基于辅助信息与长短期偏好的序列推荐
2024-11-04刘超任梦瑶冯禄华




摘 要:
为了解决序列推荐中的用户偏好漂移问题,以及更精确地捕捉用户动态偏好,提出了一种新型的序列推荐模型SILSSRec(side information and long-short term preferences based sequence recommendation)。该模型首先利用项目的类别和频次作为辅助信息,基于用户的历史交互序列,生成个性化用户嵌入表示。然后,通过考虑历史交互和当前交互之间的时间间隔,生成个性化时间间隔嵌入,并将此嵌入与项目特征嵌入融合,形成个性化时间嵌入表示。模型采用注意力机制和门控循环网络,从嵌入表示中提取用户的长期和短期偏好。此外,通过对比学习强化偏好的特征表达,并使用自适应聚合网络动态融合这两种偏好,形成用户的最终偏好表示。在8个公开数据集上的实验结果表明,SILSSRec在评估指标上优于现有的基线模型,其中AUC(area under curve)平均提高了3.82%、召回率平均提高了7.2%、精确率平均提高了0.3%。实验证明SILSSRec在不同场景下均有较好表现,有效地缓解了偏好漂移问题,提升了推荐效果。
关键词:序列推荐;辅助信息;注意力机制;长短期偏好;对比学习
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)09-009-2628-07
doi:10.19734/j.issn.1001-3695.2024.01.0032
Sequence recommendation based on side information and long-short term preferences
Liu Chao, Ren Mengyao, Feng Luhua
(Chongqing University of Technology, College of Computer Science & Engineering, Chongqing 400054, China)
Abstract:
To address the issue of user preference drift and capture dynamic user preferences more accurately in sequence re-commendation, this paper proposed a novel model named SILSSRec. The model initially leveraged categories and frequencies of items as side information to generate personalized user embeddings based on users’ historical interaction sequences. Then it created personalized temporal interval embeddings by considering the time intervals between historical and current interactions, and integrated these embeddings with item feature embeddings to form personalized temporal embeddings. The model employed attention mechanisms and gated recurrent networks to extract users’ long-term and short-term preferences from the embedding representations. Furthermore, it used contrastive learning