基于互信息解决多标签文本分类中的长尾问题
2024-11-04潘理虎李小华张睿谢斌红杨楠张林梁




摘 要:
针对当前解决多标签文本分类中长尾问题的方法多以破坏原本数据分布为代价,在真实数据上的泛化性能下降,无法有效地缓解样本的长尾分布的问题,提出了基于互信息解决长尾问题的多标签文本分类方法(MLTC-LD)。首先,创建关于标签样本的关系矩阵,计算标签样本间的依赖关系;其次,考虑标签样本间关系程度的强弱构造邻居选择器,将拥有强关系的邻居信息作为主要语义特征并作为先验信息;最后,通过图注意力神经网络将先验信息引入分类器,实现了借助分布头部数据丰富类的知识来提高尾部数据贫乏类的性能的目标。在三个不同的数据集上将MLTC-LD与八个基线模型进行了广泛的比较分析。实验结果表明,MLTC-LD 与最优的HGLRN方法相比精确度分别提高了3.5%、0.3%、1.5%,证明了该方法的有效性。
关键词:多标签文本分类;长尾问题;互信息;先验信息
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)09-014-2664-07
doi:10.19734/j.issn.1001-3695.2023.12.0623
Addressing long-tail problem in multi-label text classification based on mutual information
Pan Lihu1, Li Xiaohua1, Zhang Rui1, Xie Binhong1, Yang Nan1, Zhang Linliang2
(1.College of Computer Science & Technology, Taiyuan University of Science & Technology, Taiyuan 030024, China; 2.Institute of Information Technology, Shanxi Institute of Transportation Science, Taiyuan 030006, China)
Abstract:
To address the long-tail problem in multi-label text classification (MLTC) where current methods often compromise the original data distribution, resulting in reduced generalization performance on real data and ineffective mitigation of the long-tail distribution issue, this paper proposed a method of multi-label text classification with long-tail distribution (MLTC-LD). Initially, it created a relationship matrix for label samples to compute dependencies between label samples. Then, considering the degree of relationships between label samples, it constructed a neighbor selector, which used information from neighbors with strong relationships as the main semantic features and as prior information. Finally, by incorporating this prior information through a graph attention neural network into the