CMHICL: 基于跨模态分层交互网络和对比学习的多模态讽刺检测
2024-11-04林洁霞朱小栋





摘 要:
多模态讽刺检测的关键在于有效地对齐和融合不同模态的特征。然而,现有融合方法通常忽略多模态间组成结构的关系,并且在识别讽刺时也经常忽略了多模态数据中与讽刺情感相关的共同特征的重要性。因此,提出一种基于跨模态分层交互网络和对比学习的模型。首先,跨模态分层交互网络采用了基于交叉注意力机制的最小单元对齐模块和基于图注意力网络的组成结构融合模块,从不同层面上识别文本和图像之间的不一致性,将低一致性的样本判定为含讽刺意味的样本。其次,该模型通过数据增强和类别增强两个对比学习任务,帮助学习讽刺相关的共同特征。实验结果表明,所提模型与基线模型相比,在准确率上提升了0.81%,F1值上提升了1.6%,验证了提出的分层交互网络和对比学习方法在多模态讽刺检测中的关键作用。
关键词:多模态讽刺检测;分层交互;对比学习;交叉注意力机制;图注意力网络
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)09-008-2620-08
doi:10.19734/j.issn.1001-3695.2023.12.0626
CMHICL: multi-modal sarcasm detection with cross-modal hierarchical interaction network and contrastive learning
Lin Jiexia, Zhu Xiaodong
(School of Management, University of Shanghai for Science & Technology, Shanghai 200093, China)
Abstract:
The key to multimodal sarcasm detection is to effectively align and fuse the features of different modes. However, the existing multimodal data fusion methods ignore the relationship between multimodal intercomponent structures. Also, the importance of common features associated with sarcastic emotions in multimodal data is overlooked in the process of recognizing sarcasm. To address the above problems, this paper proposed a model based on cross-modal hierarchical interaction networks and contrastive learning (CMHICL). Firstly, the cross-modal hierarchical interaction network employed a minimal unit alignment module based on the cross-attention mechanism and a compositional structure fusion module based on the graph attention network to identify inconsistencies between text and images at different levels, and determined the samples with low consistency as sarcasm samples. Secondly, two contrastive learning tasks, based on data enhancement and category enhancement, helped to learn common features related to sarcasm and reduce false correlations within the modality. The experimental results show that the proposed CMHICL model has increased the Acc by 0.81% and the F1 value by 1.6% compared to the baseline mo-dels, which verifies the key role of the hierarchical interactive network and contrastive learning method proposed in this paper in multimodal sarcasm detection.
