱼群硬注意力模型来解析实验鱼群数据中的交互行为。该模型通过编码器网络、图注意力网络、信息聚合网络、预解码网络以及最终解码网络等结构来获取焦点单体的重要邻居;再利用深度确定性策略梯度技术设计轨道强化网络与安全强化网络,以实现集群的人工控制。多智能体仿真与集群机器人实验结果表明:所提方法能够实现集群的人工轨道、安全控制,重要邻居信息为解决集群运动的强化学习难题提供了新思路,所提控制模型在无人机群空中协作、智慧农机集群作业、物流仓储多体搬运等领域具有较大的应用潜力。
关键词:自然秩序人工控制;集群硬注意力机制;多智能体运动强化学习;集群机器人任务控制
中图分类号:TP242.6 文献标志码:A 文章编号:1001-3695(2024)09-024-2737-08
doi:10.19734/j.issn.1001-3695.2023.12.0625
Hard attention reinforcement model for swarm robotics
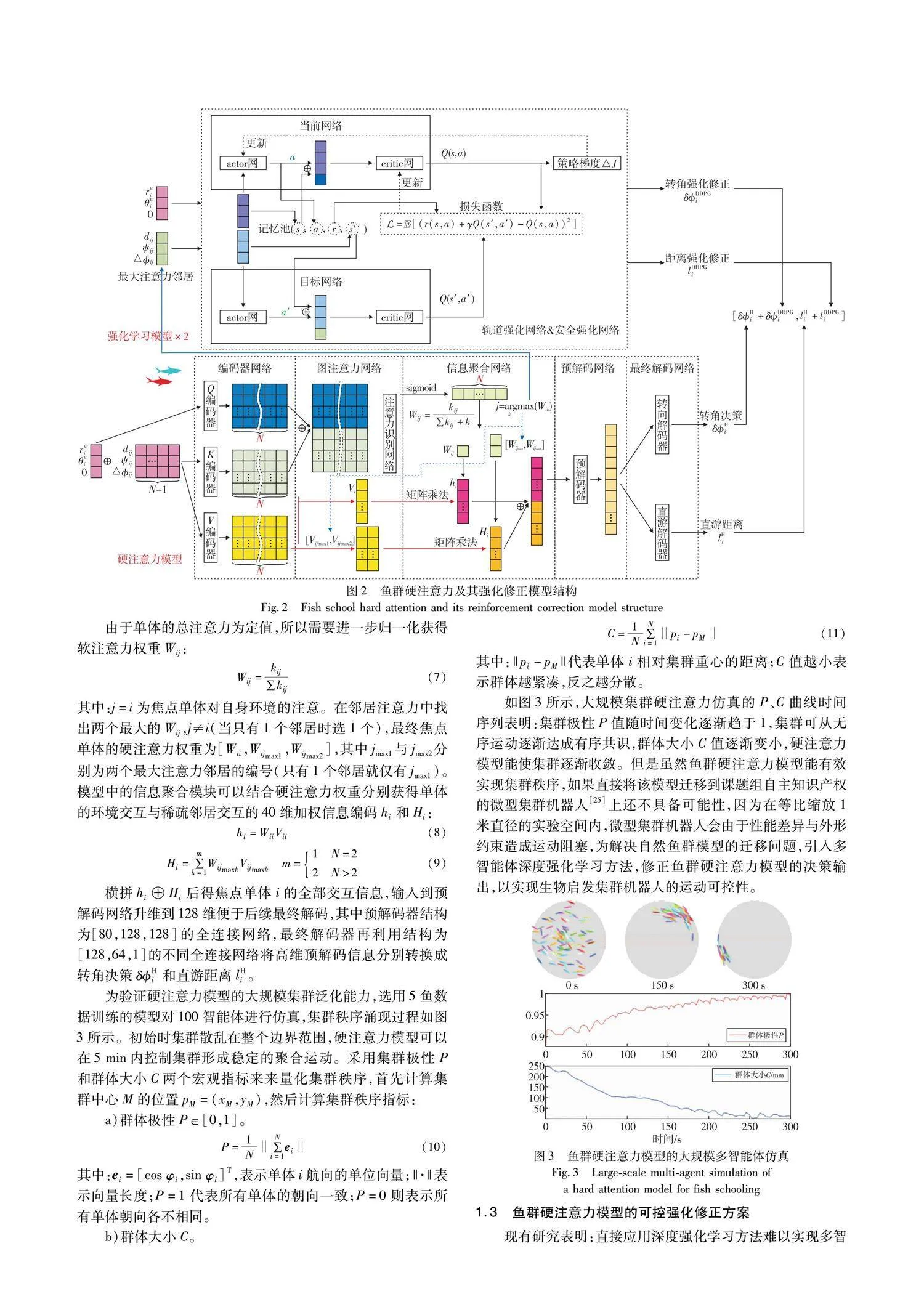
inspired by fish school emergence behavior
Liu Leia,b,Ge Zhenyeb,Lin Jiea,Tao Yub,Sun Junjiea
(a.School of Management,b.School of Optoelectronics,University of Shanghai for Science & Technology,Shanghai 200093,China)
Abstract:The biological swarm motion model enables the emergence of order in robot collectives,but controlling the natural swarm order formed by robots is challenging.To address this issue,this paper proposed the fish school hard attention model to analyze interaction behaviors in experimental fish school data.This model utilized structures such as an encoder network,graph attention network,information aggregation network,pre-decoding network and a final decoding network to capture crucial information about the focal individual’s important neighbors.Subsequently,it emploied deep deterministic policy gradient techniques to design trajectory reinforcement networks and safety reinforcement networks to achieve artificial control of the swarm.Results from multi-agent simulations and experiments with swarm robotics demonstrate that the proposed method can realize artificial trajectory and safety control of collectives.The utilization of high-attention neighborhood information for resolving reinforcement learning challenges in collective motion provides a novel approach.The proposed control model exhibits substantial potential applications in areas such as collaborative aerial operations of drone swarms,intelligent agricultural machinery operations,and multi-robot material handling in logistics and warehousing.
