面向异构数据的个性化联邦多任务学习优化方法
2024-11-04李可王晓峰王虎



摘 要:
联邦学习是一种新兴的分布式机器学习范式,在保护数据隐私的同时协作训练全局模型,但也面临着在数据异构情况下全局模型收敛慢、精度低的问题。针对上述问题,提出一种面向异构数据的个性化联邦多任务学习优化(federated multi-task learning optimization,FedMTO)算法。在包含全局任务和本地任务的多任务学习框架下,考虑个性化联邦优化问题。首先,FedMTO采用参数分解的思想,通过学习自适应分类器组合权重来协调全局分类器和局部分类器,提取全局分类器知识,实现对本地任务的个性化建模;其次,由于本地任务的数据分布不同,FedMTO在本地更新时结合正则化多任务学习策略,关注任务之间的相关性,减小不同本地任务间的差异,从而保证联邦学习过程的公平性;最后,模拟不同的数据异构场景,在MNIST和CIFAR-10数据集上进行实验。实验结果表明,与现有算法相比,FedMTO实现了更高的准确率和更好的公平性,验证了该方法针对联邦学习中的异构数据问题有着良好的效果。
关键词:联邦学习;异构数据;个性化;多任务学习;参数分解;公平性
中图分类号:TP181 文献标志码:A 文章编号:1001-3695(2024)09-011-2641-08
doi:10.19734/j.issn.1001-3695.2024.01.0006
Personalized federated multi-task learning optimization method for heterogeneous data
Li Kea, Wang Xiaofenga, b, Wang Hua
(a.School of Computer Science & Engineering, b. The Key Laboratory of Images & Graphics Intelligent Processing of State Ethnic Affairs Commission, North Minzu University, Yinchuan 750021, China)
Abstract:
Federated learning, a novel distributed machine learning paradigm, collaboratively trains a global model while preserving data privacy. It faces challenges of slow convergence and low accuracy in the global model under data heterogeneity. Aiming at the problem, the paper proposed a personalized federated multi-task learning optimization (FedMTO) algorithm tailored for heterogeneous data. In a multi-task learning framework that included global and local tasks, it considered the personalized federated optimization problem. Initially, FedMTO adopted the idea of parameter decomposition, coordinating global and local classifiers through the learning of adaptive classifier combination