Key words:multimodal sarcasm detection; hierarchical interaction; contrastive learning; cross-attention mechanism; graph attention network
0 引言
讽刺作为人类之间交流的一种特殊表达方式,通过幽默和讥讽来传递批评和反思。随着互联网的广泛使用,越来越多的用户通过发布帖子来表达自己的观点和看法,特别是在社交媒体、新闻报道、论坛和商品评价等方面。因此,为了全面挖掘这些数据中的信息,分析人类的态度、情感和倾向,有必要建立一个能够感知和理解讽刺意义的讽刺检测系统[1]。此外,用户在平台上的表达形式已不局限于文本,图文的结合往往能够更贴切地表达个人的情感[2,3],因此仅针对文本进行讽刺检测已经不足以区分用户的真实想法,在多模态下识别讽刺有助于检测帖子字面意义和真实意图之间的不一致性。然而,由于图像和文本处于不同的特征空间,多模态讽刺检测面临着一个挑战,即如何对齐和融合文本和图像模态的特征,以识别讽刺性表达中的情感矛盾。
目前的多模态讽刺检测研究中,有的研究方法通过直接串联图像模态和文本模态的特征来学习不一致的表达[4]。另有一些则利用注意力机制来融合不同模态之间的特征[5~7],或者采用模态内、模态间的交互图[1,8,9]对不同模态间的关系进行建模。尽管现有研究工作已取得较大进展,但这些方法仍然具有以下局限性:仅以微观视角考虑每个图像块和文本词元的一致性水平,且只在粗略层面上学习文本和图像间的关系。对于微观层面而言,讽刺可能通过图像局部区域或物体与文本中单词或短语含义的不协调性来传达,如图1(a)所示,图像中“99+”的通知量与文本的“little”形成鲜明的对比。然而,在一些情况下,图像和文本中隐含的感情可能在整体上完全相反,如图1(b)所示。在这种情况下,有必要探索宏观层面上的语义,在不同层次上(即图像和文本的组成结构)考虑文本与图像间更复杂的情感交互,以识别更复杂的不一致性。
此外,已有一些研究工作探索了对比学习在多模态领域的应用。这些研究利用对比学习方法来对齐文本和视觉信息[10],或将图对比学习应用于推荐系统[11]或情感分析上[12]。然而,关于利用对比学习在讽刺检测研究中提高模型提取具有辨别性特征能力的工作仍较缺乏。对比学习可以通过减小类内差异并增大类间差异,提升模型提取辨别性特征的能力;同时使多模态数据表征具有特征不变性,帮助减少模态内的错误相关性。例如,对于句子“作业是我生日最好的礼物”和“我收到的最好的生日礼物是家庭作业”,讽刺性体现在“作业”和“最好的礼物”上。尽管其他词语和句式发生了改变,但关键词传达的讽刺意味并没有改变,如果模型能够学习到这些讽刺的共同特征,就能够提高模型的性能。
因此,本文提出了一种基于对比学习和跨模态分层交互网络的方法CMHICL(cross-modal hierarchical interaction network and contrastive learning),用于多模态讽刺检测任务。其中,跨模态分层交互网络CMHI(cross-modal hierarchical interaction network)包括最小单元对齐模块MUAM(minimum unit alignment module)和组成结构融合模块CSFM(compose structural fusion module),最小单元指的是单个词元和单个图像块之间的对齐,组成结构级是指一系列词元和一系列图像块之间的对齐。这两个模块分别基于交叉注意力机制和图注意力网络,计算最小单元对齐度分数和组成结构的融合度分数,从微观和宏观两个角度学习图像和文本模态间的交互,识别不同模态之间的不一致性。此外,本文还提出了基于多模态的数据增强MBDA(multimodal-based data augmentation)和类别增强MBCA(multimodal-based category augmentation)的对比学习CL(contrastive learning)任务,通过MBCA帮助模型提取与讽刺类别相关的特征,并通过MBDA提升模型对数据中不变特征的学习能力。