to reinforce the feature representation of preferences, and an adaptive aggregation network dynamically combined these two types of preferences to form the final preference representation of users. Experiments on eight public datasets demonstrate that SILSSRec outperforms existing baseline models on evaluation metrics, with an average increase of 3.82% in AUC, 7.2% in recall rate, and 0.3% in precision. The results validate that SILSSRec performs well in various scenarios, effectively mitigating the preference drift issue and enhancing recommendation performance.
Key words:sequence recommendation; side information; attention mechanism; long and short-term preferences; contrastive learning
0 引言
在信息量急剧增加的时代,推荐系统成为一种至关重要的个性化信息过滤工具。序列推荐因用户行为数据的急剧增长、个性化需求的提升和深度学习技术的进步而崭露头角。它是推荐系统领域的一个重要分支,主要预测用户基于历史行为序列的未来可能行为。序列推荐考虑了用户行为的时序性和顺序信息,有助于揭示用户动态兴趣,实现更精准、个性化的推荐[1]。这种方法在电商、音乐、新闻和社交网络等领域都表现出重要性和有效性,能为用户提供丰富且符合期望的在线体验,并有助于提高平台的用户活跃度和商业收益。
与基于用户静态偏好和物品静态特征的传统推荐系统不同,序列推荐更关注用户与物品之间的交互序列,强调时间的顺序性,因此更能反映用户行为和兴趣的动态变化。但由于用户兴趣是不断变化的,这可能导致模型捕捉到的用户偏好与当前的实际偏好存在偏差,这就是序列推荐面临的偏好漂移问题。解决偏好漂移问题通常的思路是增加辅助信息或者从不同维度进行兴趣捕获。
近年来,序列推荐采用了诸多创新技术和策略,包括协同过滤(CF)[2]、马尔可夫链[3,4]、矩阵分解[5,6]、贝叶斯概率模型[7]等。随着深度学习技术快速发展,基于深度神经网络的方法在序列推荐领域取得了显著的进展[8,9]。现有研究通过多种深度学习方法对序列特征进行提取,如使用卷积神经网络提取序列特征的CNN [10]和使用双向循环神经网络提取序列特征的Bi-LSTM[11]。注意力机制拥有并行性并且能与其他模型融合,因此也被广泛应用于序列推荐中,进行用户特征的提取[12]。ATRank[13]将多头自注意力组件应用于序列推荐任务,加快了训练速度并提高了预测能力,它使用时间信息作为辅助信息,并且把特征值直接加在项目嵌入上。CSAN[14]引入了一种在输入序列上嵌入双向位置的特征自注意力机制,以更好地发现序列内的内部相关性,它使用项目的位置信息作为辅助信息,设计了一个不可训练的位置矩阵,并将其值添加到相应位置的输入嵌入中。PACA[15]定义了一个上下文注意力网络,用注意力机制来捕捉位置关系包含的信息,其将位置信息作为辅助信息考虑,对每个位置生成一个嵌入,把位置嵌入和会话嵌入相乘作为会话总特征。为了提高序列推荐性能,一些学者还尝试引入辅助信息来丰富用户偏好表达。如BPR-MF[16]使用了项目的类别作为辅助信息,每个项目嵌入都是项目ID嵌入和类别嵌入的拼接。ULSP-SRM[17]则采用时序位置矩阵引入时间特征作为辅助信息,采用门控循环网络提取长期特征,使用注意力将长短期偏好进行融合。此外,还有一些研究从不同的时间尺度捕获序列的特征将用户偏好分为长期和短期。如LSPM[18]使用可训练矩阵捕获长期偏好,用最近项目作为短期偏好;SHAN[19]使用了非线性层次注意力网络来分别捕获用户的长期和短期偏好。