weights. This process extracted knowledge from global classifiers to achieve personalized modeling for local tasks. Furthermore, due to the varying data distributions of local tasks, FedMTO incorporated a regularization multi-task learning strategy during local updates. This approach focused on the relevance between tasks to reduce the differences among various local tasks, thus ensuring fairness in the federated learning process. Finally, experiments were conducted on the MNIST and CIFAR-10 datasets under different data heterogeneity scenarios. The results demonstrate that compared with existing algorithms, FedMTO achieves higher accuracy and better fairness, verifying the effectiveness of this method in addressing heterogeneous data problems in federated learning.
Key words:federated learning(FL); heterogeneous data; personalization; multi-task learning; parameter decomposition; fairness
0 引言
在大数据时代,物联网和网络应用的快速发展导致网络边缘生成了呈现指数级增长的数据[1]。传统的机器学习模型建立在集中式训练大量数据之上,由深度神经网络(Deep Neural Networks,DNNs)实现。然而,现实中的数据往往由于隐私保护、行业竞争等限制[2],导致数据汇合于一处,面临着巨大的挑战,使得集中式的模型训练方式在现实场景中越发不可行。
在上述背景下,具备数据隐私保护特点的机器学习方法受到了更多的关注。联邦学习(Federated Learning,FL)[3]应运而生,作为一种新兴的人工智能基础技术,FL在2016年由谷歌(Google)首次提出,即一种客户端(包含设备、节点、组织、传感器)在中央服务器的协调下,在确保不会交换泄露客户端的本地私有数据的前提下,由多个参与方合作训练机器学习模型的范式。联邦学习有效地打破了隐私安全限制带来的数据壁垒,充分地利用了数量庞大的网络边缘设备。
然而,FL存在着局限性,客户端上的数据通常是以非独立同分布(Non-Independent Identically Distributed,Non-IID)的异构形式呈现的[4]。异构数据场景包括特征分布倾斜、标签分布倾斜、数量分布倾斜等[5]。在上述FL场景中聚合出的全局模型表现不佳,极大地影响了FL算法的收敛性。一种有效的应对方案是针对本地任务,训练局部个性化模型,即个性化联邦学习(Personalized Federated Learning,pFL)。pFL算法要能够解决数据的异构问题,并在模型的训练过程中灵活地满足客户端本地上特定的任务[6]。
