基于改进好奇心的深度强化学习方法
2024-11-04乔和李增辉刘春胡嗣栋



摘 要:
在深度强化学习方法中,针对内在好奇心模块(intrinsic curiosity model,ICM)指导智能体在稀疏奖励环境中获得未知策略学习的机会,但好奇心奖励是一个状态差异值,会使智能体过度关注于对新状态的探索,进而出现盲目探索的问题,提出了一种基于知识蒸馏的内在好奇心改进算法(intrinsic curiosity model algorithm based on knowledge distillation,KD-ICM)。首先,该算法引入知识蒸馏的方法,使智能体在较短的时间内获得更丰富的环境信息和策略知识,加速学习过程;其次,通过预训练教师神经网络模型去引导前向网络,得到更高精度和性能的前向网络模型,减少智能体的盲目探索。在Unity仿真平台上设计了两个不同的仿真实验进行对比,实验表明,在复杂仿真任务环境中,KD-ICM算法平均奖励比ICM提升了136%,最优动作概率比ICM提升了13.47%,提升智能体探索性能的同时能提高探索的质量,验证了算法的可行性。
关键词:深度强化学习;知识蒸馏;近端策略优化;稀疏奖励;内在好奇心
中图分类号:TP181 文献标志码:A 文章编号:1001-3695(2024)09-010-2635-06
doi:10.19734/j.issn.1001-3695.2024.01.0014
Research on deep reinforcement learning method based on improved curiosity
Qiao He, Li Zenghui, Liu Chun, Hu Sidong
(School of Electrical & Control Engineering, Liaoning Technology University, Huludao Liaoning 125105, China)
Abstract:
In the deep reinforcement learning method, the intrinsic curiosity model (ICM) guides the agent to obtain the opportunity to learn unknown strategies in the sparse reward environment, but the curiosity reward is a state difference value, which will make the agent pay too much attention to the exploration of new states. Then the problem of blind exploration arises, and this paper proposed an intrinsic curiosity model algorithm based on knowledge distillation (KD-ICM). Firstly, it introduced the method of knowledge distillation to make the agent acquire