Key words:natural order artificial control;collective hard attention mechanism;multi-agents motion reinforcement learning;swarm robotics task control
0 引言
自然生态系统存在大量的集群行为,如蚁群、鸟群、鱼群、兽群等,这些群落通过个体之间的社会性交互来协同运动,从而能在复杂环境中涌现宏观结构与功能来适应环境[1]。这种自组织生成的秩序对种群生存、繁衍至关重要,同时也能启发人工集群的分布式控制[2],因此吸引了大量学者从事该领域的探索。在过去的数十年中,多种数学、物理、经验模型被提出来用于解释、模拟生物集群行为,从Reynolds[3]提出的Boids模型开始,先后出现了Vicsek[4]、Couzin[5]、Calovi模型[6]等经典集群理论。上述研究总结了集群行为的基本原则:即单体通过社会性交互可以涌现集群秩序,并给出了信息交互的具体数学表达。交互模型为集群机器人的分布式控制提供了有力支撑,借鉴生物模型的集群机器人行为具有较高的运动鲁棒性[7],以及较强的规模适应性[8],从而使生物启发的多智能体分布式控制成为助推人工集群应用的重要方法,为集群机器人在工农生产、军事辅助、交通智能、生态探索等领域发展提供支持。
集群机器人研究始于20世纪90年代初,并在接下来的十年中逐渐崭露头角。2004年Dorigo等人[9]成功实现了多达20台的自装配机器人的协同任务,如定向移动、集群避障、合作搬运等;哈佛大学自组织研究实验室设计的Kilobots机器人可在微型尺度下移动、通信、交互形成宏观图样[10]。然而,面对复杂群内环境,传统自控方法已难以应对单体机器人的自组织控制[11]。
当前人工智能飞速发展,使得人工智能技术应用于集群秩序涌现逐渐成为可能:如机器学习控制无人机群[12],强化学习应用于多智能体[13]和真实机器人的路径规划[14]以及协同计算[15],神经网络控制集群机器人合作搬运[16];深度学习训练多智能体通信[17]。在集群机器人控制方面,文献[18]报道微型无人机集群采用最优控制可以达到较好的集群运动效果,但优化控制需要同时获取较多单体的信息进行集中计算,算力要求较高,并且控制不具备集群的鲁棒灵活性,利用多智能体深度强化学习是实现集群机器人控制的重要方法,如无人艇集群可以在海上围捕逃逸目标[19],但是该研究的无人艇群运动空间较大,不会产生集群阻塞的情况。文献[20]表明单独使用多智能体强化学习,难以在紧凑空间实现机器人的集群运动,为此首次使用了最大视觉DNN集群强化修正生物模型的方法,获得了较好的集群运动效果,但该研究所使用的最大视觉DNN模型具有较强的主观性,其与鱼群实验数据的匹配程度不高。研究人员利用鱼群实验数据进行深度学习、强化学习来对集群系统进行控制研究[20~22],研究结果表明:生物模型难以直接控制紧凑空间的集群机器人[23],需要借助强化学习才能实现模型迁移,但是所提最大视觉邻居方法[20,23]具有较强的主观性,同时不同目标修正下的生物模型表现还不明确。综合上述分析:利用生物集群模型的涌现特性来实现集群机器人的协同运动有助于整体行为的鲁棒灵活性,因此本文拟利用硬注意力机制来建立生物集群模型,期望获取关键邻居信息,并在此基础上进行强化学习以规避单体强化数据池过大的难题,同时提升关键邻居挑选的客观性,所提鱼群硬注意力模型及其强化修正方法有望为集群机器人的人工协同控制提供新的思路。
为解决生物模型迁移控制难题,拟设计用5条鱼的运动数据训练硬注意力模型,并嵌入到多智能体强化学习框架中,以实现集群机器人的宏观目标可控涌现,从而提升生物模型的宏观任务性能。本文贡献在于:a)利用硬注意力机制提升生物模型的稀疏信息交互客观性;b)利用集群强化学习提升生物模型的任务可控性;c)分析不同人工强化目标对生物模型的匹配程度,为探索自由生物模型启发人工集群系统调控的可能性,进而推动人工复杂系统的任务应用提供支持。