基于DNNs的模型通常由提取低维度特征嵌入的特征提取器和作出分类决策的分类器组成。DNNs模型在集中式场景和多任务学习(Multi-Task Learning,MTL)中的成功表明:特征提取器通常发挥着通用结构的作用,而分类器则往往与特定任务相关[7,8],一般作为多任务学习模型的特定层。实际FL场景中客户端需要处理不同任务,可以从每个客户端作为一个特定任务的角度出发优化FL过程[9]。故使用适合本地的特征提取器来学习特征表示,同时关注全局任务和局部任务之间分类器的相关性,对训练个性化模型具有重要意义。
本文面向FL中的标签分布倾斜和数量分布倾斜的异构数据问题,提出个性化联邦多任务优化算法FedMTO。将FL过程表述为一个两阶段的优化问题:首先,在本地初始化阶段,完成本地个性化模型与全局模型之间的分类器协作;其次,在本地更新阶段,分别对个性化模型和全局模型进行更新。对于前者,将模型参数分解,提出一种自适应分类器组合权重学习方法,在局部提取全局模型分类器的知识。后者则从多任务学习和任务之间的公平性角度出发,使用参数正则化技术,约束个性化模型的本地更新过程。本文的主要贡献如下:
a)将多客户端参与的联邦学习场景构建为多任务学习过程。通过学习训练自适应分类器权重,发现局部分类器和全局分类器之间的最优协作关系,以实现算法的快速收敛和达到良好的模型性能。
b)在本地更新中加入正则化项,捕获本地任务和全局任务之间的相关性,防止个性化模型在本地过度拟合。有效降低多任务之间的标准偏差,维护了联邦多任务学习的公平性。
c)在不同异构程度的数据场景上进行评估,验证本文算法的有效性。CIFAR-10数据集上的实验结果表明,与pFL中的六种先进算法相比,FedMTO不仅优化了个性化模型之间的性能标准偏差,并且在最佳情况下将测试准确率平均提高了6.36%。
1 相关研究
1.1 面向异构数据的联邦学习
在真实场景中,不同客户端由于特定的数据场景、数据偏好、数据生成和数据采样方式存在明显差异,使得彼此之间的数据存在异构形式,数据分布彼此不同。例如,某地区的医院准备联合训练疾病预测模型,但是这些医院可能专攻于不同领域,这将导致疾病类别和数量的分布不一致。显然,专科医院在其专业领域疾病上的数据更加丰富,但与综合医院相比,对于其他疾病的相关数据较为匮乏。上述异构数据场景正是体现了FL中标签分布倾斜、数量分布倾斜的现象。
FedAvg[3]作为首个FL算法,提供一种通用方案:训练模型的数据分散在各边缘设备上,客户端与服务器通信。在不共享本地数据的前提下,客户端使用随机梯度下降(Stochastic Gradient Descent,SGD)进行本地更新,服务器将参与通信的模型参数加权平均作为全局模型。然而,FedAvg对所有客户端“一视同仁”,忽视了数据异构问题,已经被证明在Non-IID的异构数据场景下无法收敛[10]。
已有的研究工作中相继提出了多种改进方法,大致可分为限制局部更新、改良数据分布和采用个性化策略等。一方面,限制局部更新的方法通过设计目标函数的正则化形式或局部偏差校正来优化本地学习。具有代表性的是Li等人[11]提出的FedProx算法,通过在FedAvg上添加一个限制局部更新偏差量的近端项,限制了本地更新的大小,从而避免局部模型的发散。Karimireddy 等人[12]提出了SCAFFOLD算法,通过引入服务器和客户端的更新控制变量来纠正本地训练目标中的参数偏移现象。由于加入了额外的控制变量,SCAFFOLD将每轮的通信规模增加了一倍。上述的一类方法在收敛速度方面没有明显的突破,相较于FedAvg的提升较为有限。
另一方面,改良数据分布通常通过共享小部分数据,或者使用其他方法构造出更平衡的数据分布。Zhao等人[13]的研究表明,在CIFAR-10数据集上共享5%的全局数据就可以将模型测试精度提高约30%。Zhang等人[14]提出将聚类和数据共享同时应用到FL过程,有效地减少了数据异构的影响,加快了本地模型训练的收敛速度。Jeong E等人[15]使用生成对抗式网络(Generative Adversarial Networks,GAN)模型来实现数据增强,缓解本地数据的异构程度。类似地,Change等人[16]通过基于数据分布的聚类方法来提升模型准确率。
