面向功能语义增强与标签关联的Web服务标签推荐
2024-11-04刘庆雪王荔芳潘国庆胡强



摘 要:
为了提升标签推荐的质量,提出一种面向功能语义增强与标签关联的Web服务标签推荐方法。将语境权重融入TextRank模型,提取与服务功能契合度高的关键词,用于构建功能语义增强的服务表征向量;建立标签关联图,基于改进的GraphSAGE模型生成标签关联向量;利用KNN算法获取推荐的主标签与候选标签集合,面向服务表征向量和标签关联向量构建融合适配度与关联度的标签推荐方法。实验表明,所提出方法在accuracy与F1-score指标上优于当前流行的标签推荐方法,标签推荐质量得到提升。
关键词:Web服务;语境权重;语义增强;标签关联;标签推荐
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)09-016-2678-07
doi:10.19734/j.issn.1001-3695.2024.01.0003
Label recommendation of Web services based on functional semantic enhancement and label association
Liu Qingxue1, Wang Lifang1, Pan Guoqing1, 2, Hu Qiang2
(1.School of Mechanical & Electrical Engineering, Kunming University, Kunming 650214, China; 2.College of Information Science & Techno-logy, Qingdao University of Science & Technology, Qingdao Shandong 266061, China)
Abstract:
To improve the quality of label recommendation, this paper proposed a label recommendation method for Web services oriented functional semantic enhancement and label association. It integrated the context weight into the TextRank model to extract keywords that fit well with the service function, which were used to construct the functional semantic enhanced service representation vector. It established the label association graph and generated the label association vector based on the improved GraphSAGE model. It used the KNN algorithm to obtain the recommended primary label and candidate label set. It used the service representation vector and label association vector to construct a label recommendation method combining fitness and association. Experiments show that the proposed method is superior to the current popular label recommendation methods in terms of accuracy and F1-score, and it improves the quality of tag recommendation.
Key words:Web services; context weight; semantic enhancement; label association; label recommendation
0 引言
随着云计算、移动互联网以及物联网技术的广泛应用,面向服务架构已成为网构软件开发和部署的主要模式。Web服务是一种应用广泛的服务组织形式,它是一种采用标准化协议和接口进行封装的网络应用程序。通过对Web服务的调用和集成,软件开发者可以快速实现业务系统的构建[1]。