1 鱼群硬注意力模型及其强化修正方法
红鼻剪刀鱼群游能力出色,研究发现该鱼种具有间歇性游动特性,即单体会突然改变方向并同时提升速度,接着直线减速滑行[6],这种运动模式有利于将鱼群游动轨迹分解成一系列的折线段,适于使用数据驱动建模技术。选用文献[20~23]的5鱼运动数据,该数据采集自实验边界半径为25 cm的塑料圆环内的5鱼自由运动,实验设施顶部安装有摄像机录制鱼群运动,并使用idTracker软件[24]对鱼群录像进行识别、追踪,再提取鱼群所有单体的位姿数据,经对称、滤波、筛选处理[23]用于训练深度硬注意力模型,为将该模型迁移控制集群机器人,需要设计专门的多智能体强化修正方法。
2 硬注意力强化模型的训练与仿真
使用机器人实体在小空间中直接进行强化训练不具备可行性,因为模型不成熟极易造成阻塞,自动复位系统并重新更新DDPG记忆池存在困难,需要外界机械臂辅助疏散才有可能实现机器人实体集群强化训练,为此使用仿真环境来对所设计的强化模型进行训练。
2.1 轨道与安全强化网络的奖励函数设计
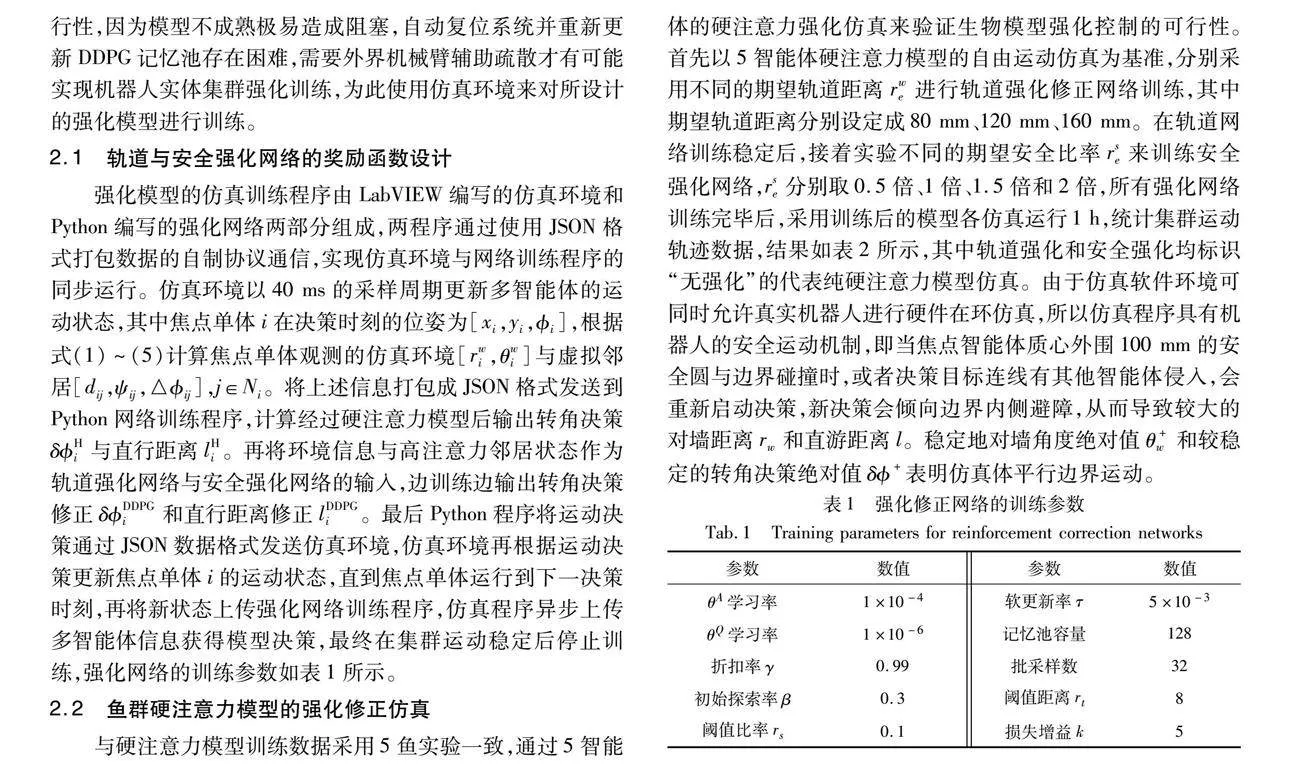
强化模型的仿真训练程序由LabVIEW编写的仿真环境和Python编写的强化网络两部分组成,两程序通过使用JSON格式打包数据的自制协议通信,实现仿真环境与网络训练程序的同步运行。仿真环境以40 ms的采样周期更新多智能体的运动状态,其中焦点单体i在决策时刻的位姿为[xi,yi,i],根据式(1)~(5)计算焦点单体观测的仿真环境[rwi,θwi]与虚拟邻居[dij,ψij,△ij],j∈Ni。将上述信息打包成JSON格式发送到Python网络训练程序,计算经过硬注意力模型后输出转角决策δHi与直行距离lHi。再将环境信息与高注意力邻居状态作为轨道强化网络与安全强化网络的输入,边训练边输出转角决策修正δDDPGi和直行距离修正lDDPGi。最后Python程序将运动决策通过JSON数据格式发送仿真环境,仿真环境再根据运动决策更新焦点单体i的运动状态,直到焦点单体运行到下一决策时刻,再将新状态上传强化网络训练程序,仿真程序异步上传多智能体信息获得模型决策,最终在集群运动稳定后停止训练,强化网络的训练参数如表1所示。
2.2 鱼群硬注意力模型的强化修正仿真
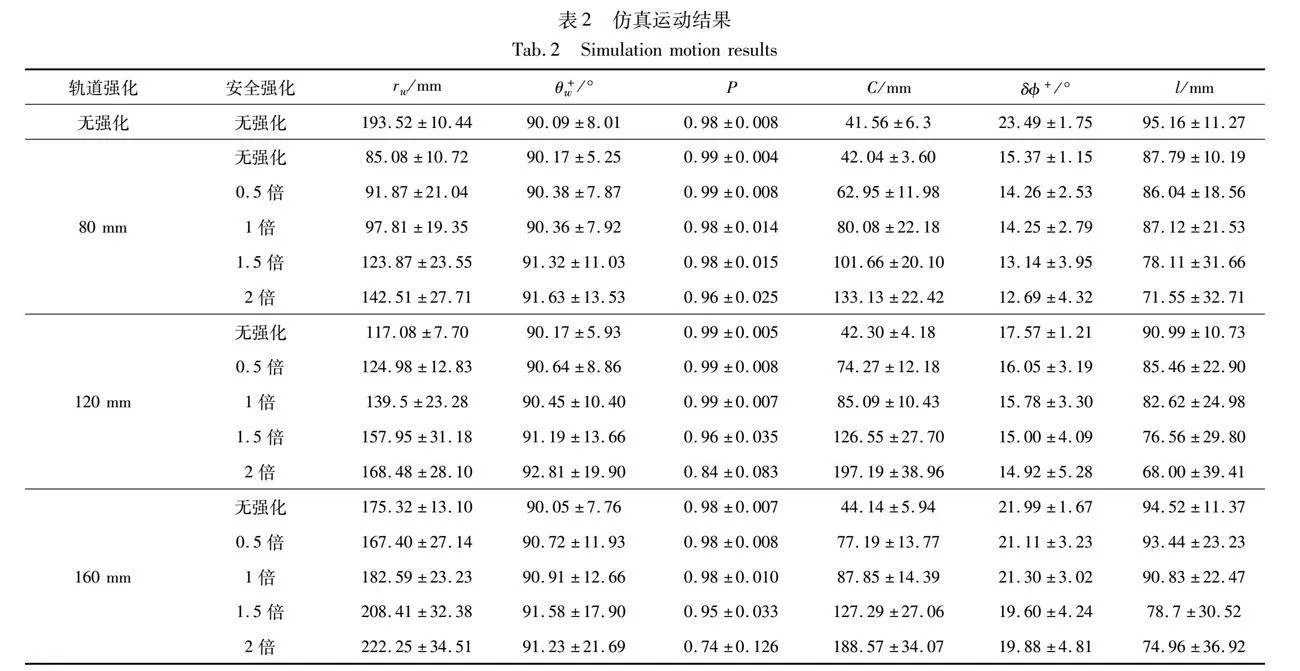
与硬注意力模型训练数据采用5鱼实验一致,通过5智能体的硬注意力强化仿真来验证生物模型强化控制的可行性。首先以5智能体硬注意力模型的自由运动仿真为基准,分别采用不同的期望轨道距离rwe进行轨道强化修正网络训练,其中期望轨道距离分别设定成80 mm、120 mm、160 mm。在轨道网络训练稳定后,接着实验不同的期望安全比率rse来训练安全强化网络,rse分别取0.5倍、1倍、1.5倍和2倍,所有强化网络训练完毕后,采用训练后的模型各仿真运行1 h,统计集群运动轨迹数据,结果如表2所示,其中轨道强化和安全强化均标识“无强化”的代表纯硬注意力模型仿真。由于仿真软件环境可同时允许真实机器人进行硬件在环仿真,所以仿真程序具有机器人的安全运动机制,即当焦点智能体质心外围100 mm的安全圆与边界碰撞时,或者决策目标连线有其他智能体侵入,会重新启动决策,新决策会倾向边界内侧避障,从而导致较大的对墙距离rw和直游距离l。稳定地对墙角度绝对值θ+w和较稳定的转角决策绝对值δ+表明仿真体平行边界运动。
轨道强化网络修正后,模型输出转角决策δ+相对于第一行无强化数据的生物模型输出具有曲率可控性,尤其在没有安全强化的情况下,不同的轨道期望强化会得出不同的曲率,显示出了转角决策的可控性。随着轨道期望距离的增加,轨道强化网络的修正转角δ+逐渐扩大,使得集群运动的曲率增加,最终体现在对墙距离rw的增加,表明强化网络通过修正转角决策δ可以实现对目标轨道的跟踪控制。受硬注意力模型影响,随着对墙距离rw的增加,导致焦点单体的运行自由空间加大,所以直游距离l会逐渐增加。整个轨道期望测试范围的对墙角度绝对值θ+w稳定,表明强化修正的沿墙运动特性较好,较高的群体极性P和紧凑的群体大小C表明集群硬注意力模型自治具有强鲁棒性,可以包容人为期望的外控干扰。