与上述两大类方法不同,个性化策略在本地维护一个私有的个性化模型,专注于提高个性化模型在本地的性能表现。本文所提FedMTO算法正是基于个性化策略实现的。
1.2 个性化联邦学习
现有的pFL方法包括:模型插值方法,通过维护一个全局模型序列和本地模型序列,对两者进行线性混合,找到模型参数的最佳插值。例如APFL[17]和L2CD[18],它们为客户端引入了一个模型插值参数,该参数在FL训练过程中通过控制全局和局部模型的权重,能够了解每个客户端的个性化程度。
对模型差异进行正则化的多任务学习,目标是训练联合执行多个相关任务的模型,在过程中利用特定领域的知识来提高模型泛化能力[19]。代表方法有FedMTL[20]和pFedMe[21],通过将客户端上的模型训练视为MTL中的一项任务,试图捕获客户端间的关系,来应对异构数据问题。
基于元学习(Meta-Learning)的局部适应策略,元学习通常被称为“学会学习”,旨在接触不同的数据分布来改进学习算法[22]。模型无关元学习(MAML)[23]算法以其良好的泛化性和对新任务的快速适应而闻名,并应用于基于梯度下降的各种方法。Per-FedAvg[24]就是建立在MAML公式上的FedAvg算法的变体,在客户端下载到全局模型后,根据本地数据分布进行额外的微调,提升模型在本地的性能。
参数解耦方法,将模型参数分解为局部私有参数和全局参数,私有参数在客户端本地训练,不参与全局聚合、不与服务器共享,通过学习特定于任务的表示以增强个性化。例如,FedRep[8]将模型分解为特征提取器、分类器,然后在本地固定分类器,服务器聚合特征提取器的参数,共享训练特征提取器。类似思想的工作还有LG-FedAvg[25]和FedPer[26]。
针对特定于客户端关系的细粒度模型聚合,FedAMP[27]在具有相似数据分布的客户端之间学习成对的协作关系,找到相关任务的相似模型,通过细粒度的加权聚合得到每个客户端的个性化云模型。FedFomo[9]算法采用了类似的方法。这类方法通常是基于启发式评估模型相似性或验证准确性实现的,需要在通信计算开销和个性化之间找到平衡。
与原型学习[28](Prototype-Based Learning)策略结合是一个新兴的研究方向,其核心思想是通过存储一组代表性的样本(原型),然后使用原型来进行分类、回归或聚类等任务。Tan等人提出FedProto[29],参与通信过程的不再是梯度,而是原型。对每个客户端进行训练的目的是局部数据的分类误差最小化,同时使得到的局部原型与相应的全局原型足够接近。
本文与FedRep[8]有着相似的参数分解思想,但不同之处在于,FedMTO结合了多任务学习,将异构数据视为每个本地任务上的不同数据分布的问题。同时运用了知识迁移策略,通过学习分类器组合权重来泛化知识,在任务之间相互传递知识,提高目标任务上的模型性能。此外,FedMTO还考虑了全局和局部任务之间的关联,关注了FL过程的公平性。
2 本文方法
2.1 问题设置
在经典的联邦学习场景中,存在N个客户端节点和一个中央服务器,客户端i上的私有数据分布为Di。目标是从客户端间分散的数据集中学习一个全局模型W,优化的全局目标函数可以定义为
3.2 结果分析
1)准确率比较
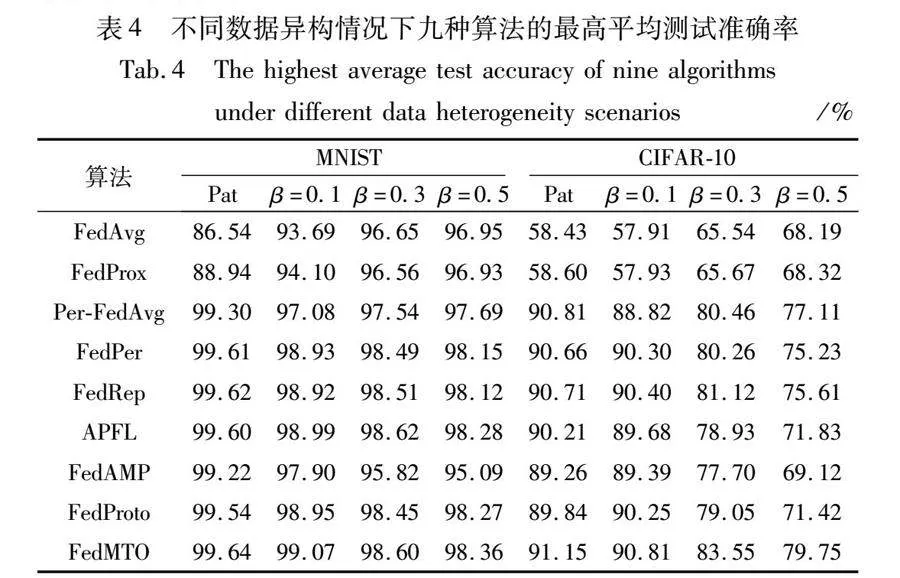
表4展示了FedMTO和其他算法在不同异构数据场景下,分别在两个基准数据集上达到的最佳平均测试准确率。从实验结果来看,个性化联邦学习算法在不同的数据集上的不同数据异构情况下,都普遍优于传统的联邦学习算法。这说明个性化联邦学习算法在数据异构场景下的有效性。本文算法更是在绝大部分情况下,都取得了最佳平均测试准确率。