本文的主要贡献包括三个方面:a)提出了CMHI方法,其在微观和宏观层面上考虑图像和文本间的交互,识别语义上的不一致性。CMHI方法使用基于交叉注意力机制的模块MUAM识别图像与文本在最小单元上的差异性,并利用基于图注意力网络的模块CSFM学习图像整体和文本上下文的不协调性。b)设计了MBDA和MBCA两个对比学习任务。MBDA通过数据增强扩充了样本数量,并在训练过程中增强了模型对样本的辨识能力;MBCA通过样本的标签,在训练过程中动态地减小了类内差异并增大类间差异。c)在公开的多模态讽刺检测基准数据集上进行一系列实验,结果表明,与已有方法相比,本文方法具有更优秀、更稳定的性能。另外,本文通过消融实验验证了本文CMHI和CL方法的有效性和必要性。
1 相关工作
1.1 讽刺检测
近年来,许多研究采用基于深度神经网络的方法进行文本的讽刺检测。Poria 等人[13]首先设计了基于预训练卷积神经网络的模型,用于提取情感和个性特征来进行讽刺检测。Tay 等人[14]提出了一种基于注意力的神经网络模型,对上下文的不相似性进行建模。文献[15]在编码器-解码器架构中引入了注意力机制,并采用三种不同的方法分别探索每种注意机制对讽刺释义的影响。考虑到单一模态数据对检测讽刺情感的准确性会受限,越来越多的研究工作使用多模态数据分析讽刺情感。
与纯文本的讽刺检测不同,基于多模态数据的讽刺检测旨在识别融合多种模态数据情况下的讽刺情绪[16]。Schifanella 等人[4]首次定义了多模态讽刺检测任务,并通过设计文本和视觉特征来处理基于文本模态和图像模态的讽刺检测任务。Cai 等人[5]创建了一个基于Twitter的多模态讽刺检测数据集,并提出了一种分层融合模型用于解决多模态讽刺检测任务。Pan 等人[6]设计了一种同时关注模态间和模态内不一致性的模型,利用注意力机制捕捉模态间的不一致性。此外,Liang 等人[1]提出了一种基于图的方法,为每个多模态示例构建异构的模态内和跨模态图,以确定模态内和跨不同模态的情感不一致,并且在此基础上设计了一个跨模态图卷积网络,利用重要的视觉信息和情感线索来感知模态之间的不一致关系。Liu 等人[17]提出了在分层模型中加入图像标题等外部知识资源,以增强模型讽刺检测的性能。
1.2 多模态数据融合
由于多模态数据融合对讽刺检测任务起到重要作用,有多项工作研究了不同数据模态间的融合方法。Zadeh 等人[18]首次提出了一种张量融合网络模型,实现双模态和三模态特征的交互。基于对模态之间的细粒度交互的关注,Chen等人[19]提出基于词级的多模态融合方法,包含门控多模态嵌入和具有时间关注度的LSTM(long short-term memory)两部分。Wu 等人[20]提出了以文本为中心的共享私有框架用于多模态融合,以文本模态为核心,通过其他两种模态增强文本的语义。受Pan等人[6]启发,Xu等人[7]通过构建分解和关系网络对跨模态对比和语义关联进行建模。李丽等人[21]采用了图神经网络的消息传递机制实现多模态特征融合。
然而,上述工作存在一个不足之处,即缺乏在多模态数据不同层次上的交互,以及在宏观层面上对语义结构的深入探索。为了解决上述局限性,本文提出了跨模态分层交互网络(CMHI),其使用交叉注意力机制和图注意力网络去捕捉图像和文本在不同层面上的对齐和融合。
1.3 对比学习
自监督学习是一种无须人工标注标签的学习方法,在自然语言处理、计算机视觉和语音处理等领域取得了重大进展。在计算机视觉领域,SimCLR[22]作为简单的视觉表征对比学习框架被提出,在表征和对比损失之间引入可学习的非线性转换。在MoCo[23]这个项目中,研究人员以对比学习为出发点,构建了一个具有队列和移动平均编码器的动态字典,这一方法使得所学到的表征能够更好地迁移到下游任务中。在自然语言处理领域,ConSERT[24]和SimCSE[25]将对比学习应用于句子表征学习,并取得了较高的性能。对比学习在多模态领域也得到了广泛应用,如Clip[26]利用图片-文本对进行对比学习训练,预训练后,用自然语言来引用已学过的视觉概念,从而将模型迁移到下游任务中;UNIMO[10]通过跨模态对比学习,将文本和视觉信息对齐到一个统一的语义空间,并且能够利用大规模数据学习更通用的表征。在多模态情感分析的工作中,Lin 等人[12]提出了一种层次图对比学习(HGraph-CL)框架,加入图对比学习策略,探索基于图增强的更合适的图结构。