加入安全强化网络后,多数仿真集群仍能保持较为稳定的对墙角度绝对值θ+w、较高的群体极性P和紧凑的群体大小C,说明强化网络修正在一定范围内可以不破坏生物硬注意力模型的自组织秩序。然而随着安全强化的期望比率增大,仿真集群的大小C值逐渐扩大,群体极性P值逐渐减小,说明生物集群的秩序正在瓦解,集群行为开始变得复杂,导致仿真安全机制得以频繁触发。直观表现在直游距离l逐渐减小,随之仿真体的对墙距离rw增大,这使得轨道跟踪的任务性能逐渐变差。在极端情况下,例如160 mm轨道期望与2倍期望安全比率情况,原有的生物集群运动秩序已经无法有效维持,表现为较大的数据方差。
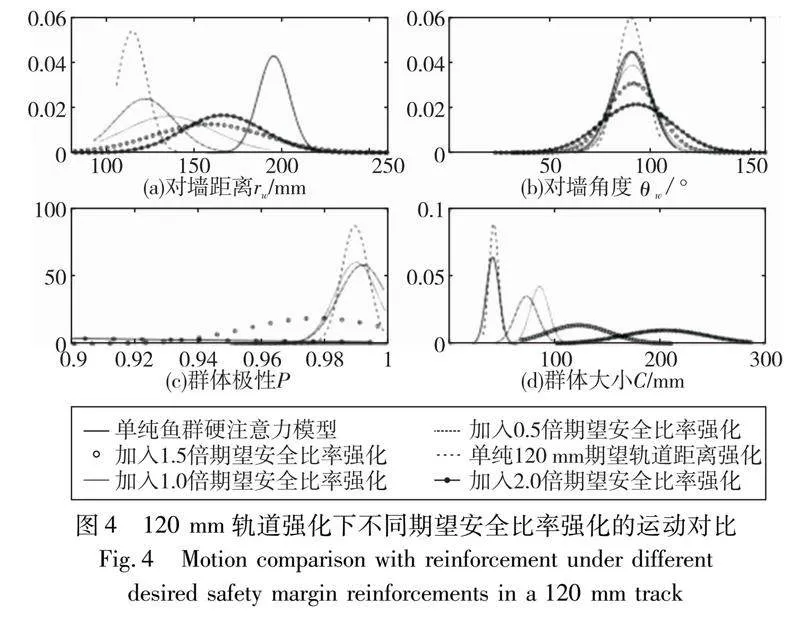
图4展示了120 mm期望轨道距离,不同期望安全距离比率的强化对比,利用高斯拟合使各参数的概率密度曲线平滑化以方便观察,其中图4(a)显示了对墙距离rw的概率密度曲线,黑色曲线为单纯使用鱼群硬注意力模型仿真的数据统计。实验表明:在不加入安全强化的前提下,仅使用轨道强化可以明显拉近集群的对墙距离,统计峰值在期望距离120 mm附近,说明通过集群强化修正确实可以将人工目标嵌入到自由生物模型中,并达到较好的控制效果,随着不同期望安全比率的强化网络加入,集群由于安全裕度的扩大导致距墙距离逐渐拉大,符合安全强化设计。图4(b)统计了不同实验下的集群对墙角度绝对值的概率密度曲线,其中黑色线为单纯使用鱼群硬注意力模型仿真的数据统计。仿真结果表明:θ+w在不同控制目标下的仿真集群与自然模型运动具有较一致的环境角度,且峰值约为90°,即平行于边界运动,其中单独轨道强化会极大提升集群运动轨道的确定性,如图4(b)红色曲线所示,形成较为确定的运动集群来跟踪设定轨道。图4(c)(d)的集群极性、大小的红色曲线也表明:单独轨道强化的集群运动确定性更高(见电子版)。随着安全强化的加入,轨道强化的确定性被逐渐消减,当加入1.5倍安全期望比率强化后,θ+w的组织性已经衰减,低于纯硬注意力的运动模型,图4(c)的集群极性P分布也表明了这一点,当设定大于1.5倍期望安全比率后,集群极性相对于生物模型已较大衰减。同时图4(d)的集群大小也表明:从1.5倍比率强化开始集群逐渐发散,虽然1.5倍比率还具有较松散的集群组织,运动间隙加大,碰撞减小形成较为安全的集群运动态势,但是加入2.0倍期望安全比率强化修正将完全破坏集群的自组织性,如图4(c)(d)所示,由于相对间距扩大,集群极性已十分微弱。
3 硬注意力强化模型的集群机器人实验
3.1 集群机器人实验平台
作为多智能体仿真环境的硬件在环扩展,集群机器人实验平台同样由集群机器人硬件平台与嵌入仿真环境(参考第2章)的LabVIEW控制软件两部分组成,其中机器人硬件平台如图5所示,采用的微型集群机器人为自主研发的Cuboids机器人系统[28],运行环境为直径1 m的圆形空间,上方装有工业相机,LabVIEW控制软件与实验相机相连,以200 ms周期进行图像采集、模式识别机器人,然后使用40 ms周期的卡尔曼滤波器跟踪机器人单体,最终获得每台机器人的位置与朝向。焦点机器人在决策时刻获取自身图像数据[xi,yi,i]与邻居位姿,然后根据式(1)~(5)将上述信息换算为机载传感的环境信息[rwi,θwi,0]与邻居信息[dij,ψij,△ij],再利用与上节仿真程序一致的过程向Python服务器请求鱼群硬注意力强化网络决策,输出[δHi+δDDPGi,lHi+lDDPGi]后则回传给LabVIEW控制软件。然后利用无线路由器,将具体的运动指令传输给Cuboids机器人。物理实现网络决策:首先机器人会旋转角度δHi+δDDPGi,然后再按照指定距离lHi+lDDPGi进行直线运动,如果成功到达指定位置则会触发下一轮决策,如果运动前方出现环境障碍或邻居闯入,则焦点机器人会停下请求新的决策,机器人安全决策过程可以参考文献[23]。