more abundant environmental information and strategy knowledge in a short time and accelerate the learning process. Secondly, by pre-training teachers’ neural network model to guide the forward network to obtain a forward network model with higher accuracy and performance, reduced the blind exploration of agents. It designed two different simulation experiments on the Unity simulation platform for comparison. The experiments show that in the complex simulation task environment, the average reward of KD-ICM algorithm is 136% higher than that of ICM, and the optimal action probability is 13.47% higher than that of ICM. The exploration performance of the agent can be improved while the exploration quality can be improved, and the feasibility of the algorithm is verified.
Key words:deep reinforcement learning; knowledge distillation; optimization of near-end policy; sparse reward; intrinsic curiosity
0 引言
强化学习(reinforcement learning,RL)是一种当智能体在复杂且不确定的环境中进行交互时,尝试让智能体获得奖励最大化的算法[1]。强化学习由于其通用性,在许多其他学科中也有研究,如博弈论、控制论、运筹学、信息论、模拟优化、群体智能、统计学和遗传算法。由于近年来的迅猛发展,强化学习在游戏、机器人路线规划、自动驾驶[2~4]等诸多领域取得了巨大的成功。
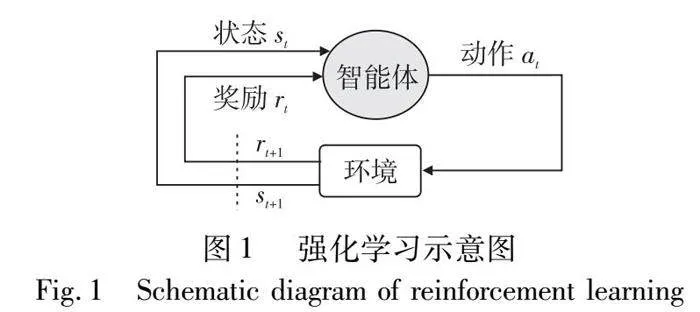
在强化学习中智能体依据奖励进行策略优化(图1),但在许多实际应用强化学习训练智能体的场景中,多数时候智能体往往都不能得到奖励。在不能得到奖励的情况下,难以正确地更新智能体策略,导致训练非常困难。因此,研究如何在奖励稀少的情况下让智能体能够去学习,对于智能体探索效率提高以及智能体策略优化的作用极其重要。
针对奖励稀疏的问题,往往有三个方向来解决:
a)课程学习[5]。课程学习是指为智能体的学习做规划,输入训练数据的时候,采取由易到难的顺序进行输入,通常可以学得比较好。