然而,为了帮助系统学习更富有判别性的特征表示,对比学习在讽刺检测任务中应用,以实现这一目标的可能性仍然缺乏深入的探索。对此,本文将提出的基于多模态的数据增强(MBDA)和类别增强(MBCA)两个对比学习方法集成于模型的训练中,帮助提高模型性能。
2 CMHICL模型
在本文模型包括了图像、文本的特征提取编码器,以及用于信息融合的跨模态分层交互模块。首先,用于提取图像、网络特征的骨干网络分别学习各自的高维表征。然后,在通过交叉注意力机制(cross-attention mechanism)进行跨模态特征对齐后,计算矩阵内积得到最小单元的对齐度分数。接下来,将最小单元模块的输出作为图注意力网络的输入,分别得到图像和文本模态的结构表示,并计算两个模态的融合度分数。模型可通过基于多模态的数据增强(MBDA)和类别增强(MBCA)的对比学习训练任务去拟合多模态的数据分布,具体过程如图2所示。
2.1 文本模态表示
文本模态的处理中,对于给定的单词序列s={wi}ni=1,采用预训练BERT模型[27]和一个额外的多层感知器(MLP)提取文本特征,得到词级别的上下文表示,并解决一词多义的问题.每个词wi被映射成d维的词向量表示:
4 实验
4.1 数据集
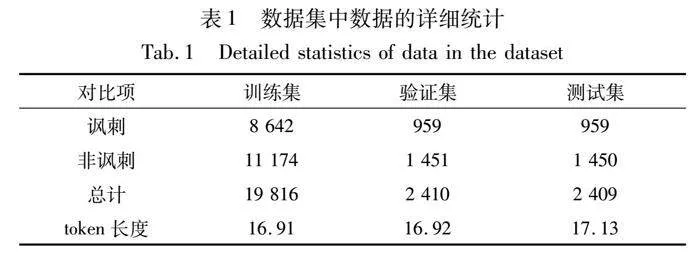
实验中,本文采用了文献[5]公开可用的多模态讽刺检测基准数据集,该数据集是基于Twitter网站中用户发表的评论构建的,每个示例包含一个图像和对应的文本,并且每个图像-文本对都有单独的情感标注。其中,标签为1表示情感值为讽刺性,并包含一些话题标签(比如:#sarcasm,#joking 等);标签为0表示情感值为非讽刺性,不包含以上话题标签。此外,本文采用了与文献[5]相同的数据预处理方法,将数据集按照8∶1∶1的比例随机划分为训练集、验证集和测试集,数据集的详细数据如表1所示。
4.2 实验设置及评价指标
本文使用了spaCy提取文本中词元之间的依赖关系,并采用BERT-base-uncased[27]和ViT模型[28]获取文本和图像的嵌入。对于图像预处理,首先将图像的尺寸调整为224×224,然后将其划分为32×32的图像块,即r=49。模型训练方面,本文采用了Adam优化器,学习率设置为2E-5,权重衰减为5E-3,批量大小为64,并使用了早停机制避免过拟合。式(16)中的系数λMBDA和λMBCA都设置为1.0。将多头交叉注意力机制的头数设置为2,其层数为3,图注意力网络的层数设置为1,在5.4节中将对关键超参数的取值影响展开实验分析。本实验使用了准确率(Acc)、精确率(Pre)、召回率(Rec)和F1值作为评价指标。
4.3 对比模型
本文将基线模型分为文本模态模型、图像模态模型和多模态模型三种类型,用于与CMHICL进行比较。
对于文本模态模型,仅使用文本数据进行讽刺检测。TextCNN[32]是一种用于文本数据的基于CNN的深度学习网络;Bi-LSTM结合了两个LSTM层,在处理长序列数据时表现出色,用于处理文本时,能够捕捉句子中最重要的语义信息;SIARN[14]采用了多维内部注意力机制的神经网络模型进行讽刺检测;SMSD[33]使用自匹配网络捕获句子中的语义不一致信息;BERT[26]是一种基于Transformer-encoder的预训练语言模型,通过在大规模无标签数据上进行预训练,可以捕捉词语、短语和句子之间的语义关系。
对于图像模态模型,仅使用图像数据进行讽刺检测。Image模型[5]使用ResNet[34]的池化层之后的图像向量来预测讽刺检测;ViT[28]利用Transformer架构和自注意力机制,使得模型能够从图像中获取全局的上下文信息;ConvNeXt[35]是一种基于CNN的模型,在图像处理方面取得了先进的性能。
对于多模态模型,则同时使用文本数据和图像数据进行多模态讽刺检测。HFM[5]提出一个新的分层融合框架模型来处理多模态讽刺检测任务;近来提出的模型,如D&R Net[7]、Res-BERT[6]、Att-BERT[6],都是基于注意力机制;InCrossMGs[1]和CMGCN[8]是基于图神经网络的模型;HKEmodel[17]将图像标题作为外部知识资源资源加入其分层模型中,用于提高讽刺检测的性能。
5 结果
5.1 讽刺检测任务结果
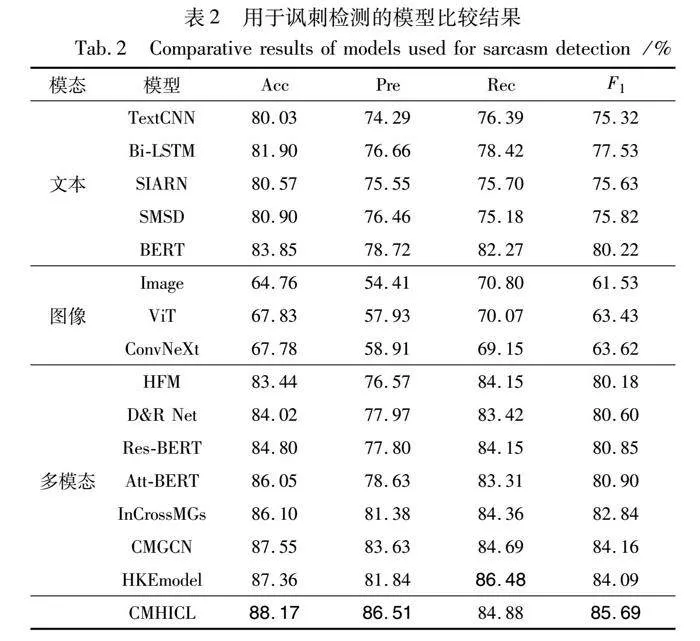