当前网络中的Web服务数量不断增加,用户可以在各类服务注册平台中查找所需的Web服务。在Web服务注册平台ProgrammableWeb和RapidAPI中,分别注册超过了26 000和40 000个服务。不断增加的Web服务,为服务的存储组织和查找带来了挑战[2]。为此,各类服务平台中注册的服务均提供了类别标签(简称标签)。这些标签为服务对应的功能业务场景。图1所示的3DTransform是用于将3D模型文件转换为.STL格式以便进行3D打印的Web服务。该服务在发布时标注了conversions、tools、3D和printing四个标签。其中,conversions为主标签,主标签标识了Web服务的主要业务功能。
借助于类别标签,可以实现Web服务的分类管理,提高服务查找效率和存储组织的合理性[3]。服务发布者提供的服务功能描述文本是确定标签的主要依据。标签推荐的主要工作是分析服务描述文本的功能语义,为其从标签库中选择合适的类别标签,因此,Web服务标签推荐本质上为文本的标签推荐问题。
传统的文本标签推荐问题中的文本描述内容较为详实、主题语义较为完善[4]。然而,Web服务的功能描述文本较为短小,通常不超过100个单词,而且服务功能、操作和评价信息杂糅,造成服务描述的功能语义特征提取难度较大,这使得Web服务类别标签推荐成为一项具有挑战性的工作。
在Web服务的标签推荐工作中,Cao等人[5]利用注意力机制将LSTM的局部隐式状态向量和全局LDA主题向量相结合,结合词序和上下文信息提取高质量的表征向量,实现更准确的服务标签分类。Fletcher[6]构建了一个注意力模型提升Web服务标签推荐效果,提出单词级和句子级的注意机制,根据句子中与标签语义相关度最高部分的功能向量优化标签向量,发挥了标签的功能标识作用,提高了标签推荐质量。Wang等人[7]利用BERT生成服务描述向量,使用注意力机制获取每个描述对标签向量生成的贡献。通过对抗学习的方式利用MLP层输出不同标签的推荐概率,实现标签推荐。
上述研究表明,时序神经网络在文本全局特征的捕获方面具有显著优势。基于此,Li等人[8]利用BERT生成服务描述向量和标签的词向量,输入到CNN和LSTM的堆叠网络来进一步提取服务描述中的语义特征,通过注意力机制计算每个标签对服务描述向量生成的贡献,将优化后的描述向量输入MLP层,输出标签推荐概率。赵鲸朋[9]将神经元有序的长短期记忆神经网络应用于服务功能向量提取,通过softmax层实现标签推荐概率输出。同时,结合层次化微调和父类别嵌入技术学习类别层次的约束关系,缩小候选标签推荐范围,提升标签推荐效率。路凯峰等人[10]借助BERT模型为服务描述中的词语生成特征向量,利用深度金字塔卷积神经网络将词语向量转换为功能向量,借助softmax实现标签推荐,提升推荐质量的同时降低了耗时。类似地,彭菲等人[11]构建多通道全局与局部语义融合框架,在框架的每个卷积通道使服务描述中的词语依次通过RoBERTa、CNN和融入快速规则近似注意力机制改进的SRU模型获取服务功能向量,将所有通道的功能向量均值通过MLP层输出推荐概率,提高了标签推荐质量。
此外,也有研究者通过挖掘标签-标签或标签-服务间的组合关系提升标签推荐质量。例如,肖勇等人[12]构建Web服务结构图和Web服务-标签的属性二部图。通过随机游走算法获取服务节点的结构特征和属性特征序列,采用skip-gram模型训练生成Web服务表示向量,基于SVM实现标签推荐,借助服务和标签间的属性信息以及服务间结构关系提升标签推荐质量。Shi等人[13]使用主动学习来训练Web服务的多标签分类器,对每个标签与服务执行二进制分类,通过层次聚类捕捉标签间的相关性,提高了Web服务标签推荐精度。Gan等人[14]使用CNN提取Web服务描述的特征,提出了一个标签嵌入模型学习标签的特征表示,将Web服务及其标签嵌入特征输入递归神经网络实现服务标签的序列化推荐。Shi等人[15]基于概率主题模型获取Mashup服务和Web服务的标签的潜在主题,然后利从Web服务关系网络中提取特征信息训练因子分解机,构建了一种基于因子分解机的主题敏感的Mashup标签推荐方法。Chen等人[16]将服务描述关键词向量和标签词向量输入MLP层,根据输出概率推荐标签,然后利用服务与标签的组合图生成标签关联向量,综合服务的关键词向量、标签关联向量均值以及上一步推荐概率来推荐缺失的标签。