对比学习是深度学习领域的一个研究方向,其核心思想是通过对比不同数据点之间的相似性和差异性来进行学习。在对比学习中,模型被训练来区分和识别数据中的相似和不同的部分,通常是在同一批次的数据中进行。通过将相似的数据点拉近,将不相似的数据点推远,模型可以学会对数据的有用表示。这种方法在视觉表现学习[20]、自然语言处理[21]和图神经网络工程[22]中都取得了令人印象深刻的成就。
最近的一些研究也将对比学习引入到顺序推荐中。S3-Rec[23]设计的模型使用四个辅助的自我监督目标,通过使用相互信息最大值来进行数据的表示学习。CL4SRec[24]应用三种数据增强方式(即裁剪、遮蔽和重新排序)来生成正数对,并对正数对进行对比以学习到稳健的顺序转换模式。DuoRec[25]提出了一个基于Dropout的模型级扩增模型,采用监督下的正向采样策略,以捕捉自监督机制下来自序列的信号。
上述研究虽然已经取得了不错的推荐效果,但是仍存在一些不足之处:对时间或位置信息的特征嵌入是固定的,无法根据不同用户来进行调整,不能捕获用户的个性化偏好;同时没有充分利用用户对项目类别的偏好来完善用户的特征表达,只用原始的GRU提取长期特征会导致部分隐含信息被遗忘,捕获短期兴趣时没有考虑长期行为随时间衰减的情况;对长短期偏好的简单融合方法无法捕捉用户的动态兴趣变化;此外,采用数据增强方式获取自监督对比学习信号,可能会导致原始序列中的隐含信息被破坏。
为解决上述问题,提出基于辅助信息与长短期偏好的序列推荐模型(SILSSRec)。模型使用用户对项目类别的偏好作为辅助信息构建个性化用户嵌入,根据用户交互行为的发生时间提出个性化时间间隔感知的项目嵌入,将最近一日内的交互作为短期兴趣序列,使用注意力机制和门控循环网络综合考虑长期序列和短期序列得到最终的用户偏好表达,减少噪声,提升推荐性能。使用不同序列编码器产生的长期和短期偏好来导出自我监督信号,而不是直接增强原始序列,这种方式可以避免破坏原始数据中的内在模式,提高最终特征提取的精确度。本文主要贡献如下:
a)提出融合长短期偏好的时间间隔感知序列推荐模型SILSSRec,引入多种辅助信息来丰富用户的特征表达,降低数据的稀疏性,提高模型推荐效果。
b)通过基于注意力机制和门控循环网络的偏好提取层来提取用户的长期偏好和短期偏好,并设置对比学习来强化长短期偏好的特征表达,进一步提升模型性能。
1 SILSSRec模型
1.1 符号定义
假设数据集中用户数为n,交互项目数为m,项目类别数为q,定义用户集为U={u1,u2,…,un},交互项目集为I={i1,i2,…,im},项目类别集为C={c1,c2,…,cq}。对于每个用户u∈U,将其历史交互序列H中的所有交互按照发生时间以天为单位进行划分,即用户u的历史交互序列为H={Du1,Du2,…,Dut},t表示序列中的最大天数,DuiH(i∈[1,t])表示用户u在第i天的所有交互的集合。由此可以得到Dut 是用户最近一天的交互集合,将其定义为用户u在t时刻的短期历史交互序列,记作Sut=Dut。H中除Dut外的部分定义为用户u在t时刻的长期交互历史序列,记作Lut={Du1,Du2,…,Dut-1}。
1.2 模型结构