classifier, the method aimed to enrich the knowledge of categories with abundant head data to improve the performance of categories with sparse tail data. An extensive comparative analysis of MLTC-LD with eight baseline models across three different datasets was conducted. The experimental results show that MLTC-LD improves precision by 3.5%, 0.3%, and 1.5% respectively, compared to the best-performing HGLRN method, demonstrating the effectiveness of this approach.
Key words:multi-label text classification(MLTC); long-tail problem; mutual information; prior information
0 引言
多标签文本分类(MLTC)是自然语言处理中一项基本任务,旨在使用适当的分类器为给定的文本分配多个标签,例如一则新闻“最近一部科幻电影在票房上取得巨大成功,该电影的特效和深刻的社会主题引发了公众的热烈讨论”主要是关于电影的描述,属于“娱乐”类别;电影涉及科幻元素,属于“科技”类别,同时,电影探讨的社会主题可归类于“社会”类别,因此该新闻文本可被标注“娱乐”“科技”“社会”三个标签。该范式在标签推荐[1]、信息检索[2]和情感分析[3]等不同领域得到了广泛应用。
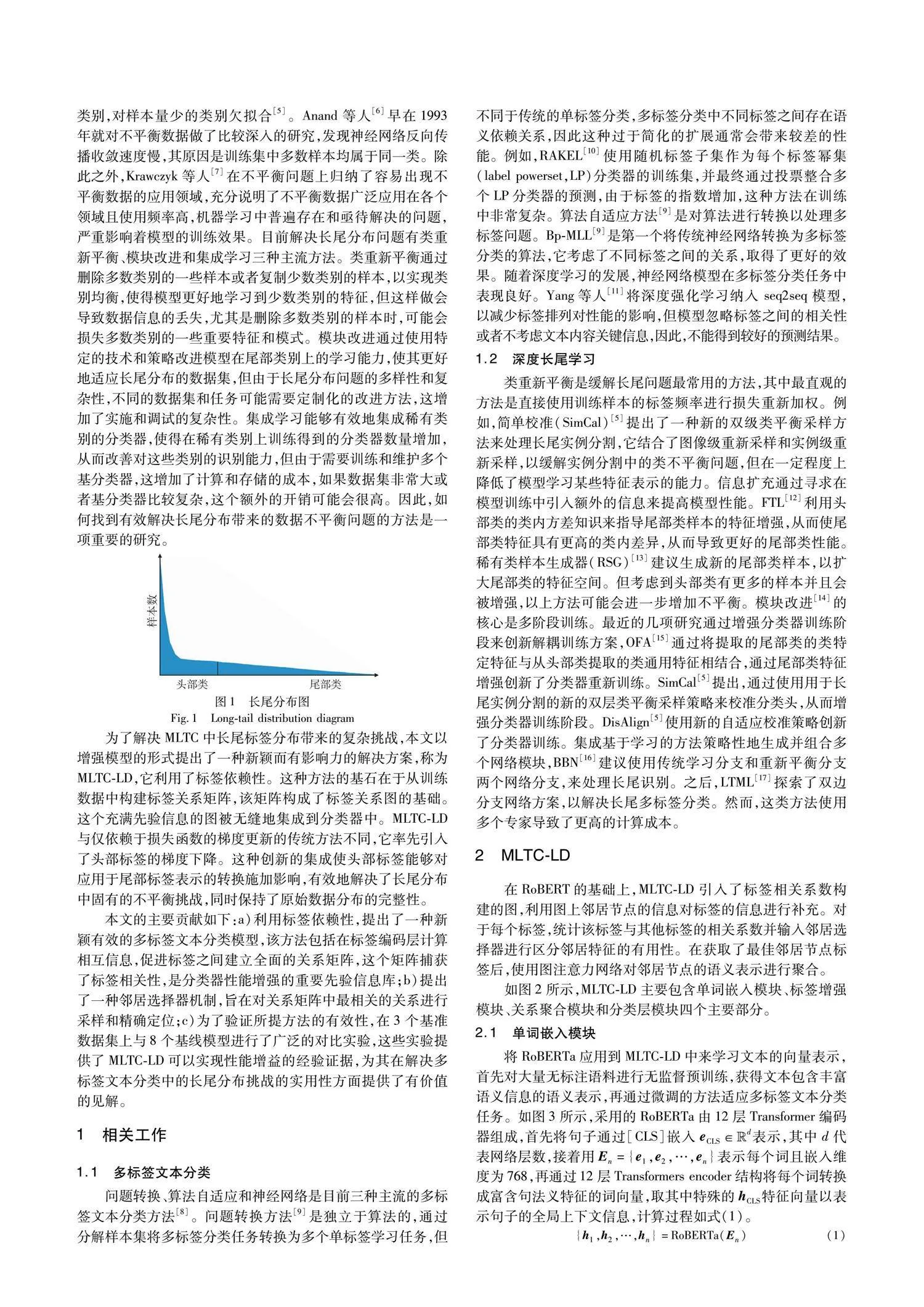
现如今的文本分类模型严重依赖于数据分布,训练样本各类别往往假设是同等数量,即各类样本数目是均衡的,但是在实际应用中,不平衡数据普遍存在,其中大型数据集通常呈现如图1所示的长尾标签分布[4]。在文本分类中,长尾模式可能意味着有一些非常特定或罕见的类别,这些类别的样本数量很少,但类别种类繁多。以具体例子来说:在一个产品评论的数据集中,大多数评论可能集中在几个主要类别,如“电子产品”“家居用品”,而像“稀有藏品”“古董书籍”这样的类别虽然类别多,但每个类别的评论数量很少。其会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,这给深度学习模型的训练带来了巨大的挑战。无论是传统的机器学习,还是如今流行的深度学习都是采用训练误差最小化的原则从假设空间中求取最优解,例如采用梯度下降的方法,这一过程对于分布均衡的数据集来说,是不存在问题的,然而对于存在长尾分布的样本来说,训练出来的模型更偏向于样本量大的类别,对样本量少的类别欠拟合[5]。Anand等人[6]早在1993年就对不平衡数据做了比较深入的研究,发现神经网络反向传播收敛速度慢,其原因是训练集中多数样本均属于同一类。除此之外,Krawczyk等人[7]在不平衡问题上归纳了容易出现不平衡数据的应用领域,充分说明了不平衡数据广泛应用在各个领域且使用频率高,机器学习中普遍存在和亟待解决的问题,严重影响着模型的训练效果。目前解决长尾分布问题有类重新平衡、模块改进和集成学习三种主流方法。类重新平衡通过删除多数类别的一些样本或者复制少数类别的样本,以实现类别均衡,使得模型更好地学习到少数类别的特征,但这样做会导致数据信息的丢失,尤其是删除多数类别的样本时,可能会损失多数类别的一些重要特征和模式。模块改进通过使用特定的技术和策略改进模型在尾部类别上的学习能力,使其更好地适应长尾分布的数据集,但由于长尾分布问题的多样性和复杂性,不同的数据集和任务可能需要定制化的改进方法,这增加了实施和调试的复杂性。集成学习能够有效地集成稀有类别的分类器,使得在稀有类别上训练得到的分类器数量增加,从而改善对这些类别的识别能力,但由于需要训练和维护多个基分类器,这增加了计算和存储的成本,如果数据集非常大或者基分类器比较复杂,这个额外的开销可能会很高。因此,如何找到有效解决长尾分布带来的数据不平衡问题的方法是一项重要的研究。