b)分层强化学习[6]。通过引入任务层次结构,包括负责决定子任务切换的高层策略,和执行具体子任务决策的低层策略。任务被分解为一系列子任务,形成层次结构,使智能体能够更有效地处理复杂问题。高层策略与整体任务性能相关,低层策略与子任务执行相关,每个层次都可以接收奖励信号。
c)设计奖励[7]。为了让智能体学到想要的结果,可以人为设计一些奖励来引导智能体。通过设计额外的奖励,从而激发智能体的“好奇心”。
通常,将智能体与环境交互得到的奖励称为外在奖励(extrinsic reward),额外设计的奖励称为内在奖励(intrinsic reward),如图2所示。
目前,内在奖励主要分为两种设计思想,第一种最简单思想是通过计数度量新颖性[8],通过跟踪智能体遇到的新状态或执行的新动作数量来度量新颖性。当智能体探索环境并发现之前未经历过的状态或采取过的动作时,为其提供内在奖励。这种方法的优势在于简单直观,可以通过维护状态或动作的计数来实现,但对于高维连续观测空间和连续动作空间没有简单的计数方法,因此往往取不到理想的效果。
为了缓解上述问题,另一种方法是利用智能体对环境的预测问题来度量新颖性,使用状态预测误差作为好奇心奖励。预测误差越小,则表明之前已经访问过,内在奖励也越小;反之误差越大,则表明之前没有访问过,内在奖励就越大。例如基于随机蒸馏网络(random network distillation,RND)方法[9]和内在好奇心奖励模块(intrinsic curiosity module,ICM)[10],两者都是将状态新颖性作为内在好奇心奖励[11],从而帮助智能体进行更好的探索。但是ICM存在过度关注于智能体对最新状态探索的问题,因此导致前向模型能力不够,无法很好地去拟合目标函数,最终造成智能体盲目探索,不能有效利用内在奖励去解决问题。
本文提出了一种改进算法,基于知识蒸馏[12]的内在好奇心奖励方法(intrinsic curiosity module with knowledge distillation,KD-ICM)。引入知识蒸馏的方法,通过预训练教师神经网络模型(teacher network)去引导前向网络,从而得到更高精度和性能的前向网络模型,在内部修正智能体的探索方向。近端策略优化(proximal policy optimization,PPO)[12]算法是基于策略的强化学习算法,存在探索不足的问题。本文将KD-ICM方法、ICM方法通过基准算法PPO实现,在Unity仿真平台设计不同的仿真环境,并对三种算法进行对比,结果表明ICM方法对PPO的性能有所提升,但是由于存在盲目探索,不能有效地利用内在奖励去解决问题,而KD-ICM方法增加了教师网络对前向网络进行指导与训练,能够有效避免盲目探索的问题。实验结果表明,KD-ICM方法在复杂仿真任务中的表现优于ICM,能加快收敛,平均奖励有显著提升。
1 方法论
1.1 近端策略优化算法的推导
传统的强化学习算法会将状态价值函数V(s)或动作价值函数Q(s, a)以表格的形式存储,如蒙特卡罗、Q学习和SARS算法[13],但是这样的方法存在很大的局限性。比如在现实任务中的状态空间基本都是连续的,存在无穷多个状态,而表格类方法无法处理复杂的动作维度和状态[14]。随着深度学习取得的巨大成功,以深度学习和强化学习组合的深度强化学习方法有效地解决了上述问题。通过利用神经网络拟合价值函数、策略网络等,避免了提取特征这一复杂问题,从而将传统的强化学习过程改变成一个端到端(end-to-end training)的学习过程。例如深度Q学习(deep Q-learning network,DQN)算法[14]、策略梯度算法(policy gradient,PG)[15]、深度确定型策略梯度算法(deep determine policy gradient,DDPG)[16]等。