由表4可知,在狄利克雷分布仿真下的异构数据场景下:随着客户端数据异构程度的增大,即分布参数β减小时,两种传统的联邦学习算法(FedAvg,FedProx)在MNIST和CIFAR-10数据集上的准确率显著下降。然而,其他的六种个性化算法的表现却保持上升。这验证了客户端上数据异构情况对联邦学习模型性能的影响极大,以及个性化联邦学习算法的可行性、有效性和针对性。
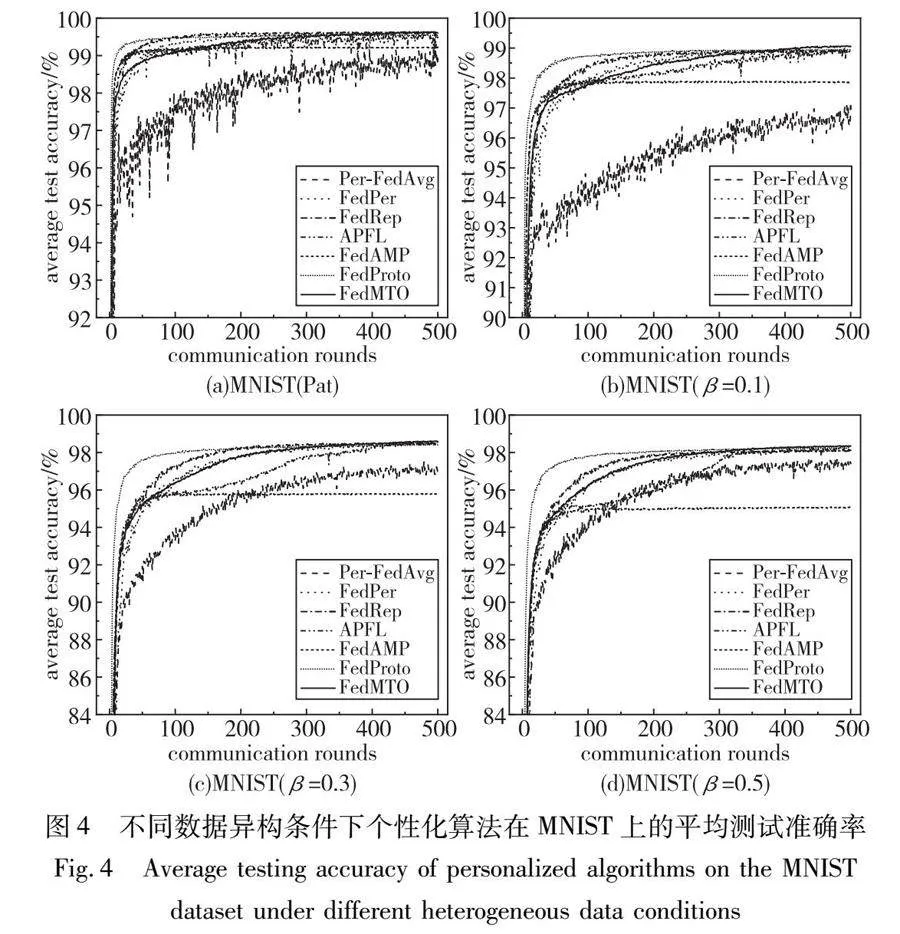
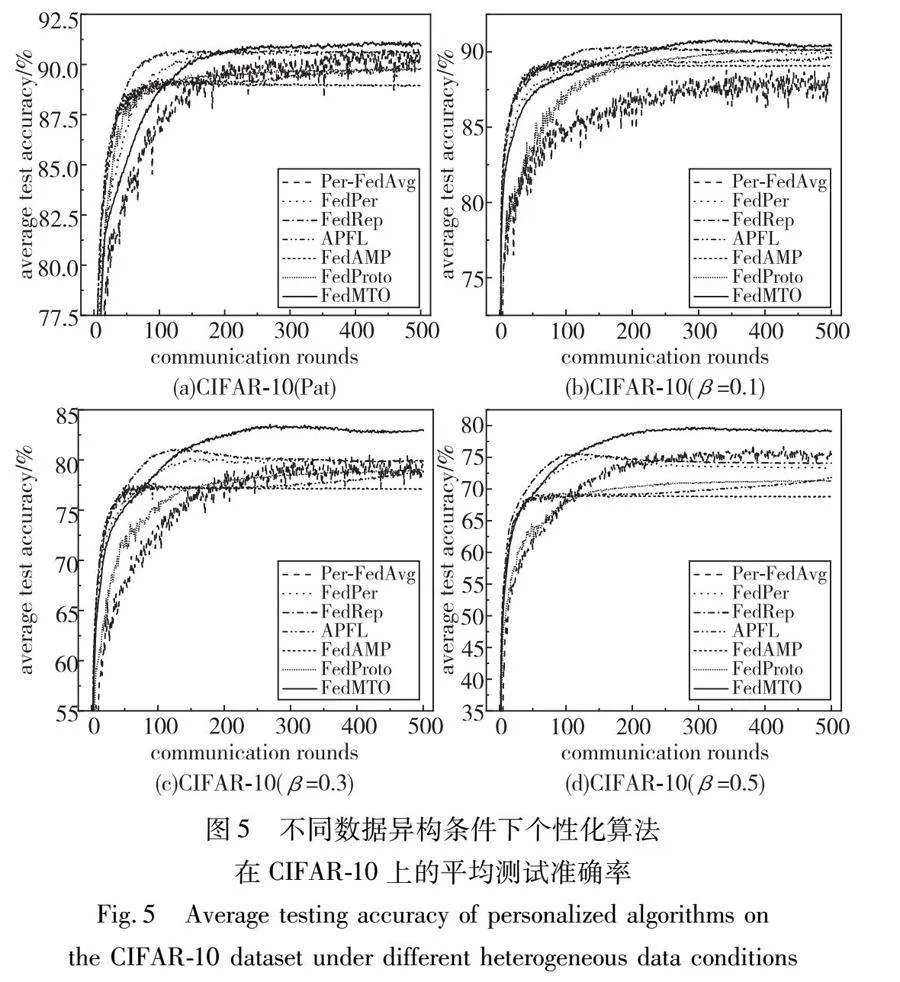
图4和图5所示为在默认参数设置下,FedMTO和其他六种个性化算法在训练过程中随着通信轮次增加,个性化模型的平均测试准确率的学习曲线。需要注意的是,由于以FedAvg和FedProx为代表的传统全局模型算法在面对异构场景时平均测试准确率的表现不佳,与个性化算法差距较大,所以不再绘制其学习曲线。
对构成比较简单的MNIST数据集,由表4和图4可以观察出,FedMTO算法与其他算法相比,可以在不同程度下的Non-IID场景取得良好的表现。首先,在数据病态异构分布的场景下,FedMTO的最高平均准确率相对于两种传统的联邦学习算法平均提升了11.9%。同时随着通信轮次增加而变化,最终优于其余的六种个性化算法。
另外在实际异构场景下,FedMTO算法在参数β为0.1、0.5的异构程度下表现依然优秀,相对传统算法将精度平均提高5.17%和1.42%,并会随着通信轮次增大而优于其他的个性化算法;虽然在参数β为0.3时,FedMTO相对于APFL有极其细微的精度差距,但相对传统算法将最佳平均准确率提高了2.05%,并且也优于其余五种个性化算法,这说明FedMTO算法依然保持了高水平的竞争力。
对于CIFAR-10数据集,其样本是现实世界中真实的物体,不仅噪声很大,而且物体的特征、大小都不尽相同,所以数据集更复杂,识别难度更大。由表4和图5可知,在数据病态异构分布的场景下,FedMTO在CIFAR-10上的表现优于其他所有算法,将个性化精度平均提升了8.84%。对于狄利克雷分布下的三种不同程度的数据异构场景,相较于其他算法,本文算法将平均个性化准确率分别提高了8.98%,7.46%,7.65%。另外,随着β的取值增大(数据的异构程度减小),六种个性化算法与FedMTO算法的性能差距就越大。在β=0.5时,差距最为明显,此时只与个性化算法对比,FedMTO也能将测试准确率平均提高6.36%。这体现出该算法的泛化性更好,在不同程度的异构数据场景下都更好地满足了本地个性化任务。
值得注意的是,以CIFAR-10数据集为例,在集中式学习下已有先进的模型在该数据集上实现了99%以上的测试准确率。然而,本研究使用的标准模型足以满足联邦学习算法的实验需求。因为本文的目标不是在集中式学习的场景下,对该数据集的图像分类任务达到最高精度,而是在联邦学习场景下评估本文的优化算法,并与其他经典的优秀算法进行包括但不仅限于准确率等指标的对比。
2)公平性比较
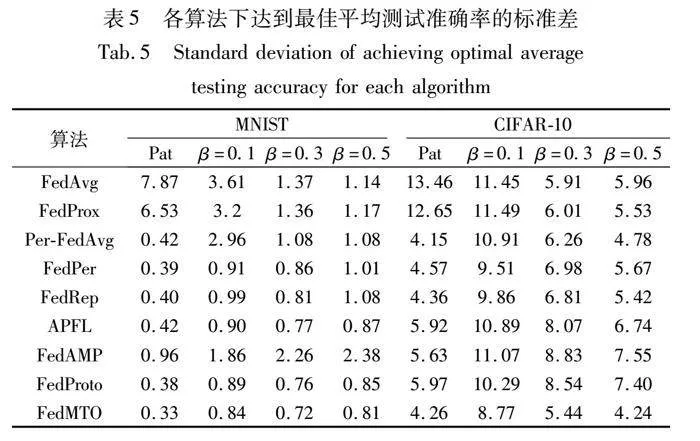
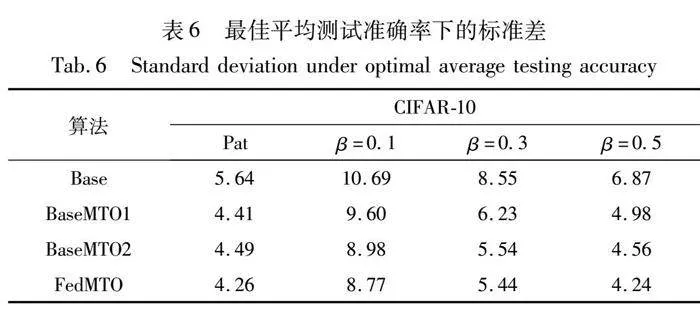
依据Li等人[32]对联邦学习中公平性的定义和评价参考指标。表5报告了各算法在达到最佳平均测试准确率时,客户端之间个性化模型测试准确率的标准差(以百分比准确率计算),来评价不同算法下的公平性。