为了解决MLTC中长尾标签分布带来的复杂挑战,本文以增强模型的形式提出了一种新颖而有影响力的解决方案,称为MLTC-LD,它利用了标签依赖性。这种方法的基石在于从训练数据中构建标签关系矩阵,该矩阵构成了标签关系图的基础。这个充满先验信息的图被无缝地集成到分类器中。MLTC-LD与仅依赖于损失函数的梯度更新的传统方法不同,它率先引入了头部标签的梯度下降。这种创新的集成使头部标签能够对应用于尾部标签表示的转换施加影响,有效地解决了长尾分布中固有的不平衡挑战,同时保持了原始数据分布的完整性。
本文的主要贡献如下:
a)利用标签依赖性,提出了一种新颖有效的多标签文本分类模型。该方法包括在标签编码层计算相互信息,促进标签之间建立全面的关系矩阵。这个矩阵捕获了标签相关性,是分类器性能增强的重要先验信息库。
b)提出了一种邻居选择器机制,旨在对关系矩阵中最相关的关系进行采样和精确定位。
c)为了验证所提方法的有效性,在3个基准数据集上与8个基线模型进行了广泛的对比实验。这些实验提供了MLTC-LD可以实现性能增益的经验证据,为其在解决多标签文本分类中的长尾分布挑战的实用性方面提供了有价值的见解。
1 相关工作
1.1 多标签文本分类
问题转换、算法自适应和神经网络是目前三种主流的多标签文本分类方法[8]。问题转换方法[9]是独立于算法的,通过分解样本集将多标签分类任务转换为多个单标签学习任务,但不同于传统的单标签分类,多标签分类中不同标签之间存在语义依赖关系,因此这种过于简化的扩展通常会带来较差的性能。例如,RAKEL[10]使用随机标签子集作为每个标签幂集(label powerset,LP)分类器的训练集,并最终通过投票整合多个LP分类器的预测,由于标签的指数增加,这种方法在训练中非常复杂。算法自适应方法[9]是对算法进行转换以处理多标签问题。Bp-MLL[9]是第一个将传统神经网络转换为多标签分类的算法,它考虑了不同标签之间的关系,取得了更好的效果。随着深度学习的发展,神经网络模型在多标签分类任务中表现良好。Yang等人[11]将深度强化学习纳入 seq2seq模型,以减少标签排列对性能的影响,但模型忽略标签之间的相关性或者不考虑文本内容关键信息,因此,不能得到较好的预测结果。
1.2 深度长尾学习
类重新平衡是缓解长尾问题最常用的方法,其中最直观的方法是直接使用训练样本的标签频率进行损失重新加权。例如,简单校准(SimCal)[5]提出了一种新的双级类平衡采样方法来处理长尾实例分割,它结合了图像级重新采样和实例级重新采样,以缓解实例分割中的类不平衡问题,但在一定程度上降低了模型学习某些特征表示的能力。信息扩充通过寻求在模型训练中引入额外的信息来提高模型性能。FTL[12]利用头部类的类内方差知识来指导尾部类样本的特征增强,从而使尾部类特征具有更高的类内差异,从而导致更好的尾部类性能。稀有类样本生成器(RSG)[13]建议生成新的尾部类样本,以扩大尾部类的特征空间。但考虑到头部类有更多的样本并且会被增强,以上方法可能会进一步增加不平衡。模块改进[14]的核心是多阶段训练。最近的几项研究通过增强分类器训练阶段来创新解耦训练方案,OFA[15]通过将提取的尾部类的类特定特征与从头部类提取的类通用特征相结合,通过尾部类特征增强创新了分类器重新训练。SimCal[5]提出,通过使用用于长尾实例分割的新的双层类平衡采样策略来校准分类头,从而增强分类器训练阶段。DisAlign[5]使用新的自适应校准策略创新了分类器训练。集成基于学习的方法策略性地生成并组合多个网络模块,BBN[16]建议使用传统学习分支和重新平衡分支两个网络分支,来处理长尾识别。之后,LTML[17]探索了双边分支网络方案,以解决长尾多标签分类。然而,这类方法使用多个专家导致了更高的计算成本。
2 MLTC-LD
