基于提示学习和超球原型的小样本ICD自动编码方法
2024-11-04徐春吉双焱马志龙



摘 要:
针对国际疾病分类(ICD)自动编码方法的长文本处理、编码的层次结构以及长尾分布等导致的模型泛化能力弱的问题,提出一种充分利用医学预训练语言模型的基于提示学习和超球原型的小样本ICD自动编码方法(hypersphere prototypical with prompt learning,PromptHP)。首先,将编码描述与临床文本融合进提示学习模型中的提示模板,使得模型能够更加深入地理解临床文本;然后,充分利用预训练语言模型的先验知识进行初始预测。接着,在预训练语言模型输出表示的基础上引入超球原型进行类别建模和度量分类,并在医学数据集上微调网络,充分纳入数据知识,提高模型在小样本ICD编码分配任务上的性能;最后,对以上两部分预测结果集成加权获得最终编码预测结果。公开医学数据集MIMIC-Ⅲ的实验结果表明,该模型优于最先进的基线方法,PromptHP将小样本编码的Macro-AUC、Micro-AUC、Macro-F1和Micro-F1分别提高了1.77%、1.54%、14.22%、15.01%。实验结果验证了该模型在小样本编码分类任务中的有效性。
关键词:自动ICD编码;小样本学习;提示学习;超球原型;预训练语言模型
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2024)09-015-2670-08
doi:10.19734/j.issn.1001-3695.2024.01.0031
Few-shot ICD automatic coding method based on prompt learning and hypersphere prototypes
Xu Chun, Ji Shuangyan, Ma Zhilong
(School of Information Management, Xinjiang University of Finance & Economics, rümqi 830012, China)
Abstract:
To address the issue of weak model generalization caused by processing long texts, hierarchical coding structures, and long-tailed distributions in international classification of diseases (ICD) automatic coding methods, this paper proposed the PromptHP method for few-shot ICD automatic coding, leveraging medical pre-trained language models. Firstly, the PromptHP method combined coding descriptions and clinical texts into the prompt template to improve the model’s comprehension of clinical texts. Then, it utilized the pre-trained language model’s prior knowledge for initial prediction. Next, it introduced the hypersphere prototypical onto the output representation of the pre-trained language model for category modeling and metric classification, while fine-tuning the network on the medical dataset to incorporate the data knowledge and improve the model’s performance on few-shot ICD coding classification tasks. Finally, it obtained the coding prediction results by integrating and weighting the two parts of the prediction results. Experimental results on the publicly available medical dataset MIMIC-Ⅲ demonstrate that PromptHP outperforms state-of-the-art baseline methods, increasing the Macro-AUC, Micro-AUC, Macro-F1, and Micro-F1 of few-shot coding by 1.77%, 1.54%, 14.22%, and 15.01%, respectively. The experimental results validate the effectiveness of the PromptHP method in few-shot coding classification tasks.