可知FedMTO在不同程度的数据异构场景下,均保持了最低测试准确率的标准差。与六种个性化算法相比,综合考虑四种异构场景,在MNIST、CIFAR-10数据集上分别将客户端之间的准确率偏差至少缩小了6.25%、12.98%。这表明以往的pFL算法在保证本地模型个性化性能之外,没有充分考虑到不同客户端设备之间的公平性。在追求提高个性化模型性能时,导致不同客户端之间训练得到的模型准确率偏差较大。FedMTO在达到近似或者更高测试精度的同时又保持了更低的测试标准差,高效又公平地完成了本地个性化任务。
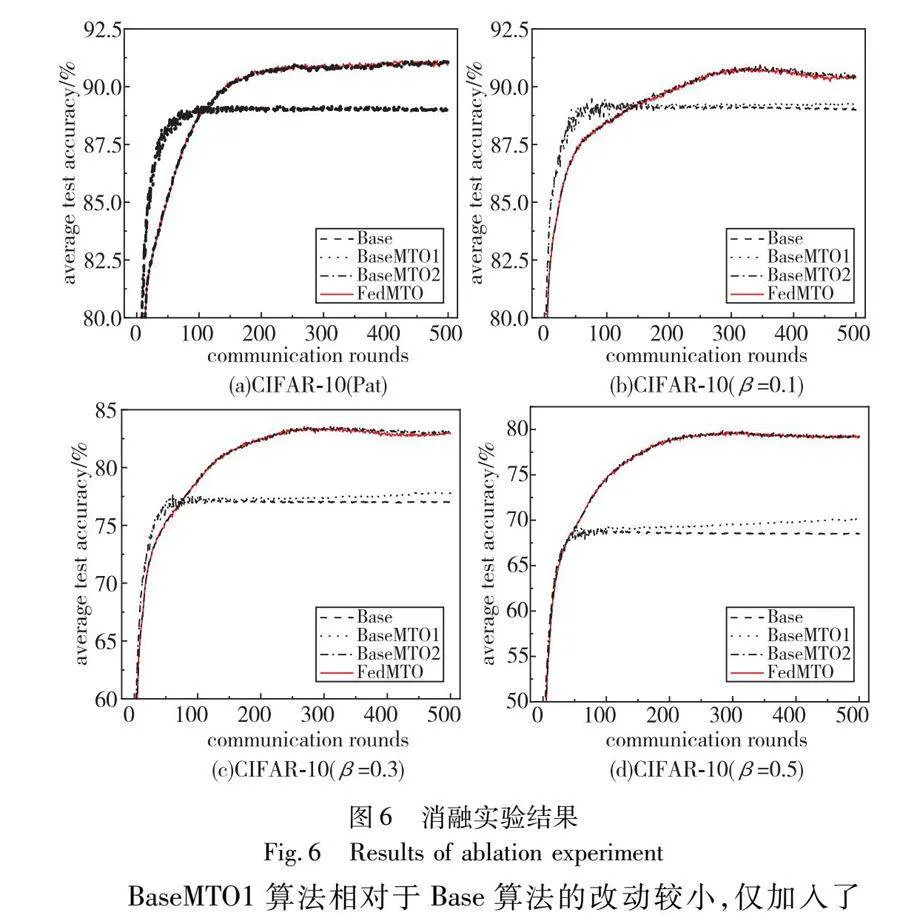
3)消融实验
FedMTO算法整体分为两个部分:(a)自适应分类器组合权重的学习。(b)结合正则化项的本地多任务学习。为了验证本文所提的优化方法的有效性,在较为复杂的CIFAR-10数据集上,对上述两部分进行了消融实验。相关的参数设置与对比实验保持一致,分别以Base算法(均不采用)、BaseMTO1算法(引入正则化项)、BaseMTO2算法(学习分类器组合权重)和FedMTO进行实验,结果如图6所示。
BaseMTO1算法相对于Base算法的改动较小,仅加入了正则化项,但是在四种异构数据的情况下,准确率仍有提高,说明正则化项对联邦多任务学习可以带来积极影响。BaseMTO1算法和Base算法往往更早地达到收敛,但是与BaseMTO2、FedMTO相比,平均最佳准确率较低,这表明学习分类器组合权重对模型个性化性能的意义更大。在β=0.5的情况下,平均准确率的差距将达到最大,对比下降了约10%。
BaseMTO2与FedMTO的最佳平均准确率总是十分接近的,说明学习自适应分类器组合权重所带来的模型性能提升较大。对本地模型分类器和全局模型分类器的权重自适应聚合,可以学习到全局模型的丰富知识,更好地完成每个本地任务。然而,就公平性而言,如表6所示,FedMTO至少将模型测试准确率之间的标准差平均减小了近4%。这表明结合了正则化多任务学习的FedMTO算法减少了不同客户端上异构数据现象的干扰。在提高个性化性能的同时,又取得了更均衡的分类效果,更充分地解决了FL中的数据异构问题。
4 结束语
本文面向联邦学习中的异构数据场景,提出一种个性化联邦多任务学习优化算法FedMTO。FedMTO采用基于参数分解方法抽象出全局分类器参数和局部分类器参数,通过学习自适应分类器组合权重,优化模型之间的协作关系,并进一步基于正则化多任务学习方法对本地更新进行约束,捕获本地任务和全局任务之间的相关性,优化联邦多任务学习过程。
通过在不同数据集上与其他算法的全面实验,证明了本文算法在个性化模型精度、联邦多任务学习优化和多任务之间的公平性等方面都有着显著的提升。考虑到真实的联邦学习场景中客户端设备异构和通信资源往往是受限制的,下一步研究准备以多任务学习思想设计高效的异步联邦学习机制,设计性能更好的联邦学习优化算法。
参考文献:
[1]Wang Shiqiang,Tuor T,Salonidis T,et al. Adaptive federated learning in resource constrained edge computing systems[J]. IEEE Journal on Selected Areas in Communications,2019,37(6): 1205-1221.
[2]Gaff B M,Sussman H E,Geetter J. Privay and big data[J]. Computer,2014,47(6): 7-9.
[3]McMahan B,Moore E,Ramage D,et al. Communication-efficient learning of deep networks from decentralized data[C]// Proc of the 20th International Conference on Artificial Intelligence and Statistics. [S.l.]: PMLR,2017: 1273-1282.