从已有工作可以看出,服务功能向量是计算标签与服务匹配的主要依据,研究者利用各种神经网络模型和注意力机制可以提升服务功能向量的生成质量。此外,借助于构建标签网络获取标签之间的关联以提升标签推荐精确度也是当前流行的方法。然而,已有方法并未强化服务描述中的功能特征词在功能向量中的特征占比,影响了服务功能向量与标签语义匹配的效果。同时,已有方法在进行标签关联度计算时,并未考虑标签间的关联权重,标签关联度的评价合理性有待于进一步提升[17]。
为解决现有方法的不足,本文提出一种面向功能语义增强与标签关联的Web服务标签推荐方法,主要工作与贡献如下:
a)提出了一种功能语义增强的服务表征向量生成方法。利用改进的TextRank模型从服务描述文本中提取功能特征词,用于建立功能语义增强的服务表征向量,提升标签与服务的适配度计算精确度。
b)建立标签关联图,利用改进GraphSAGE模型实现带有边权的标签关联图的节点向量化,依据关联强度聚合邻域节点特征,提高标签关联向量的生成质量,便于更合理地计算标签关联度。
c)使用KNN算法获取Web服务的主标签与候选标签集合,构建一种融合标签适配度与关联度的Web服务多标签推荐方法。实验证明所提出方法可以有效提升Web服务标签推荐质量。
1 研究框架
从图1中3DTransform的组织形式可以看出,一个Web服务主要包含服务名称、服务标签集合和服务描述信息。下面给出Web服务的形式化定义。
定义1 Web服务
Web服务为一个三元组s=(n, L, d),其中,n为服务名称,L为服务标签集合,d为服务描述信息。
标签推荐是指在服务发布者提供了服务描述信息后,为Web服务推荐合适的标签集合,可以描述为:给定服务s的服务描述s.d,存在标签推荐模型f,使得f(s.d)→s.L,本文工作就是建立能够高精确度推荐Web服务标签的模型f。
本文的研究框架如图2所示。首先,从已有Web服务注册平台中获取已经发布的Web服务,提取已发布Web服务的服务描述和服务标签。
然后,针对每个服务描述,利用改进TextRank模型为每个服务提取功能特征词,并为这些词生成功能特征词向量。同时,采用BERT模型为每个服务生成对应的服务功能向量。将服务的功能向量与特征词向量融合为功能语义增强的服务表征向量。
其次,采用word2vec为每个标签生成标签的词向量,同时依据服务标签之间的共现关系,构建服务标签关联图,利用改进的GraphSAGE模型为标签生成关联向量。
再次,对于待推荐标签的Web服务,为其生成功能语义增强的服务表征向量,并利用KNN算法为其确定服务的主标签和候选标签集合。
最后,依据服务与标签的适配度、主标签与候选标签之间的关联度,通过MLP层为Web服务计算标签的推荐概率,选择推荐概率最高的K-1个标签与主标签一起作为最终推荐的标签。
2 功能语义增强的服务表征向量生成
BERT是一种基于Transformer的预训练文本特征提取模型,广泛应用于服务功能向量的生成。BERT在生成服务功能向量时,注重词在句子上下文的关联特征,难以突出服务描述中能够标识服务功能的特征词本身的语义信息。若仅使用BERT模型生成的功能向量进行标签推荐会影响推荐质量。为此,本文从服务描述文本中提取功能特征词并生成特征词向量,与BERT模型生成的服务功能向量进行融合,建立一种功能语义增强的服务表征向量,以便提高服务标签的推荐质量。
TextRank常用于文本关键词的提取,它依据词共现关系构建无向图,通过评估词在图中与邻域节点的重要性进行关键词筛选。TextRank通过无监督的方式迭代训练,不依赖于人工标注的训练数据,因此,适用于Web服务描述的关键词提取。
使用TextRank为服务s提取关键词时,针对s.d={t1, t2, …, tn}构建无向加权图G=(V, E, W),图中节点vi对应词语ti,以特定长度窗口滑动遍历服务描述文本,同一窗口内的任意两个词之间建立一条无向边,边的权值wij为词语ti和tj在滑动窗口中共现次数的归一化值。W(vi)为节点vi的权重,初始值为1。TextRank模型采用式(1)对节点权重进行更新,直至各节点权重收敛,模型按照节点权重的大小推荐文本关键词。式(1)中的ρ为阻尼系数,通常设置为0.85[18, 19]。N(v)用于表示节点v的邻接节点集合。
其中:当lcj为服务si的标签时,ysi,lcj值为1,否则值为0。根据此loss,当ysi,lcj为1,优化目标为最小化预测lcj为正例概率的负对数;当ysi,lcj为0,优化目标为最小化预测lcj为负例概率的负对数。p(lcj, si)与真实标签ysi,lcj越接近,loss越小;反之loss越大。当loss收敛,模型预测效果达到最优。为服务s的预测标签时,取LC中p(lcj, si)值中最大的前K-1个标签与主标签一起构成top-K标签推荐结果。将上述方法命名为LRW-FA (label recommendation for Web services based on fitness and association)。