3.2 机器人硬注意力强化运动分析
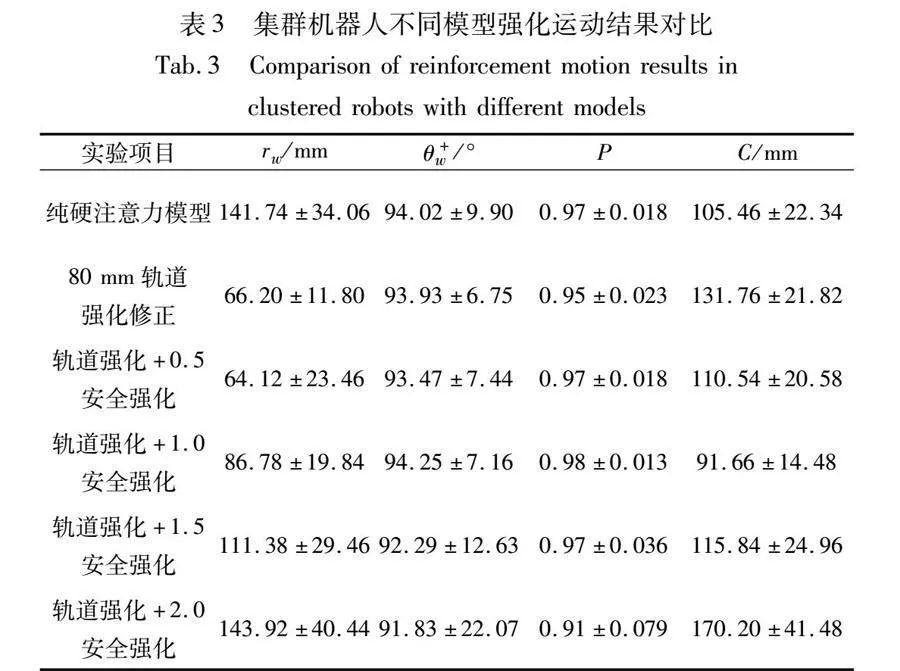
由于机器人与鱼类之间的性能、外形差异,较多机器人直接进行硬注意力模型迁移控制会形成阻塞。鉴于上述物理、性能、动态环境方面的约束,为验证所提方法连续实验的控制有效性,降低集群的复杂度,采用三Cuboids机器人在80 mm轨道强化下加入不同期望安全比率的集群运动实验。实验结果与单纯使用硬注意力模型控制的机器人进行运动数据对比,如表3所示。
由于机器人具有刚性物理外形,无法像仿真实验一样紧密运动,所以在轨道强化网络修正下,机器人以近似前后排列的方式沿边界运动。这种秩序已经修改了生物集群模型的单体交替领头的自组织模式,即跟随者较少内圈超越领导者,因此机器人对边界距离rw值较80 mm轨道期望偏小,而群体大小C值较大,对墙角度绝对值θ+w稳定在90°左右,具有较高的群体极性,表明强化修正后并未破坏硬注意力模型的运动秩序,仅改变了集群的运动形式,使其更符合机器人任务的特点。集群领域专家Theraulaz Guy在文献[29]中提到:集群机器人需要生物启发,但是绝对不能依赖生物启发,需要根据自身任务对生物集群运动进行调整,所提硬注意力模型的人工目标强化为该论断提供了一种可行路径。
在加入安全强化修正后,当期望安全比率为0.5时,机器人的运动效果与单纯80 mm轨道强化相似,跟随者受目标轨道束缚,并进一步减小了前后邻居距离,导致群体大小C值较单纯轨道强化小。当期望安全比率为1时,发生了自组织形式的改变,多余的安全裕度使机器人逐渐展现出鱼群模型的灵活性,具体表现在机器跟随者能够从内圈超越领导者,形成典型的集群反旋[23]。这种反旋组织特性的出现,使群体大小C进一步减小,群体从线形转变为块形,群体中心被迫远离边界,导致形成较大的运行曲率,实现对墙距离rw的增大;当期望安全比率大于1,机器人开始逐渐分散,群体大小C值增大,机器人的内圈超越变得更加频繁,相邻两机器人的间距也在增加,对墙距离rw也需要增加以容纳更松散的集群形态。相对稳定的对墙角度θ+w和较高的群体极性P表明:强化网络修正鱼群模型的方式能有效在集群机器人自组织运动的基础上引入人工控制,使其兼具生物模型的鲁棒、灵活性和工程应用的可控、安全性。2倍安全比率的集群运动稳定性减弱,集群极性P与集群大小C忽大忽小,说明人工控制正在瓦解生物模型的组织性,1.5倍安全比率靠近自然集群秩序的临界边缘。
图6展示了表3强化学习控制策略下的集群机器人实验运动轨迹。图6(a)为80 mm期望轨道强化下的运动轨迹,受机器人物理约束和轨道强化网络修正的影响,机器人群展现出前后线形的排列方式,并紧靠边界轨道运行,跟随者被轨道约束,无法超越领导者。图6(b)~(e)分别展示了集群机器人在80 mm轨道强化基础上加入不同安全比率期望的强化运动轨迹。图6(b)展示的0.5倍期望安全比率控制下的紧凑机器人集群,紧凑激发了鱼群模型的排斥作用,使得有些单体虽然线形排列,但也偶尔发生内圈超越的现象,表明生物模型的内在安全机制[23]可以被随时触发。随着采用1倍期望安全比率控制,图6(c)机器人之间已经存在了较大的间隙,使得跟随者具有足够的能动性从内圈超越领导者,形成了类鱼群的反旋运动。但是图6(d)~(e)表明:随着继续人为加大期望安全比率,机器人的群体大小逐渐增大,群运动秩序逐渐减弱,甚至出现濒临崩溃的趋势。
4 结束语
通过研究在鱼群硬注意力模型的基础上对集群运行轨道与安全间隙进行多智能体强化的控制方法,探索了如何在不可控的生物启发模型下加载人工控制,从而有利于集群机器人开展预定任务。
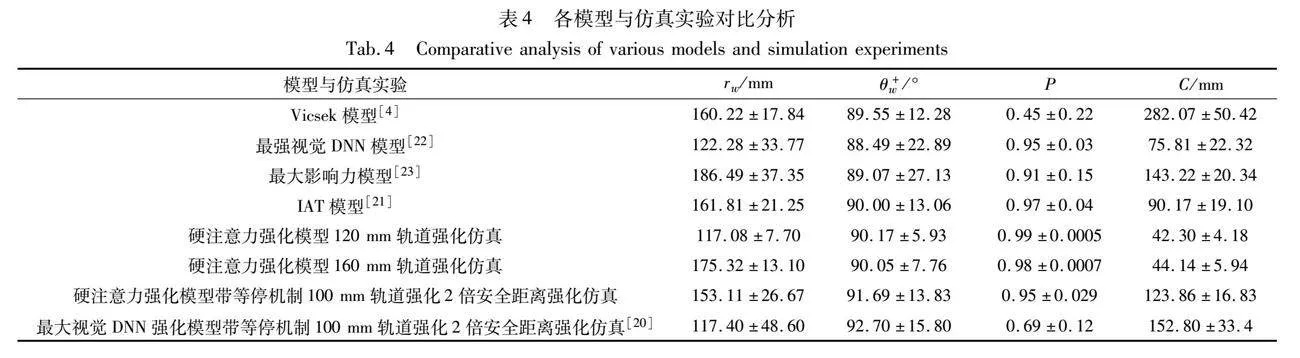