[4]Li Zengpeng,Sharma V,Mohanty S P. Preserving data privacy via fede-rated learning: Challenges and solutions[J]. IEEE Consumer Electronics Magazine,2020,9(3): 8-16.
[5]Li Qinbin,Diao Yiqun,Chen Quan,et al. Federated learning on Non-IID data silos: an experimental study[C]// Proc of the 38th International Conference on Data Engineering. Piscataway,NJ: IEEE Press,2022: 965-978.
[6]Xu Jian,Tong Xinyi,Huang S L. Personalized federated learning with feature alignment and classifier collaboration[EB/OL]. (2023-06-20). https://arxiv.org/abs/2306.11867.
[7]Bengio Y,Courville A,Vincent P. Representation learning: a review and new perspectives[J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2013,35(8): 1798-1828.
[8]Collins L,Hassani H,Mokhtari A,et al. Exploiting shared representations for personalized federated learning[C]// Proc of the 38th International Conference on Machine Learning. [S.l.]: PMLR,2021: 2089-2099.
[9]Marfoq O,Neglia G,Bellet A,et al. Federated multi-task learning under a mixture of distributions[C]// Advances in Neural Information Processing Systems. 2021: 15434-15447.
[10]Li Xiang,Huang Kaixuan,Yang Wenhao,et al. On the convergence of FedAVG on Non-IID data[EB/OL]. (2020-06-25). https://arxiv.org/abs/1907.02189.
[11]Li Tian,Sahu A K,Zaheer M,et al. Federated optimization in heterogeneous networks[C]// Proc of Machine Learning and Systems. 2020: 429-450.
[12]Karimireddy S P,Kale S,Mohri M,et al. SCAFFOLD: stochastic controlled averaging for federated learning[C]// Proc of the 37th International Conference on Machine Learning. [S.l.]: JMLR.org,2020: 5132-5143.