5 实验验证
本章开展实验,验证以下几个问题:
Q1:CWTR-BERT生成的服务表征向量用于标签推荐时是否优于其他模型?
Q2:标签关联的引入能否提升Web服务的标签推荐质量?
Q3:LWR-FA是否优于其他Web服务标签推荐方法?
Q4:关键超参数选择:a)改进的GraphSAGE的聚合器选择;b)KNN最近邻算法中邻居数量K的选择。
5.1 数据集、实验环境与评价指标
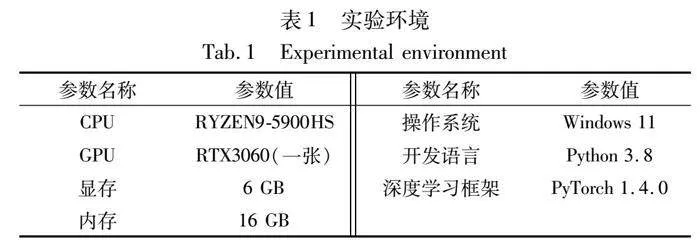
实验数据为ProgrammableWeb网站中的真实Web服务。在删除仅包含一个标签的服务和所包含的某个标签出现次数小于10的Web服务后,形成包含16 924个Web服务的数据集。采用十折交叉验证法进行模型性能评估,实验环境如表1所示。
分析数据集发现,绝大部分Web服务的标签数量为2到5个,因此本文的top-K推荐中,K设置为3、5和7。采用常用多标签推荐评价指标accuracy与F1-score[21, 22]评估Web服务多标签推荐质量。
5.2 CWTR-BERT生成服务表征向量的质量评估
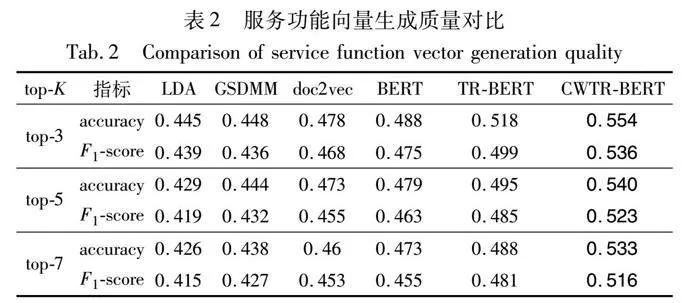
选取LDA[23]、GSDMM[24]、doc2vec[25]、BERT[26]与本文模型CWTR-BERT进行对比,其中,LDA与GSDMM为主题模型,doc2vec与BERT为神经网络模型。此外,为了验证引入语境权重后对功能特征词提取质量的改善,构建利用TextRank直接提取功能特征词对BERT生成的服务功能向量进行语义增强的方法TR-BERT(TextRank and BERT)。
表2为六种模型生成的服务功能向量,采用式(15)生成的标签适配度对应的前top-K个标签进行推荐验证。从表2可以看出,CWTR-BERT所对应的accuracy和F1在不同个数的top-K标签推荐中均取得了最优值,说明CWTR-BERT生成的功能语义增强的服务表征向量在功能区分度上得到了提升,在应用于标签推荐时可以获得更好的推荐效果。
从表中数据可以看出,LDA生成的服务功能向量用于标签推荐效果最差,主要原因是LDA作为主题模型适用于长文本的主题提取特征。相比LDA,GSDMM可以自适应地学习主题数量,在低数量级主题的服务描述中特征提取能力更强。因此,生成的服务功能向量在标签推荐质量上优于LDA模型。doc2vec与BERT为神经网络模型,相对于主题模型,它们进行语义特征提取时考虑词语的上下文信息,可以从服务描述中获得更高质量的功能特征信息。其中,BERT结合了自注意力机制,可以获取每个词在描述向量生成过程的贡献,生成的服务功能向量优于doc2vec。因此,生成的服务功能向量在计算与标签的语义适配度时效果更佳。
TR-BERT在BERT生成的服务功能向量的基础上,融入了TextRank提取的关键词特征向量,是对BERT生成的服务功能向量的一种语义增强。TR-BERT生成的服务表征向量在标签推荐指标值上均比BERT模型有所提升,这说明提取关键词转换为特征向量对已有服务功能向量进行语义增强可以有效地提升标签推荐质量。
CWTR-BERT使用CW-TextRank,在TextRank进行关键词提取的过程中融入了语境权重,能够提升表达服务描述功能场景的特征词的提取能力。从表中数据可以看出,在所有轮次实验中,TR-BERT相对于BERT在accuracy与F1-score上平均提升4.26%与5.21%。CWTR-BERT在两种指标相对于BERT分别平均提升13%与13.14%。由此可见,融入了语境权重的CW-TextRank模型考虑关键词与服务描述功能的契合度,提高了服务功能向量的语义表达质量,有利于提升标签推荐精确度与合理性。
因此,对于Q1,实验证明了生成的服务表征向量用于标签推荐时,CWTR-BERT生成质量优于其他常用服务功能向量生成模型。
5.3 标签关联的引入对标签推荐质量的影响
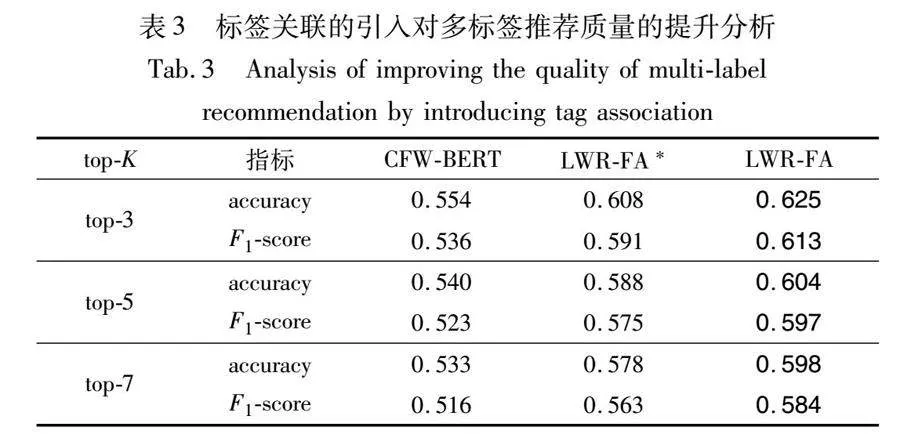
利用CWTR-BERT生成服务表征向量计算标签适配度是未引入标签关联的方法,本文方法LWR-FA是联合CWTR-BERT生成服务表征向量所计算获得的标签适配度和改进的GraphSAGE (融入标签边权处理)生成标签关联向量所获得的标签关联度共同实现标签推荐的方法。