在RoBERT的基础上,MLTC-LD引入了标签相关系数构建的图,利用图上邻居节点的信息对标签的信息进行补充。对于每个标签,统计该标签与其他标签的相关系数并输入邻居选择器进行区分邻居特征的有用性。在获取了最佳邻居节点标签后,使用图注意力网络对邻居节点的语义表示进行聚合。
如图2所示,MLTC-LD主要包含单词嵌入模块、标签增强模块、关系聚合模块和分类层模块四个主要部分。
3.3 对比实验
3.3.1 基线模型
为了充分验证本文方法的有效性,选择以下8个基线模型进行对比实验:
a)LSAN[23]是基于标签语义注意力学习特定于标签的文本表征;
b)CNN[24]主要利用卷积神经网络来学习密集的特征矩阵以捕获文本局部语义信息;
c)CNN-RNN[25]使用CNN和RNN获得局部和全局语义,并对标签之间的关系进行建模;
d)RoBERTa[26]由Facebook AI于2019年发布,是BERT的改进版本,使用更大的文本语料库进行预训练,更好地捕捉了语言的各种模式和特性;
e)SGM[27]为一种将多标签分类任务视为序列生成任务的模型,并将seq2seq用作多类分类器;
f)AttentionXML[28]利用多标签注意力机制捕获每个标签最相关的文本;
g)Labeled-LDA[29]通过使用词-标签概率获取文本中词与标签之间的相关性信息;
h)HGLRN[30]提出了一种用于多标签文本分类的层级图标签表示网络。
3.3.2 对比结果
本文MLTC-LD在AAPD和RCV1-V2基准数据集上分别进行了实验,实验结果如表4所示,表中黑体字表示结果最优。从中可以看出,本文模型在AAPD和RCV1-V2数据集上的性能显著优于所有基线模型,特别是在RCV-V2数据集上表现突出。
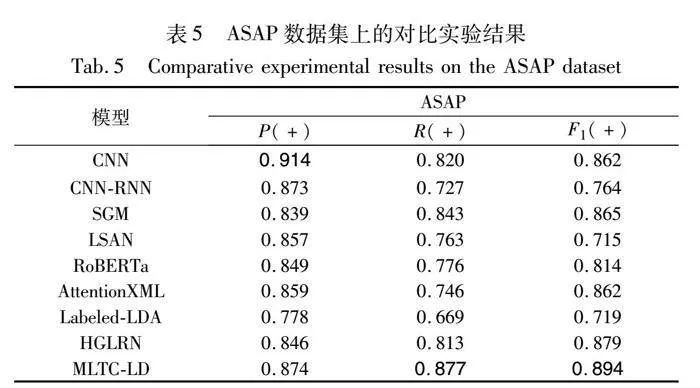
本文MLTC-LD在情感分析数据集ASAP上与基线模型的实验结果如表5所示。从实验结果可以看出,本文模型在ASAP上相较于其他基线模型整体上有明显的提升,特别是在R以及F1两个指标上取得了最好的性能,在P指标上排名仅次于CNN,证明了MLTC-LD在情感分析应用领域上是有效的,以此证明了MLTC-LD的泛化能力。
综合方面来看,CNN-RNN、SGM、LSAN、RoBERTa、AttentionXML、Labeled-LDA和HGLRN这7个对比模型相比于MLTC-LD较差,原因在于这7个模型均没有将全局标签之间的依赖关系考虑进去,因为ASAP和AAPD总词数少、类别较为明确,在挖掘文本深层次语义信息与标签的关联程度的过程中容易造成过拟合,导致模型在测试集上降低了文本的预测精度,所以对于更侧重于文本语义挖掘的CNN相较于其他模型在ASAP和AAPD上学习效率更高,在所有的对比模型中精确率指标占最大优势。相反,在RCV1-V2上,虽然各模型的分类效果都显著提升,但MLTC-LD却优于所有对比模型,主要因为MLTC-LD在捕获标签之间的关联性之外还对关联性的特征进行了筛选以获取最相关的语义信息,所以MLTC-LD模型是优越的。
3.4 消融实验
为了对MLTC-LD的整体效果进行研究,本文针对标签关系矩阵、邻居选择器、标签语义注意力三个添加模块进行消融实验。
3.4.1 验证标签关系矩阵的有效性
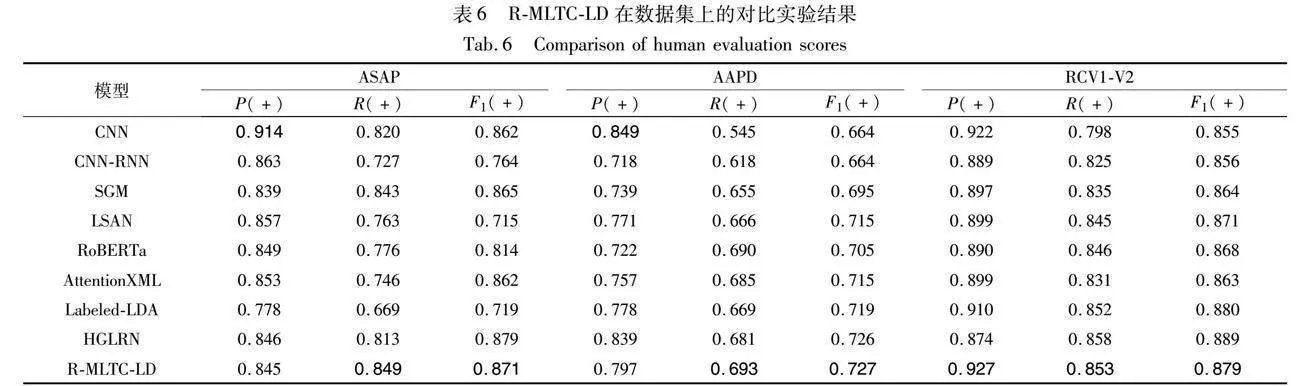
本文研究引入了R-MLTC-LD,该模型仅包含标签关系矩阵,在ASAP、AAPD和RCV1-V2数据集上和8个基线模型之间进行了比较实验,结果如表6所示。研究结果表明,R-MLTC-LD在F1得分方面优于基线模型。这种改进可归因于R-MLTC-LD从文本中捕获全局信息并学习不同标签之间的依赖关系的能力。因此,R-MLTC-LD有效地补充了尾部标签类别的语义信息,证明了整合标签关系矩阵对模型分类性能的有益影响。
3.4.2 验证邻居选择器的有效性