对比经典Vicsek模型[4]、最强视觉DNN模型[22]、最大影响力模型[23]以及IAT模型[21],分别进行5智能体1 h仿真实验来观察所提人工控制方法对自然集群秩序的影响。实验结果如表4所示,虽然传统Vicsek模型的墙角度θ+w数据非常接近于90°,但该模型仅适于集群系统的连续控制,对决策——运动模式的群体控制策略难以涌现秩序,具体表现为极性P值过小,群体大小C值过大;最强视觉DNN模型虽能形成较好的自然运动秩序,但是群体大小C值相对于所提方法同轨道强化(120 mm)的数值,极性P值略小,表明基于视觉的集群涌现方法需要保证一定的邻居空间才有利于交互模型的收敛。而最大影响力模型的训练数据来自2鱼实验数据,所以在5智能体仿真的场景下,其轨道距离过大,与所提方法同尺度轨道强化(160 mm)的数据相比,集群比较松散,运动方向的统一性还有不足,自由度过高导致难以用于实际机器人控制;IAT模型采用了软注意力模型,即焦点单体需要与所有邻居进行交互,与所提硬注意力模型相比,模型的计算复杂度更高,虽然集群极性P值较好,但与相似轨道(160 mm)强化下的群体大小C值相比还不够紧凑。相比于最大视觉DNN强化模型,所提模型的群体极性P值较好,同时具有更紧凑的集群大小C,且对墙角度θ+w更加地接近于90°,运动秩序性更好;最大视觉DNN模型控制的集群会形成蛇形队列,集群分布较散,受干扰容易发生集群断裂。综上分析:所提模型利用深度强化方法为自然集群秩序注入更明确的人工目标,具有更强的集群控制力,有利于真实机器人系统在复杂环境下的任务自组织。
研究发现:单纯依赖强化控制模型在小空间范围内直接训练集群机器人达到运动有序不具可行性[25],究其原因在于单体所处的复杂内环境需要大规模记忆池进行强化训练,还较难保证模型训练收敛,所以必须借助生物模型的自组织能力,使集群运动产生典型运动模式,在此基础上进行集群强化才具有训练可行性;同时,硬注意力模型的稀疏信息交互机制有助于焦点单体选出重要邻居,为后续多智能体强化的信息输入降低了复杂性,极大地压缩了DDPG记忆池的空间维度,为多智能体强化网络的稳定训练提供了自然秩序保障。仿真和机器人实验结果均表明,人工控制目标必须与自然模型相匹配才能表现出色的控制性能,既能保留生物集群的鲁棒灵活性,又能实现集群机器人的任务可控性,而一旦人工期望超出特定边界,集群的自组织秩序就会出现崩溃,难以维持复杂系统的功能秩序,所以后续工作需要更深入地探寻生物模型与人工干预的有效界面,实现两种控制的合理匹配。与传统的鱼群涌现模型相比,所提方法能够在硬注意力模型的涌现机制下实现人工目标控制,有利于机器集群的可控运动。
本文方法为解决复杂人工系统的自然集群运动控制提供了有益尝试,所提模型是实现集群机器人顶层任务的基础,通过人工可控涌现,能实现集群的圆心轨道集结,以及通过安全强化改变集群覆盖的大小。下阶段也可将圆形轨道变为直线轨道,实现集群的可控直线迁移,这些功能为无人机群空中协作、智慧农业集体作业、物流仓储多机搬运等应用提供了基础运动方案。将这一方法应用到具体实际场景,有望为集群机器人大规模应用创造更广阔的应用前景,从而提高社会信息物理系统的智能性和自主性,实现更高水平的任务协同自动化。
参考文献:
[1]Berdahl A M,Kao A B,Flack A,et al.Collective animal navigation and migratory culture:from theoretical models to empirical evidence[J].Philosophical Transactions of the Royal Society B:Biological Sciences,2018,373(1746):20170009.
[2]Hamann H,Khaluf Y,Botev J,et al.Hybrid societies:challenges and perspectives in the design of collective behavior in self-organizing systems[J].Frontiers in Robotics and AI,2016,3:article No.14.