基于辅助信息与长短期偏好的序列推荐模型(SILSSRec)整体结构如图1所示。模型构建的思路如下:首先,将用户历史交互序列中的项目类别和频次作为辅助信息,生成用户的个性化嵌入表示, 从而丰富了用户的特征表达,并且降低数据的稀疏性;其次,根据用户的历史交互序列与当前交互之间的时间间隔,生成动态的个性化时间间隔嵌入,并将用户历史交互项目的特征嵌入与其对应的时间间隔嵌入融合生成用户历史交互项目的个性化时间嵌入表示,将时间间隔和项目类型作为辅助信息,能够动态地描述项目特征以更加准确地表示项目;然后,利用注意力机制和门控循环网络从用户的个性化嵌入表示、用户历史交互项目的个性化时间嵌入表示和当前时间段交互项目的嵌入表示中提取用户的长期偏好和短期偏好,并设置对比学习来强化长短期偏好的特征表达;最后,采用多层感知机对用户的长期与短期偏好进行动态整合,形成综合的用户兴趣偏好表示,该表示随后被用于系统的预测层,以实现对下一项目的推荐预测。
模型共包含五部分:
a)长期偏好提取部分。通过在用户的长期历史交互序列Lut中引入物品类别和交互时间间隔作为辅助信息,得到长期交互嵌入序列Lue,t,再通过偏好学习模块从中提取用户的长期偏好utl。具体来说,根据当前时刻用户的历史交互中出现频次最高的三个物品类别,加权融合作为当前时刻用户的物品类别偏好,与用户ID的嵌入表达拼接作为个性化用户嵌入;使用了阶梯式的时间窗口捕获机制来对一段时间内的历史交互序列与当前交互的时间间隔进行建模,得到个性化时间间隔嵌入,将用户长期历史交互项目的特征嵌入与其对应的时间间隔嵌入融合生成用户的长期交互序列嵌入表示。使用注意力机制从个性化用户嵌入、个性化长期交互序列嵌入表示中学习用户的长期偏好。
b)短期偏好提取部分。在用户的短期历史交互序列Sut中引入物品类别作为辅助信息,得到短期交互序列嵌入sut,再通过短期偏好学习模块,利用门控循环单元和注意力机制来综合考虑长期偏好对短期兴趣的影响,得到用户的短期偏好uts。
c)对比学习部分。对提取到的长短期偏好使用自监督对比学习方法强化特征表达。分别提取长期偏好的代理表征ucl,tl和短期偏好的代理表征ucl,ts,将其与长期偏好utl、短期偏好uts一起利用对比学习损失函数计算自监督损失。
d)自适应融合部分。通过基于多层感知机的自适应聚合网络,学习两种偏好的融合权重,将两种偏好动态融合,生成用户的最终偏好表示。
e)预测部分。通过将用户的最终偏好表示与目标项目进行点积,计算出用户的最终偏好表达和目标项目之间的相似度来进行预测。
1.3 长期偏好提取
1.3.1 长期交互序列嵌入
现有研究通常只将项目的ID和类别进行拼接,这种方法并没有考虑到用户交互项目的时间间隔对用户偏好的潜在影响,使得项目的嵌入表示不够准确。因此本文设计个性化项目时间间隔感知嵌入网络,来丰富用户历史交互项目的嵌入表示,得到最终的长期交互序列嵌入。
个性化长期交互序列嵌入过程如图2所示。首先计算出Lut中每一个交互的发生时间t与当前交互的时间间隔Δt。考虑到时间间隔是用来辅助表达用户的长期偏好,应该强化历史序列中长期稳定偏好的特征表达。同时,如果行为是在同一天产生的,则时间间隔嵌入的值是相同的。因此使用了阶梯式的时间窗口捕获机制来对时间间隔进行建模。由于原始数据过于离散不方便直接参与计算,按照2θ(θ=1,2,…,n)来划分时间窗口,θ为窗口序号,将用户历史交互的时间与当前交互的时间间隔一一映射到对应的时间窗口中,用窗口序号作为时间间隔的代表。这种方式有助于增强历史序列中长期稳定偏好的表达。公式如下:
2.3 实验环境和参数设置
为确保实验结果准确,所有实验均在使用Intel CoreTM i9-12900HX CPU和32 GB内存、8 GB显存的NVIDIA GeForce RTX 4060 Laptop GPU的Windows 11系统中,使用Python 3.7编程语言,依赖TensorFlow1.15.0深度学习库完成。
为了保证实验的公平性和可比性,保持各模型中的公共参数相同,唯一参数为最优。将嵌入维度设置为64,训练时BATCH_SIZE大小设置为32,测试时BATCH_SIZE大小设置为128,所有数据集的learning rate为 1,dropout rate 为0.2。
2.4 对比模型
为验证 SILSSRec 模型的有效性,将其与9个现有的主流推荐模型进行了对比:
a)BPR-MF:项目嵌入是项目ID嵌入和类别嵌入的串联,通过矩阵分解来处理隐反馈数据,从而为用户提供一个物品的排序。
b)CNN:对CNN结构中内核大小为32的feature map进行最大池化操作。利用这种方法对用户的历史行为进行编码,并将所有汇集的特征传递到一个完全连接的层来生成用户行为嵌入。
c)Bi-LSTM:为了捕捉序列之间的正向和反向关联,采用双向长短期记忆网络。
d)ATRank:它通过将所有类型的行为投射到潜在的语义空间中来考虑异构用户的行为。然后,ATRank利用自注意层和注意层结合DNN获得用户偏好。
e)PACA:位置感知上下文关注将每个时间位置视为可训练的位置向量。然后,PACA通过多层感知器(MLP)捕获每个项目的上下文和相应的会话作为特定于会话的特征向量。注意值由这两个向量生成。
f)CSAN-:在CSAN的嵌入层之后引入了特征自关注,使用不可训练的位置编码作为辅助信息。最后,通过自关注网络生成用户行为嵌入。由于CSAN还使用文本、音频和图像,而笔者没有使用它们,所以在实验中将这个不完整的模型表示为CSAN-[14]。
g)LSPM:训练嵌入矩阵捕获用户长期偏好,之后将最近k项交互融合作为用户的短期偏好。最后,LSPM结合这两个偏好来获得用户的兴趣表达。
h)CL4Rec:新提出的带有对比学习的序列推荐方法。
i)SHAN:使用非线性的分层注意网络分别学习用户的长短期偏好。
j)ULSP-SRM:将融入了时序位置嵌入矩阵的用户长期历史行为序列输入 GRU 单元中,得到用户的长期动态兴趣偏好。然后采用神经注意力机制将用户的短期兴趣序列和用户的长期偏好序列进行融合,得到用户的最终兴趣偏好表示。
2.5 性能比较
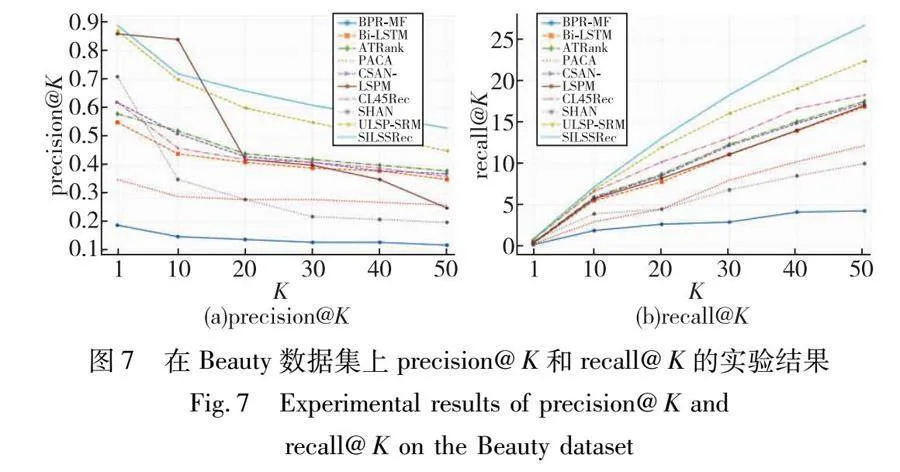
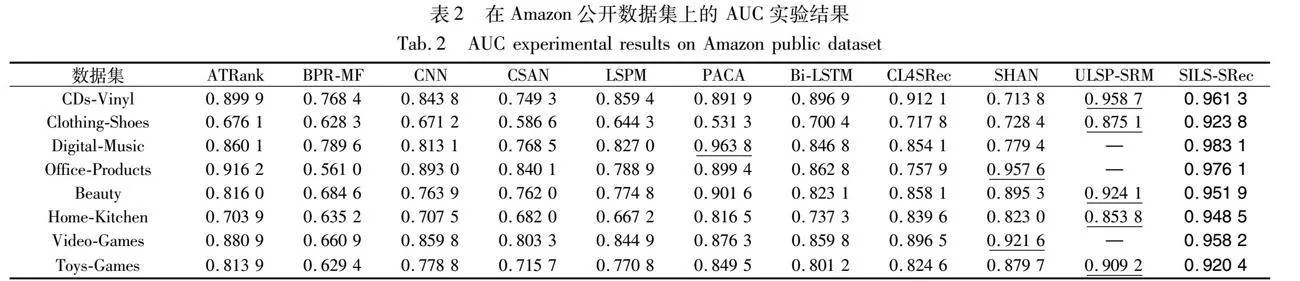
本文模型和其他对比模型的实验结果如表2所示,其中最优结果以粗体显示,次优结果以下画线显示。通过分析实验结果可以得出,模型SILSSRec 在8个子数据集上的AUC指标表现都优于对比模型,其中Beauty数据集的比较如图7所示。
从表中数据可以看出,除SILSSRec模型外,ULSP-SRM模型在多个数据集上的效果显著优于其他对比模型,这是因为ULSP-SRM模型在传统长短期偏好模型如SHAN的基础上引入了用户类别和时序位置嵌入作为辅助信息,进一步挖掘了原始序列中隐含的信息,更加准确地捕获了用户的偏好,证明了用户类别信息和交互时间间隔作为辅助信息对提升模型性能有着积极作用。本研究相比ULSP-SRM模型在五个数据集上的AUC指标平均提升了3.8%,这是因为本研究使用了多类别融合的个性化用户类别和个性化时间间隔嵌入,进一步增加了辅助信息包含的信息量,同时采用注意力机制将个性化用户嵌入和项目嵌入相结合,而不是ULSP-SRM的直接拼接,能够更好地将用户对项目类别的偏好融入长期偏好表达中。此外,本研究使用的自适应融合策略和自监督对比学习机制能够显著提升最终提取到的用户兴趣表达的准确性。
SILSSRec模型在CDs-Vinyl数据集上取得了最好的效果,说明本研究采用的长短期偏好提取方式能够准确地捕捉用户长期依赖关系和丰富的行为模式,在这样的稠密数据集上具有很高的有效性。在Clothing-Shoes数据集上,本文模型同样取得了最好效果,说明本研究采用的辅助信息方法有效弥补了原始序列信息不足的缺点,能够从有限的用户行为中学习到足够的信息来作出准确的个性化推荐,验证了模型在解决数据稀疏和冷启动问题上的有效性。模型在其他数据集上的优异表现,进一步证明了自适应融合机制和自监督对比学习的加入,赋予模型强大的特征学习能力和良好的泛化能力,使其能够应对各种实际应用场景的挑战。
2.6 参数分析
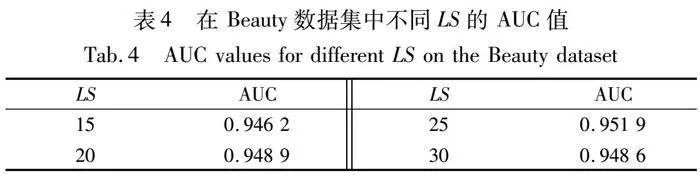
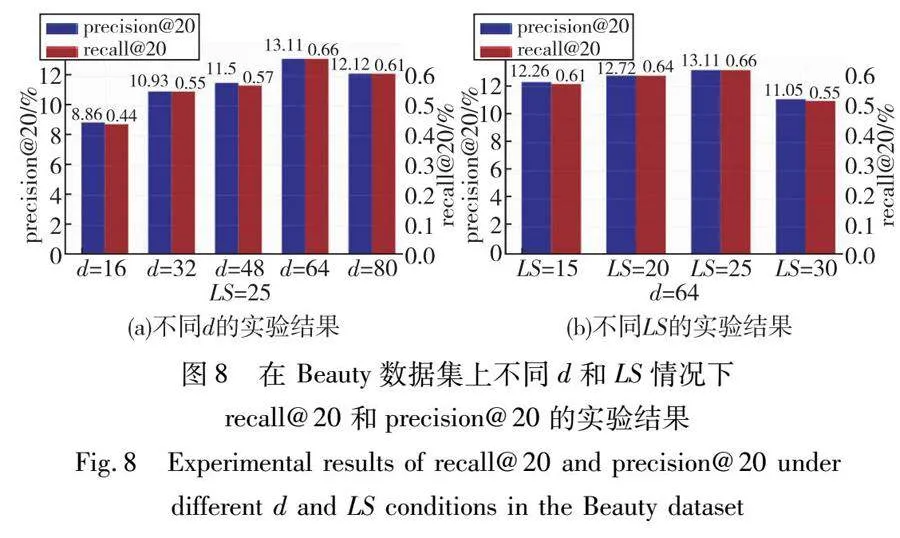