本文构建SR-MLTC-LD模型表示在R-MLTC-LD基础上引入邻居选择器,在ASAP、AAPD和RCV1-V2数据集上分别与R-MLTC-LD进行对比实验,实验结果如表7所示,从中可知,相比于R-MLTC-LD,SR-MLTC-LD在P、R与 F1上分别提升 1.1、0.9、0.5;3.0、2.2、0.9;1.1、1.8、0.4 个百分点,这是因为SR-MLTC-LD可以有效区分邻居特征的有用性,避免了高噪声的引入,同时也进一步表明邻居选择器对模型的分类性能有一定优化作用。
3.4.3 验证标签语义注意力的有效性
本文构建SR-GAT模型表示在SR-MLTC-LD基础上引入标签语义注意力,即MLTC-LD中的注意力模块,在ASAP、AAPD和RCV1-V2数据集上分别与SR-MLTC-LD进行对比实验,实验结果如表8所示。从中可知,相比于SR-MLTC-LD,SR-GAT在P、R与F1上分别提升 1.8、1.9、1.8;3.0、1.5、2.5;1.1、2.5、0.9个百分点,这是因为MLTC-LD模块通过注意力机制对标签关系图结构数据中每个标签节点与其邻居标签节点做聚合操作,促进了全局标签之间的紧密连接关系,更好地学习出标签特征信息表示,从而提高模型的整体性能。
综上所述,融合标签关系矩阵、引入邻居选择器、标签语义注意力可使得模型效果有所改善,说明本文MLTC-LD在整体上是更有效的。
4 结束语
本文提出了一种新方法来解决MLTC中长尾分布问题带来的复杂挑战。主要贡献是引入了一种图结构,它通过无缝地结合来自相邻节点的见解,成为丰富标签信息的有力工具。标签之间精确关系系数的计算,加上邻居选择器的应用,使本文方法能够有效地识别最佳邻居节点标签。实验结果基于对三个不同数据集的评估,展现了MLTC-LD在有效解决长尾问题方面的显著性能优势。
参考文献:
[1]Widyasari R,Zhao Zhipeng,Cong T L,et al. Topic recommendation for github repositories: how far can extreme multi-label learning go? [C]// Proc of IEEE International Conference on Software Analysis,Evolution and Reengineering. Piscataway,NJ: IEEE Press,2023: 167-178.
[2]Hambarde K A,Proena H. Information retrieval: recent advances and beyond[J]. IEEE Access,2023,11: 76581-76604.
[3]Chen Lei,Wang Tianqi. Utilizing contrastive learning to address long tail issue in product categorization[C]// Proc of the 31st ACM International Conference on Information and Knowledge Management. New York: ACM Press,2022: 5081-5082.
[4]Zhang Wenqiao,Liu Changshuo,Zeng Lingze,et al. Learning in imperfect environment: multi-label classification with long-tailed distribution and partial labels[C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2023: 1423-1432.
[5]Wang Tao,Li Yu,Kang Bingyi,et al. The devil is in classification: a simple framework for long-tail instance segmentation[C]// Proc of the 16th European Conference on Computer Vision. Berlin: Springer,2020: 728-744.