Key words:ICD automatic coding; few-shot learning; prompt learning; hypersphere prototypical; pre-trained language models
0 引言
国际疾病分类(international classification of diseases,ICD)是世界卫生组织制定的一种国际统一的疾病分类方法。它根据病因、病理、临床表现和解剖部位对疾病进行系统分类,以编码形式表示不同疾病。ICD编码任务是将一个或多个疾病编码分配给电子病历的过程,在提高病案管理效率、降低疾病诊断相关分组(DRGs)成本以及减少医疗费用损失等方面具有重要意义,已被广泛用于临床数据分析和健康问题监测等方面。然而,传统的人工分配编码方式对编码员的专业知识和经验积累要求很高,不仅费时费力,且容易出现差错。因此,为了提高ICD编码分配任务的效率和准确率,进行自动ICD编码研究十分有必要。
ICD自动编码是智能医学领域的重要基础任务,它被视为一项多标签文本分类任务。尽管许多研究尝试采用不同的方法来解决这一任务,从基于规则的方法到基于神经网络的方法,并在多个评估指标上取得了显著的改进,但仍有许多挑战需要解决。首先,ICD编码的长尾分布给研究带来了巨大挑战。在临床中,一些编码出现的频率很高(本文称为频繁编码——many-shot),如呼吸道感染和咳嗽,而大多数编码出现频率非常低(本文称为小样本编码——few-shot)。这种长尾分布使得模型在处理罕见疾病编码时面临着极度不平衡的训练数据,而传统的机器学习模型可能在这些罕见类别上表现不佳。其次,医生在撰写临床诊断时,往往会使用缩写和同义词,且ICD编码的层次结构会导致相同层次的疾病难以区分,这容易导致模型在分类时忽略重要信息。第三,临床记录往往拥有较长的字符序列。MIMIC-Ⅲ的出院摘要平均长度约为1 900个标记,而大多现有模型允许的最大输入长度为896个标记,如BERT和RoBERTa。医学长文本处理为ICD自动编码模型提出了更高要求。
小样本ICD自动编码是医学领域的一个重要研究课题。据统计,在医学数据集MIMIC-Ⅲ总共18 000多种ICD-9编码中,出现频率最高的前50种编码占总数据的93.1%[1],有限的训练样本是小样本ICD自动编码任务的瓶颈所在。对小样本编码的错误分配不仅会对患者带来不合理的经济负担,也会增加医疗机构的额外医疗资源开销。因此,本文认为研究小样本编码的准确预测具有重要意义。
随着预训练语言模型(pre-trained language models,PLMs)的发展,如何更有效地挖掘模型内部已学习到的知识成为当前研究的热点之一。提示学习(prompt learning)通过设计适当的提示使模型适配下游任务,被认为是一种能够充分利用模型内部知识的方法,已被证明在多种自然语言处理任务中具有显著效果[2]。
针对上述问题,提出基于医学PLM的融合提示学习和超球原型的ICD自动编码方法PromptHP(hypersphere prototypical with prompt learning)。首先,通过构建融合编码描述与临床文本的提示模板作为模型输入,能够有效挖掘医学PLM中丰富的医学知识,提高模型对上下文的理解能力。其次,加载医学预训练语言模型KEPTlongformer(knowledge enhanced promp tuning)[3]进行编码和初始预测,充分利用其蕴涵的医学常识、同义词、缩写以及编码的层次结构等内部知识,训练过程中冻结预训练模型参数。接着,在KEPTlongformer预训练语言模型输出表示的基础上引入超球原型建模类别表示并进行度量分类,采用交叉熵损失函数进行监督并优化。最后,将度量得分与校准后的PLM预测得分进行集成加权获得最终编码预测结果。其不仅有效利用了模型内部知识,也充分利用了下游小样本数据知识,使得PromptHP在ICD编码分类任务上获得更好的性能。
1 相关工作
1.1 ICD编码
ICD自动编码是医学NLP领域的一项重要任务。自20世纪90年代初以来,基于规则的方法被提出,以帮助专业编码员提高编码分配效率。这些规则大多由领域专家根据医学指南制定,通过字符串匹配或常规匹配查询关键字或短语来分配ICD编码,包括正则表达式[4]、逻辑表达式[5]、字典[6]。基于规则的方法简单而有效,但在实际使用时严重依赖于人为参与,且准确率不高,因此不能扩展到更一般的情况。
传统机器学习兴起后,许多研究人员将ICD编码问题重新定义为一个文本分类问题。通过单词袋(BoW)计数或TF-IDF(term frequency-inverse document frequency)方法提取特征,并建立分类模型实现了用于ICD自动编码的传统机器学习方法,如K-最近邻(KNN)[7]、随机森林[8]和支持向量机(SVM)[9]。传统基于机器学习方法的关键是特征的构建和选择。Perotte等人[10]以TF-IDF得到的关键词为特征,提出了FlatSVM和基于层次的SVM两种模型。传统机器学习方法都是独立地预测每个编码,忽略了编码之间的相关性,没有考虑词语的上下文关系,不能很好地对内容丰富的临床文本进行表示。