为了验证引入标签关联以及在标签关联中区分关联边的权重对推荐质量的影响,将LWR-FA中标签关联向量替换为原始的GraphSAGE,替换后的标签推荐方法命名为LWR-FA*,LWR-FA*方法引入了标签关联,但在计算标签关联度时未考虑边权之间的关联权重。
表3给出了CWTR-BERT、LWR-FA*和LWR-FA在标签推荐时的性能对比,通过表中数据可以看出,在不同top-K的标签推荐中,LWR-FA*均显著高于CWTR-BERT,在top-3、top-5和top-7中,accuracy和F1-score分别提升了9.7%、8.9%、8.5%和10.3%、9.9%、9.1%。这说明引入标签关联后,可以有效提升Web服务标签的推荐精确性。通过对比LWR-FA*和LWR-FA,LWR-FA在top-3、top-5和top-7中的accuracy和F1-score分别提升了2.9%、2.8%、3.5%和3.7%、3.8%、3.8%,从而验证了在生成标签的关联向量时融入关联边的权重,有利于更合理地生成标签关联向量,提升标签的推荐质量。
因此,对于Q2,通过实验可以证明引入标签关联能够显著提升Web服务的标签推荐精确度,同时在生成标签关联向量时,融入标签之间的关联边权能够有效提高关联向量的质量,从而进一步提升标签推荐的精确度与合理性。
5.4 标签关联的引入对标签推荐质量的影响
本节将LWR-FA与近年来提出的Web服务标签推荐方法进行对比,主要包含以下方法:
a)SGM[27]:使用双向LSTM生成服务描述向量,使用注意力机制,获取目标服务描述中与待推荐标签语义相关度最高的部分对应的描述向量,结合上一步预测的标签词向量,得到当前步的预测标签,最后输出完整的预测标签序列。
b)GRU LabelsGen[14]:利用CNN提取Web服务的描述向量和每个词的序列向量,构建标签嵌入模型来获取标签特征向量。综合利用以上特征向量,使用GRU来推荐Web服务的标签序列。
c)DSRM-DNN[28]:结合词嵌入模型与聚类算法提取服务描述中的关键词,将词向量作为DSRM-DNN模型输出,结合深度信念网络和反向传播神经网络构建多标签文本分类器。
d)GAN-LABERT[7]:利用BERT生成服务描述向量,获取每个描述对标签向量生成的贡献。将标签向量通过MLP层输出不同标签的推荐概率。
e)TagTag[16]:分为标签推荐和标签调整两个环节。在标签推荐环节,将服务描述关键词向量和标签词向量输入MLP层,根据输出概率推荐标签;在标签调整环节,利用构建的服务与标签的组合图生成标签关联向量,综合服务的关键词向量、标签关联向量均值以及上一步推荐概率以推荐缺失的标签。
f)BCLAS[9]:利用BERT生成服务描述向量和标签的词向量,并使用CNN和双向LSTM的堆叠网络来进一步提取服务描述中的语义特征,通过注意力机制计算每个标签对服务描述向量生成的贡献,将优化后的描述向量输入MLP层,输出推荐概率。
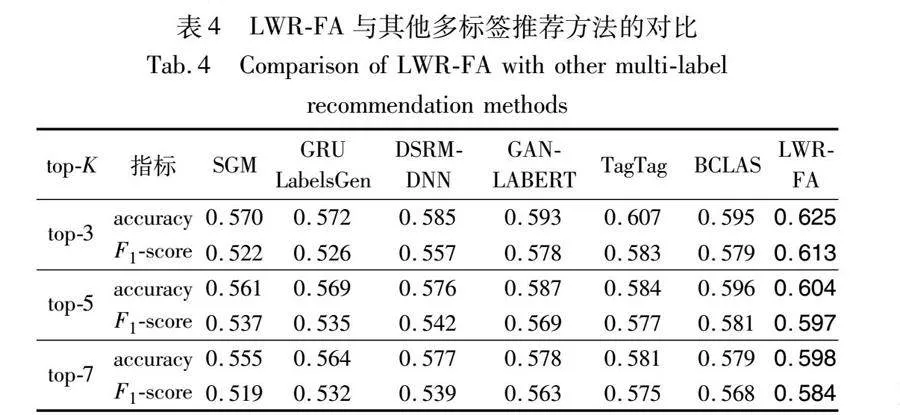
由表4数据对比可知,LWR-FA在不同轮次的top-K标签推荐实验中的评价指标均获得了最高分数。与其他六个方法相比,在accuracy上分别平均提升8.43%、7.2%、5.12%、3.92%、3.1%和3.22%,在F1-score上分别平均提升13.66%、12.65%、9.52%、4.91%、3.4%和3.82%。上述实验数据表明本文所提出的LWR-FA方法推荐的标签与服务自身标签的吻合程度高于当前流行的标签推荐方法。因此,对于Q3,本节实验表明LWR-FA的标签推荐质量皆优于对比方法。
相比对比方法,本文方法从服务功能向量生成、标签关联、候选标签集合三个层面进行了方法改进,通过引入功能特征词增加传统方法中生成的服务功能向量的语义特征区分度,可以更为精确地计算标签与服务之间的适配度。在标签关联中融入了关联边的边权,在标签关联向量生成过程中按照边权有区别的去聚合邻域节点的特征,使得标签之间的关联度计算更为合理。特别地,通过KNN确定待推荐标签中的主标签和候选标签集合,在降低推荐复杂度的同时可以提升推荐精确度。
5.5 实验关键超参数选择
本文使用改进的GraphSAGE生成标签关联向量,并依据KNN算法获取主标签和推荐标签集合。GraphSAGE聚合器的选择以及KNN中的邻居数量均会对最终的推荐质量产生影响,本节针对Q4展开实验验证。
5.5.1 改进的GraphSAGE聚合器选择
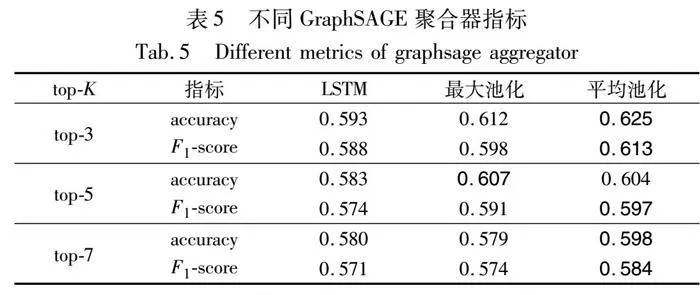