[6]Anand R,Mehrotra K G,Mohan C K,et al. An improved algorithm for neural network classification of imbalanced training sets[J]. IEEE Trans on Neural Networks,1993,4(6): 962-969.
[7]Krawczyk,Bartosz. Learning from imbalanced data: open challenges and future directions[J]. Progress in Artificial Intelligence,2016,5(4): 221-232.
[8]Liu Xuying,Wu Jianxin,Zhou Zhihua,et al. Exploratory undersampling for class-imbalance learning[J]. IEEE Trans on Systems,2009,39(2): 539-550.
[9]Zhang Minling,Zhou Zhihua. A review on multi-label learning algorithms[J]. IEEE Trans on Knowledge and Data Engineering,2014,26(8): 1819-1837.
[10]Tsoumakas G,Vlahavas I. Random k-labelsets: an ensemble method for multi-label classification[J]. Pattern Recognition,2007,109: 107583.
[11]Yang Pengcheng,Luo Fuli,Ma Shuming,et al. A deep reinforced sequence-to-set model for multi-label classification[C]// Proc of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2019: 5252-5258.
[12]Xi Yin,Xiang Yu,Sohn K,et al. Feature transfer learning for face recognition with under-represented data[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2019: 5697-5706.
[13]Wang Jianfeng,Lukasiewicz T,Hu Xiaolin,et al. RSG: a simple but effective module for learning imbalanced datasets[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 3783-3792.
[14]Huang Yi,Buse G,Abdullatif K,et al. Balancing methods for multil-abel text classifification with long-tailed class distribution[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2021: 8153-8161.
[15]Chu Peng,Bian Xiao,Liu Shaopeng,et al. Feature space augmentation for long-tailed dataC]// Proc of the 16th European Conference on Computer Vision. Berlin: Springer,2020: 694-710.