表2展示了本文模型与基准模型在性能上的比较结果。在讽刺检测任务中的实验结果表明,首先,基于文本模态的方法在性能上优于基于图像的方法,这表明文本中包含更多的讽刺性语义信息,具有更高的信息量。其次,多模态的方法在性能上优于单模态的方法,证明图像和文本的不一致性能够更好地表达讽刺性信息。同时,在多模态任务中,使用注意力机制的模型,如D&R Net[7]、Res-BERT[6]、Att-BERT[6],以及引入图神经网络方法的模型,如InCrossMGs[1]和CMGCN[8],在性能上取得了更好的效果。与HKEmodel[17]相比,本文模型在准确率(Acc)上提升了0.81百分点,在精确率(Pre)上提升了4.67百分点,在F1值上提升了1.6百分点。这表明本文模型通过识别图像和文本在局部区域和全局上的不协调性,并结合数据增强和标签增强的对比学习任务,在讽刺检测任务上取得了更好的性能。此外,本文模型优于使用外部知识的HKEmodel,进一步验证了分层模块与对比学习的结合在捕获图像和文本间的跨模态不一致性方面的优越性和有效性。
5.2 消融实验结果
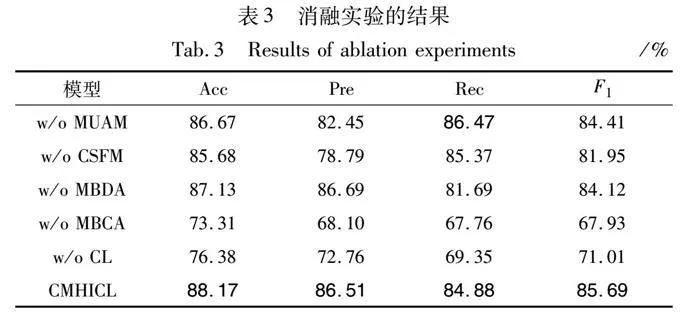
本文为了进一步验证模型中各个模块的有效性,进行了多组消融实验,包括:a)去除最小单元对齐模块(w/o MUAM);b)去除组成结构融合模块(w/o CSFM);c)去除数据增强模块(w/o MBDA);d)去除标签增强模块(w/o MBCA);e)去除对比学习训练任务(w/o CL)。
实验结果如表3所示,从表中可看出,当组合所有模块时,模型取得了最佳性能。从w/o MUAM和w/o CSFM的结果中可以观察到,去除组成结构融合模块(w/o CSFM)会导致性能显著下降,这表明在宏观层面上捕捉文本的语义依赖和图像的空间关系及结构对于识别文本模态和图像模态的不一致性起到更重要的作用,能够有效地检测讽刺。此外,去除对比学习模块(w/o CL)也导致性能下降,说明对比学习在讽刺检测任务中具有有效性。特别是在去除类别增强模块(w/o MBCA)时,模型性能大幅下降,这证明类别增强能够引导模型更有效地学习讽刺的共同特征,增大类间方差,使不同情感类别的样本相互远离。去除数据增强模块(w/o MBDA)会导致轻微的性能下降,这表明数据增强能够减少模态内的错误相关性,增加模型对于噪声和变化的鲁棒性,从而提高讽刺检测的性能。
5.3 不同图像、文本骨干网络的影响
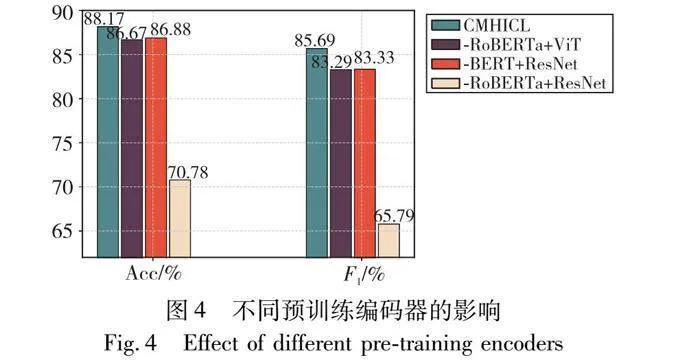
预jfYLFbKVANBT+X4AZeUR/g==训练编码器的影响:为了研究本文CMHICL与不同预训练编码器搭配使用的效果,并进一步分析使用BERT和ViT作为文本和图像的预训练编码器的原因,设置了以下变体,实验结果如图4所示。
a)BERT+ResNet:用BERT作为文本编码器,将ViT替换为ResNet-152,将每个图像块嵌入为2 048维向量。
b)RoBERTa+ViT:用RoBERTa替换BERT作为文本编码器,使用ViT作为图像编码器。
c)RoBERTa+ResNet:使用RoBERTa和ResNet编码器替换BERT和ViT编码器。
通过实验结果的观察,可以得出结论:基于BERT和ViT的CMHICL模型在准确率和F1值方面表现出色。BERT和ViT都是经过大规模预训练的模型,使用强大的预训练模型作为文本和图像编码器可以获得更好的节点表示,从而实现更好的聚合和性能。同时,它们在各自领域取得了显著的成果。BERT在自然语言处理任务中表现出色,ViT在计算机视觉任务中也取得了很好的效果。因此,将它们作为CMHICL的编码器可以充分利用它们在文本和图像领域的优势,提高模型的性能和泛化能力。
5.4 关键超参数的影响
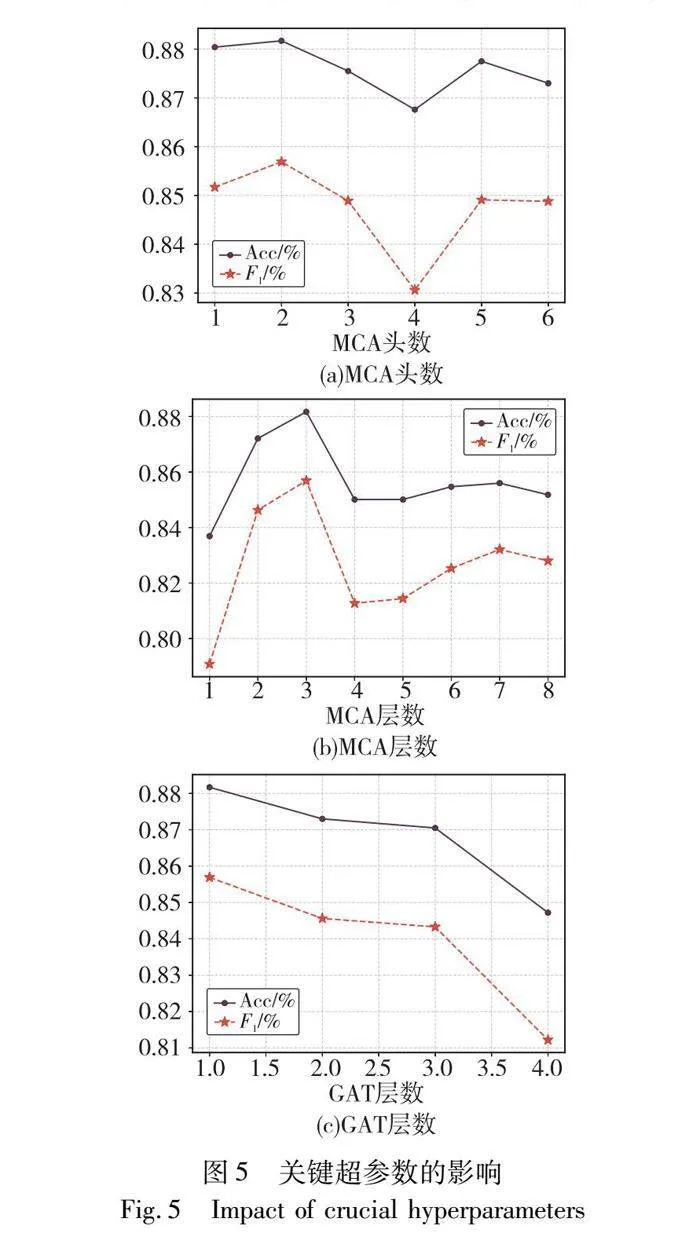
为了对比不同超参数的取值对模型性能的影响,本节比较了模型在不同的MCA头数、MCA层数以及GAT层数下讽刺检测任务的结果。考虑MUAM中MCA不同头数的影响,取MCA头数为1~6,验证其头数对模型性能的影响,结果如图5(a)所示。当MCA头数为2时,模型性能最佳。在此之后,随着头数的增加,性能有所下降。原因可能是:a)注意力头数的增加不适用于多模态讽刺检测任务中捕捉文本与对应图像间的关联信息,并且可能导致模型在训练集上过拟合;b)不同模态的数据之间存在复杂的关联,而增加注意力头数可能导致模型过度关注多模态数据中的局部信息,使得在最小单元对齐时忽略了全局关联信息。