近端策略优化算法是策略梯度算法的改进算法,即通过求解强化学习问题中目标函数的梯度,利用梯度提升的方法训练智能体。
2 实验
ML-Agents是Unity的一款开源插件,能够让开发者通过深度强化学习和模仿学习相结合的方式教授智能体“学习”,创建物理、视觉和认知丰富的AI环境,并可以将它们用于基准测试以及研究新的算法和方法。
为了验证算法的有效性,本文将KD-ICM-PPO算法用于ML-Agents搭建的两个不同的仿真任务环境push-block和pyramid中,并与PPO算法、ICM-PPO算法作对比。
在ML-Agents建立的仿真任务环境各实验参数如表1所示。
a)push-block仿真环境:
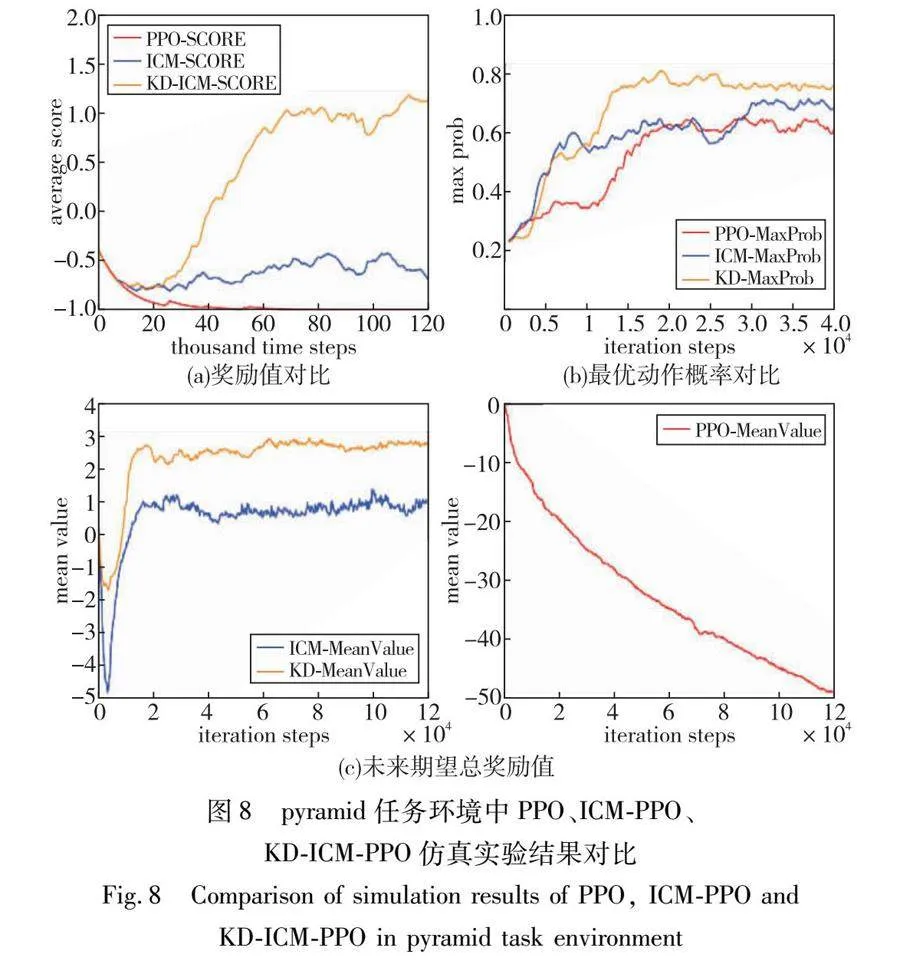
(a)仿真环境内容:智能体在平台上推动橙色的砖块,推到黑白相间的终点区域就算完成任务,如图5所示。
(b)agent设置:蓝色的小方块,使训练的智能体环境包含一个链接到单个brain的agent。
(c)brain设置:采用了射线传感器Ray Perception Sensor 3D,并且使用了两个,以获得上下立体视角,上下二层的每一层都有七条射线,70个变量对应于14个射线投射,每个变量检测三个可能的对象(墙壁、目标或块)之一。
b)pyramid仿真环境
在pyramid虚拟环境中,智能体的任务是在一个相当庞大的场景中寻找一个位于金字塔顶端的方块,如图6所示。为了触碰这个方块,智能体必须推倒支撑它的金字塔。不同于一开始就存在的金字塔和方块,它们只有在智能体触碰特定按钮后才会在场景中生成,而这个按钮会定期随机出现在环境的不同位置。
为了成功完成任务,智能体需要执行以下步骤:
(a)寻找按钮:智能体必须使用其感知系统来搜索环境,找到触发生成金字塔和方块的按钮。
(b)触碰按钮:一旦找到按钮,智能体需要移动到按钮位置,并与之交互,触发金字塔和方块的生成。
(c)寻找金字塔:智能体生成金字塔后,需要使用感知系统再次搜索环境,找到生成的金字塔的位置。
(d)推倒金字塔:智能体必须采取行动,推倒支撑方块的金字塔。
(e)触碰方块:一旦金字塔被推倒,方块将变得可触及。智能体需要移动到方块的位置,并与之交互,完成任务。
3 实验结果分析
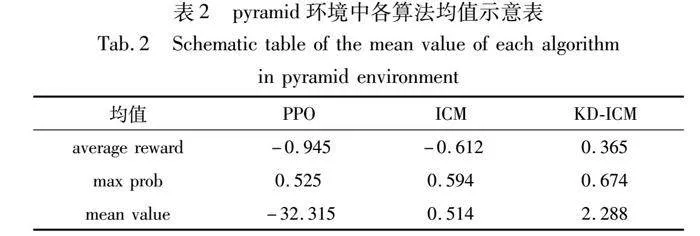
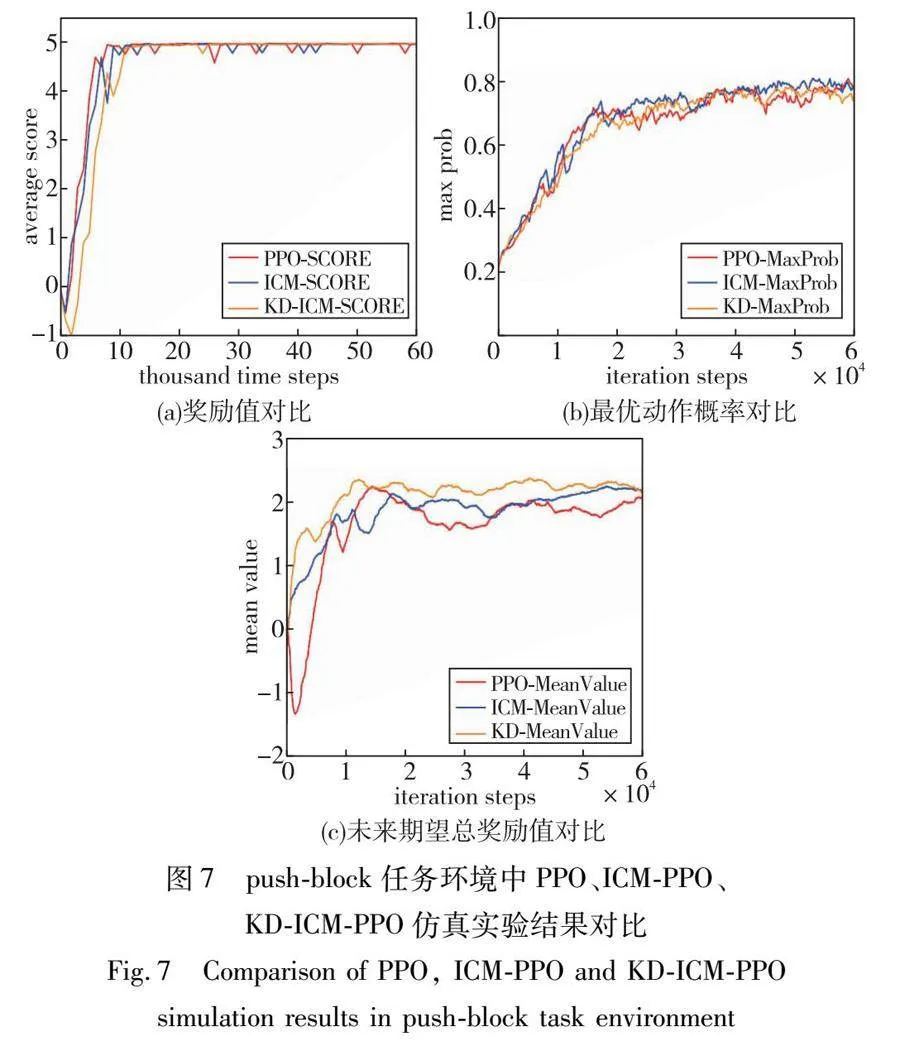
本文分别设计了push-block和pyramid两个不同的仿真任务环境作对比,push-block仿真任务环境较为简单,而pyramid仿真任务环境比较复杂。结果如表2、图7和8所示,从得到的平均奖励值、最优动作概率、未来期望值三个方面来评测智能体的性能。