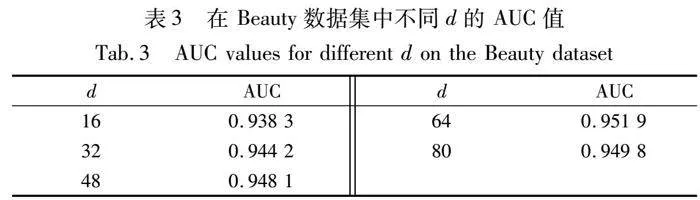
为了综合评估SILSSRec在不同超参数设置下的性能,本文对嵌入维数d和长期的序列长度LS进行了参数分析。在Amazon的子数据集Beauty上的实验结果如表3、4和图8所示。
1)嵌入维度d的影响
改变嵌入维度 d∈[16,32,48,64,80]来研究它的影响。如表3和图8(a)所示,增加维度可以提高模型性能,因为较大的潜在向量可以保留更多信息,而如果它太大,模型会开始收敛。该观察结果表明SILSSRec对嵌入维度敏感,且64维是一个较为合理的取值。
2)长期序列长度LS的影响
通过将其更改为不同的值来研究长期序列长度LS的影响。表4和图8(b)显示覆盖较长序列时性能会提高。但是,如果序列太长,模型效果就会下降。这种观察是可以解释的,因为过时的项目没有办法准确表达用户的偏好。当LS为25时,SILSSRec的效果最好,说明SILSSRec的序列长度敏感预测能力达到了顶峰。
2.7 消融实验
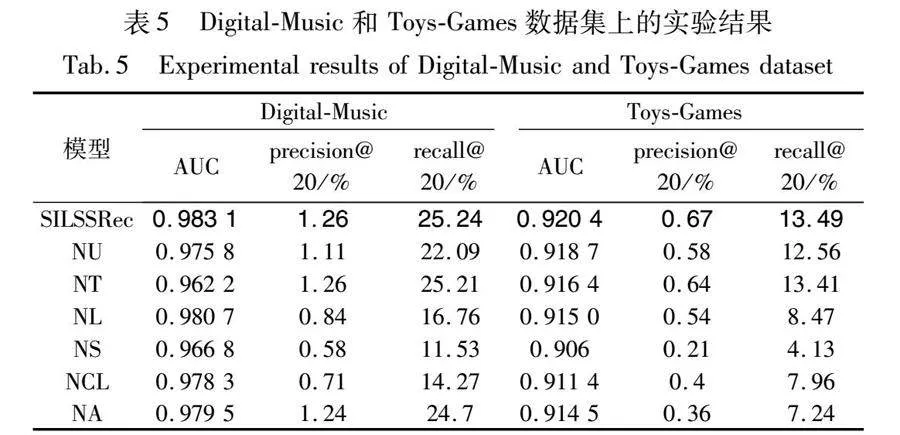
SILSSRec的主要组成部分是个性化用户嵌入模块、个性化的时间间隔嵌入模块和长短期偏好提取模块。为了验证SILSSRec中的每个主要组件对推荐性能作出的贡献,将删除相应的组件,得到以下变体:NU(没有用户个性化嵌入)、NT(没有个性化的时间间隔嵌入)、NA(没有长短期偏好自适应融合)、NL(没有长期偏好)、NS(没有短期偏好)、NCL(没有对比学习)。在Toys-Games和Digital-Music数据集上与完整模型进行对比实验。实验结果如表5所示。
本文得出以下结论:a)长期偏好和短期偏好在进行准确推荐时都很重要,尤其是后者在时间敏感性较强的下一项推荐中作用更为显著;b)根据用户喜欢的物品类别对用户进行动态分类,在捕捉用户偏好和提高推荐性能方面都有很大帮助;c)个性化时间间隔嵌入充分利用用户的行为模式,从而更好地学习了用户的兴趣偏好;d)设置对比学习,可以更好地分离长短期偏好,提升推荐效果;e)将长短期偏好自适应融合可以使长短期偏好动态地发挥各自的作用。因此,本文提出的融合辅助信息的长短期序列推荐模型各部分均有效果,能有效缓解推荐系统中的用户偏好漂移问题。
3 结束语
本文提出基于辅助信息与长短期偏好的序列推荐模型 (SILSSRec),有效解决了序列推荐存在的用户偏好漂移的问题。该模型将用户历史交互序列中项目的类别和频次作为辅助信息生成用户的个性化嵌入表示;同时,根据用户的历史交互序列与当前交互之间的时间间隔,生成动态的个性化时间间隔嵌入,并将用户历史交互项目的特征嵌入与其对应的时间间隔嵌入融合生成用户历史交互项目的个性化时间嵌入表示,使用注意力机制和门控循环网络从用户的个性化嵌入表示、用户历史交互项目的个性化时间嵌入表示和当前时间段交互项目的嵌入表示中提取用户的长期偏好和短期偏好,并设置对比学习来强化长短期偏好的特征表达。通过自适应聚合网络,将两种偏好动态融合,形成综合的用户兴趣偏好表示,随后将其用于系统的预测层,实现对下一项目的推荐预测。
在亚马逊公共数据集的8个子类别数据集进行实验,采用AUC值、recall@K和precision@K指标进行效果评估, SILSSRec模型的AUC值相比于效果次好的模型平均提升了约3.82%,最多提升了9.4%,在Beauty数据集上recall@K值平均提升了7.2%,precision@K值平均提高了0.3%,在不同数据集上的性能均显著高于其他评估模型,充分验证了本文模型在不同场景下的有效性。
在未来的研究中,笔者计划创新性地将知识图谱引入序列推荐,以提高推荐性能。基于知识图谱中丰富的连接性和语义信息,为结果提供可解释性,通过图和序列之间的对比学习获得更强的自我监督信号。
参考文献:
[1]汪菁瑶,吴国栋,范维成,等. 用户行为序列个性化推荐研究综述 [J]. 小型微型计算机系统,2022,43(5): 921-935. (Wang Jingyao,Wu Guodong,Fan Weicheng,et al. A review of research on user behavior sequence personalized recommendations [J]. Small Microcomputer Systems,2022,43(5): 921-935.)
[2]Chen Jie,Wang Xianshuang,Zhao Shu,et al. Deep attention user-based collaborative filtering for recommendation [J]. Neurocompu-ting,2020,383: 57-68.
[3]Rendle S,Freudenthaler C,Schmidt-Thieme L. Factorizing persona-lized Markov chains for next-basket recommendation [C]// Proc of the 19th International Conference on World Wide Web. New York: ACM Press,2010: 811-820.
[4]He R,McAuley J. Fusing similarity models with Markov chains for sparse sequential recommendation [C]// Proc of the 16th International Conference on Data Mining. Piscataway,NJ: IEEE Press,2016: 191-200.
[5]Qin Jiarui,Ren Kan,Fang Yuchen,et al. Sequential recommendation with dual side neighbor-based collaborative relation modeling [C]// Proc of the 13th International Conference on Web Search and Data Mining. New York: ACM Press,2020: 465-473.
[6]Khan Z,Iltaf N,Afzal H,et al. Enriching non-negative matrix factorization with contextual embeddings for recommender systems [J]. Neurocomputing,2020,380: 246-258.
[7]Morise H,Oyama S,Kurihara M. Bayesian probabilistic tensor factorization for recommendation and rating aggregation with multicriteria evaluation data [J].Expert Systems with Applications,2019,131:1-8.
[8]He Ruining,McAuley J. VBPR: visual Bayesian personalized ranking from implicit feedback [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2016.
[9]Zhou Yuwen,Huang Changqin,Hu Qintai,et al. Personalized learning full-path recommendation model based on LSTM neural networks [J]. Information Sciences,2018,444: 135-152.