GraphSAGE共提供了LSTM聚合器、最大池化聚合器和平均池化聚合器三种聚合器。使用不同聚合器的LWR-FA方法在accuracy与F1-score评价指标的数据如表5所示。
在三种top-K推荐中,使用平均池化聚合器后,相对于LSTM聚合器和最大池化聚合器,在accuracy上分别平均提升4.02%与1.61%,在F1-score上分别平均提升3.47%与1.8%,说明在LWR-FA方法中,应用平均池化聚合器的效果最佳。
标签关联图中边密度高且关联复杂,最大池化聚合器对于邻居节点中最显著的特征敏感,对于包含多个重要邻居的标签节点的特征聚合效果差;LSTM聚合器计算复杂度较高,且对于较短的邻居序列无法发挥长序列建模优势。因此以上两种聚合器在聚合特征稳定性与有效性方面不如平均池化聚合器。
5.5.2 KNN最近邻算法中邻居值K的选择
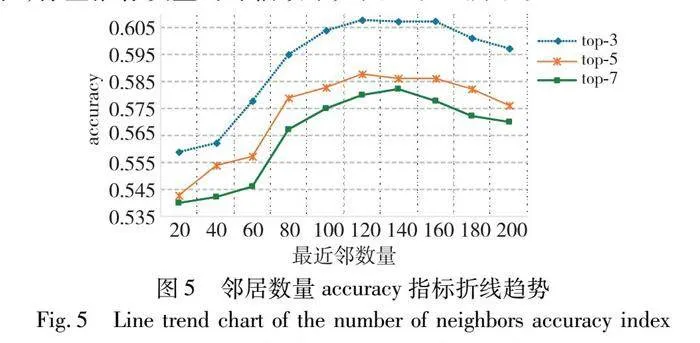
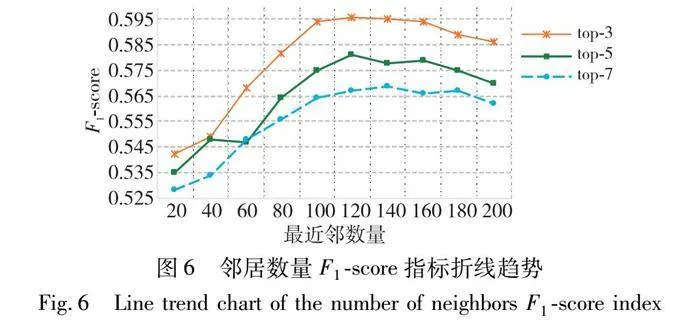
将KNN算法中的最近邻的数量设置如下:K={20, 40, 60, 80, 100, 120, 140, 160, 180, 200},使用LWR-FA方法开展实验,标签推荐质量的评估效果如图5和6所示。
由图5和6可见,在标签推荐时,随着邻居数量的增加,推荐指标在总体趋势上皆呈先上升,后缓慢下降的趋势。当邻居的数量在100~160时,accuracy与F1-score指标整体呈现出一个较高的分数区间,其中在邻居数量为120时,LRW-FA方法表现出最佳的性能。
标签推荐质量随着邻居的数量增加表现出先升后降的原因是:当参与主标签和候选标签集合的推荐的邻居较少时,主标签的准确度会受到影响,且因候选标签中数量少造成个别真实的推荐标签无法被包含在候选标签集合中,使得最终推荐精确度降低。当邻居数量过大时,会使得一些不相干的标签进入候选标签集合,从而影响最终的标签推荐质量。
6 结束语
本文提出一种面向功能语义增强与标签关联的Web服务标签推荐方法。采用CW-TextRank模型提取服务描述中的功能特征词,利用功能特征词增强服务功能向量的语义特征区分度,从标签与服务的适配度层面提高了标签的推荐精确度;构建服务标签关联图,采用改进的GraphSAGE模型为标签生成关联向量,完善了标签关联度的计算合理性;利用KNN算法生成推荐主标签和候选标签集合,建立了融合标签适配度和关联度的Web服务标签推荐方法,实现top-K标签推荐。实验表明,利用功能特征词增强服务功能语义和标签关联能够提升标签推荐的质量,文中所构建的方法在accuracy与F1-score指标上优于当前流行的标签推荐方法。
下一步的研究工作是从服务提供商和组合场景等角度拓展标签关联的范畴,以进一步提高标签推荐的精确度和合理性。
参考文献:
[1]Ju Chuanxiang,Ding Hangqi,Hu Benjia. A hybrid strategy improved whale optimization algorithm for Web service composition [J]. The Computer Journal,2023,66(3): 662-677.
[2]胡强,田雨晴,綦浩泉,等. 基于改进人工蜂群算法的云制造服务组合优化方法 [J]. 通信学报,2023,44(1): 200-210. (Hu Qiang,Tian Yuqing,Qi Haoquan,et al. Cloud manufacturing service combination optimization method based on improved artificial bee swarm algorithm [J]. Journal of Communications,2023,44(1): 200-210.)
[3]García D A,Palomo L F,Medina B I,et al. Computing performance requirements for Web service compositions [J]. Computer Stan-dards & Interfaces,2023,83: 103664.