在push-block仿真任务环境中,数据变化趋势如图7(a)~(c)所示,随着迭代步数的增加,在获得的平均奖励值对比图中,在初始时步,KD-ICM-PPO算法的表现略低于ICM-PPO算法和基准算法PPO,原因是KD-ICM方法通过预训练的教师网络模型表征能力更强的大型神经网络模型,所以能够探索到更为详细的状态信息,但增加了训练成本,所以并没有很快地收敛。从图7(c)的变化趋势图可以看到KD-ICM方法未来期望总奖励值更大,表明该方法在当前价值选择上更为优越。而图7(b)的变化趋势图表明最优动作概率变化趋势几乎相似,没有太大变化。
pyramid仿真任务环境由于任务难度大、奖励稀疏程度高,这次的任务如果使用寻常的强化学习方法是几乎不可能得到一个好的结果的。图8(a)(c)为PPO平均奖励值和未来期望总奖励值变化趋势图,PPO算法很难得到奖励或者几乎没有得到奖励,未来期望总奖励值也在不断降低。因此这里需要应用到好奇心机制,使得智能体在探索未知事物中得到奖励,有效推动了训练的进展。
如图8(a)奖励变化趋势所示,PPO算法奖励值一直处于不断降低的状态,最终稳定在奖励值为-1的负奖励上;ICM-PPO算法相比PPO算法有了一定提高,经过一定的下降后稳定在-0.5左右。KD-ICM-PPO 算法在前期经过一定的下降后,在20 000 timesteps左右开始升高,并在40 000 timesteps奖励值开始为正,在70 000 timesteps稳定在1.0左右。
如图8(c)未来期望总奖励变化趋势所示,PPO算法奖励值一直处于下降的状态;ICM-PPO算法经过一定的下降后开始上升,最终在18 000 timesteps稳定在1.0左右;KD-ICM-PPO算法经过一定的下降后开始上升,最终在17 000 timesteps左右稳定在2.0~3.0。
当前奖励值主要由内在奖励和外在奖励两部分组成,内在奖励的设计是为了鼓励智能体去探索那些可能不会立即带来外在奖励的状态,但从长远来看,这些探索有助于更好地理解环境,从而在未来作出更优的决策。因此,内在奖励通常与探索能力有关,而外在奖励则与任务的具体目标有关。从图8(a)和(c)结果显示,由于缺少内在奖励的设计, PPO算法相比ICM-PPO算法、KD-ICM-PPO算法探索性能不足,奖励一直为负值。而增加了内在奖励设计的ICM-PPO算法的奖励值虽然有了一定的提升,但其奖励值的增长仍然有限,波动在-0.5附近,这表明虽然内在奖励促进了一定的探索,但这种探索并没有转换为显著的外在奖励增长,存在盲目探索的问题。另一方面,KD-ICM-PPO算法展现出更加显著的性能提升,其奖励值持续上升,并且维持在较高水平,这表明通过知识蒸馏的方式能够更有效地将内在奖励转换为有效的探索策略,使得智能体不仅探索了更多的状态空间,而且这种探索更有效地促进了对环境的理解,这对完成具体的外在任务目标是有益的。
由此可见,内在奖励的引入是提升智能体探索性能的关键,而知识蒸馏技术进一步优化了这一过程。知识蒸馏在这里作为一种策略,通过将先进或专家智能体的策略传递给学习者智能体,以加速学习过程并提高探索的质量。这种方法让智能体不仅能够探索那些短期内可能不会带来直接外在奖励的新状态,而且能够更快地从这些探索中学习到有助于长期任务成功的知识和技能。