[13]Zhao Yue,Li Meng,Lai Liangzhen,et al. Federated learning with Non-IID data[EB/OL]. (2022-07-21). https://arxiv.org/abs/1806.00582.
[14]张红艳,张玉,曹灿明. 一种解决数据异构问题的联邦学习方法[J]. 计算机应用研究,2024,41(3): 713-720. (Zhang Hongyan,Zhang Yu,Cao Canming. Effective method to solve problem of data heterogeneity in federated learning[J]. Application Research of Computers,2024,41(3): 713-720.)
[15]Jeong E,Oh S,Kim H,et al. Communication-efficient on-device machine learning: federated distillation and augmentation under Non-IID private data[EB/OL]. (2023-10-19). https://arxiv.org/abs/1811.11479.
[16]常黎明,刘颜红,徐恕贞. 基于数据分布的聚类联邦学习[J]. 计算机应用研究,2023,40(6): 1697-1701. (Chang Liming,Liu Yanhong,Xu Shuzhen. Clustering federated learning based on data distribution[J]. Application Research of Computers,2023,40(6): 1697-1701.)
[17]Deng Yuyang,Kamani M M,Mahdavi M. Adaptive personalized fede-rated learning[EB/OL]. (2020-11-06). https://arxiv.org/abs/2003.13461.
[18]Hanzely F,Richtárik P. Federated learning of a mixture of global and local models[EB/OL]. (2021-02-12). https://arxiv.org/abs/2002.05516.
[19]Tan A Z,Yu Han,Cui Lizhen,et al. Towards personalized federated learning[J]. IEEE Trans on Neural Networks and Learning Systems,2023,34(12): 9587-9603.
[20]Smith V,Chiang C K,Sanjabi M,et al. Federated multi-task learning[C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2017: 4427-4437.
[21]Dinh T C,Tran N,Nguyen J. Personalized federated learning with moreau envelopes[C]// Proc of the 34th International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2020: 21394-21405.
[22]Hospedales T,Antoniou A,Micaelli P,et al. Meta-learning in neural networks: a survey[J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2021,44(9): 5149-5169.
[23]Finn C,Abbeel P,Levine S. Model-agnostic meta-learning for fast adap-tation of deep networks[C]// Proc of the 34th International Conference on Machine Learning. [S.l.]: JMLR.org,2017: 1126-1135.
[24]Fallah A,Mokhtari A,Ozdaglar A. Personalized federated learning with theoretical guarantees: a model-agnostic meta-learning approach[C]// Proc of the 34th International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2020: 3557-3568.
[25]Liang P P,Liu T,Ziyin Liu,et al. Think locally,act globally: federated learning with local and global representations [EB/OL]. (2020-07-14). https://arxiv.org/abs/2001.01523.
[26]Arivazhagan M G,Aggarwal V,Singh A K,et al. Federated learning with personalization layers [EB/OL]. (2019-12-02). https://arxiv.org/abs/1912.00818.
[27]Huang Yutao,Chu Lingyang,Zhou Zirui,et al. Personalized cross-silo federated learning on Non-IID data[C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2021: 7865-7873.
[28]Finn C,Abbeel P,Levine S. Model-agnostic meta-learning for fast ada-ptation of deep networks[C]// Proc of the 34th International Conference on Machine Learning. [S.l.]: JMLR.org,2017: 1126-1135.
[29]Tan Y,Long G,Liu L,et al. FedProto: federated prototype learning across heterogeneous clients [C]// Proc of the AAAI Conference on Artificial Intelligence. 2022: 8432-8440.
[30]Arjovsky M,Chintala S,Bottou L. Wasserstein generative adversarial networks[C]// Proc of the 34th International Conference on Machine Learning.[S.l.]: JMLR.org,2017: 214-223.
[31]Wojke N,Bewley A. Deep cosine metric learning for person re-identification [C]// Proc of IEEE Winter Conference on Applications of Computer Vision. Piscataway,NJ: IEEE Press,2018: 748-756.
[32]Li Tian,Hu Shengyuan,Beirami A,et al. Ditto: fair and robust fede-rated learning through personalization[C]// Proc of the 38th International Conference on Machine Learning. [S.l.]: PMLR,2021: 6357-6368.
收稿日期:2024-01-02;修回日期:2024-03-04 基金项目:国家自然科学基金资助项目(62062001);宁夏青年拔尖人才项目(2021)
作者简介:李可(2000—),男,河南开封人,硕士研究生,CCF会员,主要研究方向为联邦学习、多任务学习;王晓峰(1980—),男(回族)(通信作者),甘肃会宁人,副教授,硕导,博士,CCF会员,主要研究方向为算法分析与设计、人工智能(xfwang@nmu.edu.cn);王虎(1998—),男,江苏南京人,硕士研究生,主要研究方向为联邦学习、机器学习.