[4]王振东,董开坤,黄俊恒,等. SemFA: 基于语义特征与关联注意力的大规模多标签文本分类模型 [J]. 计算机科学,2023,50(12): 270-278. (Wang Zhendong,Dong Kaikun,Huang Junheng,et al. SemFA: a large-scale multi-label text classification model based on semantic features and associative attention [J]. Computer Science,2023,50(12): 270-278.)
[5]Cao Yingcheng,Liu Jianxun,Cao Buqing,et al. Web services classification with topical attention based Bi-LSTM [C]// Proc of the 15th International Conference on Collaborative Computing: Networking,Applications and Worksharing. Berlin: Springer,2019: 394-407.
[6]Fletcher K K. An attention model for mashup tag recommendation [C]// Proc of the 17th International Conference,held as part of the Services Conference Federation. Berlin: Springer,2020: 50-64.
[7]Wang Qunbo,Wu Wenjun,Zhao Yongchi,et al. Combining label-wise attention and adversarial training for tag prediction of Web services [C]// Proc of ICWS. Piscataway,NJ: IEEE Press,2021: 358-363.
[8]Li Bing,Nong Xiuwen,Hou Yuxiang,et al. Multi-Label Web service classification using neural networks [C]// Proc of ICCECT. Piscataway,NJ: IEEE Press,2023: 540-544.
[9]赵鲸朋. 基于深度学习的层次化Web服务分类方法研究 [D]. 北京: 华北电力大学,2021. (Zhao Jingpeng. Research on hierarchical Web service classification method based on deep learning [D]. Beijing: North China Electric Power University,2021.)
[10]路凯峰,杨溢龙,李智. 一种基于BERT和DPCNN的Web服务分类方法 [J]. 广西师范大学学报: 自然科学版,2021,39(6): 87-98. (Lu Kaifeng,Yang Yilong,Li Zhi. A Web service classification method based on BERT and DPCNN [J]. Journal of Guangxi a90b1eb4f3040d23cfad6f674879c7f4Normal University: Natural Science Edition,2021,39(6): 87-98.)
[11]彭菲,潘国庆,任志考,等. 融合多通道语义信息与注意力机制的Web服务类别标签推荐 [J/OL]. 计算机集成制造系统. (2023-08-15). [2024-03-04]. http://kns. cnki. net/kcms/detail/11. 5946. TP. 20230815. 1410. 003. html. (Peng Fei,Pan Guoqing,Ren Zhikao,et al. Web service category tag recommendation based on fusion of multi-channel semantic information and attention mechanism [J/OL]. Computer Integrated Manufacturing Systems. (2023-08-15) [2024-03-04]. http://kns. cnki. net/kcms/detail/11. 5946. TP. 20230815. 1410. 003. html.)