考虑在MUAM中MCA层数的影响,本文将MCA层数取1~8,以验证其层数对模型性能的影响,实验结果如图5(b)所示。在层数从1~3逐渐增加的过程中,准确率和F1值呈现上升的趋势,达到了最佳性能。然而,随着层数进一步增加,模型的性能开始下降。这可能是因为在最小单元对齐模块中,交叉注意力机制在前三层已经学习到了重要的信息,而后续层可能过度拟合了噪声或无关信息,导致性能下降。
对于CSFM中GAT层数的影响,本文将GAT层数分别设置为1~4,实验结果如图5(c)所示。结果表明,当文本和图像都使用一层图注意力网络时,模型达到最佳的性能。然而,随着层数的增加,模型的性能逐渐下降。这里分析原因可能如下:a)GAT模型层数过多时,节点间的注意力权重可能会逐渐趋于相似,导致节点之间差异性减小,失去自身的特性,导致产生过平滑问题;b)过深的GAT模型可能会记住训练集中的一些异常样本或噪声,而无法泛化到测试集上,导致性能下降。
5.5 讽刺情感样本聚类可视化
为了验证对比学习是否能够帮助模型学习更多隐含在多模态数据中与讽刺相关的共同特征,本文实施了样本聚类的可视化。在实验中,提取模型最后一层的数据特征向量进行可视化降维,使用t-SNE方法[36]将高维向量转换为二维向量,降维结果如图6所示。图6(a)是提取经过CMHI网络后的特征向量进行降维得到的,图6(b)是CMHICL模型输出的结果可视化。从图中可以看出,当去除对比学习模块时,数据分散在向量空间中,且有大量的重叠,表明模型难以区分不同讽刺情感的样本;图6(b)加入对比学习后,可以发现讽刺类数据全部聚集在中间部分,即相同情感数据的聚合程度更明显,而讽刺情感和非讽刺情感在向量空间中拉开了更大的距离。这说明加入对比学习能够帮助模型学习同一讽刺情感的共同特征,据此将向量空间中的数据进行分类,拉近类内距离,增大类间差距,提升多模态高级表征的辨别性,进一步证明了本文CMHICL在多模态讽刺检测任务上的有效性。
5.6 案例分析
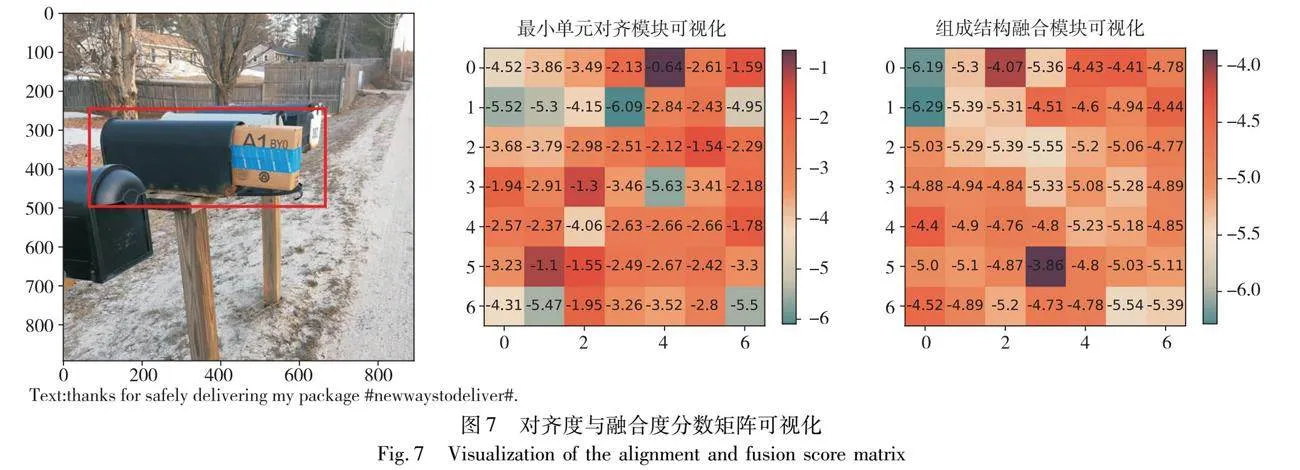
为了证明本文所提分层交互网络的有效性,本节选取Twitter数据集中的一组图像和文本作为案例,如图7所示,其中文本内容为“感谢你安全地投递我的包裹 #新的投递方式”(译文),若仅从文本的角度看,该句话并未表达出讽刺意味;然而,由于图像中的包裹是裸露在外的,与文本表达意思相反,因此本文CMHICL在将图像和文本的信息融合后,成功检测出该例子呈现讽刺意味。进一步地,将该图像-文本对输入MUAM和CSFM模块后分别得到的最小单元对齐度分数Mu以及组成结构融合度分数Mc进行可视化,得到对应的一致性分数图,若数值越小,则说明图像与文本的一致性越低,检测出讽刺意味的可能性越大。从最小单元对齐模块可视化图可发现,图像中包裹的对应区域(红框区域)的一致性分数较高,无法准确地判断出讽刺意味;而组成结构融合模块降低了包裹对应区域的融合度分数,并且区域更为集中,凸显出包裹区域与文本在讽刺检测中的低一致性。这表明,组成结构融合模块能够识别文本和图像更复杂的结构,从整体宏观的角度关注图片与文本的不一致性,弥补最小单元对齐模块的片面性,全面、综合地建立多模态融合表征与讽刺意图标签的映射,提高了模型检测多模态讽刺情感的性能。
6 结束语
本文提出了一种用于多模态讽刺检测的对比学习和跨模态分层网络。其采用了交叉注意力机制和图注意力网络,分别从最小单元层面和组成结构层面对图像和文本模态进行对齐和融合,从而学习多模态数据之间更复杂的关系。此外,为了减少模态内的错误相关性,并识别与讽刺相关的共同特征,本文设计了基于多模态数据增强和类别增强的对比学习任务。实验结果表明,本文模型相比多个基线模型具有竞争力和有效性。此外,本文模型仍存在以下局限性:a)基于类别增强的对比学习方法仍需要借助类别标签的监督信号,考虑到在多媒体数据中精准采集标签的巨大成本,后续工作将尝试采用自监督学习的方法,帮助系统学习到更具有判别性的特征表示;b)本文模型未考虑外部知识中包含的丰富信息,后续工作中将从图像中提取图像标题、形容词-名词对(ANPs)等信息进一步辅助讽刺检测任务;c)目前方法仅针对图像和文本两个模态的数据,在未来工作中将把其他模态数据如音频、视频、人体生理数据等纳入讽刺检测任务中,以进一步丰富模型的多模态数据分析能力。此外,在单一模态数据缺失情况下的多模态讽刺检测任务也值得深入探讨。
参考文献:
[1]Liang Bin,Lou Chenwei,Li Xiang,et al. Multi-modal sarcasm detection with interactive in-modal and cross-modal graphs[C]// Proc of the 29th ACM International Conference on Multimedia. New York: ACM Press,2021: 4707-4715.