[10]Zheng Lei,Noroozi V,Yu P S. Joint deep modeling of users and items using reviews for recommendation [C]// Proc of the 10th ACM International Conference on Web Search and Data Mining. New York: ACM Press,2017: 425-434.
[11]Jozefowicz R,Zaremba W,Sutskever I. An empirical exploration of recurrent network architectures [C]// Proc of International Conference on Machine Learning. [S. l. ]: Microtome Publishing,2015: 2342-2350.
[12]Vaswani A,Shazeer N,Parmar N,et al. Attention is all you need[C]// Proc of the 31st International Conference on Advances in Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2017:6000-6010.
[13]Zhou Chang,Bai Jinze,Song Junshuai,et al. ATRank: an attention-based user behavior modeling framework for recommendation [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018.
[14]Huang Xiaowen,Qian Shengsheng,Fang Quan,et al. CSAN: contextual self-attention network for user sequential recommendation [C]// Proc of the 26th ACM International Conference on Multimedia. New York: ACM Press,2018: 447-455.
[15]Cao Yi,Zhang Weifeng,Song Bo,et al. Position-aware context attention for session-based recommendation [J]. Neurocomputing,2020,376: 65-72.
[16]Rendle S,Freudenthaler C,Gantner Z,et al. BPR: Bayesian perso-nalized ranking from implicit feedback [EB/OL]. (2012-05-09) [2024-01-03]. https://doi. org/10. 48550/arXiv. 1205. 2618.
[17]雒晓辉,吴云,王晨星,等. 基于用户长短期偏好的序列推荐模型 [J]. 计算机科学,2023,50(4): 47-55. (Luo Xiaohui,Wu Yun,Wang Chenxing,et al. Sequential recommendation model based on user’s long and short term preference [J]. Computer Science,2023,50(4): 47-55.)
[18]Du Yingpeng,Liu Hongzhi,Qu Yuanhang,et al. Online personalized next-item recommendation via long short term preference learning [C]// PRICAI: Trends in Artificial Intelligence. Cham: Springer,2018: 915-927.
[19]Ying Haochao,Zhuang Fuzhen,Zhang Fuzheng,et al. Sequential re-commender system based on hierarchical attention network [C]// Proc of the 27th IJCAI International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018:3926-3932.
[20]Chen Ting,Kornblith S,Norouzi M,et al. A simple framework for contrastive learning of visual representations [C]// Proc of International Conference on Machine Learning. [S.l.]:PMLR,2020: 1597-1607.
[21]Gao Tianyu,Yao Xingcheng,Chen Danqi. SimCSE: simple contrastive learning of sentence embeddings [EB/OL]. (2021-04-18) [2024-01-03]. https://doi. org/10. 48550/arXiv. 2104. 08821.
[22]Yu Lu,Pei Shichao,Ding Lizhong,et al. Sail: self-augmented graph contrastive learning [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2022: 8927-8935.
[23]Zhou Kun,Wang Hui,Zhao W X,et al. S3-Rec: self-supervised learning for sequential recommendation with mutual information maximization [C]// Proc of the 29th ACM International Conference on Information & Knowledge Management. New York: ACM Press,2020: 1893-1902.
[24]Xie Xu,Sun Fei,Liu Zhaoyang,et al. Contrastive learning for sequential recommendation [C]// Proc of the 38th IEEE International Conference on Data Engineering. Piscataway,NJ: IEEE Press,2022: 1259-1273.
[25]Qiu Ruihong,Huang Zi,Yin Hongzhi,et al. Contrastive learning for representation degeneration problem in sequential recommendation [C]// Proc of the 15th ACM International Conference on Web Search and Data Mining. New York: ACM Press,2022: 813-823.
[26]刘超,朱波. 融合画像和文本信息的轻量级关系图注意推荐模型 [J]. 计算机应用研究,2023,40(4): 1037-1043. (Liu Chao,Zhu Bo. Light relational graph attention recommendation model fusing with profiles and text information [J]. Application Research of Computers,2023,40(4): 1037-1043.)
收稿日期:2024-01-12;修回日期:2024-03-09 基金项目:重庆市社科联资助项目(2021NDYB101)
作者简介:刘超(1983—),男,四川邻水人,副教授,硕导,博士,CCF会员,主要研究方向为社交网络分析;任梦瑶(1998—),女(通信作者),河南安阳人,硕士研究生,主要研究方向为推荐系统(575981031@qq.com);冯禄华(1998—),男,宁夏银川人,硕士研究生,主要研究方向为自然语言处理.