如图8(b)所示为最优动作概率趋势图,可以评估策略。算法的奖励值虽然有了一定的提升,但其奖励值的增长仍然有限,波动在-0.5附近,这表明虽然内在奖励促进了一定的探索发展,但这种探索并没有转换为显著的外在奖励增长,存在变化和不确定性,增强了智能体的鲁棒性能。
4 结束语
本研究致力于解决深度强化学习领域中的关键挑战:奖励稀疏和盲目探索问题。为此,本文提出了一种创新的方法,即基于知识蒸馏的内在好奇心改进(KD-ICM)算法。该方法通过在预训练的教师网络上应用知识蒸馏技术,促进智能体以更加高效的方式探索环境,特别是在那些需要复杂决策和任务执行的仿真场景中。在两个精心设计的仿真实验push-block和pyramid中发现,该算法在提高智能体的探索性能的同时能提高探索的质量。
为了进一步展现KD-ICM在实际应用中的潜力,该算法下一步将应用于智能物流和无人驾驶等具体场景。例如,在智能物流系统中,KD-ICM可以帮助智能体在仓库内进行更有效的路径规划和货物搬运任务,更加主动地探索未知区域,快速识别出高效的配送路线,提高物流效率和降低错误率。在无人驾驶汽车的应用中,KD-ICM可以促进无人车更好地学习和适应复杂的城市交通环境,提高其决策制定的准确性和安全性。在灾难响应中,KD-ICM可以训练搜索与救援机器人在复杂环境中进行搜索、导航和救援任务。
期待未来的研究能够将KD-ICM应用于更多实际问题,进一步验证其在现实世界复杂任务中的适用性和效果。这种基于知识蒸馏的内在好奇心改进方法,为深度强化学习技术的发展和应用拓宽了更广阔的道路。
参考文献:
[1]Li Yuxi. Deep reinforcement learning: an overview [EB/OL]. (2017).https://arxiv.org/abs/1701. 07274.
[2]Mnih V,Kavukcuoglu K,Silver D,et al. Playing Atari with deep reinforcement learning [EB/OL]. (2013). https://arxiv.org/abs/1312. 5602.
[3]Guo Rui,Fu Zhonghao. Dual policy iteration-reinforcement learning to optimize the detection quality of passive remote sensing device [J]. Signal Processing,2023,209: 109002.
[4]Tai Lei,Zhang Jingwei,Liu Ming,et al. A survey of deep network solutions for learning control in robotics: from reinforcement to imitation [EB/OL]. (2016).https://arxiv.org/abs/1612. 07139.
[5]Kiran B R,Sobh I,Talpaert V,et al. Deep reinforcement learning for autonomous driving: a survey [J]. IEEE Trans on Intelligent Transportation Systems,2021,23(6): 4909-4926.