近年来,随着深度学习的不断发展,将递归神经网络(RNN)[11]、卷积神经网络(CNN)[12]、图神经网络(GNN)[13]等深度神经网络应用于ICD自动编码越来越受到关注。Mullenbach等人[12]利用注意力机制将卷积神经网络(CNN)与每个编码相结合。Xu等人[8]构建了一个包含CNN、LSTM和决策树的混合系统,从非结构化、半结构化和结构化的表格数据中预测ICD编码。此外,Lipton等人[14]利用LSTM从临床测量的时间序列中预测疾病编码,而本文侧重于文本数据。
1.2 小样本学习
以往研究大多侧重于提高频繁编码的分类性能,而忽略了小样本编码。Rios等人[15]最先关注到小样本ICD自动编码,提出利用ICD层次结构信息来提高小样本和零样本编码的性能。Yang等人[16]利用交叉注意力机制和提示学习实现小样本ICD编码的多标签分类。文献[17]提出多任务原型网络,通过改进度量网络提高模型小样本分类性能。同时,各种元学习算法[18]也被提出以解决小样本学习问题,包括基于度量学习的方法[19]、基于优化的方法[20]和基于增强学习的方法[21]。经典的原型网络方法[19]将原型建模为嵌入空间中的点,可能导致模型无法有效区分不同类别的微妙差异,尤其是在类别内部变异较大的情况下。受Ding等人[22]的启发,本文将原型建模为具有额外半径参数的超球体,通过引入额外的半径参数,每个类别的原型以超球体的形式存在于嵌入空间中,从而更好地捕捉和表示类别内部的特征分布。由于医疗数据常常具有高度异质性和复杂性,采用超球原型可以在提高模型精度的同时保持模型的泛化能力和可解释性。
提示学习被证明在小样本任务中是有效的[23,24],即使在语言模型相对较小的情况下[25]。因为其在小样本学习中没有引入新的参数。以往的研究大多集中在单标签多分类任务上,如情绪分类[23]、临床ICD-9分诊[26],本文将提示学习用于ICD自动编码的多标签分配任务中,在不影响整体分类性能的前提下,提高模型的小样本编码分配性能。
2 模型构建
ICD自动编码通常被定义为一个多标签分类任务。给定一段输入的临床文本矩阵x,目标是为编码空间L={l1,l2,…,lNc}中的每个ICD编码分配一个二进制标签yi∈{0,1},其中,Nc为ICD编码数量,1代表该输入文本x对于编码li所代表的疾病是阳性的。每个候选编码都有一个简短的编码描述ci。例如,编码403.11的描述为:“Hypertensive chronic kidney disease, benign, with chronic kidney disease stage V or end stage renal disease.”编码描述c是Nc个ci的集合。
2.1 模型结构
如图1所示,PromptHP模型主要由四部分组成,分别为融合编码描述的提示学习、KEPTlongformer特征提取、超球原型度量分类、集成学习与预测。在提示学习部分,将编码描述和临床文本以模板形式T(x)结合,作为模型的输入,并构造一个答案空间的映射,用于将KEPTlongformer的预测结果映射回真实标签。在特征提取阶段,使用封装好的提示模板查询KEPTlongformer,获得包含模型内部知识的初始类别预测得分s=SM(T(x))和临床文本的隐藏表示h。超球原型度量分类部分,加入可学习的中心向量和半径参数构造超球原型,通过计算样本表示和原型表面的欧氏距离获得包含数据知识的类别k的预测得分d(h,k)。在集成学习与预测部分,使用集成函数g(·)对两部分预测得分进行加权,获得类别k的最终得分q(x,k),并使用softmax函数计算出每个标签的预测概率。计算公式为
3 实验设置
3.1 环境配置
实验所采用配置如下:Windows10实验平台,64位操作系统;CPU为Xeon Gold 6 330;GPU为NVIDIA A100,80 GB显存;Python版本为3.8;PyTorch版本为1.9;CUDA版本为11.1。
3.2 数据集
3.2.1 数据介绍
使用公共医学数据集MIMIC-Ⅲ[30]来评估本文模型,该数据集是公开可用的最大的EHR数据集,其中收录了重症监护病房的4万多名患者的临床记录。每个临床记录都由医疗编码员分配了一组最相关的ICD-9编码。本文遵循Yang等人[3]的方法对含有52 722份出院摘要和8 929个不同编码的MIMIC-Ⅲ数据集进行预处理,通过对文本进行分词处理,统一将所有标记转换为小写形式,删除符号和纯字符,同时使用“<NUM>”标记替换不包含字母字符的标记,以提高数据的一致性和可处理性。相比传统BERT系列模型将出院摘要截断为896个标记,本文将出院摘要截断为8 192个标记,能够更全面地捕捉出院摘要中的关键信息,提高ICD编码的准确性。
3.2.2 数据划分