[12]肖勇,刘建勋,胡蓉,等. 基于 GAT2VEC 的 Web 服务分类方法 [J]. 软件学报,2021,32(12): 3751-3767. (Xiao Yong,Liu Jianxun,Hu Rong,et al. Web service classification method based on GAT2VEC [J]. Journal of Software,2021,32(12): 3751-3767.)
[13]Shi Weishi,Liu Xumin,Yu Qi. Correlation-aware multi-label active learning for Web service tag recommendation [C]// Proc of ICWS. Piscataway,NJ: IEEE Press,2017: 229-236.
[14]Gan Yanglan,Xiang Yang,Zou Guobing,et al. Multi-label recommendation of Web services with the combination of deep neural networks [C]// Proc of the 15th International Conference on Collaborative Computing: Networking,Applications and Worksharing. Berlin: Springer,2019: 394-407.
[15]Shi Min,Liu Jianxun,Zhou Dong,et al. A topic-sensitive method for mashup tag recommendation utilizing multi-relational service data [J]. IEEE Trans on Services Computing,2018,14(2): 342-355.
[16]Chen Wentao,Liu Mingyi,Tu Zhiying,et al. TagTag: a novel framework for service tags recommendation and missing tag prediction [C]// Proc of ICSOC. Berlin: Springer,2022: 340-348.
[17]胡强,沈嘉吉,荆广辉,等. 基于描述语境特征词与改进 GSDMM 模型的服务聚类方法 [J]. 通信学报,2021,42(8): 176-187. (Hu Qiang,Shen Jiaji,Jing Guanghui,et al. Service clustering method based on description context feature words and improved GSDMM Model [J]. Journal on Communications,2021,42(8): 176-187.)
[18]Mihalcea R,Tarau P. Textrank: Bringing order into text [C]// Proc of EMNLP. 2004: 404-411.
[19]Gulati V,Kumar D,Popescu D E,et al. Extractive article summarization using integrated TextRank and BM25+algorithm [J]. Electronics,2023,12(2): 372.
[20]El Alaoui D,Riffi J,Sabri A,et al. Deep GraphSAGE-based recommendation system: jumping knowledge connections with ordinal aggregation network [J]. Neural Computing and Applications,2022,34(14): 11679-11690.
[21]Tang Bin,Yan Meng,Zhang Neng,et al. Co-attentive representation learning for Web services classification [J]. Expert Systems with Applications,2021,180: 115070.
[22]Pan Shirui,Wu Jia,Zhu Xingquan,et al. Tri-party deep network representation [C]// Proc of IJCAI. Palo Alto,CA: AAAI Press,2016: 12.
[23]Zhao Yi,Qiao Yu,He Keqing. A novel tagging augmented LDA model for clustering [J]. International Journal of Web Services Research,2019,16(3): 59-77.
[24]Yin Jianhua,Wang Jianyong. A Dirichlet multinomial mixture model-based approach for short text clustering [C]// Proc of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press,2014: 233-242.
[25]Dakhel A M,Desmarais M C,Khomh F. dev2vec: representing domain expertise of developers in an embedding space [J]. Information and Software Technology,2023,159: 107218.
[26]Devlin J,Chang M W,Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proc of the 17th Conference on the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapo-lis,New York: ACM Press,2019,1: 2.
[27]Yang Pengcheng,Sun Xu,Li Wei,et al. SGM: sequence generation model for multi-label classification [C]// Proc of the 27th International Conference on Computational Linguistics. 2018: 3915-3926.
[28]Wang Tianshi,Liu Naiwen,Zhang Huaxiang,et al. A multi-label text classification method via dynamic semantic representation model and deep neural network [J]. Applied Intelligence,2020,50(8): 2339-2351.
收稿日期:2024-01-17;修回日期:2024-03-06 基金项目:国家自然科学基金资助项目(61973180);云南省科技厅资助项目(202305AO350007,202305AP350017);云南省地方本科高校基础研究联合专项面上项目(202301BA070001-003,202001BA070001-197,202001BA070001-173);昆明学院引进人才项目(YJL2205);云南省昆明市院士专家工作站项目(YSZJGZZ-2022099);山东省重点研发计划软科学项目(2023RKY01009)
作者简介:刘庆雪(1980—),男,山东邹城人,副教授,博士,主要研究方向为智能制造、机器学习;王荔芳(1976—),女,云南宣威人,教授,主要研究方向为复杂系统建模与控制;潘国庆(1995—),男,山东莱州人,硕士,主要研究方向为服务计算;胡强(1980—),男(通信作者),山东邹城人,副教授,博导,博士,主要研究方向为服务计算、自然语言处理(huqiang200280@163.com).