[16]Zhang Songyang,Li Zeming,Yan Shipeng,et al. Distribution alignment: a unified framework for long-tail visual recognition[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 2361-2370.
[17]Zhou Boyan,Cui Quan,Wei Xiushen,et al. BBN: bilateral-branch network with cumulative learning for long-tailed visual recognition [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 9716-9725.
[18]Guo Hao,Wang Song. Long-tailed multi-label visual recognition by collaborative training on uniform and rebalanced samplings[C]// Proc of Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 15089-15098.
[19]Ren Yuyang,Zhang Haonan,Yu Peng,et al. Ada-MIP: adaptive self-supervised graph representation learning via mutual information and proximity optimization[J]. ACM Trans on Knowledge Discovery from Data,2023,17(5): article No. 69.
[20]Bu Jiahao,Ren Lei,Zheng Shuang,et al. ASAP: a Chinese review dataset towards aspect category sentiment analysis and rating prediction[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo-gies. Stroudsburg,PA: Association for Computational Linguistics,2021: 2069-2079.
[21]Yang Pengcheng,Sun Xu,Li Wei,et al. SGM: sequence generation model for multi-label classification[C]// Proc of the 27th International Conference on Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2018: 3915-3926.
[22]Lewis D D,Yang Yiming,Rose T G,et al. RCV1: a new benchmark collection for text categorization research[J]. Journal of Machine Learning Research,2004,3(4): 361-397.
[23]Xiao Lin,Chen Boli,Huang Xin,et al. Multi-label text classification method based on label semantic information[J]. Journal of Software,2020,31(4): 1079-1089.
[24]Jacovi A,Shalom O S,Goldberg Y. Understanding convolutional neural networks for text classification[C]// Proc of EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Stroudsburg,PA: Association for Computational Linguistics,2018: 56-65.
[25]Liu Jingzhou,Chang Weicheng,Wu Yuexin,et al. Deep learning for extreme multi-label text classification[C]// Proc of the 40th International ACM SIGIR Conference. New York,NY: ACM Press,2017: 115-124.
[26]Liu Yinhan,Ott M,Goyal N,et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019-07-26). https://arxiv.org/abs/1907.11692.
[27]Yang Pengcheng,Sun Xu,Li Wei,et al. SGM: sequence generation model for multi-label classification[C]// Proc of International Conference on Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2018: 3915-3926.
[28]You Ronghui,Zhang Zihan,Wang Ziye,et al. AttentionXML: label tree-based attention-aware deep model for high-performance extreme multi-label text classification[C]// Proc of the 33rd International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2019: 820-5830.
[29]赵宏,郑厚泽,郭岚. 基于词-标签概率的多标签文本分类研究[J]. 兰州理工大学学报,2023,49(1): 103-109. (Zhao Hong,Zhen Houze,Guo Lan. Multi-label text classification based on word-label probability[J]. Journal of Lanzhou University of Technology,2023,49(1): 103-109.)
[30]徐江玲,陈兴荣. 基于层级图标签表示网络的多标签文本分类[J]. 计算机应用研究,2023,41(2): 388-392,407. (Xu Jiangling,Chen Xingrong. Multi-label text classification based on hierarchical graph label representation network[J]. Application Research of Computers,2023,41(2): 388-392,407.)
收稿日期:2023-12-23;修回日期:2024-02-19 基金项目:山西省自然科学基金资助项目(201901D111258);山西省智能软件与人机环境系统研究生联合培养示范基地项目(2022JD11);山西省留学人员管理委员会资助项目
作者简介:潘理虎(1974—),男,河南上蔡人,教授,博导,博士,CCF会员,主要研究方向为深度学习与人工智能;李小华(1998—),女(通信作者),山西长治人,硕士,主要研究方向为自然语言处理、多标签文本分类(1328162431@qq.com);张睿(1987—),男,山西太原人,副教授,硕导,博士,主要研究方向为智能信息处理;谢斌红(1971—),男,山西太原人,副教授,硕导,硕士,主要研究方向为智能化软件和机器学习;杨楠,男,山西太原人,硕士,主要研究方向为深度学习;张林梁,男,山西太原人,博士,主要研究方向为机器学习.