本文共创建3个数据集用于对比分析,分别为MIMIC-Ⅲ-full、MIMIC-Ⅲ-50和MIMIC-Ⅲ-rare50,并根据患者编号(subject_id)和病案号(hadm_id)将各数据集划分为训练集、验证集和测试集。各数据集具体情况如下:
a)MIMIC-Ⅲ-full数据集。根据患者编号和病案号对52 722份出院摘要进行划分,得到MIMIC-Ⅲ-full数据集,其中47 719份出院摘要用于训练,1 631份用于验证,3 372份用于测试。由于本文模型会为每个候选编码构造一个编码描述和[MASK]标记,不能直接应用于包含8 929个标签的ICD编码任务中,这很容易突破模型最大字符限制和GPU内存限制。所以对于MIMIC-Ⅲ-full数据集的实验,本文首先使用MSMN模型[31]选择出前300个候选编码,然后使用本文模型进行最终预测。
b)MIMIC-Ⅲ-50数据集。采用Vu等人[32]的方式得到出现频率最高的前50个频繁编码数据集MIMIC-Ⅲ-50,共包括11 317份出院摘要,其中8 067份用于训练,1 574份用于验证,1 730份用于测试。
c)MIMIC-Ⅲ-rare50数据集。遵循先前关于小样本分类任务的研究,创建一个小样本编码数据集MIMIC-Ⅲ-rare 50。首先在MIMIC-Ⅲ-full测试集的4 075种不同的ICD编码中,筛选在训练集中的数据示例≤5且至少出现一次的编码,共筛选出685个小样本编码,然后按照每个编码出现在测试集示例数/训练集示例数的比例由高到低对筛选后的编码进行排名,按照最终排名选择前50个编码构成MIMIC-Ⅲ-rare 50数据集,以确保评估过程中有足够的测试数据用于性能评估。该数据集共包括516份出院摘要,其中249份用于训练,125份用于验证,142份用于测试。表1列出了各数据集的具体划分结果,包括各数据集训练集、验证集和测试集的总文档数;文档平均token数;token小于512、4 096、8 192的文档数;文档包含的平均编码数。
3.3 基线模型
CAML(convolutional attention network for multi-label classification)[12]:利用CNN和标签注意力机制来预测临床文本的ICD编码。
MultiResCNN(multi-filter residual convolutional neural network)[33]:利用多过滤器卷积层对文本进行编码,并利用一个剩余卷积层来扩大接受域。
AGM-HT(adversarial generative model conditioned on code descriptions with hierarchical tree structure)[34]:利用ICD编码的层次结构,为零样本的编码生成语义上有意义的特征来实现ICD编码的广义零样本多标签文本分类。
JointLAAT(label attention model with hierarchical joint learning)[32]:提出一种具有训练目标的分层联合学习机制来预测临床文本的ICD编码预测。
MSMN(multiple synonyms matching network)[31]:将LSTM作为编码器,利用多同义词注意力机制实现ICD编码分类。
GPsoap(generation with prompt)[16]:利用交叉注意力机制和提示学习实现ICD编码的多标签分类。
3.4 评价指标
为了与先前关于ICD自动编码的研究进行比较,使用F1值、曲下面积(area under curve,AUC)的宏平均(macro-average)和微平均(micro-average),以及P@k(precision at k)来评估本文模型,具体计算方法如式(17)~(21)所示。其中,“宏平均”单独计算每个类别的性能指标,然后对所有标签的指标取平均。“微平均”是将所有标签的混淆矩阵合并,然后在合并的数据上计算有效性指标。P@k指前k个预测编码的精度。AUC指受试者操作特征(receiver operating characteristic,ROC)曲线下的面积,反映了分类器对样本的排序能力。AUC的值越接近1,代表分类器的性能越好。
4 结果与分析
4.1 实验结果
表3展示了各模型在MIMIC-Ⅲ-full上的实验结果。可以看出,本文模型在所有指标上均优于对比模型。与最优基线模型MSMN相比,PromptHP在Macro-AUC、Micro-AUC、Macro-F1和Micro-F1上分别提升了0.8%、0.1%、0.6%和2.1%,在P@5和P@15上分别提升了3.7%和2.1%,说明PromptHP在提升小样本编码分类性能的同时没有降低频繁编码的分类性能。
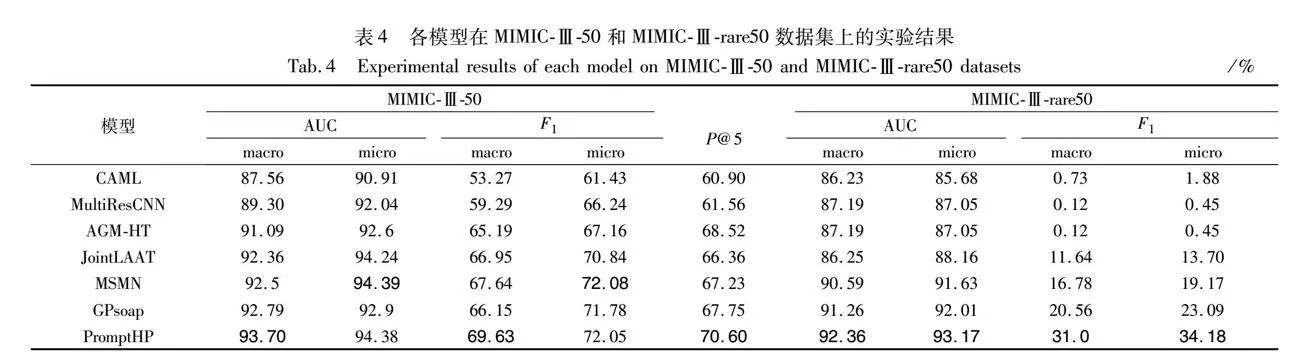