[2]Zhang Dong,Li Shoushan,Zhu Qiaoming,et al. Effective sentiment-relevant word selection for multi-modal sentiment analysis in spoken language[C]// Proc of the 27th ACM International Conference on Multimedia. New York: ACM Press,2019: 148-156.
[3]Zhang Dong,Wei Suzhong,Li Shoushan,et al. Multi-modal graph fusion for named entity recognition with targeted visual guidance[C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press,2021: 14347-14355.
[4]Schifanella R,De Juan P,Tetreault J,et al. Detecting sarcasm in multimodal social platforms[C]// Proc of the 24th ACM International Conference on Multimedia. New York: ACM Press,2016: 1136-1145.
[5]Cai Yitao,Cai Huiyu,Wan Xiaojun. Multi-modal sarcasm detection in twitter with hierarchical fusion model[C]// Proc of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2019: 2506-2515.
[6]Pan Hongliang,Lin Zheng,Fu Peng,et al. Modeling intra and inter-modality incongruity for multi-modal sarcasm detection[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2020: 1383-1392.
[7]Xu Nan,Zeng Zhixiong,Mao Wenji. Reasoning with multimodal sarcastic tweets via modeling cross-modality contrast and semantic association[C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2020: 3777-3786.
[8]Liang Bin,Lou Chenwei,Li Xiang,et al. Multi-modal sarcasm detection via cross-modal graph convolutional network[C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2022: 1767-1777.
[9]余本功,季晓晗. 基于ADGCN-MFM的多模态讽刺检测研究[J]. 数据分析与知识发现,2023,7(10): 85-94. (Yu Bengong,Ji Xiaohan. Research on multimodal sarcasm detection based on ADGCN-MFM[J]. Data Analysis and knowledge Discovery,2023,7(10): 85-94.)
[10]Li Wei,Gao Can,Niu Guocheng,et al. UNIMO: towards unified-modal understanding and generation via cross-modal contrastive learning[C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2021: 2592-2607.