[3]Reynolds C W.Flocks,herds and schools:a distributed behavioral model[J].ACM SIGGRAPH Computer Graphics,1987,21(4):25-34.
[4]Vicsek T,Czirók A,Ben-Jacob E,et al.Novel type of phase transition in a system of self-driven particles[J].Physical Review Letters,1995,75(6):1226-1229.
[5]Couzin I D,Krause J,James R,et al.Collective memory and spatial sorting in animal groups[J].Journal of Theoretical Biology,2002,218(1):1-11.
[6]Calovi D S,Litchinko A,Lecheval V,et al.Disentangling and mode-ling interactions in fish with burst-and-coast swimming reveal distinct alignment and attraction behaviors[J].PLoS Computational Biology,2018,14(1):e1005933.
[7]Harrison D,Rorot W,Laukaityte U.Mind the matter:active matter,soft robotics,and the making of bio-inspired artificial intelligence[J].Frontiers in Neurorobotics,2022,16:880724.
[8]Selvaraj S,Choi E.Swarm intelligence algorithms in text document clustering with various benchmarks[J].Sensors,2021,21(9):3196.
[9]Dorigo M,Trianni V,ahin E,et al.Evolving self-organizing behaviors for a swarm-bot[J].Autonomous Robots,2004,17(2-3):223-245.
[10]Rubenstein M,Ahler C,Nagpal R.Kilobot:a low cost scalable robot system for collective behaviors[C]//Proc of IEEE International Conference on Robotics and Automation.Piscataway,NJ:IEEE Press,2012:3293-3298.
[11]Araujo A F R,Barreto G A.Context in temporal sequence processing:a self-organizing approach and its application to robotics[J].IEEE Trans on Neural Networks,2002,13(1):45-57.
[12]Wang J J,Ma J,Hou J,et al.Operational effectiveness evaluation of UAV cluster based on Bayesian networks[J].Journal of Physics:Conference Series,2022,2282(1):012001.