表4列出了各模型在MIMIC-Ⅲ-50和MIMIC-Ⅲ-rare50上的实验结果。在基于MIMIC-Ⅲ-50的实验中,与最优基线模型MSMN相比,PromptHP在Macro-AUC、Macro-F1和P@5方面分别产生了1.2%、1.99%和3.37%的提升。但在Micro-AUC和Micro-F1值上与MSMN基本持平,这是由于MIMIC-Ⅲ-50的数据分布不平衡所导致,其中某些类别样本量远多于其他类别,微观指标会受到频繁样本类别性能的影响。在基于MIMIC-Ⅲ-rare50的实验中,PromptHP在所有指标上均优于MSMN,并在Macro-AUC、Micro-AUC、Macro-F1和Micro-F1上分别取得了1.77%、1.54%、14.22%、15.01%的提升。与以往的方法相比,宏观结果比微观方法有更显著的改进。这是由于宏观指标主要受尾部编码性能的影响,所提方法得益于提示学习和超球原型度量分类在小样本学习中表现出的优异性能。
4.2 消融实验
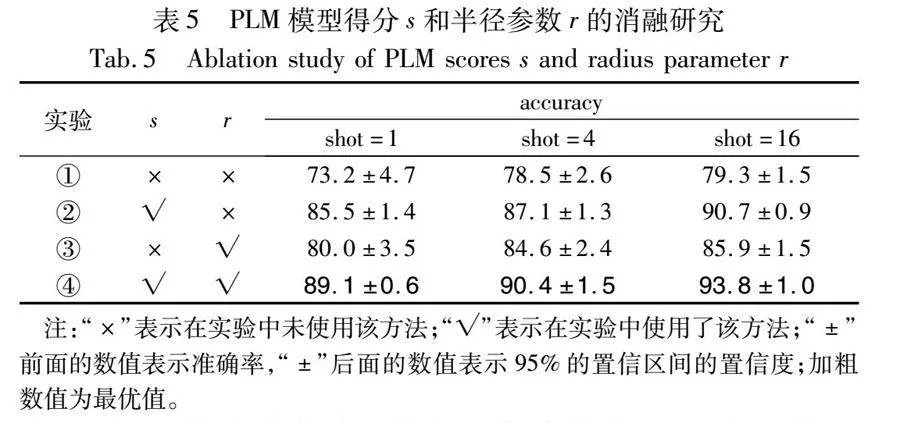
为验证PLM和超球原型对模型的作用,分别在基于MIMIC-Ⅲ-rare50的5-way-1-shot、5-way-4-shot和5-way-16-shot设置下进行消融研究,对每个实验设定5个随机种子,并用平均准确率和标准差指标进行评估。实验结果如表5所示,表中s表示PLM预测得分,r表示超球原型的半径参数。实验①表示仅使用原型网络进行分类;实验②表示使用PLM和原型网络进行分类;实验③表示仅使用超球原型网络进行分类;实验④表示使用本文模型进行实验。
a)PLM的消融实验。从表5实验①②中可以看出,使用PLM相较于仅使用原型网络在MIMIC-Ⅲ-rare50的5-way-1-shot、5-way-4-shot和5-way-16-shot设置下进行分类的准确率分别提升了12.3%、8.6%和11.4%,说明所选医学PLM能够提升小样本分类的性能。同时,从实验③④也可以看出,使用PLM后,模型比仅使用超球原型的分类准确率分别提升了9.1%、5.8%和7.9%,在训练数据非常稀缺(1-shot)的情况下模型性能提升很大,这说明模型得分包含了对医学言语理解有益的先验模型知识,验证了PLM在PromptHP的小样本性能中的积极作用。此外,整合训练数据减少了方差。随着训练数据的增多,PLM得分带来的增益减少,这是由于PLM和HyperProto得分的相对权重发生了变化。
b)超球原型的消融实验。从表5实验①③中可以看出,超球原型相较于原型网络在MIMIC-Ⅲ-rare50的5-way-1-shot、5-way-4-shot和5-way-16-shot设置下进行分类的准确率分别提升了6.8%、6.1%和6.6%,说明超球原型能够提升小样本分类的性能。同时,从实验②④可以看出,使用超球原型进行度量之后,模型分类的准确率分别提升了3.6%、3.3%和3.1%,进一步验证了在小样本的情况下,超球原型半径r的加入可以提升模型的分类性能。同时,随着训练数据的增加,超球原型对模型的稳定性也起到一定的积极作用,验证了超球原型半径参数r的引入有助于捕捉更多ICD编码类别信息,提高PromptHP的泛化性。
c)从表5中数据可以看出,同时使用PLM和超球原型的性能优于单独使用其中一项,进一步说明了本文提出的PLM和超球原型是相辅相成、相互促进的。
4.3 复杂度分析
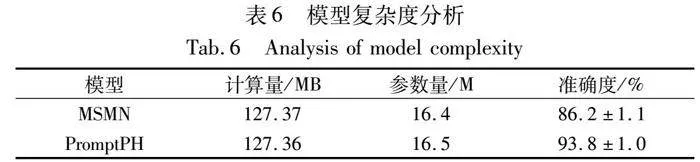
为证明本文方法的可应用性,对最优基线方法MSMN和本文方法PromptHP进行复杂度分析。通过网络结构分析工具torchsummary计算各方法的参数量和计算量。计算量即模型的时间复杂度,是指输入单个样本(一个临床文本),模型完成一次前向传播所发生的浮点运算次数,即FLOPs。在MIMIC-Ⅲ-rare50数据集上进行5-way-16-shot实验,实验结果如表6所示。
从表6可以看出,PromptHP相较于基线模型MSMN的参数量增加了0.1 M,时间复杂度提升了0.01 MB,在性能上却有显著提升。可以看出,本文方法在增加少量参数和时间复杂度的基础上,可以较大地提升模型性能。
4.4 超球原型对结果的影响
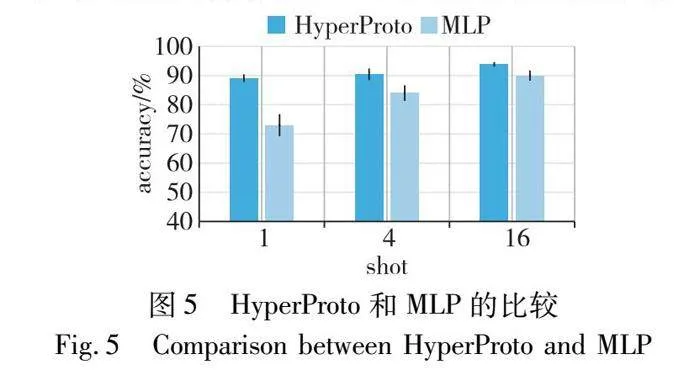
为了验证在PLM输出端建模超球原型进行度量分类对模型小样本分类性能的影响,本文采用一个两层MLP替换HyperProto并在MIMIC-Ⅲ-rare50的1-shot、4-shot和16-shot设置下进行准确率和稳定性评估,结果如图5所示。可以看出,在1-shot设置中,HyperProto明显优于MLP,这与HyperProto在小样本学习中的优势相符。在4-shot和16-shot实验中,Hyper-Proto准确率仍然较高,但差距较小。在稳定性方面,HyperProto能够保持较低的标准差分数。总体而言,HyperProto是PromptHP中的一个关键组成部分,用MLP替换会降低模型性能。
4.5 PLM对结果的影响
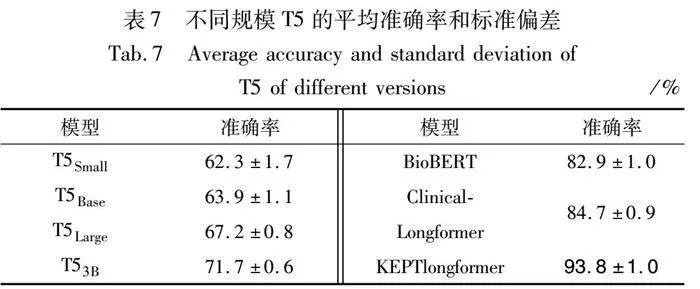
为了测试不同PLM对模型整体的影响,分别选择通用领域预训练语言模型T5[35]、医学预训练语言模型BioBERT[36]、Clinical-Longformer[27]和KEPTlongformer进行对比,其中T5模型包括T5Small、T5Base、T5Large和T53B等不同规模。通过在各PLM输出端建模超球原型,在基于MIMIC-Ⅲ-rare50的5-way-16-shot设置下评估各PLM性能。对每个实验设定5个随机种子,表7呈现了不同规模T5和医学PLM的平均准确率和标准偏差。从表7可以看出:
a)3个医学PLM相比通用领域的T5模型具有更高的准确率和较小的偏差,这验证了医学PLM早期学到的专业医学知识对小样本ICD自动编码任务的有效性。
b)相较于BioBERT和Clinical-Longformer,KEPTlongformer的平均准确率分别提高了10.9百分点和9.1百分点,在小样本ICD编码分配任务中具有更出色的表现,验证了KEPTlongformer中丰富的医学同义词、缩写以及层次结构知识对编码分配任务的正向作用。
c)从4种规模的T5模型的实验结果可以观察到一个明显的规模效应,更大的模型表现得也更好。
d)本文将超球原型部署在编码器-解码器生成式语言模型T5上并进行实验对比,验证了在PLM输出端建模超球原型的可迁移性。
4.6 λ对结果的影响
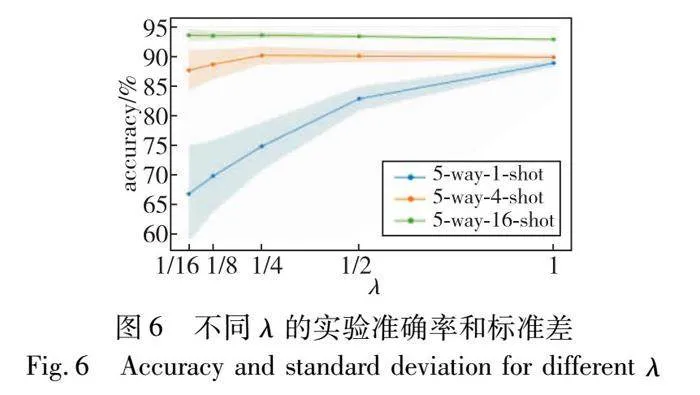
作为超参数,λ控制PLM分数和超球原型度量得分的相对重要性。在基于MIMIC-Ⅲ-rare50数据集的5-way-1-shot、5-way-4-shot和5-way-16-shot设置下评估λ对PromptHP的影响。从图6可以观察到:
a)λ在1-shot设置中对PromptHP有很大影响。随着λ的增加,PromptHP逐渐表现得更好且更稳定,这说明在极端小样本情况下,PLM内部知识对于模型性能具有重要作用。
b)随着样本数量的增加,λ的变化对模型性能的影响减弱,达到最佳效果所需的样本数量减少,说明λ可以有效地平衡PLM模型内部知识和下游数据知识之间的权重,优化模型分类性能,验证了3.5节中选择策略的有效性。
4.7 可视化实验
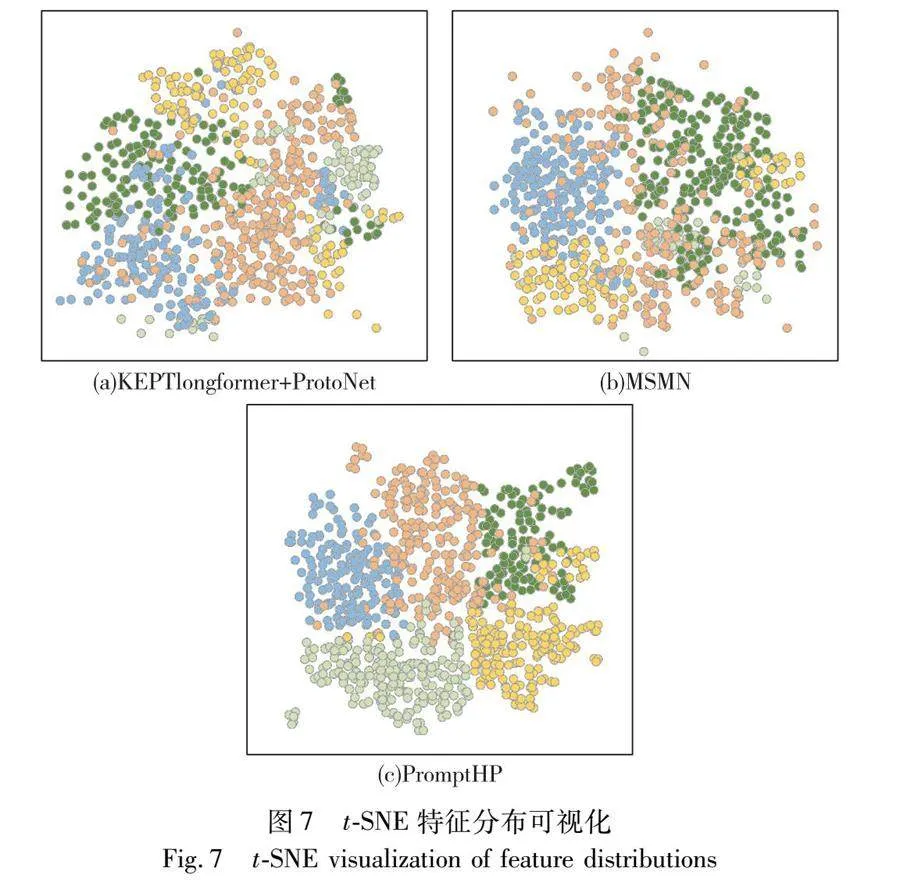
为验证本文方法的有效性,分别对KEPTlongformer+ ProtoNet、MSMN和本文方法生成的特征使用t-SNE进行可视化分析。具体来说,在MIMIC-Ⅲ-rare50数据集的训练集和测试集中各抽取5个类别,每个类别随机选择100个样本,图7(a)(b)和(c)分别展示了KEPTlongformer+ProtoNet、MSMN和PromptHP在二维空间中嵌入的t-SNE可视化结果,不同颜色代表不同的类别。从图7(b)(c)的对比可以看出,PromptHP的类内距离更小,类间区分更加明显,也产生了一些新类别的聚类,证明本文方法学习到的文本特征优于基线模型MSMN,具有更好的聚类性能。
此外,通过计算每个类别样本到其对应类别原型的平均欧几里德距离以及到其他类别的距离之间的差异来比较两种模型的样本区分度。差异越大,样本区分度越好。对于ProtoNet,训练集和测试集的差异分别为2.41和1.36;对于PromptHP,结果分别为5.17和4.82。这是由于不同类别的样本分布在不同的维度上,额外的超球半径参数有助于更好地区分不同的类别,与图7(a)和图7(c)的反映结果一致。t-SNE可视化和统计结果证明了PromptHP在学习区分性特征方面的有效性,在学习新类别表示方面的积极作用也显著提升了本文方法在小样本学习中的分类性能。
5 结束语
提出了一种基于医学预训练模型的融合提示学习和超球原型的多标签小样本ICD自动编码模型PromptHP,主要贡献包括:a)设计包含ICD编码描述的提示模板作为新的输入,充分挖掘医学预训练语言模型内部知识;b)在预训练语言模型输出端建模超球原型,充分利用下游数据知识,提高了模型在处理小样本分类任务中的泛化性。三个数据集上的实验结果表明,本文方法能够有效结合预训练语言模型内部知识和下游数据知识,并能够在大多数指标上优于目前主流的编码分配模型,尤其是在小样本学习时,性能提升较大,多组消融实验也证实了本文方法的有效性。同时,在PLM输出端建模超球原型同样适用于其他医学数据分析任务,如临床实体链接任务(entity linking,EL)。此外,由于采用的编码描述提示学习需要为每个ICD编码创建编码描述和[MASK]标记,直接应用于包含8 692个标签的ICD编码任务容易突破模型最大字符限制和GPU内存限制,在保证分类性能的前提下探索一种更加节省内存的自动ICD编码方法是未来的研究重点。
参考文献:
[1]Teng Fei,Liu Yiming,Li Tianrui,et al. A review on deep neural networks for ICD coding [J]. IEEE Trans on Knowledge and Data Engineering,2022,35(5): 4357-4375.
[2]王培冰,张宁,张春. 基于Prompt的两阶段澄清问题生成方法 [J]. 计算机应用研究,2024,41(2): 421-425. (Wang Peibing,Zhang Ning,Zhang Chun. Two-stage clarification question generation method based on Prompt [J]. Application Research of Compu-ters,2024,41(2): 421-425.)