[11]Liu Kang,Xue Feng,Guo Dan,et al. Multimodal graph contrastive learning for multimedia-based recommendation[J]. IEEE Trans on Multimedia,2023,25: 9343-9355.
[12]Lin Zijie,Liang Bin,Long Yunfei,et al. Modeling intra-and inter-modal relations: hierarchical graph contrastive learning for multimodal sentiment analysis[C]// Proc of the 29th International Conference on Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2022: 7124-7135.
[13]Poria S,Cambria E,Hazarika D,et al. A deeper look into sarcastic tweets using deep convolutional neural networks[C]// Proc of the 26th International Conference on Computational Linguistics. StpFZ7tEqXRa4YJgAFQ5ZaQZJW1eET/6YTp5JqKOPnmD4=roudsburg,PA: Association for Computational Linguistics,2016: 1601-1612.
[14]Tay Y,Tuan L A,Hui S C,et al. Reasoning with sarcasm by reading in between[C]// Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2018: 1010-1020.
[15]Keivanlou-Shahrestanaki Z,Kahani M,Zarrinkalam F. Interpreting sarcasm on social media using attention-based neural networks[J]. Knowledge-Based Systems,2022,258: 109977.
[16]Joshi A,Sharma V,Bhattacharyya P. Harnessing context incongruity for sarcasm detection[C]// Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2015: 757-762.
[17]Liu Hui,Wang Wenya,Li Haoliang. Towards multi-modal sarcasm detection via hierarchical congruity modeling with knowledge enhancement[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2022: 4995-5006.
[18]Zadeh A,Chen Minghai,Poria S,et al. Tensor fusion network for multimodal sentiment analysis[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2017: 1103-1114.
[19]Chen Minghai,Wang Sen,Liang P P,et al. Multimodal sentiment analysis with word-level fusion and reinforcement learning[C]// Proc of the 19th ACM International Conference on Multimodal Interaction. New York: ACM Press,2017: 163-171.
[20]Wu Yang,Lin Zijie,Zhao Yanyan,et al. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis[C]// Proc of Findings of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2021: 4730-4738.
[21]李丽,李平. 基于交互图神经网络的方面级多模态情感分析[J]. 计算机应用研究,2023,40(12): 3683-3689. (Li Li,Li Ping. Aspect-level multimodal sentiment analysis based on interaction graph neural network[J]. Application Research of Computers,2023,40(12): 3683-3689.)
[22]Chen Ting,Kornblith S,Norouzi M,et al. A simple framework for contrastive learning of visual representations[C]// Proc of the 37th International Conference on Machine Learning. [S.l.]: JMLR.org,2020: 1597-1607.
[23]He Kaiming,Fan Haoqi,Wu Yuxin,et al. Momentum contrast for unsupervised visual representation learning [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 9729-9738.
[24]Yan Yuanmeng,Li Rumei,Wang Sirui,et al. ConSERT: a contrastive framework for self-supervised sentence representation transfer[C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2021: 5065-5075.
[25]Gao Tianyu,Yao Xingcheng,Chen Danqi. SimCSE: simple contrastive learning of sentence embeddings[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2021: 6894-6910.
[26]Radford A,Kim J W,Hallacy C,et al. Learning transferable visual models from natural language supervision[C]// Proc of the 38th International Conference on Machine Learning. [S.l.]: PMLR,2021: 8748-8763.
[27]Devlin J,Chang Mingwei,Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics,2019: 4171-4186.
[28]Dosovitskiy A,Beyer L,Kolesnikov A,et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03). https://arxiv.org/abs/2010.11929.
[29]Velikovic' P,Cucurull G,Casanova A,et al. Graph attention networks[EB/OL]. (2018-02-04). https://arxiv.org/abs/1710.10903.
[30]Edunov S,Ott M,Auli M,et al. Understanding back-translation at scale[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2018: 489-500.
[31]Cubuk E D,Zoph B,Shlens J,et al. RandAugment: practical automated data augmentation with a reduced search space[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway,NJ: IEEE Press,2020: 702-703.
[32]Kim Y. Convolutional neural networks for sentence classification[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2014: 1746-1751.
[33]Xiong Tao,Zhang Peiran,Zhu Hongbo,et al. Sarcasm detection with self-matching networks and low-rank bilinear pooling[C]// Proc of the World Wide Web Conference. New York: ACM Press,2019: 2115-2124.
[34]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 770-778.
[35]Liu Zhuang,Mao Hanzi,Wu Chaoyuan,et al. A ConvNet for the 2020s [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 11976-11986.
[36]Van der Maaten L,Hinton G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research,2008,9(11): 2579-2605.
收稿日期:2023-12-15;修回日期:2024-02-29 基金项目:国家自然科学基金面上项目(71871144)
作者简介:林洁霞(1999—),女,广东潮州人,硕士研究生,CCF会员,主要研究方向为自然语言处理、多模态情感分析;朱小栋(1981—),男(通信作者),安徽太湖人,副教授,硕导,博士,主要研究方向为数据挖掘与深度学习、电子商务(zhuxd@usst.edu.cn).