[6]Weinshall D,Cohen G,Amir D. Curriculum learning by transfer learning: theory and experiments with deep networks [C]// Proc of International Conference on Machine Learning. 2018: 5238-5246.
[7]Kulkarni T D,Narasimhan K,Saeedi A,et al. Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation [C]// Advances in Neural Information Processing Systems. 2016.
[8]Chentanez N,Barto A,Singh S. Intrinsically motivated reinforcement learning [C]// Advances in Neural Information Processing Systems. 2004.
[9]Burda Y,Edwards H,Storkey A,et al. Exploration by random network distillation [EB/OL]. (2018).https://arxiv.org/abs/1810. 12894.
[10]Pathak D,Agrawal P,Efros A A,et al. Curiosity-driven exploration by self-supervised prediction [C]//Proc of International Conference on Machine Learning. Piscataway,NJ: IEEE Press,2017: 2778-2787.
[11]谭庆,李辉,吴昊霖,等. 基于奖励预测误差的内在好奇心方法 [J]. 计算机应用,2022,42(6): 1822-1828. (Tan Qing,Li Hui,Wu Haolin,et al. Intrinsic curiosity method based on reward prediction error [J]. Journal of Computer Applications,202,42(6): 1822-1828.)
[12]Gou Jianping,Yu Baosheng,Maybank S J,et al. Knowledge distillation: a survey [J]. International Journal of Computer Vision,2021,129(6):1-31.
[13]Schulman J,Wolski F,Dhariwal P,et al. Proximal policy optimization algorithms [EB/OL]. (2017). https://arxiv.org/abs/1707. 06347.
[14]邹启杰,李文雪,高兵,等. 基于加权值函数分解的多智能体分层强化学习技能发现方法 [J]. 计算机应用研究,2023,40(9): 2743-2748,2754. (Zou Qijie,Li Wenxue,Gao Bing,et al. Multi-agent hierarchical reinforcement learning skill discovery method based on weighted value function decomposition [J]. Application Research of Computers,2019,40(9): 2743-2748,2754.)
[15]Sutton R S,Barto A G. Reinforcement learning: an introduction [J]. Robotica,1999,17(2): 229-235.
[16]Mnih V,Kavukcuoglu K,Silver D,et al. Human-level control through deep reinforcement learning [J]. Nature,2015,518(7540): 529-533.
[17]Lillicrap T P,Hunt J J,Pritzel A,et al. Continuous control with deep reinforcement learning [EB/OL]. (2015). https://arxiv.org/abs/1509. 02971.
[18]杨瑞,严江鹏,李秀. 强化学习稀疏奖励算法研究——理论与实验 [J]. 智能系统学报,2020,15(5): 888-899. (Yang Rui,Yan Jiangpeng,Li Xiu. Sparse reward algorithm for reinforcement lear-ning: theory and experiment [J]. Journal of Intelligent Systems,2020,15(5): 888-899.)
[19]Burda Y,et al. Large-scale study of curiosity-driven learning [EB/OL]. (2018).https://arxiv.org/abs/1808. 04355.
[20]Schmidhuber J. A possibility for implementing curiosity and boredom in model-building neural controllers [M].Cambridge,MA: MIT Press,1991.
[21]Agrawal P,Carreira J,Malik J. Learning to see by moving [C]// Proc of IEEE International Conference on Computer Vision. Pisca-taway,NJ:IEEE Press,2015: 37-45.
收稿日期:2024-01-13;修回日期:2024-03-20 基金项目:国家自然科学基金资助项目(51604141,51204087)
作者简介:乔和(1973—),男,辽宁阜新人,副教授,硕导,博士,主要研究方向为人工智能算法的改进;李增辉(1997—),男(通信作者),山东潍坊人,硕士研究生,主要研究方向为深度强化学习方法改进(1363058235@qq.com);刘春(1998—),女,湖北十堰人,硕士研究生,主要研究方向为智能检测技术;胡嗣栋(1998—),男,江苏盐城人,硕士研究生,主要研究方向为神经网络算法改进.