[3]Yang Zhichao,Wang Shufan,Rawat B P S,et al. Knowledge injected prompt based fine-tuning for multi-label few-shot ICD coding [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: ACL,2022: 1767-1781.
[4]Zhou Linging,Cheng Cheng,Ou Dong,et al. Construction of a semi-automatic ICD-10 coding system [J]. BMC Medical Informatics and Decision Making,2020,20(1): 1-12.
[5]Farkas R,Szarvas G. Automatic construction of rule-based ICD-9-CM coding systems [J]. BMC Bioinformatics,2008,9(3): S10.
[6]Nunzio G M D,Beghini F,Vezzani F,et al. A lexicon based approach to classification of ICD10 codes. IMS Unipd at CLEF eHealth Task 1 [C]// Proc of CEUR Workshop. Germany: CEUR-WS Press,2017:1-9.
[7]Huang Mengxing,Han Huirui,Wang Hao,et al. A clinical decision support framework for heterogeneous data sources [J]. IEEE Journal of Biomedical and Health Informatics,2018,22(6): 1824-1833.
[8]Xu Keyang,Lam M,Pang Jingzhi,et al. Multimodal machine learning for automated ICD coding [C]// Proc of Machine Learning for Healthcare Conference. New York: PMLR,2019: 197-215.
[9]Schfer H,Friedrich C M. UMLS mapping and word embeddings for ICD code assignment using the MIMIC-Ⅲ intensive care database [C]// Proc of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Piscataway,NJ: IEEE Press,2019: 6089-6092.
[10]Perotte A,Pivovarov R,Natarajan K,et al. Diagnosis code assignment: models and evaluation metrics [J]. Journal of the American Medical Informatics Association,2014,21(2): 231-237.
[11]Blanco A,Perez A,Casillas A. Extreme multi-label ICD classification: sensitivity to hospital service and time [J]. IEEE Access,2020,8: 183534-183545.
[12]Mullenbach J,Wiegreffe S,Duke J,et al. Explainable prediction of medical codes from clinical text [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: ACL,2018: 1101-1111.
[13]Zhou Jie,Cui Ganqu,Hu Shengding,et al. Graph neural networks: a review of methods and applications [J]. AI Open,2020,1(2): 57-81.
[14]Lipton Z C,Kale D C,Elkan C,et al. Learning to diagnose with LSTM recurrent neural networks [C]// Proc of the 4th International Conference on Learning Representations. Washington DC: ICLR,2016: 1-18.