[13]邹长杰,郑皎凌,张中雷.基于GAED-MADDPG多智能体强化学习的协作策略研究[J].计算机应用研究,2020,37(12):3656-3661.(Zou Changjie,Zheng Jiaoling,Zhang Zhonglei.Research on collaborative strategy based on GAED-MADDPG multi-agent reinforcement learning[J].Application Research of Computers,2020,37(12):3656-3661.)
[14]赵增旭,刘向阳,任彬.基于方向指引的蚁群算法机器人路径规划[J].计算机应用研究,2023,40(3):786-788,793.(Zhao Zengxu,Liu Xiangyang,Ren Bin.Ant colony algorithm for robot path planning based on direction guidance[J].Application Research of Compu-ters,2023,40(3):786-788,793.)
[15]李少波,刘意杨.基于改进深度强化学习的动态移动机器人协同计算卸载[J].计算机应用研究,2022,39(7):2087-2090,2103.(Li Shaobo,Liu Yiyang.Dynamic mobile robot collaborative computing offloading based on improved deep reinforcement learning[J].Application Research of Computers,2022,39(7):2087-2090,2103.)
[16]Vorobyev G,Vardy A,Banzhaf W.Supervised learning in robotic swarms:from training samples to emergent behavior[M]//Ani Hsieh M,Chirikjian G.Distributed Autonomous Robotic Systems.Berlin:Springer,2014:435-448.
[17]Foerster J,Assael I A,De Freitas N,et al.Learning to communicate with deep multi-agent reinforcement learning[C]//Proc of the 30th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2016:2145-2153.
[18]Zhou Xin,Wen Xiangyong,Wang Zhepei,et al.Swarm of micro flying robots in the wild[J].Science Robotics,2022,7(66):eabm5954.
[19]夏家伟,朱旭芳,张建强,等.基于多智能体强化学习的无人艇协同围捕方法[J].控制与决策,2023,38(5):1438-1447.(Xia Jiawei,Zhu Xufang,Zhang Jianqiang,et al.Research on cooperative hunting method of unmanned surface vehicle based on multi-agent reinforcement learning[J].Control and Decision,2023,38(5):1438-1447.)
[20]刘磊,张浩翔,陈若妍,等.鱼群涌现机制下集群机器人运动强化的迁移控制[J].控制与决策,2023,38(3):621-630.(Liu Lei,Zhang Haoxiang,Chen Ruoyan,et al.The transfer control of swarm robotics motion reinforcement employing fish schooling emergency me-chanism[J].Control and Decision,2023,38(3):621-630.)
[21]刘磊,黄景然,赵佳佳,等.揭示生物集群系统内部信息耦合机制的深度网络模型[J].控制与决策,2023,38(5):1403-1411.(Liu Lei,Huang Jingran,Zhao Jiajia,et al.Analysis model for revealing mechanism of internal information coupling in biological collective systems based on deep network[J].Control and Decision,2023,38(5):1403-1411.)
[22]刘磊,孙卓文,陈令仪,等.基于深度学习的仿生集群运动智能控制[J].控制与决策,2021,36(9):2195-2202.(Liu Lei,Sun Zhuowen,Chen Lingyi,et al.Intelligent control of bionic collective motion based on deep learning[J].Control and Decision,2021,36(9):2195-2202.)
[23]Lei L,Escobedo R,Sire C,et al.Computational and robotic modeling reveal parsimonious combinations of interactions between individuals in schooling fish[J].PLoS Computational Biology,2020,16(3):e1007194.
[24]刘磊,陶杰,尹钟.微型机器人以及群机器人系统:中国,CN201710441229.2[P].2017-06-13.(Liu Lei,Tao jie,Yin Zhang.Microrobots and searm robot system:China,CN201710441229.2[P].2017-06-13.)
[25]Hansen E,Brunton S L,Song Zhuoyuan.Swarm modeling with dyna-mic mode decomposition[J].IEEE Access,2022,10:59508-59521.
[26]Zhou Xiao,Zhou Song,Mou Xingang,et al.Multirobot collaborative pursuit target robot by improved MADDPG[J/OL].Computational Intelligence and Neuroscience.(2022-01-01).https://doi.org/10.1155/2022/4757394.
[27]Han Chenchen,Yao Haipeng,Mai Tianle,et al.QMIX aided routing in social-based delay-tolerant networks[J].IEEE Trans on Vehicular Technology,2021,71(2):1952-1963.
[28]梁星星,冯旸赫,马扬.多agent深度强化学习综述[J].自动化学报,2020,46(12):2537-2557.(Liang Xingxing,Feng Yanghe,Ma Yang.Deep multi-agent reinforcement learning:a survey[J].Acta Automatica Sinica,2020,46(12):2537-2557.)
[29]Dorigo M,Theraulaz G,Trianni V,et al.Swarm robotics:past,present,and future[J].Proceedings of the IEEE,2021,109(7):1152-1165.
[30]Pérez-Escudero A,Vicente-Page J,Hinz R C,et al.idTracker:tracking individuals in a group by automatic identification of unmarked animals[J].Nature Methods,2014,11(7):743-748.
收稿日期:2023-12-27
修回日期:2024-03-06
基金项目:上海市自然科学基金资助项目(22ZR1443300)
作者简介:刘磊(1982—),男(通信作者),甘肃张掖人,副教授,硕导,博士,CCF会员,主要研究方向为集群智能与复杂系统控制(liulei@usst.edu.cn);葛振业(1999—),男,江苏盐城人,硕士研究生,主要研究方向为集群智能;林杰(1998—),男,湖北武穴人,硕士研究生,主要研究方向为复杂系统、可解释学习;陶宇(1997—)男,江苏淮安人,硕士,主要研究方向为集群智能、深度学习;孙俊杰(2002—),男,上海人,主要研究方向为数据挖掘.