[15]Rios A,Kavuluru R. Few-shot and zero-shot multi-label learning for structured label spaces [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: ACL,2018: 3132-3142.
[16]Yang Zhichao,Kwon S,Yao Zonghai,et al. Multi-label few-shot ICD coding as autoregressive generation with prompt [C]// Proc of the 37th AAAI Conference on Artificial Intelligence and the 35th Confe-rence on Innovative Applications of Artificial Intelligence and the 13th Symposium on Educational Advances in Artificial Intelligence. Palo Alto,CA: AAAI Press,2023: 5366-5374.
[17]于俊杰,程华,房一泉. 少样本文本分类的多任务原型网络 [J]. 计算机应用研究,2022,39(5): 1368-1373. (Yu Junjie,Cheng Hua,Fang Yiquan. Multiple-task prototypical network for few-shot text classification [J]. Application Research of Computers,2022,39(5): 1368-1373.)
[18]周晓敏,滕飞,张艺. 基于元网络的自动国际疾病分类编码模型 [J]. 计算机应用,2023,43(9): 2721-2726. (Zhou Xiaomin,Teng Fei,Zhang Yi. Automatic international classification of diseases coding model based on meta-network [J]. Journal of Computer Applications,2023,43(9): 2721-2726.)
[19]Snell J,Swersky K,Zemel R. Prototypical networks for few-shot learning [C]// Proc of the 31st International Conference on Neural Information Processing Systems. San Diego: NIPS,2017: 4080-4090.
[20]Finn C,Abbeel P,Levine S. Model-agnostic meta-learning for fast adap-tation of deep networks [C]// Proc of the 34th International Conference on Machine Learning. New York: ACM Press,2017: 1126-1135.
[21]Ding Bosheng,Liu Linlin,Bing Lidong,et al. DAGA: data augmentation with a generation approach for low-resource tagging tasks [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: ACL,2020: 6045-6057.
[22]Ding Ning,Chen Yulin,Cui Ganqu,et al. Few-shot classification with hypersphere modeling of prototypes [C]// Proc of Findings of the Association for Computational Linguistics. Stroudsburg,PA: ACL,2022: 895-917.
[23]Gao Tianyu,Fisch A,Chen Danqi. Making pre-trained language models better few-shot learners [C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg,PA: ACL,2020: 3816-3830.
[24]Brown T,Mann B,Ryder N,et al. Language models are few-shot learners [J]. Advances in Neural Information Processing Systems,2020,33: 1877-1901.
[25]Schick T,Schyuyutze H. It’s not just size that matters: small language models are also few-shot learners [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: ACL,2020: 2339-2352.
[26]Taylor N,Zhang Yi,Joyce D W,et al. Clinical prompt learning with frozen language models [J]. IEEE Trans on Neural Networks and Learning Systems,2023 (99): 1-11.
[27]Li Yikuan,Wehbe R M,Ahmad F S,et al. Clinical-longformer and clinical-BigBird: transformers for long clinical sequences [EB/OL]. (2022-01-27) [2024-03-25]. https://doi. org/10. 48550/arXiv. 2201. 11838.
[28]Sun Haitian,Dhingra B,Zaheer M,et al. Open domain question answering using early fusion of knowledge bases and text [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: ACL,2018: 4231-4242.
[29]Zhao Zihao,Wallace E,Feng Shi,et al. Calibrate before use: improving few-shot performance of language models [C]// Proc of the 38th International Conference on Machine Learning. New York: ACM Press,2021: 12697-12706.
[30]Johnson A E W,Pollard T J,Shen L,et al. MIMIC-Ⅲ,a freely accessible critical care database [J]. Scientific Data,2016,3(1): 1-9.
[31]Yuan Zheng,Tan Chuanqi,Huang Songfang. Code synonyms do matter: multiple synonyms matching network for automatic ICD coding [C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: ACL,2022: 808-814.
[32]Vu T,Nguyen D Q,Nguyen A. A label attention model for ICD coding from clinical text [C]// Proc of the 29th International Joint Confe-rence on Artificial Intelligence. San Francisco: Morgan Kaufmann,2020: 3335-3341.
[33]Li Fei,Yu Hong. ICD coding from clinical text using multi-filter residual convolutional neural network [C]// Proc of the 34th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2020: 8180-8187.
[34]Song Congzheng,Zhang Shanghan,Sadoughi N,et al. Generalized zero-shot text classification for ICD coding [C]// Proc of the 29th International Conference on International Joint Conferences on Artificial Intelligence. San Francisco: Morgan Kaufmann,2021: 4018-4024.
[35]Raffel C,Shazeer N,Roberts A,et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. The Journal of Machine Learning Research,2020,21(1): 5485-5551.
[36]Lee J,Yoon W,Kim S,et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining [J]. Bioinformatics,2020,36(4): 1234-1240.
收稿日期:2024-01-29;修回日期:2024-03-20 基金项目:国家自然科学基金资助项目(62266041);新疆自然科学基金资助项目(2023D01A73)
作者简介:徐春(1977—),女,贵州毕节人,教授,硕导,博士,CCF会员,主要研究方向为自然语言处理、大数据分析;吉双焱(1999—),女(通信作者),山西运城人,硕士研究生,主要研究方向为自然语言处理、医疗数据分析(18003482889@163.com);马志龙(1983—),男(东乡族),新疆塔城人,讲师,硕士,主要研究方向为医疗大数据分析.
